


Yesterday’s ObjectEngine launch is notable for what it brings to Pure’s future data management table. This is Pure’s third hardware platform, joining FlashArray for primary data and FlashBlade for secondary, unstructured data.
ObjectEngine positions Pure Storage for a multi-cloud, data copy serving and Data-as-a-Service future, taking on Actifio, Cohesity and Delphix.
The company says the technology is suitable for machine learning, data lakes, analytics, and data warehouses – “helping you warm up your cold data.”

The software inside comes from an acquisition, StorReduce, and a look at pre-acquisition partner documentation tells us how the software operates and where Pure could take it.
ObjectEngine is a scale-out, clustered inline deduping system. It accepts incoming backup files via an S3 interface, squashing them, and sends them along to an S3-compliant back-end – either on-premises Pure FlashBlade arrays or AWS S3 object storage. For restoration, ObjectEngine fetches the back-end S3 files and rehydrating them.
A Pure Storage Gorilla Guide mentions this point: “It’s conceivable that more public and private cloud services will be supported to help reduce the complexity and cost of F2F2C (flash to flash to cloud) backup strategies.”
The Pure Storage vision extends beyond data storage and data protection to data management.
Flash dedupe metadata
A StorReduce server uses x86 processors and stores dedupe metadata on SSDs:
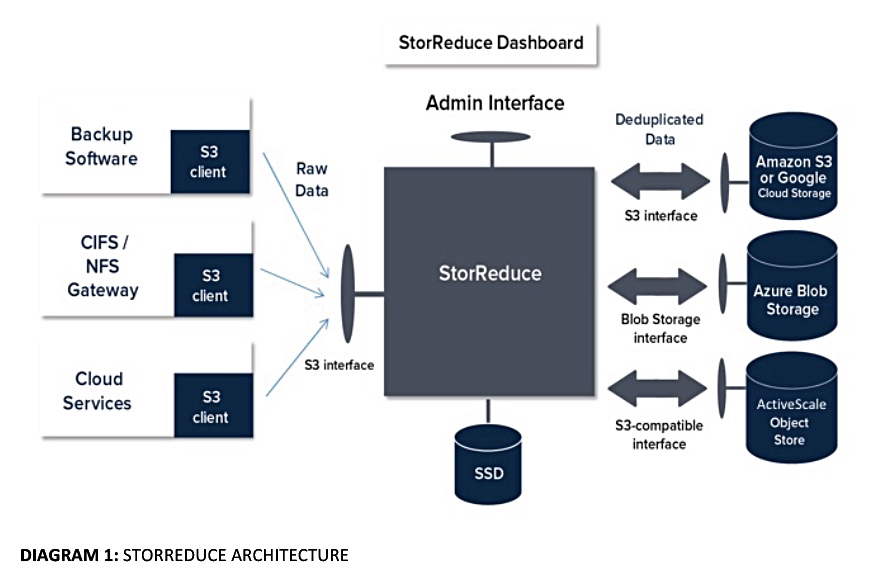
The Gorilla Guide doc says each StorReduce server keeps its own independent index on local SSD storage.
As I note here, Pure has not published deduplication ratios, but it gives big clue in the Gorilla Guide: “The amount of raw data a StorReduce server can handle depends on the amount of fast local storage available and the deduplication ratio achieved for the data. … Typically, the amount of SSD storage required is less than 0.2 per cent of the amount of data put through StorReduce, for a standalone server.”
StorReduce servers use backend object storage for:
- Deduplicated and compressed user data. Typically, this requires as little as 3 per cent of the object storage space that the raw data would have required, depending on the type of data stored.
- System Data: Information about buckets, users, access control policies, and access keys, making it available to all StorReduce servers in a given deployment.
- Index snapshots: Data for rapidly reconstructing index information on local storage.
Note this point, which is counter-intuitive considering SSDS are non-volatile: “The StorReduce server treats local SSD storage as ephemeral. All information stored in local storage is also sent to object storage and can be recovered later if required.”
A server failure means that another server can pick up its load using the failed server’s back-end stored information.
With the metadata held in local flash, “StorReduce can create writable “virtual clones” of all the data in a storage bucket, without using additional storage space.”
It can “create unlimited virtual clones for testing or distribution of data to different teams in an organisation. Copy-on-write semantics allow each individual clone of the data to diverge as new versions of individual objects are written.”
Multiple clouds
StorReduce software could store its deduped data on on-premises S3-accessed arrays, Amazon S3 or S3IA, Microsoft Azure Blob Storage, or Google Cloud Storage. ObjectEngine only supports FlashBlade and AWS S3 – for now.
We have no insider knowledge but it seems a logical next step to enlarge the addressable market for ObjectEngine by extending support for Azure Blob storage and Google Cloud Platform (GCP).
Furthermore ObjectEngine could migrate data between these clouds by converting S3 buckets into Azure blobs or the GCP equivalent. The StorReduce doc says: “StorReduce can replicate data between regions, between cloud vendors, or between public and private cloud to increase data resiliency.”
The system transfers unique data only to reduce network bandwidth needs and transmission time.
Data copy services
StorReduce had the facility of having StorReduce instances taking a freshly deduped object set, rehydrating it and pumping it out for re-use. This fits perfectly with Pure’s DataHub ideas, as mapped out below.
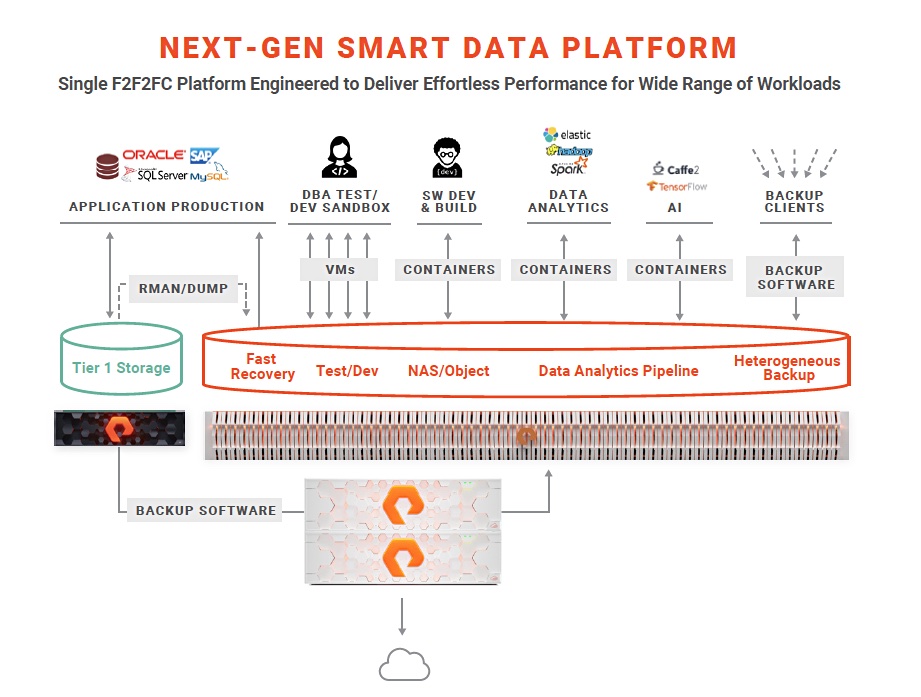
Here we see the likelihood of Pure taking direct aim at Activity, Cohesity and Delphix in the copy data management market.
ObjectEngine opens several data management doors for Pure Storage. Expect these doors to start being delineated over the next few quarters as Pure builds out its third hardware platform.





