Separate scaling of compute and data is central to VAST’s performance claims. Here is a top-level explanation of how it is achieved.
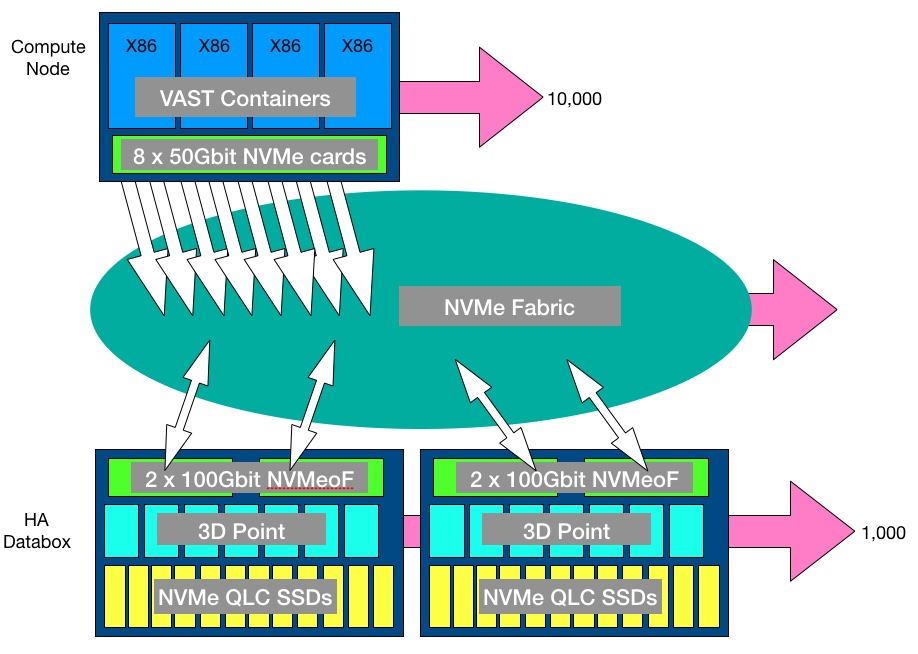
In VAST’s scheme there are compute nodes and databoxes – high-availability DF-5615 NVMe JBOFs, connected by NVMe-oF running across Ethernet or InfiniBand. The x86 servers run VAST Universal File System (UFS) software packaged in Docker containers. The 2U databoxes are dumb, and contain 18 x 960GB of Optane 3D XPoint memory and 583TB of NVMe QLC (4bits/cell) SSD (38 x 15.36TB; actually multiple M.2 drives in U.2 carriers). Data is striped across the databoxes and their drives.
The XPoint is not a tier. It is used for storing metadata and as an incoming write buffer.
The QLC flash does not need a huge amount of over-provisioning to extend its endurance because VAST’s software reduces write amplification and data is not rewritten that much.
All writes are atomic and persisted in XPoint; there is no DRAM cache. Compute nodes are stateless and see all the storage in the databoxes. If one compute node fails another can pick up its work with no data loss.
There can be up to 10,000 compute nodes in a loosely-coupled cluster and 1,000 databoxes in the first release of the software, although these limits are, we imagine, arbitrary.
A 600TB databox is part of a global namespace and there is global compression and protection. It provides up to 2PB of effective capacity and, therefore, 1,000 of them provide 2EB of effective capacity.
The compute nodes present either NFS v3 file access to applications or S3 object access, or both simultaneously. A third access protocol may be added. Possibly this could be SMB. Below this protocol layer the software manages a POSIX-compliant Element Store containing self-describing data structures; the databoxes accessed across the NVMe fabric running on 100Gbit/s Ethernet or InfiniBand.
Compute nodes can be pooled so as to deliver storage resources at different qualities of service out to clients.
Next
Explore other parts of the VAST Data storage universe;
VAST Data’s technology depends upon its data reduction technology which discovers and exploits patterns of data similarity across a global namespace at a level of granularity that is 4,000 to 128,000 times smaller than today’s deduplication approaches.
Here, in outline, is how it works.
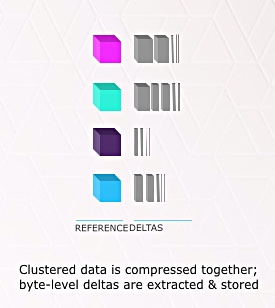
A hashing function is applied to fingerprint each GB-sized block of data being written, and this measures in some way the similarities with other blocks – the distance between them in terms of byte-level contents.
With blocks that are similar, near together as it were, with few byte differences, then one block – let’s call it the master block – can be stored raw. Similar blocks are stored only as their difference from the master block.
The differences are stored in a way roughly analogous to incremental backups and the original full backup.
The more data blocks there are in the system, the more chances there are of finding similar blocks to incoming ones.
Once data is written subsequent reads are serviced within 1ms using locally decodable compression algorithms.
Jeff Denworth, VAST Data product management VP, says that some customers with Commvault software, which dedupes and compresses backups, have seen a further 5 to 7 times more data reduction after storing these backups on VAST’S system. VAST’s technology compounds the Commvault reduction and will, presumably work with any other data reducing software such as Veritas’ Backup Exec.
If Commvault reduces at 5:1 and VAST Data reduces that at 5:1 again, then the net reduction for the source data involved is 25:1.
Obviously reduction mileage will vary with the source data type.
The SD Association is adopting the NVMe protocol to speed data access to add-in tablet and phone flash cards.
The industry standards-setting group of around 900 companies has agreed the microSD Express standard, SD v7.1, to link external flash storage cards to a phone or tablet’s processor and memory. This uses the PCIe 3.1 bus and NVMe v1.3 protocol, enabling transfers at up to 985MB/sec.
The new format removes a storage bottleneck that slowsperformance as mobile and IOT devices data usage increases.
MicroSD Express card format branding
PCIe 3.1 has low power sub-states (L1.1, L1.2) enabling low power implementations of SD Express for the mobile market. The microSD Express cards should transfer data faster than previous microSD formats while using less electricity, thus improving battery life.
By way of comparison Western Digital’s latest embedded flash card for phones and tablets, the MC EU511, runs at 780MB/sec – 26 per cent slower.
The EU511 can download a 4.5GB movie, compressed to 2.7GB, in 3.6 seconds. MicroSD Express would write that amount of data to its card in 2.7 seconds, courtesy of lower latency and higher bandwidth.
There are three varieties of microSD Express:
microSDHC Express – SD High Capacity – 4GB to 6GB capacities,
microSDUC Express – SD Ultra Capacity supporting up to 128TB.
The SD Association upgraded its SD card standard to SD Express in June 2018, bring in PCIe and NVMe to that card format, but this was not taken up by SD card suppliers.
MicroSD cards are the smallest version of the three SD card physical size options:
Standard: 32.0 × 24.0 × 2.1 mm.
Mini: 21.5 × 20.0 × 1.4 mm,
Micro: 15.0 × 11.0 × 1.0 mm.
The larger SD flash memory cards for portable devices, including phones, are much less popular than microSD cards.
The microSD Express card format is backwards-compatible with microSD card slots but older devices are unable to use the NVMe speeds. The new format is in place to adopt faster PCIE standards as they arrive, such as PCIe gen 4 with 2GB/sec raw bandwidth, and PCIe gen 5 with 4GB/sec.
An SDA white paper discusses the new standard if you want to find out more.
Western Digital is sampling a smartphone flash drive that can store a two-hour movie in 3.6 seconds.
The embedded flash drive writes data at up to 750MB/sec and goes by the name of the iNAND MC EU511. The 3.6 seconds write time quoted for a two-hour movie is for a 4.5GB video file coming in to the phone across a 5G link and using H.266 compression to reduce the data to a 2.7GB file.
The device uses WD and Toshiba’s 96-layer 3D NAND formatted with an SLC (1bit/cell) buffer. WD calls this SmartSLC Generation 6.
The drive supports Universal Flash Storage (UFS) 3.0 Gear 4/2 Lane specifications and is intended for use in all smart mobile devices.
Capacities range from 64GB, through 128GB and 256GB, to 512GB. Its package size is 11.5x13x1.0mm. The drive uses TLC (3bits/cell) apart from the SLC buffer.
The EU511 provides a top end to WD’s existing pair of EFD drives, the iNAND MC EU311 and EU321, which max out at 256GB and support UFS 2.1 Gear3 2-Lane.
My desktop with a broadband internet link takes 20-30 minutes to download a 4.5GB movie. Reducing this to less than four seconds sounds like a fantasy, and may not be possible given the landline phone infrastructure underlying the broadband link. Mobile wireless connectivity is set to overtake landline-based internet access where there is no end-to-end fibre connection.
Goodbye landline and, if it’s a broadband internet access bottleneck, good riddance too.
Western Digital is shipping MC E511 samples to prospective customers.
Nutanix is within a month of launching Buckets, a hyperconverged infrastructure, S3-compatible object service, according to our sources.
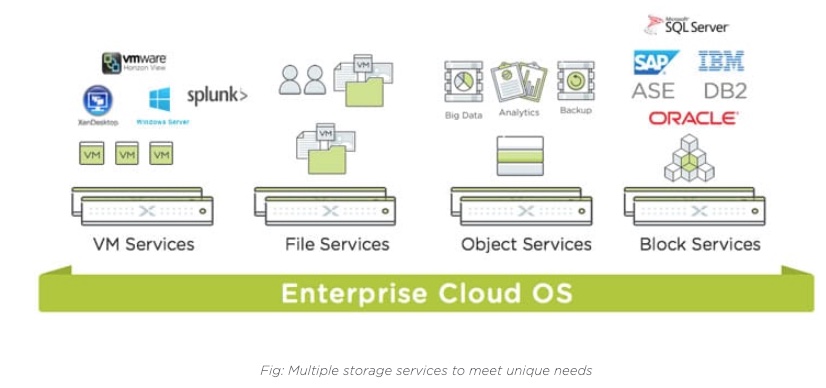
The technology gives the company a full house of storage services for VM, file, block and object.
In November 2017 Nutanix said it would develop its Acropolis Object Storage Service, based on data containers called buckets. Object services would form part of an Enterprise Cloud OS (ECOS) and sit alongside Virtual Machine and Block services and File Services.
ECOS is a suite of services for Nutanix hyperconverged infrastructure (HCI) software that runs across on-premises servers to form private clouds, and public clouds such as Amazon, Azure and Google Cloud Platform. Example services are the Acropolis Compute Cloud, Calm, a multi-cloud application automation and orchestration offering, and various Xi Cloud Services such as Xi Leap disaster recovery.
Nutanix’ complete set of storage top-level services.
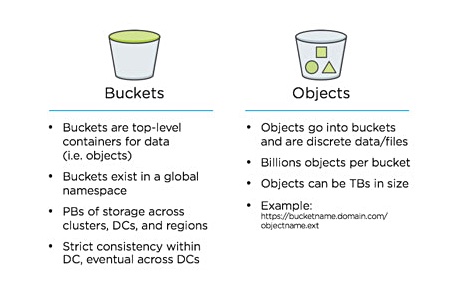
Buckets stores large unstructured datasets for use in applications such as big data analytics, archiving, compliance, database backups, data warehousing and devops. WORM (write once; read many) buckets are supported.
Billions of objects are stored in buckets which exist in a single global namespace that works across on-premises data centres (Nutanix clusters), regions within multiple public clouds, and multiple clouds. Objects can be replicated between, and tiered across clouds, and handle petabytes of data, with up to TB-sized objects.
Erasure coding means there’s no hole in a Nutanix bucket.
Access is via an S3-compatible REST API. The data in the buckets is deduplicated, compressed and protected with erasure coding. It is natively scale-out in nature: add more Nutanix compute nodes or storage capacity as needed.
There is an Object Volume Manager and it handles;
Front end adapter for the S3 interface, REST API and client endpoint,
Object controller acting as the the data management layer to interface to AOS and coordinate with the metadata service,
Metadata services with management layer and key-value store,
Atlas controller for lifecycle management, audits, and background maintenance activities.
Nutanix says Buckets is operationally easy to set up and use, talking of single click simplicity via its Prism management tool. Prism is said to use machine learning to help with task automation and resource optimisation.
We understand that Buckets will be consumable in two ways, either as Nutanix hyperconverged clusters with apps in VMs running alongside or as dedicated clusters.
AWS and Google Cloud virtual machine instances – and as of this month, Azure’s – have NVMe flash drive performance, but user be warned: drive contents are wiped when the VMs are killed.
NVMe-connected flash drives can be accessed substantially faster than SSDs with SAS or SATA interfaces.
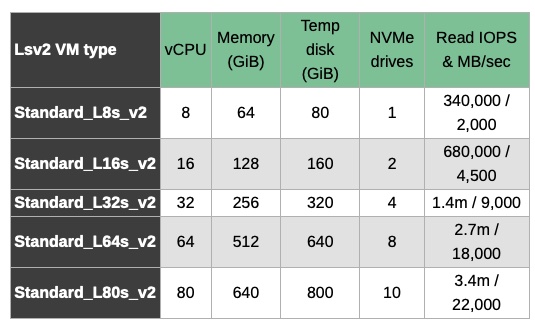
The Azure drives – which have been generally available since the beginning of February – are 1.92TB M.2 SSDs, locally attached to virtual machines, like direct-attached storage (DAS). There are five varieties of these Lsv2 VMs with 8 to 80 virtual CPUs:
The temp disk is an SCSI drive for OS paging/swap file use.
The stored data on the NVMe flash drives, laughably called disks in the Azure documentation, is wiped if you power down or de-allocate the VM, quite unlike what happens in an on-premises data centre. In other words Azure turns non-volatile storage into volatile storage – quite a trick.
That suggests you’ll need a high-availability/failover setup to prevent data loss and a strategy for dealing with your data when you turn these VMs off.
AWS and GCP
Six AWS EC2 instances support NVMe SSDs – C5d, I3, F1, M5d, p3dn.24xlarge, R5d, and z1d.
They are ephemeral like Azure VMs. AWS said: “The data on an SSD instance volume persists only for the life of its associated instance.”
Google Cloud Platform also offers NVMe-accelerated SSD storage, with 375GB capacity and a maximum of eight per instance. The GCP documentation warns intrepid users: “The performance gains from local SSDs require certain trade-offs in availability, durability, and flexibility. Because of these trade-offs, local SSD storage is not automatically replicated and all data on the local SSD may be lost if the instance terminates for any reason.”
All three cloud providers treat the SSDs as scratch volumes so you have to preserve the data on them once it has been loaded and processed.
Lenovo has teamed up with Pivot3 and Scale Computing for its HCI needs, and aiming full tilt at edge computing with a new secure SE350 server.
The ThinkSystem SE350 is the first of a family of edge servers. It is a half-width, short-depth, 1U server with a Xeon-D processor, up to 16 cores, 256GB of RAM, and 16TB of internal solid-state storage.
Which way is up?
How secure is the SE350? “You touch it and it self-destructs the data,” Wilfrid Sotolongo, VP for IoT at Lenovo’s Data Centre Group said.
It can be hung on a wall, stacked on a shelf, or mounted in a rack. This server has a zero-touch deployment system, is tamper-resistant and data is encrypted.
Lenovo ThinkSystem SE350
Networking options include wired 10/100Mb/1GbitE, 1GbitE SFP, 10GBASE-T, and 10GbitE SFP+, secure wireless Wi-Fi and cellular LTE connections.
Expect to see this in Lenovo IoT hyperconverged systems using Pivot3 and Scale Computing software.
Its partnership with Pivot3 is aimed at video security and surveillance use cases in smart city and safe campus deployments. For instance, a Middle East customer used the combo with SecureTech to secure a sprawling hotel complex, the company said.
Lenovo loves edge computing
Lenovo quotes Gartner numbers showing about 10 per cent of of enterprise-generated data is created and processed today outside a centralised data centre or public cloud. By 2022 that will jump to 75 per cent, creating a much bigger edge market.
Lenovo positions its Scale Computing hookup for retail HCI with customers such as Delhaize that deploy mini-data centres. It provides edge infrastructure that can run IT and IoT workloads, detect and correct infrastructure errors to maximise application uptime. The technology is manageable remotely or on-site by non IT teams.
Lenovo has a third card to play. It is working with VMware on Project Dimension – on-premises VMware Cloud. The idea here is to provide infrastructure-as-a-service to locations on-premises, particularly those on the edge.
Lenovo demonstrates IoT and edge solutions next week at Mobile World Congress in Barcelona.
HPE grew storage revenues three per cent year-on-year in the first 2019 quarter – the seventh quarter in a row that the company has increased revenues in this segment.
Storage revenues for the quarter were $0.98bn, accounting for 12.9 per cent of the firm’s $7.56bn total quarterly revenues. As is usual with earnings calls, companies like to talk about what is going well and HPE is no exception.
in the earnings call Tarek Robbiati, CFO, noted 20 per cent revenue in all-flash arrays, with Nimble leading the charge. Big data was another bright spot, delivering 25 per cent revenue growth year on year.
It is reasonable to infer that some product lines are experiencing revenue falls, if all these technologies are doing so well and overall growth in Q1 is three per cent. For instance, HPE’s 3PAR unit seems to be languishing in comparison with newer products.
CEO Antonio Neri said revenues grew significantly in high-margin technologies such as HPC, hyperconverged and the company’s Synergy composable infrastructure, which is now a $1bn run rate business. HPE’s hyperconverged portfolio with SimpliVity and Synergy grew 70 per cent, he added
That implies Synergy revenues in the quarter were $250m. Neri didn’t separate out SimpliVity hyperconverged product revenues or their growth rate.
IDC said SimpliVity sales in the third 2018 calendar quarter were $111.5m.
Robbiati expects storage revenue to ramp and is targeting $1bn per quarter. This should be easily attainable, considering that was only $25m shy in Q1.
HPE and other storage suppliers
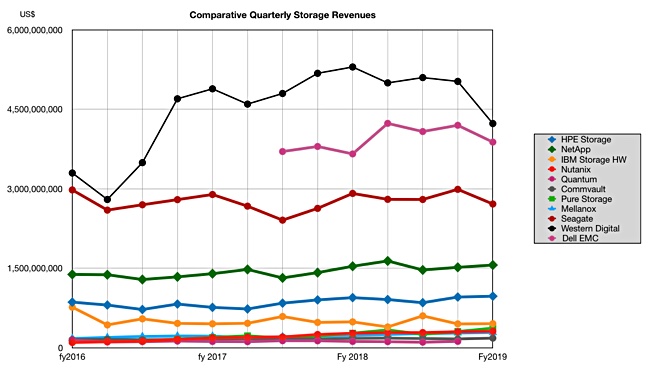
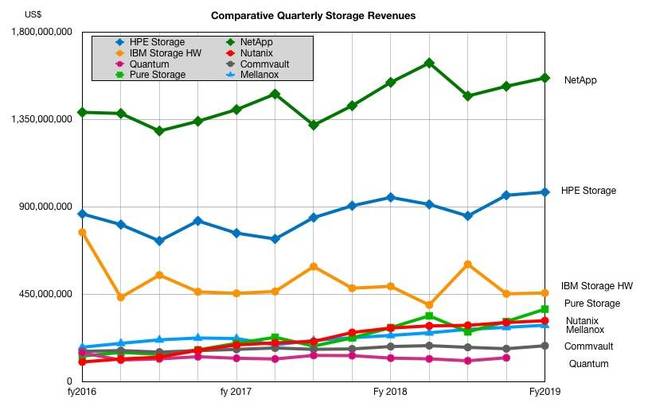
HPE’s storage performance compared to other suppliers can be charted;
The chart shows Western Digital is the top supplier revenue-wise, with $4.23bn revenues i its latest quarter. followed by Dell EMC with $3.9bn. Our Dell EMC numbers only go back a few quarters which explains the short line. Seagate is third with $2.7bn in its most recent quarter.
Let’s take these three out and look at the others in more detail:
NetApp’s latest revenues were $1.56bn, and it is comfortably ahead of HPE. It saw USA demand slow down in the quarter and the 2 per cent growth was less than its high-point guidance. HPE’s 3 per cent was as guided and it saw no demand slowdown, especially not in the public sector, which was a NetApp weakness.
We also see HPE is comfortably ahead of IBM, Pure Storage, Nutanix, Mellanox, Commvault and Quantum. The IBM numbers are for storage hardware only and it has a storage software business, the Spectrum-branded products.
Big Blue does not reveal its revenues but we think it would send IBM’s curve higher on the chart, possibly even matching HPE’s.
Toshiba has a new way to connect an SSD’s controller and flash chips, making higher-capacity and faster SSDs possible – at levels not yet seen.
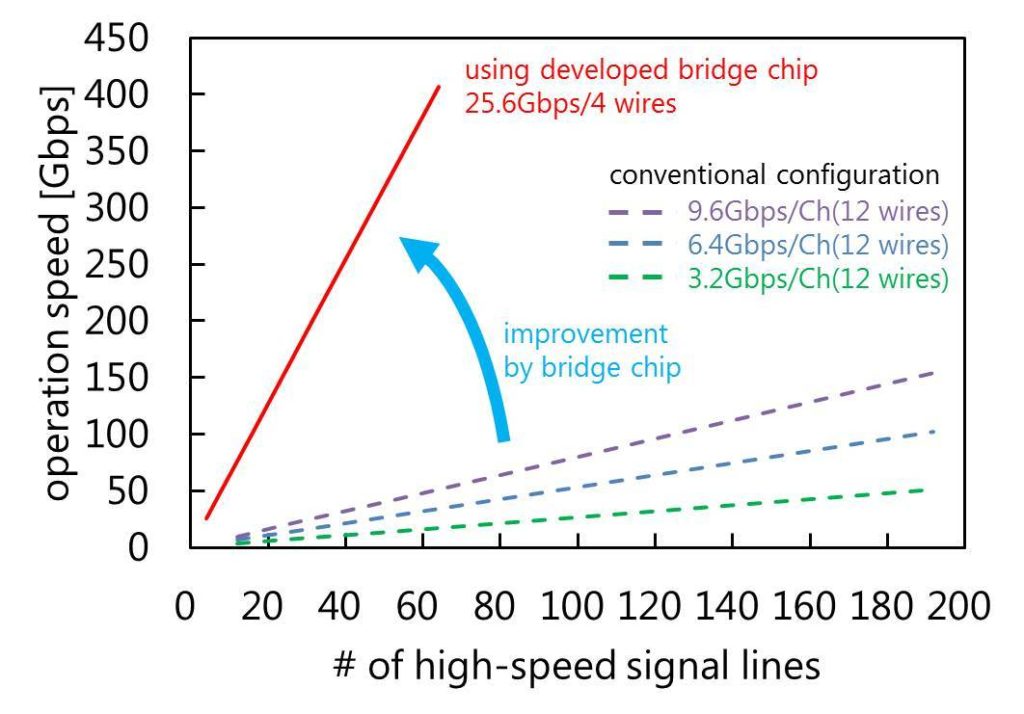
SSD capacities are limited by the number of connections between the controller and the flash chips. Currently high-speed signal lines connect the chips to the controller. The more chips there are the more signal lines are needed. But the SSD’s operating speed decreases as more chips are connected, thus limiting the SSD’s capacity.
It is even difficult to implement the wiring on the SSD board.
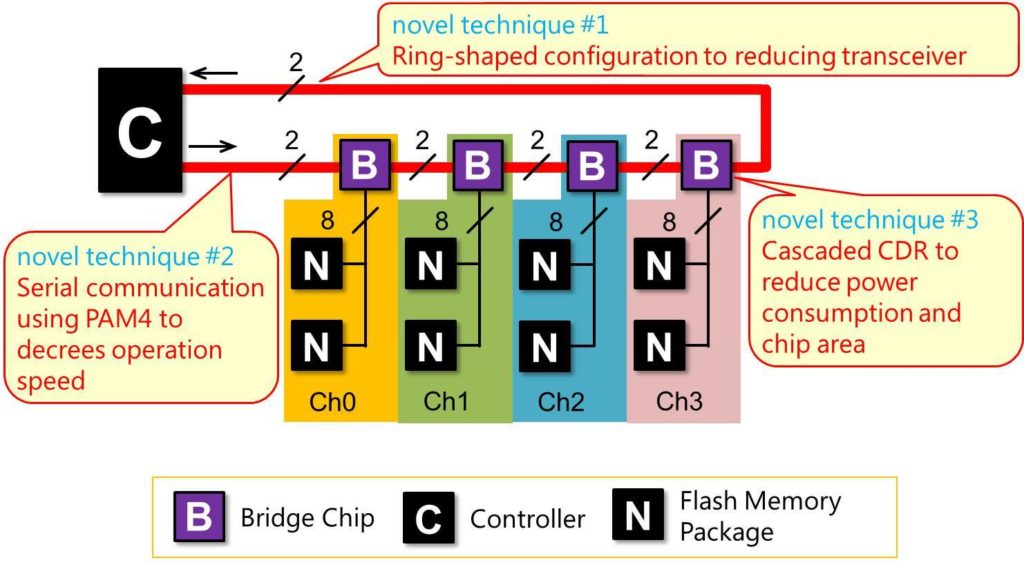
The answer is to insert a bridge chip between the controller and the flash chips. Toshiba’s bridge chip relies on a daisy chain connecting the controller and bridge chips in a ring shape. It uses a serial communication using PAM 4 (4-level Pulse Amplitude Modulation) and a jitter improvement technique for eliminating a Phase Locked Loop (PLL) circuit in the bridge chip.
Toshiba’s bridge chip diagram. CDR is Clock Data Recovery (a circuit that recovers the data and clock from the received signal.)
A PLL circuit generates an accurate reference signal. Jitter is fluctuation in the time domain of the clock or signal waveforms which degrades signal recognition.
These three techniques reduce the size and power consumption of the bridge chip, making it possible to operate a larger number of flash memory chips at high speed with fewer high-speed signal lines.
Toshiba bridge chip performance chart.
Toshiba says it will further enhance bridge-chip performance while reducing the chip’s area and power consumption. Its aim is to achieve high-speed, large-capacity NAND storage at levels not as yet realised.
Sounds good. Perhaps we’ll get super-dense Toshiba SSDs next year.
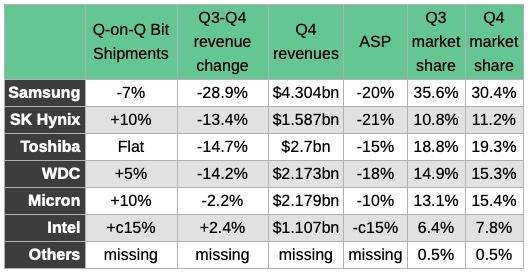
An abrupt quarter-on-quarter revenue cliff drop affected all the main flash vendors, except Intel, which saw revenues rise despite falling prices.
DRAMeXchange highlighted the sudden revenue reversals everywhere but Intel, supplying these numbers:
Everyone except Samsung increased bit shipments in the fourth 2018 quarter compared to the one before, and Intel pushed them up 15 per cent.
Samsung revenues dropped dramatically from the third to the fourth quarter – down 28.9 per cent to $4.304bn – and its market share fell 5.2 per cent to 30.4 per cent.
All the major suppliers took share from Samsung, except the Others category.
Both SK Hynix and Samsung had to cut average selling prices (ASPs) by more than 20 per cent, but SK Hynix gained market share as a result and its revenues only fell 13.4 per cent, less than half of Samsung’s percentage drop.
The DRAMeXchange researchers reckoned the first quarter of 2019 will be worse, with seasonality deepening the demand slump, resulting in a projected decline in NAND bit shipments over 2018’s final quarter.
The research outfit predicted the main NAND suppliers would lower prices further to retain their respective market shares. If you’re in the flash game, consider yourself warned.
Yesterday’s ObjectEngine launch is notable for what it brings to Pure’s future data management table. This is Pure’s third hardware platform, joining FlashArray for primary data and FlashBlade for secondary, unstructured data.
ObjectEngine positions Pure Storage for a multi-cloud, data copy serving and Data-as-a-Service future, taking on Actifio, Cohesity and Delphix.
The company says the technology is suitable for machine learning, data lakes, analytics, and data warehouses – “helping you warm up your cold data.”
ObjectEngine//A270 with four nodes (2 enclosures) above a single FlashBlade box
ObjectEngine is a scale-out, clustered inline deduping system. It accepts incoming backup files via an S3 interface, squashing them, and sends them along to an S3-compliant back-end – either on-premises Pure FlashBlade arrays or AWS S3 object storage. For restoration, ObjectEngine fetches the back-end S3 files and rehydrating them.
A Pure Storage Gorilla Guide mentions this point: “It’s conceivable that more public and private cloud services will be supported to help reduce the complexity and cost of F2F2C (flash to flash to cloud) backup strategies.”
The Pure Storage vision extends beyond data storage and data protection to data management.
Flash dedupe metadata
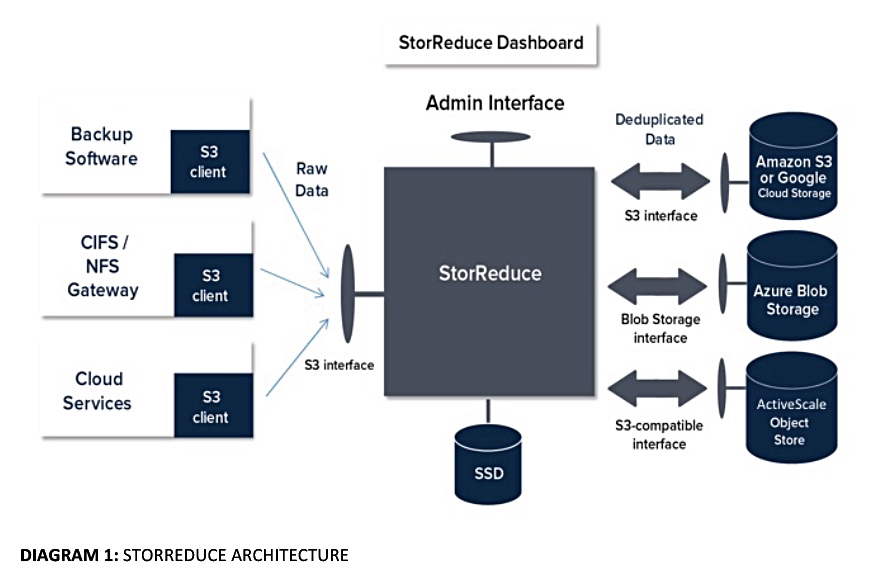
A StorReduce server uses x86 processors and stores dedupe metadata on SSDs:
StorReduce Architecture
The Gorilla Guide doc says each StorReduce server keeps its own independent index on local SSD storage.
As I note here, Pure has not published deduplication ratios, but it gives big clue in the Gorilla Guide: “The amount of raw data a StorReduce server can handle depends on the amount of fast local storage available and the deduplication ratio achieved for the data. … Typically, the amount of SSD storage required is less than 0.2 per cent of the amount of data put through StorReduce, for a standalone server.”
StorReduce servers use backend object storage for:
Deduplicated and compressed user data. Typically, this requires as little as 3 per cent of the object storage space that the raw data would have required, depending on the type of data stored.
System Data: Information about buckets, users, access control policies, and access keys, making it available to all StorReduce servers in a given deployment.
Index snapshots: Data for rapidly reconstructing index information on local storage.
Note this point, which is counter-intuitive considering SSDS are non-volatile: “The StorReduce server treats local SSD storage as ephemeral. All information stored in local storage is also sent to object storage and can be recovered later if required.”
A server failure means that another server can pick up its load using the failed server’s back-end stored information.
With the metadata held in local flash, “StorReduce can create writable “virtual clones” of all the data in a storage bucket, without using additional storage space.”
It can “create unlimited virtual clones for testing or distribution of data to different teams in an organisation. Copy-on-write semantics allow each individual clone of the data to diverge as new versions of individual objects are written.”
Multiple clouds
StorReduce software could store its deduped data on on-premises S3-accessed arrays, Amazon S3 or S3IA, Microsoft Azure Blob Storage, or Google Cloud Storage. ObjectEngine only supports FlashBlade and AWS S3 – for now.
We have no insider knowledge but it seems a logical next step to enlarge the addressable market for ObjectEngine by extending support for Azure Blob storage and Google Cloud Platform (GCP).
Furthermore ObjectEngine could migrate data between these clouds by converting S3 buckets into Azure blobs or the GCP equivalent. The StorReduce doc says: “StorReduce can replicate data between regions, between cloud vendors, or between public and private cloud to increase data resiliency.”
The system transfers unique data only to reduce network bandwidth needs and transmission time.
Data copy services
StorReduce had the facility of having StorReduce instances taking a freshly deduped object set, rehydrating it and pumping it out for re-use. This fits perfectly with Pure’s DataHub ideas, as mapped out below.
Pure’s Data Hub idea for data distribution for re-use
Here we see the likelihood of Pure taking direct aim at Activity, Cohesity and Delphix in the copy data management market.
ObjectEngine opens several data management doors for Pure Storage. Expect these doors to start being delineated over the next few quarters as Pure builds out its third hardware platform.
Veeam’s backup Cloud Tier can use Western Digital’s object-storing ActiveScale box as a target data store.
The idea is to make longer-term backup storage cheaper by moving it away from more expensive direct backup-to-disk targets to ActiveScale.
Cloud Tier is Veeam’s term for older backup data moved to AWS S3, Azure Blob or on-premises object storage. It is not separate archiving as the backups are still accessible via metadata references in the local backup store.
ActiveScale is an S3-compatible object storage array. It scales from 500TB to 49PB in one namespace and offers a claimed 19 nines data durability – 99.99999999999999999 per cent. Blocks & Files thinks this equates to a 1 in 9 quintillion chance that a data object will be lost, but our eyes glazed over as we counted the 9s.
ActiveScale P100.
Western Digital has joined the Veeam Alliance Partner Program as part of its arrangement with Veeam.
Three more points:
A Unified Data Access feature offers file access protocols as well as object access.
ActiveScale use by Cloud Tier requires Veeam Availability Suite v9.5 Update 4.
Cloud Tier also supports Western Digital’s IntelliFlash all-flash arrays, the acquired Tegile technology.