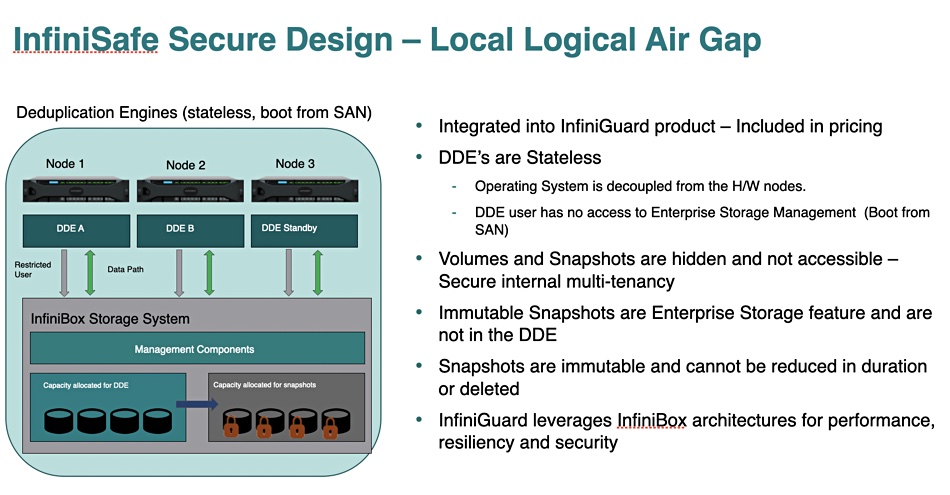
Infinidat has added automated fenced-in networks to its InfiniGuard data protection array to safeguard forensic analysis of malware attacks, and doubled throughput with new B4300 hardware. The resulting software is branded InfiniSafe, and is claimed to enable a new level of enterprise cyber-resiliency.
The InfiniGuard system is a mid-range F4200 or F4300 InfiniBox array front-ended by three stateless deduplication engines (DDEs) and running InfiniGuard software providing virtual tape library functionality (disk-to-disk backup) as a purpose-built backup appliance (PBBA). It supports Commvault, IBM Spectrum Protect, Networker, Oracle, Veeam, Veritas and other software products backing up heterogeneous storage vendor’s kit.
Stan Wysocki, president at Infinidat channel partner Mark III Systems, provided an announcement quote: “What I’m most excited about is providing our customers a comprehensive storage-based ransomware solution that combines air-gapped immutable snapshots with an automated fenced-in network to determine safe recovery points, and then delivering near-instantaneous recovery.”
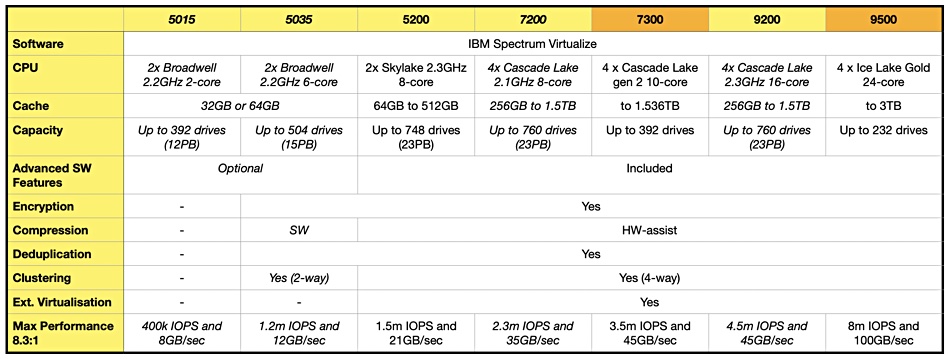
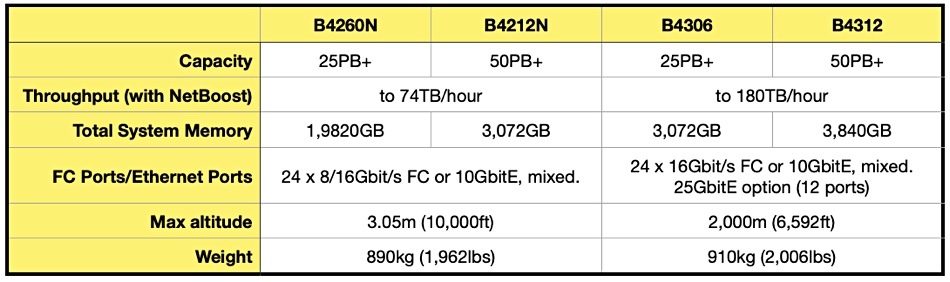
InfiniGuard arrays are preinstalled in a 42U rack with four drive enclosures preconfigured. There are InfiniGuard B4212N and B4260N systems, shipping from April 2021, based on the Infinidat mid-range F4200 array. The B4300s are based on the F4300 InfiniBox – a go-faster F4200 upgrade. Some differences between two now discontinued B4200 products and two B4300 products are listed in the table below:

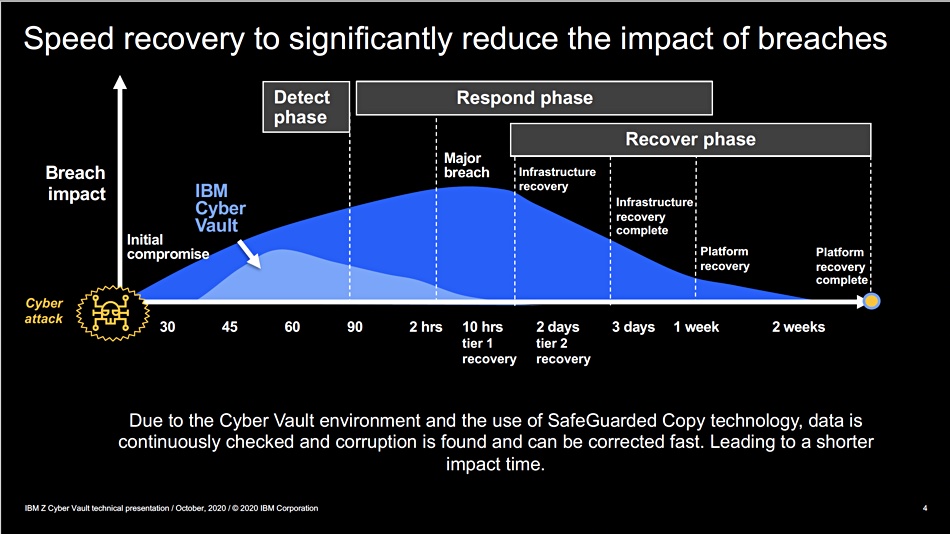
The InfiniGuard software currently offers immutable snapshots, a virtual air-gap and virtually instantaneous recovery, based on all disk drive spindles being used in the restore operation. It can also replicate an InfiniGuard system’s contents to a remote InfiniGuard system.
Performance boost
The new B4300 hardware increases the DDE CPU power by moving from six-core to 20-core CPUs and doubling DDE memory. The network link between the DDEs and the backend storage is 16Gbit/s FC, and a new 25GbitE Ethernet frontend option has been added.
InfiniGuard software has been updated to use all the cores and the result is a throughput jump from 74TB/hour to 180TB/hour. This can reduce backup windows by 50 per cent or so, as well as shortening remote replication time. This means you get to a fault-tolerant (replication complete) state faster.
Recovery time is also reduced. Infinidat can now demonstrate the recovery of a 1.2PB backup data set in 13 minutes and 30 seconds, at which point it’s available to the backup software to do a restore. Eric Herzog, Infinidat’s CMO, tells us “No one else in the PBBA space can do a full recovery in less than 30 minutes.”
Competitor HPE’s fastest StoreOnce deduping PBBA, the 5660, has a 104TB/hour throughput rating. Dell EMC’s high-end PowerProtect DP8900 runs at up to 94TB/hour. InfiniGuard B4300 is almost double that speed. However, In January 2019, ExaGrid CEO Bill Andrews claimed his firm’s EX6300E PBBA scaled out two a 400TB/hour ingest rate. Its EX84 currently scales out to 32 systems and a 488TB/hour ingest rate in the EX2688G configuration. That beats InfiniGuard’s B4300s in sheer speed but is not comparing apples to oranges in terms of system configurations. InfiniGuard looks to be one of the fastest single node, disk-based, PBBAs out there, if not the fastest.
Pure’s FlashBlade offers up to a claimed 270TB/hour recovery performance from its all-flash datastore. A single node all-flash VAST Data/Commvault system offers up to 144TB/hour restore speed. Four nodes offer up to 576TB/hour and eight nodes 1.15PB/hour; this is what scale-out design is supposed to do.
Network fencing
The latest InfiniGuard release adds support for fenced and isolated networks. Network fencing isolates a device, such an InfiniGuard array from its connecting network. That means backups can be test restored inside a closed and isolated environment to find the latest known good backup and not affect primary systems at all. This means InfiniGuard customers can disregard any compromised backups and only recover good data.
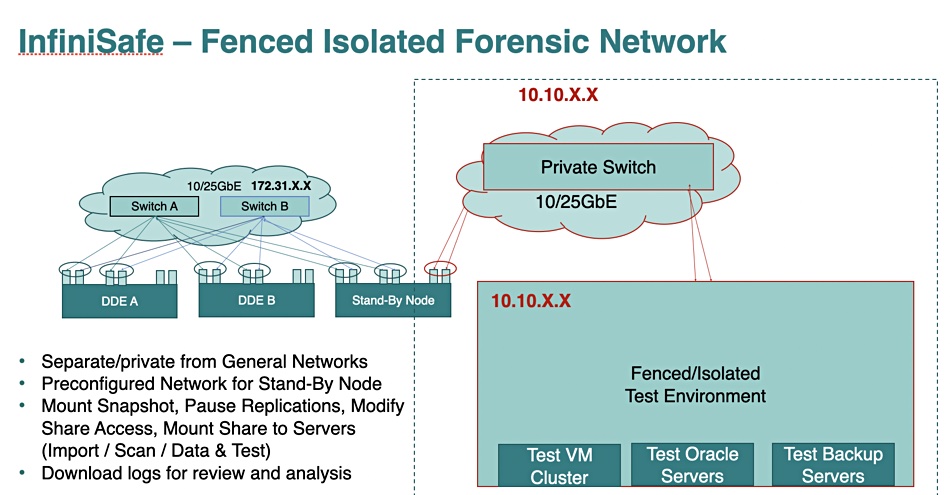
Herzog suggests that several competing PBBA vendors have cyber-resilient systems roughly similar to InfiniGuard but they can require two separate systems. With its network fencing InfiniGuard can provide the cyber resilience in a single system.