Informatica has sealed a wider agreement with Databricks, combining the full range of its AI-powered Intelligent Data Management Cloud (IDMC) within the Databricks Data Intelligence Platform.
The expanded union is designed to let customers deploy enterprise-grade generative AI applications at scale based on high-quality, trusted data and metadata, the companies said.
The deal includes four new capabilities. Firstly, GenAI Solution Blueprint for Databricks DBRX from Informatica provides a roadmap for customers to develop retrieval-augmented generation (RAG) GenAI applications using Databricks DBRX.
DBRX is an open, general-purpose large language model (LLM) designed to enable users to develop enterprise-grade GenAI applications. The Blueprint allows customers to build RAG-based GenAI solutions, using Informatica’s IDMC no-code/low-code interface and metadata-driven intelligence, and Databricks Vector Database, for embedding data, enabling access to data insights.
Secondly, Native Databricks SQL ELT will enable joint customers to perform in-database transformations with full push-down capabilities on Databricks SQL, the intelligent data warehouse. They will be able to use native Databricks functions such as the AI-powered Assistant and serverless compute, letting customers develop ETL pipelines to run on Databricks compute for AI-optimized performance, scalable data transformations, and integrations.
Thirdly, there is Cloud Data Integration-Free Service (CDI-Free) on Databricks Partner Connect. Informatica’s CDI-Free offering is gives customers access to Informatica’s cloud data ingestion and transformation capabilities. CDI-Free via Partner Connect offers users ELT processing of up to 20 million rows of data or ten ELT compute hours per month for free.
Lastly, there is full IDMC Support via Unity Catalog. The Informatica IDMC platform is now fully validated with Databricks Unity Catalog, a unified governance layer for data and AI within the Databricks platform.
The integration includes all critical IDMC services and “greatly enhances” Informatica’s ability to manage data lineage and governance on the IDMC Platform, said Informatica.
“We are expanding our innovation and collaboration with Databricks with complete support for Unity Catalog and our enhanced comprehensive GenAI solution blueprint,” said Amit Walia, chief executive officer at Informatica. “Together, we can deliver an AI-powered foundation for data management and data intelligence in the cloud to accelerate our joint customers into the era of GenAI with truly transformative applications.”
“This partnership enables us to leverage cutting-edge technologies from both market leaders to drive innovation and deliver tangible business value, not only to our internal IT, but also to the solutions offered to our clients,” said Dennis Tally, managing director at global consultancy KPMG, in a supporting quote.
Adam Conway, SVP of products at Databricks, added: “In the era of GenAI, access to trusted, high-quality data is becoming more essential than ever, especially for RAG implementations.”
Earlier this month, Cirata released Data Migrator 2.5, which also includes native integration with the Databricks Unity Catalog, centralizing data governance and access control capabilities to enable “faster data operations” and “accelerated” time-to-business-value for enterprises, said Cirata.
Media and entertainment software-defined storage specialist OpenDrives has appointed Sean Lee as its new chief executive officer. He replaces Izhar Sharon, who was originally appointed CEO in December 2022 to help break OpenDrives out of its M&E business niche, a strategy that now seems to have been reversed.
Los Angeles-headquartered OpenDrives provides media workflow solutions and storage management services. Founded in 2011 by M&E post-production professionals and technologists, OpenDrives is powered by its core Atlas software, which is deployed on-premises and into the cloud.
Sean Lee
Lee most recently served as the company’s chief strategy and operations officer, and has held leadership positions with OpenDrives since 2015. Lee was also once an OpenDrives customer, having served 15 years at Universal Studios, where he implemented efficient processes and improved workflows – something OpenDrives aims to deliver with its solutions.
As CEO of OpenDrives, Lee will “continue to leverage his experience as a customer to develop and deliver solutions that empower content creators and drive the future of M&E,” said the company.
Of Sharon’s departure, OpenDrives told Blocks & Files: “Izhar joined OpenDrives to lead the technical strategy and help move us outside of the M&E space. What’s become clear to the board is that OpenDrives’ origins is its path forward – it was founded by technologists like Sean from the industry, and innovates solutions FOR the industry.
“With Sean’s deep understanding of the M&E space, and his customer-centric approach, he’s the right individual to drive OpenDrives’ next phase.”
OpenDrives’ investors obviously want the company to re-focus on M&E. Joel Whitley, partner at IAG Capital Partners, said in a prepared statement: “Sean’s deep industry experience and charismatic outlook make him precisely what OpenDrives needs to remain focused on the M&E sector, as well as any business with content workflows.
“We are confident that he will build on this strong foundation to propel the business forward to break new ground in empowering storytellers and creatives worldwide.”
On his departure, in a LinkedIn post, Sharon said: “After a couple of great years at OpenDrives, building a foundation for the future, I am working on my next adventure. Best of luck to Sean Lee and team!”
OpenDrives recently unveiled its updated Atlas storage platform, built around a composable software architecture, which is complemented with an unlimited capacity business model.
Lee said: “We are committed to driving innovation and challenging the status quo, so that the M&E industry can continue to push boundaries and tell immersive stories that engage, inform and delight audiences everywhere on any platform.”
Operations at seven UK hospitals have been delayed after a ransomware attack on pathology lab services provider Synnovis.
The attack by the Russian Qilin group took place on June 2, knocking out server systems at the UK operations of SYNLAB, which forms part of the Synnovis partnership with the Guy’s and St Thomas’ and King’s College Hospital NHS Foundation Trusts. Synnovis went live with a Laboratory Information Management System (LIMS) in October 2023 that combined multiple separate IT systems at the trusts into a single logical system.
A new LIMS powered by Epic software went live across the two hospital trusts that month. It locked the trusts into a single system dependent upon SYNLAB operations for pathology test results. When the server system of Synnovis, the NHS-SYNLAB partnership, went down, the trusts’ patient treatment operations were devastated.
Guy’s and St Thomas’ CEO Ian Abbs sent out a mail on June 3, saying: “I can confirm that our pathology partner Synnovis experienced a major IT incident earlier today, which is ongoing and means that we are not currently connected to the Synnovis IT servers. This is having a major impact on the delivery of our services, with blood transfusions being particularly affected. Some activity has already been cancelled or redirected to other providers at short notice as we prioritise the clinical work that we are able to carry out.”
As for SYNLAB, it described the attack as “an isolated incident to Synnovis with no connection to the cyber-attack on SYNLAB Italy on 18 April 2024.” It added: “The rest of the SYNLAB Group including the other SYNLAB facilities in the UK are not impacted.”
SYNLAB is an international medical diagnostics provider headquartered in Munich, Germany. It is the leading provider of diagnostic services and specialty testing in Europe. It employs around 27,000 people across its operations. SYNLAB is publicly listed on the Frankfurt Stock Exchange and had revenues of €3.25 billion in 2022. Major shareholders include private equity firms Cinven and Novo Holdings among others.
In its 2020 ESG Report, SYNLAB said: “We take our responsibility towards storing and processing data on our IT systems very seriously. Potential data breaches or system failures can have real life impacts for the patients who rely on our diagnosis. We are introducing policies to ensure that the data is encrypted and secure, and we work closely with a network of external partners to neutralise any potential cybersecurity risks.”
Valerio Sorrentino
It established a Chief Information Security Officer (CISO) position that “focuses on identifying cybersecurity and IT compliance risks as they may impact our strategic, operational, and financial performance.” Valerio Sorrentino is SYNLAB’s Group ISO and has posted about the dangers of phishing attacks on LinkedIn. He says he was “recognized by Lacework as one of the 50 CISOs in the world to watch in 2024.”
Sorrentino knows about the targeting of healthcare providers by malware attackers, posting on LinkedIn eight months ago: ”l want to inform you that the North Korean state-sponsored actor, called the Lazarus Group, is targeting healthcare entities in Europe and the United States as reported by Cisco Talos.”
IT Services supplier CSI previously supplied a Security Operations Centre to SYNLAB in the UK and has published a case study about this contract, saying readers can “learn how SYNLAB, one of Europe’s largest medical testing companies, stays one step ahead of cyberattacks including WannaCry and Petya.”
CSI’s case study says: “CSI’s Security Operations Centre (SOC) deployed AI-driven threat protection to neutralise advanced threats and continuously protect the endpoints without disrupting users. Now its SOC experts can react immediately to alerts and work with Synlab to resolve cyber security-related incidents.”
Mark Dollar
CSI has not responded to an inquiry about its current involvement with SYNLAB and whether it was part of efforts to fend off the Synnovis attack.
SYNLAB ops fell prey to two previous attacks, one of which being the unconnected attack on its Italy offshoot described earlier. A SYNLAB operation in France was attacked by Clop group ransomware in June 2023. Then, in April 2024, SC Media reported that SYNLAB Italia had been hit by a cyberattack that disrupted its laboratories, medical centers, and sampling points, compromising 1.5 TB of data, including personal and medical details of patients and employees. The Black Basta ransomware group infiltrated its networked system, causing the shutdown of IT systems in 380 labs and medical centers in Italy. SYNLAB has emphasized that the Synnovis attack is not related.
David Akinpitansoye
SYNLAB Italia reportedly did not pay the demanded ransom and took almost a month to get its systems back online.
After the latest attack took place, SYNLAB UK CEO Mark Dollar put out a statement saying: “We take cybersecurity very seriously at Synnovis and have invested heavily in ensuring our IT arrangements are as safe as they possibly can be.”
Neither Dollar nor his Data Protection Officer, David Akinpitansoye, have responded to our inquiries about the incident, which is ongoing with weeks of disruption likely.
Two enterprise data protection companies, one old, one new – both public – are sponsoring two US cricket teams.
Update. Veeam tells us it “has sponsored the Seattle Orcas cricket team for over a year now – the first in our market to sponsor a major cricket team.” 11 June 2024.
Newly public Rubrik is the official cybersecurity sponsor for the San Francisco Unicorns’ Major League Cricket (MLC) season starting July 5 this year. The Unicorns’ roster features World Cup winners and global talents from international teams including Australia, Pakistan, and New Zealand. Long-time public company Commvault is an associate sponsor of the defending champions of Major League Cricket, MI New York, where Accenture is the principal sponsor. MI (Mumbai Indians) New York is a T20 cricket team established in 2023. The T20 format is shorter and, hopefully, faster paced than world test cricket games, entailing just 20 overs per innings.
Rubrik CMO Andres Botero said: “Unicorns are unique, special – a phenomenon. This notable Bay Area team brings innovation, excellence, and resilience to the cricket pitch, making this partnership a perfect match.”
Rubrik said it shares a common philosophy with the SF Unicorns built around a commitment to recruiting exceptional talent, delivering innovation, and relentlessness. Rubrik’s brand will be prominently displayed on the Unicorns’ team assets and uniforms throughout the season.
SF Unicorns co-ownerAnand Rajaraman said: “Rubrik is exactly the kind of game-changing Unicorn the team is named for. This agreement is a testament to our shared commitment to excellence through talent, innovation and teamwork.”
Commvault CMO Anna Griffin also said in a statement: “Sponsoring the MI New York cricket team is Commvault’s opportunity to support one of the most dynamic and fast-growing sports in the world. It’s a no-brainer.”
Commvault’s sponsorship will feature opportunities to engage with fans including exclusive watch parties, contests, and cricket clinics with professional players. Fans, partners, and customers will also have the chance to join these events in the Dallas and Morrisville stadiums.
Griffin said: “This partnership not only allows us to engage with cricket fans but also reinforces our dedication to fostering community and resilience. We’re excited to share the Commvault spirit and support the MI New York team on their journey. We’re thrilled to connect with cricket fans and bring the Commvault spirit to the pitch.”
Commvault said cricket is the second most watched sport globally, with more than 2.5 billion fans. As cricket’s popularity surges in the United States, Commvault’s collaboration with MI New York aims to bring the thrill of the game to a broader, more diverse audience. In Commvault’s view, it serves as an opportunity to educate an untapped global fan base about the importance of resilience – critical knowledge that is applicable to both personal and professional life, whether on the pitch or in a Commvault Cleanroom defending against cyberattacks.
Mumbai Indians play in the Indian Premier League and is owned by Indiawin Sports Pvt. Ltd, a subsidiary of Reliance Industries, one of India’s largest conglomerates. MI is a global cricketing force, with five T20 teams spanning three continents, and four countries including both men and women.
The San Francisco Unicorns, in partnership with MLC, plan to build a world-class home for the team in the Bay Area, which will seat up to 15,000 people and be capable of hosting major international cricket events. The team’s primary investors are Silicon Valley entrepreneurs Anand Rajaraman and Venky Harinarayan, who are founding partners of data-driven venture firm rocketship.vc, and previously founded US-focused database technology provider Junglee, which was sold to Amazon in 1998 for $250 million.
For more details on the MI New York schedule and how to watch, visit Commvault’s official blog. Commvault is also associated with India’s Hyderabad Cricket League. Check out SFUnicorns.com and Rubrik.com to find out more about their partnership.
More than half of IT professionals plan to migrate or modernize some of their VM workloads to Kubernetes, according to research looking at cloud-native platforms and how they can speed application delivery.
The Pure Storage and Dimensional Research survey, “The Voice of Kubernetes Experts Report 2024: The Data Trends Driving the Future of the Enterprise,” explores the top priorities and trends in the cloud-native landscape, including modern virtualization, cloud-native database and AI/ML adoption using Kubernetes, and the rise of platform engineering.
The report questioned 530 “mature and advanced” platform leaders with more than four years of experience directly managing data services in a Kubernetes environment.
Over the next five years, 80 percent of respondents expect all or most of their new applications would be built with cloud-native platforms. For their cloud-native technology, they prefer the flexibility of deploying in hybrid cloud environments, with 86 percent confirming they run their technology across both public and private clouds.
Traditional VM infrastructure is said to be at an “inflection point” with more than half (58 percent) of organizations planning to migrate some of their VM workloads to Kubernetes, and 65 percent planning to migrate VM workloads within the next two years.
Nearly all (98 percent) of respondents run data-intensive workloads on cloud-native platforms with critical apps like databases (72 percent), analytics (67 percent), and AI/ML workloads (54 percent) being built on Kubernetes. And 96 percent said they already have platform engineering teams to increase the scalability and flexibility of their apps. Executives have shown willingness to invest in training (63 percent), consultants (60 percent), and hiring skilled engineers (52 percent) to support this function.
“The rise of cloud-native platforms marks a fundamental shift in how businesses conceptualize, develop, and deploy applications at scale,” says the report. “Recognizing the benefits, organizations are migrating their VMs to cloud-native platforms to drive enhanced scalability, flexibility, and operational simplicity – all while reducing overall costs.”
“While migrating VM-based applications to Kubernetes remains challenging, robust data services and container platforms are making it possible, enabling accelerated development, seamless management, automation, and optimized IT infrastructure,” added Archana Venkatraman, senior research director, cloud data management, at analyst house IDC.
Cirata has released Data Migrator 2.5, which now includes native integration with the Databricks Unity Catalog. Expanding the Cirata and Databricks partnership, the new integration centralizes data governance and access control capabilities to “enable faster data operations” and “accelerated” time-to-business-value for enterprises.
Databricks Unity Catalog provides a unified governance layer for data and AI within the Databricks Data Intelligence Platform. Using Unity Catalog enables organizations to govern their structured and unstructured data, machine learning modules, notebooks, dashboards, and files on any cloud or platform.
By integrating with Unity Catalog, Cirata Data Migrator helps run analytics jobs as soon as possible or to modernize data in the cloud. It supports Unity Catalog’s functionality for stronger data operations, access control, accessibility, and search. It automates large-scale transfer of data and metadata from existing data lakes to cloud storage and database targets, even while changes are being made by the application at the source.
With Data Migrator 2.5, users can now select the Databricks agent and define the use of Unity Catalog with Databricks SQL Warehouse. This helps data science and engineering teams maximize the value of their entire data estate while benefiting from their choice of metadata technology in Databricks, said the pair.
“As a long-standing partner, Cirata has helped many customers in their legacy Hadoop to Databricks migrations,” said Siva Abbaraju, go-to-market leader, migrations, Databricks. “Now, the seamless integration of Cirata Data Migrator with Unity Catalog enables enterprises to capitalize on our data and AI capabilities to drive productivity and accelerate their business value.”
Paul Scott-Murphy, chief technology officer at Cirata, added: “By unlocking a critical benefit for our customers, we are furthering the adoption of data analytics, AI and ML, and empowering data teams to drive more meaningful data insights and outcomes.”
Cirata Data Migrator 2.5 with native integration with Databricks Unity Catalog is available now.
Cirata, the successor to crashed WANdisco, reported decreased revenues and increased losses for 2023. Sales fell 30 percent year-on-year to $6.7 million, and the pre-tax loss increased to $36.5 million, from the $29.6 million seen 2022.
Last week, Databricks moved to acquire data management software player Tabular for over $1 billion.
Graph database and analytics player Neo4j has integrated its product within the Snowflake AI Data Cloud.
A graph database is a systematic collection of data that emphasizes the relationships between different data entities. It stores nodes and relationships instead of tables or documents.
By 2025, Gartner has estimated that graph technologies will be used in 80 percent of “data and analytics innovations”, up from 10 percent in 2021.
Neo4j says its graph data science is an analytics and machine learning (ML) solution that identifies and analyzes hidden relationships across billions of data points to improve predictions and discover new insights.
Neo4j says customers include the likes of Nasa, Comcast, Adobe, Cisco and Novartis.
Neo4j graph example
The Snowflake integration enables users to instantly execute more than 65 graph algorithms, eliminating the need to move data out of their Snowflake environment, the company says.
Neo4j’s library of graph algorithms and ML modelling enables customers to answer questions like “what’s important”, “what’s unusual”, and “what’s next,” said the provider. Customers can build knowledge graphs, which capture relationships between entities, ground LLMs (large language models) in facts, and enable LLMs to reason, infer, and retrieve relevant information more accurately and effectively, it claimed.
The algorithms can be used to identify anomalies and detect fraud, optimize supply chain routes, unify data records, improve customer service, power recommendation engines, and many other use cases.
The technology potentially allows Snowflake SQL users to get more projects into production faster, accelerate time-to-value, and generate more accurate business insights for better decision-making.
The alliance empowers users to leverage graph capabilities using the SQL programming language, environment, and tooling they already know, said the partners, removing complexity and learning curves for customers seeking insights crucial for AI/ML, predictive analytics, and GenAI applications.
Customers only pay for what they need. Users create ephemeral graph data science environments seamlessly from Snowflake SQL, enabling them to pay only for Snowflake resources utilized during the algorithms’ runtime using Snowflake credits. These temporary environments are designed to match user tasks to specific needs for more efficient resource allocation and lower cost. Graph analysis results also integrate seamlessly within Snowflake, facilitating interaction with other data warehouse tables.
Sudhir Hasbe, chief product officer at Neo4j, added: “Neo4j’s graph analytics combined with Snowflake’s unmatched scalability and performance redefines how customers extract insights from connected data, while meeting users in the SQL interfaces where they are today, for unparalleled insights and decision-making agility.”
The new capabilities are available for preview and early access, with general availability “later this year” on Snowflake Marketplace, the partners said.
Earlier this year, Snowflake reported that GenAI analysis of data in its cloud data warehouses is greatly rising.
Open source data mover Airbyte announced the launch of its Snowflake Cortex connector for Snowflake users who are interested in building generative AI (GenAI) capabilities directly within their existing Snowflake accounts. With no coding required, users can create a dedicated vector store within Snowflake (compatible with OpenAI) and load data from more than 300 sources. Users can create a new Airbyte pipeline in a few minutes. The Airbyte protocol handles incremental processing automatically, ensuring that data is always up to date without manual intervention.
…
Data analyzer Amplitude announced GA of its Snowflake native offering. This allows companies to use Amplitude’s product analytics capabilities without their data ever leaving Snowflake, making it faster and easier to understand what customers are doing, build better products, and drive growth.
…
Data protector Cohesity announced that Cohesity Data Cloud now supports AMD EPYC CPU-powered all-flash and hybrid servers from Dell, HPE, and Lenovo.
…
IDC’s “China Enterprise Solid-State Drive Market Share, 2023” report reveals that DapuStor has secured the fourth position in China’s enterprise SSD market share for 2023 (PCIe/SATA included). DapuStor serves more than 500 customers, spanning telecommunications operators, cloud computing, internet, energy and power, finance, and banking sectors, covering a range of datacenters and intelligent computing centers.
…
Lakehouse supplier Databricks announced new and expanded strategic partnerships for data sharing and collaboration with industry-leading partners, including Acxiom, Atlassian, Epsilon, HealthVerity, LiveRamp, S&P Global, Shutterstock, T-Mobile, Tableau, TetraScience, and The Trade Desk. Data sharing has become critically important in the digital economy as enterprises need to easily and securely exchange data and AI assets. Collaboration on the Databricks Data Intelligence Platform is powered by Delta Sharing, an open, flexible, and secure approach for sharing live data to any recipient across clouds, platforms, and regions.
…
AI development pipeline software supplier Dataloop announced its integration with Nvidia NIM inference microservices. Users can deploy custom NIM microservices right into a pipeline up to 100 times faster with a single click, integrating them smoothly into any AI solution and workflow. Common use cases for this integration include retrieval-augmented generation (RAG), large language model (LLM) fine-tuning, chatbots, reinforcement learning from human feedback (RLHF) workflows, and more.
…
Data mover Fivetran announced an expanded partnership with Snowflake, including Iceberg Table Support and a commitment to build Native Connectors for Snowflake. Fivetran’s support of Iceberg Tables provides Snowflake customers the ability to create a lakehouse architecture with Apache Iceberg, all within the Snowflake AI Data Cloud. Fivetran will build its connectors using Snowflake’s Snowpark Container Services and they will be publicly available in the Snowflake Marketplace.
…
Data orchestrator Hammerspace said its Global Data Platform can be used to process, store, and orchestrate data in edge compute environments and the Gryf, a suitcase-sized AI supercomputer co-designed by SourceCode and GigaIO. Gryf + Hammerspace is highly relevant for use cases such as capturing large map sets and other types of geospatial data in tactical edge environments for satellite ground stations and natural disaster response. It is an effective way to transport large amounts of data quickly.
Hammerspace says it can run on a single Gryf appliance alongside other software packages like Cyber, geospatial, and Kubernetes containerized applications, and other AI analytic packages. Its standards-based parallel file system architecture combines extreme parallel processing speed with the simplicity of NFS, making it ideal for ingesting and processing the large amounts of unstructured data generated by sensors, drones, satellites, cameras, and other devices at the edge. The full benefit of Hammerspace is unlocked when multiple Gryf appliances are deployed across a distributed edge environment so that Hammerspace can join multiple locations together into a single Global Data Platform.
…
Streaming data lake company Hydrolix has launched a Splunk connector that users can deploy to ingest data into Hydrolix while retaining query tooling in Splunk. “Splunk users love its exceptional tooling and UI. It also has a reputation for its hefty price tag, especially at scale,” said David Sztykman, vice president of product management at Hydrolix. “With the average volume of log data generated by enterprises growing by 500 percent over the past three years, many enterprises were until now faced with a dilemma: they can pay a growing portion of their cloud budget in order to retain data, or they can throw away the data along with the insights it contains. Our Splunk integration eliminates this dilemma. Users can keep their Splunk clusters and continue to use their familiar dashboards and features, while sending their most valuable log data to Hydrolix. It’s simple: ingesting data into Hydrolix and querying it in Splunk. Everybody wins.” Read more about the Hydrolix Splunk implementation and check out the docs.
…
IBM has provided updated Storage Scale 6000 performance numbers: 310 GBps read bandwidth and 155 GBps write bandwidth. It tells us that Storage Scale abstraction capabilities, powered by Active File Management (AFM), can virtualize one or more storage environments into a single namespace. This system can effectively integrate unstructured data, existing dispersed storage silos, and deliver data when and where it is needed, transparent to the workload. This common namespace spans across isolated data silos in legacy third-party data stores. It provides transparent access to all data regardless of silos with scale-out POSIX access and supports multiple data access protocols such as POSIX (IBM Storage Scale client), NFS, SMB, HDFS, and Object.
AFM also serves as a caching layer that can deliver higher performance access to data deployed as a high-performance tier on top of less performant storage tiers. AFM can connect to on-prem, cloud, and edge storage deployments. A Storage Scale file system with AFM provides a consistent cache that provides a single source of truth with no stale data copies supporting multiple use cases.
…
Enterprise cloud data management supplier Informatica announced Native SQL ELT support for Snowflake Cortex AI Functions, the launch of Enterprise Data Integrator (EDI), and Cloud Data Access Management (CDAM) for Snowflake. These new offerings on the Snowflake AI Data Cloud will enable organizations to develop GenAI applications, streamline data integration, and provide centralized, policy-based access management, simplifying data governance and ensuring control over data usage.
…
Kioxia Europe announced that its PCIe 5.0 NVMe SSDs have been successfully tested for compatibility and interoperability with Xinnor RAID software and demonstrated up to 25x higher performance in data degraded mode running PostgreSQL than software RAID solutions with the same hardware configuration. This setup is being demonstrated in the Kioxia booth at Computex Taipei.
…
Micron makes GDDR6 memory that pumps out data at 616 GBps of bandwidth to a GPU. Its GDDR7 product, sampling in this month, delivers 32 Gbps of high-performance memory, and has over 1.5 TBps of system bandwidth, which is up to 60 percent higher than GDDR6, and four independent channels to optimize workloads. GDDR7 also provides a greater than 50 percent power efficiency improvement compared to GDDR6 to improve thermals and battery life, while the new sleep mode reduces standby power by up to 70 percent.
…
Wedbush analyst Matt Bryson tells subscribers: “According to DigiTimes, Nvidia’s upcoming Rubin platform (2026) will feature gen6 HBM4, with Micron holding a competitive edge in orders into Rubin due to core features such as capacity and transmission speed (expected to be competitive with South Korean products) and US status/support. Currently, SK Hynix and Samsung are also heavily investing in HBM4.”
…
Mirantis announced a collaboration with Pure Storage, enabling customers to use Mirantis Kubernetes Engine (MKE) with Pure’s Portworx container data management platform to automate, protect, and unify modern data and applications at enterprise scale – reducing deployment time by up to 50 percent. The combination of Portworx Enterprise and MKE makes it possible for customers to deploy and manage stateful containerized applications, with the option of deploying Portworx Data Services for a fully automated database-as-a-service. MKE runs on bare metal and on-premises private clouds, as well as AWS, Azure, and Google public clouds. With the Portworx integration, containerized applications can be migrated between different MKE clusters, or between different infrastructure providers and the data storage can also move without compromising integrity.
…
MSP data protector N-able has expanded Cove Data Protection disaster recovery flexibility by introducing Standby Image to VMware ESXi. The Standby Image recovery feature also includes support for Hyper-V and Microsoft Azure, providing MSPs and IT professionals with better Disaster Recovery as a Service (DRaaS) for their end users. Standby Image is Cove’s virtualized backup and disaster recovery (BDR) capability. It works by automatically creating, storing, and maintaining an up-to-date copy of protected data and system state in a bootable virtual machine format with each backup. These images can be stored in Hyper-V, Microsoft Azure, and now also in VMware ESXi.
…
AI storage supplier PEAK:AIO has launched PEAK:ARCHIVE, a 1.4 PB per 2U all-Solidigm QLC flash, AI storage, archive, and compliance offering, with plans to double capacity in 2025. It integrates with the PEAK:AIO Data Server with automated archive, eliminating the need for additional backup servers or software. The administrator, at the click of a button, can present immutable archived data for review and instant readability without any need to restore. Learn more here.
…
William Blair analyst Jason Ader talked to Pure Storage CTO Rob Lee and tells subscribers Lee “highlighted the company’s opportunity to replace mainstream disk storage across hyperscaler datacenters, noting that it has moved into the co-design/co-engineering phase of discussions. … management spoke to three primary factors that have tipped its discussions with the largest hyperscalers, including the company’s ability to reduce TCO (power, space, cooling, and maintenance) thanks to its higher-performance AFAs, improve the reliability and longevity of hyperscalers’ storage, and decrease power consumption within data centers as power constraints become more evident in the face of AI-related activity and GPU cluster buildouts. Given these technical advantages, Pure confirmed that it still expects a hyperscaler design win by the end of this fiscal year.”
…
Seagate announced the expansion of Lyve Cloud S3-compatible object storage as a service with a second datacenter in London. It will support growing local customer needs allowing easy access to Lyve Cloud and a portfolio of edge-to-cloud solutions, including secure mass data transfer and cloud import services. Seagate has also broadened its UK Lyve Cloud channel. This is through a new distribution agreement with Climb Channel Solutions as well as a long-term collaboration with Exertis, offering a full range of advanced cloud and on-prem storage offerings.
…
SnapLogic announced new connectivity and support for Snowflake vector data types, Snowflake Cortex, and Streamlit to help companies modernize their businesses and accelerate the creation of GenAI applications. Customers can leverage SnapLogic’s ability to integrate business critical information into Snowflake’s high-performance cloud-based data warehouse to build and deploy large language model (LLM) applications at scale in hours instead of days.
…
Justin Borgman, co-founder and CEO at Starburst, tells us: “As the dust starts to settle around the Tabular and Databricks news, a lot of us are left wondering what this means for the future of Apache Iceberg. As someone who has been a part of the data ecosystem for two decades, I think it is important to remember three things:
Iceberg is a community-driven project. Top committers span from a range of companies including Apple, AWS, Alibaba and Netflix. This is in stark contrast to Delta Lake, which is effectively an open sourced Databricks project. Iceberg is not Tabular, and Tabular is not Iceberg.
The next race will be won at the engine-layer. We see Trino – and Icehouse –as the winner. Iceberg was built at Netflix to be queried by Trino. The largest organizations in the world use Trino and Iceberg together as the bedrock for analytics. There’s a reason some of the biggest Iceberg users like Netflix, Pinterest, and Apple all talked about the Trino Icehouse at the Apache Iceberg Summit just three weeks ago.
It will take time. Moving from legacy formats to Apache Iceberg is not an overnight switch and has the potential to become as much of a pipe dream as ‘data centralization’ has been. The community needs platforms that will support their entire data architecture, not just a singular format. We originally founded Starburst 7 years ago to serve this mission when the battle was between Hadoop and Teradata, and the challenges are just as real today.”
…
Enterprise data manager Syniti announced that Caldic, a global distribution solutions provider for the life and material science markets, will use Syniti’s Knowledge Platform (SKP) to help improve its data quality and build a global master data management (MDM) platform for active data governance. This will allow Caldic to work with clean data, now and in the future.
…
Synology announced new ActiveProtect appliances, a purpose-built data protection lineup that combines centralized management with a scalable architecture. ActiveProtect centralizes organization-wide data protection policies, tasks, and appliances to offer a unified management and control plane. Comprehensive coverage for endpoints, servers, hypervisors, storage systems, databases, and Microsoft 365 and Google Workspace services dramatically reduce IT blind spots and the necessity of operating multiple data protection solutions. IT teams can quickly deploy ActiveProtect appliances in minutes and create comprehensive data protection plans via global policies using a centralized console. Each ActiveProtect appliance can operate in standalone or cluster-managed modes. Storage capacity can be tiered with Synology NAS/SAN storage solutions, C2 Object Storage, and other ActiveProtect appliances in the cluster. The appliances leverage incremental backups with source-side, global, and cross-site deduplication to ensure fast backups and replication with minimal bandwidth usage. ActiveProtect will be available through Synology distributors and partners later in 2024. Check it out here.
Synology ActiveProtect appliances
…
Veeam announced the introduction of Lenovo TruScale Backup with Veeam, a cloud-like experience on-premises that helps secure workloads regardless of their location and enables customers to scale infrastructure up or down as needed. TruScale Backup with Veeam combines Lenovo ThinkSystem servers and storage, Veeam Backup & Replication, Veeam ONE, and Lenovo TruScale services to provide data protection as a service for a hassle-free on-premises or co-located deployment. TruScale Backup with Veeam is available now.
…
Veeam announced its Backup & Replication product will be available on Linux and could be available in the first half of 2025.
…
Archival software supplier Versity announced the GA release of Versity S3 Gateway, an open source S3 translation tool for inline translation between AWS S3 object commands and file-based storage systems. Download a white paper about it here.
…
Re new Western DigitalSSDs and HDD, Wedbush analyst Matt Bryson says: “We have validated that WDC is working with FADU on some new SSD products and would not be surprised if that controller vendor is supporting one or both of the new SSDs. … On the HDD front, we expect the new drives will likely include an 11th platter. We believe WDC has a near- to intermediate- term advantage around areal density (as STX works through the go-to production problems with HAMR that have led management to suggest an initial hyperscale qualification might have to wait until CQ3).”
Storage and backup cloud provider Backblaze has taken the wraps off Backblaze B2 Live Read, giving customers the ability to access, edit, and transform content while it’s still being uploaded into its B2 Cloud Storage.
The service is particularly useful for media production teams working on live events, and promises “significantly faster and more efficient workflows,” and the ability to offer new monetized content quicker.
The patent-pending technology has already been adopted by media and entertainment (M&E) production solution providers, including Telestream, Glookast, and Mimir, who are integrating the service into their production environments.
“For our customers, turnaround time is essential, and Live Read promises to speed up workflows and operations for producers across the industry,” said Richard Andes, VP, product management at Telestream. “We will offer this innovative feature to boost performance and accelerate our customers’ business engagements.”
The technology can be used to create “near real-time” highlight clips for broadcasters’ news segments and sports teams’ in app replays, and can be used to promote content for on-demand sales “within minutes” of presentations at live events. On-set staff requirements can also potentially be reduced through the offering too, said Backblaze.
Live Read supports accessing parts of each growing object or growing file as it uploads, so there’s no need to wait for the full file upload to complete. This is a “major” workflow accelerator, especially when organizations are shooting for 4K to 8K resolutions and beyond, Backblaze says. When the full upload is complete, it’s accessible to customers like any other file or object in their Backblaze B2 Cloud Storage bucket, with no middleware or proprietary software needed.
“Backblaze’s Live Read is a game changer for helping organizations deliver media to their audiences dramatically faster,” said Steinar Søreide, CTO at Mimir. “Adding this offering to our platform unlocks a whole new level of impact for our user community.”
Beyond media, the Live Read API supports other demanding IT workloads. For instance, organizations maintaining large data logs or surveillance footage backups have often had to parse them into hundreds or thousands of small files each day, in order to have quick access when needed. With Live Read, said Backblaze, they can now move to far more manageable single files per day or hour, while preserving the ability to access parts “within seconds” of them having been written.
Gleb Budman
“Live Read is another example of the powerful innovation we’re delivering to support our customers and partners to do more with their data,” said Gleb Budman, Backblaze CEO.
Live Read is available in private preview now, with general availability planned “later this year”, said Backblaze
Earlier this year, Backblaze added Event Notification data change alerts to its cloud storage, so that events can be dealt with faster by triggering automated workflows.
For the year ended December 31, 2023, Backblaze revenues were $102 million, 20 percent higher than the previous year. It reported $58.9 million net loss, down from the $71.7 million net loss in 2022.
Pure Storage has taken a stake in visual AI provider LandingAI. The flash storage specialist says the investment in LandingAI’s multi-modal Large Vision Model (LVM) solutions will “help shape the future” of vision AI for the enterprise customers it serves.
Pure Storage reckons the move will reinforce its AI strategy to help customers with their training environments, enterprise inference engine or RAG environments, and upgrade all enterprise storage to enable “easier data access for AI.”
Andrew Ng
LandingAI was founded by CEO Andrew Ng in 2017 and has raised $57 million. He was co-founder of online course provider Coursera, and was founding lead of Google Brain. The Google Brain project developed massive-scale deep learning algorithms. Ng was also previously chief scientist at Chinese search engine Baidu.
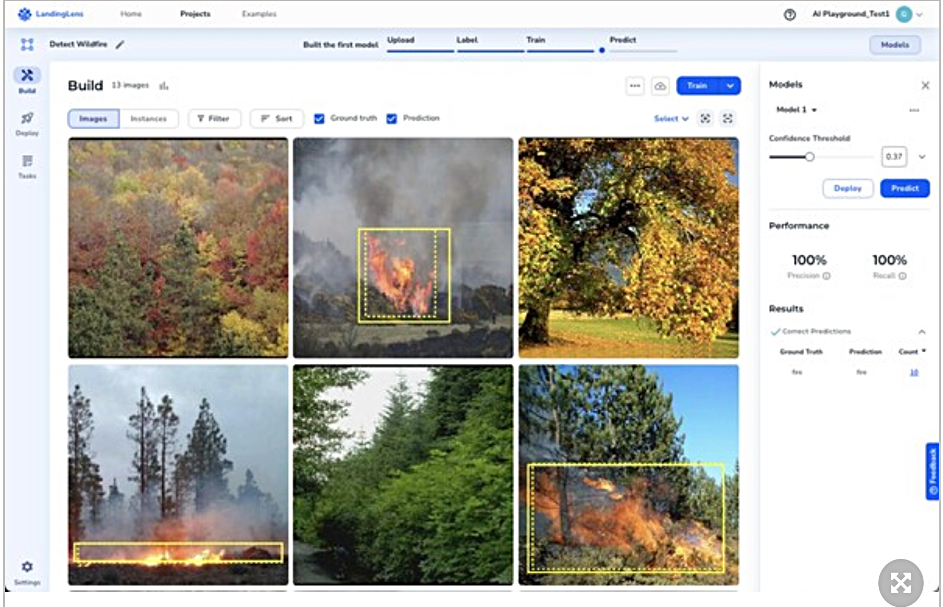
LandingAI’s flagship product, LandingLens, is a computer vision cloud platform designed to enable users to build, iterate, and deploy computer vision solutions “quickly and easily.”
With data quality key to the success of production AI systems, LandingLens promises users “optimal data accuracy and consistency.”
LandingAI bills itself as a “pioneer” in the field of domain-specific LVMs, which enhance the ability to process and understand visual data at scale. This makes sophisticated visual AI tools more accessible and efficient, we’re told.
LandingLens computer vision project. We could envisage a visual LLM being trained to detect forest fires using a stream of forest images from video cameras located in and around a forest
“Enterprises will need solutions to apply generative AI to their data, which will increasingly consist of not just text, but richer image and video data as well,” said Ng. “We are partnering with Pure Storage to meet this customer need.”
Rob Lee
Rob Lee, CTO at Pure Storage, added: “Our strategic partnership with the LandingAI team, including its pioneering leaders Andrew Ng and Dan Maloney, will lead to significant AI/ML advancements for our customers.”
The value of Pure’s LandingAI investment has not been publicly disclosed. Existing investors in LandingAI include Intel, Samsung, Insight Partners, and McRock Capital among others.
Last week, Pure reported an improved first quarter. Sales increased 20 percent year-on-year to $693.5 million for the period ended May 5. The quarterly loss was $35 million, an improvement on the $67.4 million lost a year ago.
Western Digital has defined a six-stage AI data cycle and introduced two new SSDs and a disk drive to match them.
Update. SN861 Flexible Data Placement (FDP) section added. 2 July 2024
The AI data cycle stages are (1) archives of raw data content, (2) data prep and ingest, (3) AI model training, (4) interface and prompting, (5) AI inference engine, and (6) new content generation. Stage 1 needs high-capacity disk drives. Stage 2 needs high-capacity SSDs for data lake operations. Stages 3, 4, and 5 need the same high-capacity SSDs plus high-performance compute SSDs for model training run checkpointing and caching. Stage 6 brings us back to needing high-capacity disk drives.
Rob Soderbery
Rob Soderbery, EVP and GM of Western Digital’s Flash Business Unit, said: “Data is the fuel of AI. As AI technologies become embedded across virtually every industry sector, storage has become an increasingly important and dynamic component of the AI technology stack. The new AI Data Cycle framework will equip our customers to build a storage infrastructure that impacts the performance, scalability, and the deployment of AI applications.”
Western Digital is introducing three new Ultrastar-brand storage drives:
DC SN861 SSD for fast checkpointing and caching
DC SN655 SSD for the high-capacity SSD requirement
DC HC690 HDD for the storage of raw and new content data
DC SN861 SSD
This is Western Digital’s first PCIe gen 5 SSD and suited for AI training model run checkpointing. It introduced its PCIe gen 4 SN850 drive back in 2020, but this was an M.2-format drive with limited capacity: 500 GB, 1 and 2 TB. It also had an SN840 PCIe gen 3 drive in the U.2 (2.5-inch) format with 1.6 TB to 15.36 TB capacity range in 2020.
The SN861 comes in the E1.S, E3.S, and U.2 formats with up to 16 TB capacity. E1.S is like a larger version of the M.2 gumstick format. Western Digital claims the SN861 “delivers up to 3x random read performance increase versus the previous generation with ultra-low latency and incredible responsiveness for large language model (LLM) training, inferencing and AI service deployment.”
Details are slim. We don’t know the type of NAND used, but understand it to be TLC. Nor do we know the 3D NAND generation and layer count. It’s probably BiCS 6 with 162 layers but could be the newer BiCS 8 with 218 layers.
It will come in 1 and 3 drive writes per day (DWPD) variants with a five-year warranty, and supports NVMe 2.0 and OCP 2.0. The E1.S version is sampling now. The U.2 model will be sampling in July with volume shipments set for the third quarter. There is no information about the E3.S version’s availability or the E1.S volume shipment date.
WD says the Ultrastar DC SN861 E1.S version supports Flexible Data Placement (FDP). This “allows the placement of different data in separate NAND blocks within an SSD. In a conventional SSD all data written to the drive at a similar time will be stored in the same NAND blocks. When any of that data is either invalidated by a new write or unmapped then the flash translation layer (FTL) needs to do garbage collection (GC) in order to recover physical space. In a data placement SSD data can be separated during host writes allowing for whole NAND blocks to be invalidated or unmapped at once by the host.”
DC SN655 SSD
This is a high-capacity SSD. The existing PCIe gen 4-connected DC SN655 SSD with its 15.36 TB max capacity has been expanded more than fourfold to support up to 64 TB using TLC NAND in a U.3 format. The U.3 format is equivalent to U.2 in physical size and a U.3 chassis bay supports SAS, SATA, and NVMe interfaces in the same slot.
SN655 variants are sampling now and volume shipments will start later this year, with more drive details being released then.
DC HC690 disk drive
Western Digital has tweaked its DC HC680 SMR tech to lift its capacity from 28 to 32 TB. There are few details available at present and our understanding is that this is a ten-platter drive – it might be 11 – using shingled magnetic media (SMR – partially overlapping write tracks) with OptiNAND energy-assisted PMR (ePMR), and triple-stage actuator (TSA) in a helium-filled enclosure. There is an ArmorCache write cache data safety feature.
Competitor Seagate announced 30 TB conventional Exos HAMR drives in January with a 32 TB SMR HAMR drive now available as well. Western Digital has caught up to that capacity point using microwave-assisted magnetic recording (MAMR). Toshiba demonstrated a 32 TB shingled HAMR drive and a 31 TB 11-platter MAMR drive last month. Now all three HDD manufacturers are at the 32 TB SMR drive level.
SPONSORED FEATURE: It’s easy to see why running enterprise applications in the cloud seems like a no-brainer for chief information officers (CIOs) and other C-suite executives.
Apart from the prospect of unlimited resources and platforms with predictable costs, cloud providers offer managed services for key infrastructure and applications that promise to make the lives of specific tech teams much, much easier.
When it comes to databases, for example, the burden and costs involved in deploying or creating database copies and in performing other day-to-day tasks just melt away. The organization is always working with the most up-to-date version of its chosen applications. Cloud providers may offer a variety of nontraditional database services, such as in-memory, document, or time-series options, which can help the organization squeeze the maximum value out of its data. That’s the headline version anyway.
Database administrators (DBAs) know that the reality of running a complex database infrastructure in the cloud and maintaining and evolving it into the future isn’t so straightforward.
Consider how an enterprise’s database stack will have evolved over many years, even decades, whether on-premises or in the cloud. DBAs will have carefully curated and tailored both the software and the underlying hardware, whether regionally or globally, to deliver the optimal balance of performance, cost, and resilience.
That painstaking approach to hardware doesn’t encompass only compute. It applies just as much to storage and networking infrastructure. International Data Corporation (IDC) research shows that organizations spent $6.4 billion on compute and storage infrastructure to support structured databases and data management workloads in the first half of 2023 alone, constituting the biggest single slice of enterprise information technology (IT) infrastructure spending.
As for the database itself, it’s not just a question of using the latest and greatest version of a given package. DBAs know it’s a question of using the right version for their organization’s needs, in terms of both cost and performance.
That’s why DBAs may worry that a managed service won’t offer this degree of control. It might not support the specific license or version that a company may want to put at the heart of its stack. Moreover, some DBAs might think that the underlying infrastructure powering a cloud provider’s managed database is a black box, with little or no opportunity to tune the configuration for optimal performance with their preferred software.
Many database teams – whether they’re scaling up an existing cloud database project or migrating off-prem – might decide the best option is a self-managed database running on a platform like Amazon Web Services (AWS). This gives them the option to use their preferred database version and their existing licenses. It also means they can replicate their existing infrastructure, up to a point at least, and evolve it at their own pace. All while still benefiting from the breadth of other resources that a provider like AWS can put at their disposal, including storage services like Amazon FSx for NetApp ONTAP.
Costs and control
Though the self-managed approach offers far more flexibility than a managed service, it also presents its own challenges.
As NetApp Product Evangelist, Semion Mazor explains, performance depends on many factors: “It’s storage itself, the compute instances, the networking and bandwidth throughput, or of all that together. So, this is the first challenge.” To ensure low latency from the database to the application, DBAs must consider all these factors.
DBAs still need to consider resilience and security issues in the cloud. Potential threats range from physical failures of individual components or services to an entire Region going down, plus the constant threat of cyberattacks. DBAs always focus on making sure data remains accessible so that the database is running, which means the business’ applications are running.
These challenges are complicated and are multiplied by the sheer number of environments DBAs need to account for. Production is a given, but development teams might also need discrete environments for quality assurance (QA), testing, script production, and more. Creating and maintaining those environments are complex tasks in themselves, and they all need data.
Other considerations include the cost and time investment in replicating a full set of data and the cost of the underlying instances that are powering the workloads, not to mention the cost of the storage itself.
That’s where Amazon FSx for NetApp ONTAP comes in. FSx for ONTAP is an expert storage service for many workloads on AWS. It enables DBAs to meet the performance, resilience, and accessibility needs of business-critical workloads, with a comprehensive and flexible set of storage features.
As Mazor explains, it uses the same underlying technology that has been developed over 30 years, which underpins the on-prem NetApp products and services used in the largest enterprises in the world.
The data reduction capabilities in FSx for ONTAP can deliver storage savings of 65 to 70 percent, according to AWS. Mazor says that even if DBAs can’t quite achieve this scale of compression, scaled up over the vast number of environments many enterprises need to run, the benefit becomes huge.
Another crucial feature is the NetApp ONTAP Snapshot capability, which allows the creation of point-in-time, read-only copies of volumes that consume minimal physical storage. Thin provisioning, meanwhile, allocates storage dynamically, further increasing the efficient use of storage – and potentially reducing the amount of storage that organizations must pay for.
Clones and cores
One of the biggest benefits, says Mazor, comes from the thin cloning capability of NetApp ONTAP technology. Mazor says that it gives DBAs the option to “create new database environments and refresh the database instantly with near zero cost.” These copies are fully writable, Mazor explains, meaning that the clone “acts as the full data, so you can do everything with it.”
This capability saves time in spinning up new development environments, which in turn speeds up deployment and cuts time to market. Mazor notes that, from a data point of view, “Those thin clone environments require almost zero capacity, which means almost no additional costs.”
Moving these technologies to the storage layer, rather than to the database layer, contributes to more efficient disaster recovery and backup capabilities. Amazon FSx for NetApp ONTAP also provides built-in cross-region replication and synchronization, giving DBAs another way to meet strict recovery time objective (RTO) and recovery point objective (RPO) targets.
These data reduction, snapshot creation, thin provisioning, thin cloning, and cross-region replication and synchronization features all help DBAs to decouple storage – and, crucially, storage costs – from the Amazon Elastic Compute Cloud (EC2) instances needed to run database workloads. So, storage can be scaled up or down independently of the central processing unit (CPU) capacity required for a given workload.
With fewer compute cores needed, costs and performance can be managed in a much more fine-grained way. DBAs can reduce the need for additional database licenses by optimizing the number of cores required for database workloads and environments. Of course, going the self-managed route means that enterprises can use their existing licenses.
This comprehensive set of capabilities means DBAs can more accurately match their cloud database infrastructure to real workload needs. It also means the cost of running databases in AWS can be further controlled and optimized. It can all add up to a significant reduction in total storage costs, with some customers already seeing savings of 50 percent, according to AWS.
The decision to operate in the cloud is usually a strategic, C-level one. But DBAs can take command of their off-premises database infrastructure and gain maximum control over its configuration, cost, and performance by using Amazon FSx for NetApp ONTAP.