Fujitsu has embarked on an ambitious M&A programme to enable it to supply “transformational services [in a] very competitive” market. The Japanese tech giant has drawn up a list of 20 potential targets, according to the FT.
Nicholas Fraser, an acquisition consultant from McKinsey who joined the company in March 2020 to lead the investment programme, wrote in Fujitsu’s fiscal 2020 report: “To build the capability we need to deliver what our customers need, we must move fast to evolve what we do. Inorganic growth, encompassing both acquisitions and venture investments, is a powerful tool for accelerating this evolution. Inorganic growth is most effective when it is done programmatically. This means doing a number of deals each year and not just one or two every few years.”
He added: “DX (digital transformation) is about both digital (technologies) and transformation (capability). We are filling our investment pipeline with opportunities that help us on both of these fronts: gaining differentiation in digital technologies such as AI, advanced data/analytics, or cybersecurity, and gaining capability to engage customers in transformative discussions.”
Adoption of 5G phone services is also a focus area, with US sanctions on Huawei opening up more opportunities for Fujitsu. The coronavirus pandemic has also accelerated Fujitsu customers’ adoption of remote working and digital services.
The new acquisition programme is part of Fujitsu’s ¥600bn ($5.7bn) digital transformation drive.
Takahito Tokita.
Fujitsu president and CEO Takahito Tokita told a 2019 Fujitsu annual forum audience that the company needed to change to a global services focus because its current hardware-focus made it unbalanced.
In the fiscal 2020 annual report, he stated: “We have not yet turned the corner toward growth, and frankly, we recognise that rebuilding our global business is the most challenging of the four priority issues.”
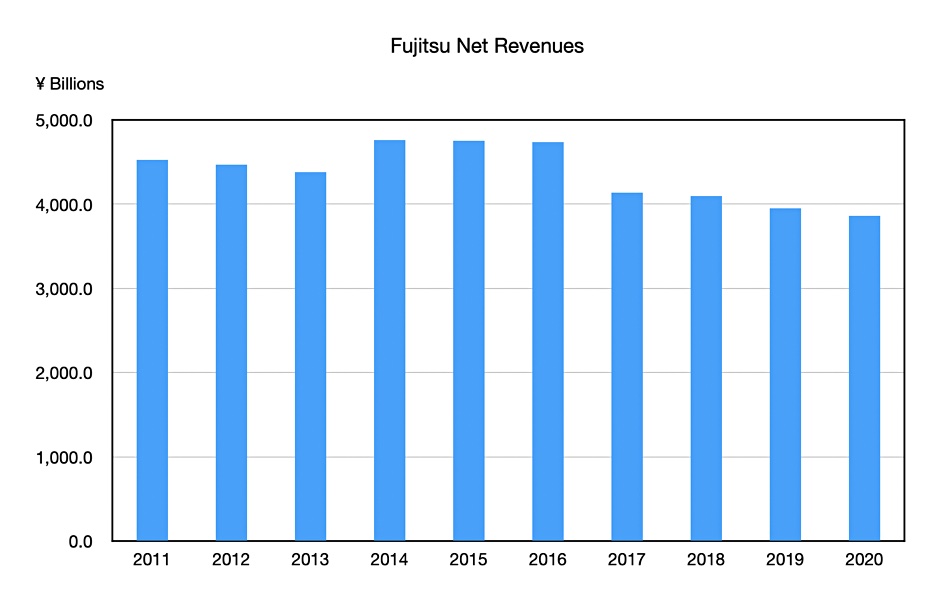
Nine year revenue history shows stagnation and gentle decline.
He said: “We are also working to build an ecosystem that supports DX through M&As and investments in venture companies. For example, in light of the now widespread view that data will be the “new oil” of the global economy, we are collaborating with companies that have advanced software platforms for data analysis. By doing so, we are keen to create new markets that did not exist before and establish a competitive advantage in them.”
Background notes
Fujitsu had sales of about ¥3.8 trillion in fiscal 2020 – about $35.5bn – and employs 130,000 people worldwide. It has a comprehensive server and storage hardware product line featuring, for example, supercomputers, Primergy servers and ETERNUS storage arrays. But it also has legacy hardware products such as mainframes and SPARC servers. It divested its PC business to Lenovo in 2017 and sold off its Arrow smartphone business in 2018.
Recently it has taken up OEM and reselling partnerships in the storage area, and supplies NetApp arrays, Commvault appliances, Datera enterprise storage software, Quantum tape libraries, Qumulo filers, and Veritas data protection products.
We might expect changes are coming to Fujitsu’s server and storage businesses, such as subscription-based business models and cloud-based management.
A New York hedge fund spoiled Intel’s Christmas with calls for the company to get its act together. Dan Loeb, CEO of Third Point, said in a letter published Dec 29 that the semiconductor giant was going through a”rough patch”.
Third Point has amassed a near-billion dollar stake in Intel and you can read Loeb’s letter, addressed to Intel chairman Dr. Omar Ishrak, in full here, but here is the nub of his comments:
Intel has declined, market cap is down, staff morale is low and the board is neglecting its duty.
Intel must correct process lag with Asian competitors TSMC and Samsung.
Nvidia and ARM are using Asian competitors and eating Intel’s lunch
This has US national security implications – US needs access to leading edge semiconductor supply (presumably by retaining semiconductor manufacturing capacity in the US).
Loeb’s recommendations
Should Intel remain an integrated device manufacturer?
Intel needs to figure out how to serve its competitors as customers – e.g. making chips designed by Apple, Microsoft and Amazon that are currently built in East Asia.
Potential divestment of “certain failed acquisitions”.
For the sake of argument, let’s assume that Intel takes on board Third Point’s suggestions. It is unclear at time of writing if Loeb wants Intel to split itself into two separate corporate entities – a fabless chip designer and a US fab business – or if he wants the company to pursue the Amazon-AWS route. We suspect he has the the first option in mind, as an independent foundry could potentially open to its doors to AMD and Nvidia.
That said, it is highly unlikely that the maker arm of Intel could quickly retool its fabs to, say, make ARM chips for the likes of AWS and Apple. Any move into contract manufacturing would require substantial and sustained investment. We have no insight into which “failed” acquisitions Loeb is referring to, but note that Altera ($16.7bn) and MobileEye ($15.3bn) are the big recent acquisitions.
Optane stuff
But what about Intel’s Optane-branded 3D XPoint SSD and Persistent Memory business? The company is estimated to have “lost well over one billion dollars per year in 2017-2019 to bring 3D XPoint to the break-even point,” according to the tech analyst Jim Handy.
Today, it buys in chips from Micron and plans to manufacture gen 3 and gen 4 Optane chips. But why? The company is doubling down on its commitment to Optane -and may even have moved into operating breakeven point.
Intel is using Optane as a defensive moat for its x86 server chip business against AMD. This logic relies on customers agreeing it is worthwhile spending extra money on servers with Xeon CPUs and DRAM to buy Optane persistent memory. And Optane is building up steam in AI, machine learning and financial trading applications. But is this a big enough market?
The hyperscalers, who are the biggest purchasers of server chips, have displayed little interest. AWS, for example, one of Intel’s largest customers for its Xeon CPUs, has developed Graviton server instances that use its own Arm-based CPUs.
If AWS is adding Arm-powered server instances because they are better for microservices-based apps. We think it likely other public cloud and hyperscale cloud services suppliers will follow the same route.
Because of this and because of Loeb’s input, Blocks & Files thinks that it is possible we will see Intel rowing back on Optane persistent memory and SSDs in 2021, and possibly even sell the business to Micron. Intel is now selling its NAND memory business to SK hynix, which would make an Optane spin-off suggestion even more likely.
As Handy says: “The economies of scale have allowed Intel to finally reach the break-even point, and from now on Optane is likely to either continue to break even or to make a profit. This is enormously important if the company ever wants to spin off the Optane business. A spin-off seems very likely since Intel has exited nearly every memory business it has participated in since its founding: SRAM, DRAM, EPROM, EEPROM, NOR flash, Bubble Memories, and PCM. The only two left are NAND flash and 3D XPoint.”
Infinidat co-CEO Kariel Sadler left the company without fanfare last month. His departure may pave the way for the appointment of a sole CEO.
Eran Brown, Infinidat’s EMEA and APAC field CTO also left the firm in December, to work for AWS. Dan Shprung, EVP EMEA and APJ, left Infinidat in October to join Model9 as Chief Revenue Officer.
Sandler’s LinkedIn profile reveals he stopped working at the enterprise large array supplier in December, after nearly ten years with the company. He now describes himself as “Ex co-CEO at Infinidat.”
Kariel Sandler
Infinidat instituted the co-CEO scheme in May last year, following the sideways move of founder and CEO Moshe Yanai to become Chief Technology Evangelist.
Infinidat outsider Boaz Chalamish became executive chairman of the board. COO Kariel Sandler and CFO Nir Simon were appointed as Co-CEOs, nominally replacing Yanai.
The co-CEO function started looking shaky in November when Shahar Bar-Or was hired from Western Digital and appointed Chief Product Officer and General Manager of Infinidat’s Israel operations. He reports directly to executive chairman Boaz Chalamish. In our view, this makes Chalamish effectively the CEO of the company.
Sandler was a long-time associate of Yanai, working with him at IBM, which acquired XIV, and XIV before Infinidat was started up.
All storage media technologies saw increased density in 2020 – tape, disk, flash, persistent memory and even DNA. However QLC flash advances meant the nearline disk bastion is now under attack.
Overall there was no single major step forward that turned the storage world on its head last year. DNA storage developers amazed everybody with what they could do but this cuts no ice with storage professionals buying devices to store data now. They want data accessed in microseconds or milliseconds, not days.
Tape
Tape began the year with LTO-8 (12TB raw) and finished with a reduced capacity LTO-9 format – 18TB raw instead of original 24TB. The 2019 interruption in LTO-8 shipments due to the legal spat between manufacturers FujiFilm and Sony, while demand for tape capacity rose, means that LTO-8 capacity is no longer high-enough, so LTO-9 is being brought forward.
Showing tape capacity has a long runway ahead, Fujifilm and IBM demonstrated a 580TB capacity tape. This is 32 times more than current LTO-9 capacity and required a tape that was 1,255m long.
This provides a vivid insight into tape data access speed as streaming three quarters of a mile of tape through a drive will take several minutes. According to Quantum document, streaming time is increasing as tape’s physical speed through a drive is decreasing;
LTO-6 @ 6.83 m/sec when reading or writing
LTO-7 @ 5.01 m/sec
LTO-8 @ 4.731 m/sec.
We don’t have a LTO-9 tape speed number. Quantum said: “Slower tape speed is an enabler for future generations of LTO drives to offer higher data rates.” At 5m/sec it would take 251 seconds to move the full length of an LTO-9 tape through a drive.
Tape search speed is faster, 10m/sec with full height LTO-8 drives. That means it could take 125.5 seconds to stream the tape through the drive when looking for a piece of data – still slow compared to disk.
LTO-9 tape has 12 Gb/in2 areal density. An 18TB disk drive has 1022 Gb/in2. That means LTO-9 tape can achieve the same 18TB capacity with only 1/85th of the areal density than that of an 18TB disk. No wonder tape’s area density has such a large development head room.
Disk
Disk began 2020 with the standard 3.5-inch nearline drive storing 16TB, and ended it with 18TB and 20TB drives from Western Digital and Seagate. Both companies are developing next-generation technology to progress beyond current Perpendicular Magnetic Recording (PMR). This technology is reaching a dead end beyond which capacity can increase no further, due to the bit areas becoming too small to hold data values in a stable manner.
Western Digital intends to use microwaves to write data to a more stable recording medium called MAMR technology, while Seagate is overcoming its new medium’s resistance to change by using temporary bursts of heat (HAMR). Seagate has started shipping HAMR drives but Western Digital is only shipping partial MAMR tech drive drives using so-called ePMR technology.
We anticipate WD to ship MAMR drives this year, and Toshiba, the third disk drive manufacturer, to follow suit.
Dual or multi-actuator tech appeared in 2020, with Seagate adopting the technology. There are two read/write heads and they divide a disk drive into two logical halves that perform read/write operations concurrently to increase overall IO bandwidth.
But, even so, the time to access data on a disk depends mostly upon the seek time. This is the time needed to move a read/write head to the right track, and then for the track to spin under the head until the right data block is accessed. This can take between 5 and 10 milliseconds (5,000µs and 10,000µs). The data access latency for a QLC (4bits/cell) SSD is in the 100µs or less area – up to 1,000 times faster. That opened the door for QLC SSDs to go after the nearline capacity storage business.
Flash
The big stories with flash and SSDs have been the increasing 3D NAND layer count and the rise of QLC (4bits/cell) NAND.
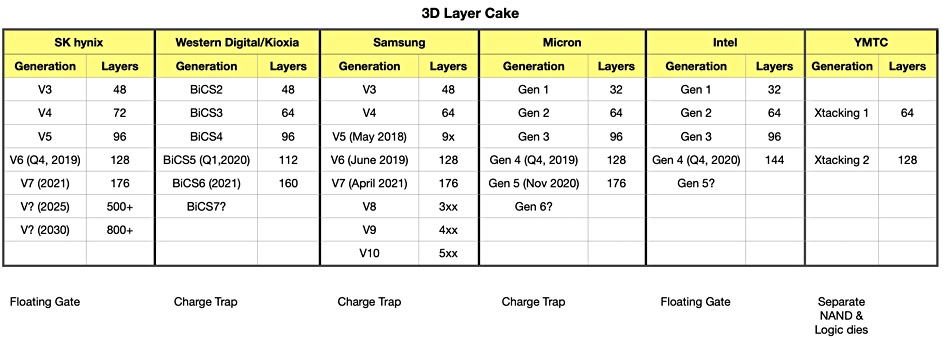
A table illustrates the layer count increase clearly.
Western Digital and Kioxia started 2020 with 96-layer 3D NAND in production and 112 layer in development. The pair now have 160-layers in development. Samsung and SK hynix are moving from 128-layer to 176-layer. Intel moved from 96 layer to 144 layer. (It also sold its NAND business to SK hynix late last year but that sale won’t complete until 2025.)
In general, adding 48 or so layers to a 3D NAND die increases manufacturing cost but assuming similar or better manufacturing yields, there is an overall decrease in cost/TB.
Adding a fourth bit to each cell increases capacity by a third. QLC flash doesn’t last as long as current TLC (3bits/cell) flash so extra over-provisioning cells are needed to compensate for worn-out cells. Even so, 150-layer-plus 3D NAND with QLC cell formatting, provides a flash SSD that is cheaper to make than a sub-100-layer TC flash SSD.
In April, Micron aimed its 5210 ION QLC NAND SSD at the nearline disk drive replacement market.
We now have many flash array suppliers adding QLC flash to their product lines; Pure Storage, NetApp, Nexsan, StorONE and VAST Data.
Tech developments suggest that the SSD threat to disk will intensify. Intel suggests that coming PLC (5bits/cell) NAND will enable the total cost of SSD ownership to drip below that of disk in 2022.
Persistent Memory
There is one main persistent memory game in town, and that’s Intel’s Optane. But let’s give a nod to Samsung’s Z-SSD.
The Z-SSD had a big win in 2020, with IBM adopting it for the FlashSystem arrays, with up to 12 x 1.6TB Z-SSDs supported.
Optane SSDs, which are not persistent memory products, but faster SSDs, were used by StorONE in its S1 Optane Flash Array, and also by VAST Data.
StorONE S1 Optane array.
Intel started shipping second generation 3D XPoint technology in 2020, meaning 4-layers, double that of the gen 1 products. The company announced three products using gen 2 XPoint: PMem 200 Optane Persistent Memory DIMMs, server-focused P5800X Optane SSDs, and an H20 client SSD combining a gen 2 Optane cache with 144-layer QLC 3D NAND.
Intel put in a sustained and concerted effort throughout 2020 to increase its support by applications. The hope is that, as customers take up these applications they will buy Optane persistent memory to send their performance to a higher level.
To date, adoption of Optane persistent memory – Optane DIMMs used as quasi-DRAM to expand a server’s memory pool – has been muted. But the adoption of the PCIe Gen 4 bus, twice the speed of PCIe 3.0, could deliver a bigger bangs-per-buck bump than Optane for less cash.
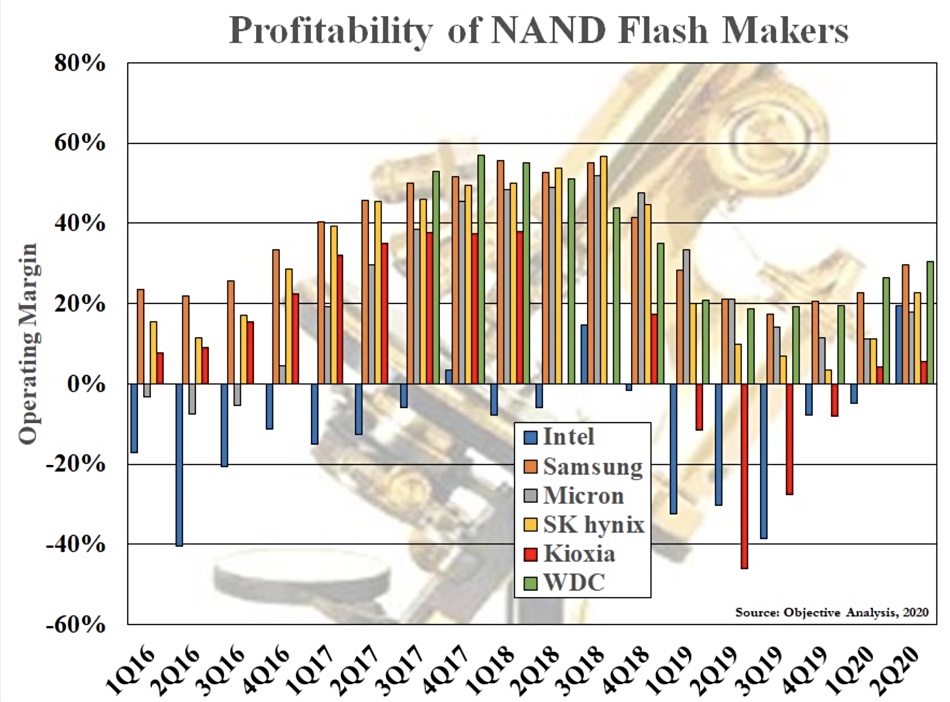
Intel in December outlined two coming Optane technology generations, with no performance details. All-in-all, Intel is making slow progress although it may have turned the corner on Optane profitability, according to tech analyst Jim Handy, in a blog in August. He included a chart in the blog;
This shows the operating margin of NAND manufacturers from 1Q 2016 to 2Q 2020, with Intel’s Non-volatile Solutions Group represented by a blue bar that’s mostly in negative territory. Handy thinks this is due to Optane losses. However, in 2020 the picture changes. NSG made a 19 per cent positive margin in 2020’s second quarter.
Handy comments: ”Intel has lost well over one billion dollars per year in 2017-2019 to bring 3D XPoint to the break-even point.”
He says: “The economies of scale have allowed Intel to finally reach the break-even point, and from now on Optane is likely to either continue to break even or to make a profit. This is enormously important if the company ever wants to spin off the Optane business. A spin-off seems very likely since Intel has exited nearly every memory business it has participated in since its founding: SRAM, DRAM, EPROM, EEPROM, NOR flash, Bubble Memories, and PCM. The only two left are NAND flash and 3D XPoint.”
Intel is now selling its NAND memory business to SK hynix, which would make Handy’s Optane spin-off suggestion even more likely.
DNA
DNA storage came into prominence a couple of times last year, with its fantastic promise of extraordinary capacity in a small space. But that extraordinary capacity; one gram of DNA being able to store almost a zettabyte of digital data, one trillion gigabytes, comes at a cost.
Catalog DNA storage unit.
A lot of mechanical movement, chemical reactions, complicated lab machinery and time is needed. A Microsoft and University of Washington demo system had a write-to-read latency of approximately 21 hours for a 5-byte data payload.
But, again, scientist-led startups like Twist BioSciences and Catalog are pushing the DNA storage envelope forward and we might hear more about it in 2021. Indeed, Catalog now has a $10 million war chest to fund its development.
VMware is suing its former COO and now new Nutanix CEO Rajiv Ramaswami for contractual misdeeds.
The company’s complaint revolves around alleged secret talks between Ramaswami and Nutanix while he was working on “VMware’s key strategic vision and direction” with other VMware senior leaders.
In a statement, VMware said it has initiated legal proceedings in California, against Ramaswami “for material and ongoing breaches of his legal and contractual duties and obligations to VMware.”
Ramaswami joined Nutanix as CEO in December, two days after leaving VMware.
The VMware lawsuit alleges “Rajiv Ramaswami failed to honour his fiduciary and contractual obligations to VMware,” because he was “meeting with at least the CEO, CFO, and apparently the entire Board of Directors of Nutanix, Inc. to become Nutanix’s Chief Executive Officer.”
VMware declared it is not a litigious company by nature and has “tried to resolve this matter without litigation. But Mr. Ramaswami and Nutanix refused to engage with VMware in a satisfactory manner.”
Nutanix in a statement said: “VMware’s lawsuit seeks to make interviewing for a new job wrongful. We view VMware’s misguided action as a response to losing a deeply valued and respected member of its leadership team.”
Rajiv Ramaswami.
The company added: “Mr. Ramaswami and Nutanix have gone above and beyond to be proactive and cooperative with VMware throughout the transition. Nutanix and Mr. Ramaswami assured VMware that Mr. Ramaswami agreed with his obligation not to take or misuse confidential information, and VMware does not contend otherwise.”
This was apparently not enough as “VMware requested that Mr. Ramaswami agree to limit the ordinary performance of his job duties in a manner that would equate to an illegal non-compete covenant, and it requested that Nutanix agree not to hire candidates from VMware in a manner that Nutanix believes would be contrary to the federal antitrust laws.”
Nutanix believes “that VMware’s action is nothing more than an unfounded attempt to hurt a competitor and we intend to vigorously defend this matter in court.”
Comment
The two company statements represent what they want to say in public about their dispute and we don’t know what they said in private. It seems apparent that VMware feels threatened, even betrayed, by Ramaswami’s move to Nutanix and wants to limit the damage it perceives could result from the move.
A US employment contract may have a non-compete clause in it which forbids the employee from leaving and working with a competitor until a certain amount of time has passed after their resignation.
However such non-compete clauses are not enforceable in California law and VMware’s statement does not mention the “non-compete” phrase. Instead it alleges Ramaswami has breached his legal and contractual duties and obligations.
That said, the VMware lawsuit appears similar in nature to a non-compete dispute, particularly as its statement mentions Ramaswami having talks with Nutanix when he was working on “VMware’s key strategic vision and direction”. This implies Ramaswami could direct Nutanix activities from a standpoint of knowledge of VMware’s strategies; the kind of thing non-compete clauses are designed to prevent.
Nutanix’s claim that VMware “seeks to make interviewing for a new job wrongful” sets the scene for a court decision on how far legal and contractual duties and obligations extend into seeking new employment.
Bezels, like car radiator grilles, perform a function. They allow cooling air to enter a rack enclosure whilst protecting the delicate internal components from damage. That allows the bezel designer a lot of latitude in creating a bezel that’s pleasing to the eye while fulfilling its air ingest and protection roles.
These front panels should be icons of distinction, as finely crafted as car radiators, elegant badges bringing light, inspiration and imagination to dull rack walls in data centres. So let’s fight bezel boredom.
In the interests of good bezel design and improving the mental wellbeing of data centre admin staff, we’ll explore some examples of the good, the bad and the ugly in the bezel universe.
Embezeling, here we go
Let’s start at the bottom, with the ugly ones, grilles with logos:
What a utilitarian bunch. Why not add some colour?
Better, but we could do more, so much more:
That’s more like it. Top marks, Caringo! And well done, Backblaze with those red pods.
We could have lit-up logos:
A bit more adventurous with the shapes and colours?
Yes, well, okay DDN, perhaps not.
What about pretend-it’s-not-a-grille bezels;
What about collecting bezels, a nice addition to any wall?
Snapped this before the buildings were sold to Google. Signed by the hardware engineers that worked on the projects. pic.twitter.com/50zv1Jz524
You can see CEO Scott Dietzen’s signature, John Cosgrove’s, Max Kixmoeller’s and others. That is a bezel to treasure. You look at it and you think; “What a flash array!”
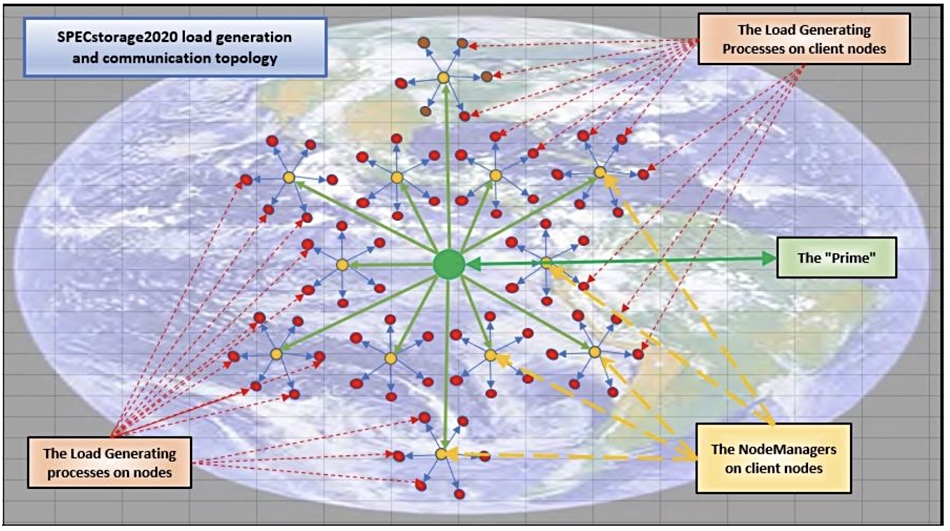
One of the more complicated file storage performance benchmarks is being replaced – by a successor that is even more complicated.
The SPECsfs 2014 SP2 benchmark determines file performance in five different workloads: software builds, video streaming (VDA), electronic design automation (EDA), virtual desktop infrastructure (VDI) and database. Each category test gets a numerical score and overall response time (ORT).
The new SPEC Solutions 2020 benchmark modifies the SFS 2104 SP2 test by adding two new workloads, dropping two existing ones, and tweaking the test methodology. This means that the new benchmark results cannot be compared to the old ones.
There is a new AI_IMAGE (AI image processing) workload, representative of AI Tensorflow image processing environments, and a new Genomics one. The existing SPECsfs 2014 software build, EDA and VDA workloads are retained but the VDI and Database workloads are being scrapped.
That’s because the technology of these has changed and is continuing to evolve. These workloads could be re-introduced later, after the collection of new base trace data has been completed.
SPEC Solutions 2020 benchmark scaling diagram.
The test scale has substantially increased. SPECsfs2014_SP2 scaling was up to 60,000 load-generating processes globally. This is expected to increase to around 4 million load-generating processes distributed globally in SPEC Solution 2020. All of the geographically distributed load generating processes will be kept in sync, at a sub millisecond resolution.
The updated benchmark has a new statistical collection mechanism that enables users to extract runtime counter information and load it into a database for graphical representation by, for example, Graphite, Carbon, and Grafana.
SPEC Solution 2020 graphical output.
SPEC Solution 2020 can support a non-POSIX storage system with a plugin shared library for accessing an AFS storage service. Others may be added in the future, such as an object store, S3, Ceph, and more. The new test supports custom workloads for private, no-publishable testing. It’s also possible to combines Unix and Windows load generators in a workload definition.
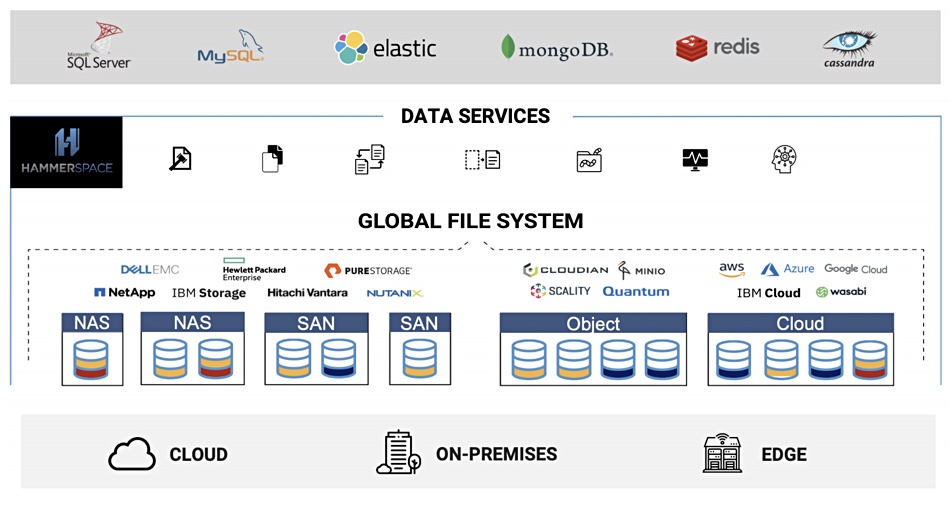
NetApp and Hammerspace have recently begun talking about ‘storageless storage’. No, it’s not an oxymoron, but a concept that takes a leaf from the serverless compute playbook.
For NetApp, storageless, like serverless, is simply a way of abstracting storage infrastructure details to make the lives of app developers simpler. Hammerspace envisages storageless as a more significant concept.
In a soon to be published blog, Hammerspace founder and CEO David Flynn said: “Storage systems are the tail that wags the data centre dog.” He declares: “I firmly believe that the move away from storage-bound data to storageless data will be one of the largest watershed events the tech industry has ever witnessed.”
Ten top tenets of storageless data, according to Hammerspace
It must be software-defined and not be dependent on proprietary hardware.
It must be able to supply all forms of persistence; block, file, and cloud or object; read-only, read/write; single or shared access.
It must be able to use all forms of storage infrastructure; block, file, or object protocol-based; systems or services, and on-premises, in the cloud, or at the edge.
Universal access across Kubernetes clusters, data centres, and clouds.
Have objective-based orchestration.
Possess a full suite of data services.
Have performance and scalability via a parallel architecture, direct data access and RDMA-capable.
Intrinsic reliability and data protection.
Ease of use with Instant assimilation of any networked filesystem, any existing persistent volume with files, zero copy of data, self-service, and auto scale-up/down.
Easy to discontinue using – export data without any need to copy.
Storageless data orchestration
Hammerspace claims it overcomes data gravity or inertia by untethering data from the storage infrastructure to provide dynamic and efficient hybrid cloud storage as a fully automated, consumption-based resource. Users self-service their persistent data orchestration to enable workload portability from the cloud to the edge.
David Flynn
Flynn told Blocks & Files in a phone interview: “Storage is in charge while data is effectively inert. Data doesn’t even exist outside of the storage holding it. You don’t manage data, you manage storage systems and services while data passively inherit the traits (performance, reliability, etc.) of that storage; it doesn’t have its own. Essentially, data is captive to storage in every conceivable way.”
Data owners are compelled to organise data to suit how it is to be broken up and placed onto and across different storage systems (infrastructure-centric), Flynn says, instead of how they want to use it (data-centric). Data is stored in many silos and is hard to move.
It seems impossible to get consistent and continuous access to data regardless of where it resides at any given moment, regardless of when it gets moved, or even while it is being moved, since moving it can take days, weeks, or even months, according to Flynn. He thinks it is an absurdity to manage data via the storage infrastructure that encloses it.
Storageless data means that user do not have to concern themselves with the specific physical infrastructure components, he argues. Instead, an orchestration system maps and manages things automatically onto and across the infrastructure. This allows the infrastructure to be dispersed, to be diverse, to scale and do so without compounding complexity.
Kubernetes
He declares that Kubernetes in the serverless compute world is the orchestration system that places and manages individual containers onto the server infrastructure. In the storageless data world, Hammerspace is the orchestration system that places and manages individual data objects onto the storage infrastructure. Both do it based on the requirements, or objectives, specified by users in metadata.
Flynn notes that we are hitting the end of Moore’s Law and microprocessors are not growing in performance at rates like they used to. So, he argues, there is nowhere to go but to scale applications out across many servers.
Serverless compute, made possible by Kubernetes, is the only way to manage the complexity that scaling out creates, but it suffers from a data problem. Flynn said: “Infrastructure-bound data is the antithesis of the scalability, agility, and control that Kubernetes offers. Storageless data is the answer to the Kubernetes data challenge.”
Hammerspace context diagram for storageless data orchestration for Kubernetes.
NetApp and Spot
NetApp was spotted in October using the term ‘storageless storage’ at the virtual Insight conference in October in reference to Spot, the company’s containerised application deployment service.
NetApp said Spot brings serverless compute and storageless volumes together for high performing applications at the lowest costs. Serverless compute means a cloud-native app is scheduled to run and the server requirements are sorted out by the cloud service provider when the app is deployed. The developer does not have to investigate, define, and deploy specific server instances, such as Amazon’s EC2 c6g, medium EC2 instances or others.
As Spot is both serverless and storageless, the developer does not need to worry about either the specific server instance or the storage details. In both cases, the containerised app needs a server instance and a storage volume provisioned and ready to use. But the app developer can forget about them, concentrating on the app code logic in what, from this viewpoint, is effectively a serverless and storageless world.
Anthony Lye, general manager for Public Cloud at NetApp, blogged in September: “To get a fully managed platform for cloud-native, you need serverless AND storageless.” [Lye’s emphasis.]
Shaun Walsh
In a November blog post, Shaun Walsh, NetApp director for cloud product marketing, claimed: “NetApp has the first serverless and storageless solution for containers. Just as [Kubernetes] automates serverless resources allocation for CPU, GPU and memory, storageless volumes, dynamically manage storage based on how the application is actually consuming them, not on pre-purchased units. This approach enables developers and operators to focus on SLOs without the need to think about storage classes, performance, capacity planning or maintenance of the underlying storage backends.”
Developers can run containers with self-managing, container-aware storage.
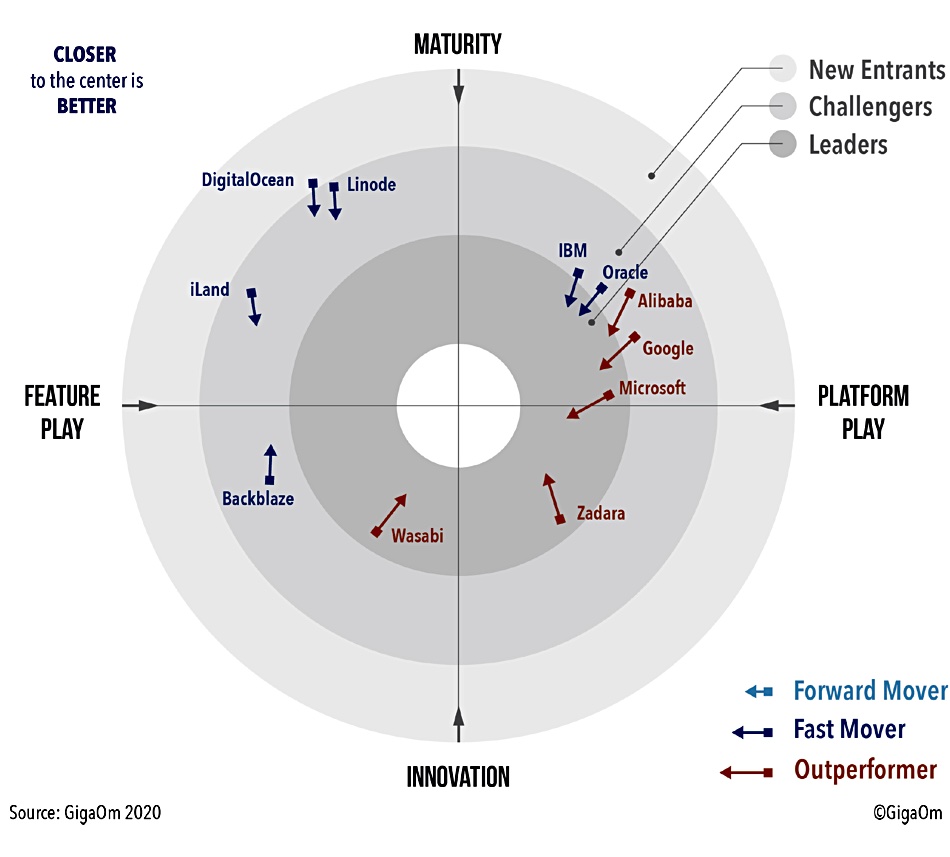
Pricing unpredictability and egress charges are the main problems with Amazon’s S3 object storage, according to GigaOm. But there are plenty of competitive options, the tech analyst firm notes. (And we note that AWS could resolve these pricing issues any time it likes.)
“Hyperscalers (Microsoft Azure, Google Cloud, Alibaba) are direct Amazon AWS competitors and can offer a complete ecosystem,” said GigaOm analyst Enrico Signoretti, while “others focus more narrowly on object storage services and niche markets (Wasabi, BackBlaze, iLand), providing a better user experience and pricing for specific use cases.”
GigaOm S3 Alternatives report.
Vendors such as IBM, Oracle, DigitalOcean and Linode present some appealing add-ons and pricing models that can bring down costs and improve application efficiency. Zadara provides a private cloud that covers multiple clouds and the on-premises world.
Signoretti’s findings are published in the new GigaOm Radar for Alternatives to Amazon AWS S3. In the report, he places ten suppliers in a 4-circle, 4-axis, 4-quadrant Radar screen. The arrows project their anticipated direction in the next 12-18 months.
GigaOm Radar Chart for S3 alternative suppliers.
In the Leaders category the top three are Microsoft Azure, Wasabi and Zadara. IBM, Oracle, Google and Alibaba are challengers that may become leaders. The Challengers’ ring includes Backblaze, Linode, iLand. Digital Ocean, a New Entrant, is poised to become a Challenger.
We have gleaned from the report some bullet points on individual vendors, most of which offer S3-compatibility:
Alibaba is noted as using nearline disk storage to provide good access speed.
Backblaze is a serious player but is available only in US-West and EU-central regions.
Digital Ocean uses Ceph, and bucket size might be a problem.
Google Cloud is a solid option.
IBM Cloud Object Storage has a differentiated SQL Query feature.
Iland is focused on backup, archiving, cloud-tiering, and disaster recovery.
Linode is a three-region supplier for SMBs.
Azure is well-respected but not S3-compatible.
Oracle is a compelling service for Oracle customers.
Wasabi already has more than 18,000 customers.
Zadara offers storage-as-a-service in 56 regions in 18 countries.
Amazon late last year launched AWS Outposts, a fully managed service based on a converged infrastructure rack, including server, storage, networking, and AWS cloud software services. The appliance is integrated with the public AWS cloud for a consistent hybrid cloud AWS experience across the customer’s data centres and its AWS accounts.
We think there is an arguable case that AWS Outposts represents an existential threat to the on-premises part of the hybrid cloud storage and server market.
Let’s remind ourselves just how big AWS’s storage business is. Its $8bn annual revenues – according to William Blair analyst Jason Ader – make the company the world’s second biggest data storage biz, albeit half the size of the runaway market leader, Dell. For comparison this is $2.6bn more than NetApp’s fy20 revenues, almost twice HPE’s fiscal 2021 $4.56bn storage revenues, and more than four times IBM’s fiscal 2020 storage hardware business, and about five times Pure’s fiscal 2020 revenues of $1.643bn.
The rush to support AWS Outposts has been breathtaking, with multiple storage-centric vendors already certified by Amazon as AWS Outposts-ready. They include Clumio, Cohesity, Commvault, CTERA, Iguazio, Infinidat, NetApp, Redis Labs, Pure Storage, Qumulo and WekaIO.
Perhaps they have little choice. AWS’s market presence makes Outposts an enticing proposition (and far more so than Google’s competing Anthos or Microsoft’s partner-led Azure Stack offerings).
We polled a number of data storage vendors for their response and all, with one exception, think we are barking up the wrong tree.
To summarise the counter-argument, Outposts represents another opportunity for storage vendors to work with AWS and deliver better storage facilities to joint customers. Here are the views of three vendors.
Pure Storage
A Pure spokesperson said: “AWS Outposts is a validation of the importance of hybrid cloud in the enterprise. We have supported customers’ hybrid cloud environments with Cloud Block Store and now Portworx, tackling the most difficult piece of running in a hybrid or multi-cloud environment – providing consistent and portable data services.”
AWS Outposts rack
Pure argues that Outposts provides AWS customers a way to connect and deploy applications that run in their data centre or edge locations with parts of their applications that run in-region at AWS, and serving those applications with in-region services.
This simplifies application management and deployment, but for many edge applications that are data-intensive, have low-latency requirements at the edge, or have high-bandwidth requirements for data, there’s a need for much higher performance, enterprise-grade and reliable dedicated storage running at the edge with Outposts.
Pure’s spokesperson told us: “With FlashBlade, we can provide high-performance storage for analytics, AI, IOT and other typical Edge workloads. With FlashArray, we can provide the high-performance SAN needed for many of the traditional business applications that we serve today
“[Pure-owned] Portworx software is also an Outposts Ready solution, and provides customers running on Outposts compute, the enterprise-grade container storage services they need, but just as importantly the application and data-management workflows (backup, DR, migration) and portability they need.”
He said: “We see Outposts as another compute platform that our customers are choosing, one that is well-connected to in-cloud management and specifically targeted at edge workloads, and one where we are able to provide unique value. We have and continue to work closely with AWS as an Advanced Technology Partner to develop solutions for Outposts as well as other AWS service offerings.”
B&F notes Pure’s focus on AWS Outposts’ compute and not its storage facilities.
Panasas
For Panasas, AWS Outposts is competition but weak and poor competition.
AWS positions Outposts as being suitable for high performance computing (HPC). Panasas, which supplies HPC storage, disagrees.
Curtis Anderson, Software Architect at Panasas, told us: “This seems a bit disingenuous on their part. Sure, you can easily remove the wait times, just pay them more.” The same is true for an on-premises HPC system suffering long wait times; buy more kit.
“AWS Outposts are, by definition, built upon AWS’s infrastructure model. If HPC doesn’t work well in an AWS data centre, then HPC will not work well in an “Outpost” (very much smaller with fewer resources to call upon) of that data centre architecture that happens to be on-prem.”
He said: “The core part of the AWS architecture that gives them the “11 nine’s availability” they advertise is replicating your data to multiple “availability zones” and providing compute locally in those zones that can continue operations on that data if there’s a disruption in the primary AWS availability zone you use. Only snapshots of Outpost storage will be replicated to the local AWS Region, so the frequency of snapshots determines how much work you’ve lost and have to recreate in the event of a major outage. So, in essence, [there’s] no “11 nine’s availability” for an Outpost.
Anderson thinks Outposts HPC is akin to a reduced managed services contract: “where the vendor brings all the gear with the contract, but they’re not bringing a cloud with them. The customer gets HPC outcomes as pure OpEx, like regular AWS deployments, rather than a traditional managed services contract where there is CapEx to buy and OpEx to pay for ongoing management.“
Blocks & Files hasn’t found any other storage vendor who would say that AWS Outposts is an AWS attack on the on-premises data centre business, whereby AWS could hope to make inroads into their on-premises server, storage and networking business.
Infinidat
Infinidat didn’t really want to talk to us about AWS Outposts as a competitor. But the company has pointed us towards a statement by Robert Cancilla, EVP, Business Development & Global Alliances: “AWS has created the ability for enterprises to integrate with Infinidat’s storage more easily, for high performance and scalability at a lower cost. While AWS is bringing cloud operational models on-premises, Infinidat is complementing AWS Outposts with elastic pricing models that cloud users demand.”
AWS Outposts is available as a 42U rack that scales from one to 96 racks to create pools of compute and storage capacity.
AWS plan to launch Outpost appliance for small edge locations next year; 1U and 2U rack-mountable servers that provide local compute, storage and networking services. For example, the 2U form factor is suitable for standard 19-inch wide, 36-inch deep cabinets, and uses an Intel processor to provide up to 128 vCPUs, 512 GiB memory, and 8TB of local NVMe (all-flash) storage, with optional accelerators like AWS Inferentia or GPUs.
We’ve asked AWS if any software that runs as an instance in the AWS cloud could run in Outposts. It has yet to provide an answer. We think it will be yes.
AWS introduced several storage services last month at re:Invent 2020.
In August the company announced Elastic Block Store (EBS) io2, a Block Express service that provides SAN facilities. October saw AWS announce that the EBS CSI driver now supports creating volumes on worker nodes running in AWS Outposts subnets. The EBS CSI driver makes it possible to provision, attach, and mount EBS volumes into Kubernetes pods. This release also includes support for io2 volume types.
In other words an Outposts system can host a SAN for use by the Outposts compute instances. There are coming all-flash edge location Outposts configurations.
A VMware variant of AWS Outposts will soon be available, delivering a fully managed VMware Software-Defined Data Centre (SDDC) on premises.
Dell has unveiled Project Karavi, an initiative to add enterprise storage features to the Kubernetes CSI interface.
K8s CSI is being used by enterprises for mission-critical workloads such as databases, notes Itzik Reich, Dell EMC veep, in a blog post. These users want more from CSI than storage provisioning and basic data protection. They want enterprise-class features such as encryption, replication (disaster recovery), etc. “to be offered for Kubernetes, even if the Container Storage Interface does remain ignorant of such capabilities.”
The objective of Karavi, says Reich is “is to expose enterprise storage features to Kubernetes users.” It “aims at improving the observability, usability and data mobility for stateful applications with Dell Technologies Storage portfolio.”
Observability
The initial part is all about observability. Karavi Observability collects capacity and performance metrics and basic storage topology info by pulling the data from the storage array and the CSI drivers and sending it to the open source tools Grafana and Prometheus.
There are two parts to Karavi Observability. Karavi Topology provides Kubernetes administrators with the topology data related to containerised storage provisioned by a CSI driver for Dell EMC storage products.
Karavi Metrics for PowerFlex captures telemetry data about Kubernetes storage usage and performance obtained through the CSI driver for Dell EMC PowerFlex.
This is all very well but surely CSI needs a set of functions that can be abstracted across multi-vendors’ kit rather than just a Dell EMC-specific set of extensions?
Bootnote. Karavi is an uninhabited islet off the north east coast of Crete, near to the Kyriamadi peninsula.
Brexit, China, the cloud and 3D NAND are the main themes in this week’s digest. We also have a multitude of smaller items, including a large customer going all-in on AWS and recovering media file storage manager Quantum making a prominent hire.
Brexit and Data Storage
Brexit is looming, deal or no deal. We ran a quick vox pop to gauge the sentiment of the data storage industry. Our respondents were pretty phlegmatic
Henk Jan Spanjaard, VP EMEA at Quantum: “The storage industry as a whole is unlikely to be profoundly affected by Brexit, especially with its software-as-a-service demand and supply chain. It’s on the hardware side where things might get a little tricky. We expect some delays as shipping lanes will become busier than usual, partly due to Brexit and also the available freight capacity being used to transport future Covid-19 vaccines and other medical supplies.
“We’ve actually anticipated this as a company and made sure that all shipments in UK that are due by the end of this year will go out early. … To sum up, it’s unlikely that Brexit will affect the supply of storage hardware to the UK from the EU and outside as we, including Quantum as a company and the industry as a whole, have been preparing for this for a long time.”
STX Next is a software development house specialising in Python. The company is based in Poland, but a large proportion of its clients are UK-based.
Szymon Piasecki, STX Head of DevOps, said: “Based on our experience with clients, we can mainly speak about the approach to cloud storage services. Theoretically Brexit shouldn’t have much of an effect; GDPR still applies and providers like AWS are adamant that services will be stable in 2021 and that they are compliant with both UK and EU regulations. Despite this, some of our UK clients have specifically requested for us to move their data to the London region. They aren’t sure what’s going to happen and they’d rather be cautious.
“However, most of our clients are ready for Brexit. They know what to expect in terms of data storage and which data should stay in the UK vs which can be processed in the EU. That’s because discussions about the right way to store data in light of Brexit have been ongoing since as far back as 2018.”
Florian Malecki, Senior International Director of Marketing for StorageCraft, told us: “Brexit has been looming for several years now. Many of the issues will come down to compliance. The entire IT industry has been preparing for this. While post-Brexit, businesses selling products and services into the UK will need to comply with both the GDPR and the UK version of the GDPR, there is substantial, if not virtually universal-overlap.
“Moreover, what I am hearing in discussions with our UK partners indicates that, based on what is known, they expect minimal, if any, impact on IT storage hardware and software products and as-a-service supply between the UK and Europe.”
Tsinghua Unigroup bond defaults
China’s Tsinghua Unigroup, with subsidiaries involved in DRAM and NAND manufacturing, has defaulted on several bond repayments. Nikkei Asia reports that Tsinghua Unigroup will default on $2.6bn of offshore bonds as well as failing to repay a $450m Eurobond on 10 December. It has also not made a 260 million yuan ($39.72m) interest payment due on an on-shore bond issued in Shanghai, saying it is suffering from strained liquidity.
This Eurobond default will cause cross-defaults of three other offshore bond issued by Tsinghua, valued overall at $2bn. The South China Post reports Tsinghua previously defaulted on a $199m debt in November.
Tsinghua is looking into ways to solve its current liquidity issue by trying to raise funds through multiple channels.
Zhao Weiguo
These four non-payment events throw a shadow across Tsinghua’s future.
Tsinghua Unigroup is a conglomerate 51 per cent owned by Tsinghua University and 49 per cent by chairman Zhao Weiguo. Tsinghua in turn is the majority owner of Yangtze Memory Technology (YMTC) which builds NAND chips. YMTC is a designated Chinese national champion in the Made in China 2025 project. Tsinghua’s cash problems may inhibit YMTC’s activities.
Shorts
Star Alliance, the world’s largest airline alliance, to migrate all of its data, platforms, and business-critical applications to AWS and close its data centres, which will reduce its infrastructure total cost of ownership by 25%. It is working with Tata Consultancy Services (TCS) – an AWS Partner Network Premier Consulting Partner on the migration.
DDN said its AI-focused EXAScaler storage system has been adopted as the dedicated storage of the “AI Bridging Green Cloud Infrastructure” supercomputer system, being developed by Japan’s National Institute of Advanced Industrial Science and Technology (AIST) and Fujitsu. AIST’s Green Cloud Infrastructure expands the existing Fujitsu-provided AI Bridging Cloud Infrastructure (ABCI), which has been in operation since August 1, 2018.
ChaosSearch has closed a $40m B-round of VC funding, taking total funding to $50m. Founded in 2017, ChaosSearch indexes all data as-is, without transformation, so customers can run queries and analyses against a single unified data lake, with unlimited capacity and data retention time.
Brian ‘Beepy’ Pawlowski.
Quantum has appointed Brian ‘Beepy’ Pawlowski as Chief Development Officer. He comes from a near three-year stint at composable systems house DriveScale where he was CTO. Prior to that he spent 3 years at Pure Storage, initially as a VP and Chief Architect, and then an advisor. Before that he ran the Aborted FlashRay development at NetApp. That project was canned in favour of the SolidFire acquisition. Beepy actually joined NetApp as employee number 18 in a CTO role. He was at Sun before NetApp.
Datadobi and Wasabi have teamed up with a service that integrats DobiMigrate and DobiProtect with Wasabi hot cloud storage. Channel partners and end clients get an enterprise-class solution for migrating unstructured data from anywhere to Wasabi, with protection against accidents, ransomware, and other cyberthreats, at a cost that is as much as 80 per cent less than competitors, the companies say.
NVMe-oF storage supplier Excelero‘s NVMesh now supports Intel’s new P5800X Optane SSD. The software delivers at least a 2.5x performance boost for storage bandwidth and throughput with stable low latencies.es with 60TB total capacity.
Filebase, which supplies decentralised object storage based on a blockchain network, has announced GA of its Filebase 2.0 release, providing on-demand object storage scaling across multiple decentralised storage networks. It integrates with Storj’s Tardigrade storage network. Filebase looks to support additional storage networks and has plans for private on-premise cloud systems using decentralised technology.
Ascend.io has updated the Ascend Unified Data Engineering Platform with the addition of flex-code data connectors, a first-of-its-kind connector framework for data ingestion in the Apache Spark ecosystem. It has added support for 40+ new connector types. These flex-code data connectors connect not just from, but to, any data system in the world.
iXsystems has introduced the TrueCommand Cloud cloud-based service to simplify TrueNAS management and lower operational costs and improve productivity through increased asset utilisation, system optimisation, real-time system monitoring, and on-demand provisioning. TrueCommand manages TrueNAS CORE, Enterprise, and SCALE instances and can be used by MSPs, Enterprises, smaller organisations, and other TrueNAS users.
LucidLink, a supplier of cloud file services, has announced single sign-on (SSO) with Okta, an identity and access management (IAM) provider. Administrators and root users can create the LucidLink application within Okta and assign and manage users and groups to the LucidLink application. Azure AD support will be added, providing coverage for the bulk of LucidLink’s customer base.
Pure Storage has announced the availability of Pure as-a-Service in AWS Marketplace and a new Cloud Block Store Efficiency Guarantee. This is backed by Pure’s promise to reduce cloud storage consumption with no feature trade-offs. Pure’s FlashArray and Portworx by Pure Storage have both achieved AWS Outposts Ready designation.
SMB backup supplier StorageCraft has announced ShadowProtect SPX v7 which can recover files, folders, and entire systems in seconds, and boot backup images as VMs using patented VirtualBoot technology. VirtualBoot allows partners to instantly recover larger data set sizes up to 4TB.
WekaIO announced that Weka File System (WekaFS), with its Kubernetes Container Storage Interface (CSI) plug-in, has completed interoperability testing with Rancher Labs’ Kubernetes management platform. WekaIO and Rancher Labs will offer enterprises an integrated, end-to-end tested system. Rancher Labs (now a SUSE company) and Weka have joined each other’s Technology Alliance Partner Programs.
XenData has joined the Active Archive Alliance. XenData provides storage systems optimised for video, medical imaging, video surveillance and other applications. Its digital archive systems scale to 100+ petabytes and provide cost-effective, secure, long-term retention of file-based assets on RAID, LTO, optical cartridges and the cloud.