Cohesity has completed a $250m series E round that values the data management startup at $2.5bn.
Mohit Aron, CEO and founder, said today in a press release: “Closing a major funding round during these times of economic uncertainty is testament to the promise that our investors see in Cohesity.
“More enterprises globally are abandoning legacy offerings in favour of our modern, software-defined approach to data management … critical during these challenging times as customers are looking to reduce total cost of ownership while enabling remote IT teams.”
Cohesity CEO and founder Mohit Aron.
Cohesity will use the new cash to boost research and development, expand its presence in the USA, EMEA and APAC, and to build reseller and partnership channels.
Total funding stands at $660m and its valuation has more than doubled from the $1.1.bn set in a previous funding round in June 2018. Rubrik, Cohesity’s arch-rival, has taken in about $550m in its funding rounds.
How many customers?
Cohesity said today that it doubled customer count from the first half of fiscal 2019 ended January 31 2019 to the first half of 2020. Also it has doubled the volume of customer data under management during the same time. The company claims a 150 per cent increase in recurring revenue as it has moved to a software-led business model. But it has not provided any numbers.
Cohesity frequently changes the way it announces customers numbers, making it harder for others to calculate growth. For instance, in January 2017 the company said its customer count had passed 80 and in January 2018 it said the count had doubled over the past eight months. In August 2018 it stated its customer count had quadrupled in its fiscal year ended July 31 2018. It reported more than 100 customers in EMEA by November 2018.
In October 2019 Cohesity announced another doubling in customers for the fiscal 2019 year ending July 31. Now it says customers have doubled from January 2019 to January 2020.
So we can do some rough estimates, using those 80 customers in January 2017 as our starting point:
Jan 2017 – 80+ customers
Jan 2018 – customer count doubled over past eight months, meaning at least 160.
Aug 2018 – 4x increase in fiscal 2018 means at least 320 customers (compared with Jan 2017)
Oct 2019 – Customer count doubled in fiscal 2019 – meaning at least 640 customers.
Jan 31 2020 – 100 per cent y/y increase means at least 640 customers and possibly upwards of 1,000
Our sense is that Cohesity has surpassed 1,000 customers, and probably many more than that. Next thing is to try to figure out average customer spend…
Micron has revamped the 5210 ION SSD’s firmware to make it last longer.
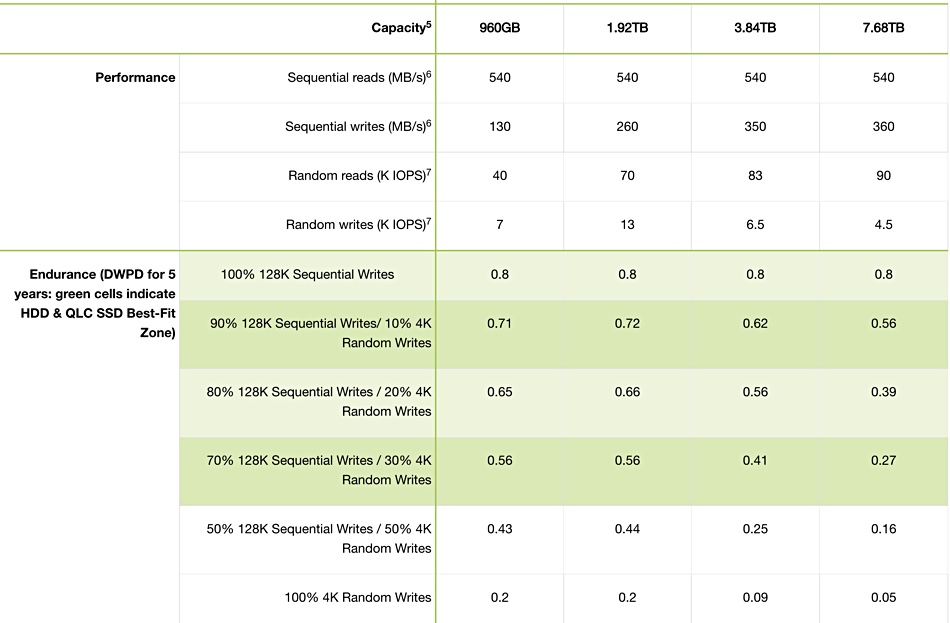
Micron said the improved endurance make it a suitable replacement for disk drives in general-purpose servers and storage arrays. The US chipmaker has added a 960GB entry-level model, which is VMware vSAN-certified and claims you should think about ditching 10K rpm disk drives and use the 5210 ION SSD instead.
The 5210 ION SSD was the first quad-level cell (QLC) data centre SSD, when it came to market in May 2018. It had a 6Gbit/s SATA interface and three capacity points: 1.92TB, 3.84TB and 7.68TB. Endurance was a lowly 1,000 write cycles.
Micron has provided detailed endurance numbers by workload and clear performance numbers:
Basically, the higher the random write proportion in a workload the lower the endurance.
The random write IOPS tops out at 13,000 for the 1.92TB version, which is a significant improvement from the 2018-era version’s 4,500 maximum.
Quantum quietly bought Atavium, a small storage and data workflow startup, for an undisclosed sum last month.
There are obvious synergies with Quantum’s StorNext file workflow management suite. Atavium software identifies and manage data and optimises data movement through processing workflows. It provides search and policy-based tiering – flash to disk to S3 cloud – and uses ‘zero-touch tagging’ to mark files as they pass through workflow stages.
Quantum is bedding down the acquisition by reorganising engineering into primary and secondary storage portfolios.
Atavium co-founder CEO Ed Fiore, a former engineering VP at Dell EMC, becomes Quantum’s general manager for primary storage. He takes charge of Atavium source code and intellectual property and developingStorNext capabilities for media library software, real-time search and analytics, hybrid multi-cloud experience and ease of use.
Fellow Atavium co-founder Mark Bakke joins Quantum as Fiore’s technical director. He will explore enterprise-wide networking and cloud capabilities.
Ed Fiore (left) and Mark Bakke
Quantum’s secondary storage portfolio is to be headed up by Bruno Hald, a 25-year company vet. He currently runs the archive and data protection product groups.
Quantum CEO Jamie Lerner issued the following quote: “It’s noteworthy that with the work we’ve done to rationalise our cost structure, we’re able to elevate our talent while decreasing operational expenses. Ed Fiore and Mark Bakke provide the startup calibre talent that is essential to our primary storage portfolio as we transition to delivering more software-defined solutions.
“I’m also thrilled to promote Bruno Hald to a new role that will enable us to focus on the unique requirements of archive and data protection customers who depend on Quantum.”
Atavium was set up by a bunch of Compellent veterans in Minneapolis in December 2015 and raised $8.7m and employed about 30 staff in its short life.
The Korean memory maker is sampling two PCIe 4.0 drives, the 96-layer TLC flash PE8010 and PE8030. It is also prepping the 128-layer TLC PE8111.
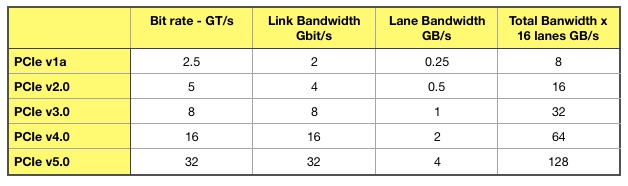
The PCIe 4.0 bus interface has a 16Gbit/s data link speed, with up to 16 lanes. This delivers 64GB/sec, which is twice as fast as the current PCIe gen 3’s 32GB/sec maximum.
Update: The capacity range for the PE8010 and 8030 is 1TB to 8TB.
No data sheets are available for the two new drives. An SK Hynix spokesperson told us: “We are not allowed to open the data sheets to the public.”
The company has not revealed latency, endurance or warranty details. But the new drives use a maximum of 17W – for what that’s worth.
The PE8010 is designed for read-intensive use and the PE8030 is intended for mixed read and write use. They both come in the 2.5-inch U.2 format. Basic performance numbers are up to 1,100,000/320,000 random read and write IOPS and 6,500/3,700 MB/sec sequential read and write bandwidth.
SK hynix PCIe gen 40 SSD.
The PE8111 uses newer 128-layer 3D NAND technology and comes in the EDSFF IU long ruler format, and a 16TB product is slated for sampling in the second half of this year. A 32TB product will follow suit but we do not have a date range for sampling. Both use a 1Tbit die and are optimised for Facebook’s Open Compute Project (OCP) storage products.
The 16TB SSD’s performance is pedestrian compared to the PE8010 and 8030, with random read and write IOPS up to 700,000/100,00 and sequential read and write bandwidth of 3,400/3,000 MB/sec.
Update; SK hynix has explained that the PE8111 uses the PCIe gen 3 bus, not the newer and faster PCIe gen 4 bus. That is why its performance is so much less than the PE8010 and PE8030 drives.
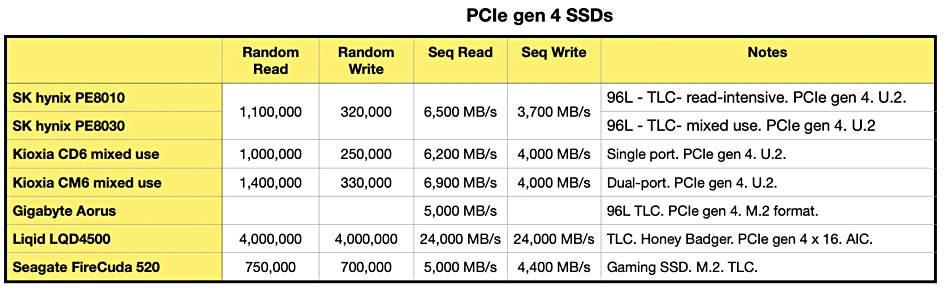
We can compare SK hynix’s PCIe gen 4 SSDs with recently announced competitor products and have tabulated the summary data.
(Empty cells mean we don’t have the data. This table has been updated on 9 April 2020 to remove the PE8111 drive as it does not use the PCIe Gen 4 interface.)
The SK hynix PE8010/8030 SSDs look faster than Kioxia’s CD6 – but not its CM6. The Aorus, like Seagate’s FireCuda 520, is in the slow lane for sequential reading. Liqid’s LQD4500 is a class apart, but it uses 16 PCIe 4.0 lanes whereas the others max out at four lanes.
Also, this Liqid AIC format drive is intended for use in composable server systems and not as a commodity data centre server SSD.
SK hynix is a relatively new entrant to the enterprise SSD market and its competitors include Kioxia, Western Digital, Micron and Samsung.
Infinidat has no immediate plans to add Optane support because its memory-caching technology is already faster than Intel’s 3D XPoint.
In a press briefing today, Yair Cohen, VP of product at the high-end storage supplier, noted Infinidat arrays already serve most IOs from DRAM. Therefore, an Optane layer between its disks and DRAM does not generally increase array speed. This is not the case for a typical all-flash array vendor, where putting metadata in Optane and/or caching data in Optane could well increase speed.
Yair Cohen
Cohen said there is sometimes a need to overcome marketing-led perceptions that because Optane is fast, an Infinidat-Optane combo will be faster again. This may be the case for some applications, but for most customers Optane inside Infinidat arrays adds cost but does not boost performance.
He was more enthused about NVMe over Fabrics (NVMe-oF) and said Infinidat will support the storage networking technology later this year. He did not provide details.
Also, Cohen revealed Infinibox arrays can accommodate shingled and multi-actuator disk drives but their introduction is contingent on cost.
And the company may add S3 archiving to the public cloud but it has no plans to offer a software cloud version of its array.
Infinibox array recap
Infinibox stores data in nearline disk drives, striping data across many drives in small 64KB chunks. Following initial reads, it uses its so-called NeuralCache to predict subsequent data reads. Ninety per cent or more of reads are satisfied from DRAM and the rest is from disk. One hundred per cent of writes are written to DRAM and then destaged to disk or a small SSD capacity layer between DRAM and disk.
Infinidat is faster than flash because of this DRAM caching, and cheaper than all-flash arrays because it uses HDDs for bulk primary data storage.
The net result, according to Yair Cohen, is that “most customers see us as a competitor to all-flash arrays at half the price.”
We asked Cohen about Infinidat thoughts on supporting the S3 object protocol and tiering old data to S3 vaults in the public cloud.
He said Infinibox already uses low-cost disk storage and can store fast access archives within the array. But he also acknowledged that some customers need to tier off older data to an archive. He implicitly accepted, that S3 storage might be cheaper than Infinidat storage: “We understand the need for an S3 tier. We could tier to the public cloud using S3 in future. It’s a good requirement.”
We also asked if Infinidat had considered porting its array software to the public cloud. “We are not pursuing this path,” Cohen replied.
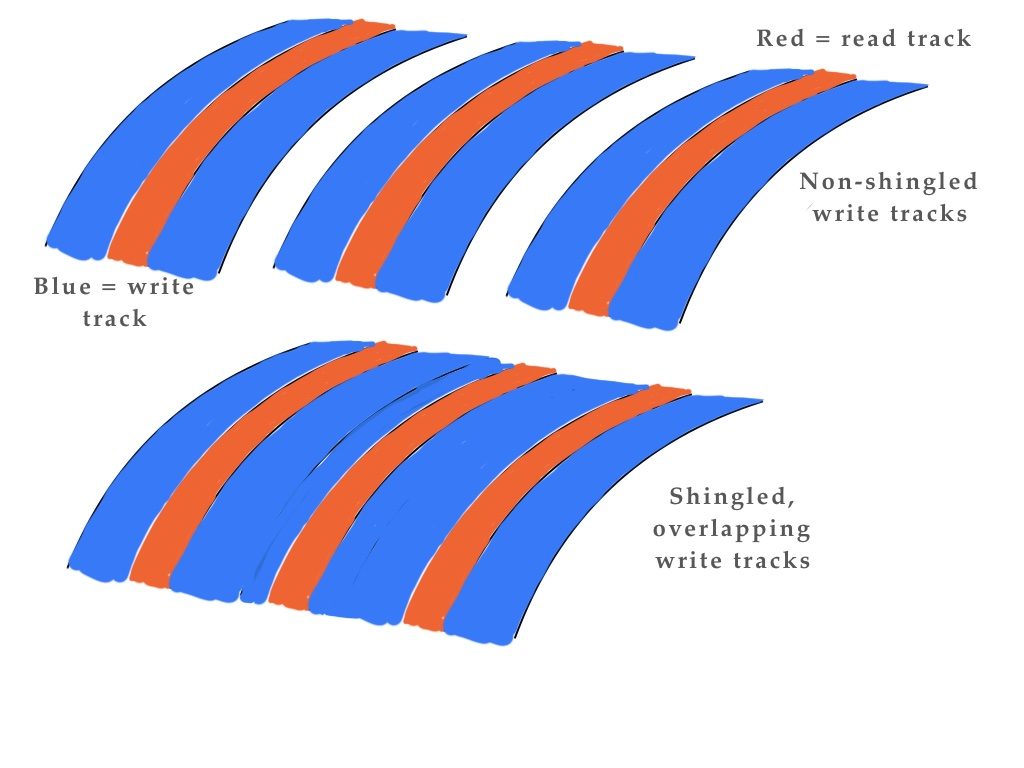
Shingling and multi-actuator drives
Shingled disk drives cram more data on a disk by partially overlapping blocks of wide write tracks leaving the narrower read tracks intact. Disk reads are as fast as with non-shingled drives, but any data rewrites require a whole block of tracks to be read, processed and then written back to disk, slowing things down.
Seagate multi-actuator technology.
A multi-actuator disk drive has its set of read and write heads divided in half, with each subset accessing half the disk drive. This means a multi-actuator 16TB drive is actually two 8TB drives in a logical sense, with each able to operate in parallel.
Cohen said that adopting these technologies depends almost entirely on cost. Infinidat’s architecture already works with the delays inherent in mechanical disk drives. Infinidat will offer shingled and/or multi-actuator drives only if they provide an effective cost advantage over conventional drives.
Starboard, which revealed its buying spree in the data management vendor last week, wields a big stick. The activist investor seeks out “deeply undervalued companies and actively engages with management teams and boards of directors to identify and execute on opportunities to unlock value for the benefit of all shareholders.”
Commvault did not mention Starboard by name. But it said in a statement last week the rights plan is “intended to protect the interest of the Company and its shareholders by reducing the likelihood that any person or group gains control of Commvault through open market accumulation or other tactics without paying an appropriate control premium.”
The plan will help “ensure that the Board has sufficient time to make informed decisions that are in the best interests of the Company and all Commvault shareholders.”
The poison pill is activated when an investor builds a holding above 10 per cent – or 20 per cent in the case of certain passive Commvault investors. This triggers a share buying discount of 50 per cent and “Rights held by any entity, person or group whose actions trigger the Rights Plan, and those of certain related parties, would become void.”
Commvault’s rights plan runs from April 3, 2020 and expires on April 1, 2021.
Lightbits Labs, an all-flash array startup, claims server systems need external SANs to use flash memory properly. Users may only get only get 15 to 25 per cent flash capacity utilisation and 50 to 85 per cent of their flash spend is wasted.
—-
Update 9 April, 2020; Lightbits has contacted us since publication of this article to say it was making a general point about servers and that its observations do not apply to VMware vSAN. A spokesperson said: “During the IT Press Tour call, Kam Eshghi, our Chief Strategy Officer, stated that DAS is severely under-utilized. Your logical conclusion was that if DAS is under-utilized, and HCI uses DAS, that it makes HCI under-utilized. While we don’t disagree with the logic, it is essentially apples and oranges for the point Kam was making.
“To clarify, HCI software (sharing both CPU and storage [DAS] resources across a cluster) was NOT included in Kam’s statement about utilization. This is a very important distinction: Kam was referring to DAS with no software layer on top to allow for sharing. Where there is no software sharing layer, the very serious underutilization of DAS applies. With the sharing layer like HCI, utilization is greatly improved.
“Kam’s statement was only about DAS in a non-shared environment, vs. a shared disaggregated solution (such as Lightbits). This incident shows us we need to do better in explaining this important subtlety as we can see now how the wrong conclusions can be drawn if we do not spell it out clearly.”
—-
VMware is developing a TCP driver which will enable Lightbits’ SAN array to integrate with vSAN.
At a press briefing last week, Kam Eshghi, VP of strategy and business development at Lightbits Labs, told us: “We can be disaggregated storage for HCI … and can serve multiple vSAN clusters.”
“VMware is developing in-line TCP drivers. [They’re] not in production yet. … More to come… The same applies to other HCI offerings. More details this summer.”
Eshghi said the first NVMe-over Fabric systems used RDMA over converged and costly lossless Ethernet (ROCE). With NVMe-over TCP, existing TCP/IP cabling can be used to save costs. This affords NVMe-oF performance and latency, albeit at a few microseconds slower than ROCE.
Accessing servers need an operating system with an NVMe/TCP driver and the ability to talk to the SAN as if it is directly-attached storage. For the fastest IO response, Lightbits servers can be fitted with a LightField FPGA accelerator card, using a PCIe slot.
HCI architecture does not like SANs
Kam Eshghi, Lightbits Labs
Why does VMware’s vSAN need Lightbits Lab’s SAN array – or indeed any external SAN? The whole point of hyperconverged infrastructure (HCI) is to remove the complexity of external – aka ‘disaggregated’ – SAN storage and replace it with simpler IT building blocks. Clustered HCI systems combine server, hypervisor, storage and networking into single server-based boxes, and performance and capacity scale out by adding more boxes to the HCI cluster.
As performance needs have grown, HCI cluster nodes have started using flash SSD storage. In the industry’s ceaseless quest to gain more cost-effective and higher-density flash, SSD technology in recent years has progressed from MLC (2bits/cell) flash to TLC (3bits/cell) and QLC (4bits/cell).
According to Lightbits, TLC and QLC flash are problematic used in bare metal servers, because SSD endurance – capacity for repeated writes – is much lower than the earlier generation MLC. Flash capacity must be managed carefully to prevent needless writes that diminish the SSD’s working life.
SSD controllers incorporate Flash Translation Layer (FTL) software which translates incoming server IO requests such as logical block addresses into concepts that the SSD can manage, such as pages, etc. The FTL formats outgoing data into terms that the server can understand and manages the drive’s capacity to minimise writes.
Global Flash Translation Layer
Eshghi said Lightbits arrays manage drive capacity more efficiently by using a global FTL that works across all the SSDs. To preserve the life of smaller drives, IOs can be redirected to drives with the biggest capacity.
In a bare metal server or cluster, the SSDs are all directly attached to individual servers, according to Lightbits. The company argues the servers cannot afford the CPU cycles required to run FTL endurance enhancing routines across all drives. Also, it is impractical to operate a global FTL across all the server nodes’ directly-attached flash storage in a cluster.
Therefore, the only way to manage the flash properly is to put a bunch of it in a disaggregated SAN that is linked to the bare metal server nodes.
Update; This does not apply in the HCI situation, which has a software sharing layer. As Lightbits’ statement above says; “Where there is no software sharing layer, the very serious under-utilization of DAS applies. With the sharing layer like HCI, utilization is greatly improved.”
Eshghi said Lightbits technology works particularly well with cloud-native apps and also NoSQL, in-memory and distributed applications such as Cassandra, mongoDB, MySQL, PostgreSQL, RocksDB and Spark. These apps can all suffer from poor flash utilisation, long recoveries from failed drives and flash endurance issues.
Working with VMware
Lightbits Labs does not claim its fast NVMe-oF storage is necessarily faster or superior than its competitors. It argues instead that its global FTL is so good that it is worth breaking the general HCI rule – ‘no external storage’ in certain circumstances.
The argument Lightbits makes is strong enough for VMware to work with the company to make Lightbits’ disaggregated SAN work with vSAN.
Eshghi pointed out that the company already has a relationship with VMware parent Dell Technologies, which offers a PowerEdge R740xd server preconfigured with Lightbits software. He said the relationship was strengthening so that Lightbits’ SAN could integrate with VMware’s vSAN.
He also referred us to a demo at VMworld in August 2019 where Lightbits showed how its technology could integrate with vSAN.
He said VMware is developing an in-line TCP/IP driver for vSAN and showed a slide (below) highlighting Lightbits SAN and its integration with vSAN.
Lightbits-vSAN integration slide
From this we infer that Lightbits NVMe-oF TCP array will hook directly into a vSAN cluster and provide flash storage for the vSAN nodes.
Lightbits said vSAN users will be able disaggregate their hyperconverged infrastructure where necessary, and scale storage and compute independently with no change to the vSAN management or user experience. vSAN users could also benefit from Lighbits’ features such as NVMe-oF performance, enhanced SSD endurance, thin provisioning, wirespeed compression and erasure coding for fault tolerance.
Blocks & Files thinks Lightbits is positioning itself alongside HPE Nimble (dHCI), Datrium and NetApp as a disaggregated SAN supplier for HCI schemes. Lightbits implies its edge is TCP/IP integration with VMware’s vSAN and other HCI systems, and its clustered NVMe-oF TCP nodes.
Google has announced databases can run faster in its cloud via the Memcached protocol.
Memorystore for Memcached beta launch is available in major Google regions across the US, Asia and Europe and rolls out globally in coming weeks.
Google already supports the Redis in-memory caching system, which it suggests is applicable for use cases such as session stores, gaming leaderboards, stream analytics, API rate limiting, and threat detection.
Both caching systems are popular and so Google has announced Memorystore for Memcached as a fully-managed service. On-premises apps accessing Memcached can also use the service in Google Cloud Platform. Google is responsible for deployment, scaling, managing node configuration on the client, setting up monitoring and patching the Memcached code.
Memcached is popular for database caching. It provides an in-memory key:value store and is multi-threaded, enabling a single system to scale up. The Redis in-memory caching system is single-threaded and scales by adding nodes in a cluster.
However, strings are the only data type supported by Memcached whereas Redis supports several kinds of data structures such as lists, sets, sorted sets, hyperloglogs, bitmaps and geospatial indexes. Redis also has more features. For example, Memcached evicts old data from its cache via a Least Recently used algorithm. Redis has six different eviction policies to choose from, allowing finer-grained control.
Memorystore for Memcached can be accessed from applications running on Google’s Compute Engine, Google Kubernetes Engine (GKE), App Engine Flex, App Engine Standard, and Cloud Functions.
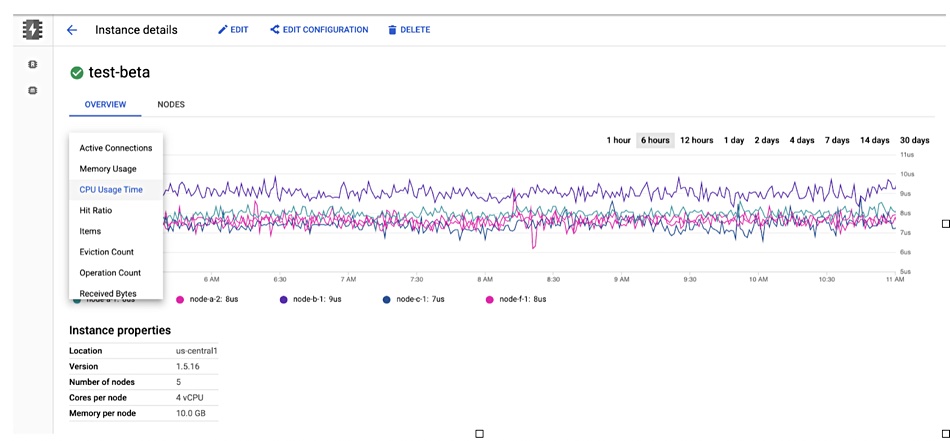
Google Memorystore for Memcached dashboard showing CPU usage.
Memcached instances can be scaled up and down to optimise the cache-hit ratio and price. Detailed open source Memcached monitoring metrics to help decision making are available in a dashboard. The maximum instance size is a hefty 5TB.
You can read a quick start guide and other documentation on the Google Cloud website.
LITE-ON has deferred the transfer of its SSD business to Kioxia due to the pandemic, but still expects it to go ahead.
Kioxia, the renamed Toshiba Memory Holdings, said it was buying LITE-ON’s SSD business for $165m in August last year.
That meant Kioxia is getting LITE-ON’s brands such as Plextor, operations, assets including equipment, workers, intellectual property, technology, client and supplier relationships and inventories, and access to its channels. These include LITE-ON’s relationships with Dell and other PC suppliers..
However, LITE-ON has announced that “unfinished integration works caused by the coronavirus (COVID-19) outbreak” has caused a delay from the original target date of April 1st, 2020. Kioxia has SSD production lines in the Philippines and the pandemic caused these to be closed on March 18.
LITE-ON has engaged in what it describes as good faith discussions with Kioxia and “does not expect any adverse impact to the SSD operations will be caused by the deferral of the closing date.”
Blocks & Files expects the transfer to complete by the end of the year, barring unforeseen circumstances.
Two rival groups developing CPU-peripheral bus standards have agreed to work together.
The CXL and Gen-Z groups announced yesterday a memorandum of understanding, which opens the door for future collaboration. Blocks & Files expects a combined CXL-Gen-Z specification will be developed quickly and available before the end of the year.
Jim Pappas, CXL Consortium board chair, issued a quote: “CXL technology and Gen-Z are gearing up to make big strides across the device connectivity ecosystem. Each technology brings different yet complementary interconnect capabilities required for high-speed communications. We are looking forward to collaborating with the Gen-Z Consortium to enable great innovations for the Cloud and IT world.”
Gen-Z Consortium President Kurtis Bowman had this to say: “CXL and Gen-Z technologies work very well together, and this agreement facilitates collaboration between our organisations that will ultimately benefit the entire industry.”
The MOU
CXL and Gen-Z technologies are read and write memory semantic protocols focused on low latency sharing of memory and storage resource pools for processing engines like CPUs, GPUs, AI accelerators or FPGAs. CXL is looking at coherent node-level computing while Gen-Z is attending to fabric connectivity at the rack and row level.
The MOU between the two groups outlines the formation of common workgroups to provide cooperation and defines bridging between them.
Companies wishing to participate must simultaneously be a promoter or contributor member of the CXL Consortium and a general or associate member of the Gen-Z Consortium.
Why we need a new bus standard
Server CPUs, as they get more cores and link to GPUs with multiple engines, FPGAs, and ASICs, need a faster bus to link the data processing entities to memory and storage devices and other peripherals. Current bus technology is unable to transmit data fast enough to keep the processing engines busy.
PCIe speed table.
Today’s PCIe gen 3 bus is transitioning to PCI 4.0, which is twice as fast, and PCIe 5 is set to follow. But even PCIe 5.0 considered too slow for modern requirements. Accordingly, four consortiums have emerged to move bus technology standards forward: CXL, Gen-Z, CCIX and OpenCAPI.
We think CCIX and OpenCAPI are toast and will have to find niche technology areas to survive or merge somehow with CXL and Gen-Z.
Four buses in a row
The Compute Express Link (CXL) bus protocol specification means that CXL can run across a PCIe 5.0 link when it arrives. CXL is supported by the four main CPU vendors; AMD, ARM, IBM and Intel. Gen Z, OpenCAPI and CCIX have not attracted the same degree of CPU manufacturer support.
CXL is also supported by Alibaba, Cisco, Dell EMC, Facebook, Google, HPE, Huawei and Microsoft.
CXL diagram
The Gen-Z consortium is supported by AMD, ARM, Broadcom, Cray, Dell EMC, Hewlett Packard Enterprise, Huawei, IDT, Micron, Samsung, SK hynix, Xilinx and others, but not Alibaba, Facebook and Intel. It has more than 40 members.
The CCIX (Cache Coherent Interconnect for Accelerators) was founded in January 2016 by AMD, ARM, Huawei, IBM, Mellanox, Qualcomm, and Xilinx – but not Nvidia or Intel.
The OpenCAPI (Open Coherent Accelerator Processor Interface) was established in 2016 by AMD, Google, IBM, Mellanox and Micron and other members are Dell EMC, HPE, Nvidia and Xilinx. OpenCAPI has been viewed as an anti-Intel group, driven by IBM.
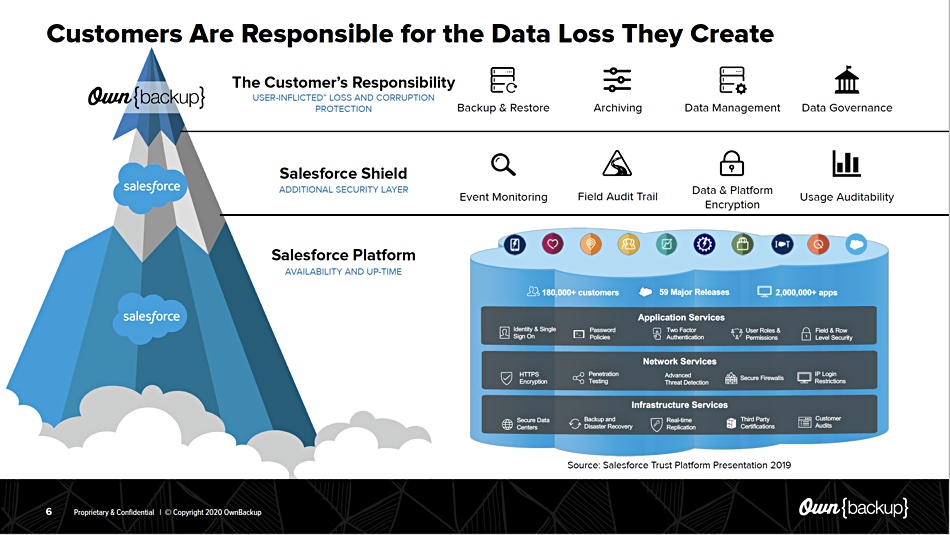
The unwritten rule for Salesforce users is: ‘Backup your own data’.
Without a dedicated backup app, customers could risk losing their data because Salesforce does not offer complete dataset backups on a daily basis.
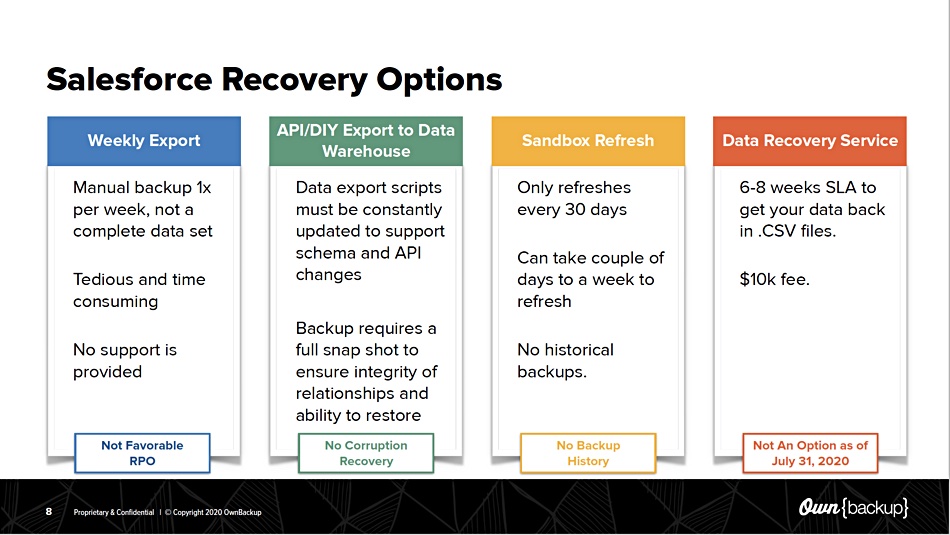
Salesforce’s built-in data protection facilities include:
Weekly export – this does not include full data set and you could lose up to a week’s worth of data
Export to data warehouse – needs a script and API knowledge
Sandbox refresh – 30-day refresh period
Data recovery service – six-eight weeks needed plus $10,000 fee
None of the above options meet what an enterprise IT department would regard as a satisfactory backup service for important data. For the enterprise, the acceptable data loss period is measured in seconds or minutes rather than hours, days or weeks. And restore needs to be fast – ideally measured in minutes.
The data custodian
SaaS applications such as Salesforce do not regard themselves as custodians of the tenants’ data in their multi-tenant SaaS environment. You the customer are the custodian of your data – just like you are when running applications in your own data centre.
Of course, the enterprise could roll its own backup app; to do the job it would need to set up a scripting routine to use the Salesforce API calls or write its own application code. But this is option is not feasible for most users.
That is why additional SaaS applications such as OwnBackup for Salesforce provide a backup, restore, archive data protection service for Salesforce customers. Competing Salesforce backup applications include CopyStorm, Druva, Reflection Enterprise and Kaseya’s Spanning.
OwnBackup set up in 2015 and has raised $49.8m in four funding rounds. It has offices in Tel-Aviv, New Jersey and London. The company offers automated complete and daily dataset (data and metadata) backup plus archiving and sandbox seeding for test and dev. OwnBackup’s technology was initially developed as a sideline from 2012 onwards by CTO Ariel Berkman, while working at Recover Information Technologies, an Israeli firm that recovers data from crashed storage drives and media.
Multi-tenancy problem
Why can’t customers use their existing backup applications to do the job?
OwnBackup co-founder Ori Yankelev told us in a press briefing last week that traditional relational database backups require customer access to the underlying infrastructure. “They need an agent on the machine. With multi-tenant [SaaS] applications this is not possible. The customer doesn’t have access to the infrastructure.”
A customer cannot run a backup agent on Salesforce infrastructure: only Salesforce could do that. However, Salesforce provides access to its infrastructure through API calls only – which OwnBackup uses to provide its service.
Data that is input into Salesforce is visible to customers when they operate the app. But this is not necessarily the case for the metadata that Salesforce uses, as API calls are required to access that information. A backup application has to access this data to be able to backup and restore customer data.
SaaS backup silos
The upshot is that the Salesforce customer needs a dedicated backup silo and backup software for Salesforce data, even if they operate on-premises backup facilities.
Also, note that OwnBackup and other backup apps tend to specialise in one SaaS app target. This means customers likely need different third-party backup apps for each SaaS application they use.
Yankelev said OwnBackup is considering adding Workday to its coverage. But he noted: “Its APIs don’t deliver the flexibility needed for us to deliver our services. Hopefully it will change.” Subject to this caveat, the company could announce OwnBackup for Workday by the end of 2020.
Our impression is that a SaaS app’s API set is not necessarily designed to enable a third-party backup application to backup and restore a customer’s complete dataset with minimal or no data loss.
Amazon Web Services has upped the read operations per second for default Elastic File Systems users from 7,000 to 35,000 – at no charge.
The company has posted some details in a blog, which explains there are two file access modes:
General purpose (GP) with now 35,000 random read IOPS,
MAX I/O performance mode with up to 500,000 IOPS and slightly higher metadata latencies than GP mode.
AWS’s EFS competes with Azure and Google file services. With this initiative, AWS has made its default or standard file access seven times faster than Google’s standard access mode. Amazon’s MAX IO performance mode’s 500,000 IOPS comfortably outstrips Google’s premium mode, with its 60,000 IOPS.
Google Cloud Filestore
At the end of 2018 Google began beta testing Cloud Filestore with NFS v3 support and two classes of service:
Standard costing 20¢/GB/month, 80 MB/sec max throughput and 5,000 max IOPS,
Premium at 30¢/GB/month, 700 MB/sec and 30,000 IOPS.
Google also offered startup Elastifile’s file service which supported NFS v3/4, SMB, AWS S3 and the Hadoop File System. The service delivered millions of IOPS at less than 2ms latency, according to Google, It bought Elastifile in July 2019 and said it would be integrated into the Cloud Filestore. This now offers standard (5,000 IOPS) and performance (60,000 IOPS) tiers.
Azure Files
Microsoft’s Azure Files supports SMB access and is sold in three flavours
General Purpose V2 or basic with blob, file, queue, table, disk and data lake support,
General Purpose V1 for legacy users with blob, file, queue, table, and disk support,
FileStorage for file only.
GP v2 and v1 have standard and premium performance tiers, with files access only in the standard tier. The premium tier includes FileStorage and uses SSDs. The default premium tier quota is 100 baseline IOPS with bursting up to 300 IOPS for an hour. If the client exceeds baseline IOPS, it will get throttled by the service.
This performance is nowhere near AWS EFS or Google Cloud Filestore. levels. Microsoft will need to raise its game here.