


Storage array enhancements used to be simple; a faster drive led to faster arrays. But memory-like protocols and drives have muddied the water, and hardware-enhanced drive and array controllers are also clamouring for attention.
Let’s take a brief look at seven storage technology enhancements, kicking off with Violin Memory and Fusion-IO, which initiated the all-flash array (AFA) in 2005. We will then move onto NVMe SSDs, NVMe-over-Fabrics, Optane, quad-level flash AFAs, DPUS and PCIe 4.0.
For the purpose of this article, we’re ignoring speed bumps within storage link technologies, such as as Fibre Channel, SAS and SATA.
First big advance: SSDs
SSDs are a huge advance on disk drives, moving data access latency from disk drives’ seek time latency of 2ms to 8ms to SSD’s 150µs to 300µs (0.15ms to 0.3ms).
When enterprise feature were added – for example, dual ports and reasonable endurance – SSDs entered the array market in all-flash array form, and also as caches and tiers in hybrid flash-disk arrays. The hybrids were slower than AFAs but held a lot more data and were faster than all-disk arrays.
AFAs are becoming the standard way of storing an organisation’s primary, tier 1 data on-premises. The technology has been tweaked, with NAND dies getting denser through layering (3D NAND) and cells holding more data as SLC (1bit/cell) gave way to MLC (2bits/cell), then TLC (3bits/cell). and now we’re seeing QLC (4 bits/cell).
Two and three; NVMe and NVMe-oF
SSDs got a significant speed bump with NVMe. That gave them direct access to the PCIe bus, dropping latency down to 30µs (0.03ms). This helped servers accessing directly attached NVMe SSDs, but did not help arrays as they have a time-consuming network hop between them and accessing servers.
However, NVMe was extended across Ethernet using remote direct memory access and enabled NVMe-over Fabric connected arrays to achieve read latencies around 100µs. This is radically faster than the 200ms or so experienced from busy Fibre Channel or iSCSI AFAs. (There’s a lot of variability with AFA access, so think of these numbers as guidelines.)
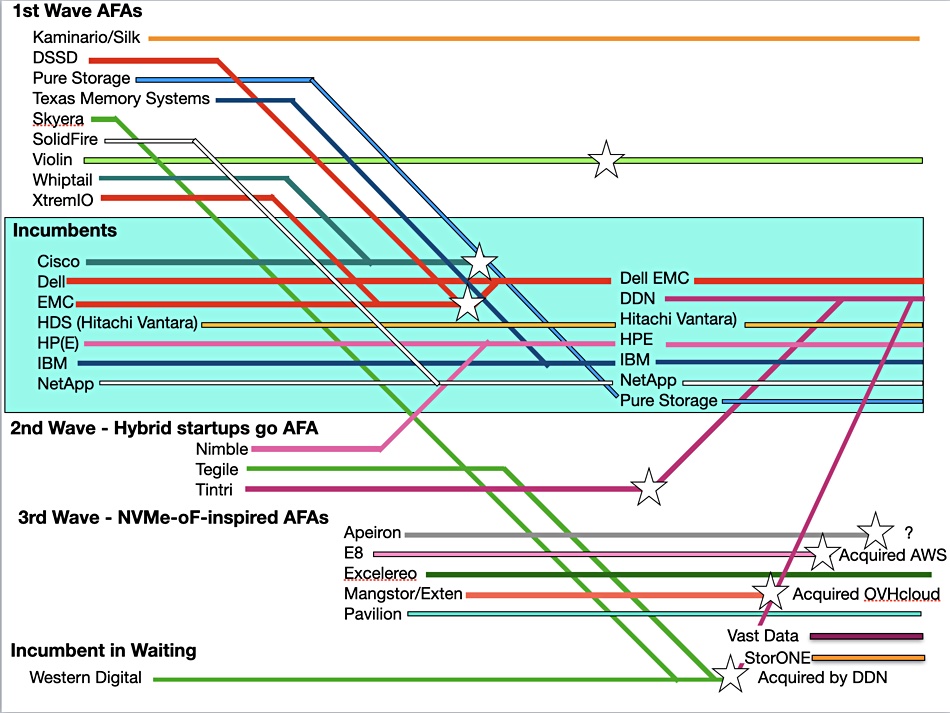
A group of NVMe-oF array startups came into the scene – Apeiron, E8, Excelero, Mangstor and Pavilion Data – to build faster arrays than the mainstream suppliers, which were limited to slower iSCSI and Fibre Channel.
But – and this is a big ‘but’ – NVMe-oF required system and application software changes. This is because it is a drive-level protocol and not a Fibre Channel protocol which abstracts drives into virtual constructs known as Logical Unit Numbers (LUNs). However that has changed. Modern Linux has the NVMe-oF client functionality built-in as does VMware v7.
This has inhibited and slowed NVMe-oF adoption to the extend that mainstream suppliers were able to build in NVMe-oF support and thus match the startups’ technologies. Apeiron has gone quiet, and has not answered our requests for comment. Mangstor became Extern Technologies which was bought by OVHcloud. E8 was bought by Amazon, which leaves just Excelero and Pavilion standing amongst this wave of startups and also Nimbus Data with its ExaFlash arrays.
It is not a certainty that NVME-oF will achieve widespread adoption, as other technologies have arrived that enhance storage speed.
Four – Optane
Optane is a tricky technology to understand, as it is built by Intel into SSD and memory products. it is marketed as filling a gap in the memory-storage hierarchy.
In the memory storage hierarchy memory devices are accessed by application and system software at the bit and byte-level using load/store instructions with no recourse to the operating system’s IO stack. Memory devices are built in DIMMs (Dual Inline Memory Modules).

Storage devices are accessed at the block, file or object level through the operating system’s IO stack.
A new type of disk or a new type of 3D NAND SSD is accessed same storage device way.
A new memory product such as DDR4 is accessed in the same memory access way as its predecessor
However, Optane breaks this simple separation between storage access and memory access. It can be accessed in either storage, as an SSD, or, faster, as memory in a DIMM format. To make life more complex it can be used in two ways when accessed in DIMM format: Memory Mode or App Direct Mode (DAX or Direct Access Mode).
Adding yet more complexity, DAX can be sub-divided again into three options; Raw Device Access, via a File API, or Memory Access. Finally the File API method has two sub-options; via a File System or via a Non-volatile Memory-aware File System (NVM-aware).
In total this provides six Optane access methods; one SSD and five PMEM or DIMM methods;
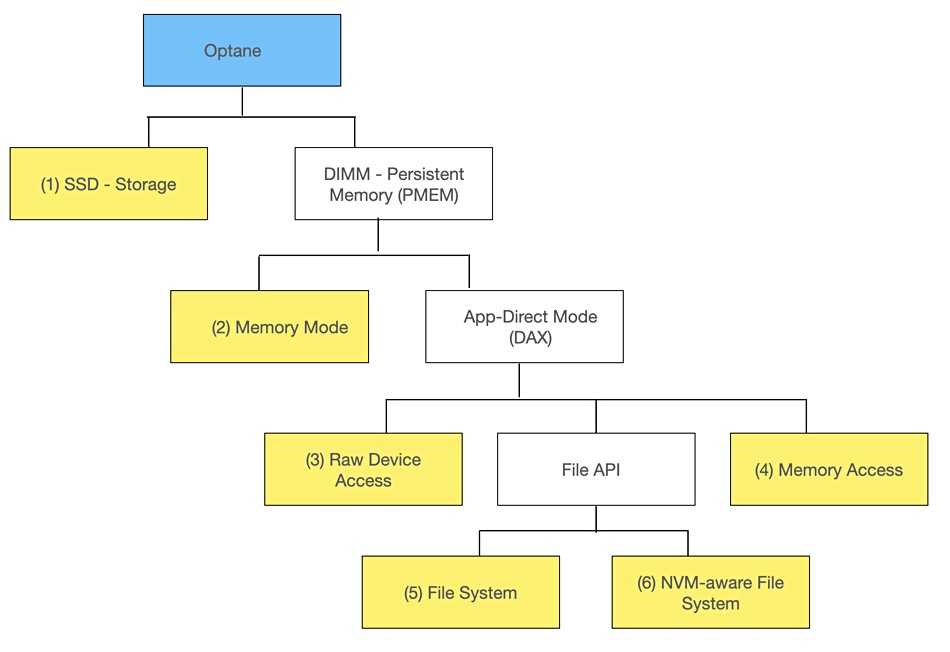
In effect we have not one Optane product but six. It is little surprise that the pace of adoption has been measured, as any application provider wanting to support Optane PMEM has to decide which mode or modes to support and then implement it.
There has been no sight or sound of an all-Optane SSD array. It would seem feasible in theory but its cost would probably be prohibitive. A 480GB Optane SSD costs $588.64 on Amazon. One thousand units would populate a 480TB array and the SSD cost would be a notional $588,640.00, pushing a complete all-Optane 480TB array cost past $600,000 with the 3-year TCO cost even higher.
To give an indication of how expensive this is, the 3-year TCO for a 736TB all-QLC flash StorONE array with Optane tiering, 2 x HPE DL380 GEN10 controllers, plus a pair of HBAs is $417,547.
Five – QLC AFA
QLC flash arrays are cheap enough, according to suppliers such as Pure Storage, VAST Data or StorONE, to store primary and/or secondary data and so mount a replacement attack on nearline or secondary storage arrays and even filers. Such systems currently use hybrid or disk arrays and migrating to QLC flash should deliver significant performance benefits.

The QLC AFAs are accessed in the same way as the arrays they replace, ie. as storage devices, and there is none of the complexity associated with Optane adoption. We expect QLC flash arrays to hit prime time, with mainstream storage vendors such as NetApp adopting the technology.
NVMe-oF access to QLC flash arrays will suffer from the same difficulties as NVMe-oF access to other AFAs.
Six – DPUs
Data Processing Units (DPUs) are storage hardware processing products that operate at drive, array and infrastructure level and offload the host server CPUs from storage-related tasks, and also other tasks such as east-west networking within a data centre. DPU suppliers include:
- Drive-level – Eideticom, NGD, Nyriad, ScaleFlux.
- Array-level – Nebulon, Pensando.
- Infrastructure-level – Fungible, Mellanox, Pliops.

They are a new strand of technology and, at drive-level, do not represent a like-for-like replacement in terms of data access. Storage processing, or compute-on-storage, like video transcoding and data reduction, has to be apportioned between server host and DPU-enhanced drives, and software must be provided for the DPU drives.
Users should not see any access difference at array level, apart from the claimed better performance. Infrastructure-level deployments could see a need for disruptive deployments to gain the performance and any other claimed benefits.
The nascent DPU scene is developing rapidly, but it is far too soon to estimate ultimate adoption levels.
Seven – PCIe Gen 4
One of the biggest speed bumps for storage drives will come with the move from gen 3 PCIe to PCIe 4.0. PCIe is the bus that connects a server’s memory to peripheral components such as storage drives. PCIe 4.0 delivers up to 64GB/s , which is double PCIe 3’s 32GB/s maximum. (This is based on PCIe Gen 3’s lane speed being 1GB/sec and Gen 4’s lane speed being 2GB/sec.) SSDs will be able to ship data faster to a host’s memory.
The PCI-SIG releases the spec for PCIe 5 in May 2019. This will connect at 128GB/s.
Net:Net
We can assume QLC flash arrays and PCIe 4.0 will become a standard feature of the storage landscape. NVMe-oF, Optane and DPUs are works in progress . We think Optane will spread quite widely, use case by use case, and more quickly than NVMe-oF. DPUs will also be a niche technology until market sweet spots emerge.





