AI-focused analytics lakehouse supplier Databricks wants to raise more funding to continue its breakneck expansion and aims to overtake Snowflake as the largest data analytics company in the world.
Databricks supplies a data lakehouse, a combination of a data warehouse and data lake, and was founded in 2013 by the original creators of the Apache Spark in-memory big data processing platform. It has raised $3.5 billion in funding through nine funding events and is heavily focussed on AI/ML analytics workloads. Databricks had a $38 billion valuation in 2021. In August 2022 Databricks said it had achieved $1 billion in annual recurring revenues, up from $350 million ARR two years prior, but it did not say it had a positive cash flow.
Both Silicon Angle and The Information report Databricks wants to raise hundreds of millions of dollars. The two mention sources close to the company that say Databricks made an operating loss of $380 million in its fiscal 2023, which ended in January, and has lost around $900 million in its fy2023 and fy2022 combined.
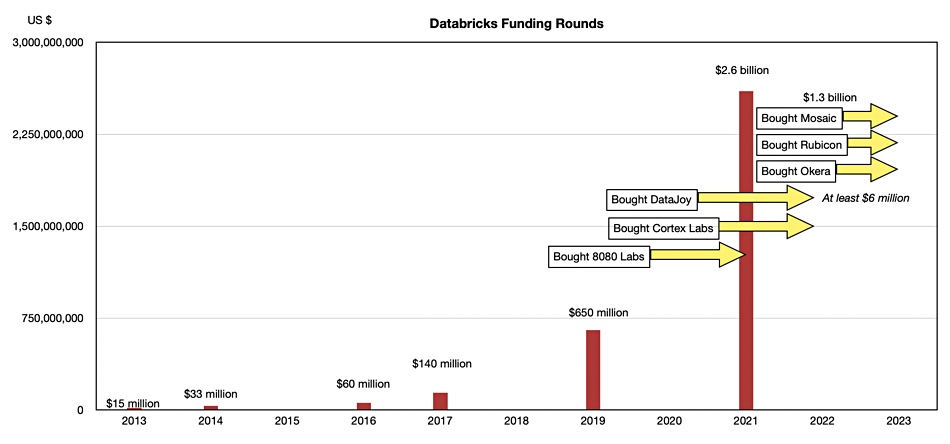
Databricks pulled in a massive $2.6 billion in funding in 2021 and embarked on an acquisition spree to buy in AI/ML-related software technology:
October 2021 – 8080 Labs – a no-code data analysis tool built for citizen data scientists,
April 2022 – Cortex Labs – an open-source platform for deploying and managing ML models in production,
Oct 2022 – DataJoy – which raised a $6 million seed round for its ML-based revenue intelligence software,
May 2023 – Okera – definitive agreement to buy AI-centric data governance platform,
June 2023 – Rubicon – storage infrastructure for AI,
June 2023 – Mosaic – definitive agreement for $1.3 billion in a what Databricks tells us is a mostly stock deal. Buy completed 19 July 2023.
Charting these with its funding rounds gives an indication of Databricks’ fund raising and acquisition spending:
Blocks & Files chart.
The cost of the Mosaic acquisition was $1.3 billion while the other five acquisitions were for undisclosed amounts. In essence Databricks pulled in a lot of cash in 2021 and then spent a lot of cash in 2021 (buying 8080 Labs), 2022 (buying Cortex Labs and DataJo) and so far this year (buying Okera, Rubicon and Mosaic). That was in addition to its normal cash burn growing the company with marketing spend on trade shows, etc.
Databricks sees the generative AI market as a huge opportunity to grow its business substantially. For that it needs more cash. We’ve asked the company for a comment and were told: ”Databricks won’t comment on this occasion.”
South Korean memory fabber SK hynix is sampling an HBM3E chip, a month after Micron’s gen 2 HBM3 chip was unveiled.
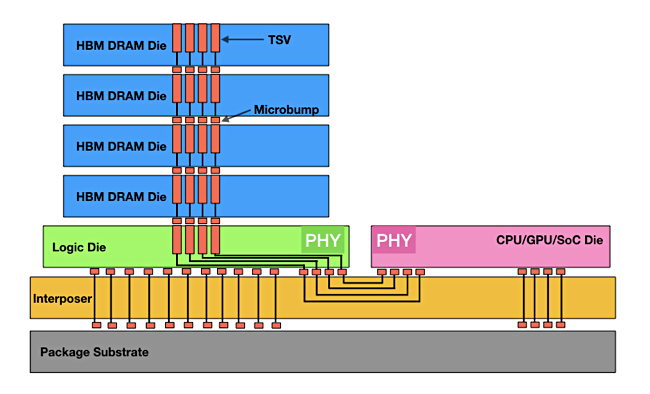
HBM3E is High Bandwidth Memory gen 3 Extended and follows the HBM3 standard which was introduced in January 2022. Such memory is built from stacks of DIMM chips placed above a logic die, which is attached to an interposer that connects them to a GPU or CPU. Alternatively the memory chips can be directly stacked on the GPU. Either way the DRAM-to-GPU/CPU bandwidth is higher than the traditional X86 architecture of DRAM connected by sockets to the processor. Industry body JEDEC specifies HBM standards and its HBM3 standard was issued in January. Now vendors, incentivized by the AI and ML boom, are rushing to make it out of date.
SK hynix is facing depressed revenues because of memory and NAND over-supply in a low-demand market, though the memory market is starting to show some signs of recovery. Sungsoo Ryu, Head of DRAM Product Planning at SK hynix, said: “By increasing the supply share of the high-value HBM products, SK hynix will also seek a fast business turnaround.”
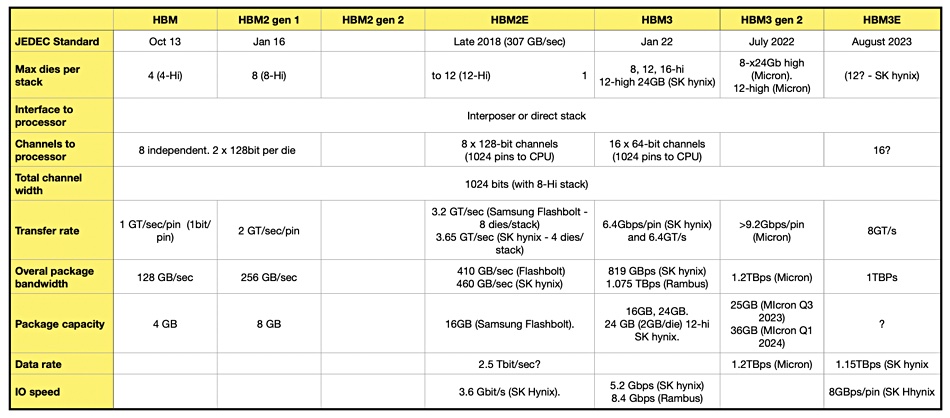
HBM generations table.
The company characterizes itself as one of the the world’s only “mass producers” of HBM3 product and plans to volume produce HBM3E from the first half of next year. SK hynix talked up its production of memory for the AI market, currently being significantly enlarged by demand for ChatGPT-type Large Language Models (LLMs). SK believes that LLM processing is memory limited and aims to rectify that.
Details of the SK hynix product are few, with the company only saying it can process data up to 1.15 terabytes(TB) a second, which is equivalent to processing more than 230 full-HD movies of 5GB-size each in a second. Micron announced a more than 1.2TBps HBM3 gen 2 product last month, suggesting that SK hynix has work to do.
Micron’s HBM3 gen 2 product has 24GB capacity using an 8-high stack, with a 36GB capacity 12-high stack version coming. SK hynix announced a 12-stack HBM3 product in April, with 24GB of capacity.
We suspect that SK hynix’s HBM3E product may be developed from this 24GB capacity, 12-stack offering and could achieve 36GB.
SK hynix says the HMB3E product is backwards-compatible with HBM3; just drop it in to an existing design and make the system go faster.
Research house Futurum has backed a recent research paper that suggests HDDs could be greener than SSDs. The paper states that the biggest carbon emissions happen at the time of manufacture, with production of SSDs creating more carbon than disk drives.
In a research note “Are SSDs really more sustainable than HDDs?” Futurum analyst Mitch Lewis claims “the manufacturing process for the flash devices used in SSDs is highly energy-intensive [which is] about 8x higher embodied cost compared to Hard Disk Drives (HDDs) with an identical capacity.”
He is referencing a recent study presented at HotCarbon 2022 titled “The Dirty Secret of SSDs: Embodied Carbon,” co authored by University of Wisconsin–Madison comp sci prof Swamit Tannu, and Prashant J Nair, an assistant comp sci professor at the University of British Columbia.
The study claims: “Manufacturing a gigabyte of flash emits 0.16 Kg CO2 and is a significant fraction of the total carbon emission in the system… the flash and DRAM fabrication centers have limited renewable electricity supply, forcing fabs to use electricity generated from carbon-intensive sources.” This 0.16kg CO2 is the embodied carbon cost of SSDs.
Despite being physically bulkier, “compared to SSDs, the embodied carbon cost of HDDs is at least an order of magnitude lower.” This is because HDD manufacturing is much less semiconductor-intensive than SSD fabrication and semiconductor manufacturing needs more electricity than HDD manufacturing. Also, “most semiconductor fabrication plants rely on the electricity generated by coal and natural gas plants” rather than renewable sources.
Deciding how green an SSD or HDD is isn’t simply a matter of assessing its operational electricity usage and “one must account for the embodied [carbon] cost when deciding on the storage architecture.”
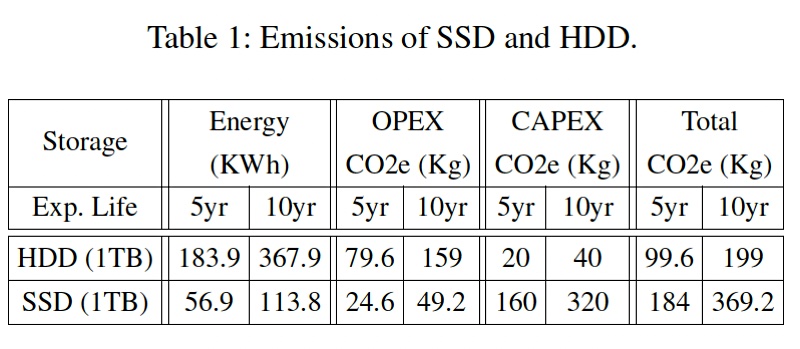
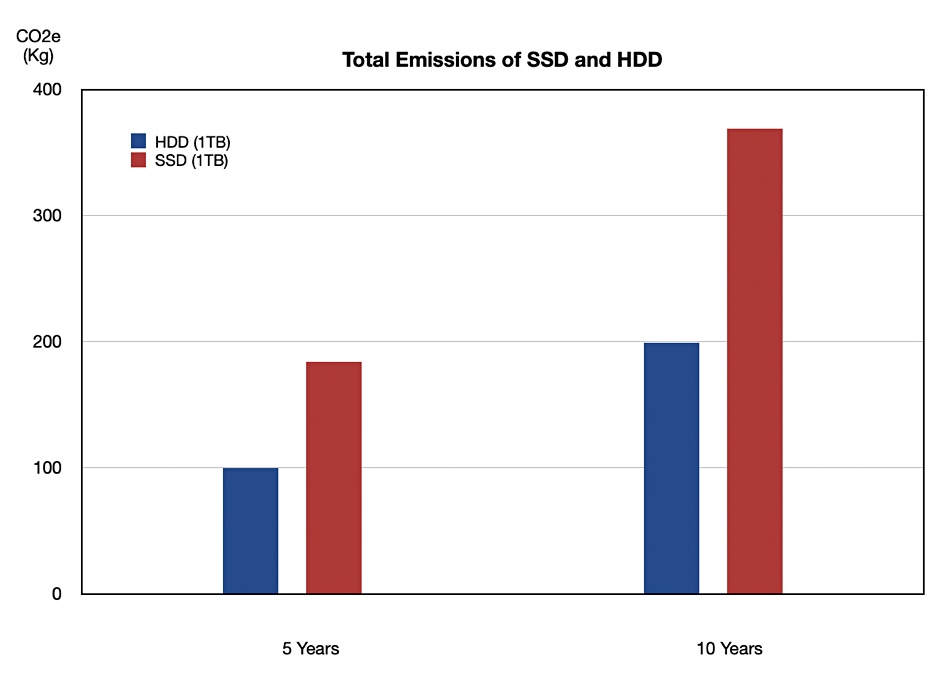
The study assesses and compares the lifetime emissions of HDDs and SSDs, with five-year and 10-year life span periods, in a table:
CO2e is the emitted carbon cost in kilograms. We charted the total lifetime HDD and SSD emissions numbers (rightmost two columns) to show the result graphically:
According to this study, HDDs also emit less carbon during manufacture and their operational life than SSDs, and are thus more acceptable from an environmental view point.
Some caveats:
The study assumes average HDD power consumption to be 4.2W, whereas SSD consumes 1.3W power.
The opex (operational life) CO2e number uses a total energy consumption emission factor specified by the US EPA – 0.7kg/kWh from 2019 data.
The capex is the embedded carbon cost from manufacturing.
The 10-year calculation has a capex upgrade cost as both SSD and HDD are assumed to have five-year lifetimes.
Lewis writes: “The common thought is that SSDs are generally more sustainable than HDDs because they are more power efficient, primarily due to the lack of moving parts. This energy efficiency argument is heavily used in vendor marketing, specifically from storage vendors selling all-flash storage systems.”
But the research study changes things. “This is a fairly surprising result. The vast majority of vendors claim that SSDs are far more sustainable than HDDs, yet this report seems to show otherwise.”
Lewis suggests the authors may not have considered that “the technology refresh cycles of HDDs and SSDs have grown apart… A 4- or 5-year refresh cycle… is what is typically used for HDDs… [Longer vendor warranties] are allowing IT organizations to keep SSD devices for up to 10 years.”
Making that assumption gives the SSD a 10-year carbon cost of 209.2kg CO2e, which is much closer to the HDD figure, though still in excess of it.
As SSDs increase their capacity (density) faster than HDDs “this difference in density may allow IT organizations to reduce their overall physical footprint, and therefore total emissions [and this] would make up for the difference between HDD and SSD emissions.”
“Still, the difference in the sustainability of SSDs and HDDs is likely much closer than many flash storage vendors would like to admit.” But in the future “denser devices that provide significant footprint consolidation may also improve the total carbon emissions in the datacenter,” meaning SSDs.
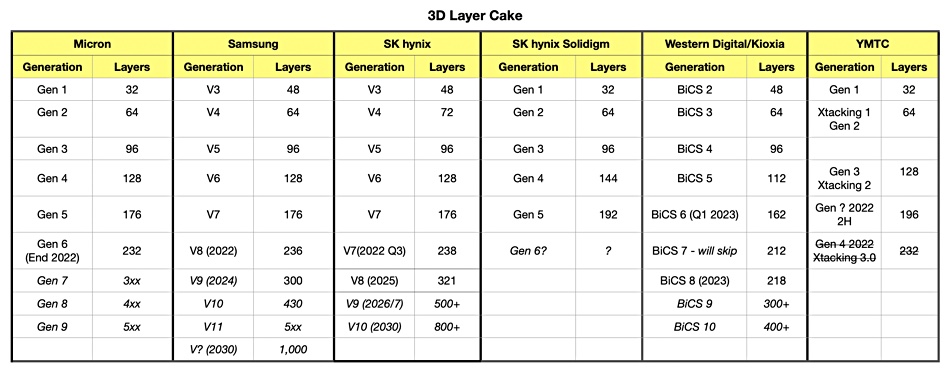
Samsung is planning to build 300-layer3D NAND according to a paywalled DigiTimes Asia report.
This would make Samsung the second 3D NAND fabber after SK hynix to reach the 300-layer point. Sk hynix announced its 321-layer NAND a few days ago at FMS 2023. Micron has a 232-layer tech, SK hynix subsidiary Solidigm is at 192 layers while Kioxia/WD are at the 218-layer level with their BiCS gen 8 technology. China’s YMTC technology progress has been halted due to US IT technology export controls.
Blocks & Files table
Generally speaking, the more layers in 3D NAND, the higher the capacity of the die, assuming the cell dimensions don’t change, and the lower the production cost per TB of flash. This leads to fewer NAND chips being needed to produce flash drives at existing capacity levels, higher-capacity flash drives and, hopefully, a lower cost in $/TB terms.
The 300L Samsung V-NAND device will be made by string-stacking two 150-layer components (strings of cells) together. As more layers are added to a 3D NAND element on a flash wafer it is necessary to etch holes (vias) between layers, and line the holes with chemical substances as part of the die fabrication. These need to be perpendicular to the plane of the wafer and have a regular cross-section and shape as they penetrate the myriad layers involved.
As the layer count increases, it becomes more and more difficult to ensure these characteristics and the yield of the wafer, in terms of good dies versus bad dies, decreases. Stacking two 150-layer components will be easier in manufacturing terms than building a single 300-layer product, although manufacturing takes longer.
The SK hynix 321-layer product is formed from 3 strings, or plugs, stacked together according to a PC Watch photo of an SK hynix slide shown at FMS 2023. Each string has 107 layers. The existing hynix 238-layer technology has two strings, each with 119 layers.
Samsung’s 10th 3D NAND generation could be a 430 layer die and that could also use 3-string stacking technology.
Micron and WD/Kioxia will be encouraged to move to 300-layer technology because, unless they do, their production costs will be higher than both Samsung and SK hynix, putting them at a price disadvantage. Similarly, SK hynix subsidiary Solidigm will face the same pressures.
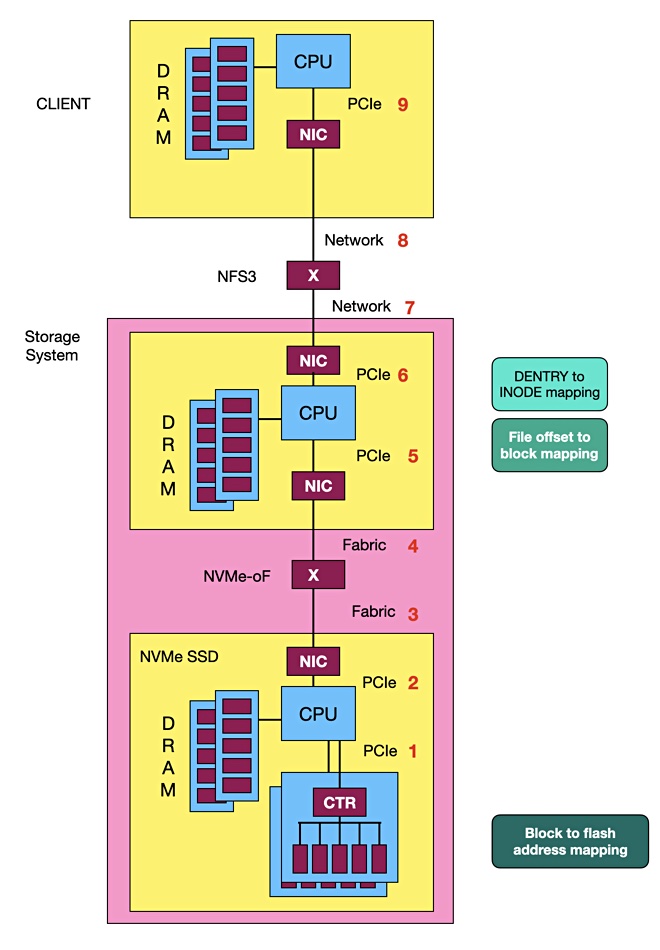
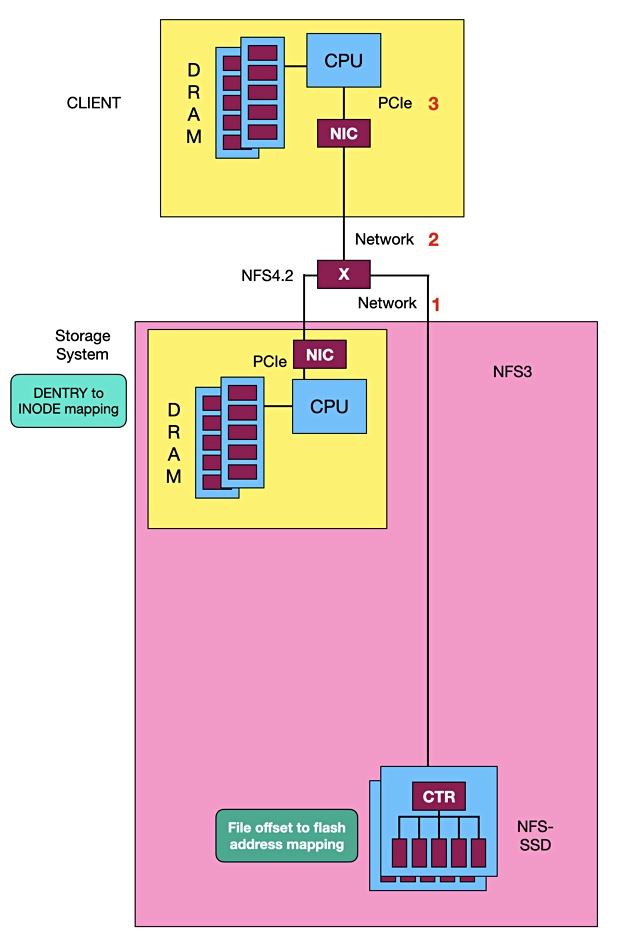
Hammerspace founder and CEO David Flynn has proposed an NFS SSD. Flynn’s notion is based on NFS Ethernet SSDs. The Ethernet SSD concept has been floated before with Kioxia in 2020, for example, putting a Marvell Ethernet controller into an SSD and addressing it as an NVMe device using RoCE. It had previously promoted an Ethernet SSD concept in 2018 as Toshiba Memory.
The Hammerspace CEO says conventional SSDs, when accessed by NFS clients over NVMe, have chatty PCIe connections with up to nine of them per NFS access.
The X device is a PCIe switch.
This can be simplified. The DENTRY (in-memory representation of Directory Entry in Linux) INODE mapping can be carried out by the storage system CPU separate from the client-to-NVMe SSD link chain. This mapping identifies where the data being accessed is located in the target SSD.
The SSD is then accessed by Ethernet and carries out mapping operations to find the file data’s address. Part of the file system now resides in the NFS SSD, which needs software running in its controller processor to achieve. The end result is only three connections between the accessing client and the NVMe SSD. That should lower cost and could improve data access performance and write amplification.
With an array of NFS SSDs you could get parallel access, speeding up IO.
Flynn presented his ideas at the 2023 IEEE Massive Storage Systems and Technology (MSST) conference in SantaClara. Analyst Tom Coughlin wrote about them here.
Bootnote
In November 2021 Kioxia launched EM6 SSDs accessed over RoCE NVMe-over-Fabric links and installed in a 24-slot EBOF — an Ethernet Bunch of Flash box — capable of pumping out 20 million random read IOPS. This provided block access to Ethernet SSDs. The EM6 is a native NVMe SSD fitted with a Marvell 88SN2400 NVMe-oF SSD converter controller that provides dual-port 256Gbit/sec Ethernet access. This product appears to have gone away; we’ve asked Kioxia to confirm this and the company said: “The EM6 is no longer available and it was never released to production.”
IBM is adding a server and software to its Diamondback tape library to build an on-premises S3 object storage archive.
The DiamondBack (TS6000), introduced in October last year, is a single-frame tape library with up to 14 TS1170 tape drives and 1,458 tape LTO-9 cartridges, storing 27.8PB of raw data, and 69.6PB with 2.5:1 compression. It transfers data at up to 400MBps with 12 drives active and has a maximum 17.2TB/hour transfer rate.
Diamondback
DiamondBack S3 has an added x86 server, as the image shows, which provides the S3 interface and S3 object-to-tape cartridge/track mapping. Client systems will send Get (read) and Put (write) requests to DiamondBack S3 and it will read S3 objects from, or write the objects to, a tape cartridge mounted in one of the drives.
IBM’s Advanced Technology Group Tape Team is running an early access program for this Diamondback S3 tape library. Julien Demeulenaere, sales leader EMEA – Tape & High-End Storage, says Diamondback S3 will be a low-cost repository target for a secure copy of current or archive data. It will enable any user familiar with S3 to move their data to Diamondback S3. A storage architect can sign up for a 14-day shared trial on a Diamondback S3 managed by IBM, so they can verify the behavior of S3 for tape.
The S3-object-on-tape idea is not new, as seen with Germany’s PoINT Software and Systems and its Point Archival Gateway product. This provides unified object storage with software-defined S3 object storage for disk and tape, presenting their capacity in a single namespace. It is a combined disk plus tape archive product with disk random access speed and tape capacity.
Archiving systems supplier XenData has launched an appliance which makes a local tape copy of a public cloud archive to save on geo-replication and egress fees.
Quantum has an object-storage-on-tape tier added to its ActiveScale object storage system, providing an on-premises Amazon S3 Glacier-like managed service offering. SpectraLogic’s BlackPearl system can also provide an S3 interface to a backend tape library.
DiamondBack S3 does for objects and tape what the LTFS (Linear Tape File System) does for files and tape, with its file:folder interface to tape cartridges and libraries. Storing objects on tape should be lower cost than storing them on disk, once a sufficient amount has been put on the tapes – but at the cost of longer object read and write times compared to disk. IBM suggests it costs four times less than AWS Glacier with, of course, no data egress fees.
Demeulenaere told us: “There is no miracle, we can’t store bucket on tape natively. It’s just a software abstraction layer on the server which will present the data as S3 object to the user. So, from a user point of view, they just see a list of bucket and can only operate it with S3 standard command (get/put). But it is still files that are written by the tape drive. The server will be accessed exclusively through Ethernet; dual 100GB port for the S3 command, one GB Ethernet port for admin.
“The server is exclusively for object storage. It can’t be a file repository target. For that, you will need to buy the library alone (which is possible) and operate it as everybody is doing (FC, backup server).”
Secure Data Recovery (SDR) is offering to rescue files up to 256KB from corrupted SanDisk Extreme SSDs for free. A $79.99 licence fee is required for larger file recoveries.
Some 2TB and 4TB Western Digital SanDisk Extreme Pro, Extreme Portable, Extreme Pro Portable and MyPassport SSDs, released in 2023, have suffered data loss due to a possible firmware bug. This has sparked a lawsuit which hopes to become a class action. Secure Data Recovery thinks it has a way to salvage most if not all of the data from such drives.
SDR reckons the firmware bug messes up allocation metadata which stops the SSD managing data distribution among its flash pages and cells. SDR says its “software detects traces of scrambled metadata and file indexes. Once located, it pieces the information together and retrieves the data.” It is providing a process to recover the lost data with users paying a license fee if files above a certain size are recovered. We haven’t tried this process or verified it and include it here for information purposes only.
SanDisk Extreme Pro SSD.
The sequence of operations a user needs to carry out, after connecting the SSD to a PC or Mac host, is this:
2) Select the location containing lost data. That is C: drive for most users.
3) Select Quick File Search or Full Scan.
4) Choose the relevant file or folder.
5) Continue with the relevant subfolder if applicable.
6) Select the file from the list on the right.
7) Click to select the output folder for recoverable files. That is the E: drive for most users.
8) Click Recover in the bottom-right corner of the window. A status update will appear if successful.
9) Click Finish in the bottom-right corner of the window.
SDR says that “sometimes, the parent folder structure is lost in the process. However, the files inside them are unaffected. Most subfolders remain intact. Recovered files from missing directories are assigned to a Lost and Found folder.”
The company is a SanDisk platinum partner for its recovery services under a no-data-no-recovery-fee deal. WD’s data recovery webpage lists four US-based recovery operators: Ontrack Data Recovery, Drive SaversDataRecovery, Datarecovery.com and Secure Data Recovery.
Ascend.io’s CEO/founder Sean Knapp says he believes that the data ingestion market won’t exist within a decade, because cloud data players will provide free connectors and different ways to connect to external sources without moving data. He thinks consolidation in the data stack industry is reaching new heights as standalone capabilities are getting absorbed into the major clouds.
…
SaaS app and backup provider AvePoint reported Q2 revenue of $64.9 million, up 16 percent year on year. SaaS revenue was $38.3 million, up 39 percent year on year, and its total ARR was $236.2 million, up 26 percent. There was a loss of $7.1 million, better than the year-ago $11.1 million loss. It expects Q3 revenues to be $67.6 to $69.6 million, up 9 percent year on year at the mid-point.
…
Backblaze, which supplies cloud backup and general storage services, has hired Chris Opat as SVP for cloud operations. Backblaze has more than 500,000 customers and three billion gigabytes of data under management. Opat will oversee cloud strategy, platform engineering, and technology infrastructure, enabling Backblaze to scale capacity and improve performance and provide for the growing pool of larger-sized customers’ needs. Previously, he was SVP at StackPath, a specialized provider in edge technology and content delivery. He also spent time at CyrusOne, CompuCom, Cloudreach, and Bear Stearns/JPMorgan.
…
An IBM Research paper and presentation [PDF] proposes to decouple a file system client from its backend implementation by virtualizing it with an off-the-shelf DPU using the Linux virtio-fs/FUSE framework. The decoupling allows the offloading of the file system client execution to an ARM Linux DPU, which is managed and optimized by the cloud provider, while freeing the host CPU cycles. The proposed framework – DPFS, or DPU-powered File System Virtualization – claims to be 4.4× more CPU efficient per I/O, delivers comparable performance to a tenant with zero-configuration or modification to their host software stack, while allowing workload-specific backend optimizations. This is currently only available with the limited technical preview program of Nvidia BlueField.
…
MongoDB has launched Queryable Encryption with which data can be kept encrypted while it’s being searched. Customers select the fields in MongoDB databases that contain sensitive data that need to be encrypted while in-use. With this the content of the query and the data in the reference field will remain encrypted when traveling over the network, while it is stored in the database, and while the query processes the data to retrieve relevant information. The MongoDB Cryptography Research Group developed the underlying encryption technology behind MongoDB Queryable Encryption and is open source.
MongoDB Queryable Encryption can be used with AWS Key Management Service, Microsoft Azure Key Vault, Google Cloud Key Management Service, and other services compliant with the key management interoperability protocol (KMIP) to manage cryptographic keys.
…
Nexsan – the StorCentric brand survivor after its Chapter 11 bankruptcy and February 2023 purchase by Serene Investment Management – has had a second good quarter after its successful Q1. It said it accelerated growth in Q2 by delivering on a backlog of orders that accumulated during restructuring after it was acquired. Nexsan had positive operational cash flow and saw growth, particularly in APAC. It had a 96 percent customer satisfaction rating in a recent independent survey.
CEO Dan Shimmerman said: “Looking ahead, we’re recruiting in many areas of the company, including key executive roles, and expanding our sales and go-to-market teams. Additionally, we’re working on roadmaps for all our product lines and expect to roll these out in the coming months.”
…
Nyriad, which supplies UltraIO storage arrays with GPU-based controllers, is partnering with RackTop to combine its BrickStor SP cyber storage product with Nyriad’s array. The intent is to safeguard data from modern cyber attacks, offering a secure enterprise file location accessible via SMB and NFS protocols and enabling secure unstructured data services. The BrickStor Security Platform continually evaluates trust at the file level, while Nyriad’s UltraIO storage system ensures data integrity at the erasure coded block level. BrickStor SP grants or denies access to data in real time without any agents, detecting and mitigating cyberattacks to minimize their impact and reduce the blast radius. Simultaneously, the UltraIO storage system verifies block data integrity and dynamically recreates any failed blocks seamlessly, ensuring uninterrupted operations. More info here.
…
Cloud file services supplier Panzura has been ranked at 2,075 on the 2023 Inc. 5000 annual list of fastest-growing private companies in America, with a 271 percent increase year on year in its ARR. Last year Panzura was ranked 1,343 with 485 percent ARR growth. This year the Inc. 5000 list also mentions OwnBackup at 944 with 625 percent revenue growth, VAST Data at 2,190 with 254 percent growth, and Komprise at 2,571 with 212 percent growth. SingleStore and OpenDrives were both on the list last year but don’t appear this year.
…
Real-time database supplier Redis has upgraded its open source and enterprise product to Redis v7.2, adding enhanced store vector embeddings and a high-performance index and query search engine. It is previewing a scalable search feature which enables a higher query throughput, including VSS and full-text search, exclusively as part of its commercial offerings. It blends sharding for seamless data expansion with efficient vertical scaling. This ensures optimal distributed processing across the cluster and improves query throughput by up to 16x compared to what was previously possible.
The latest version of the Redis Serialization Protocol (RESP3) is now supported across source-available, Redis Enterprise cloud and software products for the first time. Developers can now program, store, and execute Triggers and Functions within Redis using Javascript. With Auto Tiering, operators can keep heavily used data in memory and move less frequently needed data to SSD. Auto Tiering offers more than twice the throughput of the previous version while reducing the infrastructure costs of managing large datasets in DRAM by up to 70 percent.
The preview mode Redis Data Integration (RDI) transforms any dataset into real-time accessibility by seamlessly and incrementally bringing data from multiple sources to Redis. Customers can integrate with popular data sources such as Oracle Database, Postgres, MySQL, and Cassandra.
…
Silicon Motion has confirmed the termination of the merger agreement with MaxLinearand intends to pursue substantial damages in excess of the agreement’s termination fee due to MaxLinear’s willful and material breaches of the merger agreement. A July 26 MaxLinear statement said:”MaxLinear terminated the Merger Agreement on multiple grounds, including that Silicon Motion has experienced a material adverse effect and multiple additional contractual failures, all of which is clearly supported by the indisputable factual record. MaxLinear remains entirely confident in its decision to terminate the Agreement.” A July 26 8-K SEC filing contains a little more information.
…
HA and DR supplier SIOS has signd with ACP IT Solutions GmbH Dresden top disribute its products in Germany, Switzerland, and Austria.
…
SK hynix is mass-producing its 24GB LPDDR5X DRAM, the industry’s largest capacity.
Robert Scoble
…
Decentralized storage provider Storj has a partnership with Artificial Intelligence-driven mental health tech company MoodConnect. The two intend to unveil a state-of-the-art mental health tracker designed to help individuals and corporations capture, store, and share sentiment data securely. MoodConnect empowers users to track, store and share their own emotion data from conversations and to securely possess this data for personal introspection, to share with healthcare professionals, with friends and family, or to gauge organizational sentiment within a company. It will use Storj distributed storage. MoodConnect has appointed Robert Scoble as its AI advisor.
Broadcom has unveiled its updated 256-port and 512-port Fibre Channel Director switches, operating at 64Gbps. This represents the seventh generation of Fibre Channel storage networking technology, accompanied by a higher-capacity extension switch.
Fibre Channel (FC) is a lossless networking scheme used in Storage Area Networks (SANs). The seventh-generation FC succeeds the 32Gbps Gen 6 version. Systems, including servers and storage arrays, employ FC host bus adapters for switch connections and subsequent access to host systems. The larger switches with the most network ports are termed Directors, while devices designed for long-distance links are known as Extension Switches. Almost three years after launching its first 64Gbps Fibre Channel (FC) switch gear, Broadcom is updating its products with more 64Gbps ports.
Broadcom’s Dennis Makishima, VP and GM for its Brocade Storage Networking division, said: “High density and global network extension technology enables Broadcom customers to build datacenter infrastructure that is scalable, secure, and reliable.”
Broadcom Brocade X7-8 and X7-4 Directors in their 14RU and 8RU chassis
In 2020, Broadcom announced the first-generation Brocade brand X7 Directors with up to 384 64Gbps line rate ports, using 8 x 48-ports or 512 x 32Gbps ports, G720 switches with 56 x 64Gbps line rate ports in a 1RU design, and 7810/7840 extension switches. Now it has been able to work up to providing 512 x 64Gbps ports in the X7 Director by using a new 64-port blade with SFP-DP transceivers, which is 33 percent faster, it says, than the prior transceivers.
Broadcom has also added the 64Gbps Brocade 7850 Extension Switch to the product set, enabling faster worldwide scale and delivering up to 100Gbps over long distances. It manages the longer latency and packet losses that occur with such extended distances. The new switch complements the existing 7810 switch, with its 12 x 32Gbps FC and 6 x 1/10Gbps Ethernet ports, and also the 7840 with its 24 x 16Gbps FC/FICON and 16 x 1/10Gbps Ethernet ports. FICON is the Fibre Channel IBM mainframe link.
Brocade 7850 Extension Switch
The 7850 is significantly faster than the 7810 and 7840, with 24 x 64Gbps FC and FICON ports, and 16 x 1/10/25Gbps and 2 x 100Gbps Ethernet ports. It supports in-flight encryption and can be used to hook up a disaster recovery site to the main site, with lossless failover between WAN links.
Cisco’s MDS 9700 Fibre Channel Director uses a 48-Port 64Gbps Fibre Channel Switching Module (blade). Its MDS 9000 24/10-Port Extension Module provides 24 x 2/4/8/10/16Gbps FC ports and 8 x 1/10 Gbps Ethernet Fibre Channel over IP (FCIP) ports. Broadcom’s new gear is faster.
There is backwards compatibility for 8, 16, and 32Gbps Fibre Channel with the new Broadcom products. The Brocade X7 Director and 7850 Extension Switch are available now. Get an X-7 Director product brief here and 7850 Extension Switch details here.
Supermicro has launched a PCIe gen 5 storage server line with E3.S flash drives and CXL memory expansion support aimed squarely at the HPC and ChatGPT-led AI/ML markets.
The EDSFF’s E3.S form factor updates and replaces the U.2 2.5-inch drive format, inherited from the 2.5-inch disk drive days. Supermicro is supporting single AMD and dual Intel CPU configurations in either 1RU or 2RU chassis, with up to four CXL memory modules (CMM) in the 1RU chassis, and NVMe SSDs filling the E3.S slots. Given that they use the latest AMD and Intel processors, these are likely the fastest raw spec storage servers on the market and are aimed at the AI inferencing and training markets.
Supermicro president and CEO Charles Liang said: “Our broad range of high-performance AI solutions has been enhanced with NVMe based Petabyte scale storage to deliver maximum performance and capacities for our customers training large AI models and HPC environments.”
The systems support up to 256TB/RU of capacity, meaning a full rack could hold 10.56PB of raw storage.
There are four separate products or SKUs and a table lists their characteristics:
The 1RU models can accommodate up to 16 hot-swap E3.S drives, or eight E3.S drives, plus four E3.S 2T 16.8mm bays for CMM and other emerging modular devices. The 2RU servers support up to 32 hot-swap E3.S drives. Maximum drive capacity is 15.36TB in the E3.S format currently, but 30TB E3.S drives are coming later this year, and that will double the maximum capacity at 512TB/RU, meaning 1PB in 2U and 20PB in a full rack. The data density and raw access speed will seem incredible to users with arrays of 7 or 15TB PCIe gen 3 or 4 drives.
Both Kioxia and Solidigm are working with Supermicro to get their coming higher-capacity SSDs supported by these new storage servers.
It’s likely that the other main storage server suppliers – Dell, HPE, and NetApp – will use similar designs for their scale-out storage hardware in the near future. A lids-off picture shows the basic Supermicro design: drives at the front, then fans, logic, memory and processors in the middle, with power supplies and network ports at the back.
Clockwise from top left: single AMD 2U, dual-Intel 2U, dual-Intel 1U, single AMD 1U
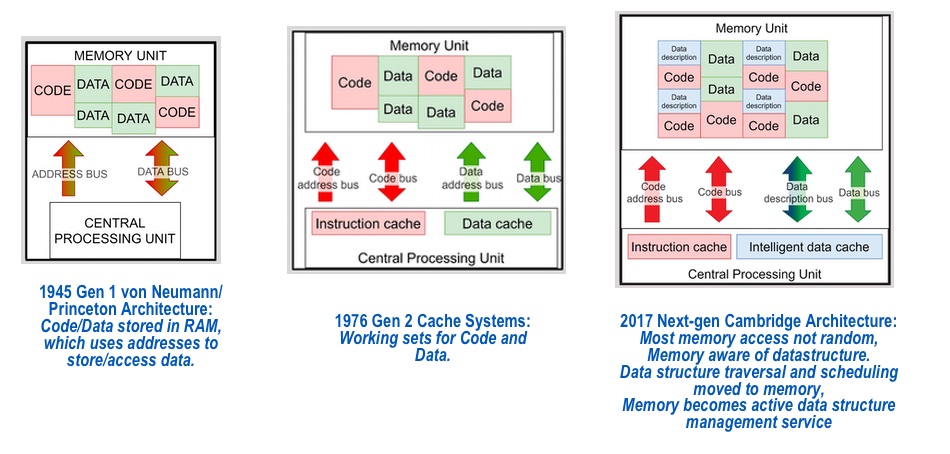
UK startup BlueShift Memory has won an FMS 2023 Most Innovative Memory Technology award for its memory accelerating FPGA that it claims offers up to 1,000 times speed up for structured data set access.
Fabless semiconductor company BlueShift was founded in 2016 in Cambridge, England, by CTO and ex-CEO Peter Marosan, a mathematician with experience in cloud and grid computing. He said he realized that a memory wall was developing between processors and memory with cores sitting idle between memory accesses because there was not enough CPU-memory bandwidth, with caching being rendered less useful as data set sizes increase.
Marosan said: “We have worked extremely hard over the past couple of years to prove the concept of our disruptive non-Von Neumann architecture and to develop our self-optimizing memory solution, and it is very rewarding to have our efforts acknowledged by the Flash Memory Summit Awards Program.”
He has devised the ‘Cambridge’ architecture to follow on from current cached CPU-memory systems developed from researchers at Harvard/Von Neumann/Princetonm who created architectures specifying CPU-memory interactions.
BlueShift diagrams
The Cambridge architecture way to provide more bandwidth is for the memory system to understand some data structures and stream data as it’s needed to the CPU cores instead of waiting for them to finish an instruction, move on to the one in cache, rinse and repeat, coping with cache misses and going to DRAM, etc.
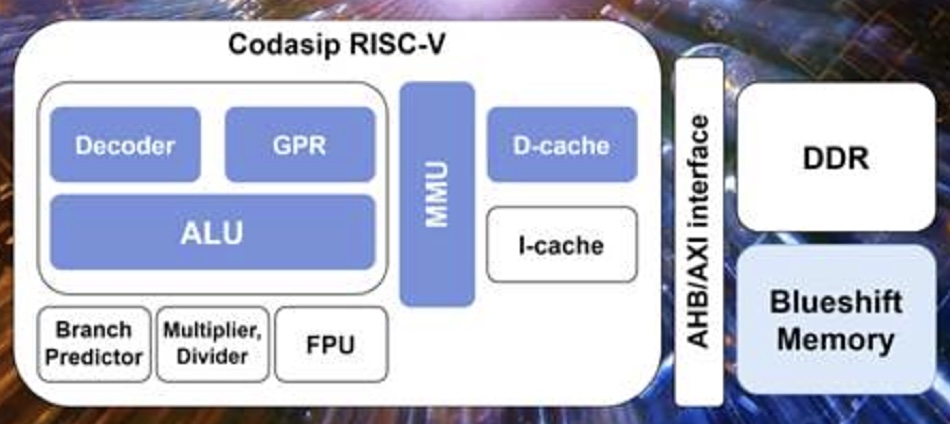
BlueShift has developed an FPGA featuring an integrated RISC-V Processor with a modified Codasip core to maximise memory bandwidth, and accelerate CPU core-DRAM access. It does this for HPC, AI, augmented and virtual reality machine vision, 5G Edge and IoT applications where large datasets have to be processed in as short a time as possible.
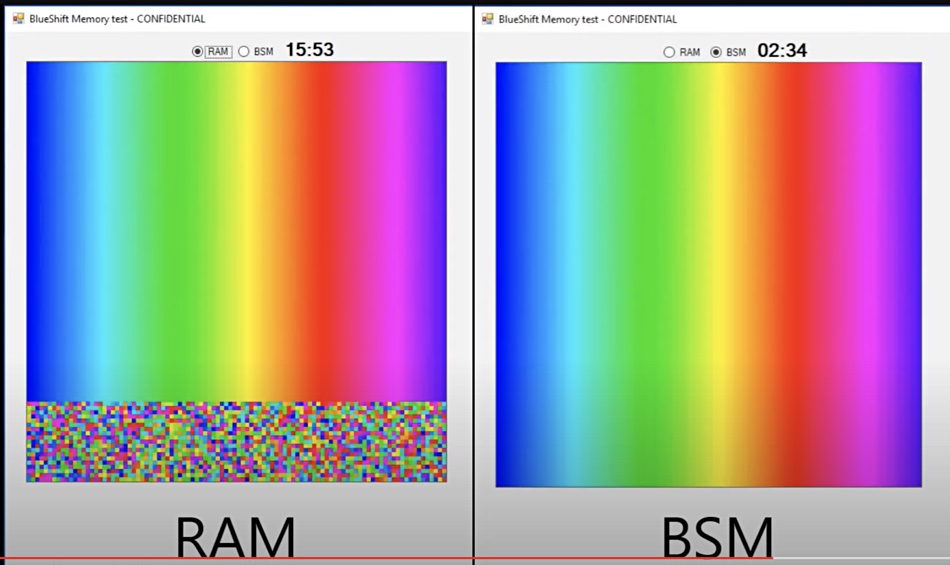
The sort job compared two systems sorting an array of random coloured squares into a spectrum. One was a 100 MHz CPU/DRAM system doing the job along with a 100MHz BlueShift Memory (BSM) system shipping data to its CPU. The BSM system completed the job in 2 minutes 34 secs while the unaided CPU system took 19 minutes and 34 secs, 8.3x longer.
Data sort demo with BSM system completed in 2 mons and 34 seconds.
BlueShift presented a paper, titled “Novel memory-efficient computer architecture integration in RISC-V with CXL” at FMS 2023. It reported that its demonstration BSM device had achieved an acceleration factor of 16 to 128 times for processing image data, along with ultra-low power consumption.
The BlueShift Memory IP can be integrated into either memory chips or processors, or can be used in a stand-alone memory controller. The company says it can cut memory energy access costs in half, and provide zero-latency memory accesses.
Nutanix has launched a turnkey GPT-in-a-box for customers to run large language model AI workloads on its hyperconverged software platform.
Update: Nutanix does not support Nvidia’s GPU Direct protocol. 5 Sep 2023.
GPT (Generative Pre-trained Transformer) is a type of machine learning large language model (LLM) which can interpret text requests and questions, search through multiple source files and respond with text, image, video or even software code output. Sparked by the ChatGPT model, organizations worldwide are considering how adopting LLMs could improve marketing content creation, make chatbot interactions with customers better, provide data scientist capabilities to ordinary researchers, and save costs while doing so.
Greg Macatee, an IDC Senior Research Analyst, Infrastructure Systems, Platforms and Technologies Group, said: “With GPT-in-a-box, Nutanix offers customers a turnkey, easy-to-use solution for their AI use cases, offering enterprises struggling with generative AI adoption an easier on-ramp to deployment.”
Nutanix wants to make it easier for customers to trial and use LLMs by crafting a software stack including its Nutanix Cloud Infrastructure, Nutanix Files and Objects storage, and Nutanix AHV hypervisor and Kubernetes (K8S) software with Nvidia GPU acceleration. Its Cloud Infrastructure base is a software stack in its own right, including compute, storage and network, hypervisors and containers, in public or private clouds. GPT-in-a-box is scalable from edge to core datacenter deployments, we’re told.
The GPU acceleration involves Nutanix’s Karbon Kubernetes environment supporting GPU passthrough mode on top of Kubernetes.
Thomas Cornely, SVP, Product Management at Nutanix, said: “Nutanix GPT-in-a-Box is an opinionated AI-ready stack that aims to solve the key challenges with generative AI adoption and help jump-start AI innovation.”
We’ve asked what the “opinionated AI-ready stack” term means and Nutanix’answer is: “The AI stack is “opinionated” as it includes what we believe are the best in class components for the model runtimes, Kubeflow, PyTorch, Torchserve, etc. The open source ecosystem is fast moving and detailed knowledge of these projects allows us to ensure the right subset of components are deployed in the best manner.’’
Nutanix is also providing services to help customers size their cluster and deploy its software with open source deep learning and MLOps frameworks, inference server, and a select set of LLMs such as Llama2, Falcon GPT, and MosaicML.
Data scientists and ML administrators can consume these models with their choice of applications, enhanced terminal UI, or standard CLI. The GPT-in-a-box system can run other GPT models and fine tune them by using internal data, accessed from Nutanix Files or Objects stores.
Gratifyingly for Nutanix, a recent survey found 78 percent of its customers were likely to run their AI/ML workloads on the Nutanix Cloud Infrastructure. As if by magic, that bears out what IDC’s supporting quote said above.
Nutanix wants us to realize it has AI and open source AI community credibility through its:
Participation in the MLCommons (AI standards) advisory board
Co-founding and technical leadership in defining the ML Storage Benchmarks and Medicine Benchmarks
Serving as a co-chair of the Kubeflow (MLOps) Training and AutoML working groups at the Cloud Native Computing Foundation (CNCF)
Get more details about this ChatGPT-in-a-box software stack from Nutanix’s website.
Bootnote. Nutanix’ Acropolis software supports Nvidia’s vGPU feature, in which a single GPU is shared amongst accessing client systems, each seeing their own virtual GPU. It does not support Nvidia’s GPUDirect protocol for direct access to NVMe storage, bypassing a host CPU and its memory (bounce buffer).






















{kind=link}