


VAST Data’s technology depends upon its data reduction technology which discovers and exploits patterns of data similarity across a global namespace at a level of granularity that is 4,000 to 128,000 times smaller than today’s deduplication approaches.
Here, in outline, is how it works.
A hashing function is applied to fingerprint each GB-sized block of data being written, and this measures in some way the similarities with other blocks – the distance between them in terms of byte-level contents.
With blocks that are similar, near together as it were, with few byte differences, then one block – let’s call it the master block – can be stored raw. Similar blocks are stored only as their difference from the master block.

The differences are stored in a way roughly analogous to incremental backups and the original full backup.
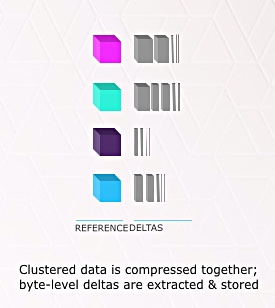
The more data blocks there are in the system, the more chances there are of finding similar blocks to incoming ones.
Once data is written subsequent reads are serviced within 1ms using locally decodable compression algorithms.
Jeff Denworth, VAST Data product management VP, says that some customers with Commvault software, which dedupes and compresses backups, have seen a further 5 to 7 times more data reduction after storing these backups on VAST’S system. VAST’s technology compounds the Commvault reduction and will, presumably work with any other data reducing software such as Veritas’ Backup Exec.
If Commvault reduces at 5:1 and VAST Data reduces that at 5:1 again, then the net reduction for the source data involved is 25:1.
Obviously reduction mileage will vary with the source data type.
Next
- VAST decoupling compute and storage
- VAST striping and data protection
- VAST universal file system
- VAST Data’s business structure and situation
- Return to the main VAST Data article here.





