


Ed Walsh left his job as head of IBM Storage last week to take on the CEO role at ChaosSearch, a log data analytics startup. Co-founder Les Yetton has stepped aside to make way for Walsh.
ChaosSearch CTO Thomas Hazel told us in a briefing this week that Walsh “has the experience and vision to enable us to very rapidly scale to meet customer demand we are seeing”.
Hazel and Yetton set up the company in 2016 to devise a faster, more-efficient way of searching the incoming flood of log and similar unstructured data heading for data lakes. They saw that analysis was becoming IO-bound because the Moore’s Law progression of compute power scaling was slowing. Their answer was to build software toc ompress and accelerate the analytics IO pipeline.

Walsh said in a press statement today: “The decision to leave IBM was extremely difficult for me, but the decision to join ChaosSearch was very easy. Once I saw the unique and innovative approach they take to enable ‘insights at scale’ within the client’s own Cloud Data Lake and slash costs, I knew I wanted to be part of this company.”
He added: “Unlike the myriad log analytic services or roll-your-own solutions based upon the Elastic/ELK stack, ChaosSearch has a ground-breaking, patent-pending data lake engine for scalable log analytics that provides breakthroughs in scale, cost and management overhead, which directly address the limits of traditional ELK stack deployments but fully supports the Elastic API.”
The ELK stack refers to ElasticSearch, Logstash and Kibana; three open-source products maintained by Elastic and used in data analysis.
Background
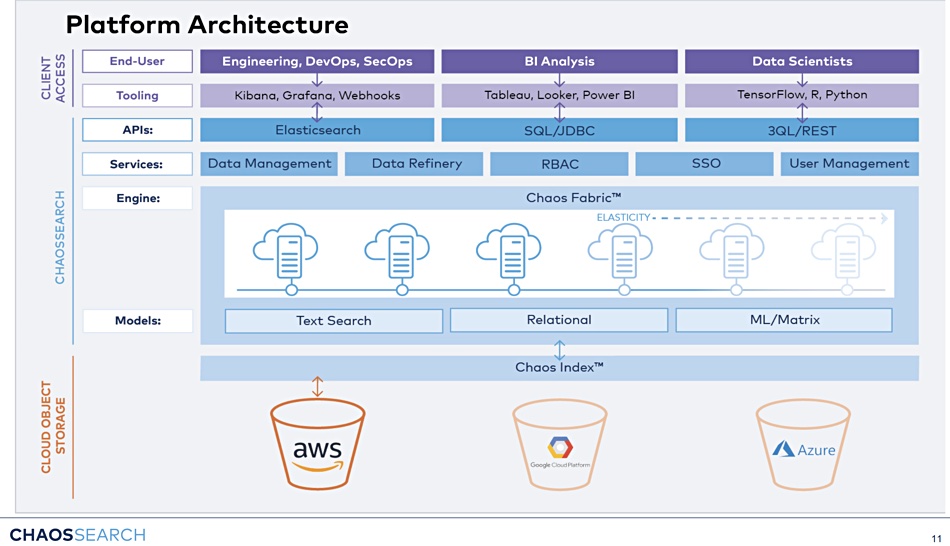
ChaosSearch saw that data in data lakes needed compressing for space reasons, and also extracting, transforming and loading (ETL) into searchable subsets for Elastic Search and data warehouses such as Snowflake. This involved indexing the data to make it searchable. What the founders invented was a way of compressing such data and indexing it in a single step.
Hazel told us Gzip compression takes a 1GB CSV file and reduces it to 500MB. Paquet would turn it into an 800MB file while Lucene would enlarge it three to five times by adding various indices. ChaosSearch reduces the 1GB CSV file to 300MB, even when indexing is performed.
Bump the 1GB CSV file to multiple TB or PB levels and the storage capacity savings become quite significant. Overall analytics time is also greatly reduced because the two separate compression and ETL phases are condensed into one.
The compression means that more data can be stored in the analysis system and this improving analytics results.

ChaosSearch thinks a cloud data lake can be stored in cloud object storage (S3) and function as a single silo for business intelligence and log analytics. The company is initially focusing on the log analytics market and says its technology can run search and analytics directly on cloud object storage. Walsh claimed ChaosSearch technology is up to 80 per cent less expensive than alternatives, in our briefing with the company.
The ChaosSearch scale-out software will be available on Amazon’s cloud initially and be extended to support Azure and GCP. Upstream analysis tools such as Elasticsearch access its data through standard APIs.
Check out a white paper for a detailed look inside ChaosSearch’s technology.





