Infinidat’s performance-boosting software upgrade, announced this week, will help the company add NVMe fabric links and storage-class memory to iInfinibox arrays.
InfiniBox 4.0.40 adds SMB support, better protection with snapshot changes, and delivers 30 per cent IOPS improvement and 22 per cent throughput increase.
Latency is reduced by 50 per cent as a result of many small software, according to our sources. For example, the last remaining kernel module – for Infiniband – was transplanted into user space. Also the company has implement a more sophisticated dispatch algorithm was.
This work is part of Vision 50, an engineering project to reduce Infinibox average global latency in the field to under 50 microseconds.
In November 2018 we reported Infinidat’s goal to add NVMe over Fabrics networking. Blocks & Files understands this latest work prepares the way. Also the company is tapping into storage-class or persistent memory – in other words it will support Optane. This will accelerate access to Infinibox data faster than NVMe-oF on its own.
Huawei has launched the all-flash entry-level OceanStor Dorado3000 v3 array and added NVMe support to mid-range and high end all-flash Dorado storage.
The OceanStor Dorado is a classic SAN array. From high to low-end the range consists of the Dorado18000 v3, Dorado6000 v3, Dorado5000 v3 and Dorado3000 v3. With NVMe latency is reduced to as low as 300 microseconds,
NVMe support has been a long time coming. Huawei first talked about adding NVMe SSDs to Dorado arrays in 2015. The Dorado V3 all-flash storage products were launched in 2016.
The company claims OceanStor Dorado V3 mid-range and high-end all-flash storage are the industry’s first to fully support the NVMe architecture. This is unremarkable since NVMe drive support is now widespread throughout the industry.
No pricing and availability information was released at time of publication.
Western Digital will introduce shingling to its MAMR drives to build a path to 20TB capacity in 2020 and from there to 40TB and 100TB.
Write tracks are wider than read tracks and shingled disk drives take advantage of this to overlap write tracks as a way of cramming more read tracks on a platter. The downside is that blocks of write tracks need erasing and re-writing when new data replaces old data. This is time consuming.
Shingled Magnetic Recording (SMR) drives are slower than conventionally recorded disk drives and as such are not drop-in replacements. Rewriting block changes can be handled by the drive itself or by a host server. Western Digital prefers host-managed shingling.
The company is targeting 2020 to introduce 20TB and 20TB+ MAMR (Microwave-Assisted Magnetic Recording) disk drive technology to increase areal density beyond the current Perpendicular Magnetic Recording (PMR) technology’s limit.
Eyal Shani, Director, Technical Product Marketing, Devices GTM, at WD, told a Technology Live briefing in London today that these drives will use shingling. He said SMR adds between 16 per cent and 25 per cent additional capacity beyond the increase due to MAMR.
At the 16 per cent level, a 20TB MAMR drive without SMR would have 17.2TB capacity. This is a small increase over current 16TB PMR drive technology. Hence the need for shingling.
Shani said cloud hyperscalers like Dropbox are the target market for such drives.
He revealed WD is developing dual-actuator technology to increase disk drive IO rates. The first actuator will handle the high 4 platters and the second looks after the lower 4 platters. Expect a statement on availability in June 2019.
WD Dual-actuator prototype.
If WD thinks it necessary to introduce shingling in its post-PMR drives Seagate and Toshiba are likely to follow the same route.
Update
March 8. A Western Digital spokesperson said: “Western Digital’s energy-assist PMR (ePMR) products (MAMR, for example) will not be limited to SMR, and we wanted to make sure that this is clear, as it may not have been clearly communicated during our presentation.
“Our plans are to continue to deliver both SMR and conventional magnetic recording (CMR) as they both offer distinctive benefits and value to the market. Western Digital also remains on schedule to ship energy-assist products during calendar 2019 – no specific date has been set.”
Scale-out filer Qumulo is developing its own Amazon S3 bucket storage capability and has cloud archiving in mind.
Currently it uses Minio’s object storage S3 code to provide S3 storage capability. Datera does the same thing.
Molly Presley, Qumulo product marketing director, told a Technology Live briefing in London today that the company is developing its own S3 code. The first version should arrive in March 2019 and enables applications accessing the Qumulo store through NFS or SMB to read S3 object storage buckets.
Over time you’ll be able to write to that object, coming in from NFS or SMB again, and also influence the placement of the data object.
Presley said challenges include object storage being eventually consistent while file storage is instantly consistent. Another concerns the 1 to 1 mapping between files and objects. The S3 object in its AWS bucket needs to be a native S3 object.
Qumulo is also developing the ability to archive to S3 buckets, on top of the existing Archive-optimised nodes. This will see AWS S3 become a cloud tier behind the on-premises Qumulo archive box. Initially Amazon will move the objects to Glacier for lower cost archiving, but Presley said Qumulo is thinking about doing such things itself.
Joel Groen, Qumulo product manager, responding to an audience question, said multi-cloud access for file will emerge. Users will be able to move the data back and forth. Qumulo has replication today. Over time it will help develop ways to move data sets between clouds more efficiently.
Azure Blob storage support is coming sometime in 2019. Customers are running Qumulo in Google Cloud Platform but this capability has not been announced yet. Blocks & Files expects that to come this year as well.
Is Acronis nuts? It’s developing a general hyperconverged infrastructure appliance for a market that has already matured and consolidated around the Dell EMC and Nutanix duopoly. But it just might have an edge with service providers.
The company has built a hyperconverged backup appliance and looking at a general HCI appliance, Ronan McCurtin, Acronis senior sales director, said in a briefing in London today.
Acronis sells idata protection and cyber security products in two markets: on-premises business kit and cloud service providers. McCurtin says on-premises is Acronis’ core market, with five million or so users, while cloud is its newer and faster-growing market.
He said Acronis hasn’t really fulfilled its potential but is determined to do so in both markets, albeit with different growth rates; ”Growing 10 per cent in the on-premises market would be huge. Growing 10 per cent in the cloud market would be a disaster.”
McCurtin said Acronis was not going to go head-to-head with Nutanix or Dell EMC. But a software HCI appliance represents a new growth opportunity and Acronis thinks its channel partners can help it find a niche in a market owned Dell EMC and Nutanix. Service providers will sell services based on existing products, managed through a single Acronis facility and supported by Acronis.
Comment
It ought to be relatively easy to graft an HCI product onto its existing service provider business, so long as it supports multi-tenancy, quality of service, and simple management.
The Acronis HCI represents an incremental upgrade for service providers.would be managed and can be supported through already existing arrangement.
An Acronis HCI would also represent an incremental extension of existing business for Acronis’ on-premises customers.
McCurtin acknowledged the duopoly’s dominance but said it was early days in the HCI market and there was a long way to go. In other words, there is room for new entrants, despite suppliers like Maxta failing and exiting the market.
Infinidat, the enterprise high-end array provider,has added SMB filer support, boosted IOPS and throughput, and strengthened its snapshot capabilities.
New features in InfiniBox 4.0.40 software include:
Support for SMB protocols v2.1 through v3.1.1, to add Windows networked file support and integration with Windows ecosystems and data workflows
Improved InfiniSnap snapshots with immutable snapshots for volumes, filesystems and consistency groups
NFS self-service file recovery system called Snapshot Directory
Performance boost with 30 per cent IOPS improvement, 22 per cent throughput increase and a reduction in latency
The update boosts InfiniBox F6000 arrays performance from one million-plus IOPs to 1.3 million IOPS and up to 15.2 GB/sec throughput. Infinidat says latency is typically less than 1 msec – at a customer event late last year the company showed latency under 50μs, as measured from the host.
The Immutable snapshot feature can protect data from malware and ransomware.
With Snapshot Directory, end users can browse, select and recover files that have been inadvertently deleted or modified, without any admin assistance.
SMB protocol support is available initially on newly deployed InfiniBox models and will be generally available in the second quarter of 2019. Other features are available now as a no-charge and non-disruptive upgrade.
In its nineteenth year the HPC storage supplier Panasas has secured a fresh funding round and given the board a makeover.
The cash infusion is less than $50m and “tranched”, meaning stage payments are dependent upon performance, CEO Faye Pairman told us. The new investors will occupy four of seven seats in the enlarged board.
The funding comes entirely from two new investors, KEWA Financial, a US. insurance company, and Dowroc Partners, a private fund owned by investment professionals with expertise in storage technology, energy, and cloud computing.
Panasas’s last funding in 2013 comprised a $15m private equity investment by Mohr, Davidow Ventures and a $25.2m venture capital F-round, with participation from Samsung Ventures, Intel Capital and others.
Enterprise HPC players
So why does Panasas need more money now?
Robert Cihra partner at Dowroc Partners, said Panasas is a “small company that’s looking to grow…This is an investment in growth.”
The money will fund technology and product development, support expansion into new markets, and the exploration of OEM relationships. This at a time of growing competition in Panasas’s core market.
General enterprises are driving this with their need for HPC-like storage systems to handle fast access to millions and sometimes billions of file for their big data analytics and machine learning applications.
The technology development has attracted new entrants alongside the classic quintet of (now Red Hat) Ceph, Dell EMC’s Isilon, DDN, IBM’s Spectrum Scale and Panasas.
Panasas historically shipped its HPC storage software running in its own proprietary arrays until November 2018, when it made its software portable. The file system was updated and the ActiveStor hardware requirement became commodity X86 server-based.
This opens possibilities for partnership options such as running software on other suppliers’ hardware. Jim Donovan, Panasas chief marketing officer, at the time of the announcement, said the move gives “us the opportunity to port PanFS to other companies’ hardware. That’s the potential. We’re not announcing any OEM deals at the moment.”
Blocks & Files thinks Panasas will announce new partnerships fairly quickly. We imagine HPE is a company Panasas will talk to and, looking further afield, Cisco and possibly Lenovo.
All aboard the Panasas…Express?
Panasas CEO Faye Pairman
There is now a seven-member board compared to the 4-member one last year. The board directors are
Faye Pairman, President and CEO
Elliot Carpenter, CFO
Andre Hakkak – founder and managing partner, White Oak Global Advisors
David Wiley, founder and CEO KEWA – new member
Robert Cihra, partner at Dowroc Partners and 20-year Wall Street analyst – new member
Jorge Titinger, CEO of Titinger Consulting, ex-SGI SGI – new member
Jonathan Lister, VP Global Sales Solutions at LinkedIn – new member
As you can see the four new members could outvote the three legacy members.
Pairman told us Tittinger’s HPC and Lister’s sales and business growth experience will help drive Panasas’s roadmap and re-accelerate growth.
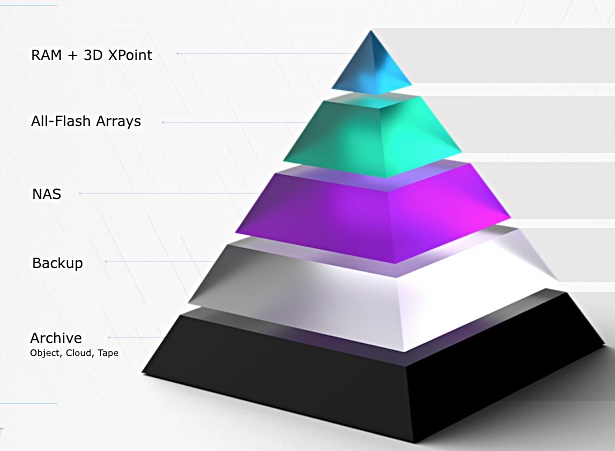
VAST Data wants to direct an extinction event for hard drives.
This is a bold ambition but VAST Data is a remarkable startup, certainly in the scope of its claims and use of new technology. Without QLC flash, 3D XPoint, NVMe over fabrics, data reduction, metadata management, its product simply would not exist.
The company has accumulated $80m in funding through two VC rounds and officially launches its technology today. But it is already shipping product on the quiet and says customers are cutting multi-million dollar checks for petabytes of storage. Existing customers include Ginkgo Bioworks, General Dynamics Information Technology and Zebra Medical Vision.
It also claims it has earned more revenue in first 90 days of general availability than any company in IT infrastructure history, including Cohesity, Data Domain, and Rubrik combined.
So what is the fuss all about?
VAST opportunities
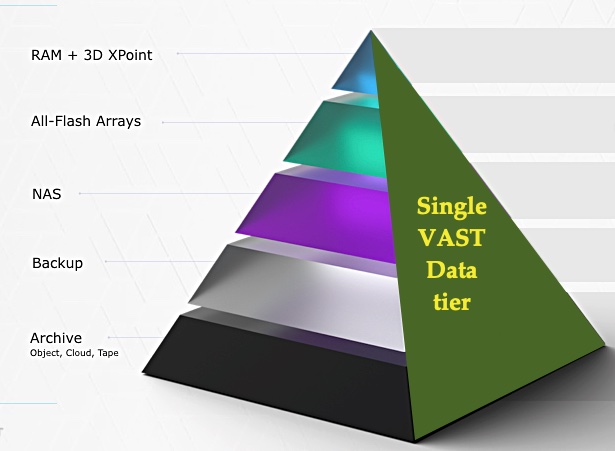
This may sound unreal: VAST Data has found a way to collapse all storage tiers onto one with decoupled compute nodes using NVMe-oF to access 2U databoxes filled with QLC flash data drives and Optane XPoint metadata and write-staging drives, with up to 2PB or more of capacity after data reduction.
How do VAST’s claims stack up? They seem plausible but it is, of course, early days. Our subsidiary articles look at the various elements of VAST Data’s story: click on the links below.
Let’s try it from another angle. VAST Data has created an exabyte-capable, single tier, flash-based capacity store that can cover performance to archive-level data storage needs at a cost similar to or lower than hard disk drives. This equates to about $0.03/GB instead of a dual-port NVMe enterprise SSDs at $0.60/GB.
Single VAST Data tier
At its heart the technology depends upon a new form of data reduction to turn 600TB of raw flash and 18TB of Optane SSD into up to 2PB or more of effective capacity. Without this reduction technology the exabyte scaling doesn’t happen
In addition, extremely wide data stripes provide for global erasure coding and fast drive recovery.
There is a shared-everything architecture embodied in separate and independently scalable compute nodes in a loosely-coupled cluster running Universal Filesystem logic. These link across an NVMe link to databoxes (DBOX3 storage nodes) which are dumb boxes filled with flash drives for data and Optane XPoint for metadata.
Exploded view of VAST Data’s DBOX3, showing side-mounted drives. Ruler-format drives would fit quite nicely in this design.
The flash drives have extraordinary endurance – 10 years – because of VAST’s ability to reduce the number of writes; the opposite of write amplification.
The pitch is that VAST’s data reduction and minimised write amplification enables effective flash pricing at capacity disk drive levels with performance at NVMe SSD levels for all your data; performance, nearline, analytics, AI machine learning, and archive.
Benefits
With a flat, single-tier, self-protecting data stricture there s no need for separate data protection measures.
There is no need for data management services for secondary, unstructured data.
There is no need for a separate archival disk storage infrastructure.
There is no no need to tier data between fast and small device and slow, cheap and deep devices.
There is no need to buy, operate, power, cool, manage, support and house such devices.
With a single huge data store with NVMe access and, effectively, parallel access to the data, then analytics can be run without any need for a separate distributed Hadoop server infrastructure.
The way data is written and erasure coded is crucial to VAST’s data protection capabilities and centres on striping.
Suppose a QLC drive fails. Its data contents have to be rebuilt using the data stripes on the other drives. Here things gets clever. VAST Data’s System has clusters of databoxes with 20-30 drives each. There can be 1,000 data boxes and so 20,000 – 30,000 drives. Because it has so many drives with a global view VAST it has its own way of global erasure coding which has a low overhead. With, for example, a 150+4, you can lose 4 drives without losing data and have just a 2.7 per cent overhead.”
VAST says its 150+4 scheme is 3x faster than a smaller disk stripe, such as 8+2, and classic Reed-Solomon rebuilds.
VAST Data DBOX3 databox.
The stripe erasure code parameters are dynamic. As databoxes are added the stripe lengths can be extended, increasing resilience. We could envisage a 500+10 stripe structure. Ten drives can be lost and the overhead is even loser, at two per cent. This scheme is twice as fast as disk drives at erasure rebuilds.
With a 150+4 structure customer need to read (recover) from all the drives but only an amount that’s equivalent to a quarter of the drives. There are specific areas in XPoint for the resiliency scheme, and they tell a compute node part from this drive and that part from that drive, using locally decodable algorithms.
Because of these locally decodable codes VAST does not need to read from the entirety of the wide stripe in order to perform a recovery.
So each CPU reads its part of the stripes on the failed drives and recovery is, VAST says, fast. It’s roughly like Point-in-Time recovery from synthetic backups.
Next
Move on and explore more parts of the VAST Data storage universe;
VAST Data was founded in 2016 by CEO Renen Hallak, an ex-VP for R&D at XtremIO and its first engineer. Some time before that he worked on computer science looking at computing complexity, which seems appropriate.
He left XtremIO in 2015 and had a round of talks with potential customers and storage companies, talking about storage needs and technology roadmaps before founding VAST Data.
Hallak’s key insight was that customers did not want tiered storage systems but had to use them because flash storage was too expensive and not capacious enough, while disk was too slow.
He came round to thinking that QLC (4 bits/cell) flash and better data reduction could provide the capacity and XPoint the fast write persistence and metadata storage. NVMe over fabrics could provide a base for decoupled compute nodes running storage controller-type logic, accessing storage drives fast, and enabling huge scalability.
VAST Data founder and CEO Renen Hallak
Ex-Dell EMC exec Mike Wing is VAST Data’s president and owns sales. He spent 15 years at EMC and then Dell EMC, running the Xtremio business and packaging VMAX and Unity all-flash systems.
Shacher Fienblit is the VP for R&D, coming from being the CTO at all-flash array vendor Kaminario. Jeff Denworth is VP for Product Management, and joined from CTERA. Analyst Howard Marks, the Deep Storage Net guy, is a tech evangelist and it’s his first full time post since 1987.
VAST Data’s R&D is in Israel. Everything else is in the USA, including the New York headquarters and mostly on the East Coast, because that’s where most of the target customers are to be found. There is a support office in Silicon Valley.
It received $40m in A-round funding in 2017 and had just has raised $40M of Series B funding, with the round led by TPG Growth, with participation from existing investors including Norwest Venture Partners, Dell Technologies Capital, 83 North and Goldman Sachs. Total funding is $80M.
Now VAST has come out of stealth, confident it has world-beating storage technology.
It sells its product three ways;
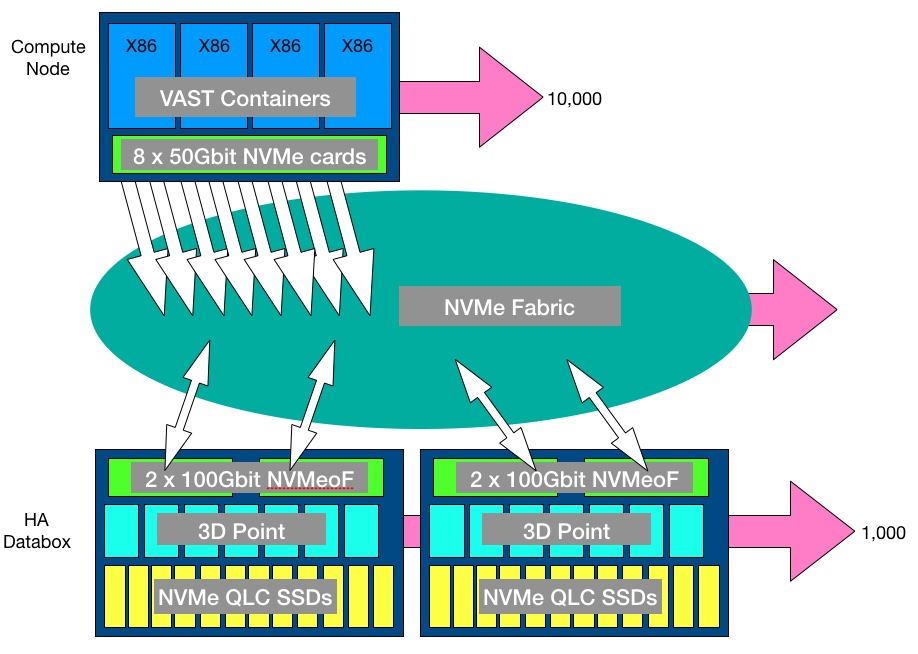
As a 2U quad server appliance, with 8 x 50Gbit/s Ethernet links, running VAST containers, presenting NFS and S3 out to client servers, and the databox enclosure,
As a Docker container image and databox enclosures, with the host servers running apps as well as the VAST containers,
As a Docker container, meaning software-only.
The last point means that VAST could run in the public cloud, were the public cloud able to configure databoxes in the way VAST needs.
Every startup loves its technology baby and is convinced it is the most beautiful new child in the world. Hallack and his team are certain VAST will become a vast business.
If they are right VAST will be not just an extinction event for hard disk drives but also represent a threat to virtually all existing HW and SW storage companies. Can its tech live up to this potential or will it, like other startups, be a shooting star, with a bright but brief burst of light before burning up? We’ll see. It’s going to be an interesting ride; that’s for sure.
Next
Explore more parts of the VAST Data storage universe;
The VAST Data system employs a Universal Storage filesystem. This has a DASE (Disaggregated Shared Everything) datastore which is a byte-granular, thin-provisioned, sharded, and has an infinitely-scalable global namespace.
It involves the compute nodes being responsible for so-called element stores.
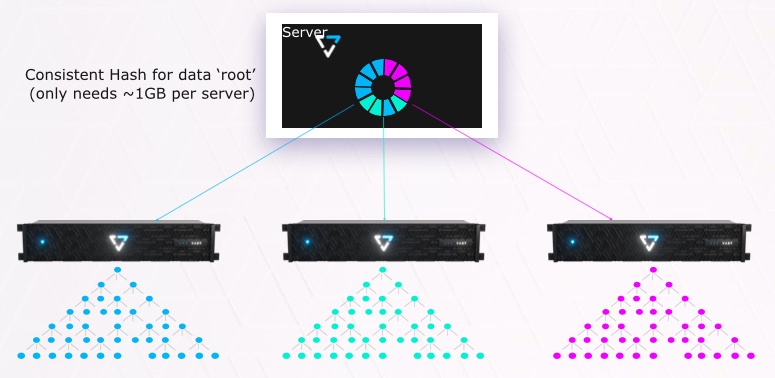
These element stores use V-tree metadata structures, 7-layers deep with each layer 512 times larger than the one above it. This V-tree structure is capable of supporting 100 trillion objects. The data structures are self-describing with regard to lock and snaps states and directories.
VAST Data tech evangelist Howard Marks said: ‘Since the V-trees are shallow finding a specific metadata item is 7 or fewer redirection steps through the V-Tree. That means no persistent state in the compute-node (small hash table built at boot) [and] adding capacity adds V-Trees for scale.”
The colour wheel in the server is the consistent hash table in the compute-node that provides the first set of pointers to the blue, cyan and magenta V-trees in the data-nodes.
There is a consistent hash in each compute node which tells that compute node which V-tree to use to locate a data object.
The 7-layer depth means V-trees are broad and shallow. Marks says: “More conventional B-tree, or worse, systems need tens or hundreds of redirections to find an object. That means the B-Tree has to be in memory, not across an NVMe-oF fabric, for fast traversal, and the controllers have to maintain coherent state across the cluster. Since we only do a few I/Os we can afford the network hop to keep state in persistent memory where it belongs.”
V-trees are shared-everything and there is no need for cross-talk between the compute nodes. Jeff Denworth, product management VP, said: “Global access to the trees and transactional data structures enable a global namespace without the need of cache coherence in the servers or cross talk. Safer, cheaper, simpler and more scalable this way.”
There is no need for a lock manager either as lock state is read from XPoint.
A global flash translation system is optimised for QLC flash with four attributes:
Indirect-on-write system writing full QLC erase blocks which avoids triggering device-level garbage collection,
3D XPoint buffering ensures full-stripe writes to eliminate flash wear caused by read-modify-write operations,
Universal wear levelling amortises write endurance to work toward the average of overwrites when consolidating long-term and short-term data,
Predictive data placement to avoid amplifying writes after application has persisted data.
The idea of long-term and short-term data enables long-term data (with low rewrite potential) to be written on erase blocks with limited endurance left. Short-term data with higher rewrite potential can go to blocks with more write cycles left.
VAST buys the cheapest QLC SSDs it can find for its databoxes as it does not need any device-level garbage collection and wear-levelling, carrying out these functions itself.
VAST guarantees its QLC drives will last for 10 years with these ways of reducing write amplification. That lowers the TCO rating.
Remote Sites
NVMe-oF is not a wide-area network protocol as it is LAN distance-limited. That means distributed VAST Data sites need some form of data replication to keep them in sync. The good news is, Blocks & Files envisages, is that only metadata and reduced data needs to be sent over the wire to remote sites. VAST Data confirms that replication is on the short-term roadmap.
Next
Explore more aspects of the VAST Data storage universe;
Separate scaling of compute and data is central to VAST’s performance claims. Here is a top-level explanation of how it is achieved.
In VAST’s scheme there are compute nodes and databoxes – high-availability DF-5615 NVMe JBOFs, connected by NVMe-oF running across Ethernet or InfiniBand. The x86 servers run VAST Universal File System (UFS) software packaged in Docker containers. The 2U databoxes are dumb, and contain 18 x 960GB of Optane 3D XPoint memory and 583TB of NVMe QLC (4bits/cell) SSD (38 x 15.36TB; actually multiple M.2 drives in U.2 carriers). Data is striped across the databoxes and their drives.
The XPoint is not a tier. It is used for storing metadata and as an incoming write buffer.
The QLC flash does not need a huge amount of over-provisioning to extend its endurance because VAST’s software reduces write amplification and data is not rewritten that much.
All writes are atomic and persisted in XPoint; there is no DRAM cache. Compute nodes are stateless and see all the storage in the databoxes. If one compute node fails another can pick up its work with no data loss.
There can be up to 10,000 compute nodes in a loosely-coupled cluster and 1,000 databoxes in the first release of the software, although these limits are, we imagine, arbitrary.
A 600TB databox is part of a global namespace and there is global compression and protection. It provides up to 2PB of effective capacity and, therefore, 1,000 of them provide 2EB of effective capacity.
The compute nodes present either NFS v3 file access to applications or S3 object access, or both simultaneously. A third access protocol may be added. Possibly this could be SMB. Below this protocol layer the software manages a POSIX-compliant Element Store containing self-describing data structures; the databoxes accessed across the NVMe fabric running on 100Gbit/s Ethernet or InfiniBand.
Compute nodes can be pooled so as to deliver storage resources at different qualities of service out to clients.
Next
Explore other parts of the VAST Data storage universe;