Object First, the Veeam-only backup target startup, has announced a smaller Ootbi Mini model and added a malware-attracting Honeypot feature plus central fleet management for all of a customer’s Ootbi appliances.
The company was established in 2022 by Veeam founders Ratmir Timashev and Andrei Baronov to provide an S3-based Ootbi (Out-of-the-Box Immutability) backup appliance. It launched in February 2023, offering immutable object storage in a four-way clustered and non-deduplicating appliance. By the start of 2025, there were three-node raw capacity options – 64 TB, 128 TB and 192 TB – with an NVMe SSD landing zone and disk drives for actual retention. It also offers on-prem to public cloud data copies and perpetual license/capex or subscription business models and there is a top-end 432 TB model with up to 8 GB/s performance.
Ootbi Mini has the same ransomware-proof data protection, intuitive user interface and simple Veeam integration as the existing Ootbi Appliances. Ootbi says the Mini has “absolute immutability, which means no one, not even an admin, can alter the firmware, operating system, storage layer, or backup data.”
David Bennett
Object First CEO David Bennett said: “With the launch of Ootbi Mini, any organization in any location can have enterprise-grade immutability within a small footprint. Our new Honeypot feature takes cyber resilience a step further by giving IT teams early warning of cyberthreats, while Fleet Manager will simplify how customers can monitor and manage their Ootbi deployments.”
The Ootbi Mini is designed for ROBO (remote and branch offices), edge locations, and small businesses. It comes in a desktop tower form factor, is available in 8, 16, and 24 TB capacities, and can be clustered with other Ootbi Mini appliances. It has a three-disk mirrored array inside, tolerating up to two disk failures without data loss. The component details are:
• Maximum Nodes Per Cluster: 4 • Disk Arrangement o Primary Array: 3 x 8 | 16 | 24 TB SATA HDD (Mirror Raid) o Cache Disks: 480 GB SATA, SSD • Dedicated OS Disks: 256 GB M.2 NVMe (SSD) • Network Interface: Dual Port 10G SFP+ or Intel AMT port 2.5 Gb RJ-45 and GbE RJ-45 • Management: 2.5 Gb RJ-45 (Intel AMT) • Power o Total Output Power: 350 W Gold Level power supply o Power Cables: Region-specific power cables included
The Object First Honeypot feature debuts with version 1.7 of its software. A user can deploy a decoy VBR (Veeam Backup & Replication) environment in the box with two mouse clicks. It runs on a securely segmented part of Ootbi and acts as a tripwire. If suspicious activity is detected, the Honeypot software sends alerts through the customer’s preferred channel.
Ootbi Fleet Manager is a cloud-based application enabling customers to monitor their Ootbi fleet from a single dashboard. It provides customized organization of clusters, with granular monitoring and reporting for Ootbi devices within them. Users can view their Ootbi footprint and obtain hardware health and utilization data.
Ootbi Mini is available as either a CapEx purchase or a consumption-based subscription. It can be ordered now, with deliveries beginning in January 2026. Ootbi Fleet Manager is available as a beta software program here. Honeypot is available at no cost to current Ootbi customers using v1.7 Ootbi software.
SK hynix’s announcement of its 321-layer 3D NAND in QLC format has raised questions about Solidigm’s role in the organization.
Solidigm was a pioneer in high-capacity SSDs for enterprise use with its 61.44 TB QLC drive in July 2023 and a 122 TB drive in November 2024, both of which used 192-layer QLC 3D NAND. This NAND technology was introduced in mid-2022. Since then, other NAND suppliers have surpassed 200 layers, leaving Solidigm lagging. SK hynix introduced 238 layers in mid-2023 and is now talking about 321-layer product and ultra-high-capacity SSDs following Sandisk and Kioxia 256 TB SSD announcements.
This raises several questions:
What is the role of Solidigm in the SK hynix organization if SK hynix now leads with ultra-high-capacity SSDs?
Will Solidigm enter the 200-plus and even the 300-plus layer count area?
Will Solidigm adopt SK hynix NAND technology or continue to develop its own technology?
Is PLC flash a dead end or will we see product arrive?
How will Solidigm cope with its fabs in Dalian, China, being in the wrong geography from US President Donald Trump’s point of view, and attracting tariffs on the product it manufactures?
Blocks & Files spoke to Roger Corell, Solidigm’s senior director of AI and leadership marketing, who indicated that Solidigm is not being sidelined within SK hynix.
Roger Corell
“We are undergoing an AI-fueled business momentum or business growth phase here,” he said. “And we’d like to think that, owing to some efforts from Solidigm, that storage is increasingly a part of that discussion.”
“I think if we just went back maybe two years ago or so, or maybe even more recently, storage really wasn’t part of that discussion. And now that we’re in this era of every watt, every square inch counting, maximizing your critical investments in GPUs, maximizing your GPU utilization, is essential, that storage is… increasingly part of the conversation on what does it take to efficiently scale critical AI infrastructure.”
“We are in the era where every watt and every square inch counts. Somebody might get approval for a 500 megawatt datacenter, which sounds great, but boy, they’re going to want to maximize, optimize their investment within their power and space budget. And as we get into this exabyte-class era, the storage impact on this every watt and every square inch matters moment becomes even more important in terms of optimizing your critical resources. And then I think the last thing is, so we talked about one thing, exabyte class storage, every watt and square inch counts. And I think the third area is, and we’ve alluded to this, is don’t have storage be the bottleneck, right? You’ve got to maximize your compute investments optimization. So if you look at these factors, if you will, on why we think storage is meeting this AI moment and then we reflect back on Solidigm’s portfolio, we think we’re really, really well positioned.”
He said Solidigm has “deep industry engagements across multiple segments, we have design wins, we have AI design wins with fastest growing neo-clouds, hyperscalers leading storage, OEMs leading storage box providers. As you know, we are validated with being on the Nvidia RVL list where their latest E1.S product for direct attached storage. So we think that… our portfolio is meeting this AI storage moment.”
Blocks & Files: From my perspective, I’m seeing Solidigm having a layer count for its SSDs that is lagging behind SK hynix. So my understanding is you are on 192 layers at the moment and SK hynix is on 238 with 321 being developed.
Roger Corell: I think there’s multiple angles I want to approach that from. Layer count is important and, yes, you’re absolutely right. We are at 192. We are working on developing our next generation now, which will push us beyond 2XX.
It’s so much more than layer count, OK? It’s layer count, it’s bits per cell, it is cell size and, as a result of cell size, how densely you can pack those cells. So you can almost think of layer count as vertical scaling. You can think of cell size and the density on packing those cells as linear scaling.
We talked about bits per cell. Let me dive into that a little bit. OK, QLC ain’t easy, right? We are on our fourth generation. We started shipping in 2018, as you know. We have shipped over 120 exabytes. Why don’t you think anybody else has shipped in-volume QLC? Because it’s really, really hard. So we have a lot of experience here.
But then you also get into component integration, component optimization. I’m not going to get into a lot of details here, but we’ve done things to significantly reduce the size of our PLI (Power Loss Imminent) [and] significantly reduce the size of our controller. That frees up more NAND die placement spaces on a given board. And then packaging also factors into it. We have the smallest NAND package in the industry.
When you factor in all the above, that’s why we were first to 61.44. That’s why we’re first to 122.88. That’s why we have strong confidence we’ll be the first to 245. We anticipate shipping 245 by the end of 2026.
We have confidence in where we are now and where we are investing in moving forward in sustaining our high-cap leadership.
Blocks & Files: Will the 245 TB drive use the existing 192 layers?
Roger Corell: No. It will push into the 200-layer count.
Blocks & Files: And will these chips be made in your Dalian fabs?
Roger Corell: Yes, they will.
Blocks & Files: I would understand from what you’ve said that this will be Solidigm technology. You’re not going to be adopting SK hynix technology.
Roger Corell: This will be a yes. This will be on floating gate technology, but as long as you’ve brought up technology, let’s talk about that. As you know, we have two technologies in our portfolio. We have floating gate and we have charge trap, and we believe that that is a critical advantage for Solidigm, a unique technology portfolio advantage. Charge trap is really good at certain things that maybe are best aligned with a category of workloads. And floating gate is really good at certain things that are well aligned with the needs of certain [other] workloads. And it’s this combined technology portfolio access that maps us to why our AI portfolio is meeting the moment.
We’ve got our [charge trap-based] PS1010 for direct-attached storage, which has amazing performance but also leads in terms of cooling efficiency. And then we’ve got the floating gate-enabled high capacity portfolio, again, 61.44, 122 TB shipping, 245 TB by the end of 2026… OK, in terms of AI, you’ve got storage for direct-attached storage (DAS) and you’ve got storage for network-attached storage (NAS). And we believe we have a leadership product in both of these key storage infrastructure areas for AI.
Blocks & Files: Do you think you’ll stick with QLC and that PLC is not going to be realistic for quite a few years?
Roger Corell: Interesting question… We demonstrated a working PLC SSD at FMS in August of 2022, so we think there will be a future for PLC. When? Tough to say, but I think the market is moving in a direction where eventually PLC will have its place in our SSD portfolio. We are evaluating it.
Blocks & Files: Will Solidigm consider bringing out a very high-speed access SSD, like the Kioxia near-storage-class memory FL6?
Roger Corell: We do have an SLC device in the market right now, the P5810. Our company aspiration is we are a strong number two in [the] enterprise SSD business right now. We have aspirations to be number one. We listen to our customers. If our customers are telling us that they need that product, then we’re going to give it a hard look. Yes, it’s a super compelling product and, if we see a need for it, we will look into a strategy to enable it.
Comment
Solidigm will move beyond 192-layer 3D NAND into the 200-plus layer count area, and have a 245 TB-class SSD out by the end of 2026 using its own technology, with the NAND manufactured in Dalian.
Bootnote
SSDs with PLI technology contain energy-storing capacitors that can act as a backup in the event of a power failure. With PLI, SSDs detect a power outage as soon as it occurs and write in-flight data in the NAND to prevent data loss.
Interview: An interview with Pure Storage CEO Charles Giancarlo started by discussing AIOps and its Enterprise Data Cloud’s control plane and finished with the concept of Pure as a dataset management company. It is developing a full stack of dataset management features and function layered on top of its storage arrays and their software.
Charles Giancarlo.
Part one of this interview will take us from AIOPs to the dataset management topic. Part 2 will look at what data set management means.
B&F: Do you remember two or three years ago, maybe four or five years ago even, AIOps was a thing and now it’s not and yet …
Charles Giancarlo: Well, it is and it isn’t.
B&F: That’s where it gets interesting, isn’t it? Because your Enterprise Data Cloud control plane is an example, to me, of AIOps.
Charles Giancarlo: Organizations have to start thinking about things differently. What I’m about to talk about is yet another, let’s say it’s the next iteration of it, that I think is another mind blowing thing overall.
If I could use an analogy, ETL (Extract, Transform, Load) is effectively a batch job. … I’m going to talk about batch, interpretive and compilation as an analogy, okay? We haven’t talked about interpretive software in decades, but you remember. Let’s think about AIOps, to use the old phrase today, ETL chains and so forth. You have to find your data. You then have to determine what is the end structure of the data that it needs to be for your analytics app or your AI app, whatever it is. Then you have to copy your data, replicate it, transform it, set it up in the new architecture, even for Snowflake or whatever. That can take weeks or even months to do all of that. And then it’s ready for processing. Well, that’s a batch job. Anything that takes a lot of time to prepare before you can run it is batch.
B&F: This is not going to happen in real time. This is going to be with background processes going on.
Charles Giancarlo: What can happen in real time are general prompts into a big AI. That’s about language. What can’t happen in real time is enterprises taking their data because it’s not been processed by AI. Think about the training that OpenAI took. It took what? Months? Years. Okay. Well, that’s what has to happen before enterprises can get meaning out of their own data. It may not take years, but it takes weeks or months to prepare it even for inference because they have to get it ready for inference. So think of that as a batch job.
Once we have the AI data cloud, or sorry, once we have the Enterprise Data Cloud in place, first of all, the data is accessible. Now, secondly, is we believe we can put in, I’m going to call it interpretive, meaning that instead of it taking weeks, we believe we can [do it faster] with an AI engine. And because AI, if nothing else, is really good at translation, we can translate it from raw data to the data that you need, to the data in the form that you need to process. So it replaces the T in the ETL chain.
The Data Cloud replaces the E in the ETL chain, and then you still have to process it. So I think of it as interpretive, meaning that, yes, it’s not entirely real time, but now you’re talking about minutes rather than days or weeks.
I think the next step, which is going to be years in the future, is why not tag data as it’s being written now, meaning production data as it’s being written. I understand now. You can’t do that today. You won’t be able to do it tomorrow, and why not? Because companies don’t know what they need. In other words, you can’t tag it with something if you don’t know what the use of the data is. And why are you going to invest in a whole bunch of GPUs when you don’t know what you need. So I think it’s going to start with interpretive and eventually move to that last step, which I would then call compiled because it’s all ready to go.
B&F: I’m going to use a stack analogy here. So this is Pure Storage and this is Dell, and this is VAST, and sitting above them, according to David Flynn [Hammerspace] and Jason Lohrey [Arcitecta], are data managers. These people are saying, we’ll stick a vector database or other databases in our data management systems, and then we can feed data up the AI data pipelines better. And this is something, as far as I understand, you don’t do. Should you?
Charles Giancarlo: That’s the question. And because the issue about data managers that have existed for a very long time, and, … broad level, what’s the best way to put it? It’s ignoring the fact that VAST specifically is designed as a data store to feed AI, so they’re not a production data store at all, right?
Think of the way that data today, data storage today, is structured as being application-specific. So their application-specific is directly to the data management, directly to the AI. But then you’ve got to get the data there from the production environment.
What we are saying, and by the way, okay, so Dell has lots of different production environments. We have a lot of different production environments. The thing that we’re doing that’s different is it’s a single operating system. You got a half dozen there [with Dell]. And then, secondly, by tying it together, so all of our systems now operate as a cloud. Whether you want to go to a data lake or data warehouse or lake house. There’s all kinds of names around this, whether you want to go to that or not. The point is, you can use your production level data as the data feed, the real-time, or almost real-time data feed, rather than having to specifically copy all of your data to yet another data store that’s specifically designed for another specific purpose.
B&F: If a customer comes along to you and says, your stuff is great, but I need a vector database. I’m going to go to Pinecone, or I’m going to go to Weaviate, and that’s the data I’m going to shovel up the AI data pipeline. So your job is to feed Pinecone in this particular regard. Why not bring the vector data base down into Pure’s software environment?
Charles Giancarlo: Well, the real question I think, which is true for any system vendor, is what are the benefits and what are the limitations by putting it, embedding it, within your own environment. So think about Hadoop, right? In some ways, Hadoop was designed so that you can not only have storage, but you would have whatever database you choose embedded within the same environment.
The challenge of course for that is it didn’t have flexibility in terms of compute versus capacity. You basically had equal amounts of compute and capacity that you had to add up. So you were limiting it. The other question is, well, are you cost-burdening your storage with compute that you don’t need or not enough compute that you do need? So is there some inherent technical advantage to combining the two on one processor, or is it the case where having it operate effectively outside the storage system is just as effective? You don’t lose any benefit, but on the other hand it gives you much greater flexibility.
So I guess our view, and I’ll come back to your question because I’m going to answer it in a different way. Our view is; let the database be the database. The customer can buy as much power or as little power as they need. We just want to be able to feed it. Now, there is an area though, where we can add a lot of value, and that is on the metadata side of things, because why can’t we store the additional metadata with the storage metadata?
We have a giant metadata engine. We can add additional metadata to it. Does it really matter? And now the metadata is stored with the data. Does that make sense?
B&F: indeed.
Charles Giancarlo: Okay. So that is a benefit of what we can do that’s unique, right? That doesn’t add, in my view, doesn’t add unnecessary overhead to what we do and keeps the flexibility of how much performance, how much database performance do you need, how much AI performance you need versus how much storage and capacity you need.
B&F: Let me try and attack my point in a slightly different way to see if I can bend you around. Okay. You have workflow operations in your control. So you can have templates for workflows and you can set applications, system applications running inside those workflows?
Charles Giancarlo: Yes, we can.
B&F: So you could orchestrate an AI data pipeline.
Charles Giancarlo: We certainly could. Quite happily, yes. And now with MCP it makes it so much easier.
B&F: So I think we’re in the same place at this point. You won’t necessarily stick a vector database inside Purity, but you will be able to schedule a Pinecone ingest and vectorization operation.
Charles Gancarlo: Yes. Today we demonstrated how now we can schedule a full database app with disaster recovery all based on a set of precepts and our NCPs (Nvidia Cloud Partners) that are operating directly with, for example, any one of the virtualization engines as well as any one of the databases.
B&F: So you’re using workflows at the moment, which are in the storage environment?
Charles Giancarlo: Correct?
B&F: The data protection environment.
Charles Giancarlo: That’s right.
B&F: Which is still storage.
Charles Giancarlo: Yes, it is.
B&F: But you’ve got a general workflow operator, correct?
Charles Giancarlo: Yes.
B&F: You could do whatever you want.
Charles Giancarlo: We can do whatever we want. We’re doing that.
B&F: If you want to schedule compute, you can schedule compute.
Charles Giancarlo: Correct.
B&F: So Pure is no longer necessarily a storage company.
Charles Giancarlo: That’s correct. We’re a workflow company and we will become more of what … right now, we’re going to be a data set management company.
****
Part 2 of this interview will dive into the data set management concept.
We had the opportunity to interview Jason hardy, Hitachi Vantara’s CTO for AI, and the conversation started by looking at VSP One and disaggregation and ended up talking about AI agent-infused robots. Physical AI. Read on to see how we got there.
Blocks and Files: Hitachi Vantara’s VSP One storage line is a classic controllers-integrated-with-storage-shelves architecture, and this contrasts with the disaggregated compute and storage nodes exemplified by VAST Data’s DASE (Disaggregated Shared Everything) architecture. This has been taken up by HPE with its Alletra MP 10000 line, Pure with its FlashBlade//EXA, and NetApp’s AI-focussed ONTAP architecture revision. Is this storage array technology direction of interest to Hitachi Vantara?
Jason Hardy: We are definitely thinking about what those platforms, what VAST has created, even what Pure has done a bit of now.
What that actually means, and how using things like VSP One Block, and how that can benefit from it. What does NVMe over fabric look like for something like that? So utilising what we’re really good at and then innovating forward from there.
“it’s something that when we look at the entire market and what’s trending and what is the demand going to push from an AI perspective from all these highly parallelized workloads is how can we create something of value using our foundation, but then really delivering on what the customers need, especially at scale.’
Blocks and Files: “So it’s conceivable to think of a mid range vs P one block piece of hardware at the moment and thinking of that being separated out into controller nodes and storage nodes?”
Jason Hardy: I actually take it one step further. So what VSP One Block is really good at is providing that block capability. A lot of these, especially looking from an AI workload perspective, they require a file system, the scale-out file system functionality. So from my standpoint, VSP One Block plays a big piece of that, but it’s just one piece of that because of object, and how object is becoming a primary platform, an active contributor to the AI ecosystem.
So how do we bring … that in? And then also looking at how while block plays a core role of it, we still need file system functionality and things like that. On top of it, it turns out most GPU servers don’t have Fibre Channel ports and things like that. So obviously NVMe over TCP is an option for that. But really, when you start looking at multiple compute requirements, then you have the need to share data. And having just one affinity in the traditional sense to a server doesn’t really benefit the pool of resources that customers are purchasing and growing into to support a lot of their AI demands. So from our perspective, block plays a big piece of it mid-range, but there’s a lot more to it.
Blocks & Files: Hitachi Vantara supports GPU Direct with VSP One and that’s used in its broader Hitachi iQ AI infrastructure platform. Will Hitachi extend this protocol support?
Jason Hardy: S3 RDMA, or GPU Direct S3, is another thing. … that’s something that is a very high priority for us as we continue to work with Nvidia from a partnership perspective. We’re on our third generation of VSP One Object and we were the first to release in an on-prem object store Iceberg tables. So no one else has that functionality in the object store.
Blocks and Files: Do you see Hitachi v’s main interest in AI being an inference rather than training?
Jason Hardy: For us it’s all aspects of it and that’s because it’s important. So obviously training was a big push when generative ai AI came out and that was creating the large language models. AI is going to [and] still requires a lot of LLMs, but it’s going to require SLMs as another piece of it.
Blocks and Files: Small language models.
Jason Hardy: Exactly. And then as we move into the physical AI realm, which is this next wave after Agentic AI. We’re heavily focused on the physical AI realm because that is what Hitachi Limited Is a big piece of. And that was what our latest announcement was; how we’re building out and creating physical AI capabilities to support our industrial, our own internal industrial business units, as well as what our customers are asking for.
Physical AI is really going to transform a lot of the manufacturing space. It’s more than just self-driving cars.
Blocks and Files: How do you see it transforming things there?
Jason Hardy: if we pick out the manufacturing robot process, a lot of that is based on basic computer vision capabilities that; hey, I can sort something and understand if there’s a type A widget, this is a B, or this is a damaged widget and this is a not damaged widget. And then being able to work inside of that. What physical AI is going to do is basically now blend the agentic capabilities, basically giving agency to these systems into the physical space to where now it’s more than just having a picker. It’s now having humanoid type platforms.
Blocks and Files: I see. It’s like this; current industrial robots are great at sticking a screw in a car chassis, doing one 10,000 times a day. But they can’t put a nut on the end of it.
Jason Hardy: Correct. And now what happens is; we’re blending a lot of this together so that they are more aware of their surroundings and what they operate inside of. You can give them more human-like dexterity. But most importantly is; you can train them in virtual space with photorealistic surroundings because that’s very important to how that robot brain you’re training can then be put into a physical robot and now have the ability to understand its surroundings, its environment, very complex tasks and adapt as it needs to work through those tasks.
Blocks and Files: Okay. So let’s say I’ve got a car manufacturing product line at the moment with 20 robots doing the various things I did at the moment. If you wanted to change that to a new model or change it to a variation on the existing model, you’re probably going to have to do a software upgrade. That’s to all the computers behind it, whereas what you’re saying is …
Jason Hardy: Robotics will have to change. So, having just an articulating arm, like you said, can put a screw in. That’s a robot that does one thing and it’s been designed and built to do that one thing. It’s now how do we take that further? And it will be even a transformation in the robotics that are even incorporated into that. So it’ll be much as manufacturing processes are retrofit or improved as they go through normal maintenance or as they go through expansion to increase capacity, there will then also be a, hey, we have an investment of new robotics that come in, or humanoid style robotics that have a bit more mobility than just a picker or an articulating arm doing just a screw.
Blocks and Files: I could think of perhaps a PC motherboard. So an assembly line for it’s staffed by human workers and they take in a slab of a wafer at the end and at the back out comes the mother board and people have picked up components from trays oriented them, oriented the motherboard, put them in place, sold them. And you have a line of these people gradually adding more and more components to the motherboard. So I could envisage perhaps a smart robot doing all those things.
Jason Hardy: Exactly at lightning speed or lightning beeping at an accelerator. And 24 hours a day of course.
And they don’t get tired.
Blocks and Files: And is this real? Have you got prototypes of this kind of thing?
Jason Hardy: We’re in the middle now of doing a lot on our manufacturing process to get to that point. So we’ve been designing assembly lines for a very long time, for our own purposes, for other people and for our customers. So more to come.
Blocks and Files: if I could think of an average assembly line at the moment. with humans doing the stage things I’ve talked about, what would be the advantages of replacing that with a robotic system? What kind of things would excite manufacturing?
Jason Hardy: Higher capacity, higher output, more products per hour and a higher quality output. … The yield rate will be higher and you will have less failures through physical installation problems. You are now mitigating a lot of those human0created problems. And that’s just one piece of it, but it is improved efficiency. It is that 24 x 7 cycle.
What you’re also walking into now is the co-working of humanoids and humans saying, for example: “Hey, I’m new to the building. Where’s lunch at?” Or: “Hey, help me mail something.”
Whatever, you can interface with a robot now who understands you, the employee or the person, its surroundings and can guide you into a location or can help you with a task. So it’s a lot about bringing the autonomy that agentic AI has creating now into the physical ai, into the physical space, wrapping that inside of a package – like a robot, and then having that fulfil a task for you, being an assistant, a helper or being a piece of your manufacturing line.
Blocks and Files: No other storage company I talked to has been going on about this topic, but then no other storage company I talked to Is a major, part of the Hitachi group.
Jason Hardy: Exactly. And we have a very different perspective on this because our business is all of this. It is everything from manufacturing, a raw product all the way out to the IT systems and the digital transformation that these raw product manufacturers have to go through. Our own processes around how we manufacture trains or how we manufacture energy components are going through this transformation. So we are literally customer zero where we eat our own dog food or drink our own champagne.
That’s why we’re investing so much into it, because we ourselves see a lot of value from this, and our customers will obviously benefit from that as well.
Deduplicating backup target appliance supplier ExaGrid has passed 4,800 customers and says it’s the largest independent backup storage provider behind the big primary storage vendors, meaning Dell, HPE, NetApp, Pure, Hitachi, Huawei, and IBM.
ExaGrid’s appliances are disk drive-based and ingest backup data into a so-called landing zone where it is kept in a raw state with deduplication carried out later. This means restores from the landing zone are fast as the data does not have to be rehydrated from a deduplicated state, as is the case with all inline deduplicating appliances, whether they be disk, hybrid disk and flash, or all flash.
Bill Andrews
President and CEO Bill Andrews said: “We are pleased that we have achieved 19 consecutive quarters of free cash flow and EBITDA. Revenue and EBITDA continue to grow year over year… ExaGrid continues to have an over 70 percent competitive win rate, replacing primary storage behind the backup application from Dell, HPE and NetApp and others, as well as inline deduplication appliances such as Dell Data Domain, HPE StoreOnce and NetBackup appliances.”
Revenue in the quarter grew, with Andrews telling an IT Press Tour in New York: ”We slowed down a little bit, our growth, because of all the tariff stuff. The whole IT datacenter, not AI, has slowed down… We’re still growing, but not at the same rate two years earlier.”
He said: “We replaced Data Domain more last quarter than any other quarter since I’ve been here.” He also said that, in his customer base, there is a declining presence of backup apps like Dell NetWorker and Avamar, IBM Spectrum Protect and NetBackup.
The quarter’s highlights included:
Added over 160 new customers
19th consecutive quarter of cash, EBITDA, and P&L positive operations
50 percent of ExaGrid’s business comes from existing customer reorders
49 percent of the business came from outside the US
Adding more than 14 sales regions worldwide
Released Version 7.3.0, which included support for Rubrik and MongoDB Ops Manager, and added deduplication for encrypted Microsoft SQL Server direct dumps
Andrews told us: “Over 70 percent of new customer revenue comes from six and seven figure deals; 40 percent by deal count. The 40 percent are much bigger deals so that 40 percent by deal count is 70 percent to 80 percent of new customer bookings each quarter.”
“A $1 million deal is the same value as 20 x $50,000 deals. And that is new business. We also have a large existing customer base buying additional appliances and renewing maintenance and support with over 4,800 active installed customers buying additional appliances and renewing maintenance and support. 99.1 percent of our customers are on maintenance and support.”
In Andrews’ view, the big backup software providers – Cohesity, Commvault, Rubric and Veeam – are less interested in selling backup appliances combining hardware and software. They want to be software-defined and have customers bring their own hardware. ExaGrid is supporting a growing number of backup software suppliers so that, should customers switch backup suppliers, they can keep their ExaGrid appliances.
In our view, the next significant development in ExaGrid’s business will be an all-flash appliance and news of that is still under wraps.
Restructuring Quantum Corp has hired Geoff Barrall away from Index Engines to be its Chief Product officer, a new position, to lead product strategy, innovation, and engineering direction.
The company is now in a more stable position, following its debt restructuring and exec team refreshment. It’s also changed its external auditors, following a stream of financial reporting issues, from Grant Thornton LLP to CohnReznick LLP. We understand a CFO search is under way to replace the departed Lewis Moorehead.
Hugues Meyrath
CEO Hugues Meyrath said: “Geoff is a proven product and technology leader with a remarkable track record of founding companies, scaling global engineering teams, and shaping product strategies that drive market leadership.”
He told us: “I hired Geoff as a contractor the past three or four weeks and I literally had him crawl through all our engineering organization and he came back with an assessment of the way [we] can attack primary storage and the way we’re going to attack the market in general. And we’re seeing a hundred percent eye to eye. And I just looked at him at the end of the presentation and said, okay, you want to go do this with me? And he signed up.”
“We’re going to have to reorg the whole engineering team the way they work. We’re going to have to re-look at what do we do.”
We understand Barrall will be looking at the Raptor tape libraries, StorNext, Myriad, DXi deduping systems, Pivot3 video surveillance, and ActiveScale object storage products, and working out how they can work better individually and together, and respond to market needs such as the whole AI situation.
Barrall was Index Engine’s Chief Product Officer, and worked alongside its CRO Tony Craythorne, who joined Quantum as its CRO in July. Craythorne’s LinkedIn entry is illuminating about his time at Index Engines, and he’s worked with Barrall before, at Bamboo Systems.
Geoff Barrall
Barrall’s background is impressive. Before Index Engines, he served as Chief Technology Officer at Hitachi Vantara, where he shaped product strategy, partnerships, and advanced research, supporting $4 billion in annual revenues. Earlier in his career, he founded NAS supplier BlueArc Corporation, which he grew into one of the most recognized storage brands of its time before its acquisition by Hitachi. He was also the founder of Drobo and Connected Data, and has held multiple executive, board and advisory positions across the storage and IT industry.
Barrall said: “Quantum has a unique position in the market with its ability to deliver high-performance storage, cyber-resilient protection, and low-cost, long-term archives—all critical for today’s AI data-driven world. I’m excited to join Quantum at this pivotal moment to accelerate its innovation engine, align product strategy to customer needs, and deliver solutions that help organizations maximize the value of their data.”
Meyrath told us: “I think at this point we have more financial stability that we’ve had for several years. … I have my product guy now. I have my sales guy now. I have a good supportive board. I think we have the pieces and now we’re just going to put our heads down … and execute.”
It may be a tad early but we think we can start to say: “Welcome back Quantum.”
Veeam, the world’s largest data protection and cyber-resilience supplier, could be buying Securiti for around $1.8 billion, Bloomberg reports.
Securiti was started up in 2017, is based in San Jose, and operates in the Data Security Posture Management (DSPM) space with offerings encompassing data discovery, security, governance, and compliance. It aims to help organizations adopting AI to manage and use their data across on-prem and multiple public cloud environments, including SaaS. Its CEO and President is Rehan Jalil who has Symantec and Symantec-acquired BlueCoat exec time in his CV. He started up Securiti with other ex-Symantec/Bluecoat execs and the company has raised some $156 million in A, B, and C-rounds between 2019 and 2022, plus undisclosed amounts in three venture rounds, with the most recent one in March, 2023.
The main offering is a Data Command Center which is built around a knowledge graph. This Data Command Graph contains contextual information about data items and AI objects, and provides, Securiti says, a unified data control framework to manage security, privacy, governance and compliance. There are a claimed 1,000+connectors which it can use to link to data sources and get information about their data types. Eg; Azure Blob, AWS S3, Snowflake, Databricks, Salesforce, ServiceNow, and others, such as Pinecone and Weaviate for vector databases.
Securiti knowledge graph example.
Securiti customers can use this Data Command Center instead of having separate tools. They can, we understand, discover shadow data, enforce access controls, and analyze breach impacts.
Veeam is owned by private equity business Insight Partners, having been bought for $5 billion in 2020. It has the largest revenue share of the data protection market, according to IDC. It was valued at $15 billion in a secondary share offering at the end of 2024 and Microsoft invested in Veeam in February this year. Veeam then announced three of its Microsoft-focused services would use Microsoft’s CopilotAI tool. Veeam bought ransomware extortion negotiator Coveware in April last year.
The company is partnering Continuity Software for anti-ransomware technology and Palo Alto Networks for cyber-attack responses.
Veeam does not have a specific DSPM-focussed offering but does have DSPM features embedded in some of its products. For example, automated data classification in backups, immutable storage such as S3 Object Lock, Veeam ONE’s AI-powered threat detection provide visibility and risk management that accord with DSPM.
We would think that acquiring Securiti takes Veeam into the general DSPM market and enables it to compete better with Rubrik, which has become a cyber-resilience supplier after starting out as a pure data protection vendor. Specifically, it added DSPM to its Rubrik Security Cloud in December last year, using Microsoft labeling to protect sensitive data access. Veeam could integrate its own security and data protection offerings into the Securiti Data Command Center, and provide data loss and recovery features for it, matching if not exceeding Rubrik’s DSPM capbilities.
Opinion: Any organization that has not been hit by ransomware thinks, by default, that its defenses are good.
If internal voices are raised, saying it needs to upgrade its defenses, supporters balk at the costs involved and assume that, since we haven’t been hit yet, we must be OK. They realize that many other organizations have been hit and sometimes severely damaged, but assume that their defenses were inadequate, which they obviously were. If our defenses are good, and they must be because we haven’t been hit, then we don’t need to spend extra money strengthening them when there are so many other demands on that money.
But there is no validation standard for cyber-defenses, only security suppliers keen to sell you their consultancy, products, and other services to protect vulnerabilities or provide attack recoverability. There is no independent or trusted cyber-defense validation standard, no objective test by which you can assess your defenses against a cyberattack and make vulnerabilities visible.
The police can visit your house and suggest security measures that householders can take to help prevent burglaries. But they can’t visit businesses or other organizations to provide digital security help; it’s way, way beyond their expertise level. The only bodies that can do this want to sell you something, which makes them less trustworthy. For such suppliers, trying to scare prospective customers out of their complacency and selling them defensive measures is near impossible, without direct evidence of their specific vulnerabilities.
Of course, if you have suffered a ransomware or other damaging malware attack, then you will devote the effort and resources needed to strengthen your defenses – because you know you were vulnerable, have some idea of the attack entry point and internal spread paths, and a board and leadership unified in their determination to prevent it ever happening again.
Governments can’t realistically provide a cybersecurity validation service for enterprises and other organizations. Bureaucratic wheels turn exceedingly slowly; such efforts would try to cover every circumstance and would likely devise something cumbersome, unrealistic, and late. We would be better off looking at benchmark organizations like STAC. They are funded by businesses and develop performance tests for those businesses covering specific cases and market sectors.
We need a STAC-like body to develop cybersecurity tests that businesses could run against their internal and supply chain systems, and deliver a rating and vulnerability identification and assessment scores. We could envisage, for example, financial, manufacturing, or healthcare organizations refusing to cooperate with other suppliers in their sector unless they had a minimum validated security level. Perhaps cybersecurity insurance suppliers could help here too, requiring customers to meet minimum validated cybersecurity levels.
The best way for organizations to raise their collective cybersecurity is to come together and fund the development of cyber-defense validation tests, in a STAC-like model, and then only digitally connect to other entities with a minimum security validation rating. Such a rating could then spread and become standard practice.
NAKIVO has announced v11.1 of its Backup & Replication software and so we thought it would be. a good time to take a look at the company.
It was started up in 2012 in the USA by CEO Bruce Talley and six others: VP Product Management Sergei Serdyuk, QA engineer and product manager Veniamin Simonov, VP SW Development Nail Abdalla, VP Operations Margarita Matsko, Senior SW Developer Oleksii Osypov, and VP for QA, Sergey Yazvinskiy. Simonov is now at Xopero Software in Poland. The initial intent was to provide VMware vSphere backup, like Veeam. It expanded to cover Hyper-V in 2016, added disaster recovery and business continuity in 2018, AHV support and MSP market coverage in 2019. MSPs can offer backup (BaaS), replication (RaaS) and disaster recover (DRaaS) all as a service. The SW covers AWS EC2, Oracle databases, Office 365 and more environments and there have been no external funding rounds, it growing its business from its revenues. in fact it’s been profitable from year one.
Like Acronis, Veeam and HYCU source Comtrade SW, NAKIVO has a strong eastern European background. Veeam and Acronis have grown the most but NAKIVO has grown quite impressively too.
Sergei Serdyuk.
Serdyuk told us the firm has more than 16,000 paying customers, with coverage for physical, virtual and NAS sites, and cloud/SaaS operations. It provides, it says, fast recovery with instant restore and automated failover, handled through a unified, single pane of glass management console. There are over 3,000 channel partners and, Serdyuk said: ”Roughly half of our revenue and customers are coming from EMEA, 35 percent comes from Americas and 15 percent from Asia.” Prominent customers include CocaCola, Cisco, the Detroit Police, Honda, the city of Dan Francisco, Siemens, Radisson and Verifone.
He explained that: “MSP is one of our big customer groups. We have a very good solution for them because we are cost effective. They care a lot about this because MSPs need to be competitive.”
The second quarter of this year found NAKIVO enjoying 40 percent year-on-year revenue growth in the Americas, with 22 percent revenue growth overall. Its customer count grew 9 percent Y/Y; that’s over 1,400 new customers. There was a 43 percent growth in enterprise deployments so it’s not just more small and medium businesses coming on board.
The Backup & Replication product has had additional functionality added steadily over the years and, naturally, cybersecurity is coming to the fore these days;
The company has added functionality such as MFA, RBAC, backup immutability, and encryption. V11.1 brings in a Direct Connect facility for MSPs whereby they can connect to tenant VMware, Hyper-V, and Proxmox VE virtual machines, and physical servers, without requiring open ports on the tenant side.
Serdyuk told us: “it allows our MSP customers to seamlessly connect to their clients without having to tweak networking infrastructure at the client site. So they basically download the component, install it, and it connects back securely to the MSP.”
There is multi-language support, including English, Spanish, French, German, Italian, Polish and Chinese. Proxmox VE backups get the ability to have virtual machines booted from them, have replicas created, restore direct from tape, VM temp-lates to maintain configuration consistency, and automated backup integrity validation.
Serdyuk said VMware migration as a big issue for SMBs: “You probably remember this big turmoil with changes in Broadcom and ProxMox, by our data, was the number one platform that businesses of all sizes consider migrating to. Of course, the larger the business, the less likely they were going to migrate. … A good portion of our customers started using ProxMox in production and we continue to develop it.”
VMware gets real-time replication with automated failover to real-time VM replicas during outages. Serdyuk again: “Before we started, my assumption was that real time replication would only be used by enterprises. It turns out that SMBs also want to do this, but on a much smaller scale. They would just have a couple of virtual machines for which they want to have real time replication.”
On the physical server side there are more granular backups, for specific volumes and folders on Windows and Linux machines without requiring full backups.
NAKIVO is less expensive than Veeam;
We asked Serdyuk if NAKIVO will start providing AI facilities for users to query and manage their backups? He said: “That’s the future, obviously. Yes.” But: ”My thinking is that, at least at this point in time, I view AI as a really like a copilot where you can have distributed infrastructure. I will not trust AI to do a failover. I could maybe trust the script, but even then, I still want the human to look at something before they push the big red button.”
He believes that NAKIVO”s growth will accelerate: “We are making internal changes that should accelerate us. We should grow twice as faster as we are now.”
Download a NAKIVO presentation deck, with more information, including (US) pricing tables, here.
UK-based AI data storage firm PEAK:AIO has secured more than $6.8 million in seed funding to accelerate product development, expand its team, and forge partnerships for global growth.
The software-defined all-flash storage company was founded in 2021. In March, it announced a 2RU DataServer, a pNFS NAS system based on a Dell server with Solidigm NVMe SSDs and Nvidia CX7 Ethernet NICs. PEAK:AIO says its software “delivers dramatically faster performance while consuming less energy,” and has talked about a CXL memory-based KV cache offload system. It also has an NVMe flash-based PEAK:ARCHIVE product offering up to 1.4 PB capacity in a 2RU chassis.
PEAK:AIO will use the new funding to accelerate its global expansion, grow its team, and advance development of its high-performance platform. The company currently offers a single-node Data Server and plans to evolve it into a fully scale-out system.
Mark Klarzynski
Co-founder and Chief Strategy Officer Mark Klarzynski said: “We’ve already proven what true AI-first infrastructure can achieve; now we’re scaling that vision. This funding fuels the next phase of PEAK:AIO: open, high-performance, and built to outpace legacy at every level. Our upcoming designs are engineered to set a new standard, one that legacy systems simply weren’t built to reach.”
Klarzynski said he is considering new product ranges and enhancements enabled by the funding. The company “is shifting gear, moving from category-defining performance in single-node systems to building the future of scaled-out, AI-native infrastructure and beyond. The company will accelerate the delivery of its pNFS platform, KV cache and AI-focused S3, while embracing modern-day architectures like CXL, and grow its global footprint through strategic partnerships and on-the-ground deployments.”
The funding round was led by UK-based Pembroke VCT with a $5 million investment, with participation from Praetura Ventures, also in the UK, and joined by a Silicon Valley investor.
Viewed simply as an AI-focused, fast all-flash array supplier, PEAK:AIO has formidable competition: Dell, DDN, HPE, IBM, NetApp, Pure Storage, VAST Data, and WEKA, for example, with Cloudian and MinIO in the speedy object storage space as well. Its product technology will need to significantly outpace and outshine these suppliers to gain traction.
The investors are positive. Fred Ursell, Head of Investments at Pembroke Investment Managers, said: “With a team that has repeatedly scaled and exited category-defining businesses, and early validation from some of the most complex customers in the world, we believe PEAK:AIO is positioned to be a critical enabler of the AI revolution.”
Louise Chapman, a Fund Principal at Praetura Ventures, added: “Our investment into PEAK:AIO comes at a very opportune time for the AI sector, with Google, Microsoft and Nvidia all announcing plans to invest tens of billions into the UK. Going forward, this news will create even bigger opportunities for companies such as PEAK:AIO, which has already been enjoying impressive traction to date – both in the UK and on a global scale. We’re now looking forward to being part of the company’s next chapter and supporting the team.”
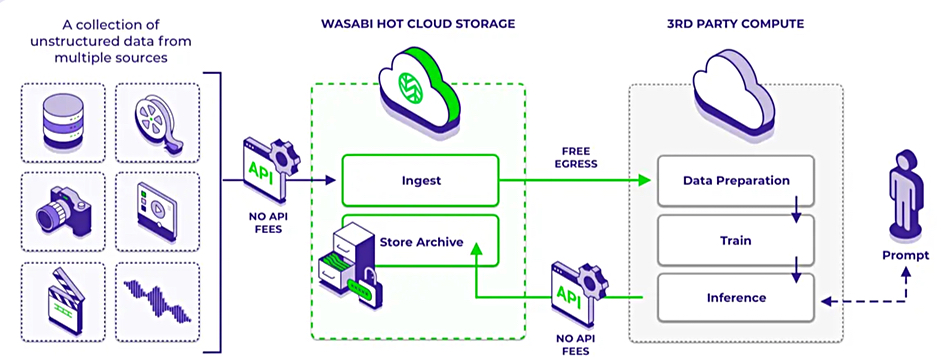
Cloud storage supplier Wasabi has raised $32.5 million and set up AI data storage facilities with export to external GPU compute.
Wasabi Technologies started out providing S3-compatible public cloud object storage as an Infrastructure-as-a-Service supplier (IaaS). Now it has file (NAS), video surveillance and video media storage offers. Basically, it resells disk drive space for much less than AWS, Azure or GCP to people who don’t want the bother of running their own HDD-based object or file storage operation in-house. For example, it undercuts AWS by up to 80 percent and has no egress or API request fees. It partnered with Kioxia to add NVMe SSDs into its storage mix earlier this year, and now has a Wasabi Direct Connect offering for low latency and high bandwidth data transfers.
Wasabi raised $250 million to grow its business by adding regions in 2022 – it added Italy in 2024, passed 100,000 customers, and added AI-powered metadata generation for video data (AiR) last year by acquiring Curio.
According to a recent filing, the company has raised $32.5 million in a private placement share sale to three investors, in which shares worth $70 million were on offer. This takes the total raised since being started up in 2015 to around $580 million.
The AI data storage offering has ingest and archival storage aspects. Ingested data can be indexed, cataloged, and have custom metadata added to it, using the acquired Curio technology. The archive part means storing it in Wasabi’s existing object storage facility. It says its “low-latency object storage accelerates training, fine-tuning, and inference, with 100 Gbps direct connect for real-time AI updates.”
Wasabi AI data storage graphic.
Wasabi says its AI storage connects with GPU providers (Nvidia Inception Program), AI/ML tools such as large language models, ML platforms, and cloud AI services. There is a single pricing tier: $6.99 per TB/month pay-as-you-go.
The AiR tier refers to Wasabi’s automated indexing, cataloging, and metadata tagging of video data. There is a wait list for this and it’s not open to new customers. RCS in the table refers to reserved capacity storage.
There is no specific AI data storage tier and no ability to run GPU compute inside Wasabi’s cloud, unlike AWS, Azure, and GCP. Wasabi does not support S3 over RDMA, unlike Cloudian and MinIO, but then none of the big three public clouds support it either.
We think that Wasabi’s AI data storage offering is in its very early days and hope to see more AI and AI data pipeline facilities being offered in the future. For example, specific AI storage classes, in addition to, and differentiated from, the current object, NAS, and video-surveillance classes. They would be differentiated by having extra AI-specific services, but what they might be is unclear. The under-subscribed funding suggests investors can’t yet see this either.
Bootnote
Michael Bayer, Wasabi’s CFO, told us: “We have held our financing release as it will be done in multiple closings due to various statutory requirements we have to follow because we may be oversubscribed. We anticipate the round will have a final close in the third or fourth week of October, and once we are closed, we will have a comprehensive release regarding the amount and participants.”
Graph database supplier Neo4j is offering its Aura Agent to help customers build and deploy agents on their own data in minutes, an MCP Server to add graph-powered memory and reasoning into existing AI applications, and a $100 million investment in GenAI-native startups to increase its technology’s take-up.
Up until now, the main data source for GenAI large language models (LLMs) and agents has been unstructured file and, latterly object data. AI apps can get access to structured (block) data in relational databases using traditional standard SQL and other searches. But these don’t reveal the relationships between items in these databases. Graph databases encapsulate such relationships (see description here).
We have understood graph database technology and suppliers, like Illumex, Memgraph, and Neo4j to be edging slowly into the GenAI LLM and agent world but that view may well need to be altered, as we shall see.
Agentic AI is going to involved agents co-operating in a context and needing to have a “memory” of that context as they execute. They will also need, Neo4j says, to be able to reason, and that requires awareness of relationships between the entities they are processing.
Neo4j cites an MIT research finding that 95 percent of AI pilots fail to deliver returns. It highlights “model quality fails without context” and points to a lack of memory and contextual learning as among the biggest reasons for failure. Neo4j reckons it can add context and memory to AI agents and wants to be “the default knowledge layer for agentic systems.”
Charles Betz, a Forrester VP and Principal Analyst, said in a 2025 blog. “The graph is essential. It is the skeleton to the LLM’s flesh.”
Emil Eifrem.
Emil Eifrem, Neo4j Co-Founder and CEO, reckons: “Agentic systems are the future of software. They need contextual reasoning, persistent memory, and accurate, traceable outputs, all of which graph technology is uniquely designed to deliver. Neo4j transforms disconnected data into actionable knowledge, and this investment allows us to advance that vision faster.”
The company has built an MCP (Model Context Protocol) server so that external AI agents can link to and integrate with Neo4j’s graph database data. It supports natural language querying, auto-generated graph data models, memory persistence, and automated management of Neo4j AuraDB instances. AuraDB is Neo4j’s fully-managed graph database.
It has also developed its own Aura Agent, now in early access mode, with “end-to-end automated orchestration and AIOps for graph-based knowledge retrieval. This, it says: “that enables users to build, test, and deploy AI agents grounded directly on their enterprise data in minutes.”
Nitin Sood.
Nitin Sood, SVP and Head of Product Portfolio and Innovation at multinational molecular biotechnology company QIAGEN, said: “Neo4j Aura Agent promises to improve healthcare by designing and deploying AI agents that create comprehensive knowledge graphs from our … biomedical knowledge. With new ways to interrogate these graphs, researchers can approach drug discovery in ways that were impossible before.”
This means Neo4j has an agent-building facility with which its customers can interrogate their graph data, and an MCP server so that external agents can do the same. But how will it get AI-agent-building organizations to use them and its databases? That’s where the $100 million comes in.
The investment
Neo4j says it will invest $100 million over 12 months to support 1,000 worldwide GenAI-native startups to build and scale agentic AI with graph technology. Participants will receive access to cloud credits, technical enablement, and go-to-market support to help them build and scale agentic systems with graph technology. That means it will be dealing with an average rate of 83-84 companies a month.
We understand that these include cloud (Aura) credits, tech enablement (aka fully-managed AuraDB graph database and graph expert help) and go-to-market support (co-marketing and GTM partnerships) are valued in total at a notional $100 million. It doesn’t mean that each company will get $100,000 cash.
David Klein.
David Klein, Co-Founder and Managing Partner at One Peak, and a Neo4j Board Director, said: “Eight out of ten GenAI-native startups I speak with are re-platforming on Neo4j. They tell me that it’s the natural choice when you’re serious about building intelligent systems with context and memory.”
We didn’t know how many GenAI-native AI startups there are, and what proportion of them get to speak with Klein, so we asked three chatbots about the startup number.
According to Grok, xAI’s clever chatbot, there are over 6,000 GenAI-native startups worldwide. This figure comes from ecosystem trackers that distinguish startups and scaleups innovating directly in GenAI (e.g., model development, content generation tools, and AI-native applications) from broader AI companies. It includes more than 16,500 total companies in the GenAI space, but the startup subset emphasizes early-stage innovators.
The Perplexity chatbot agreed with these numbers, as did ChatGPT: “According to StartUs Insights, there are ~6,020+ generative AI startups globally as of their 2025 report.” If Klein’s 8 out of 10 numbers are even remotely generally applicable then there are a large number of such startups thinking about graph technology. We shall see.
Neo4j’s Startup Program is now live at neo4j.com/startups. It has 208 members, including Firework, Garde-Robe, Hyperlinear, Mem0, OKII, Rivio, and Zep. Check out the Startup Program FAQ here. Apply to join the program here.
A fully supported version of the Neo4j MCP Server will be available by the end of the year. Aura Agent should also be generally available by then.
Bootnote 1
We might expect to see partnerships building up between AI LLM and agent-focussed unstructured data suppliers, both file and object, and the graph database companies. That would widen the latter’s go-to-market channel.
Bootnote 2
Neo4j was started up in 2007 and has raised approximately $580 million across 9 funding rounds and events, the most recent a $50 million grant in 2024. This is serious funding.