


The revelation that some WD Red NAS drives are shipped with DM-SMR (Drive-Managed Shingled Magnetic Recording) prompted us to ask more detailed questions to the Blocks & Files reader who alerted us to the issue.
Alan Brown, a British university network manager, has a high degree of SMR smarts and we are publishing our interview with him to offer some pointers to home and small business NAS disk drive array builders.
Blocks & Files: Can you contrast CMR (Conventional Magnetic Recording) and SMR write processes?
Alan Brown: When you write to a CMR disk, it just writes to sectors. Some drives will try to optimise the order the sectors are written in, but they all write data to the exact sector you tell them to write it to.
When you write to a SMR disk it’s a bit like writing to SSD – no matter what sector you might THINK you’re writing to, the drive writes the data where it wants to, then makes an index pointing to it (indirect tables).
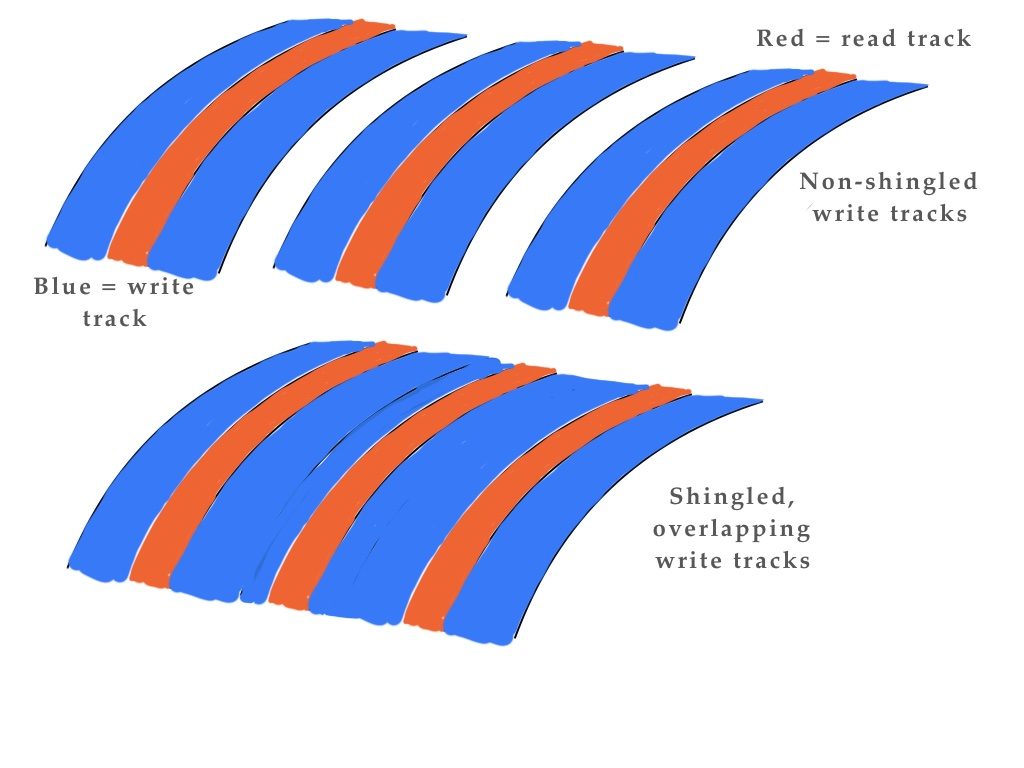
What’s below is for Drive-managed SMR drives. Some of this is conjecture, I’ve been trying to piece it together from the literature.
Essentially, unlike conventional drives, a SMR drive puts a lot of logic and distance between the interface and the actual platter. It’s far more like a SSD in many ways (only much much slower).
SMR disks have multiple levels of caching – DRAM, then some CMR zones and finally shingled zones
In general, writes are to the CMR space and when the disk is idle the drive will rearrange itself in the background – tossing the CMR data onto shingled areas – there might be 10-200 shingled “zones”. They’re all “open”(appendable) like SSD blocks are. If a sector within a zone needs changing, the entire zone must be rewritten (in the same way as SSD blocks) and zones can be marked discarded (trimmed) in the same way SSD blocks are.
Blocks & Files: What happens if the CMR zone becomes full?
Alan Brown: When the CMR zone fills the drive may (or may not) start appending to a SMR zone – and in doing so it slows down dramatically.
If the drive stops to flush out the CMR zone, then the OS is going to see an almighty pause (ZFS reports dozens of delays exceeding 60 seconds – the limit it measures for – and I measured one pause at 3 minutes). This alone is going to upset a lot of RAID controllers/software. [A] WD40EFAX drive which I zero-filled averaged 40MB/sec end to end but started at 120MB/sec. (I didn’t watch the entire fill so I don’t know if it slowed down or paused).
Blocks & Files: Does resilvering (RAID array data rebalancing onto new drive in group) involve random IO?
Alan Brown: In the case of ZFS, resilvering isn’t a block level “end to end” scan/refill, but jumps all over the drive as every file’s parity is rebuilt. This seems to trigger a further problem on the WD40EFAXs where a query to check a sector that hasn’t been written to yet causes the drive to internally log a “Sector ID not found (IDNF)” error and throws a hard IO error from the interface to the host system.
RAID controllers (hardware or software, RAID5/6 or ZFS ) will quite sensibly decide the drive is bad after a few of these and kick the thing out of the array if it hasn’t already done so on the basis of a timeout.
[Things] seems to point to the CMR space being a few tens of GB up to 100GB on SMR drives. So, as long as people don’t continually write shitloads, they won’t really see the issue, which means when for most people “when you’re you’re resilvering is the first time you’ll notice something break.”
(It certainly matches what I noticed – which is that resilvering would run at about 100MB/s for about 40 minutes then the drives would “DIE” and repeatedly die if I attempted to restart the resilvering, however if I left it an hour or so, they’d run for 40 minutes again before playing up.)
Blocks & Files: What happens with virgin RAID arrays?
Alan Brown: When you build a virgin RAID array using SMR, it’s not getting all those writes at once. There are a lot of people claiming “I have SMR raid arrays, they work fine for me”.
Rather tellingly … so far none of them have come back to me when I’ve asked: “What happens if you remove a drive from the RAID set, erase it and then add it back in so it gets resilvered?”
Blocks & Files: Is this a common SMR issue?
Alan Brown: Because I don’t have any Seagate SMR drives, I can’t test the hypothesis that the IDNF issue is a WD firmware bug rather than a generic SMR issue. But throwing an error like that isn’t the kind of thing I’d associate with SMR as such – I’d simply expect throughput to turn to shit.
It’s more likely that WD simply never tested adding drives back to existing RAID sets or what happens if a SMR drive is added to a CMR RAID set after a disk failure – something that’s bound to happen when they’re hiding the underlaying technology – shipped a half-arsed firmware implementation and blamed users when they complained (there are multiple complaints about this behaviour. Everyone involved assumed they had “a bad drive”).
To make matters worse, the firmware update software for WD drives is only available for Windows and doesn’t detect these drives anyway.
The really annoying part is that the SMR drive was only a couple of pounds cheaper than the CMR drive, but, when I purchased these drives, the CMR drive wasn’t in stock anyway.
I just grabbed 3 WD Reds to replace 3 WD Reds in my home NAS (as you do…), noticed the drives had larger cache, compared the spec sheet, couldn’t see anything different (if you look at the EFRX vs EFAX specs on WD’s website you’ll see what I mean) and assumed it was just a normal incremental change in spec.
Blocks & Files: What about desktop drive SMR?
Alan Brown: The issue of SMR on desktop drives is another problem – I hadn’t even realised that this was happening, but we HAD noticed extremely high failure rates on recent 2-3TB drives we put in desktops for science work (scratchpad and NFS-cache drives). Once I realised that was going on with the Reds, I went back and checked model numbers on the failed drives. Sure enough, there’s a high preponderance of drive managed-SMR units and it also explains mysterious “hangs” in internal network transfers that we’ve been unable to account for up until now.
I raised the drives issue with IxSystems – our existing TruNAS system is approaching EOL, so I need to replace it and had a horrible “oh shit, what if the system we’ve specified has hidden SMR in it?” sinking feeling. TruNAS are _really_ good boxes. We’ve had some AWFUL NAS implementations in the past and the slightest hint of shitty performance would be politically dynamite on a number of levels so I needed to ensure we headed off any trouble at the pass.
It turns out ixSystems were unaware of the SMR issue in Reds – and they recommend/use them in the SOHO NASes. They also know how bad SMR drives can be (their stance is “SMR == STAY AWAY”) and my flagging this raised a lot of alarms.
Blocks & Files: Did you eventually solve the resilvering problem?
Alan Brown: I _was_ able to force the WD40EFAX to resilver – by switching off write caching and lookahead. This dropped the drive’s write speed to less than 6MB/sec and the resilvering took 8 days instead of the more usual 24 hours. More worryingly, once added, a ZFS SCRUB (RAID integrity check) has yet to successfully complete without that drive producing checksum errors, even after 5 days of trying.
I could afford to try that test because RAIDZ3 gives me 3 parity stripes, but it’s clear the drive is going to have to come out and the 3 WD Reds returned as unfit for the purpose for which they are marketed.





