Parallel NFS-based data manager/orchestrator Hammerspace has selected the Xsight Labs E1 800G DPU to eliminate legacy storage servers from AI data storage.
Hammerspace claims this collaboration advances the Open Flash Platform (OFP) vision of a democratized, efficient, and radically simplified data storage infrastructure offering more than 10x storage density and 90 percent lower total cost of ownership. Its OFP concept replaces all-flash arrays with directly accessed SSDs in JBOFs that have a controller DPU, Linux, its parallel NFS (pNFS) software, and a network connection. Israel-based fabless semiconductor business Xsight Labs provides end-to-end networking technologies to support exponential bandwidth growth (e.g., up to 800G and 12.8T speeds) for cloud infrastructure, 5G, machine learning, and compute-intensive workloads.
David Flynn
David Flynn, Hammerspace CEO, says: “Legacy storage is collapsing under the weight of AI. By fusing our orchestration software with Xsight’s 800G DPU, we flatten the data path and turn every Linux device into shared storage. The result is an open architecture that scales linearly with performance, slashes cost, and feeds GPUs at the speed AI demands.”
The company says its OFP architecture redefines the data center by removing the traditional storage server, “the expensive middleman,” from the storage path. Instead, flash storage connects directly to the network using open standards such as Network File System (NFS) and Linux, creating a dramatically simpler and more enduring architecture.
Xsight E1 800G DPU chip
Hammerspace has selected Xsight’s E1 800G DPU to realize the OFP vision for the next generation of warm storage AI infrastructure. This required a DPU with the Arm core density, memory bandwidth, and 800Gbps Ethernet connectivity necessary for high-performance environments.
Xsight’s E1 800G DPU is an edge server for AI data center infrastructure and comes in the form of a PCIe Gen 5 add-in card or 1 RU edge server. It features:
800G DPU with 100 percent fast-path all-layer processing (no slow-path architecture – see bootnote)
64C x Arm N2s, TDP 90W, TSMC n5
8 x 112G SerDes allowing 2x400GE, 4x200GE, 8x100GE
Networking, security, storage, and compute (SDN model with hardware acceleration)
Arm System Level 6 Ready workload compatibility on all Linux distros
Xsight says there is no traditional slow-path and fast-path misalignment in the E1 – it has no slow path. This allows full line rate at 800G with no use of accelerators.
Ted Weatherford
Ted Weatherford, VP Business Development at Xsight Labs, said: “Hammerspace’s orchestration software allows every network element, regardless of memory size, to function as a flat layer zero storage node. The scalability and performance story here will set the pace for the entire AI industry. Hammerspace’s stack coupled with our E1 DPU – which is silently a full-blown Edge server – offers the performance leading warm-storage solution.
“The magic is we are fast-piping warm storage directly to the GPU clusters eliminating all the legacy x86 CPUs. The solution offers an exabyte per rack, connected directly with hundreds of giant Ethernet pipes, thus simplifying the AI infrastructure profoundly.”
What Hammerspace and Xsight are saying is that AI datacenters no longer need external storage arrays to hold training and inference data. They can use basic Linux-controlled JBOFs (just a box of flash) with component SSDs directly connected to GPU servers to save costs and power. It’s somewhat similar to messaging from Western Digital with its OpenFlex JBOFs, and Kioxia with its now abandoned Kumoscale product technology.
Early access deployments of the Xsight Labs E1 DPU, integrated with Hammerspace’s orchestration software, are underway with strategic partners. Limited volume shipments are planned to begin in Q4 2025 with production systems available early Q1 2026.
Bootnote
We understand that Hammerspace’s flattened AI warm storage architecture is optimized for AI workloads, particularly in hyperscale datacenters. There is a direct data path between GPUs and SSDs holding so-called warm data – frequently accessed, but not as often as active training (hot) datasets.
Xsight’s fast path and slow path concepts relate to the fast path being the high-speed, hardware-accelerated data plane optimized for line-rate processing of the data traffic. The slow path is the exception-handling or control plane path, managed by embedded software running on Arm cores (or similar) within the DPU. Misalignment occurs when the fast-path and slow-path are not synchronized in their configuration, state, or behavior.
Broadcom announced its third-generation Tomahawk 6 Davisson (TH6-Davisson) product, the industry’s first 102.4 Tbps co-packaged optics (CPO) Ethernet switch – double the bandwidth of any CPO switch available today. Broadcom claims Davisson is changing the game for AI infrastructure. By reducing link flaps and power consumption, it not only cuts costs, but enables faster, more reliable AI model training. This allows Broadcom customers to achieve higher MFU, fewer job failures, and greater cluster uptime, unlocking unprecedented value for both scale-up and scale-out AI deployments.
…
Broadcom announced Thor Ultra for AI Scale-Out networking, the industry’s first 800G AI Ethernet network interface card (NIC) engineered to deliver advanced RDMA for large-scale AI datacenters with over 100,000 XPUs. Compliant with the new Ultra Ethernet Consortium (UEC) capabilities, Thor Ultra delivers the performance, scalability and openness required for tomorrow’s scale-out AI clusters – without lock-in and with true interoperability.
RDMA is key to accelerating job completion in AI datacenters. However, traditional RDMA cannot keep pace with the demands of future AI workloads. It lacks Multipathing Support, cannot handle Out-of-Order Packet Delivery, and relies on slow retransmission methods like Go-Back-N, and uses Congestion Control mechanisms that are difficult to tune.
Thor Ultra introduces a suite of advanced RDMA features designed to meet the demands of next-generation AI workloads:
Packet-level multipathing for efficient load balancing.
Out-of-order data placement to XPU memory, maximizing PCIe link utilization.
Reliable packet delivery with hardware-based selective acknowledgment (SACK) and retransmissions.
Programmable congestion control to seamlessly adapt to future congestion management algorithms.
…
Ceramic-coated glass tablet archival storage startup Cerabyte showed early access media samples containing copies of the U.S. Constitution at the 2025 Open Compute Project (OCP) Global Summit, October 13-16 in San Jose, California. Watch this video to learn about Cerabyte’s progress in 2025.
…
Reuters reports that data streaming software supplier Confluent is looking for a buyer: “The software provider is working with an investment bank on the sale process, which is in its early stages and was instigated after both private equity firms and other technology companies expressed their interest to the company in buying it, the sources said… Some of the sources had told Reuters while Confluent’s technology is highly sought-after, it became vulnerable to takeover approaches when its stock price dived in July, when it reported losing business from a large customer.”
…
Data protector CrashPlan announced a strategic partnership with cloud storage supplier Wasabi Technologies to store its backups. This partnership eliminates the costly egress and API fees charged by hyperscalers by offering a flat-rate, predictable pricing model, enabling CrashPlan customers to store more data for longer at a fraction of the cost. This partnership covers Microsoft 365, Google Workspace, endpoint devices, and file servers.
…
DeepTempo announced an integration with Cribl, bringing its deep-learning behavioral detection engine directly into Cribl’s telemetry pipeline. It says this is the first time enterprises can run purpose-built deep learning models within their data orchestration workflow, detecting polymorphic and AI-driven threats like agentic attacks and zero-click exploits before data even reaches the SIEM. It says that, as legacy rule-based tools continue to miss behavior-driven threats, this partnership gives SOC teams a new intelligent layer of preprocessing, powered by DeepTempo’s LogLM foundation model that “understands the language of logs.”
…
Generative AI inference pioneer d-Matrix, in collaboration with Arista, Broadcom and Supermicro, announced SquadRack, the industry’s first blueprint for disaggregated, standards-based, rack-scale systems for ultra-low latency batched inference. Showcased at the Open Compute Project Global Summit, SquadRack provides a reference architecture to build turnkey solutions enabling blazing fast agentic AI, reasoning and video generation. It delivers up to 3x better cost-performance, 3x higher energy efficiency, and up to 10x faster token generation speeds compared to traditional accelerators.
SquadRack configured with eight nodes in a single rack enables customers to run Gen AI models up to 100 billion parameters. For larger models or large-scale deployments, it uses industry standards-based Ethernet to scale out to hundreds of nodes across multiple racks.
d-Matrix JetStream IO Accelerators enabling ultra-low latency device-initiated, accelerator-to-accelerator communication using standard Ethernet.
Supermicro X14 AI Server Platform integrated with Corsair accelerators and JetStream NICs.
Broadcom Atlas PCIe switches for scaling up within a single node.
Arista Leaf Ethernet Switches connected to JetStream NICs enabling high performance, scalable, standards-based multi-node communication.
d-Matrix Aviator software stack that makes it easy for customers to deploy Corsair and JetStream at scale and speed up time to inference.
SquadRack configurations will be available for purchase through Supermicro in Q1 2026. Learn more here.
…
Industrial AI supplier Cognite announced a partnership with Databricks, and plans for a bidirectional, zero-copy data sharing integration between the Cognite Industrial AI and Data Platform, which includes Cognite Atlas AI and Cognite Data Fusion, and the Databricks Data Intelligence Platform, including Databricks’ flagship AI product, Agent Bricks. This collaboration leverages the open ecosystem approach of both platforms to provide a unified, domain-specific intelligent data foundation for Industrial AI, driving operational efficiency and measurable business value across the enterprise.
…
Channel-led DataCore launched its Freedom360 Partner Program. The software-defined DataCore offering includes SANsymphony for block storage, Nexus for file (via the ArcaStream acquisition in February 2025), Swarm for object, Puls8 for containers, and StarWind for hyperconverged infrastructure (acquired in May 2025). Pixitmedia solutions (acquired in Feb 2025) further extend opportunities in media and entertainment, supporting end-to-end workflows in broadcast, live events, post-production, and creative pipelines. Freedom360 has a progressive certification framework – Base, Specialist, and Excellence – that recognizes partner commitment and rewards contribution. This system gives every partner, whether newly onboarded or long established, a clear path to higher rewards, greater visibility, and stronger collaboration with DataCore. The framework is designed to accelerate cross-sell opportunities across the portfolio. DataCore is modernizing partner training and certification
…
DDN Infinia is available in Oracle Cloud Marketplace and can be deployed on Oracle Cloud Infrastructure (OCI). Oracle Cloud Marketplace is a centralized repository of enterprise applications offered by Oracle and Oracle partners. DDN Infinia delivers cloud-native, GPU-optimized, software-defined object storage designed to mitigate the complexity, performance bottlenecks, and costs that stall modern AI pipelines. Infinia is optimized for OCI bare metal instances, providing improved performance for AI, analytics, and data-intensive workloads while supporting OCI’s native governance, spend management, and compliance frameworks.
…
Automated data mover Fivetran signed a definitive agreement to merge in an all-stock deal with dbt Labs. Fivetran CEO George Fraser will serve as CEO of the unified company, and dbt Labs CEO Tristan Handy will serve as co-founder and President. Following close of the transaction, the combined company will be approaching nearly $600 million in ARR. As part of this transaction, the company is committed to keeping dbt Core open under its current license and maintaining it with and for the community, ensuring its development remains vibrant.
The unification of Fivetran and dbt sets the standard for open data infrastructure, a new approach that reduces engineering complexity by automating data management end to end. It works across any compute engine, catalog, BI tool, or AI model, is built on open standards like SQL and Iceberg, and remains flexible so organizations avoid lock-in and can scale with future workloads.
Finalisation of the merger remains subject to customary closing conditions, including regulatory approvals.
…
Data security supplier Forcepoint announced the expansion of its Self-Aware Data Security platform to protect enterprise databases and structured data sources. With this launch, Forcepoint is the first to extend AI Mesh Data Classification technology across both structured and unstructured data throughout the hybrid enterprise, delivering unified Data Security Posture Management (DSPM) and adaptive data loss prevention in a single platform.
Most DSPM tools stop at cloud visibility without remediation, widening the gap between visibility and control. Forcepoint extends its AI Mesh-powered discovery and classification into enterprise databases and business applications, while unifying visibility with enforcement across SaaS apps, endpoints, networks and AI workflows. This closes that gap by giving enterprises and governments a single, AI-native platform to secure both structured and unstructured data consistently. Read a blog to learn more.
…
According to an HPEblog: “The HPE Alletra Storage MP X10000, supporting unstructured, data-intensive workloads, will soon introduce native support for the Model Context Protocol (MCP) – enabling seamless integration between storage, compute, and AI frameworks. Together, they create a modular, software-defined platform that grows with the business.”
…
Anti-ransomware backup startup HyperBunker has closed an €800,000 seed round from Fil Rouge Capital and Sunfish Venture Capital.
…
GPU-based NVMe RAID supplier Graid Technology has entered a strategic license agreement with Intel to take the lead in developing, marketing, selling, and supporting Intel VROC (Virtual RAID on CPU) worldwide. Together, CPU- and GPU-based RAID architectures will deliver unparalleled speed, scalability, and resilience for AI, HPC, and data-intensive workloads.
As we understand it, Intel VROC is a blend of hardware and software RAID storage, designed to maximize the performance of NVMe SSDs in high-end computing environments like servers and workstations. It enables RAID configurations (such as RAID 0, 1, 5, 10, and matrix RAID) directly through the CPU, eliminating the need for separate hardware RAID controllers or host bus adapter (HBA) cards, which reduces complexity, cost, power consumption, and frees up PCIe slots.
At close, which is expected by the end of the year, Graid Technology will assume responsibility for all Intel VROC customer support and future development. Both Intel and Graid Technology say they are committed to ensuring a seamless transition with regular updates and transparent communication throughout the process.
Graid told us: “[Our] SupremeRAID is a software-defined RAID solution that runs on the GPU, not a hardware card. Under the new agreement, we’ll lead global sales, development and support for Intel VROC, which remains a CPU-based RAID product. Together they offer complementary, software-defined RAID architectures for different performance needs.’
…
JEDEC Solid State Technology Association announced it is nearing completion of the next version of its Universal Flash Storage (UFS) standard: UFS 5.0. Designed for mobile applications and computing systems that demand high performance with low power consumption, UFS 5.0 should deliver:
Increased sequential performance up to 10.8 GB/s to meet AI demands.
Integrated link equalization for more reliable signal integrity.
Distinct power supply rail to provide noise isolation between PHY and memory subsystem, easing system integration.
Inline Hashing for greater security.
…
Lightbits Labs, which supplies software-defined, disaggregated, NVMe over TCP storage, and CYBERTEC, the largest PostgreSQL consultancy and services delivery company in Europe, announced a strategic technical alliance that offers optimized next-gen infrastructure for high-performance PostgreSQL workload needs. The collaboration combines CYBERTEC’s PostgreSQL expertise with Lightbits’ high-performance block storage to help organizations overcome the storage bottlenecks that limit the growth and performance of PostgreSQL databases at scale.
…
Ingo Wiegand
Mainframe software modernizer Mechanical Orchard has hired Ingo Wiegand as VP of Product, reporting directly to CEO Rob Mee. His most recent position was GM & VP of Product Management at Samsara, where he led the video-based safety product through a phase of hyper-growth to several hundreds of millions in ARR over the course of five years. Wiegand will scale the Imogen product, including managing the roadmap, driving smooth collaboration between teams, and ensuring the successful translation from vision to delivery.
Imogen “rewrites mainframe applications safely and quickly by focusing on the behavior of the system as represented by data flows, rather than on just translating code. This approach, encapsulated in the platform, signals the end of opaque, risky and uncertain mainframe transformation projects, resets the technical debt meter and restores control to IT teams through rewriting systems into clean, modern code. Customers span the global banking, retail, healthcare, manufacturing, and logistics sectors.”
…
Wedbush analyst Matt Bryson told subscribers that Samsung announced its Q3 operating profit is expected to grow around 32 percent year-over-year to ₩12.1 trillion ($8.5 billion), marking its highest levels since Q2 2022 and far exceeding consensus of ₩10 trillion. Although detailed figures weren’t disclosed, the Chosun Daily estimates Samsung’s semiconductor division (DS) drove the majority of the upside earning around ₩5 trillion, more than ten times its Q2 profit of ₩400 billion. A number of reports attributed the earnings beat to stronger-than-expected prices of commodity DRAM and NAND, stemming from demand for AI datacenter servers, and overall tighter chip inventory levels.
Pfeiffer University, a private nonprofit liberal arts institution in North Carolina, is using VergeIO to replace VMware, reducing Pfeiffer’s infrastructure costs by approximately 85 percent. “VMware wasn’t calling us back,” said CIO Ryan Conte. “VergeOS was the only product I looked at that didn’t need hardware. Others told me to buy new, but I had good servers with life left in them. VergeOS let me use them.” VMware’s move to per-core subscriptions increased Pfeiffer’s projected costs to $35,000-$45,000 annually, compounded by the elimination of discounts offered to higher education institutions. In addition, MSPs pushed for hardware refreshes or cloud migrations that would have cost Pfeiffer $100,000 to $200,000 – a significant capital expense for most private nonprofit institutions.
VergeIO stood out because it:
Supported reuse of HP Gen9/10/11 and Dell servers, allowing the university to repurpose existing equipment.
Combined virtualization, storage, networking, and data protection into a single platform.
Enabled in-house migration of 30–40 VMs without professional services.
Delivered built-in disaster recovery, replication, and ransomware protection, eliminating the need for a separate $20,000–$30,000 backup project.
Western Digital announced the opening of its expanded System Integration and Test (SIT) Lab, a state-of-the-art 25,600 sq ft facility in Rochester, Minn. and called it a strategic investment to provide research, development and global operations and enable real-world testing and validation with a mini datacenter environment. The SIT Lab serves as a massive, dedicated collaboration hub where the company’s engineers work alongside key customers throughout every stage of the product lifecycle, including development, qualification, production ramp and end-of-life. WD’s global SIT lab network has multiple sites close to its customers in the United States and across Asia. A blog says more.
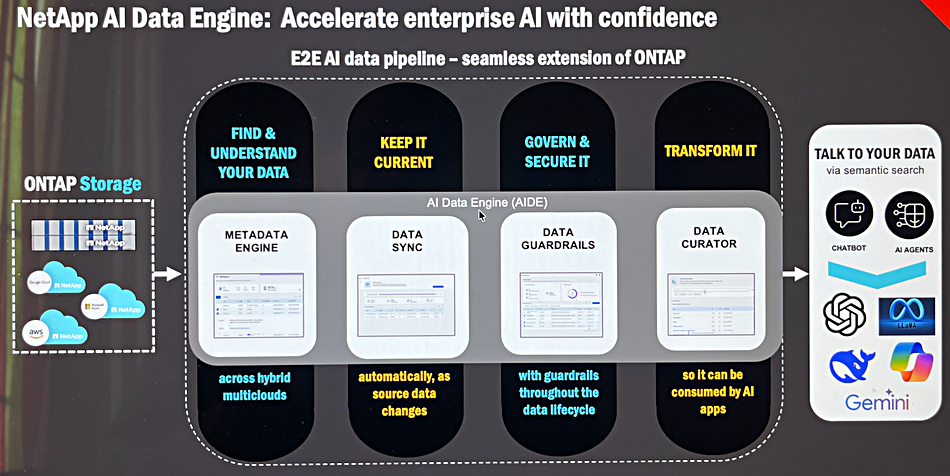
New all-flash NetApp AFX arrays separately scale storage and compute while an AI Data Engine pre-processes ONTAP data for AI LLM and agent use, and customers get a NetApp Ransomware Resilience Service along with block-enhanced Goggle Cloud integration.
These announcements were made at NetApp’s INSIGHT 2025 event in Las Vegas, and represent its adoption of improved scale-out facilities and data pipeline capabilities for its storage in order to better support AI enterprise workloads, as well as strengthen its cyber-resilience facilities. The disaggregation of compute and storage nodes has been a distinguishing feature of VAST Data’s storage, enabling parallel access to data without using a complex parallel file system. The basic scheme has been taken up by HPE with its Alletra MP storage systems, Pure Storage with its FlashBlade//EXA and Qumulo with its Stratus software. Now NetApp is offering its AFX disaggregated storage to its 22,000 or so customers.
Syam Nair.
Netapp Chief Product Officer Syam Nair said: “The combination of NetApp AFX with AI Data Engine provides the enterprise resilience and performance built and proven over decades by NetApp ONTAP, now in a disaggregated storage architecture, and all still built on the most secure storage on the planet.”
AFX
The AFX arrays have three hardware components connected by a high-speed and low-latency internal network;
AFX components: AFX 1K storage controller (top), 3 x DX50 data compute nodes (middle), NX224 NVMe enclosure (bottom).
AFX 1K storage controller: 2 RU enclosure with 11 PCIe gen 5 expansion slots running an ONTAP instance.
Optional DX50 data compute node: AMD Genoa 9554P processor, Nvidia L4 GPU, 1 RU chassis. This powers the AFX metadata engine, and other AI Data Engine services. It continuously indexes data and enables data engineers to discover and curate datasets by using familiar SQL queries. As this engine runs on dedicated compute nodes, it doesn’t affect the performance of the primary AI workloads.
NX224 NVMe enclosure (storage node): 24-slot NVMe SSD boxes supporting 7.6 TB, 15.3 TB, 30.7 TB, and 60TB SSDs and providing a single pool of storage.
There can be up to 128 AFX storage controllers in a cluster, along with up to 52 storage enclosures, which provide more than 1 EB of effective capacity, and 10 data compute nodes. The supported storage protocols are pNFS, NFS, SMB, S3, and NFS/RDMA. The internal Ethernet networking is based around Cisco Nexus 400G switches.
The AFX system requires ONTAP v9.17.1 or later and the AFX software includes the AI-powered, autonomous ransomware protection. It’s certified for NVIDIA DGX SuperPOD, and can connect to GPU servers using Cisco switches, with up to 64 fixed 400G ports on the Nexus 9364D-GX2A and 32 fixed 400G ports on the Nexus 9332D-GX2B.
It inherits ONTAP software features such as S3 SnapMirror data copying to StorageGRID, CloudSync and XCP connectivity to AWS, Azure and GCP, plus integration with NetApp’s AFF and FAS arrays via SnapMirror, SVM DR, SVM Migrate and FlexCache.
AI Data Engine
The AI Data Engine (AIDE) provides an AI data pipeline to have AFX-stored data made deliverable to and usable by AI Large language Models (LLMs) and agents. It is a built-in ASI-focussed ETL (Extract, Transform and Load) pipeline that uses the AFX metadata engine. The AIDE software can discover and characterize data spread across a customer’s NetApp data estate, both on-premises and in the three main public clouds. As fresh data comes in and/or old data is deleted the metadata is updated.
The metadata is used to govern the data and provide guardrails to protect its access and use, and AIDE also transforms – vectorizes – the data for LLM/agent use. Knowledge graph technology is being evaluated so that structured database records (block data) can also be used by the AI agents. There are four AIDE components covering these functions;
Metadata engine – automatically generates a structured, up-to-date, interactive view of a NetApp data estate, with lightweight, optimized ASPs for querying
Data Sync – maintains data recency automatically with SnapMirror for automated sync and SnapDiff for automatic change detection. Works across a global data estate.
Data Guardrails – continually scans, classifies and categorizes data across hybrid multi-cloud environments. Identifies sensitive data and risks and facilitates policy creation for automated sensitive data handling. Sensitive data can be automatically redacted or excluded.
Data Curator – data discovery, search, vectorization, and retrieval.
AIDE contains a vector database so that the unstructured data it manages can be used by LLMs and agents in semantic searches.
The AIDE system uses the Nvidia AI Data Platform reference design, which includes Nvidia GPUs, AI Enterprise software including NIM microservices for vectorization and retrieval, which joins advanced compression, fast semantic discovery, and secure, policy-driven workflows. AIDE will run natively within the AFX cluster on top of the optional DX50 data control nodes. Future ecosystem support includes the integration of Nvidia’s RTX PRO Servers featuring RTX PRO 6000 Blackwell Server Edition GPUs.
The subscription-based NetApp Keystone STaaS (Storage-as-a-Service) for Enterprise AI is based around AFX, the AIDE software, and built-in cyber-resilience. Its performance and capacity scale independently on demand. NetApp says it features pay-as-you-go pricing and predictable billing.
Ransomware resilience
NetApp’s Ransomware Resilience, previously called Ransomware Protection, is an integrated AI-powered ransomware detection facility. There are two new capabilities: data breach detection at storage level, which is a claimed first, and isolated recovery environments – clean rooms – to enable safe and clean recovery of mission-critical data.
The data breach detection is AI-driven and identifies anomalous user and file system behaviors that are early indicators of potential data exfiltration; a breach attempt. When a breach attempt is detected, Ransomware Resilience automatically alerts the customer via their security information and event management (SIEM) setup. Customers can also block further unauthorized transfer of sensitive data.
The isolated recovery environment uses AI-powered scanning to identify corrupted data and the point at which it was modified. It then guides the user through a workload restoration process of the most recent safe data.
NetApp says its ONTAP Autonomous Ransomware Protection with Artificial Intelligence (ARP/AI) now supports data stored in file and block protocols. It has demonstrated 99 percent detection of tested, full-file encryption ransomware attacks with zero false positives in external testing and validation.
Google Cloud
NetApp is improving and extending the integration of ONTAP services into its Google Cloud NetApp Volumes (GCNV) offering. This is a fully-managed file service based on NetApp’s ONTAP operating system running on the Google Cloud Platform as a native GCP service. It supports NFS V3 and v4.1, and SMB, and provides snapshots, clones, replication, and cross-region backup.
Now it’s getting three enhancements;
Block Capabilities: The Flex service level now supports unified storage with both NAS (NFS/SMB) and SAN (iSCSI block) protocols. This better enables customers to use Google Cloud for their enterprise business appls, such as hosting virtualized environments and managing databases.
Gemini Enterprise Integration: Customers can use data stored in NetApp Volumes as a native source for AI Applications front-ended by Gemini Enterprise, Google’s platform for automating business workflows using its Gemini family of machine learning models. NetApp says customers can build bespoke AI agents without custom code or RAG pipelines, and with context-specific data from reputable, vetted sources, improving the quality and reliability of AI-generated outputs.
Enhanced Unified Global Namespace: Enterprises can now extend their unified global data estate across cloud and on-premises environments into Google Cloud with new FlexCache capabilities in NetApp Volumes. Data stored in other ONTAP-based storage in customer data centers or across multiple clouds can be instantly made visible and writeable in a NetApp Volumes environment, but with data transferred granularly only when requested. This allows for a customer’s entire hybrid cloud data estate to be seamlessly accessed in Google Cloud. Customers can migrate data and snapshots effortlessly between environments using SnapMirror, supporting hybrid use cases such as cloud migration, disaster recovery, and workload balancing across environments.
NetApp’s Pravjit Tiwana, SVP and GM of Cloud Storage and Services, said: “Our customers will benefit from consistent low-latency performance, enhanced data management with features like snapshots and replication, and the operational simplicity of managing both file and block storage from the same NetApp Volumes service.”
Other INSIGHT 2025 news
NetApp made other announcements including new & expanded collaborations with Red Hat, Equinix, and Cisco, aiming for deeper integration across hybrid cloud, virtualization, and AI infrastructures.
NetApp is now running its development and testing engineering environments on Red Hat OpenShift Virtualization, enabling faster provisioning, reduced complexity, and greater agility. Red Hat has built an intelligent data infrastructure that leverages NetApp ONTAP technology to power its global IT and development operations, enabling faster software delivery and improved operational efficiency.
NetApp and Red Hat have introduced new systems that bring together Red Hat OpenShift Virtualization with Amazon FSx for NetApp ONTAP and Red Hat OpenShift Service on AWS (ROSA), as well as Google Cloud NetApp Volumes on OpenShift Dedicated on Google Cloud.
The Equinix news is about SAP customers currently running or planning to move to S/4HANA having a path to move to a hosted virtualized managed services environment running VCF and NetApp ONTAP to optimize cost, efficiency, and security.
The NetApp AFX will soon feature in a FlexPod AI offering, which includes Cisco UCS servers and Nexus data center switching.
NetApp has introduced an Object API for Seamless Access to Azure Data & AI Services. Customers can now access their Azure NetApp Files data through an Object REST API. They no longer need to move or copy file data into a separate object store to use it with Azure services. Instead, NFS and SMB datasets can be connected directly to Microsoft Fabric, Azure OpenAI, Azure Databricks, Azure Synapse, Azure AI Search, Azure Machine Learning, and more.
Availability
Google Cloud NetApp Volumes block capabilities are now generally available to customers upon request. The strengthened Gemini Enterprise Integration is available in preview on customer request. The Object API for Seamless Access to Azure Data & AI Services is also in public preview.
Learn about the full set of new capabilities in Google Cloud NetApp Volumes and other updates across the NetApp portfolio here.
AWS and the other top CSPs would like to migrate mainframe applications to their public clouds but many of these incredibly sticky apps tend to stay where they are. VirtualZ provides a halfway house, making mainframe data accessible to public cloud apps.
AWS Transform for Mainframe is a service that helps organizations move their old mainframe applications to AWS without having to rewrite everything from scratch. It scans mainframe COBOL, PL/I, JCL, and database definitions to understand how the mainframe app works. Next, it automatically converts that code into languages like Java, C#, or compatible AWS-native formats. It moves mainframe databases and files into AWS services like RDS or S3. Then it rebuilds and helps set up and test the converted applications on AWS infrastructure, finally running and managing the new apps.
That’s the theory, but the process may not result in a complete migration off the mainframe, and VirtualZ can help with bridging software. We discussed this with co-founder and CEO Jeanne Glass.
Blocks & Files: Tell me about the top four public clouds and mainframe data access and migration.
Jeanne Glass
Jeanne Glass: All four major public clouds – AWS, Google Cloud, Microsoft Azure, and Oracle Cloud Infrastructure – have modernization strategies focused on bridging mainframe workloads with the cloud.
While each takes a different approach, the biggest common challenge remains data access: connecting high-value mainframe data securely to modern platforms. AWS leads with its Mainframe Modernization and AWS Transform for Mainframe initiatives.
Google Cloud is expanding its Dual Run and AI-driven migration offerings, while OCI focuses on enterprise re-hosting and partner-driven migration frameworks.
VirtualZ works across all four – providing no-code, out-of-the-box connectivity between IBM Z, distributed and cloud environments to make data readily available for AI, analytics, and modernization.
Blocks & Files: Tell me more about AWS Transform for Mainframe. What is it for and what does it do?
Jeanne Glass: The genesis of AWS Transform traces back to AWS’s 2021 acquisition of Blu Age, a French software company specializing in model-driven code transformation. Blu Age’s modernization framework now forms the foundation of AWS Transform’s AI-based automation.
AWS Transform generates cloud-native, Java-based code. There’s an optional “Reforge” step that enhances the generated Java code for better readability, maintainability, and alignment with cloud DevOps practices. AWS Transform also supports Infrastructure as Code (IaC) templates for provisioning environments.
All in all, AWS Transform could slim down a mainframe-to-AWS cloud conversion process from years to months. It’s still a long time, and not all mainframe apps, especially the mission-critical ones, are being migrated, which means customers can have a hybrid mainframe-public cloud environment – which is where we can fit in.
Blocks & Files: How does VirtualZ work with AWS Transform for Mainframe?
Jeanne Glass: VirtualZ complements AWS Transform by addressing the data side of modernization. While Transform automates code analysis and refactoring, VirtualZ’s Lozen software operationalizes data access – allowing modernized COBOL or Java applications running on AWS to securely read and write live IBM Z datasets (such as VSAM) in real time, without replication or code changes.
Together, AWS and VirtualZ deliver a modernization pathway, from code transformation to live, hybrid data operations, without having completed migration off the mainframe. A VirtualZ blog discusses this.
AWS has also expressed interest in funding a direct Lozen connector for AWS Transform, similar to the existing Lozen integration with Rocket Enterprise Server. That connector would allow Transform-modernized workloads to access mainframe data in real time – completing the modernization loop from code to data to cloud.
Blocks & Files: Do Google, Azure, and OCI have equivalent services to AWS Transform for Mainframe? If so, is VirtualZ working with them?
Jeanne Glass: Each major cloud has its own modernization initiative, but none yet match the AI-driven automation of AWS Transform for Mainframe.
Google Cloud offers Dual Run and migration frameworks leveraging its AI/ML stack.
Azure provides modernization services and partner-led programs for host transformations.
OCI continues to strengthen enterprise modernization through its Mainframe Modernization Service.
VirtualZ is cloud-agnostic and actively supports integration with all of them. Our platform works consistently across AWS, Azure, Google Cloud, and OCI to enable governed, no-code access to mainframe data by applications in these clouds.
Blocks & Files: Is VirtualZ seeing a need to respond to the surge of interest in GenAI, LLMs, and agents? What needs are emerging in its customer base?
Jeanne Glass: Yes. The rise of GenAI and LLMs has made secure, governed access to enterprise data a top priority. Customers increasingly want to leverage operational and historical data – especially from mainframes – to train AI models, generate insights, and automate business processes. The challenge is providing that data to AI systems without compromising compliance or performance.
Blocks and Files: How is VirtualZ planning to respond?
Jeanne Glass: We see two clear opportunities.
Integrating with the GenAI ecosystem: enabling AI and agentic systems to request only the precise mainframe data they need—live, secure, and in native format—without replication.
Embedding AI within our software: using AI-driven inference to automatically interpret complex mainframe structures (such as SMF, RACF, or COBOL copybooks) and generate the metadata or parsers needed to make that data usable by modern platforms.
Our long-term vision is to evolve from making data available to making it understandable—reducing human effort in data discovery, preparation, and integration for GenAI, LLMs, and intelligent agents.
Bootnote
Blu Age software converted applications written in languages such as COBOL, PL/I, NATURAL, RPG/400, and COBOL/400 into Java services and web frameworks.
Toshiba has verified 12-platter disk drive technology, enabling a 20 percent increase in capacity over its 10-platter microwave-assisted magnetic recording (MAMR) technology.
The company currently ships conventionally-recorded MG11 disk drives with up to 24 TB capacity from their 10 aluminum platters, and up to 28 TB capacity MA11 shingled drives, those with partially overlapping write tracks, also with 10 platters. MAMR uses microwaves to enhance the effectiveness of the write signal applied to the perpendicular magnetic recording (PMR) recording medium on the platter surface. Adding two extra platters inside the standard 3.5-inch enclosure requires thinner platters and four more read-write heads, one for each extra surface. Toshiba is the first disk drive manufacturer in the industry to do this.
Raghu Gururangan
Raghu Gururangan, VP for Engineering & Product Marketing at Toshiba America Electronic Components, stated: “Toshiba’s 12-disk HDD platform delivers the scalability and reliability needed to support the exponential growth in AI-driven data center storage, enabling exabyte-class capacity with proven recording technologies.”
The “proven recording technologies” point is a nod to Seagate’s HAMR technology, which has been in development for decades and has reportedly faced verification challenges with hyperscaler customers. However, these challenges are disappearing.
Seagate’s heat-assisted magnetic recording (HAMR) technology enables it to reach 30 conventionally recorded TB with its 10-platter Exos 30 and 36 TB with its shingled Exos M. We are expecting Seagate to announce a 40 TB Exos M drive by the end of the year, using a fourth generation of its HAMR tech – Mozaic 4+.
Seagate has a higher density per platter – 3 TB conventional and 3.6 TB shingled – than Toshiba’s 2.4 TB conventional and 2.8 TB shingled capacities. By moving to 12-platter tech, using thinner, glass platters, Toshiba could increase its capacity to 28.8 TB conventional and 33.6 TB shingled, closer to but still not matching Seagate.
Toshiba says it aims to introduce 40 TB-class drives to the market in 2027. That implies it will use a more advanced version of MAMR to get to the 3.3 TB/platter level or above. But it will be 18 months or so behind Seagate.
Western Digital uses similar ePMR (enhanced PMR) technology to Toshiba, and 11 platters to get to 26 TB with its conventionally recorded Ultrastar DC HC590 and 32 TB with its shingled HC690 drives, 4 TB more than Toshiba’s MA11.
Toshiba is also investigating the use of 12-disk stacking technology with next-generation HAMR. That would give it the areal density increase needed to catch up with Seagate. Western Digital is also intending to adopt HAMR technology at some point in the future.
Were Seagate to adopt 11 or 12-platter technology, its capacity advantage over competitors would increase markedly.
Toshiba’s 12-disk stacking technology will be featured at the IDEMA Symposium on October 17 in Kawasaki, Japan.
Arch-rivals Samsung and SK hynix are teaming up with OpenAI to build local Stargate datacenters in South Korea as part of the chatbot maker’s global infrastructure push.
Stargate is a $500 billion OpenAI datacenter infrastructure project to build 20 AI-focused datacenters for OpenAI’s ChatGPT. The intent is to have them operating by 2029. OpenAI is partnering with SoftBank and Oracle in the project.
Reuters reported earlier in October that OpenAI was working with Samsung and SK hynix on building two datacenters in South Korea, with an initial capacity of 20 megawatts, “after OpenAI CEO Sam Altman met South Korean President Lee Jae Myung and the chairmen of Samsung Electronics and SK hynix at the presidential office in central Seoul.” There will be an SK hynix/OpenAI datacenter at Jeollanam-do and a Samsung/OpenAI one at Pohang, according to Korea’s Chosun Daily.
We understand the two Korean memory makers may help fund part of these projects.
Samsung and SK hynix will scale up memory chip production to a target of 900,000 DRAM wafer starts per month. OpenAI does not specify whether this will be standard DRAM or specialized HBM, the type of stacked memory that provides more bandwidth and capacity for closely connected GPUs than that provided by socketed DRAM to x86 CPUs.
The KED Global media outlet said it was for HBM. We understand that the Stargate orders could include server DRAM, graphics DRAM, and even SSDs as well.
KED Global says 900,000 wafers/month is double the current global production capacity. We understand that SK hynix currently operates at 160,000 DRAM and HBM wafer starts per month.
That means both Samsung and SK hynix will have to build new HBM fabs. A knock-on effect could be that they build less DRAM, which is not as profitable as HBM.
Last year, we reported that SK hynix was increasing its memory manufacturing capacity, and would invest about ₩9.4 trillion ($6.8 billion) in building an HBM fabrication plant at the Yongin Semiconductor Cluster in Gyeonggi Province, Korea. The fab construction would start in March 2025 and finish May 2027. The intention is then to add three more plants one after the other to the cluster. Another new SK hynix plant, its Cheongju M15X facility, should be complete by the end of this year.
The Stargate deals mean more than ₩100 trillion ($72 billion) of incremental demand for Samsung and SK hynix if the OpenAI order rate is consistent at that level. In effect, OpenAI is securing its HBM and other memory component supply chains for the two South Korean datacenters planned with them.
Altman said: “Korea has all the ingredients to be a global leader in AI – incredible tech talent, world-class infrastructure, strong government support, and a thriving AI ecosystem. We’re excited to work with Samsung Electronics, SK hynix, and the Ministry of Science and ICT through our global Stargate initiative to support Korea’s AI ambitions.”
Samsung and SK hynix will also look to deploy ChatGPT Enterprise and API capabilities into their operations to improve workflows and support innovation.
OpenAI also signed a series of agreements to explore developing AI datacenters in Korea. These include a Memorandum of Understanding with the Korean Ministry of Science and ICT (MSIT) to evaluate building AI datacenters outside the Seoul Metropolitan Area, supporting regional economic growth and job creation.
There is a separate partnership with SK Telecom to explore building another AI datacenter in Korea, and an agreement with Samsung C&T, Samsung Heavy Industries, and Samsung SDS to assess opportunities for additional datacenter capacity in Korea.
Sustained chatbot demand
Will there be the sustained AI chatbot demand that could sustain such vastly expensive datacenter building and memory fabrication projects? Altman spoke to analyst Ben Thompson in a Stratechery interview after “OpenAI launched a number of new initiatives, including Apps in ChatGPT.”
OpenAI is “introducing a new generation of apps you can chat with, right inside ChatGPT. Developers can start building them today with the new Apps SDK, available in preview.”
“Apps will be available to all logged-in ChatGPT users outside of the European Economic Area, Switzerland, and the United Kingdom on Free, Go, Plus and Pro plans. Our pilot partners–Booking.com, Canva, Coursera, Figma, Expedia, Spotify and Zillow are also available today in markets where their services are offered starting in English. More pilot partners will launch later this year and we expect to bring apps to EU users soon.”
We might imagine that enterprise apps could become available inside ChatGPT as well.
Altman told Thompson: “Most people will want to have one AI service, and that needs to be useful to them across their whole life. And so you’ll use ChatGPT, but you’ll want it to be integrated with other services and so you need to have other apps inside of ChatGPT.”
ChatGPT will act as the front end, with other apps integrated but still visible within it. Altman said: “We’ve been thinking about apps and ChatGPT and how we’re going to unify the API and the consumer business for a long time.”
He remarked: “My favorite analogy for AI, my favorite historical analogy, is the transistor… I think it will just kind of seep everywhere into every consumer product and every enterprise product too.”
Where the transistor underpinned the development of hardware underlying IT, as a base component, ChatGPT will overlay everything as a top layer, not a bottom layer, in this view.
If this works, consumer use of ChatGPT would be enormous, and keep these Stargate datacenters busy.
Thompson asked about Altman’s enormous deals with Nvidia and AMD and TSMC, and queried: “Who do you expect to pay for it? Is this a matter of what these deals are about, you guaranteeing you’ll buy the output of it and you need these companies to invest?”
To which Altman responded: “Yes, I expect OpenAI revenue to pay for it.”
We would imagine this applies to the Samsung, SK hynix, and other deals in South Korea as well.
Thompson: “Do you see yourself almost as a financial guarantor who’s helping them secure better interest rates?”
Altman: “Yes, but we will help with financing. We are working on plans to be able to help with the financing these companies need at this kind of scale ahead of revenue.”
Thompson also asked specifically about the Samsung and SK hynix deals: “One of the surprising deals, just to get in the weeds a little bit, was with Samsung and SK hynix. Obviously memory is a massive constraint as far as building out these chips in the future, is this sort of tied into the AMD deal?”
Altman: “Give us a few months and it’ll all make sense and we’ll be able to talk about the whole – we are not as crazy as it seems. There is a plan.”
Bootnote
Samsung has more good news. Wedbush analyst Matt Bryson told subscribers that Jensen Huang has personally informed Samsung that its HBM3e has passed Nvidia’s quality qualification tests and that Nvidia intends to place orders. Bryson says the two companies “are now reportedly fine-tuning details such as volume, pricing, and delivery schedules.”
Enterprise data services supplier CTERA envisions a future where office workers create their own virtual employee assistants – domain-specific AI agents that work with curated private datasets using the Model Context Protocol (MCP).
CTERA emerged from the enterprise file sync and share era and has evolved into an intelligent data services platform. The company offers a software-defined, multi-protocol system with a globally addressable namespace spanning both file and object storage. Data remains accessible in real-time from any location, over any protocol, while being stored economically in object storage – whether Amazon S3, Azure Blob Storage, or on-premises S3-compatible targets. The platform extends access through intelligent caching, ensuring frequently accessed data stays local.
After introducing its data intelligence platform a year ago, CTERA is now revealing more details about its AI-focused vision.
Aron Brand.
Outlining the fundamental issue plaguing enterprise AI initiatives, CTO Aron Brand told an IT Press Tour audience: “We’ve seen that there’s a naive approach right now when companies or organizations try to train AI on their private data, and they’re saying … we’ll just point our AI tools at all our data. We’ll vectorize everything. We’ll add a RAG layer, and we’ll plug in GPT 5, the smartest model that we can find, and then we sit back and watch the magic happen.”
The reality is far less magical. “Gen AI is very good at producing very confident mistakes when you provide low quality data,” Brand warned. Poor data quality doesn’t improve through AI processing – it just produces more convincing errors.
VP for alliances Saimon Michelson set the scene by saying three steps are needed to deal with data growth, security and AI.
Location intelligence – understand what data data exists across the enterprise through a globally-addressable namespace.
Metadata intelligence – Index it and create and organize metadata to create a secure data lake
Enterprise intelligence – analyze and process data using AI and other tools.
Saimon Michelson.
He likens this to three waves: “Wave number one is we’ve created a library. A library of all the content that we have everywhere. Wave number two is, we’ve sorted this library, based on the indexes, and we can find things. Wave number three is actually opening the books and seeing what is written in that book, what is reliable and how it can better help our business.”
“That’s really how we envision this kind of road that inevitably, every organization is going to take.”
CTERA recognizes data lives everywhere: distributed on-prem data centers, edge sites, and the public cloud regions, and with remote office workers. “The only model we can think of is hybrid,” Michelson said. “That’s why we’re seeing hybrid becoming kind of a bigger share in the in the market. We’re not here saying that cloud is decreasing or that on-premise is decreasing. I think the whole pie is becoming bigger and bigger.”
It is inevitable, according to CTERA, that enterprises and organizations will need a unified data fabric, with a natural language interface. Michelson said: “There’s all these large language models that can help me.
“It’s natural language. We can talk to it like we talked to another human. That’s the Holy Grail.”
Brand says the enterprise intelligence area is a new focus for CTERA: “something that we believe will become an essential part of any storage solution in the next few years. This is what we call enterprise intelligence, or turning your data into an asset by actually peering into the content.”
He identified the root causes of AI project failures: bad data trapped in separated silos with poor access controls and inadequate security. The solution requires two elements. First, AI-assisted tools for data classification and metadata enrichment to impose order on messy data. Second, an unstructured data lake that consolidates information from disparate locations into a unified format, converting PDFs, Word files, and other documents into something Gen AI can understand and store in an indexed data lake.
“[We’re] providing new tools that allow you to classify your data, to enrich the metadata, and to split your data into meaningful data sets that are high quality in order to feed your AI Agent,” Branded revealed. “You need the tools to help you to curate [your data].”
Traditional approaches copy enterprise data into Gen AI tools – a security nightmare. CTERA takes a different approach.
“The key element here, I believe, is not avoiding the copying of the data from enterprise sensitive systems into the Gen AI tools, but having the Gen AI tools have the ability to connect to the source data, without a copy, while at the same time enforcing the permissions on the source file system. So if you have files and documents that have permissions or ACLs, as long as the users that are querying this AI system, the system is fully aware of their credentials and their group membership and it’s enforcing the same permissions, then we’re relatively safe.”
“I think this is currently the holy grail of the industry; having an intelligent data fabric that consolidates all the data from different parts of the organization, from different data repositories of different data formats, bringing this all into a data fabric that allows Gen AI to have access to high quality, curated and safe.”
CTERA is providing a pipeline that transforms messy, uncurated information into something that is Gen AI-ready.
The system ingests documents from storage silos (NFS exports, SMB shares, S3 buckets, OneDrive, SharePoint) and extracts textual information into a unified markdown format. This includes transcribing videos and audio, converting images to text, and performing OCR.
AI analyzes content to create a semantic layer. For contracts, this might extract signatories, dates, amounts, and other conceptual information, enabling more accurate searches and analytics queries, such as how many contracts exceed $1 million? The system scans for sensitive data – personal information, health records, confidential material – and removes risky content. After curation, data is vectorized and inserted into searchable indexes (vector or full-text). Users can retrieve data relevant to their specific inquiries and insights.
The end game is what CTERA refers to as “virutal employees” – AI agents that serve as subject matter experts on specific business aspects.
“I don’t want this necessarily to work in a chat interface. Maybe if the users are in Microsoft Teams. I want this virtual employee to join our meetings. I want this virtual employee to be in my chapter,” Brand said. “I want them to be in my corporate data systems, everywhere that I am. I want these virtual employees to be to be there and help me do my work more efficiently, and allow me as an employee to focus on things that are more interesting and more creative.”
Some years ago CTERA added a notification service to its global file system: “which is really the foundation for this third wave. It’s a publish, subscribe system that allows various consumers to register to data that is in the global file system and to understand when a file is created, when a file is deleted, renamed, and to be able to respond to this.”
“And now as part of our CTERA data intelligence offering, which is an optional add on to our platform, we’re providing another client for the notification service, which is creating a permission-aware repository of curated enterprise knowledge,
“You can think of it as a system that includes all the steps that I mentioned before, the data curation, the consolidation of the data, to unify formatting of the data, the guardrails for security and the ability to deploy agents or virtual employees. All are provided within the system.”
The intent is to provide trustworthy answers to any question an employee might have on their area of the business, with the ability for it to be highly secure. Brand claims many systems provide RAG and provide search capabilities, but few do so in a way that is suitable for the most sensitive enterprise, or military or federal or government companies. Underpinning this system is MCP, or model context protocol.
Brand said: “We have decided to go all in on MCP… We think that this is more than a trend – this is a fundamental shift. We believe that any enterprise storage solution that won’t have MCP in the next year will essentially make your data, your AI blind to your data.
CTERA uses both MCP client and server components. “The MCP client allows our system to invoke essentially any external tool. There are hundreds or 1,000s of MCP tools available today, starting for anything from sending emails, querying databases, searching the web, generating images, triggering workflows so that our system can connect to any enterprise data source or output to any enterprise output destination,” he told the IT Press Tour audience. “We have an MCP server in various levels in our product.
The MCP server is built into the global file system at the metadata layer, enabling AI tools (OpenAI, Anthropic, Copilot) to interact with the global file system. The data intelligence component works at the content level on curated datasets, allowing clients like Copilot, Claude, ChatGPT, and Cursor to create insights from the semantic layer.
The data intelligence component is separate from CTERA’s basic global file system and can be deployed independently. “We made efforts to make sure we’re not in the data path,” Brand said. “When data intelligence reads data, it can go directly to the object storage, and that’s why it doesn’t pose as much load on our system. We bypass it, basically CTERA Direct; you could think of it as RDMA for object storage.”
The system isn’t limited to CTERA data. It’s built as a multi-source platform capable of reading from Confluence, wikis, websites, SharePoint, and other NAS systems.
He provided a customer example: “One project we’re working on with a medical firm. Today, they use doctors in order to do medical analysis of insurance claims, and so essentially, they have hundreds of documents, and it could cost 1,000s of dollars per case to analyze all these documents, and to produce a report about the case.
“We’re working with them to dramatically cut the effort that they’re spending on that and streamline this preparation by using the metadata extraction … from each of these documents. They automatically get the relevant and important fields and things and a medical summary of what happened in each of these cases. They’re able to produce this report, and they could save perhaps 80 percent of the effort.”
Comment
CTERA is demonstrating domain-specific AI agents (virtual employees) interacting with cleaned data in an entirely private platform, and reckons it is delivering reliable outcomes faster than human employees. The company is implementing an AI data pipeline on top of its storage infrastructure while keeping it architecturally separate.
As basic hybrid data storage becomes commoditized – a reality VAST Data recognized previously – the value shifts to the data access and AI-aware pipeline stack built on top. Pure Storage is pursuing a similar strategy.
The question for enterprises is no longer whether to adopt AI, but how to do so securely with high-quality, curated data. CTERA’s answer: empower employees to build their own virtual assistants using trusted, permission-aware enterprise data.
Contact CTERA here to find out more about its data intelligence offering.
Pure Storage has come a long way since it presented the world with its FlashArrays back in 2011. It’s expanded its all-flash storage portfolio with FlashBlade, Evergreen Storage for non-disruptive upgrades, developed cloud-native solutions like Portworx and Pure Fusion for hybrid and multi-cloud environments and introduced Pure1 for AI-driven management. And of course it IPO’d in 2015.
Charles Giancarlo become its CEO in 2017, and we talked about AIOPS, AI data and arrived at a data set management term in the first part of an interview. In this second part we look some more at that and move on to off-the-shelf SSDs, software stacks and copilots.
B&F: Can you tell me more about the data set management idea?
Charles Giancarlo: Let’s talk about data management versus data dataset management. And then eventually, I think we’ll take on more data management. So when data management’s talked about today, it’s talked about in the sense that you talked about before, which is this particular data store for this particular AI or analytics engine. They’re managing that. What they’re not managing is [that] this is a lot to manage, and if you try to manage all of the individual bits of data in this, I think you’d fail right now.
But in the meantime, if you manage the data sets, meaning you don’t necessarily, or we don’t necessarily know every bit of data in every dataset, but if we can keep track of the data sets themselves, not just, and again, not just the ones necessarily that we run, but where are they? What is the dataset lifecycle management? How long should they stay alive? When should they be killed?
B&F: This is generalised data management. The data could reside on somebody else’s kit.
Charles Giancarlo: Over time. I mean, we won’t get there today. We’re not there today, but over time we could get there. Okay. And what is the problem? Okay, what is the lineage of that dataset? Because it’s a copy of a copy of a copy. It is a combination of two different data sets that been put together for core analysis, that has a copy, that has a copy, and keeping track of all of this. And I’ll give you a sense why you want dataset lifecycle management.
B&F: Keeping track of all this so that you are not wasting storage space on redundant copies when you don’t need to have them.
Charles Giancarlo: You don’t need that. But there’s also the other thing, what about today? The copies that somebody made and then they left the company and nobody remembers? That’s compliance, the ghost copies, right? It’s a compliance issue. And what happens is, a lot of those eventually get part of ransomware, because what happens is they’re forgotten about, maybe not known about at all. So they’re not subject to ongoing security things such as a key rotation.
B&F: It’s just like a waiting open back door.
Charles Giancarlo: Yes. It’s out in the trash now and someone’s rummaging through the trash and they find it, and that’s a big problem. So you need lifecycle management. If it’s not touched in three months and nobody owns it, get rid of it.
B&F: Okay. Back down in the weeds. The FlashArray//ST, FAST, uses off the shelf SSDs. I was wondering; let’s take a Pure DFM, let’s reorganise it and make it SLC. Could you do that?
Charles Giancarlo: Yes.
B&F: What would the speed of that be like compared to the SSDs?
Charles Giancarlo: It’d be tremendously fast.
B&F: Which brings me to the question, well, why not do that [instead of using COTS SSDs]?
Charles Giancarlo: Actually, we could use TLC as well. Part of the reason was that what customers were really asking for was just very, very high throughput. And we also have some unique electronics that we built in there to offload a lot of the services that in our regular product gets handled by the Intel processor. So that also reduced latency, increased the overall performance. So it was for us, it was an easier way; tactical. Yes, it was tactical.
B&F: So in the future, will it survive?
Charles Giancarlo: Oh, everything we try to do, or, I should say, we’ve got a pretty good track record so far, is always evergreen. And so when you ask, will it survive, none of our stuff survives. It’s always updated every three years. [But] it will survive, I believe. Maybe it’ll just become one more of the standard, but it’ll survive. Certainly.
B&F: Do you think that Pure could get involved in high bandwidth flash?
Charles Giancarlo: So, the real question, I think in our minds, because this kind of relates to, for example, EXA, is how large and how specialised do we see a particular market? And if it’s large and specialised, then maybe using more off-the-shelf components such as, so for example, in EXA we’re using pretty standard JBODs.
Part of the reason for that is that it’s a unique market actually, compared to the overall storage market. I know I say this every quarter, but the market hears something different, compared to the overall storage market., it’s not that big a market, alright. It’s a very specialised market. Part of that specialised market is sometimes they want InfiniBand, sometimes they want Ethernet. And there’s a specsmanship aspect to this where you always have to be at the front end of the specs and we could spend more of our time on DFMs doing that, or we can buy SSDs and let them do that.
And so it’s a small enough market where we don’t get enough benefit. You’re trading off, I guess more engineering dollars to get a slight benefit versus faster time to market, and that’s the trade off we make.
I think the FAST, even though we’re excited about it; we started the design for one particular customer and we think there’s more than one customer that’ll enjoy this. But again, I don’t think it’s going to be mainstream.
B&F: It’s not generally going to be common across all your customers.
Charles Giancarlo: That’s correct. And therefore it makes sense to leverage some off the shelf technology.
B&F: Pure and Vast are both erecting very comprehensive and capable software stacks on top of their storage. They’re doing different things, but they’re very large and very capable and they’re resting on a storage hardware and storage array operating system base. But go far, far beyond that. I’d characterise NetApp, IBM, HPE and Dell as not doing that. Sure, HPE is doing GreenLake and so on, but this is just a new way of consuming storage. It’s not a new software stack.
Charles Giancarlo: Both Dell and HPE, in my view, are still doing something that I pejoratively call and they call full stack. Okay. And why do I say that’s pejorative? Full stack is a vertical architecture. What we’re saying is; okay, virtualization has already flattened and made horizontal compute. It flattened and made horizontal networking. Storage is the only thing that is still subservient to the application environment. So it’s vertical. We’re saying that should also be horizontal.
And so at this point, full stack is a hardware concept that doesn’t make sense. What you want are virtual full stacks that you can create out of software. You don’t want any physical full stacks. Right? But that’s where HPE, because they’re very much in a hardware mindset, because that’s what they do. Both Dell and HPE. So they talk about vertical full stacks as in a hardware full stack. And that’s what companies should not be doing.
This is like 10 years ago. But not now. Right? They should be creating a flexible environment. That means that you create virtualized environments for compute, for your networks, as well as, in our view, for their storage as well.
B&F: Last question. The Copilot. It’s a very Microsoft term.
Charles Giancarlo: Fair enough. Yes. But everybody’s using it for their own purposes. It’s not just us. Everybody’s using copilot now as an AI layer above their, let’s call it management or operations platform. Part of the reason why they call it copilot is most companies say, we don’t yet want to let the genie out in the box. It’s got to be a human in the loop. And that’s why it tends to be called copilot.
B&F: I shouldn’t assume that because you use the term copilot that you’re using Microsoft’s Copilot.
Charles Giancarlo: No, not at all. Not at all. In fact, we reserve the right, and we do, we use different LLMs. In fact, in some cases multiple of them, because they each have their own idiosyncrasies and benefits or detriments.
****
Charles Giancarlo is a terrific CEO to talk to for a semi-tech guy – I’m not an engineer and nor am I an analyst – like me. He can handle any type of question – about markets, about technologies, business models, SW stacks and so forth without blinking. He listens to questions and answers them in his own way without marketing-speak. He lets you have a real conversation. Its enjoyable and you learn a lot.
It wasn’t a basket case, Quantum, far from it, but it was certainly struggling on the edge, and had been for a few years when a boardroom shake-up toppled chairman, president, and CEO Jamie Lerner and installed board director Hugues Meyrath in his place as CEO.
Meyrath’s CV has a lot of entries:
Jul 1994 to Jul 1999 – Western Digital, Product Marketing Manager
Jul 1999 to Feb 2001 – Deutsche Banc Alex Brown, Research Associate
Feb 2001 to Nov 2001 – Credit Suisse First Boston, Research Associate
Nov 2001 to Dec 2002 – Sanrise, Director Business Development
Jan 2002 to Sep 2003 – Quantum, Senior Manager, Business Development
Sep 2003 to Mar 2009 – Brocade, Director Marketing & Product Manager, President of SBS subsidiary, GM & VP
Mar 2009 to Feb 2012 – Juniper Networks, VP Services then VP SW Division
Feb 2012 to Jan 2017 – EMC then Dell, VP Product Management & Business Development, EMC BRS div, VP/MD Dell Technologies Capital
Jan 2017 to Aug 2022 – ServiceChannel, Chief Product Officer, Advisor
Sep 2022 to present – Quantum, Board member
Dec 2022 to present – Startup advisor
Feb 2025 to present – NASCAR Racing Experience, part time
Jun 2025 – Quantum, president and CEO
He moved across to the USA from Belgium in 1994 to join Western Digital after graduating from the University of Louvain, Belgium, with a BS degree in Engineering and Business. He was one of the hundreds if not thousands of English-speaking tech graduates from all around the world who then saw the US as the door to a thrilling and solid future, free from the constraints holding back career development in their home countries.
While at WD, he studied for and achieved an MBA at the University of California, Berkeley, Haas School of Business. This led to his next two stops in the finance area, and then he returned to tech, as a Business Development Director at Sanrise in 2001, joining Quantum just over a year later as Senior Director for Business Development. He subsequently joined Brocade, then Juniper, followed by Dell, where his finance knowledge became relevant in a Dell Technologies Capital position, and then ServiceChannel as a Chief Product Officer in 2017.
Fortive bought ServiceChannel for $1.2 billion in mid-2021. Meyrath stayed on as an advisor, but left the following year and took on positions we might think befitting to a semi-retired and wealthy exec, including joining Quantum’s board, when Lerner was its chairman, president, and CEO. But then this year, he jumped back into full-time tech exec life to head up Quantum when Lerner left. We talked about his background and how he thinks about Quantum.
B&F: How did the Quantum board position come about?
Hugues Meyrath
Hugues Meyrath: I had phone calls from people that were invested in Quantum a long time ago. And they said: “Hey, I was referred by someone, and I had this long history with Quantum, right?” So in the ’90s, mid-’90s for five or six years, I was program manager in building heads for Quantum disk drives and heads for the Quantum DLT type drives.
[Meyrath left Quantum for Brocade in the fall of 2003 when the head of the tape automation business where he worked quit.]
Brocade was great for me. I went from a product manager all the way to being part of the exec staff, run all the product for a while, global services, then went to Juniper. And Juniper was where I learned that culture fit when you get into a job is important. It was just a culture [thing], it just didn’t work for me. So I couldn’t wait to get out of there. But I did my three years at Juniper and got recruited by EMC to be the product guy for the backup and recovery division, which they called BRS.
I took the job that Brian Biles had at the time. So I was Brian’s successor at EMC for four or five years. And then what happened is, I sit there at EMC and we are cranking out the next Data Domain, the yearly release of Networker, a yearly release of Avamar. And I started looking at all the holes that we had in the portfolio and started working with EMC venture teams on making investments in some cloud areas where we had massive gaps.
And then at some point my boss, the GM of BRS, and Scott from EMC Ventures called me and said, you should really spend your time on the venture side of things and making investments. I spent three years working with Greg Adkin who was [the] investor in storage, and I was sitting on seven, eight boards as an observer as EMC started making investments. And then, when Dell decided to purchase EMC, I worked on the integration for a year because I was a product guy.
It is just hard at some point to see people with great ideas come and present them to you and then, if you’re a product person, you just want to go do something. So I decided I was going to back away from ventures and join a company. A friend of mine had bought this weird company, ServiceChannel, that does facility management SaaS, that had about $8 million in ARR, and I decided to go help him. And we grew from $8 million to about $100 million dollars in ARR and then sold it to Fortive for $1.2 billion. It was a non-linear ride.
We went through three CTOs, three VPs of engineering, three sales guys, three CMOs. It was a hell of a ride. But then we sold it for $1.2 billion and I’m like, OK, I need a break. And that’s when I retired.
And so when I got the reference call on Quantum, I started talking to them about the different parts of the business. And then a couple of weeks later, Ben [Perl] from Neuberger Berman calls me and says, I’m in 150 companies. I can’t be on the board of every one of them. I’d like to recommend you to the board to Jamie Lerner, who was CEO. So I went and met Jamie… and we hit it off and he asked me to join the board and that’s how I ended up on the board.
B&F: Jamie’s a very nice, smart, and energetic guy, and I got the impression he relished the fight, he relished struggles, and he struggled and struggled and struggled to get Quantum growing again. But things just kept on popping out of the woodwork and biting him in the ass, like the hyperscalers and the tape libraries, the ongoing financial reporting problems that came up again and again and again. And I guess in the end, it was time for a fresh hand.
Hugues Meyrath: That’s one of the things we struggled with at the board. Jamie’s a great person, he’s a great sales guy. But I think, fundamentally, we felt that we needed a change in direction, because the plan was not working, right? At some point, things are just not working, and I’m going to have my time too. Everybody has. It’s kind of the philosophy of American tech. At some point a plan runs its course. I think an average tech company is like 11 years old, right? Quantum’s 45. So a plan runs its course and we felt as a board we just needed a new plan, and new people with new energy, and do a massive turnaround. And it had to be different. We felt like the playbook had to be different, and the people had to be different, and the investor’s different, right?
****
Part 2 of this interview will look at Quantum’s products and Meyrath’s view of their prospects.
Bootnote
Jamie Lerner is now the co-founder and managing director of Helikai, which develops and operates AI agents in vertical markets. We understand this is an AI agents-as-a-service operation.
Ataccama has announced Data Quality Gates, an extension of its data quality suite that validates data in motion across the data stack. The new capability applies rules in real time, intercepting unfit inputs before they distort analytics, compromise compliance reporting, or degrade AI models. By running checks in real time as data flows through pipelines, it prevents invalid records before they contaminate downstream systems. Instead of surfacing only after they hit dashboards or reports, flawed inputs such as incomplete transaction codes or restricted country data are intercepted immediately. This “shift-left” approach reduces remediation costs, lowers compliance risk, and ensures AI and analytics are powered by trusted inputs, the company claimed.
…
Big data analytics supplier Cloudera has developed a sovereign data and AI platform specifically for the AWS European Sovereign Cloud. Cloudera is working with AWS to provide joint customers with a sovereign-by-design data and AI platform to store and analyze data within EU borders. This sovereign-by-design system will align with regional sovereignty and compliance mandates, we’re told, making it especially well-suited for highly regulated industries and public sector organizations.
…
DDN has released an SK Telecom case study describing its role in the Petasus GPUaaS cloud, about which VAST Data has also released a case study. SK Telecom is studiously quiet about the role of the two storage vendors in its GPUaaS development. Neither acknowledges the other’s role in SKT’s GPUaaS development or offering. Our understanding is that:
Both DDN and VAST Data have been involved with the SK Telecom Petasus GPUaaS development in South Korea. DDN initially, followed by VAST Data.
Later, VAST Data was also involved with Petasus in South Korea and DDN is now involved with Petasus in Japan.
It also appears that the Petasus cloud can work with either DDN EXAScaler or VAST Data storage.
Neither supplier has responded to requests to confirm or deny this.
…
ExaGrid released a new AI-powered RTL feature: Auto Detect & Guard. According to the pitch, the Auto Detect & Guard feature monitors all daily operational deletes, trains/learns, and creates patterns. If a delete request is outside of the pattern, the customer’s IT team is alerted and ExaGrid automatically extends the delayed delete policy so data in the Repository Tier is never deleted. If the delete was an operational delete, the IT team can clear the alert and ExaGrid will return to the original delayed delete policy. This provides two benefits: an early warning of a possible cyber attack where the attackers are trying to delete the backup data and ensuring that the backup data is not deleted on ExaGrid’s non-network-facing Repository Tier.
…
Data source connector and mover Fivetran announced GA of the Oracle Binary Log Reader, a new replication method within its managed service that enables high-volume, low-latency replication from Oracle databases. Fivetran is also expanding its Oracle offering with several features intended to give customers more flexibility and control over their data pipelines. Oracle as a destination allows enterprises to integrate data from more than 700 pre-built sources – or custom pipelines built with the Fivetran Connector SDK – directly into Oracle, providing an automated path to centralize data for analytics and AI. New row filtering capabilities let teams replicate only the data they need, reducing costs and improving downstream performance, while data type locking ensures consistency between source and destination systems by locking data types for critical workloads.
…
Data security supplier Forcepoint announced the expansion of its Self-Aware Data Security platform to protect enterprise databases and structured data sources. It extends AI Mesh Data Classification technology across both structured and unstructured data throughout the hybrid enterprise, delivering unified Data Security Posture Management (DSPM) and adaptive data loss prevention in a single platform. As enterprises accelerate SaaS, cloud, and AI adoption, structured data remains a critical blind spot. Databases and data lakes house customer records, financial assets and intellectual property but have lacked consistent visibility and policy enforcement alongside files, emails, and SaaS apps. By extending AI Mesh Data Classification to structured sources, Forcepoint enables organizations to discover, classify and remediate risks in real time with a single-policy framework.
…
Hitachi Vantara is working toward a strategic partnership with Supermicro, to combine Supermicro’s GPU and AI compute capabilities with the performance and scale of Hitachi Vantara’s Virtual Storage Platform One (VSP One), giving enterprises a foundation for driving AI infrastructure, mission-critical applications and data-intensive workloads. The parties are finalizing terms of an agreement that would enable Supermicro to sell VSP One to its customers, and Hitachi Vantara will be able to sell Supermicro servers, storage, GPUs, and hardware systems, broadening availability through established channels. The companies anticipate making these technologies available through global channels, including VSP One Block, VSP One SDS (block) and VSP One Object. [We’re told VSP One file wil also be involved.] VSP One can also be managed through the VSP 360 unified control plane, which integrates data management tools across a storage environment to monitor key performance indicators, including storage capacity utilization and overall system health.
…
Kioxia has announced an expanded RocksDB plug-in that ups SSD lifespan and performance in multi-drive RAID environments. In a 4-drive RAID 5 setup, Kioxia’s new plug-in reduced write amplification factor (WAF) by approximately 46 percent and boosted throughput to 8.22x the performance of MDRAID (Linux software RAID). In a 2-drive mirrored configuration, WAF was reduced to approximately 1/3 and achieved throughput of 1.45x compared to MDRAID. The technology achieves these gains by consolidating data writes, so they are written sequentially – preventing data fragmentation and reducing garbage collection. Kioxia will release the plug-in as an open-source contribution. The new plug-in will be featured with the Kioxia XD8 Series SSD in a live demonstration at the Kioxia booth (A51) during the 2025 OCP Global Summit.
…
NetApp says a global study it conducted with IDC shows the AI race is no longer about who adopts AI first, but who builds the strongest foundation behind it. The research finds that organizations with the most advanced data and infrastructure strategies are pulling ahead, translating AI experimentation into business results. According to the study, these “AI Masters” are seeing 24 percent revenue gains and 25 percent cost savings compared with less mature peers.
…
VAST Data says it has a customer with 1.5 EB of storage capacity. That would equate to, for example, more than 24,400 of Solidigm’s 61.44 TB QLC drives. We suspect it’s an AI-focused hyperscaler deployment – potentially Coreweave or Colossus.
…
ReRAM developer Weebit Nano has taped-out (released to manufacturing) test chips featuring its embedded Resistive Random-Access Memory (ReRAM) module at onsemi’s 300mm production fab in East Fishkill, NY. The chips are being developed in onsemi’s Treo platform, which is a 65nm Bipolar-CMOS-DMOS (BCD) process. Coby Hanoch, CEO of Weebit Nano, said: “Our collaboration with onsemi is progressing rapidly, and this successful tape-out marks a major milestone in completing the technology transfer of Weebit ReRAM to onsemi’s advanced BCD process. We’ve already validated our technology on multiple wafer lots using onsemi’s tools and flow, optimizing the process and demonstrating solid performance and reliability. We’re now progressing towards qualification.”
HYCU has had its status for data protection in hybrid clouds raised from Challenger to Leader by GigaOm in its 2025 Cloud Data Protection (CDP) Radar report, as presented to an IT Press Tour audience.
The CDP report covers 23 suppliers and the bulk of them,15 and all the Leaders, are grouped in the lower right Platform Play – Innovation quadrant. GigaOm’s Radar evaluates supplier products in a technology area and locates them in a 2D circular space, a quasi-radar display screen, featuring concentric rings – leader, challenger, and new entrant. Those set closer to the center are judged to be of higher overall value. Each vendor is characterized on two axes – balancing Maturity versus Innovation and Feature Play versus Platform Play. There is an arrow indicating the supplier’s development speed over the coming 12 to 18 months, from Forward Mover, through Fast Mover to Outperformer.
Here’s the 2025 GigaOm CDP Radar diagram;
Prevously GigaOm issued separate Cloud-native and Hybrid Cloud Data Protection Radars. In the 2024 issue of GigaOm’s Hybrid Cloud Data Protection (HCDP) report HYCU was classed as a Challenger in the lower reaches of the Feature Play/Innovation quadrant.
GigaOm HCDP Radar diagram in 2024 report.
Its position has changed dramatically, as it has crossed over into the Platform Play/Innovation quadrant and is now classed as a leader. GigaOm’s analyst notes that HYCU’s R-Cloud offering has “rapid RTOs and comprehensive end-user self-service, and world-class cross-cloud mobility.
Cobalt Iron has also been promoted from a 2024 Challenger to a 2025 Leader, crossing from the Feature Play/Innovation quadrant to the Platform Play/Innovation quadrant as well.
The overall leader is Druva, followed by nine other leaders, with Commvault closest. Druva’s Ranga Rajagopalan, chief products and marketing officer, said: “With DruAI, we’re helping organizations rapidly detect anomalies, guide clean recoveries, and automate protection workflows — all within a fully managed, 100 percent SaaS platform. GigaOm’s recognition validates our vision for making cyber resilience autonomous, where built-in AI and cloud-native simplicity work together to keep data secure without added complexity.”
There were nine leaders in the 2024 version of this report but, since then, two of them have become one, with Cohesity buying Veritas, HPE/Zerto has dropped back to Challenger status, while AWS and Microsoft are new entrants to this Radar, being cloud-native, and jumping straight to leadership status.
A comparison between the included suppliers in the 2024 and 2025 Radars reveal relatively few changes;
However, some of the supplier positioning moves in GigaOm’s HCDP Radar since 2022 seem almost bizarre, witness Barracuda and Kaseya (Unitrends);
Barracuda and Kaseya (Unitrends) positional changes in the 2022 to 2025 GigaOm HCDP and CDP Radar report diagrams.
Such pronounced changes suggest analyst and criteria changes. We checked and the report analysts have been;
2024 – Dr. Shane C. Archiquette – with large changes from 2023
2023 – Max Mortillaro and Arjan Timmerman – with small changes from 2022
2022 – Max Mortillaro and Arjan Timmerman
The large changes in supplier status on this Radar correlate perfectly with analyst changes.
Bootnote
Five suppliers did not provide direct input to the GigaOm report, with the analyst relying purely in desk research: Cohesity, IBM, Kaseya, Microsoft and Open Text.
The Aston Martin Aramco Formula One Team (AMF1) has completed its migration to run 100 percent of its data storage on NetApp.
NetApp’s systems are used by the AMF1 team for AI-powered design, simulation, and race-day strategy. They support telemetry analysis, help optimize race strategies, and improve car performance on and off the track. This enables faster design-to-build cycles and improved performance. We’re told that NetApp enables AMF1 to run complex simulations faster and more efficiently by providing high-throughput data storage and seamless access to massive datasets across hybrid cloud environments. This accelerates design iterations, allowing engineers to refine aerodynamics and strategy before the car even hits the track.
Fabrizio Pilotti
AMF1 CIO Fabrizio Pilotti said: “From simulations in the CoreWeave Wind Tunnel and CFD workloads to trackside telemetry, we generate and analyze petabytes of data in the pursuit of building a winning car and a winning team. NetApp provides scalable and secure infrastructure tailored for AI capability and other high-performance computing workloads, which gives us the power we need to make the right data-driven decisions across design, simulation and race-day strategy.”
The NetApp storage is based around converged infrastructure rack-scale FlexPod systems with StorageGRID scalable, geo-distributed object storage, containers with Kubernetes, the Astra Trident data connectivity and storage orchestrator, and VMware, integrated with Cisco UCS compute servers, and Nexus and MDS networking.
The system features a NetApp BlueXP control plane spanning all its workloads from the factory in Northamptonshire, UK, to race tracks and in the public cloud. This simplifies management and increases data availability.
Spot the NetApp logo on the nose cone
We should understand that there is a FlexPod setup at each F1 race track as well as at the Northamptonshire factory. It receives and stores radioed telemetry from the AMF1 cars during the race. Telemetry data can be transmitted to the factory in about ten minutes, where it can be put into a simulator system with a test driver to see what race car settings can be changed to improve things like tire degradation, ride height, and airflow over the car. NetApp’s SnapMirror technology is used to transfer data post-race back to the UK AMF1 operation.
Gabie Boko
NetApp CMO Gabie Boko said: “Formula One is one of the most demanding technical environments in the world. Races are won by split-second determinations on the track, built on a foundation of thousands of design and engineering decisions over the preceding weeks. The Aston Martin Aramco team needs prompt access to massive datasets from multiple sources without wasting time or resources on orchestrating data across different platforms.”
Prior to 2023, the AMF1 team’s storage systems came from Pure Storage, via a deal with ServiceNow, with that deal starting in 2020. It provided FlashArray//M all-flash storage systems to manage the AMF1 team’s data demands, including telemetry and analytics. Although ServiceNow is still an AMF1 technology provider, the storage supplier role has been taken over from Pure Storage by NetApp.
Now, two years after taking on the storage provider position at AMF1, NetApp has finished migrating the data off the Pure arrays, with their block storage, onto its StorageGRID object-based systems.