Toshiba told Blocks & Files yesterday that its P300 desktop disk drives use shingled magnetic recording technology (SMR), which can exhibit slow data write speeds. However, the company does not mention this in end user drive documentation.
All three disk drive manufacturers – Western Digital, Seagate and Toshiba – have now confirmed to Blocks & Files the undocumented use of SMR technology in desktops HDDs and in WD’s case, WD Red consumer NAS drives. SMR has enabled the companies to reach higher capacity points than otherwise possible. But this has frustrated many users, who have speculated why their new drives are not working properly in their NAS set-ups.
According to the Geizhals price comparison website, Toshiba’s P300 desktop 4TB (HDWD240UZSVA) and 6TB (HDWD260UZSVA) SATA disk drives use SMR.
Toshiba P300 SMR results from Geizhals search
A P300 datasheet does not mention SMR. It states: “Toshiba’s 3.5-inch P300 Desktop PC Hard Drive delivers a high performance for professionals.” However, SMR drives can deliver a slow rewrite speed.
Blocks & Files asked Toshiba to confirm that the 4TB and 6TB P300 desktop drives use SMR and clarify which drives in its portfolio use SMR.
A company spokesperson told us: “The Toshiba P300 Desktop PC Hard Drive Series includes the P300 4TB and 6TB, which utilise the drive-managed SMR (the base drives are DT02 generation 3.5-inch SMR desktop HDD).
“Models based on our MQ04 2.5-inch mobile generation all utilise drive-managed SMR, and include the L200 Laptop PC Hard Drive Series, 9.5mm 2TB and 7mm 1TB branded models.
“Models based on our DT02 3.5-inch desktop generation all utilise drive managed SMR, and include the 4/6TB models of the P300 Series branded consumer drives.”
The company also told us which other desktop drives did and did not use SMR:
MD07ACA – 7,200rm 12TB, 14TB CMR (base of X300 Performance Hard Drive Series branded models
MD04 – 7,200rpm – 2, 4, 5, 6TB CMR (base for X300 Performance Hard Drive Series branded models
DT02 – 5,400rpm – 4, 6 TB SMR (base for P300 Desktop PC Hard Drive Series 4TB and 6TB branded models)
DT01 – 7, 200rpm – 500GB, 1,2,3 TB CMR (base for P300 Desktop PC Hard Drive Series 1/2/3TB branded models)
Why SMR is sub-optimal for write-intensive workloads
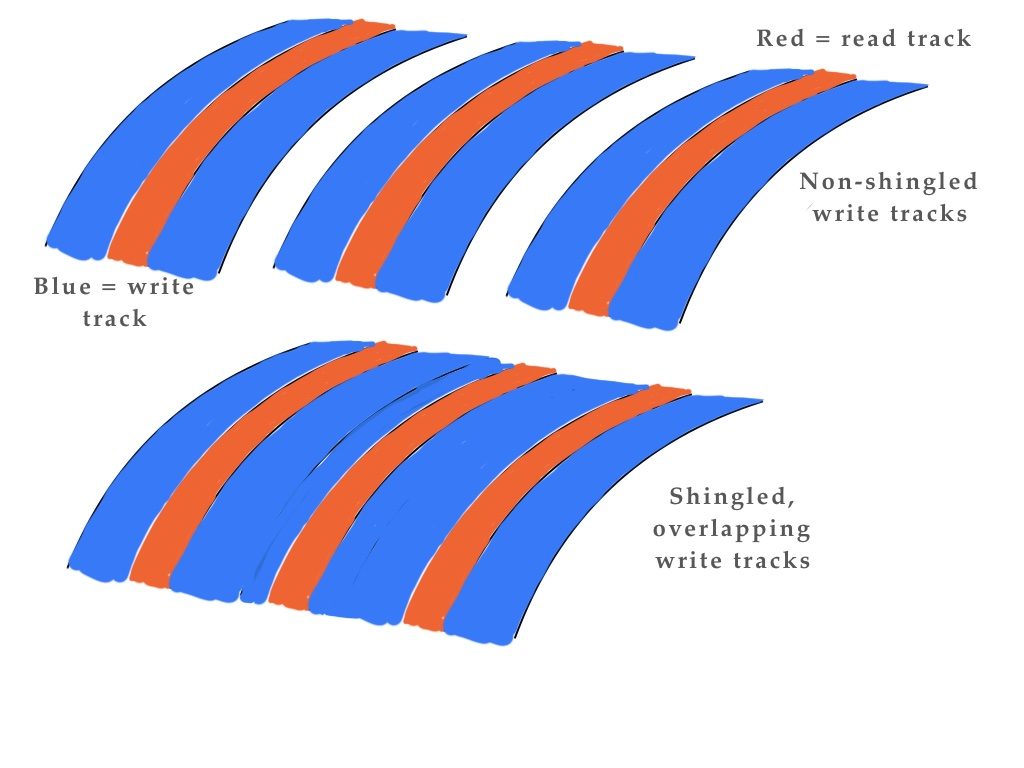
Shingled magnetic recording gets more data to disk plates by partially overlapping write tracks, leaving the read track within them clear. Read IO speed is unaffected but data rewrites requires blocks of tracks to be read edited with the new data and rewritten as a new block. This lengthens data rewrite time substantially compared with conventionally recorded drives.
Caching writes to a non-shingled zone of the drive and writing them out to the shingled sectors in idle time will hide the slow rewrite speed effectively – until the cache fills when rewrite IO requests are still coming in.
The cache is then flushed and all the data written to the shingled area of the drive, causing a pause of potentially many seconds while this is done.
Cohesity has developed a smartphone app for its Helios management software, to better enable admin staff to respond to external threats in real time.
Cohesity smartphone Helios alert
For instance, the manager of a Cohesity infrastructure can now receive ransomware alerts 24×7 on their Apple or Android phone. They respond to the alert by logging in to Helios via a web browser to manage their Cohesity installation.
The manager could initiate system changes, stage a recovery or get to the workload where an anomaly had been spotted faster than simply relying on regular checks, Cohesity claims.
Vineet Abraham, Cohesity SVP of products and engineering, said in a statement: “Cybercriminals don’t just work during office hours and having a way to monitor the health of your data clusters from a mobile device 24 hours a day, seven days a week, and receive notifications that could uncover a ransomware attack in action, could save your organisation millions of dollars and keep brand reputations intact.”
Data change rates
Using Cohesity software, an organisation can converge all its secondary data into a single storage vault covering on-premises and public cloud environments. Data is backed up and protected with immutable snapshots, and the public cloud can be used as a file tier and to store backup data.
Helios can detect a ransomware attack by tracking data change rates and recognising any larger than normal daily change rates. Such a change could be the result of ransomware data encryption activity, general malware or people maliciously trying to modify data in the production IT environment.
Helios also matches data stored and storage utilisation against historic patterns as well as data change rates.
This data state tracking uses machine learning models. Helios send alerts to the Cohesity manager’s phone and also to the customer’s IT security facility so that any attack activity can be stopped and systems disinfected.
Cohesity’s Helios mobile app also provides:
Support case status tracking across a customer’s entire Cohesity estate
Cohesity installation health
Protection status of virtual machines, databases, and applications
Storage utilisation and performance for backup, recovery, file services and object storage.
Cohesity last week announced the completion of a $250m capital raise which valued the company at $2.5bn.
Some Seagate Barracuda Compute and Desktop disk drives use shingled magnetic recording (SMR) technology which can exhibit slow data write speeds. But Seagate documentation does not spell this out.
A 5TB Desktop HDD (ST5000DM000) product manual does not mention SMR.
The Archive drives are for archiving and Exos drives are optimised for maximum storage capacity and the highest rack-space efficiency. Seagate documentation for the Exos and Archive HDDs explicitly spells out that they use SMR.
Seagate markets the Barracuda Compute drives as fast and dependable. Yet it is the nature of SMR drives that data rewrites can be slow.
When we asked Seagate about the Barracudas and the Desktop HDD using SMR technology, a spokesperson told us: “I confirm all four products listed use SMR technology.”
In a follow-up question, we asked why isn’t this information is not explicit in Seagate’s brochures, data sheets and product manuals – as it is for Exos and Archive disk drives?
Seagate’s spokesperson said: “We provide technical information consistent with the positioning and intended workload for each drive.”
Update
Seagate issued this statement on April 21: “Seagate confirms that we do not utilize Shingled Magnetic Recording technology (SMR) in any IronWolf or IronWolf Pro drives – our NAS solutions family. Seagate does not market the BarraCuda family of products as being suitable for NAS applications, and does not recommend using BarraCuda drives for NAS applications. Seagate always recommends to use the right drive for the right application.”
Why SMR drives are sub-optimal for write-intensive workloads
Shingled magnetic recording gets more data to disk plates by partially overlapping write tracks, leaving the read track within them clear. Read IO speed is unaffected but data rewrites requires blocks of tracks to be read edited with the new data and rewritten as a new block. This lengthens data rewrite time substantially compared with conventionally recorded drives.
Caching writes to a non-shingled zone of the drive and writing them out to the shingled sectors in idle time will hide the slow rewrite speed effectively – until the cache fills when rewrite IO requests are still coming in.
The cache is then flushed and all the data written to the shingled area of the drive, causing a pause of potentially many seconds while this is done.
The revelation that some WD Red NAS drives are shipped with DM-SMR (Drive-Managed Shingled Magnetic Recording) prompted us to ask more detailed questions to the Blocks & Files reader who alerted us to the issue.
Alan Brown, a British university network manager, has a high degree of SMR smarts and we are publishing our interview with him to offer some pointers to home and small business NAS disk drive array builders.
Blocks & Files: Can you contrast CMR (Conventional Magnetic Recording) and SMR write processes?
Alan Brown: When you write to a CMR disk, it just writes to sectors. Some drives will try to optimise the order the sectors are written in, but they all write data to the exact sector you tell them to write it to.
When you write to a SMR disk it’s a bit like writing to SSD – no matter what sector you might THINK you’re writing to, the drive writes the data where it wants to, then makes an index pointing to it (indirect tables).
Blocks & Files shingling diagram
What’s below is for Drive-managed SMR drives. Some of this is conjecture, I’ve been trying to piece it together from the literature.
Essentially, unlike conventional drives, a SMR drive puts a lot of logic and distance between the interface and the actual platter. It’s far more like a SSD in many ways (only much much slower).
SMR disks have multiple levels of caching – DRAM, then some CMR zones and finally shingled zones
In general, writes are to the CMR space and when the disk is idle the drive will rearrange itself in the background – tossing the CMR data onto shingled areas – there might be 10-200 shingled “zones”. They’re all “open”(appendable) like SSD blocks are. If a sector within a zone needs changing, the entire zone must be rewritten (in the same way as SSD blocks) and zones can be marked discarded (trimmed) in the same way SSD blocks are.
Blocks & Files: What happens if the CMR zone becomes full?
Alan Brown: When the CMR zone fills the drive may (or may not) start appending to a SMR zone – and in doing so it slows down dramatically.
If the drive stops to flush out the CMR zone, then the OS is going to see an almighty pause (ZFS reports dozens of delays exceeding 60 seconds – the limit it measures for – and I measured one pause at 3 minutes). This alone is going to upset a lot of RAID controllers/software. [A] WD40EFAX drive which I zero-filled averaged 40MB/sec end to end but started at 120MB/sec. (I didn’t watch the entire fill so I don’t know if it slowed down or paused).
Blocks & Files: Does resilvering (RAID array data rebalancing onto new drive in group) involve random IO?
Alan Brown: In the case of ZFS, resilvering isn’t a block level “end to end” scan/refill, but jumps all over the drive as every file’s parity is rebuilt. This seems to trigger a further problem on the WD40EFAXs where a query to check a sector that hasn’t been written to yet causes the drive to internally log a “Sector ID not found (IDNF)” error and throws a hard IO error from the interface to the host system.
RAID controllers (hardware or software, RAID5/6 or ZFS ) will quite sensibly decide the drive is bad after a few of these and kick the thing out of the array if it hasn’t already done so on the basis of a timeout.
[Things] seems to point to the CMR space being a few tens of GB up to 100GB on SMR drives. So, as long as people don’t continually write shitloads, they won’t really see the issue, which means when for most people “when you’re you’re resilvering is the first time you’ll notice something break.”
(It certainly matches what I noticed – which is that resilvering would run at about 100MB/s for about 40 minutes then the drives would “DIE” and repeatedly die if I attempted to restart the resilvering, however if I left it an hour or so, they’d run for 40 minutes again before playing up.)
Blocks & Files: What happens with virgin RAID arrays?
Alan Brown: When you build a virgin RAID array using SMR, it’s not getting all those writes at once. There are a lot of people claiming “I have SMR raid arrays, they work fine for me”.
Rather tellingly … so far none of them have come back to me when I’ve asked: “What happens if you remove a drive from the RAID set, erase it and then add it back in so it gets resilvered?”
Blocks & Files: Is this a common SMR issue?
Alan Brown: Because I don’t have any Seagate SMR drives, I can’t test the hypothesis that the IDNF issue is a WD firmware bug rather than a generic SMR issue. But throwing an error like that isn’t the kind of thing I’d associate with SMR as such – I’d simply expect throughput to turn to shit.
It’s more likely that WD simply never tested adding drives back to existing RAID sets or what happens if a SMR drive is added to a CMR RAID set after a disk failure – something that’s bound to happen when they’re hiding the underlaying technology – shipped a half-arsed firmware implementation and blamed users when they complained (there are multiple complaints about this behaviour. Everyone involved assumed they had “a bad drive”).
To make matters worse, the firmware update software for WD drives is only available for Windows and doesn’t detect these drives anyway.
The really annoying part is that the SMR drive was only a couple of pounds cheaper than the CMR drive, but, when I purchased these drives, the CMR drive wasn’t in stock anyway.
I just grabbed 3 WD Reds to replace 3 WD Reds in my home NAS (as you do…), noticed the drives had larger cache, compared the spec sheet, couldn’t see anything different (if you look at the EFRX vs EFAX specs on WD’s website you’ll see what I mean) and assumed it was just a normal incremental change in spec.
Blocks & Files: What about desktop drive SMR?
Alan Brown: The issue of SMR on desktop drives is another problem – I hadn’t even realised that this was happening, but we HAD noticed extremely high failure rates on recent 2-3TB drives we put in desktops for science work (scratchpad and NFS-cache drives). Once I realised that was going on with the Reds, I went back and checked model numbers on the failed drives. Sure enough, there’s a high preponderance of drive managed-SMR units and it also explains mysterious “hangs” in internal network transfers that we’ve been unable to account for up until now.
I raised the drives issue with IxSystems – our existing TruNAS system is approaching EOL, so I need to replace it and had a horrible “oh shit, what if the system we’ve specified has hidden SMR in it?” sinking feeling. TruNAS are _really_ good boxes. We’ve had some AWFUL NAS implementations in the past and the slightest hint of shitty performance would be politically dynamite on a number of levels so I needed to ensure we headed off any trouble at the pass.
It turns out ixSystems were unaware of the SMR issue in Reds – and they recommend/use them in the SOHO NASes. They also know how bad SMR drives can be (their stance is “SMR == STAY AWAY”) and my flagging this raised a lot of alarms.
Blocks & Files: Did you eventually solve the resilvering problem?
Alan Brown: I _was_ able to force the WD40EFAX to resilver – by switching off write caching and lookahead. This dropped the drive’s write speed to less than 6MB/sec and the resilvering took 8 days instead of the more usual 24 hours. More worryingly, once added, a ZFS SCRUB (RAID integrity check) has yet to successfully complete without that drive producing checksum errors, even after 5 days of trying.
I could afford to try that test because RAIDZ3 gives me 3 parity stripes, but it’s clear the drive is going to have to come out and the 3 WD Reds returned as unfit for the purpose for which they are marketed.
Some users are experiencing problems adding the latest WD Red NAS drives to RAID arrays and suspect it is because they are actually shingled magnetic recording drives submarined into the channel.
Alan Brown, a network manager at UCL Mullard Space Science Laboratory, the UK’s largest university-based space research group, told us about his problems adding a new WD Red NAS drive to a RAID array at his home. Although it was sold as a RAID drive, the device “keep[s] getting kicked out of RAID arrays due to errors during resilvering,” he said.
Resilvering is a term for adding a fresh disk drive to an existing RAID array which then rebalances its data and metadata across the now larger RAID group.
Brown said: “It’s been a hot-button issue in the datahoarder Reddit for over a year. People are getting pretty peeved by it because SMR drives have ROTTEN performance for random write usage.”
However, SMR drives are not intended for random write IO use cases because the write performance is much slower than with a non-SMR drive. Therefore they are not recommended for NAS use cases featuring significant random write workloads.
Smartmontools ticket
Brown noted: “There’s a smartmontools ticket in for this [issue] – with the official response from WDC in it – where they claim not to be shipping SMR drives despite it being trivial to prove otherwise.”
That ticket’s thread includes this note:
“WD and Seagate are _both_ shipping drive-managed SMR (DM-SMR) drives which don’t report themselves as SMR when questioned via conventional means. What’s worse, they’re shipping DM-SMR drives as “RAID” and “NAS” drives This is causing MAJOR problems – such as the latest iteration of WD REDs (WDx0EFAX replacing WDx0EFRX) being unable to be used for rebuilding RAID[56] or ZFS RAIDZ sets: They rebuiild for a while (1-2 hours), then throw errors and get kicked out of the set.”
(Since this article was published Seagate and Toshiba have also confirmed the undocumented use of shingled magnetic recording in some of their drives.)
The smartmontools ticket thread includes a March 30, 2020, mail from Yemi Elegunde, Western Digital UK enterprise and channel sales manager:
“Just a quick note. The only SMR drive that Western Digital will have in production is our 20TB hard enterprise hard drives and even these will not be rolled out into the channel. All of our current range of hard drives are based on CMR Conventional Magnetic Recording. [Blocks & Files emboldening.] With SMR Western Digital would make it very clear as that format of hard drive requires a lot of technological tweaks in customer systems.”
WD’s website says this about the WD Red 2TB to 12TB 6Gbit/s SATA disk drives: “With drives up to 14TB, the WD Red series offers a wide array of solutions for customers looking to build a high performing NAS storage solution. WD Red drives are built for up to 8-bay NAS systems.” The drives are suitable for RAID configurations.
Synology WD SMR issue
There is a similar problem mentioned on a Synology Forum where a user added 6TB WD Red [WD60EFAX] drive to a RAID setup using three WD Red 6TB drives [WD60EFRX] in SHR1 mode. He added a fourth drive to convert to SHR2 but conversion took two days and did not complete.
The hardware compatibility section on Synology’s website says the drive is an SMR drive:
The Synology forum poster said he called WD support to ask if the drive was an SMR or conventionally recorded drive: “Western Digital support has gotten back to me. They have advised me that they are not providing that information so they are unable to tell me if the drive is SMR or PMR. LOL. He said that my question would have to be escalated to a higher team to see if they can obtain that info for me. lol”
Also: “Well the higher team contacted me back and informed me that the information I requested about whether or not the WD60EFAX was a SMR or PMR would not be provided to me. They said that information is not disclosed to consumers. LOL. WOW.“
Price comparison
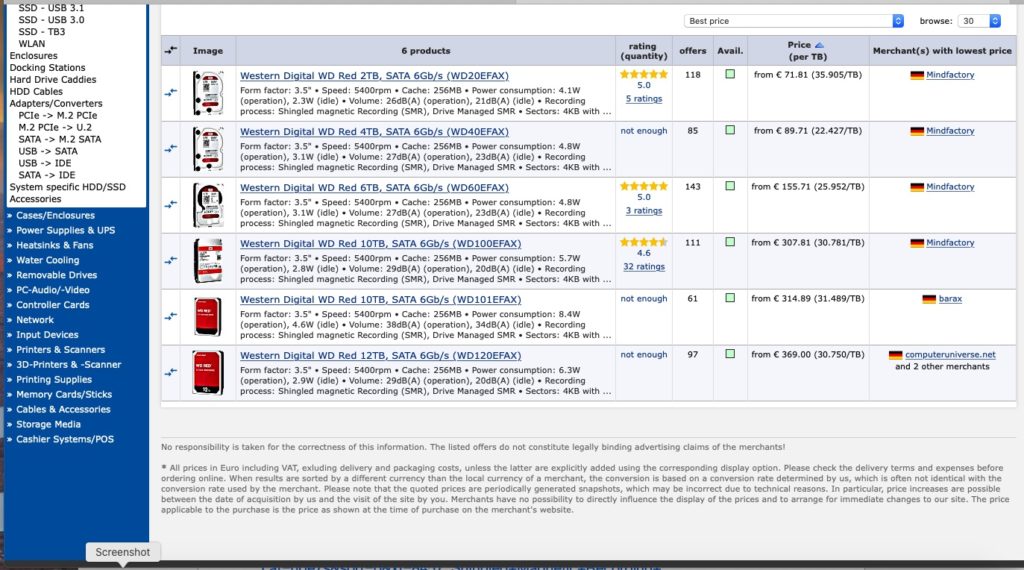
A search on Geizhals, a German language price comparison site, shows various disk drives using shingled magnetic media recording. Here, for example, is a search result listing for WD Red SATA HDDs with SMR technology. The result is:
However, a WD Red datasheet does not mention SMR recording technology.
WD comment
We brought all these points to Western Digital’s attention and a spokesperson told us:
“All our WD Red drives are designed meet or exceed the performance requirements and specifications for common small business/home NAS workloads. We work closely with major NAS providers to ensure WD Red HDDs (and SSDs) at all capacities have broad compatibility with host systems.
“Currently, Western Digital’s WD Red 2TB-6TB drives are device-managed SMR (DMSMR). WD Red 8TB-14TB drives are CMR-based.
“The information you shared from [Geizhals] appears to be inaccurate.
“You are correct that we do not specify recording technology in our WD Red HDD documentation.
“We strive to make the experience for our NAS customers seamless, and recording technology typically does not impact small business/home NAS-based use cases. In device-managed SMR HDDs, the drive does its internal data management during idle times. In a typical small business/home NAS environment, workloads tend to be bursty in nature, leaving sufficient idle time for garbage collection and other maintenance operations.
“In our testing of WD Red drives, we have not found RAID rebuild issues due to SMR technology.
“We would be happy to work with customers on experiences they may have, but would need further, detailed information for each individual situation.”
Comment
Contrary to what WD channel staff have said, the company is shipping WD Red drives using SMR technology. (Since publication of this article, Western Digital has published a statement about SMR use in 2TB-6TB WD Red NAS drives.)
WD told us: “In a typical small business/home NAS environment, workloads tend to be bursty in nature, leaving sufficient idle time for garbage collection and other maintenance operations.”
Not all such environments are typical and there may well not be “sufficient idle time for garbage collection and other maintenance operations”.
We recommend posters on the Synology forum, data hoarder Reddit and smartmontools websites to get back in touch with their WD contacts, apprise them of the information above and let them know that WD is “happy to work with customers on experiences they may have”.
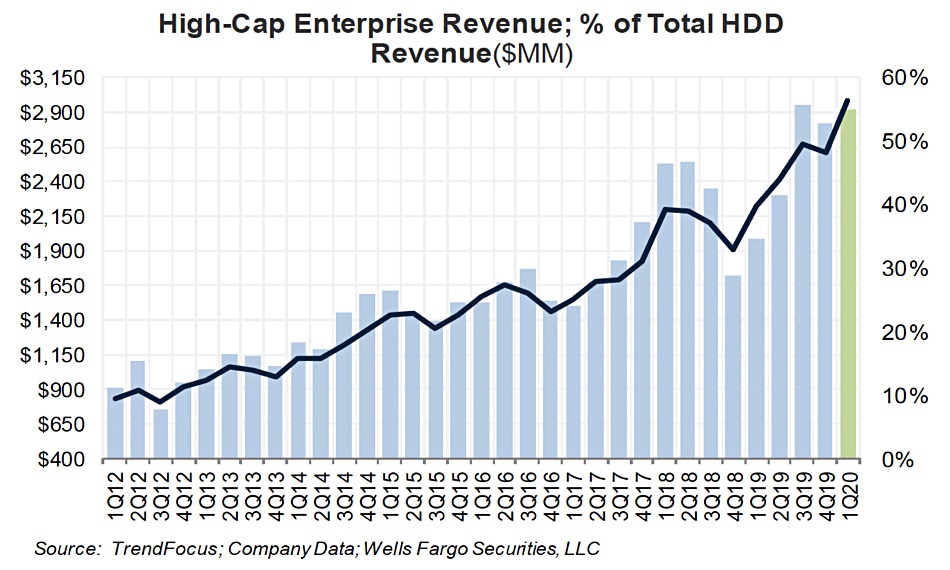
Disk shipments in 2020’s first quarter show nearline drives taking up almost half of all HDD units and the majority of capacity and revenue. Shipments for all other types of hard disk drives declined in the quarter, according to the specialist market research firm Trendfocus.
This confirms the general trend for increased nearline drive unit sales, taking up more capacity and revenue share of the HDD market. Hyperscaler buyers such as the cloud service providers represent the main proportion of nearline disk buyers.
Trendfocus estimates somewhere between 66.5 million and 68.1 million disk drives shipped in the first quarter – 67.3 million at the mid-point, which is a 13 per cent decline year on year. Seagate had 42 per cent unit share, Western Digital took 37 per cent and Toshiba 21 per cent.
The 3.5-inch high-capacity nearline category totalled 15.7 million drives, up 43 per cent. This represents 23.3 per cent of all disk drive shipments.
Nearline drives accounted for about 150EB of capacity, up 65 per cent compared with +43 per cent and +89 per cent in Q3 2019 and Q4 2019. According to Wells Fargo analyst Aaron Rakers, nearline drives could account for 55 per cent of total Q1 2020 HDD industry revenue, up two per cent on 2019.
Some 24 million 2.5-inch mobile drives were shipped in Q1, which is down more than 45 per cent y/y, according to Rakers. He thinks some of the decline reflects the “supply chain disruption from covid-19”. Seagate and Western Digital each had about 35 per cent unit share and Toshiba shipped 30 per cent.
About 23 million 3.5-inch desktop drives shipped in the quarter, down 20 per cent on the previous quarter, Rakers noted, citing “seasonal declines, as well as reduced mid-quarter PC and surveillance production due to covid-19”.
The last category is for 2.5-inch enterprise or mission-critical drives and just 4.2 million were shipped, down 12 per cent on the previous quarter. Rakers said: “Shipments continue to face increased SSD replacement.”
China’s Yangtze Memory Technology Corporation (YMTC) has begun sampling what it claims is the world’s highest density and fastest bandwidth NAND flash memory.
YMTC has developed the X2-6070 chip with a 1.333Tb capacity and 1.6Gbit/s IO speed using 128-layer 3D NAND with QLC (4 bits per cell) format. The chipmaker has also launched the X2-9060 chip with 512Gbit capacity and a TLC (triple-level cell) format from its 128 layers.
YMTC 128-layer QLC NAND chips
Grace Gong, YMTC’s SVP of marketing and sales, said the company will target the new QLC product at consumer grade solid-state drives initially and then extend the range into enterprise-class servers and data centres.
QLC is coming
Gregory Wong, principal analyst of Forward Insights, said in the YMTC press release: “As client SSDs transition to 512GB and above, the vast majority will be QLC-based. The lower read latency of enterprise and datacenter QLC SSDs compared to hard drives will make it suitable for read-intensive applications in AI, machine learning and real-time analytics, and Big Data. In consumer storage, QLC will become prevalent in USB flash drives, flash memory cards, and external SSDs.”
YMTC said the X2-6070 has passed sample verification on SSD platforms through working with multiple controller partners. We can expect several QLC and TLC SSDs using the X2-6070 and X2-9060 chips to launch in China, and possibly in other countries, between now and mid-2021.
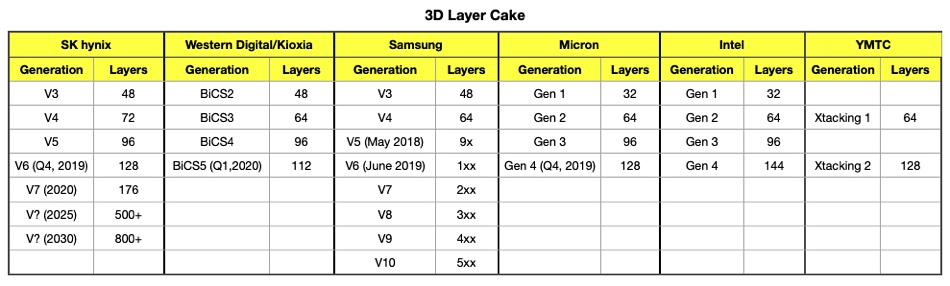
With this launch, YMTC, a self-acknowledged newcomer to the flash memory industry, has joined the mainstream NAND vendors in developing 100+ layer technology.
The net result of their efforts is that SSDs using 100+layer 3D NAND in QLC format should ship from multiple sources in 2021.
A table shows how the vendors compare.
Xtacking
YMTC’s new chips use a second generation of the company’s proprietary Xtacking technology. This separates the manufacture of the NAND chips and controller chips, with each on their own wafers. The chips are attached electrically through billions of metal VIAs (Vertical Interconnect Accesses). The VIAs are formed across each NAND and controller wafer in one process step and the chips are then cut out. NAND chips and controller chips are mated so that the VIAs line up (shown by the red pillars in the diagram below).
Xtacking diagram with peripheral controller logic die placed above separate NAND die and the two electrically connected with VIAs (green pillars).
There are two benefits to this design, according to YMTC. First, the chip area is reduced by 20 to 30 per cent because the peripheral controller logic is not placed on one side of the chip, as is otherwise the case. Secondly, the controller logic can be developed in parallel with the NAND die and this saves three months of development time, according to YMTC.
YMTC’s current NAND chip has 64 layers and we understand that the 128-layer chip is in effect two 64-layers, stacked one above the other in a string-stacking scheme. The 64-layer chip also uses Xtacking to put the controller logic above the NAND cells. YMTC’s 128-layer chip uses a second generation of Xtacking technology.
Layer cake
As well as YMTC, other suppliers also place the NAND die’s peripheral circuitry under or over the 3D NAND cells. For example, Samsung’s Cell over Peripheral architecture, arranges the bit-storing cells on top of the CMOS logic needed to operate the die. Intel and Micron have similar CMOS-under-Array designs.
SK hynix is preparing the 16TB 128-layer TLC PE8111 SSD in the EDSFF IU long ruler format, with sampling due in the second half of the year. A 32TB product will follow, but we don’t have a sampling date. Both chips use a 1Tbit die.
In January Western Digital and Kioxia announced 112-layer 3D NAND, with early shipping dates pegged at Q4 2020. BiCS5 technology will be used to build TLC and QLC NAND.
In December last year Micron said it was developing 128-layer chips with replacement gate (RG) technology. Gen 1 RG technology will start production in the second half of 2020, with slightly lower-cost chips. A gen 2 chip that brings in more layers, lower costs and a strong focus on QLC will appear in fy2021.
Last September Intel said it will move from 96-layer to 144-layer 3D NAND and will ship 144-layer SSDs in 2020. This is likely to be a pair of 72-layer string stacks.
Why is DRAM confined in a 10nm semiconductor process prison when microprocessors and the like are being built using 7nm processes, with 5nm on the horizon? If DRAM could be fabricated with a 7nm process, costs per GB would go down.
However, for the next few years 7nm DRAM is fantasy, due to capacitor and other electrical limitations at the sub-10nm level.
DRAM process shrink progression
DRAM is more expensive and more tricky to manufacture than processor silicon, due to its critical nature. It has to hold data over many logic clock cycles. So it will lag in fabrication processes.
Process size shrinkage is the key to lower DRAM costs. Broadly speaking, the industry standard 300mm semiconductor wafer has a fixed cost. Therefore the more chips you can fit on the wafer the lower the cost per chip.
Micron NAND wafer
DRAM process sizes shrank significantly in recent years, until 2016.
2008 – 40nm-class – meaning 49nm to 40nm and classed as 4x
2010 – 30nm-class – 39nm – 30nm – or 3x
2011 – 20nm-class – 29nm – 20nm – or 2x
2016 – 10nm-class – 19nm – 10nm – or 1x
Today, vendors are still shipping at the 1xnm node level. There are three sub-levels and the industry refers to them as:
1xnm – 19nm – 17nm (Gen1)
1ynm – 16nm – 14nm (Gen 2)
1znm – 13nm – 11nm (Gen 3)
Next, and in R&D, vendors have three more scaled generations of DRAM on the roadmap, all still at the 1xnm node level. Those are called:
1anm (Gen 4)
1bnm (Gen 5)
1cnm (Gen 6)
Each progression should involve some decrease in DRAM cell size in some dimension to increase density, lower power, etc. The 1a DRAM chips are slated to ship in 2021 or possibly sooner.
DRAM cell sizes are measured using an nF² formula where n is a constant, derived from the cell design, typically between 6 and 8, and F is the feature size of the process technology. Thus, with a 16nm feature size and n=8, then the area is 8 x (16 x 16) = 2,048 square nanometres. Use a 14nm feature size instead and the area is 1,568 square nanometres, 23 per cent less. This is why it is worth shrinking the feature size. You get more GB of DRAM on a wafer that way.
Billions of cells can fit on a single chip, with thousands of cells in a row. Smaller cells can mean billions more in a chip.
Samsung 10nm-class DDR4 DRAM chips produced with EUV equipment.
Overall we have six 1x-class generations and cannot breach the 10nm process barrier. Why?
Capacitor aspect ratio
The capacitor in a DRAM cell needs to be large enough to store a measurable charge. Shrinking DRAM cell size laterally, by its length and width, decreases the capacitor’s volume, which is, to be blunt, bad: it reduces its effectiveness. This reduction in volume can be compensated for by increasing the capacitor depth or height.
Debra Bell, senior director of DRAM Product engineering at Micron, wrote in an article: “In cell capacitor scaling, the aspect ratio is a challenge.” That’s the ratio between the height and lateral size of the capacitor structure. Make one or both too small and the capacitor cannot do its job effectively.
Increasing the capacitor’s depth has its own problems, as an IBM Zurich research blog stated: “In the long term, this represents a bottleneck – not only due to geometrical constraints, but also because charge accumulation at the top of the ‘well’ makes it more challenging to use the entire storage capacity.”
Another problem is that capacitors leak charge, which is why they have to be refreshed periodically: this is why it is called dynamic random address memory or DRAM, as opposed to static memory, which doesn’t need constant charge refreshing, as data is stored in logic gates but is more expensive. DRAM researchers are looking at getting rid of the capacitor, we hear, by storing the charge in the transistor body using different transistor materials.
Another difficulty is that as cell size decreases and fabricators cram more cells into an array, the relative length of the word and bit lines increases. This affects the time it takes to put a charge in a capacitor and move the charge along the lines.
The net result is that decreasing DRAM cell size beyond the limits met at the 1x nanometer processes is impractical to impossible in the short-term, certainly out to 2025 at earliest. It looks increasingly as if there will have to be some breakthrough in materials to enable us to make the jump into sub-10nm DRAM.
To understand why this is the case let’s take a brief tour of kinds of semiconductor chip manufacturing and DRAM design, where we’ll see the key role played by capacitors.
Under the hood
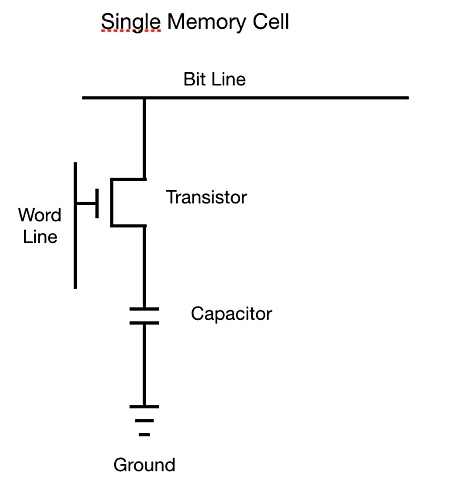
Random-access memory cells are each made up of tiny circuits, typically involving one transistor that acts as an access gateway, and one capacitor that functions as a charge store. In semiconductor jargon, this design is termed ‘1T1C’ and shown below.
Blocks & Files diagram,
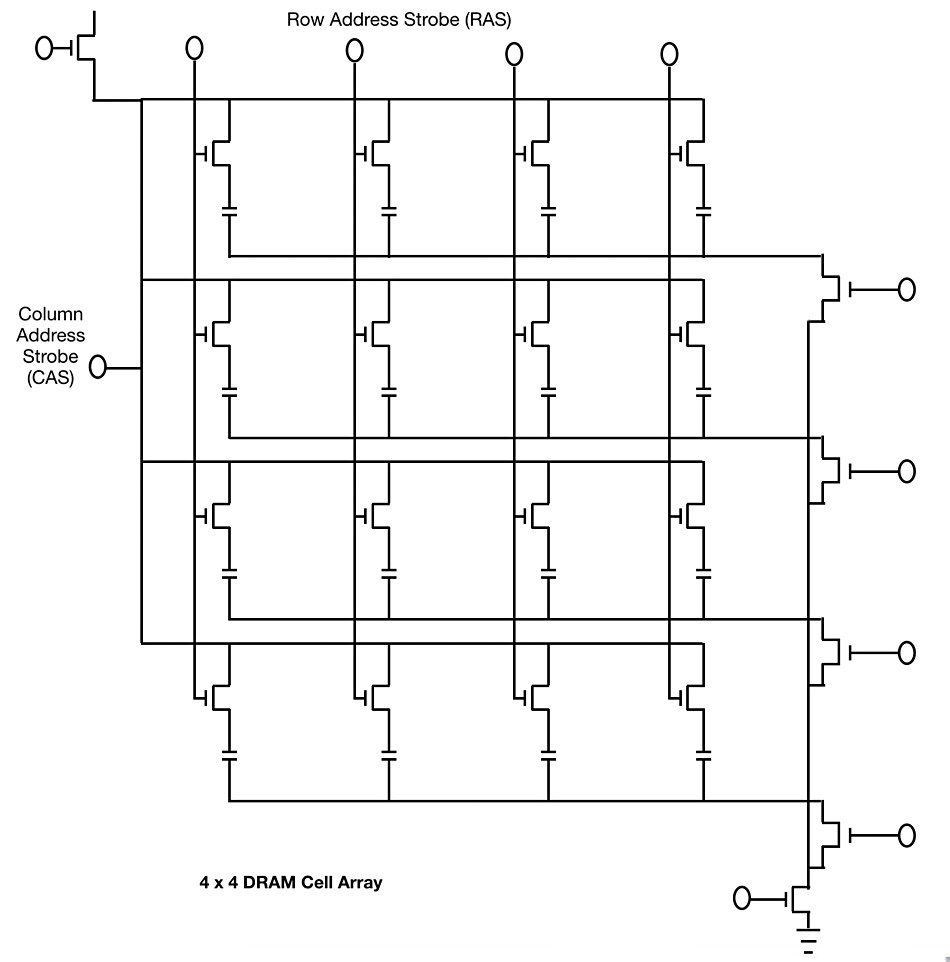
Each circuit is addressable using so-called address strobes. This makes them usable in rows and columns of RAM, called arrays. And each 1T1C circuit in this array is a cell. The cells line up in rows with a bit line connector. Columns of these cells are connected by word lines.
A cell’s address is defined by its location at the intersection of these two orthogonal bit lines and word lines. The address strobes do their work along the word and bit lines as shown in the diagram below.
Blocks & Files diagram
That’s for memory cells. But logic chips, built out of high-density logic gates, are entirely different. They are super-high density. They are incomparable to 1T1C repetitive building blocks, with relatively large capacitors in them, which is why they can scale down past the 10nm barrier.
As we noted then, Commvault is reorganising sales, marketing and product strategies under the leadership of Sanjay Mirchandani. He was installed as CEO in February last year with the approval of Elliot Management, another activist investor, which ripped into Commvault in March 2018.
Starboard looks for “deeply undervalued companies and actively engages with management teams and boards of directors to identify and execute on opportunities to unlock value for the benefit of all shareholders.”
In a 13D SEC filing on April 9 Starboard revealed it now owned 9.9 per cent of Commvault’s shares, just under the 10 per cent holding trigger that would set into operation Commvault’s poison pill rights plan. Commvault’s board voted in the plan on April 3, shortly after Starboard’s stake building was revealed.
In the filing, Starboard named six directors for whom it would seek proxy votes from shareholders to elect them to the board at Commvault’s 2020 AGM. The date of the AGM has not yet been announced.
A Commvault statement confirmed: “Starboard has submitted director nominations, and the Commvault Board will, consistent with its fiduciary duties, consider them.”
The statement revealed Commvault’s CEO and CFO had “spoken with Starboard representatives several times to understand their views and perspectives,” after learning of Starboard’s 9.3 per cent holding.
The six Starboard nominees are;
Philip Black – former CEO of Nexsan Technologies,
R. Todd Bradley – CEO of Mozido, a provider of digital commerce and payment solutions
Gavin T. Molinelli – Starboard partner
Jeffrey Smith – Starboard CEO and CIO
Robert Soderbery – president of UpLift and former Cisco Enterprise SVP)
Katherine Wagner – Yale University professor – Department of Economics
Black has previous with Starboard. He was nominated by Starboard for Quantum’s board when Starboard attacked that under-performing company in May 2013. The initial result of Starboard’s engagement with Quantum was thre of its directors joined Quantum’s board and that was followed by changed product strategies and a new CEO. The changed strategies included a focus on optimising tape revenues and building out its scale-out storage portfolio.
Wells Fargo analyst Aaron Rakers told subscribers this week: “We’d highlight that out of the 23 [Starboard] campaigns analyzed, 15 (65 per cent) resulted in major cost realignments, spinoffs, or eventual sales of the company.”
Also: “Starboard’s tech campaigns have been highly beneficial to investors with an average 2-yr. peak return of 48 per cent and an average return of 19 per cent from start to end of campaign vs. the S&P500 +7 per cent over the same time period. We would note that the average activist campaign from Starboard from initiation to final outcome is fairly quick; lasting an average of about 9 months.”
Blocks & Files expects some of Starboard’s nominees to be accepted by Commvault’s board.
Pure Storage has teamed up with Kasten to integrate its storage arrays with Kasten’s containerised app backup.
The news is detailed in a Pure Storage blog co-authored by Pure principal solutions architect Jon Owings and Kasten head of product Gaurav Rishi.
They say: “If you are a Pure Storage customer with Kubernetes applications, this solution can now enable you to use cases such as:
Easy backup/restore for your entire application stack to make it easy to ‘reset’ your application to a good known state
Fast cloning to a different namespace within your cluster for debugging
Disaster recovery of your applications in another cluster, region, or cloud.”
A free edition of K10 can be installed in less than ten minutes, according to the bloggers.
Orchestrators
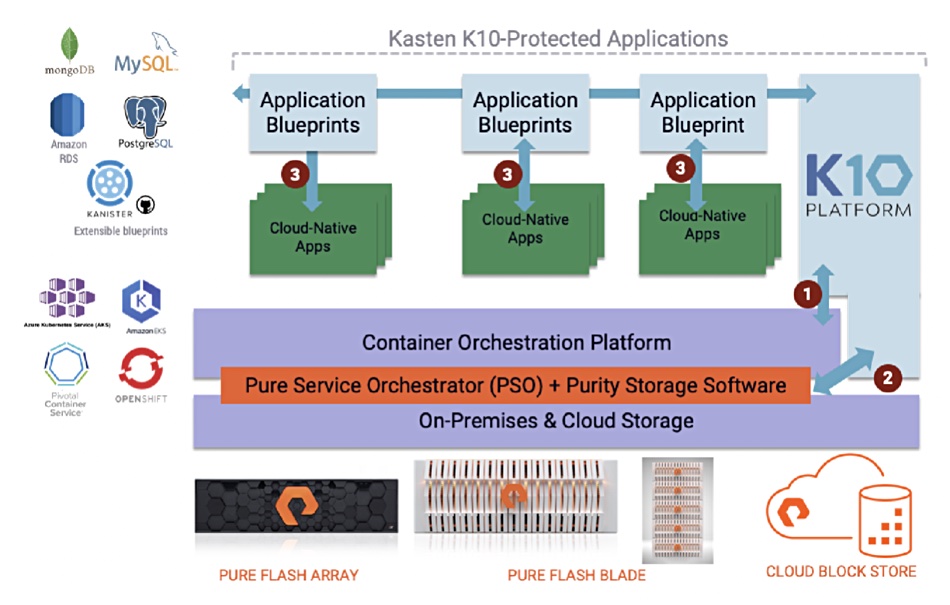
The PSO (Pure Storage Orchestrator)-K10 integration means that K10 can discover containerised applications in a Kubernetes environment and use FlashBlade, for example, as a vault for its backups.
Pure-Kasten diagram.
PSO provides primary block storage via FlashArray and Cloud Block Store and secondary file + object with FlashBlade storage for containers.
The software acts as an abstraction layer that presents a fleet of Pure storage arrays as a single federated resource for provisioning storage-as-a-service to containers. Some or all of the arrays can simultaneously provide storage to other servers for bare metal or virtualized workloads.
The fleet can comprise a mix of FlashArray, FlashBlade and Cloud Block Store arrays, and PSO uses policies to decide which array satisfies which cloud-native storage request. PSO supports various container orchestrators such as Kubernetes and Docker.
Blocks & Files diagram
Kasten’s K10 software uses Kubernetes to provide agentless data protection and mobility at the application level to containerised workloads.
K10 automatically discovers applications and their container components and policies. It provides backup and restore at the application level for hybrid computing setups and can move applications from one run-time environment to another. This may be useful for disaster recovery purposes.
K10 has built-in security features, such as role-based access controls, air-gapped installs, encryption at rest and in motion for storage, backup and application mobility. It also has integrations with RDBMS and NoSQL databases.
Cohesity has completed a $250m series E round that values the data management startup at $2.5bn.
Mohit Aron, CEO and founder, said today in a press release: “Closing a major funding round during these times of economic uncertainty is testament to the promise that our investors see in Cohesity.
“More enterprises globally are abandoning legacy offerings in favour of our modern, software-defined approach to data management … critical during these challenging times as customers are looking to reduce total cost of ownership while enabling remote IT teams.”
Cohesity CEO and founder Mohit Aron.
Cohesity will use the new cash to boost research and development, expand its presence in the USA, EMEA and APAC, and to build reseller and partnership channels.
Total funding stands at $660m and its valuation has more than doubled from the $1.1.bn set in a previous funding round in June 2018. Rubrik, Cohesity’s arch-rival, has taken in about $550m in its funding rounds.
How many customers?
Cohesity said today that it doubled customer count from the first half of fiscal 2019 ended January 31 2019 to the first half of 2020. Also it has doubled the volume of customer data under management during the same time. The company claims a 150 per cent increase in recurring revenue as it has moved to a software-led business model. But it has not provided any numbers.
Cohesity frequently changes the way it announces customers numbers, making it harder for others to calculate growth. For instance, in January 2017 the company said its customer count had passed 80 and in January 2018 it said the count had doubled over the past eight months. In August 2018 it stated its customer count had quadrupled in its fiscal year ended July 31 2018. It reported more than 100 customers in EMEA by November 2018.
In October 2019 Cohesity announced another doubling in customers for the fiscal 2019 year ending July 31. Now it says customers have doubled from January 2019 to January 2020.
So we can do some rough estimates, using those 80 customers in January 2017 as our starting point:
Jan 2017 – 80+ customers
Jan 2018 – customer count doubled over past eight months, meaning at least 160.
Aug 2018 – 4x increase in fiscal 2018 means at least 320 customers (compared with Jan 2017)
Oct 2019 – Customer count doubled in fiscal 2019 – meaning at least 640 customers.
Jan 31 2020 – 100 per cent y/y increase means at least 640 customers and possibly upwards of 1,000
Our sense is that Cohesity has surpassed 1,000 customers, and probably many more than that. Next thing is to try to figure out average customer spend…
Micron has revamped the 5210 ION SSD’s firmware to make it last longer.
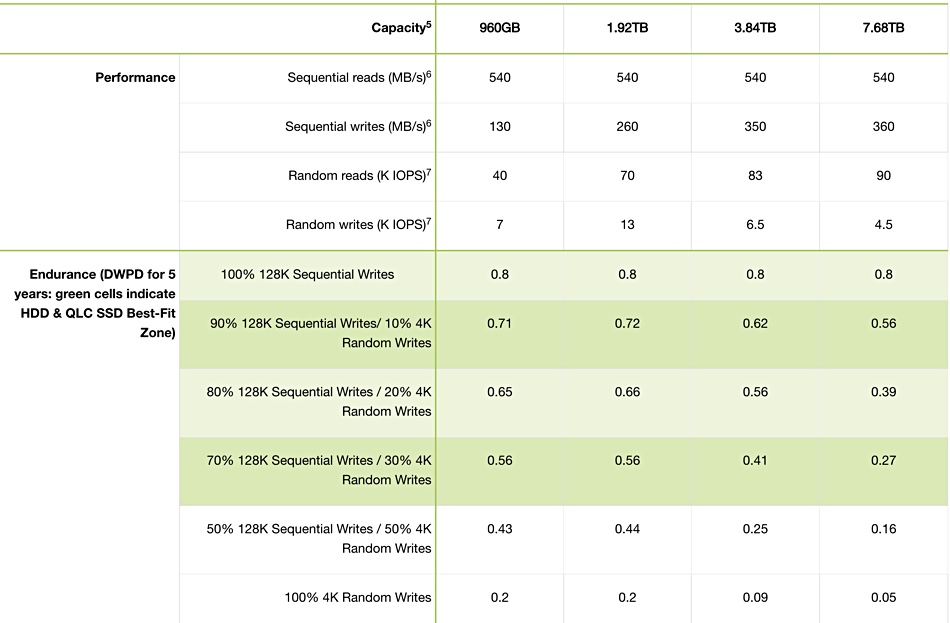
Micron said the improved endurance make it a suitable replacement for disk drives in general-purpose servers and storage arrays. The US chipmaker has added a 960GB entry-level model, which is VMware vSAN-certified and claims you should think about ditching 10K rpm disk drives and use the 5210 ION SSD instead.
The 5210 ION SSD was the first quad-level cell (QLC) data centre SSD, when it came to market in May 2018. It had a 6Gbit/s SATA interface and three capacity points: 1.92TB, 3.84TB and 7.68TB. Endurance was a lowly 1,000 write cycles.
Micron has provided detailed endurance numbers by workload and clear performance numbers:
Basically, the higher the random write proportion in a workload the lower the endurance.
The random write IOPS tops out at 13,000 for the 1.92TB version, which is a significant improvement from the 2018-era version’s 4,500 maximum.