WekaIO has hired Ken Grohe as president and chief revenue officer, as it looks to ramp up to IPO.
Grohe joins from Stellus Technologies, a Samsung backed startup that shut down the entire sales and marketing team in April – just three months after launching its first product.
Ken Grohe.
Weka CEO Liran Zvibel said in a statement: “Ken’s expertise in this market and keen understanding of the customer journey will be the catalyst that drives the next phase of growth for Weka… Ken’s role will be influential in executing the company’s vision to become the de-facto solution for enterprise high-performance computing.”
Steve Duplessie, senior analyst at Enterprise Strategy Group (ESG) chipped in: “I have known Ken since our shared time at EMC, he is one of the best performing sales and marketing executives you will ever meet.”
Grohe’s career includes senior positions at SignNow, Barracuda Networks, Virident, and encompasses a 25-year stint at Dell EMC, where he finished as GM for the global flash business.
He told us he had been job hunting and had received two written and two verbal offers when the Weka offer arrived. Grohe said customers he talked to advised him to join WekaIO. Weka’s momentum impressed him, with its 600 per cent revenue growth rate in 2019, and so far maintaining growth rates in the pandemic.
“This company more resembles VMware than any other company I know,” Grohe added. He said its product is hardware-agnostic and heterogeneous, widely applicable and scales to huge levels; “We eat petabytes for lunch.”
Sales success
He noted existing OEMs, like HPE, have already invested in Weka. And he reckons it can keep the peace with partners – as VMare does -and grow the market overall for everyone.
Grohe tells us there are four general strategies to grow sales to high levels; VARs, OEMs, selling direct to masses of customers, and big game hunting – going directly for million dollar-size deals. Weka is equipped to do all four simultaneously, he said.
There’s confidence there. In his hiring announcement he declarles: “I have proven success in this market, and I am grateful to join the leadership team and to have the opportunity to influence and guide Weka into the next phase of growth…The pathway to IPO is ahead of us.”
Stellus
And Stellus? Grohe declined to comment. That company has gone quiet since May and executives are not responding to our enquiries.
That company launched its first product at the beginning of February. So what reason would there be for CEO Jeff Treuhaft to pull the sales and marketing plug three months later? Did Samsung cut funding for some reason? is it pandemic-related? It’s a mystery.
Intel has announced second generation Optane Persistent Memory DIMMs with the same capacity as gen 1 but faster IO. The company has also launched new SSDs.
Intel said the PMEM 200 series is optimised for use with gen 3 Xeon 4-socket processing systems, which also launched today.
The Optane PMEM 200 series DIMMs come in 128GB, 256GB and 512GB capacities and their sequential bandwidth is up to 8.10GB/sec for reads and 3.15GB/sec for writes. The first generation series runs up to 6.8GB/sec reading and can reach 2.3GB/sec writes.
We calculate the PMEM 200 is around 19 per cent faster at reads and 37 per cent faster at writes. On average, there is 25 per cent higher memory bandwidth overall, according to Intel. That’s a benefit of using 4-layer XPoint, instead of the 2 layers in gen 1.
Endurance varies with capacity. 128GB = 292 petabytes written; 256GB = 497PBW; 512GB = 410PBW. For comparison, the gen 1 256GB capacity product has a 360PBW rating.
Intel says the PMem 200 series provides up to 4.5TB of memory per socket for data intensive workloads (e.g. in-memory databases, dense virtualisation, analytics, and HPC.)
3D NAND SSDs
The new data centre D7-P5500 and P5600 SSDs are U.2 format drives, built with 96-layer 3D NAND in TLC cell format and an NVMe interface running across PCIe Gen 4 with 4 lanes. The P5500 has a 1 drive write per day endurance while the P5600 has a 3DWPD rating, making it better suited to heavier write workloads.
Available capacities are 1.92TB, 3.84TB and 7.68TB for the P5500. The P5600 needs to over-provision for extended endurance, and so available capacities come in lower at 1.6TB, 3.2TB and 6.4TB.
The PCE gen 4 links should enable high performance. The P5500 and P5600 deliver 7GB/sec when sequential reading and 4.3GB/sec when writing. Both drives provide up to 1 million random read IOPS, with the P5500 delivering up to 230,000 random write IOPS and P5600 providing up to 260,000 random write IOPS.
Zerto, the disaster recovery startup, has raised $53m in equity and venture debt financing. It will use the money to bolster its cash position and on updating its software.
Details are thin – the valuation is not disclosed and there is no momentum press release boasting of sales growth. Also the capital raising comes less than three months after significant layoffs. This looks defensive and it would be no surprise if this is a down round.
CEO Ziv Kedem said in a statement today: “This is another milestone for the business and allows us to confidently push forward with our plans to provide customers with a solution for their next generation business realities.”
Zerto raised $70m four years ago in its previous funding round. Established in 2009, Zerto is a startup only in the sense that it has not yet filed for IPO. The company claims more than 8,000 customers and over 1,500 resellers. Entirely unconfirmed and unsourced revenue estimates range from $104m-$140m.
Our take is that Zerto needs to add cloud-native and general backup strings added to its bow before it can envisage an exit. Datrium and others are pushing hard on the ransomware disaster recovery front. Also Kasten and Portworx shows that basic containerised app DR is possible through Kubernetes.
Zerto, by contrast, looks a bit old-fashioned and expensive. The company has to develop great technology to preserve and extend the customer base into cloud-native apps. It also needs to make progress with a continuous journalling approach to general backup.
Data management startup Cohesity has hired a chief financial officer- its first since 2017. The appointment of Robert O’Donovan signifies a change of gear in its financial strategy to emergence from VC funding status.
Cohesity needs a CFO to prepare the company for IPO, according to our sources, who say a trade sale is the less preferred option. O’Donovan joins the company from DataStax, where he was CFO. He also held senior positions at Pivotal and Dell EMC.
Robert O’Donovan.
Cohesity CEO and funder Mohit Aron issued a quote: “At this important stage in the evolution and growth of Cohesity, Robert’s years of experience managing the financial operations for innovative technology market leaders will help support our ambitious business objectives.”
O’Donovan also issued a quote: “The scale and growth Cohesity has achieved is testament to the tremendous value that its data management innovations bring to organisations, and my role is to ensure the company has the best framework to continue transforming the industry.”
Cohesity last had a CFO in late 2017. Since then, SVP Lorenzo Montesi has held the financial reins, navigating the company through $250m D-round in 2018 and a $250m E-round this year. Total funding now stands at $660m. Montesi will now report to O’Donovan.
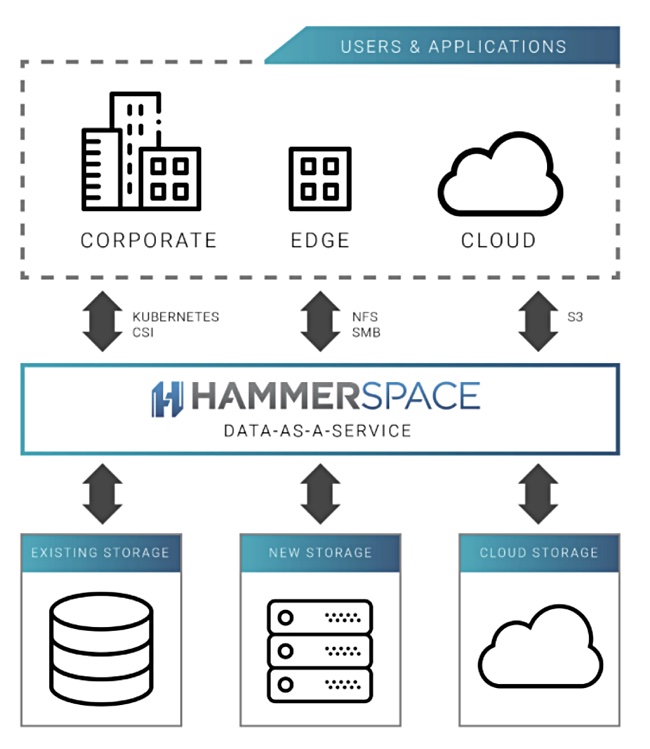
Hammerspace came out of stealth in December 2018 with a software technology said to unify file silos into a single network-attached storage (NAS) resource that can provide access to unstructured data anywhere, in hybrid or public clouds. Since then it has extended its reach, for example, adding Kubernetes support and ransomware protection.
Blocks & Files had the opportunity to conduct an email interview with CEO and co-founder David Flynn. We asked him how the Covid-29 pandemic has affected the company and also how Hammerspace positions itself against competitors. His replies have been edited for brevity.
Flynn co-founded FusionIO, a pioneering all-flash storage startup, but left the company about 18 months before its $1.1bn acquisition by SanDisk in 2014. He then co-founded Primary Data, a data management startup that bagged $100m funding in cash and debt over four years. However, the company shut in January 2018 without bringing product to market. Hammerspace emerged from the ashes in May 2018, in the same offices as Primary Data.
David Flynn.
Blocks & Files: How has the Covid-19 pandemic affected demand for the Hammerspace product?
David Flynn: The pandemic is forcing people to accelerate their cloud initiatives, deploying tools, and workloads at scale to support unexpected growth in their remote workforce. Hammerspace helps customers leverage the infrastructure that they already have to get their data to the cloud nearly instantly and without the need for a data migration. Hammerspace is experiencing a surge in demand, as customers see us as an easy-button for their woes.
Hammerspace saves time and cost for IT by greatly reducing intervention, eliminating tedious tasks like sync jobs between sites or remote backup. Customers tell us that this saves them millions of dollars.
Blocks & Files: How does Hammerspace tech help work-from-home employees?
David Flynn: We have been working with our channel partners and Citrix to increase productivity and the experience for Citrix Virtual App and Desktop users (CVAD). What we bring to Citrix VAD is that users and all their data no longer must be ‘homed’ to a single location.
Hammerspace untethers ‘User Profile Data; so that we can automatically and instantly bring it closer to the users, increasing productivity by saving time and improving performance.
Also, because our replication is multi-site active-active, user data won’t be lost in an outage. So, regardless of where your employees or consultants sit – we can get them to access their data using the cloud, co-lo facilities, or their own data centers without a hiccup.
Hammerspace says it supplies data as a service.
Blocks & Files: How has Hammerspace messaging changed concerning the relationship between data and the storage infrastructure?
David Flynn: Over the last year, our messaging has evolved; but the fundamentals that the company was founded on remain true.
Hybrid IT is made up of multiple data centers full of mixed infrastructure from various vendors pushing an array of cost-models. The only way to bring order to this chaos is to adopt a data-centric approach to how we store, access, manage, and protect data.
Hammerspace helps customers by intelligently leveraging the underlying infrastructure without being subordinate to it. Our model turns that chaos into a strength, giving us the resources to adapt to ever-changing needs by continuously optimizing data across any-and-all hybrid infrastructure.
Blocks & Files: How do you market this?
David Flynn: How do we market a successful product around it? People have budgets for storage that do data management, but they don’t have budgets for data management. So, we have taken the gloves off and position ourselves as software-defined hybrid cloud storage.
Hybrid cloud storage from Hammerspace can store, serve, manage, and protect data anywhere – on white-box servers, on enterprise NAS, on any public or private cloud, and in Kubernetes. We emphasize our unique value including data-in-place assimilation, an active-active global file system, autonomic data mobility, Kubernetes integration, and enhanced metadata. We do this while significantly reducing the overall TCO of storage, improving performance, and getting complexity under control.
Blocks & Files: What sort of customers buy Hammerspace and why? What amount of data do they need to have stored for them to find Hammerspace technology useful?
David Flynn: Hammerspace customers are diverse, spread across telecoms, media & entertainment, financial services, federal, and pharmaceuticals – among others. While some of our customers have industry-specific workflows, the broad base suffers from many of the basic hybrid cloud use-cases such as data migrations, DR to cloud, archive, or adding persistent storage to Kubernetes.
Our customers have told us that they are looking for something easier to manage while reducing the overall cost of storage. Data growth is forcing them to search for a better way to get hundreds of TB to tens of PB of unstructured data to the cloud and are frustrated with the storage-centric approaches pushed by legacy NAS vendors and their derivatives.
Blocks & Files: Is Hammerspace a software-defined storage metadata management product that abstracts existing file and object storage in whatever on-premises or public cloud location it happens to be, and enables customers to better optimise data placement for performance, cost, and compliance?
David Flynn: This is a great way to articulate what we do, but I would make a few suggestions. Right now, Hammerspace is not targeting regulatory compliance use-cases. On the other hand, our product is fully featured for data protection and to serve data directly as storage.
One other essential note – we are also having success as a storage and data management solution for Kubernetes. We upend the misguided idea that you need to create yet another storage silo with a container-specific storage platform. With our CSI driver, we support both block and file persistent volumes, we provide feature-rich enterprise-class data management capabilities to Kubernetes for single, multi-cluster, and hybrid-cloud environments – using any storage.
Our recent article about Fujifilm’s Object Archive software, which will support object data on its magnetic tape, prompted PoiNT Systemes to get in touch.
The German firm’s S3-enabled Archival Gateway software already pumps excess object data to tape, thus saving more expensive disk capacity.
Yesterday the company added support for IBM TS3500 and TS4500 libraries, “covering both LTO drives and IBM 3592 series models” via the release of Version 2.1 of the software.
Founded in 1985, PoINT originally developed archive storage on optical disks – and for a few years it was owned by Digital Equipment Corp. Today, independently owned PoINT develops storage management software and an archive gateway to move object storage data to tape using the S3 protocol. There are solution briefs for NetApp StorageGRID and Cloudian’s HyperStore and customers include Daimler, Bayern Invest, SiXT, ReiseBank and WAVE Computersysteme.
Archival Gateway
PoINT Archival Gateway features erasure coding, parallel access to tape drives for high throughput rates and multiple library support for high capacity scaling. It supports up to 256 tape drives (LTO or IBM 3592) and eight libraries and can pump data at 230GB/sec. That mean13.8TB/min, 828TB/hour, and realistically can go past 1PB/day.
The software runs on redundant server nodes. Using its own format, it saves blocks of data redundantly on different tape cartridges so that data is not lost, should one cartridge fail. Object data is stored natively, with data and metadata preserved. This means objects are restored without conversion or rebuild processing.
The software supports multiple tape libraries:
PoINT Archival Gateway is described in a white paper. It has two instantiations: interface nodes which link to accessing client systems; and database nodes which look after target tape systems. These nodes run separately from each other and multiple copies can be executed, providing parallelism. Accessing clients link to the gateway across Ethernet. The gateway then links to the tape libraries using Fibre Channel or iSCSI.
PoINT told us it will support the Fujifilm object initiative. Software engineer Manfred Rosendahl said: “Currently the PoINT Archival Gateway uses its own tape format to provide features like erasure coding, which is not possible with the previously available formats like LTFS. We’ve been talking to Fujifilm for some time now and we will also support the new OTFormat in future releases of PoINT Archival Gateway.”
DDN, the veteran high performance computing storage vendor that recently bought several enterprise storage businesses, has had a makeover.
Here is its new logo:
And this is what the company has to say about the new logo.
“DDN’s new circular segmented logo symbolizes the company’s new energy and reflects its path of continuous innovation and renewal. A bright and vibrant new color scheme pays tribute to its legacy and modernizes the brand to underscore the company’s dedication to its customers and the desire to combine the best technologies with dynamic expertise to deliver a streamlined experience with deeper more valuable insight into their data assets.”
So there you have it, but why did the company go to the bother of a rebrand? DDN has emerged from a flurry of acquisitions to become an enterprise and HPC vendor covering containers, virtual systems, files, blocks, objects, and software-defined storage.
Nexenta SW-defined file and object storage in May 2019
IntelliFlash organisation from Western Digital in September 2019
Bulked-up DDN says it has 10,000 customers and is the largest privately-held storage supplier, with 20 technology centres around the globe. The company has assimilated the acquisitions into DDN and Tintri business units and is now pitching itself a provider of “Intelligent Infrastructure”. It can provide storage to enterprise and HPC customers and support on-premises, public cloud and hybrid cloud use.
DDN offers classic storage for HPC, which is basically parallelised data access to vast data file stores. HPC-style IT has been adopted by enterprises for big data analytics and the AI/machine learning world.
Tintri’s patch – legacy on-premises enterprise IT – is evolving too, with virtualised servers meeting a wave of containerisation and Kubernetes orchestration and a widening adoption of software-defined storage to avoid hardware supplier lock-in. That storage in general is unifying some or all of block, file and object access to simplify the storage infrastructure, and adopting a predictive analytics-style management facility delivered as a service.
The on-premises world is butting up against public cloud and reacting with hybrid clouds combining on-premises and public cloud IT facilities and consumed with public cloud-like on-demand scalability and subscription payment schemes.
Behold the new DDN, which says HPC-like workflows in the enterprise market, driven by AI and huge analytics, are moving IT organisations to embrace parallel file systems and scalable data management platforms.
Sure, storage demand is growing, but DDN is now competing with the mainstream storage array vendors (Dell, HPE, NetApp, Pure, etc.), filer and object storage suppliers (Isilon, Qumulo, Cloudian, Scality, etc.), and HPC businesses such as Panasas, as well as new technology startups (Infinidat, StorONE, VAST Data, Weka, etc.)
DDN’s HPC market strength gave it the financial firepower to make the four acquisitions. Can it parlay this into general enterprise IT market success against such a widespread array of deep-pocketed and new, VC-funded technology suppliers? Let’s hope it does because that will spur them to do better too.
Open source developer MayaData has announced Kubera; a product for the operational management of Kubernetes.
Kubernetes came into being at Google because managing the development, deployment and de-commissioning if containers was excessively complex for developers. Now MayaData has launched Kubera because managing Kubernetes has become too complex.
Murat Karslioglu, Head of Product at MayaData, issued a quote: “Kubera builds on our experience in supporting a community of thousands of OpenEBS users. Originally intended to be used only by our support – we quickly learned that our users could benefit from Kubera as well.”
He says individual users and enterprises of all sizes are finding that Kubera helps them to achieve cost savings and productivity gains when using Kubernetes.
Kubera is a service delivered from the cloud and its functionality includes;
Simplified configuration, management and monitoring of stateful workloads on Kubernetes, including Kafka, PostgreSQL, Cassandra, and other workloads
Simplified back-up of stateful workloads on Kubernetes, whether the workloads are stored in the CNCF open-source project OpenEBS or otherwise
Dynamic visualisations of an entire Kubernetes environment, with point and click controls for capabilities such as snapshotting and cloning of data and compliance checks and alerts
Automated lifecycle management of data layer components including a newly available Enterprise Edition of OpenEBS and underlying storage such as disks and cloud volumes.
MayaData CEO Evan Powell told us: “An analogy might be helpful. Whereas our OpenEBS is often compared to vSAN from VMware – Kubera provides the analytics, visualization, controls and automation for efficient operations of OpenEBS on Kubernetes much like VMware’s vRealize Operations software provides similar capabilities to users of vSAN.
Free individual Kubera plans are available as well as Team and Enterprise plans including support services from MayaData for the entire environment including the OpenEBS Enterprise Edition and related components. Kubera subscriptions start at $49 per user per month.
Update; June 17 – SAS roadmap and performance data added.
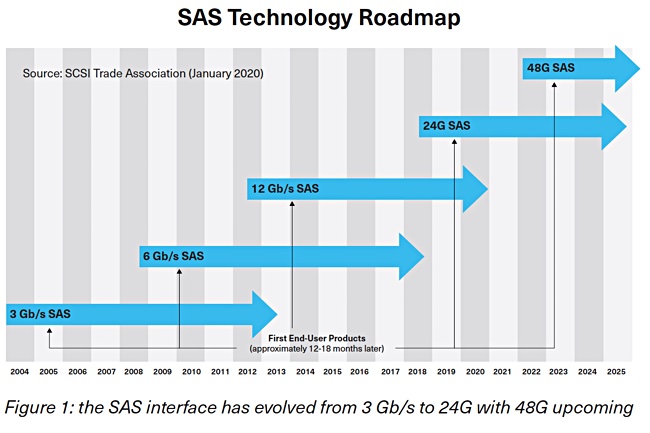
Although the NVMe interface is set to rule the fast SSD interface roost, Kioxia has released a PM6 gen 4 SAS interface drive running at 24Gbit/s.
This is double the bandwidth of current 12Gbit/s SAS links, which is good news for system builders wedded to SAS.
SAS technology roadmap to 48Gbit/s.
Otherwise the PM6 looks pretty much like its PM5 predecessor. That 12Gbit/s SAS drive was launched in August 2017 and used Kioxia’s (then Toshiba’s) 64-layer BiCS 3D NAND technology in TLC format. The PM6 gets the benefit of newer 96-layer BiCS tech in the same TLC format, meaning KIoxia can produce drives with the same capacity as before but using fewer dies, so lowering its costs.
Like the PM5, the PM6 comes in write-intensive, mixed-use, and read-intensive versions, with different endurance levels; 10, 3 and 1 drive writes per day respectively. Capacities vary in each case;
PM6 WI – 400GB, 800GB, 1.6TB, 3.2TB,
PM6 MU – 800GB, 1.6TB, 3.2TB, 6.4TB, 12.8TB,
PM6 RI – 960GB, 1.92TB, 3.84TB, 7.68TB, 15.36TB, 30.72TB.
Update: The initial performance data supplied by Kioxia is sequential read bandwidth of up to 4.3GB/second. The PM5 in read-intensive form delivered up to 2.1GB/sec so that improvement is welcome.
Other PM5 performance numbers are; up to 340,000 random read IOPS, 120,00 random write IOPS, and 2.72GB/sec sequential write throughput. Kioxia subsequently said the PM6 has, compared to the PM5 read-intensive model;
Up to 54 per cent improved sequential write bandwidth – calculated to be 3.2GB/sec
Up to 144 per cent better random read performance – calculated to be 489,600 IOPS
Up to 185 per cent greater random write performance – calculated to be 222,00 IOPS
KIoxia tells us the PM6 is a dual-port enterprise drive and is capable of recovering from the failure of two of its dies. The security features include sanitise instant erase (SIE), TCG Enterprise self-encrypting drive (SED) and FIPS 140-2 certification.
PM6 drives are now available for evaluation and qualification. Samples of 30.72TB products are scheduled to be available after August. SSDs based on 24G SAS will soon be available in servers from market leading OEMs. Market availability for the PM6 24G SAS SSD Series is expected in Q4 2020.
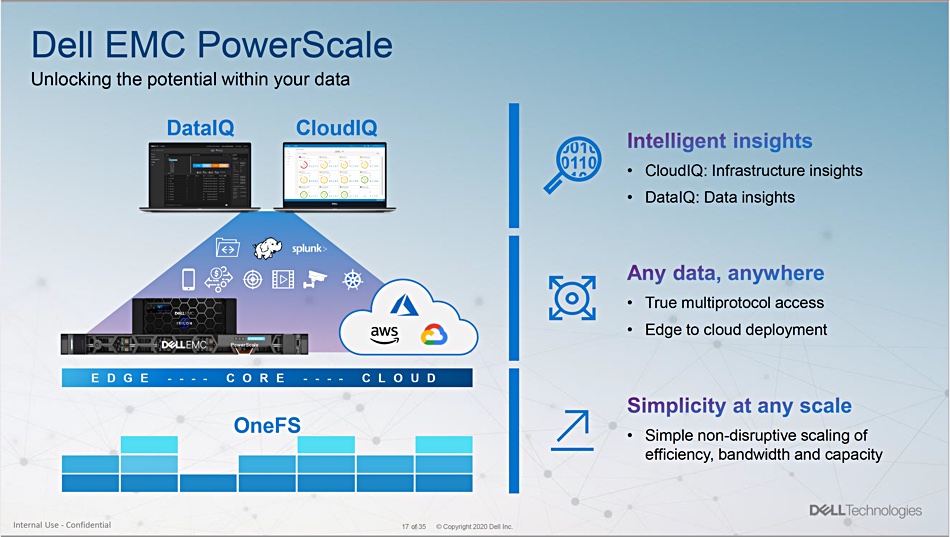
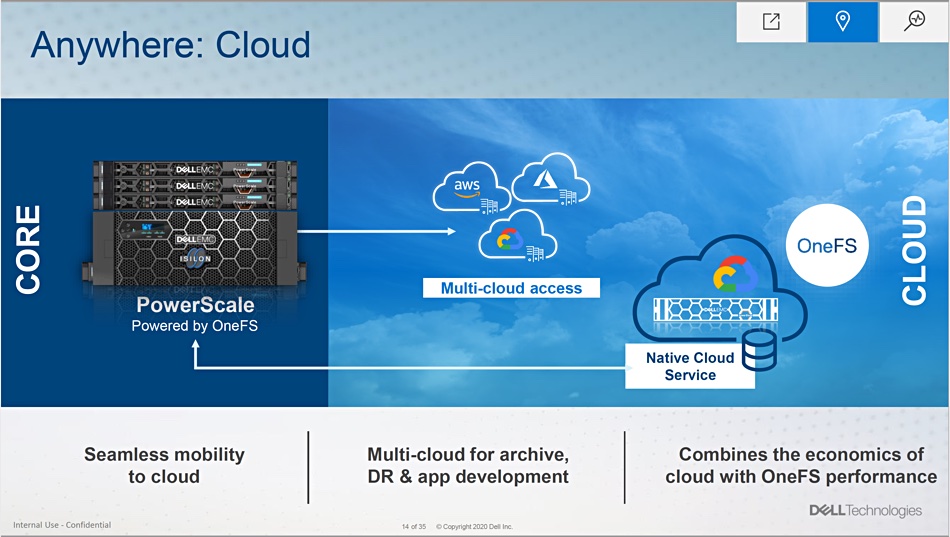
Dell has updated its Isilon scale-out filers with new PowerScale branding and products as well as S3 object access and a DataIQ data analytics feature.
PowerScale is the brand that Dell deputy chairman Jeff Clarke referred to in comments about the coming Unstructured.NEXT product in the Q1 earnings call in May, calling it “the last of the powering up of the portfolio.”
Dan Inbar, GM and president for Storage at Dell, issued a quote: “The amount of unstructured data enterprises store as file or object storage is expected to triple by 2024, and there are no signs of it slowing.”
Dell has now, following on from the PowerStore launch, completed its Power-branding of its storage products. It has two unstructured data storage products: Isilon for files and ECS for object storage.
By adding S3 object access to v9.0 of the PowerScale OneFS operating system, the way is paved for a unified Isilon/ECS product line. However, ECS and Isilon are not coming together yet, with ECS meant for purpose-built object stores.
Hardware
There are two PowerScale models, both all-flash and 1U in size, and each based on a Dell PowerEdge server – the F200 SAS drive system and the F600 all-NVMe drive system. The existing Isilon range has three product classes covering a high performance to high capacity spectrum:
All-flash nodes – F800 and F810 (basically F800 + deduplication)
Hybrid flash/disk nodes – H600, H500, H5600 and H400
Nearline and Archive filers – A200 and A2000 for cool and cold data.
The PowerScale F200 and F600 fit in the all-flash node category and slot in below the F800 in capacity terms.
PowerScale F200 and F600 systems.
The F200, a single CPU socket system with just 4 SSDs (960GB, 1.92TB, 3.84TB) and 3.84TB to 15.36TB capacity, is aimed at Internet edge, remote and branch office (ROBO) deployments.
The F600 is a higher performing system with two CPU sockets, 8 drives (1.92TB, 3.84TB, 7.68TB) and a 15.36TB to 61.44TB capacity range. Its processing power supports OneFS deduplication and compression and it could go in larger ROBO sites and in data centres for media and entertainment workloads.
There can be from 3 to 252 of these systems in a cluster and they can be mixed and matched with existing Isilon clusters.
In comparison the F800, with a Xeon E5-2697A v4 CPU, is much higher capacity, supporting 60 SAS SSDs (1.6TB, 3.2TB, 3.84TB, 7.68TB, 15.36TB) with a 96TB to 924TB range.
Performance
Dell has not released specific PowerScale product performance numbers or even released details of the actual CPUs used. However, it has said the v9 PowerScale OneFS can deliver up to 15.8 million IOPS and the new PowerScale nodes (F200 and F600) are up to 5x faster than “its predecessor,” without specifying the predecessor. We think it is the F800.
We know the F800 provides up to 250,000 IOPS and 15GB/sec throughput as a single node, and we can compare F200 and F600 attributes to that.
The F200 with just one CPU and 4 SAS drives supports 2 x 10/25GbitE network links whereas the F800, with its 60 drives and single CPU, supports 2 x 10/25/40 GbitE. We suspect the F200 will be slower than the F800.
The F800 can have up to 256GB of memory for its CPU to handle the 60 SAS SSDs, but the F600, with just 8 x NVMe SSDs (faster than SAS), has up to 384GB of memory; 50 per cent more DRAM for 86 per cent fewer drives. It also supports 2 x 10/25/100 GbitE networking, more than the F800’s 40GbitE top end.
The F600’s superiority in CPU socket number, DRAM capacity, SSD speed, and IO port bandwidth suggests that its IOPS and throughput numbers will be significantly higher than those for the F800. In fact we think the F600 will deliver 5x more performance than the F800, meaning 1.25 million IOPS and more throughput as well. A literal 5x throughput improvement would mean 75GB/sec but we think this could be unrealistic.
Operating System
The F200 and F600 are supported by v9 of the (PowerScale) OneFS operating system, codenamed Cascades. It runs on all existing Isilon nodes as well. This version adds S3 object access to existing support for NFS, SMB and HDFS.
All data on the system can be simultaneously read and written through any protocol.
Data reduction has been improved to make it up to 6x better than the previous OS version, delivering an effective increase in capacity for existing Isilon nodes supporting data reduction, such as the F810.
OneFS v9.0 supports clusters with up to 60PB of raw capacity; an immense amount. New nodes can be added to a cluster and brought online in a claimed 60 seconds. Then the data load across the cluster can be automatically rebalanced to relieve hot spots. Old nodes can be decommissioned with no downtime.
There are new Ansible and Kubernetes integrations to make PowerScale better suited for DevOps work.
PowerScale OneFS can also run in the AWS, Azure and Google clouds, enabling a single environment across Internet Edge, ROBO, data centre and public cloud locations.
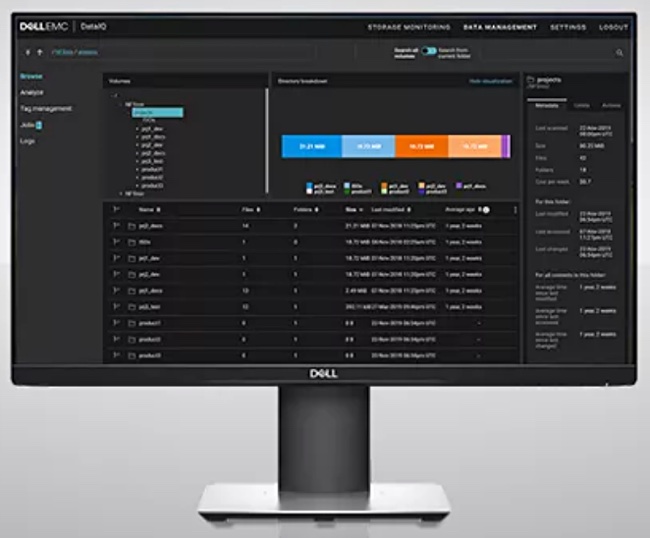
DataIQ
DataIQ software provides a single view of file and object data across Dell EMC (including Unity), third-party and public cloud storage. This heterogeneous file and object environment can be scanned, searched, classified, tags added to items, and data automatically moved according to policies.
DataIQ screen.
That means the data is known about and can be stored in the most cost-effective system for its access level. It also allows for self-service or automated movement of data between file and object stores, and between on-premises and public cloud locations. Data can also be moved between PowerScale and ECS systems.
DataIQ provides reporting on data usage, storage costs, user access patterns and more.
Data items of different types can be grouped into a project with tags and then such projects dealt with as single entities. We could envisage a film project with associated file components which can be managed as a single item and moved from one system to another.
DataIQ gives Dell a foothold in the heterogeneous data management space, enabling it to start competing with other file data managers such as InfiniteIO and Komprise. It is also included with PowerScale giving Dell an effectively instant customer base.
A duplicate finder plugin locates redundant data across volumes and folders, enabling users to delete duplicates, save costs and streamline their storage infrastructure. That brings Dell into the copy data management space as well.
PowerScale systems, like other Dell storage products, can be managed through the CloudIQ monitoring and predictive analytics service.
We understand Dell is considering OEMing OneFS. Having it available on PowerEdge servers would help enable this.
Dell PowerScale OneFS v9.0, PowerScale product nodes and DataIQ are now generally available globally. Existing Isilon and ECS products remain supported.
New EU vehicle emission regulations have created an onerous workload for car manufacturers.
When prospective car-buyers access an online Peugeot Citroen’s (Groupe PSA) site, they need to know if the vehicle configuration they select meets the new WLTP (world harmonised light-duty vehicles test procedure) standard. To deliver the expected user experience, meaning having a snappy web site, the WLTP calculations should be completed in less than 100ms. Also the calculations need to be accurate and reliable enough to avoid fines that could reach up to €100 million annually.
Peugeot Citroen’s mainframe system does not have the power to meet the demand for checking WLTP compliance in real-time.
Insight Edge diagram.
If the WLTP software layer is executed entirely on the mainframe, it is limited to 200 requests/sec. But the Peugeot Citroen requirement is to support 3000 requests/sec.
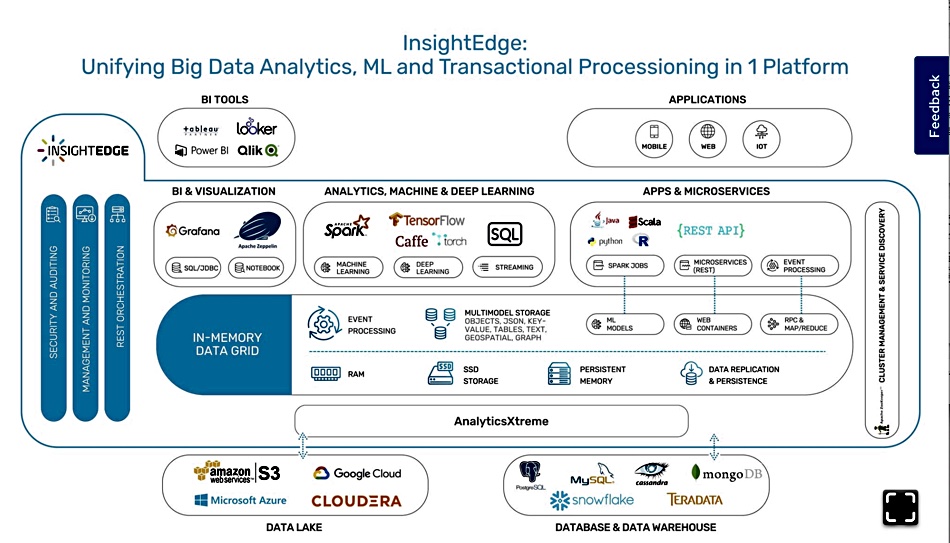
Rather than update the mainframe, which would be expensive, Groupe PSA decided to offload the WLTP processing to a networked 3-server X86 cluster It used an in-memory, real-time analytics SW product called InsightEdge from GigaSpaces, implemented through CAP Gemini. The difficulty of computing WLTP compliance at individual car configuration level is indicated by CAP Gemini deciding in-memory software was needed.
A trio of X86 servers running InsightEdge in-memory software to work out vehicle emissions delivers 15 times more requests per second than the mainframe can do alone.
A caching alternative was rejected because it meant accessing the mainframe to execute complex queries and analytics, which slowed things down.
The caching alternative would not support added intelligence for processing and simplifying the requests on the fly, with aggregation and masking. InsightEdge co-locates data and business logic in the same memory space to lighten storage IO and context switch needs and speed request processing.
Groupe PSA’s deployed WLTP software has an adapter layer on the mainframe, which connects via an orchestration layer to InsightEdge. That SW is deployed on a cluster of three HPE ProLiant DL380-G9 servers running in full high-availability mode, and with 16 partitions.
This InsightEdge system delivers a 15-19ms query and analytics response time, and handles up to 95.2 per cent of calculation requests without accessing the mainframe. So the mainframe is not entirely off-loaded.
The legacy design of dual-controller storage arrays is unsuited for today’s performance and capacity demands. So claims Pavilion Data, the NVMe-over-Fabrics array startup.
All suppliers will need to junk dual-controller systems if they are to cope with growing data volumes, CEO Gurpreet Singh told a press briefing last week.
Unfurling the company’s near-term roadmap, Singh said the company’s Hyperparallel Flash Array (HFA) deliver unmatched performance and capacity and represents a “third wave of computing”.
Pavilion Data says its HFA beats file and block access competitors and provide better throughout per rack unit than object storage competitors.
HFA has up to 20 controllers, with shared memory for metadata, and fast access to NVMe SSDs with parallel access to the SSDs. The system supports block, object and NFS file access. The company said SMB support is contingent on customer demand. Each controller is dynamically defined as a block, file or object access controller, and a second controller acts as a standby backup.
U.2 format SSDs only are supported. However the SSDs are mounted on carriers, so fresh formats could be supported by redesigned carrier cards.
Pavilion’s roadmap includes 30TB SSD support in the second half of this year along with an IO card and Optane SSD support.
V2.4 of the Pavilion OS will add a fast object store, Nagios system monitoring software integration, data compression and Windows drivers for NVMe-oF TCP and RoCE.
Competition
Pavilion likes to compare HFA performance using raw IOPS and GB/sec numbers with latencies, and add cabinet rack unit take-up and capacity to emphasis performance rack space density.
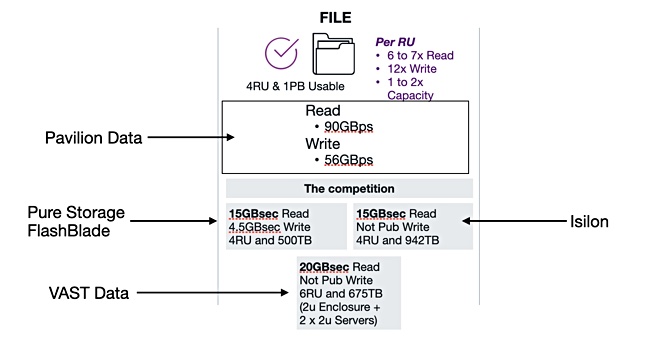
In the briefing, it contrasted a 4U, 1PB usable capacity HFA system for block access with publicly available numbers from a Dell EMC PowerMax (80U and 3PB), NetApp’s AF800 (48U and 4.4PB) and a Pure Storage Flash Array (6 to 9U – it was uncertain which – and 896TB)
The diagram shows Pavilion’s IOPS and GB/sec superiority:
This is a grab from a Pavilion slide with supplier labels added
This Pavilion slide compares file access with Pure Storage’s FlashBlade and Isilon and VAST Data systems.
This is a grab from a Pavilion slide, with supplier labels added
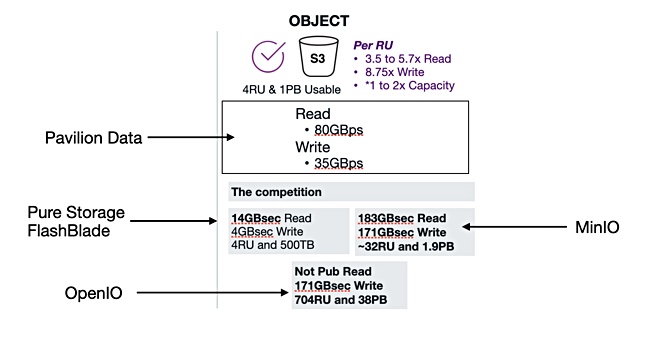
And it has repeated the exercise with Pure Storage, MinIO and OpenIO for object storage.
This is a grab from a Pavilion slide with supplier labels added.
Pavilion is slower in absolute throughput terms than MinIO and OpenIO but uses much less rack space. The company said: “Pavilion outperformed all competitors in the same rack space. When normalized to a per RU basis, we actually outperformed MinIO and OpenIO as well.”
It outperformed Pure in the same rack space. The roadmap includes a fast object store later this year and this may swing the object performance meter in Pavilion’s favour.
Background
Gurpreet Singh said Pavilion Data has broken free from the other NVMe-oF array startups (we think he is referring to Excelero), citing last year’s $25m capital raise which takes total funding to $58m. The company has more than 85 employees and “many” customers, though it won’t say how many. It claims one US Federal customer runs the world’s largest NVMe-oF system but it can’t reveal the name, nor the size of the system.
Public customers include the Texas Advanced Computing Center (TACC), where three Pavilion HFAs replaced five EMC DSSDs, and Statistics Netherlands.