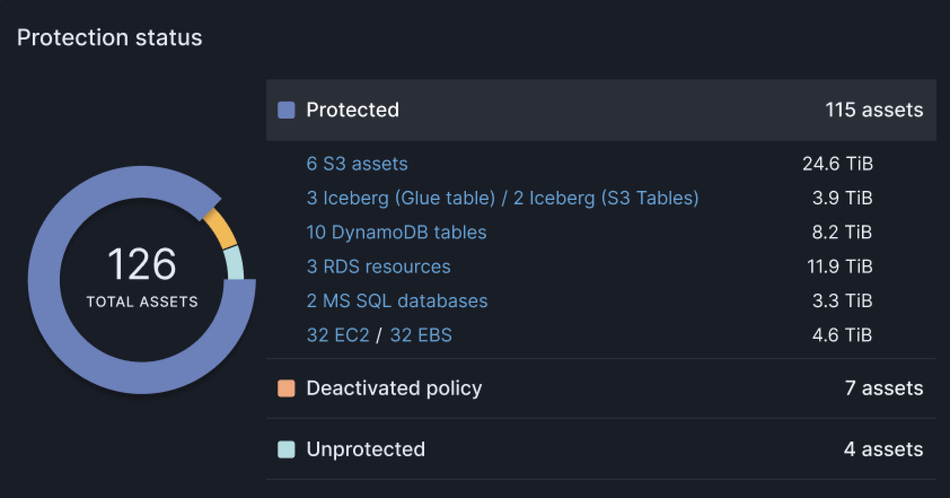
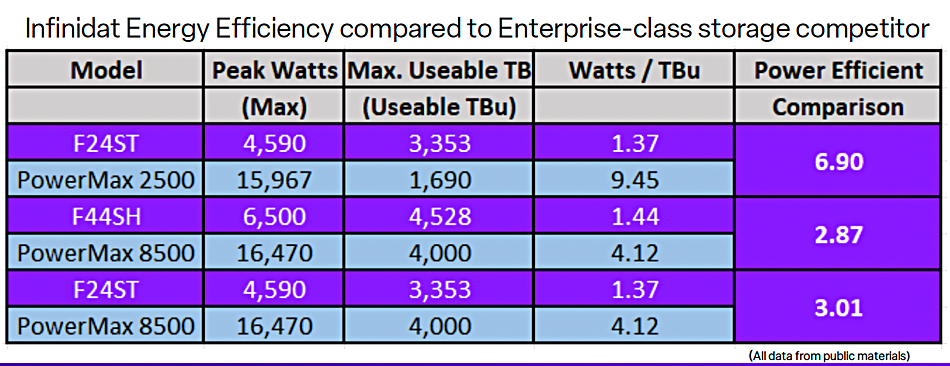
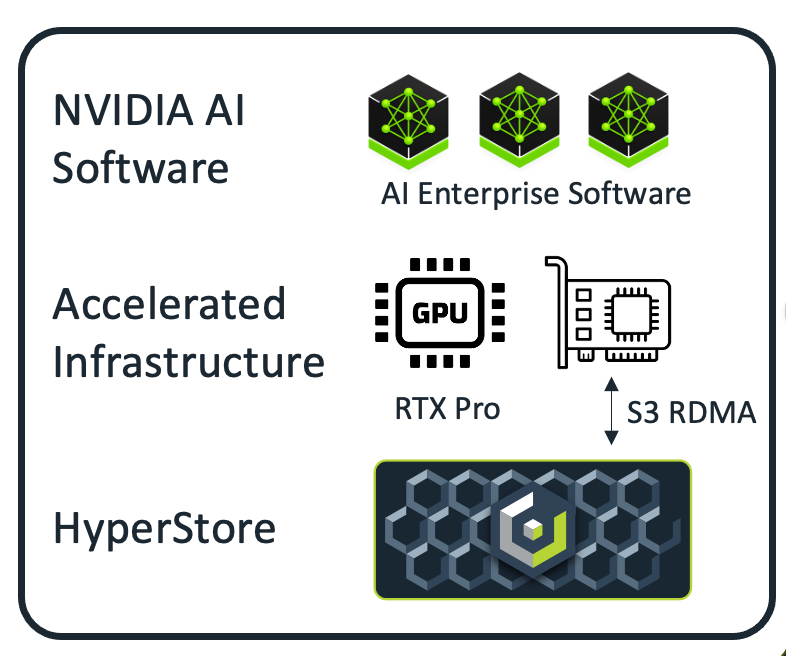
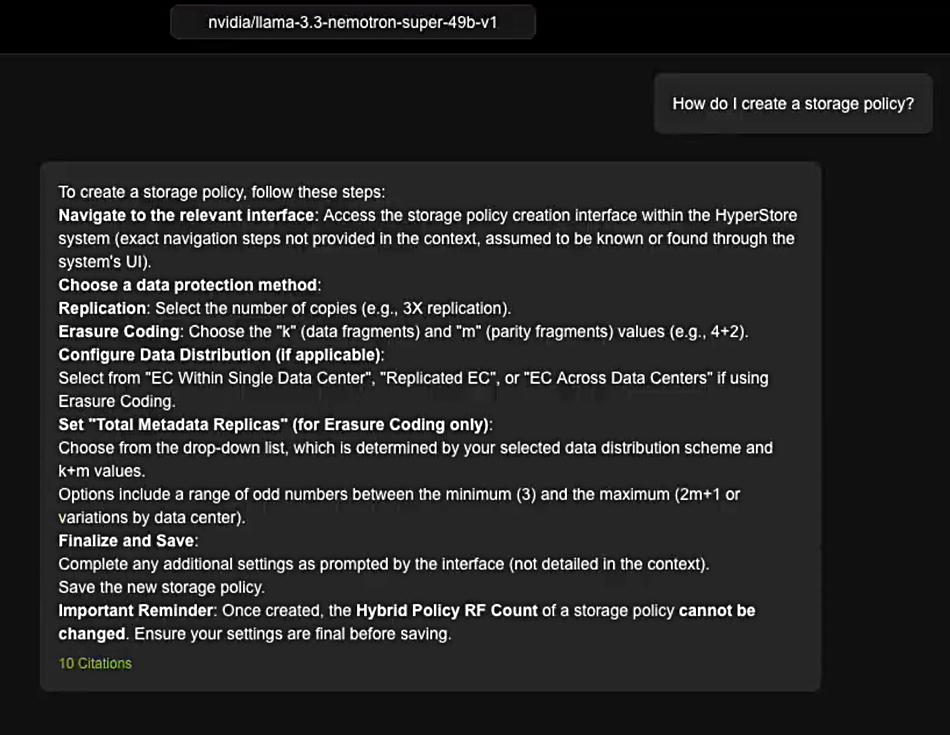
Data protector Acronis announced GA of True Image 2026 with built-in patch management for Windows and a strengthened security engine with AI-based threat detection, anti-ransomware, and malware scanning. Acronis claims it is the first consumer software to proactively safeguard against emerging cyberthreats and provide identity protection, fast backup, easy recovery, and advanced cyber protection in an all-in-one tool. Acronis True Image 2026 can be applied to five computers and unlimited mobile devices. Learn more here.
…
Automated data exchange supplier Adeptia announced a rebrand of its flagship Connect platform as Adeptia Automate. With new AI-enhanced capabilities, the end-to-end data platform helps data experts and business users manage first-mile data with greater speed, control, and ease. Adeptia Automate pairs AI-guided data mapping with a modern UX and scalable and flexible architecture to turn disconnected data into actionable intelligence, helping modern enterprises eliminate IT bottlenecks, speed up partner onboarding, and boost enterprise efficiency. It has enhanced usability, enterprise-grade scalability, frictionless operations, and increased data governance.
…
US-based cybersecurity firm Blue Goat has criticized UK government moves to prohibit public bodies and critical national infrastructure (CNI) operators from paying ransom demands and requiring private organizations to notify authorities if they intend to make a payment. It says bans will push adversaries to adapt, and that adaptation can be painful for victims who lack contingency plans. “Organizations should assume attackers will pivot to data theft, crippling disruption and supply-chain targeting. The immediate priorities for UK organizations are straightforward: harden defenses, test incident response, and ensure you have a credible recovery plan that does not depend on ransom payments.”
…
Data protector CloudCasa released a software update featuring:
- Backup to NFS storage: In addition to object storage, CloudCasa now supports backups directly to NFS targets, providing greater flexibility for on-premises and edge environments.
- File browsing and download for VM backups: Users can now browse and download individual files from virtual machine disks and file systems, enabling quick file-level recovery without restoring the full VM.
- Disaster recovery restore for Longhorn volumes: CloudCasa adds a streamlined disaster recovery (DR) restore option for Longhorn environments with DR volumes configured for continuous data replication between clusters, simplifying recovery during failover scenarios.
…
The London Stock Exchange Group (LSEG) is partnering with Databricks so that financial firms can deploy AI agents directly on live LSEG market data. This will bring AI-ready financial data – starting with Lipper Fund Data & Analytics and Cross Asset Analytics – natively into the Databricks platform. Customers can now combine LSEG market data with their own, enabling them to build and deploy governed AI agents for real-time investment analytics, risk management and trading workflows using Databricks’ Agent Bricks. For analysts, the company claims this means fewer hours wrangling legacy data feeds, and the ability to run real-time investment, trading, and compliance agents within days, not quarters.
…
An independent study revealed that enterprises using the Denodo Platform alongside modern data lakehouses like Snowflake or Databricks achieve a staggering 345 percent ROI, $3.6 million in cost avoidance, payback in 6.5 months, and 3-4x faster time-to-insight. Veqtor8 published the results of this study in a whitepaper entitled “The ROI of Using the Denodo Platform alongside the Modern Data Lakehouse,” and a complimentary copy is available on the Denodo website. Denodo produces a data management platform product that virtualizes data sources.
…
MRAM developer Everspin announced a strategic collaboration with Quintauris to bring its MRAM technology into the Quintauris RISC-V ecosystem. By integrating Everspin’s MRAM technologies with Quintauris’s reference architectures and real-time platforms, the partnership works to ensure memory subsystems meet the highest standards for performance and functional safety. Everspin has shipped more than 200 million MRAM devices.
…
South Korea’s SSD controller supplier FADU has unveiled its Sierra FC6161 PCIe Gen 6 SSD controller, read and write speeds of up to 28.5 GB/s, 500 MB/s more than Silicon Motion’s PCIe Gen 6 SM8466 controller, with up to 28 GB/s speeds and 512 TB total capacity. The Sierra FC6161 supports random read/write IOPS of 6.9 million/1 million. It will operate at a sub-9 W TDP (Thermal Design Power) level.
…
Data-moving business Fivetran says clothing brand Steve Madden is using Fivetran to centralize its advertising, web traffic, and social engagement data from its global digital footprint. It relies on Fivetran to integrate data from a wide range of platforms including Facebook Ads, Google Analytics 4, Facebook Pages, Google Search Console, TikTok Ads, LinkedIn Ads, Instagram Business, and Snapchat Ads. The retailer also leverages Fivetran’s Connector SDK to bring in custom data from additional platforms like Adform.
By unifying these sources, Steve Madden’s marketing and analytics teams can view paid and organic performance side-by-side across all major channels, align campaign spend with engagement and conversion data, and eliminate the need for manual data pulls from multiple platforms.
…
Fivetran has acquired open source transformation company Tobiko Data, the company behind SQLMesh and SQLGlot. With the acquisition, Fivetran claims this strengthens its position as the only fully managed, end-to-end platform that combines data movement, transformation, and activation – making it easier for customers to deliver governed, AI-ready data with speed and scale.
This marks Fivetran’s second acquisition of the year, following its acquisition of Census to expand into reverse ETL. Last year, Fivetran surpassed $300 million in annual recurring revenue, expanded its Connector SDK to help developers build high-quality production connectors, and launched Hybrid Deployment to support pipelines across private cloud and on-premises environments. Fivetran also expanded its Managed Data Lake Service to support Amazon S3, Azure Data Lake Storage, Microsoft OneLake and Fabric, and Google Cloud Storage. The service integrates with all major data catalogs and supports open table formats like Iceberg, helping enterprises build governed, AI-ready data lakes at scale.
…
Google has added AI-based ransomware detection and recovery features to Google Drive for Desktop. It identifies attempts to encrypt a lot of files at once and stops file syncing to the Google cloud, after detecting three to five modified files. Files uploaded to Google Drive are already scanned for malware. Users get “ransomware detected” alerts and can restore affected files using the web UI. This software is in an open beta phase.
…
HighPoint Technologies has introduced the Rocket 7638D, a PCIe Gen 5 switch adapter designed with a GPUDirect Storage (GDS) hardware architecture. The adapter eliminates the traditional CPU bottleneck by enabling Nvidia GPUs to directly access massive datasets, ensuring maximum GPU utilization for AI, ML, HPC, and scientific workflows. It is the first 48-lane Gen 5 PCIe switch adapter engineered with a dedicated x16 Gen 5 pathway for both an external GPU and NVMe storage from a single slot. This architecture creates a direct, peer-to-peer data channel that bypasses the host CPU entirely. HighPoint’s hardware architecture provides a direct data path that, when paired with compatible third-party software, enables a full GDS stack.

With 48 PCIe Gen 5 lanes, dedicated x16 pathways for a Gen 5 GPU and NVMe Storage (up to 16 drives and nearly 2 petabytes), the Rocket 7638D delivers unprecedented bandwidth, capacity and performance. It simplifies deployment with native OS support and a suite of monitoring utilities, across Intel, AMD, and ARM computing platforms. Read more here.
…
HPE Alletra Storage MP B10000 has been fully integrated with AWS Outposts. This means customers can attach data volumes backed by MP B10000 storage to Amazon EC2 instances on AWS Outposts right through the AWS Management Console. In addition, customers can boot EC2 instances on Outposts directly from MP B10000 storage. Learn more here.
…
Streaming data lake supplier Hydrolix has purchased intellectual property from Quesma to continue supporting Kibana interoperability. Hydrolix had previously partnered with Quesma through a reseller agreement to bundle its Kibana gateway proxy into the Hydrolix platform. Recently, Quesma notified Hydrolix of its intent to cease support for the product, and Hydrolix worked with Quesma to purchase the technology to ensure uninterrupted support for customers who depend on the integration.
…
Kioxia and Sandisk announced the start of operation at the Fab2 (K2), a state-of-the-art semiconductor fabrication facility, at the Kitakami Plant in Iwate Prefecture, Japan. Fab2 has the capability to produce eighth-generation, 218-layer 3D flash memory, featuring the companies’ CMOS directly bonded to array (CBA) technology, and future advanced 3D flash memory nodes to meet growing demand for storage driven by AI. Production capacity at Fab2 will ramp up in stages over time, in line with market trends, with meaningful output expected to begin in the first half of 2026.

…
Observability business New Relic released its 2025 Observability Forecast report, showing that high-impact outages carry a median cost of $2 million per hour, or approximately $33,333 for every minute systems remain down. For the UK and Ireland specifically, the annual median cost of high-impact IT outages for organizations surveyed in those countries is $38 million per year. Respondents across the UK and Ireland see tool sprawl as a significant challenge, with a third (33 percent) of organizations citing too many monitoring tools and siloed data as a barrier to achieving full-stack observability, compared to the regional EMEA average of 27 percent. Access the report here.
…
Nutanix has announced the availability of its Nutanix Cloud Clusters (NC2) software on OVHcloud in the EMEA region. It provides customers the opportunity to build hybrid and multicloud deployments that support European data-sovereignty objectives. More information can be found here.
…
Veeam backup storage target device supplier Object First has released survey data that uncovers a growing crisis in the IT and cybersecurity community: 84 percent of IT professionals report feeling uncomfortably stressed at work due to rising cyber threats – and nearly 60 percent are considering leaving their jobs because of it. The survey of 500 US IT and security professionals reveals the emotional toll of being the “last line of defense” against cyberattacks:
- 47 percent feel pressure from leadership to “fix everything” after a breach
- 18 percent feel “hopeless and overwhelmed” during or after an incident
- 59 percent have thought about quitting due to stress
- 74 percent say recovery tools are too complex, fueling further burnout
To help address this, Object First partnered with Cybermindz, a San Francisco–based nonprofit dedicated to mental resilience in cybersecurity, to release resources including stress-reduction tools and a practical recovery protocol for IT professionals. Object First and Cybermindz have released a short video about this.
…
Personal Media Corporation announced its PC data erasure software “DiskShredder ToGo” has achieved ADISA Product Assurance Certification to NIST SP 800-88 following testing by ADISA Research Centre. “DiskShredder ToGo” is a data erasure software that can be used an unlimited number of times within 90 days of purchase, with no restrictions on the number of devices that can be erased. The product has been available through Personal Media Corporation’s online store since April 2025, responding to the surge in erasure demand driven by the planned end of Windows 10 support in October 2025. It’s the first Japanese data erasure software to receive certification from ADISA Research Centre.
…

The CEO of SSD controller and drive supplier Phison, Pua Khein-Seng, inventor of the USB flash drive, said in an interview reported by the Taiwanese CommonWealth Magazine that: “NAND will face severe shortages next year. I think supply will be tight for the next ten years … In the past, every time flash makers invested more, prices collapsed, and they never recouped their investments. So companies slowed spending starting around 2019-2020. Then in 2023, Micron and SK hynix redirected huge capex into HBM because the margins were so attractive, leaving even less investment for flash.”
Multibillion AI datacenter build-outs will need data storage as well as GPUs, and he thinks SSDs will take an increasing share of it. “In 2020, the SSD-to-HDD ratio in datacenters was in the single digits versus more than 90 percent. Today, it’s about 20 to 80 percent. Looking ahead, SSDs will account for 80 to 100 percent. The real question is: how much new capacity will be needed to support that transition? That’s why I say flash will remain strong for the next ten years.”
…
Mainframe-to-cloud connectivity supplier Precisely enhanced its Data Integrity Suite with AI-driven features that enable organizations to operationalize high-quality, AI-ready data faster and better. There are natural language interfaces, AI-powered rule and description generation, AI-generated sample data, and LLM integration in pipelines. Learn more here.
…
Precisely has updated its EnterWorks software, integrating master data management (MDM) with the Data Governance service in the Precisely Data Integrity Suite. The release enables organizations to link master data to policies, goals, and metrics – ensuring greater visibility, accountability, and compliance across the business. There is also a modernized user interface with visual enhancements across the dashboard, repository lists, and record detail views. Learn more here.
…
Quobyte, which supplies a distributed parallel file system, says the University of California, Davis, has moved from an NFS-based NAS system to its software for HPC storage, after evaluating it along with BeeGFS and Ceph. Data reads continue during hardware component repairs; if a node or rack is lost, the cluster continues to operate. No maintenance windows are needed for hardware or software upgrades. This results in 100 percent availability, 24/7/365, for optimal resource utilization. Common hardware failures, such as failed drives, are handled automatically and have become non-events. Migrating to Quobyte was straightforward because it used Quobyte’s qcopy tool. The team streamlined the initial data synchronization, minimizing manual intervention and ensuring that the bulk of the data transfer was handled in a highly parallelized, fast, and metadata-preserving manner, including external attributes and access controls.
…
Samsung is developing CXL 3.1 and PCIe 6.0 CMM-D products, which should be available next year. A PM1763 Gen 6 SSD will arrive in early 2026, with twice the performance, better energy efficiency, and 25 W power draw, compared to its (PCIe 5) predecessor. It will have an EDSFF form factor and 256 TB capacity, with a 512 TB version in 2027.
…
Storage test house SANBlaze announced its OCP-compliant 2.6 test suite as an addition to its NVMe qualification platform. The Certified by SANBlaze test suite within its latest version 11.0 Build 7 software now supports all aspects of NVMe qualification with the addition of the industry accepted Open Compute Project (OCP) 2.6, with ongoing work for OCP 2.7. Other capabilities in the Certified by SANBlaze test suite include FDP (Flexible Data Placement), PCIe Single Root I/O Virtualization (SR-IOV), ZNS, NVMe-MI, TCG, SRIS/SRNS clocking, and T10/DIF. The SANBlaze OCP 2.6 package is now available for distribution. Contact sales at sales@sanblaze.com.
…
Object storage supplier Scality is working with Inria, the French national research institute for digital science and technology, on a Cyberté project “developing data storage solutions that are secure, reliable, sovereign, and sustainable, by integrating artificial intelligence into the core of software infrastructures.” Research conducted by Inria’s project teams will allow Scality to integrate the following into its software:
- AI predictive models to anticipate hardware and software failures.
- Real-time anomaly detection algorithms to identify early signs of attacks such as ransomware or data exfiltration, even in encrypted traffic.
- Frugal AI approaches and methodologies to reduce the energy footprint by using software-defined power meters (PowerAPI initiative).
More information here.
…

HDD supplier Seagate’s LaCie unit has a new Rugged SSD4 drive “for creators who need durable storage and drive performance, on the go.” The drive supports filmmakers, photographers, and audio professionals working outside the studio, with:
- Up to 4,000 MB/s read and 3,800 MB/s write speeds.
- USB 40 Gbps port allows quick file transfers across Mac, iPad, PC, and mobile devices.
- Durable casing: IP54-rated for dust and water resistance and drop-tested to three meters.
- Signature LaCie colour: Designed with the classic orange bumper, providing renowned durability, everywhere.
It is priced at $119.99 for 1 TB, $214.99 for 2 TB, and $399.99 for 4 TB. In the UK it’s available for £139.99 (1 TB), £249.99 (2 TB), and £449.99 (4 TB) through Seagate’s website.
…
SK hynix has assembled the industry’s first High NA EUV (High Numerical Aperture Extreme Ultraviolet) lithography system, the ASML TWINSCAN EXE:5200B, for mass production at its M16 fabrication plant in Icheon, South Korea. This will enable the company to design and build its chips with smaller feature sizes. It will enable printing transistors 1.7 times smaller and achieve transistor densities 2.9 times higher, compared with the existing EUV system, with a 40 percent improvement in the NA to 0.55 from 0.33. SK hynix has been expanding the scope of EUV adoption for production of the most advanced DRAM since the first introduction of the technology in 2021 for the 1nm, the fourth generation of the 10nm tech.
Matt Bryson at Wedbush says SK hynix intends to add around 20 EUV systems by 2027. It already has around 20 units, including some used for R&D. With each system costing hundreds of millions of dollars, the total investment is expected to exceed $4 billion. We believe much of this capacity will likely be focused on HBM, limiting additional wafer starts in standard DRAM.
…
Cloud data warehouser Snowflake announced Cortex AI for Financial Services, with the following features:
- Complex Machine Learning Workflows: Snowflake Data Science Agent acts as an AI coding agent, automating data cleaning, feature engineering, model prototyping, and validation so teams can move from raw data to production-ready models faster. This means automating and streamlining models that underpin quantitative research, fraud detection, customer 360, and underwriting workflows.
- Analysis of Unstructured Data: With Snowflake Cortex AISQL adding functions like AI-powered extraction and transcription, businesses can harness unstructured data by efficiently processing and derive insights from documents, audio, and images at scale – transforming end-to-end workflows like customer service, investment analytics, claims management, and next-best action.
- Easy Access to Flexible Insights: Snowflake Intelligence (in public preview) offers business users an intuitive conversational interface to gain insights using natural language from data stored in Snowflake, as well as third-party data, apps, and agents – allowing users to quickly uncover actionable insights from both structured tables and unstructured documents. This democratizes access to data and insights across financial institutions, and eliminates the technical overhead that slows down business decision-making.
Snowflake also announced a managed Model Context Protocol (MCP) Server, now in public preview.
…
Parallel file system supplier VDURA’s V5000 Data Platform is being used by a Tier-1 US federal system integrator to support one of the world’s largest defense GPU deployments. It’s being used to accelerate AI and Computational Fluid Dynamics (CFD) workloads combining flash-class performance, unified tiering across NVMe and HDD, and built-in end-to-end encryption. Phase 1 of the deployment includes 20 PB of high-performance storage, achieving sustained transfer rates above 800 GB/s, with future scalability to 200 PB and 2.5 TB/s. The system reduces cost-per-terabyte by over 60 percent compared to all-flash alternatives, improved energy efficiency by 44 percent, and lowered operational overhead to just half an FTE (full-time equivalent).
…
Comparing EMEA data from its 2024 and 2025 Ransomware Trends Reports, Veeam discovered that:
- Paying doesn’t always pay off: In 2023, more than half (54 percent) of EMEA organizations that paid a ransom successfully recovered their data. In 2024, this fell sharply to just 32 percent.
- More organizations are recovering data without paying: 14 percent in 2023 vs 30 percent in 2024.
- Organizations still aren’t prepared: Despite a 22 percent year-on-year drop in ransom payments, 63 percent of organizations would still be unable to recover from a site-wide crisis due to limited infrastructure plans.
- Only 37 percent had arrangements in place for alternative infrastructure in 2024.
…
DigiTimes reports HDD supplier Western Digital plans to invest $1 billion in Japan between now and 2031 to strengthen next-generation HDD technology (HAMR) and production processes. Its report says “The investment comes amid surging demand for datacenter storage driven by widespread adoption of generative artificial intelligence (AI), with WD’s cloud business unit accounting for up to 90 percent of revenue in the second quarter of 2025.”