Arrikto, a small California startup, has devised a form of shared storage for Kubernetes-orchestrated workloads. It claims customers can save 64 per cent of AWS costs by running a 100TB Cassandra cluster in AWS using Arrikto’s Rok software, as opposed to Amazon’s Elastic Block Store.
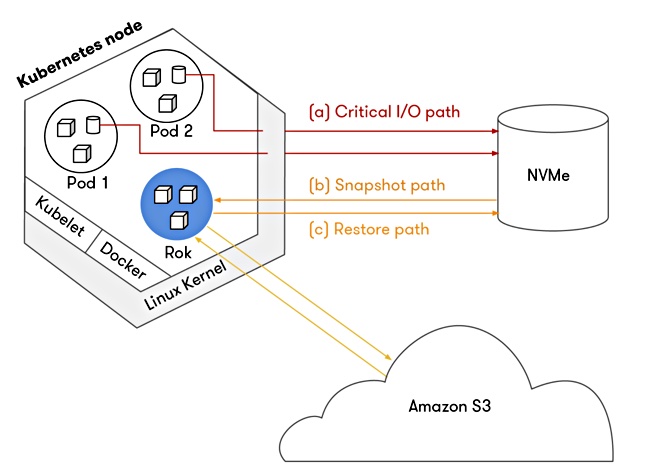
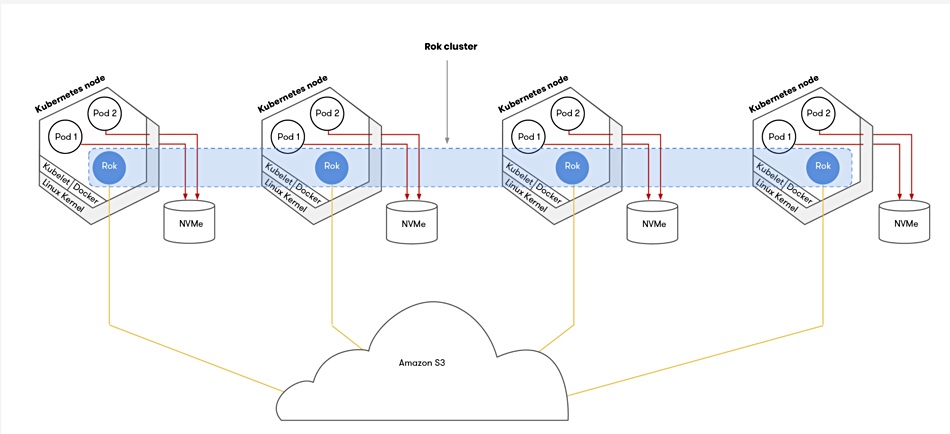
Rok uses local NVMe SSD storage on a cluster node to provide persistent storage to containers. The node is located on-premises or in a public cloud.
Rok snapshots the application’s containers, stores those snapshots in S3-compatible storage and enables sharing across a global infrastructure.
Arrikto snapshots can migrate a containerised workload – apps plus data – across machines in the same cluster or across distinct locations and administrative domains over a decentralised network. This facilitates collaboration.
Rok lives on the side of the local storage stack and acts as a global data distribution layer that makes cloud-native apps permanent and portable. The software-only thin data services layer abstracts the underlying persistent storage and provides instant, parentless clones and snapshots.
Rok distribution layer concept
Customers can take immutable group-consistent snapshots of their applications and keep them in a backup store such as AWS S3. Combined with Rok’s instant cloning, recovery from hardware failure for this setup is quoted in minutes regardless of the stored volume’s capacity.
Rok Registry
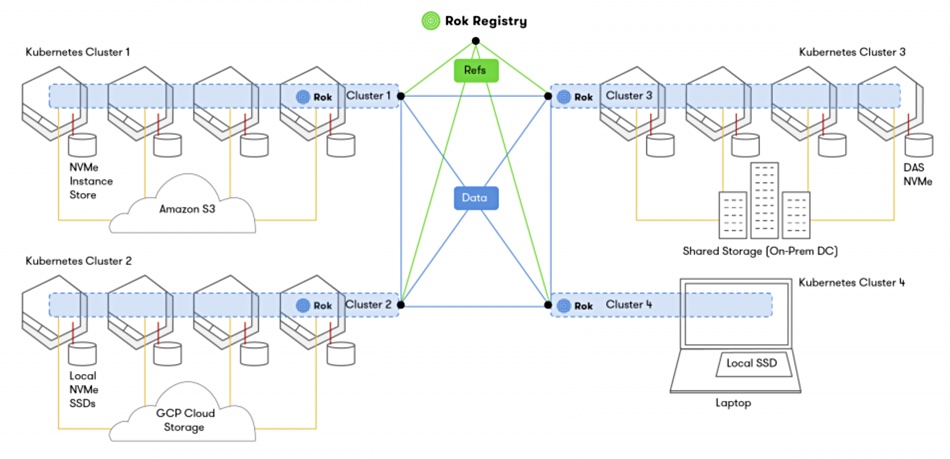
Rok Registry is operated via a single pane of glass where customers can search, discover, and share datasets and environments with other users. Users create private or public groups and can define fine-grained access control lists.
Rok Registry brings together many Rok instances in a peer-to-peer network. The management tool does not store the actual data – merely references to data.This allows Rok instances to exchange snapshot pieces over the network. Only the changed parts traverse the network when users create new snapshots.
There is no vendor lock-in and customers can use any type of hardware for compute and storage. They can also move to the cloud provider of their choice, or move among different cloud providers.
Cost reductions
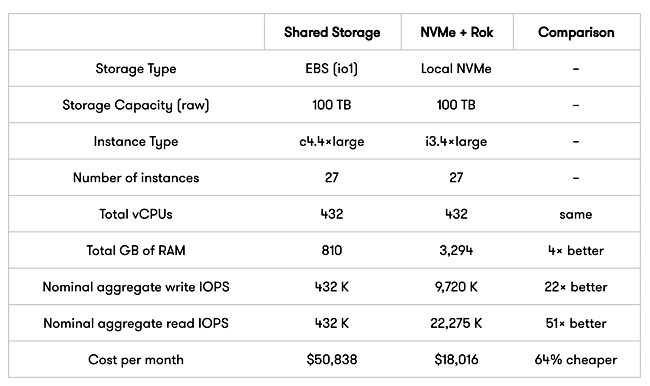
A Cassandra cluster running in AWS typically uses Amazon’s Elastic Block Store (EBS). Let’s envisage a 100TB Cassandra cluster on AWS that uses Rok store, with NVMe SSDs local to each instance. Arrikto claims this is 64 per cent cheaper per month, with a 51x read IOPS advantage. Here is Arrikto’s table:
The same setup on Google Cloud results in a 32 per cent cost advantage for Rok, according to Arrikto.
Citing performance and cost-savings, the company strongly recommends NVMe-backed instances combined with Rok.
Not a virtual SAN
From a data protection point of view, think of Arrikto as being akin to Kasten‘s K10 software, which provides backup and recovery for cloud-native applications and application migration across heterogeneous environments. Arrikto has pretty much the same functionality.
Kasten CEO Niraj Tolia, tells us: “We believe that Arrikto and Kasten occupy separate places on the data management spectrum. Arrikto is focused on primary storage [and] states that it is focused on fast storage for Kubernetes and, like all traditional storage vendors, providing supporting snapshots and cloning is a core part of any storage system’s functionality.
“… It is critical to have data protection provided by a completely separate system with its own fault domain. This is why Kasten focuses on cloud-native backup, works with a variety of storage vendors, and provides customers the freedom of choice of selecting the best storage vendor for their environment (cloud or on-premises).”
Like Arrikto, Portworx provides storage and data protection for containerised applications. It also offers high-availability, backup, continuous replication and disaster recovery, on top of basic storage provisioning.
Rok does not provide a virtual SAN, such as provided by StorageOS. Apps running in each node in an Arrikto cluster can only access their local storage. They cannot access the SSDs running on another node.
Arrikto background
Arrikto – Greek for ‘explosive’ – was founded in Palo Alto by CEO Constantinos Venetsanopoulos and CTO Vangelis Koukis in 2014. They were engineers in the Hellenic Army and subsequently involved in building the Greek Research and Technology Network’s large-scale public cloud infrastructure.
Funding totals $4m, with a $2m seed round in 2015 and a $2m round in 2019.
Portworx, the California container storage startup, today issued a so-called momentum release, boasting of customer and revenue growth.
As usual with US startups, the company does not mention actual figures but by any reckoning it is a small fish in the data storage world – annual revenues according to this possibly out-of-date estimate are $14m. However, Portworx’s bullishness is an indicator that the container storage market could shaping up into serious money.
Portworx today said it had “more than 145 customers, including 54 Global 2000 or government accounts”. It reports 136 per cent growth in revenue year over year in Q1 2020, and 92 per cent revenue growth from Q4 2019. Thirteen sales were over $100,000, up from five sales over $100,000 in Q1 2019.
A 2019 Portworx survey showed 87 per cent of respondents said that they used container technologies, compared with 80 per cent in 2018 and 55 per cent in 2017.
Portworx emerged from stealth in 2015 and has bagged $55.5m funding over three rounds. Its software runs on commodity servers and aggregates their storage into a virtual SAN providing scale-out block storage. It provides storage from this pool for containers, at container granularity, and with a global namespace. File and object storage are on its roadmap.
Portworx’s pitch is that the storage supplied to containers through an orchestration layer like Kubernetes should be containerised itself and also enterprise class, with features like security, data protection, backup and recovery, disaster recovery, SLA management, and compliance.
It says traditional enterprise storage, with the features, is suited to virtual server environments but not cloud-native ones, even if they Kubernetes CSI plug-ins. Storage provision for containers has to be supplied at the speed and scale of container instantiation, deployment and removal. Portworx claims that only cloud-native storage, its cloud-native storage, can meet this need – not legacy SANs.
Nutanix has bolstered support for ServiceNow with the latest iteration of the Calm app automation and management tool and its Prism Pro monitoring SW. The company says the update enables joint customers to reduce IT infrastructure service management costs and simplify processes and procedures.
Rajiv Mirani, Nutanix CTO, said in a statement: “This strengthened integration with ServiceNow, along with the broader suite of Nutanix automation solutions, will allow IT teams to reduce the amount of time they spend on day-to-day management of their cloud infrastructure, as well as applications, so they can focus on supporting business priorities.”
The first Nutanix-ServiceNow integration was announced in October 2019, with ServiceNow automatically discovering Nutanix systems data: HCI clusters, individual hosts, virtual machine (VM) instances, storage pools, configuration parameters and application-centric metrics. ServiceNow users can provision, manage and scale applications via Nutanix Calm blueprints.
With Nutanix Calm 3.0, joint customers use ServiceNow’s approval flow and audit capabilities to automate app lifecycle events such as upgrades, patches, and expansions. Passwords can be maintained in a central CyberArc vault via a CyberArc-ServiceNow integration.
Users of Nutanix Prism Pro management tool are now able to get and respond to alerts and incidents directly in their ServiceNow portal. They can track infrastructure issues through automatically created tickets in ServiceNow and resolve them in this ticketing system.
Joint customers will be able to limit unintended public cloud consumption. They can incorporate Nutanix cost and security optimisation recommendations into existing ServiceNow workflows by automated ticket creation – which is based on cost savings recommendations and security vulnerability alerts – and assign them to the appropriate owner.
Calm 3.0 adds functionality to provision Infrastructure as Code (IaC) with a Python-based domain-specific language (DSL) for writing Calm blueprints. The Calm DSL has the same capabilities as the Calm UI, but is human-readable version-controlled code that can handle most complex application scenarios.
Nutanix says the expanded ServiceNow integrations are available to customers. Calm 3.0 is current under development.
Competition
Nutanix aims to make its hyperconverged system portfolio easier for ServiceNow customers to use than competitor products. The stakes are high as ServiceNow is used by three quarters of the Fortune 500 and dominates Gartner’s 2019 IT Service Management magic quadrant. The message is that, if customers use ServiceNow and want an HCI system, they should buy Nutanix now.
Dell EMC has an OpenManage integration to enable ServiceNow users to monitor and manage their PowerEdge server infrastructure within the ServiceNow console. There appears to be no specific VxRail integration with ServiceNow.
Cisco’s HyperFlex HCI is managed by Cisco’s InterSight, a SaaS infrastructure management tool. There is a ServiceNow ITSM (IT service management) plugin for InterSight, which provides inventory sync and incident management. That means HyperFlex incidents can be tackled through ServiceNow.
HPE’s OneView, the precursor to InfoSight, had an integration with ServiceNow in 2016. It synced hardware catalog entries across platforms, bi-directionally tracked hardware physical events and presented these events as service tickets in the ServiceNow workflow. Blocks & Files understands InfoSight has inherited this capability.
HPE and CTERA have strengthened their partnership so that all HPE SimpliVity HCI customers can run CTERA’s file services software and “replace aging NAS systems and securely connect remote users wherever they are”.
CTERA File for HPE SimpliVity offers CTERA’s software-defined SMB and NFS filer and 90-day subscription to a CTERA cloud service that includes elastic cloud scaling and multi-site collaboration. At the end of the 90 days, users may extend the hybrid cloud service or simply keep the local filer.
According to CTERA chief strategy officer Oded Nagel, the covid-19 pandemic has provided more impetus to deliver secure file access services to remote users. With the extension, remote SimpliVity users can get access to remote office file services and virtual desktop infrastructure.
SimpliVity is HPE’s hyperconverged Infrastructure (HCI) system that uses HPE servers. Ever keen to partner and sell its server hardware, HPE has alighted on CTERA as a way of shifting more SimpliVity tin, as Blocks & Files understands it, while CTERA gets access to HPE’s channel and customer base.
HPE storage and storage software partnerships
CTERA Networks supplies cloud file storage gateway and collaboration software using a global filesystem, with added security features. It announced a reselling deal with HPE in March 2019 whereby its Edge X Series had CTERA software running on 2-node SimpliVIty hardware
That partnership also involved HPE selling the CTERA software portfolio as part of its HPE Complete program on top of HPE hardware and in combination with 3PAR and Scality.
All this has provided the foundation for extending CTERA software availability to the entire SimpliVity customer base.
Update: May 26, 2020. Customer availability note added.
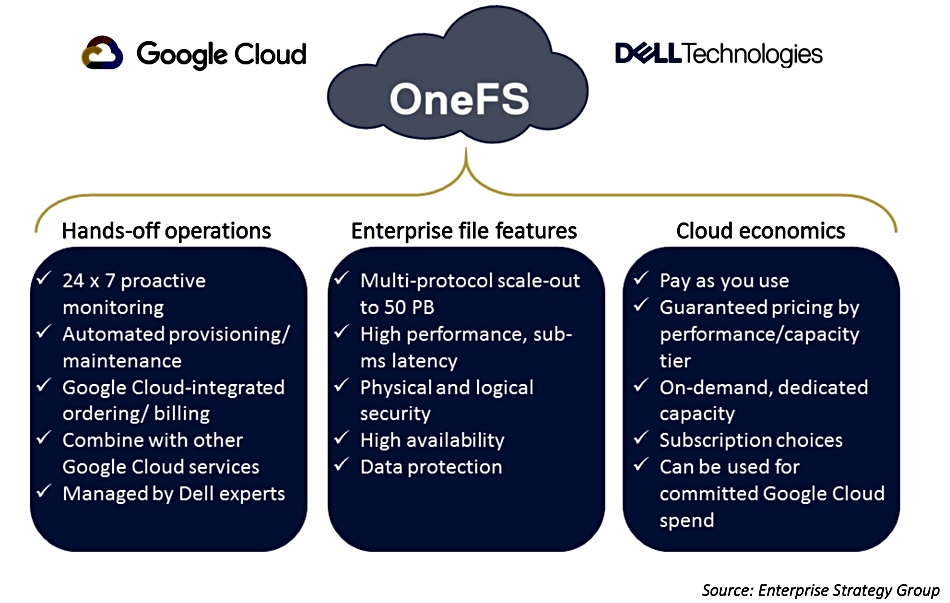
Dell Technologies has added the scale-out Isilon OneFS file server to Google Cloud. Customers get 50PB file name space and 200GB per second aggregate throughput, which is managed by Dell Enterprise Services and billed through Google.
OneFS for Google Cloud provides terabit networking and sub-millisecond latency between the Isilon hardware and Google Compute Engine services. The annual subscription service can count toward any committed Google Cloud spend.
The OneFS software has not actually been ported to run on Google hardware within Google Cloud. The planting of Isilon filers in to the Google Cloud is more akin to NetApp’s Azure NetApp Files, where NetApp filers are placed in Azure data centres.
Customers order the Isilon service via Google Cloud Marketplace. Customers are provided with Isilon Gen6 hardware and configuration and management is conducted through the Google Cloud console. Each Isilon cluster is dedicated to a single customer, so performance is predictable and data tenancy is assured. There are no egress charges associated with moving data between this storage platform and other Google Cloud services.
Existing applications using Isilon OneFS file storage can run in Google Cloud and use OneFS in the same way.
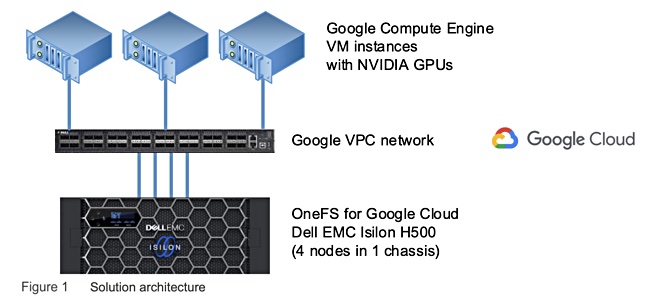
A Dell Technologies white paper shows how OneFS for Google Cloud can be used for deep learning and illustrates an example setup:
Isilon hardware communicates across a Google Virtual Private Cloud (VPC) for access by Google compute instances. VPCs are global resources and are not associated with any particular region or zone.
Dell Technologies did not provide any availability information. Blocks and Files suspects there will be geographic availability restrictions.
Competition and Performance
Isilon’s OneFS joins Filestore, NetApp Cloud Volumes, Google’s Elastifile and Panzura as file server suppliers in GCP. Qumulo is also available for Google’s cloud but listed separately. In that listing Qumulo claims it’s the fastest and most affordable file system in the cloud. This claim may now be out of date.
ESG used the IOzone, an industry-standard benchmark, and Scratch DNA, a benchmarking tool that emulates the write-intensive storage workloads typically generated in genomics research. It tested a 2PB OneFS file system with peak 200GB/sec aggregate read throughput and 121GB/sec aggregate write throughput on IOzone (1024 threads). Scalability was linear. The peak Scratch DNA aggregate write throughput was 110 GB/sec.
Response time was under a millisecond. ESG compared this to a mystery Vendor X competitive NAS supplier running on Google Cloud. It refused to identify who it was, and acknowledged that vendor’s release numbers used a smaller workload and smaller filesystem. That said, OneFS offers up to 500x higher file system capacity, 46x maximum read throughput and 96x higher maximum write throughput.
A 500X higher capacity, based on OneFS’s 50PB limit, would mean a 100TB limit. NetApp Cloud Volumes offers up to 100TB. Qumulo on Google Cloud scales to the petabytes level. Filestore scales up to 63.9TB. We couldn’t find a capacity limit for Panzura but nonetheless we think ‘Vendor X’ is NetApp and its Cloud Volumes product.
A NetApp Azure benchmark webpage talks of Azure NetApp Files delivering 30MiB of bandwidth with a 5TiB volume. It delivers around 1,600MIB/sec writes and 4,500MIB/sec reads on a Linux system. MySQL latency was between 1.8 and 4.6ms.
There’s no obvious apples-to-apples comparison here but our impression is that OneFS for Google Cloud is faster than Azure NetApp Files.
Dell is the top scale-out file system vendor in IDC’s Worldwide Scale-Out File-Based Storage 2019 Vendor Assessment, ranking above NetApp, IBM and Qumulo.
Update. A Dell spokesperson tells us that customers in North America, Singapore and Sydney will be able to take advantage of OneFS for Google Cloud at launch, with additional global locations to be announced based on customer demand.
Interview A set of containers that would need 20 servers to run in a VM-based environment would need fewer than 4 servers to run in a bare-metal Diamanti environment; stats like this make Blocks & Files want to know how and why Diamanti’s bare metal hyperconverged systems can run Kubernetes workloads faster than either single servers or HCI systems – so we asked.
Brian Waldon, Diamanti’s VP of product, provided the answers to our questions
Blocks & Files: How do containerized workloads run more efficiently in a Diamanti system than in a commodity server+storage system?
Brian Waldon: Diamanti’s Ultima Network and Storage offload cards and bare metal hyperconverged platform are the greatest drivers to the increased workload efficiency that Diamanti provides.
Diamanti D10 server diagram showing offload cards
Diamanti offloads network and storage traffic to dedicated embedded systems, freeing up the host compute resources to power workloads and improve performance. This minimizes iowait, giving customers a 10x to 30x performance improvement on I/O-intensive applications while getting consistent sub-100 microsecond latency and 1 million IOPS per node.
The use of offload cards in the data center is not entirely new – the AWS Nitro architecture has helped to deliver better consolidation for EC2 instances and produce more cost efficiency for AWS. However, by combining offload card technology with purpose-built Kubernetes CNI and CSI drivers and bare metal, optimized hardware (w/ NVMe and SR-IOV), Diamanti has an integrated software and hardware solution that removes extraneous translation layers that slow things down.
Blocks & Files: How much more efficient is a Diamanti cluster than a Dell EMC VxRail system on the one hand and a Nutanix AHV system on the other?
Brian Waldon: Generally, we are compared to virtualized infrastructure, and again here our offload technology provides far greater efficiencies. We have a holistic platform that is designed for containerized workloads. While we happen to use X86 servers behind the scenes we have eliminated a lot of the layers between the X86 server and the actual workload, which is another key component to the efficiency with our platform.
Given that we have a hyperconverged platform, Diamanti can use the bare minimum amount of software to achieve the same goals as competitive solutions and really drive efficiency. Our platform can drive up to 95 per cent server utilisation; alternatively, virtualised infrastructure can use up to 30 per cent of server resources just to perform infrastructural functions such as storage and networking using expensive CPU resources.
One of our customers was running an Elasticsearch application on 16 standard x86 servers supporting 2.5 billion events per day. They accomplished the same on just 2 nodes [servers] of the Diamanti platform while also reducing index latency by 80 per cent.
Another customer saw similar improvements with their MongoDB application – reducing their hardware requirements from a 15-node cluster to just 3 nodes of Diamanti while still getting 3x greater IOPS.
Separately, and with Redis Enterprise, Diamanti supported average throughput of more than 100,000 ops/sec at a sub-millisecond latency with only four shards running on a three-node cluster with two serving nodes.
Blocks & Files: How does the Diamanti system compare to industry-standard servers plus a storage array with a CSI plugin?
Brian Waldon: The key differences are the innovations behind the storage offload cards and the full-stack approach from CSI down to the hardware.
Because Diamanti has a holistic hyperconverged system we can provide guaranteed Quality of Service (QoS), access and throughput, from the perspective of storage, and honour that from end to end. We have a built-in storage platform to drive local access to disk while still providing enterprise-grade storage features such as mirroring, snapshots, backup/restore, and asynchronous replication.
Diamanti also minimises staff set up and support time by providing a turnkey Kubernetes cluster with everything built-in. We give customers an appliance that automatically clusters itself and provides a Kubernetes interface.
Comment
Diamanti claims a 3-node cluster can achieve more than 2.4 million IOPS and have sub-100μs cross-cluster latency. Basically it’s a lot more-bangs-for-your-bucks message. The company says it knocks performance spots off commodity servers running Linux, virtualised servers and hyperconverged systems running virtual machine hypervisors.
It’s software uses up less of a server’s resources and its offload cards get data to and from containers faster. Result; you run more containers and run them faster.
You can check out a Diamanti white paper about running containers on its bare metal to find out more. A second Diamanti white paper looks at Redis Enterprise testing.
Pivot3 is lowering cost per TB by running its video surveillance HCI software on a Lenovo gen 2 AMD EPYC server.
Cutting to the chase, the new Lenovo ThinkSystem SR655 server can support more video cameras, run more application software to process the images and stream data faster from the camera sites to a data centre than its Intel Xeon predecessor. That will help Pivot3 sell better against Intel-based HCI systems.
Customers also get significantly more bandwidth for video recording and 150 per cent increase in networking speed, with 25GbitE support for faster video transfer from the edge to the core.
The SR655 is a single socket AMD EPYC 7002, 2U server with up to 64 cores. This is claimed to provide equivalent performance to a dual-socket Intel-based server but costs less. For example, there is an opportunity for 50 per cent cost savings on software that is licensed per socket.
According to Pivot3, the EPYC processor is more powerful than the Intel Xeon used previously – a viewpoint it shares with HPE, which recently announced the SimpliVity VDI system,
The company claims the Pivot3/SR655 server delivers 10 per cent lower cost per terabyte, 14 per cent better capacity density, and supports PCIe 4.0, helping to deliver 100 per cent more bandwidth than similar servers using slower PCIe gen 3. The company is referring obliquely here to Xeon.
Users streaming data from AWS can save egress charges by storing and streaming the data using LucidLink’s Filespaces bundled with AWS S3 storage.
Peter Thompson, LucidLink CEO, has provided an announcement quote: “We … heard a great deal of frustration from our customers around the unpredictable nature of egress fees … we were able to come up with a bundle that will satisfy most customer requirements, assisting in cost predictability. As an added benefit, we eliminate the complexity of setting up a cloud service and pass on the combined buying power we create directly to our customers.”
The deal is that you buy a Filespaces subscription bundled with AWS S3 storage. Filespaces plus 1TB of S3 storage and 1TB of outbound (egress) traffic costs $85 per TB per month. Users are billed at $0.05/GB ($50 per terabyte) for egress costs above 1TB per month.
According to a Microsoft price comparison site, AWS S3 data egress costs $0.09/GB for the first 10TB with an initial 1GB free, and then decreases to $0.05/GB at 150TB or more. That makes the LucidLink 1TB+ egress charge of $0.05/GB look pretty good.
LucidLink claims it is making cloud services more accessible and predictable because users can now more accurately forecast egress fees.
The company is targeted cost-sensitive users who need good performance when processing files on-premises streamed from the cloud. Examples include video editors and others in the media and entertainment industry.
Veeam has joined forces with Kasten to offer cloud-native application backup to its customers. The deal spans sales, marketing and technology.
This partnership solves a problem for Veeam – how to get a foothold in cloud-native backup for cloud-native applications that run as a bunch of containers in a Kubernetes-orchestrated system.
Veeam aims to provide full spectrum backup to its customers, but has found that many are adopting a DevOps approach and running Kubernetes-orchestrated, cloud-native systems, sometimes with thousands of containers in clustered server systems. The company is facing a build, buy, or partner decision. Today’s outcome is its decision to partner with Kasten and its K10 product.
Dan Kogan, Veeam product and solutions marketing VP, writes in a company blog: “We’ve been seeing our customer’s interest increase in Kubernetes as a critical piece of their cloud infrastructure, creating a new area around container-native data protection that they need help in addressing. To that end, we’re excited to share that we are partnering with Kasten, the leaders in backup solutions for containerised workloads.”
Containers eat Veaam’s lunch
In the virtual server world, a virtual machine (VM) and an application are often effectively identical, and always closely intertwined. Veeam’s genius was to gain deep awareness of how hypervisors schedule and run applications in virtual machines and so provide better VM backup.
The company has made a killing in providing backup and restore under a data availability theme, first for apps in virtual servers, then virtual servers in the cloud and also physical servers. But containerisation and DevOps style development has encroached onto the virtual server world. Where does Veeam fit in?
A containerised application needs a backup facility that understands the backup focus is the application, not the container. Veeam could move with VM environments that migrated to the cloud – VMware Cloud Foundation, for example. But it had no capability for cloud-native backup for cloud-native apps.
Container backup
This has opened up opportunities for specialist startups such as Kasten, which recognised that Kubernetes and its orchestrating ilk provides the same framework for container backup as hypervisors do for VM backup.
In Kubernetes there is no mapping of applications to servers or VMs. Instead, applications are mapped to a set and sequence of containers. VM-focused or server-focused backup is blind in the Kubernetes world. Containerised app atomicity is the sine qua non here.
Bewildering containerised application environment
Comment
Veeam has signed reseller deals before, for instance with N2SW, to underpin Veeam Availability for AWS. This provided a cloud-native agentless backup and availability system to protect AWS apps and data.
It bought N2SW for $42.5m in January 2018. Problems ensued involving Veeam’s then Russian ownership, non-US domicile and N2SW’s federal business. Veeam sold N2SW in October 2019. Veeam is now US-domiciled, following the $5bn acquisition by Insight Partners in January 2020.
Kasten provides another route for Veeam into cloud-native backup. Will Veeam want to own its own containerised application backup technology? Blocks & Files thinks this is on the table, and Kasten, with total funding of $17m, is an inexpensive option.
It’s all about more and more speed and faster disaster recovery in this week’s roundup. Read on,
Nvidia DGX A100 GPU server
Nvidia has launched its third generation DGX GPU server, the DGX A100. This has encouraged third party suppliers to announce DGX support.
Iguazio, which supplies a high-speed, high-capacity storage platform for analytics-type workflows, including AI, was quick off the blocks. It says its data science platform technology supports GPU-as-a-service and has been certified DGX-ready by Nvidia.
Data scientists and engineers can work on a single self-service data science platform, which has horizontal scaling and dynamically allocates GPUs to workloads for greater resource efficiency. Iguazio’s open source projects, Nuclio and MLRun, serverless and orchestration frameworks respectively, manage GPU resources, and support stateful and distributed workloads.
Iguazio’s GPU-as-a-Service offering is part of the Nvidia DGX-Ready Software program.
HPC and general enterprise storage supplier DDN supports the DGX A100 with its A3I product. This originally paired DDN’s AI200 and AI400 all-flash arrays, running Lustre-based Exascaler software, with Nvidia’s DGX-1.
The A3I now works with NVIDIA’s DGX A100 and Mellanox switches and NICs. DDN says that A1400X-based A3I systems are deployed in Nvidia’s own data centre to provide high-performance and scalable shared file access for the DGX A100-based SuperPOD. This SuperPOD uses 140 DGX A100 systems.
DDN and Nvidia plan to release new reference architectures based on A3I and DGX A100.
Nvidia has said Dell, IBM, NetApp, Pure Storage and VAST Data storage lines will support the DGX A100.
InfiniteIO and Google Cloud Platform
InfiniteIO is now an official Google partner whereby its Hybrid Cloud Tiering software can be used to move infrequently accessed files from on-premises storage to GCP, saving on-premises file space and cost, but with no change to application access. The InfiniteIO system does all the file metadata processing usingFile Metadata Engine accelerator software and hides the file movement from applications.
InfiniteIO supports all four classes of Google Cloud Storage: standard, nearline, coldline, and archive. The upcoming v2.5 software release supports Native File Format for files tiered to object storage. Native File tiers whole files instead of storing the data in a proprietary format and allows customers to access tiered files directly via Google Cloud Storage.
The mdtest benchmark tests metadata performance of parallel filesystems using various simulated metadata workloads. InfiniteIO Blogger Kris Meier has described how an mdtest benchmark for a single-node InfiniteIO/Google Cloud Platform configuration reduced latency from about 1ms to 40μs.
InfiniteIO announced Hybrid Cloud Tiering functionality last month. It supports Amazon Web Services, Google Cloud Platform, IBM Cloud, Microsoft Azure and Oracle Cloud Platform. Currently supported on-premises NFS- and S3-based private cloud platforms include Cloudian, Dell EMC, HPE, NetApp, Scality and Western Digital.
InfiniteIO is planning an announcement on Microsoft Azure once it formalises the business partnership.
Memverge Big Memory Computing
Memverge, a supplier of in-memory computing software, has closed a $19m funding round led by Intel Capital, taking total funding to $43.5m.
The California startup today announced the Big Memory Computing scheme, a combination of DRAM, Intel Optane persistent memory and its own Memory Machine software technologies. It says it has a roadmap to achieve petabyte scale at nanosecond-speed.
Eric Burgener, research VP at IDC, said: “Without requiring any existing application rewrites, Big Memory Computing delivers the highest category of data persistence performance with the enterprise-class data services needed for the real-time, mission-critical workloads that will increasingly drive competitive differentiation for digitally transformed enterprises.”
Memverge’s technology includes instant and non-disruptive ZeroIO Snapshot for data persistence. Charles Fan, CEO and co-founder of MemVerge, said: “We founded MemVerge on the premise that every application should run in memory. There are clear use cases in AI/ML and financial market data analytics today.”
Brad Anderson, EVP of NetApp, which is a MemVerge investor, said: “MemVerge’s software combines persistent memory, hyperconverged architecture, and container orchestration, all critical components to support data-intensive applications including AI, machine learning and intelligent analytics. Our investment in MemVerge supports what we feel is the next step in the evolution of storage technology.”
MemVerge Memory Machine software will be available to select customers as part of the Early Access Program this quarter.
Nutanix improves disaster recovery
Nutanix has added new disaster recovery facilities for its AHV hypervisor:
Multi-Site Disaster Recovery: This helps customers to recover from the simultaneous failure of two or more data centres, while keeping applications and data available to users. It uses automation technology to eliminate the complexity of DR installation and on-going orchestration.
Near Sync Disaster Recovery: Nutanix now supports near sync replication with an RPO of only about 20 seconds, a 3x improvement from before.
Synchronous Data Replication is now natively supported and can be used by customers to deliver a highly available service for workloads, such as virtual desktop infrastructure, databases, and general server virtualization.
DR Orchestration with Runbooks.
Nutanix reckons it is the only leading HCI vendor to offer a 20-second RPO – Cisco, Dell EMC, VMware, HPE and NetApp can’t match it, in other words.
The new DR capabilities are included in Nutanix HCI software and are generally available.
Sony PlayStation 5 SSD
Tim Sweeney CEO of Epic, the games developer, discusses the new SSD inside Sony’s PlayStation 5 gaming console, in interview with The Verge He said it has a “multi-order bandwidth increase in storage management”.
This drive is an 825GB NVMe M.2 format SSD that holds compressed data and has 5.5GB/sec of raw data bandwidth; 9GB/sec compressed, according to TweakTown. That media outlet says this Sony SSD has a 12-channel controller and a PCIe gen 4 interface.
It will use decompressed data for real-time processing and loading. Games will boot in a second with no load screens. The drive can load 2GB of date in 0.27secs.
Sweeney said the SSD will enable a virtual game world, tens of gigabytes in size, to render on screen in less than a second because the drive can transfer information so fast: “The storage architecture on the PS5 is far ahead of anything you can buy on anything on PC for any amount of money right now. It’s going to help drive future PCs. [The PC market is] going to see this thing ship and say, ‘Oh wow, SSDs are going to need to catch up with this.”
Shorts
Copy data manager Actifio has announced its strongest Q1 to date, with record revenue and double digit Y/Y growth. It recorded several seven-figure deals from some of the hardest-hit Covid-19 regions around the globe (Northern Italy, UK, New York).
IaaS provider Priseda will offer cybersecurity-enabled private cloud DRaaS, using Asigra software, to business customers. The new GridObserver (GO) solution will be sold through the IT channel and provide full-service DRaaS and network management services.
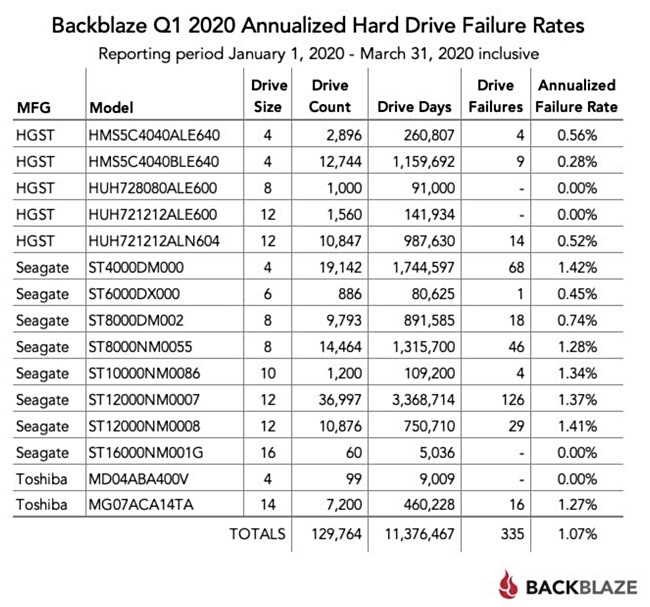
Cloud backup and storage supplier Backblaze has provided its latest hard disk drive reliability stats in one of its regular blogs.
Hitachi Vantara, The American Heart Association, and Burst IQ& have announced a COVID-19 data challenge to accelerate understanding of the correlation between other health conditions or health disparities and COVID-19 mortality. The challenge gives researchers access to The American Heart Association’s Precision Medicine Platform, developed by Hitachi Vantara, and Burst IQ’s global COVID-19 datasets.
The US Commerce department has decided that semiconductor chips manufactured overseas using US software or hardware cannot be shipped to Huawei or any of its subsidiaries without US government permission. Wells Fargo senior analyst Aaron Rakers told subscribers: “We … believe that there is long-term potential for a technological decoupling of the U.S. and Chinese semiconductor industries, creating a worldwide bifurcation of semi technology.”
B&F suggests this means non-X86 standard CPUs could emerge from China along with separate DRAM and NAND technology. US-operated semi fabs in China, such as Intel’s Dalian facility, could be the target of any Chinese response to the US Commerce department move.
The OpenFabrics Alliance (OFA) and the Gen-Z Consortium today announced a Memorandum of Understanding (MOU) to advance industry standardisation of open-source fabric management. The MOU creates the framework for a series of technical exchange meetings between the two organisations to determine future activities. In April the CXL and Gen-Z groups announced a memorandum of understanding, which opened the door for their future collaboration.
MariaDB today announced the immediate availability of its database-as-a-service MariaDB SkySQL through the Google Cloud Marketplace. SkySQL has a cloud-native, Kubernetes-based architecture.
Nvidia’s Mellanox unit has launched the ConnectX-6 Lx SmartNIC, a 25/50 gigabit per second (Gb/s) Ethernet smart network interface controller (SmartNIC.) It uses software-defined, hardware-accelerated engines to offload security and network processing from host CPUs. The card provides RDMA over converged Ethernet (RoCE), advanced virtualization and containerisation, and NVMe over Fabrics functionality.
The chip incorporates IPsec in-line cryptography, hardware Root of Trust, and a 10x performance improvement for Connection Tracking. ConnectX-6 Lx is sampling now, with general availability expected in Q3 2020.
Portshift, which supplies cloud-native workload protection, announced it has received Red Hat’s Container certification. This expands the availability of Portshift’s workload protection across Red Hat’s hybrid cloud portfolio, including Red Hat OpenShift, to help provide more secure and compliant containerised application deployments.
OSNEXUS, a supplier of grid-scale software-defined storage, has released QuantaStor 5.6. New features include NAS storage-tiering to cloud platforms, S3 Reverse Proxy capabilities for IBM Cloud Direct Link, scale-out Ceph technology upgrades, and enhanced hardware enclosure visualisation capabilities for Ceph.
Quest Software has announced NetVault v13 to help organisations simplify data protection and recovery strategies across cloud environments and workloads. The software includes a new Rest API interface and support for Office 365 Teams.
Redis Labs has teamed up Microsoft to deliver Redis Enterprise as new, fully integrated tiers of Azure Cache for Redis. The service is available today in Private Preview. The functionality includes Redis on Flash, modules, and, in the future, the ability to create an active geo-redundant cache for hybrid-cloud architectures.
Seagate has announced a limited time offer for buyers of its PhotoDrive backup device at Walmart stores. It will include a complimentary, three-year Mylio Create plan. This includes automatic multi-device syncing for up to 50,000 photos, editing features, and cloud-optional backup storage.
SIOS has announced general availability of its v9.5 Protection Suite for Linux. This software is aimed at complex high-availability SAS S/4HANA environments and provides application-aware monitoring, cloning, and failover orchestration. It can be used on-premises and by MSPs and public cloud providers. V9.5 includes support for the latest Linux operating systems and databases, including RHEL 8.1, CentOS 8.0, CentOS 8.1, Oracle 8.0, and Oracle 8.1.
Tape library and unstructured data storage suppler Spectra Logic has launched a Remote Installation Programme to support customers during the global coronavirus outbreak. This is for customers who are restricted from having outside personnel step onsite, enabling them to receive remote assistance with installation, set-up, testing and service.
Syncsort has rebranded itself as Precisely, following its December 2019 acquisition of the Pitney Bowes software and data business. Precisely says it is a world-class business with leading software and data enrichment products, annual revenue in excess of $600m, 2,000 employees, and 12,000 customers in more than 100 countries, including 90 of the Fortune 100.
CEO Josh Rogers said: “Put simply, better data means better decisions, and Precisely offers the industry’s most complete portfolio of data integrity products, providing the trusted link between data sources and analytics that helps companies realize the value of their data and investments.”
Google has announced its Google Cloud VMware Engine, whereby customers can run applications on VMware Cloud Foundation in Google Cloud. The GC VMware engine will be generally available this quarter. DR supplier Zerto supports the GC VMware Engine and says customers can use Google Cloud as a replacement for their Disaster Recovery site. It says it provides 24×7 availability with its continuous data protection and fast RTOs (minutes) and RPO (seconds).
People
Database copy manager and data ops supplier Delphix has hired Alex Hesterberg as chief customer officer, and Deron Miller as SVP of Americas Field Operations. Hesterberg, ex-Riverbed and Pure Storage, will be responsible for Delphix’s solution consulting, implementation, pre-sales, customer success, support, education, and other services functions.
NetApp CEO George Kurian has hired ex-Microsoft exec Cesar Cernuda to be NetApp’s President, a role formerly held by Kurian. Cernuda will be responsible for NetApp’s global world-wide go-to-market operations including sales, marketing, services, and support. At Microsoft Cernuda was president of Microsoft Latin America (and a Corporate VP and looked after Microsoft’s products, services, and support offerings across Latin America.
There has been speculation that Kurian is about to leave and Cernuda is his replacement. ESG founder Steve Duplessie thinks this is wrong. Before Kurian became NetApp CEO the job was carried out by Tom Georgens. He had previously been NetApp’s President for several years, reporting to the then-CEO Dan Warmenhoven.
Nutanix has promoted Christian Alvarez to SVP w-w Channels.
Quest Software has appointed Patrick Nichols, ex-CEO at Corel, as its new CEO. His predecessor Mike Kohlsdorf is joining Francisco Partners Consulting as President.
Scale-out file storage supplier Qumulo has appointed Craig Bumpus as its chief revenue officer. Previous incumbent Eric Stollard has moved into an executive advisory role for Qumulo for the next year. Berry Russell has been appointed SVP and GM of cloud and Michael Cornwell as CTO.
Datera is cutting staff and reducing some salaries to reduce cash burn. The storage software startup last week raised an undisclosed sum in a funding round, CEO Guy Churchward wrote on LinkedIn, which involves “a plan-pivot from ‘foot jammed on gas’ to ‘get to cash flow positive by the end of FY2020”.
Datera said the reorganisation is its response to the covid-19 pandemic and its effect on the storage market.
Blocks & Files understands the company has laid off 10-15 per cent of the workforce and that Churchward has taken a temporary 80 per cent salary cut.
Last week Datera’s website stopped working briefly and CTO Hal Woods posted an ‘I’ve been laid off‘ message on LinkedIn. This prompted speculation on Reddit that Datera was in trouble. Churchward posted this response on the website.
1. I’ve been the operating CEO of Datera since late 2018 and I am still here.
2. Website had a brain fart yesterday due to an expired credit card on file and was back up shortly after.
3. To the funding point we just concluded another round with a plan-pivot from ‘foot jammed on gas‘ to ‘get to cash flow positive by the end of FY2020’. (of which I posted last week – LinkedIn update Post on Q1 and beyond .)
Even coming off a stellar 2019 result followed recently by >150% growth in Q1 bookings, we felt we should (like many others) be cautious in our forward planning.
As such we ratcheted back expenses that were being incurred to prime a faster/riskier growth trajectory and took a very small reduction in workforce mainly aimed at pairing back executive coverage to the fundamentals of customers and product support.
Every company is adapting and flexing to the current market conditions, I could already see CFBE (Cash Flow Break Even) on the near horizon, so a plan adjustment to accomplish this in 2020 would be an epic achievement. This without question would make Datera stronger for future growth and open many more avenues and opportunities to us.
Update: Two other execs are no longer listed on Datera’s leadership webpage;
Claudio Fleiner, Co-founder and Chief Architect,
Chris Cummings, CMO.
Datera supplies scale-out enterprise-class clustered block and object storage software as an alternative to hyperconverged infrastructure (HCI) and traditional external SAN array storage. It has a reselling partnership with HPE, with its software part of HPE’s Complete program.
The company reported 325 per cent revenue growth in 2019 compared to 2018, and has transitioned from perpetual license sales to a subscription business model.
Update: May 18 – TouchSupport customer review of ExaFlash One.
Nimbus Data, a data storage vendor based in Los Angeles, has announced the ExaFlash One all-flash array with a multi-function, multi-protocol, multi-mode OS, and simplified and transparent pricing.
The company has recruited Eric Burgener, research VP in IDC’s Infrastructure Systems, Platforms and Technologies Group, for this quote: “With its versatility, federated architecture, and multi-tenant management capabilities, Nimbus Data AFX is a well-conceived solid state storage platform for dense enterprise workload consolidation.”
A customer, Nick Smith, director of Remote IT and Broadcast Engineering at World Wrestling Entertainment, said: “We were able to deploy it in 30 minutes. We are consistently writing to the ExaFlash array at line-rate, and it is performing flawlessly.”
The array hardware is a 2U x 24 x U.2 slot enclosure with dual active:active controllers.
ExaFlash One
Supported host links are 8 x 16Gbit/s FC, 8x 10 or 40GbitE, 8 x InfiniBand FDR, or 4 x 16Gbit/s FC + 4 x 10GbitE. A maximum 2 million IOPS of performance is claimed.
The case is populated with 48TB (12 x 4TB SSDs) to 768 TB (24 x 32TB SSDs) or delivered empty with a set of qualified 12Gbit/s SAS SSDs from Kioxia, Samsung, Seagate and Western Digital that customers can buy themselves.
The arrays can be federated but there is no back-end fabric, and no data IO between or across the federated systems. This is not clustering – the federation is via scale-out independent nodes.
ExaFlash One has a separate out-of-band Ethernet management link with a single and central point of management.
AFX software
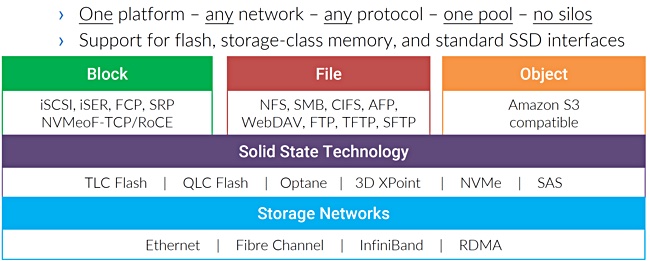
The AFX operating system is claimed to provide block, file and object storage (S3) access with a wide set of supported access protocols:
It is also said to include data management features including snapshots, cloning, replication, multi-pathing, RAID, thin provisioning, compression, deduplication, checksums and encryption.
The array can be operated in three modes;
Intelligent mode – with the data management features
Ludicrous mode – RAID protection only and optimised for throughput and IOPS
Bare-metal mode – with direct access to each SSD using NVMe-oF, iSCSI. FC or SRP
Support and pricing
Nimbus has announced a support scheme with a flat annual fee per array and a single support tier with 24 x 7 x 365 availability and next-day parts replacement. There are free non-disruptive controller upgrades after three years, all-inclusive software, free software updates and an absence of capacity-based license fees.
The company said the array’s power usage is carbon-neutral, courtesy of a renewable energy offset scheme. There is a 60-day money-back guarantee and support contracts run from one to seven years.
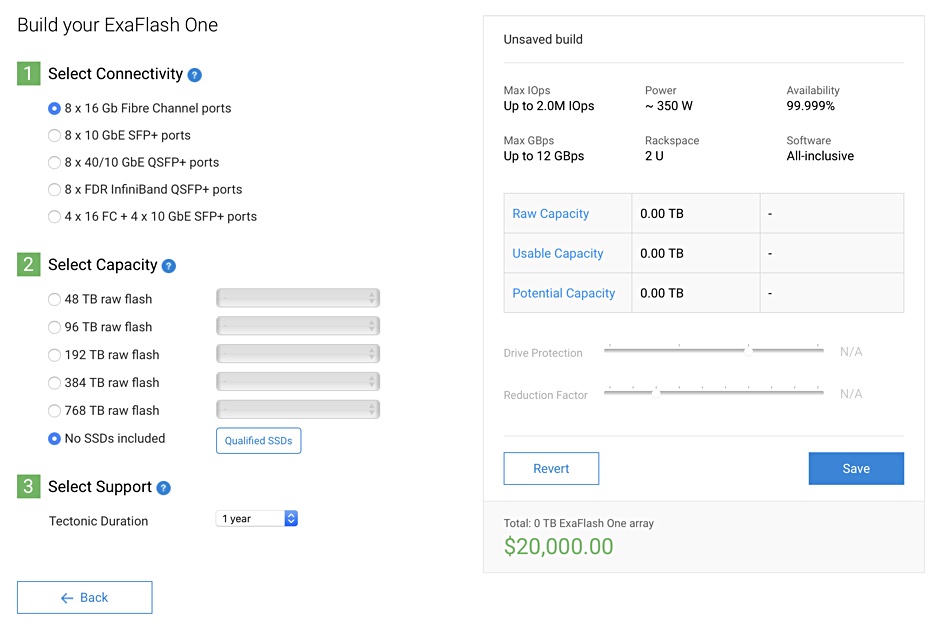
Customers can set up an account on the Nimbus website, spec out and price an array themselves. Nimbus claims a $10,000 starting price but we were only able to get down to $20,000 using the online facility.
Update: That was by selecting the ‘No SSDs included’ option. Nimbus explains that $10,000 is the ExaFlash One system base price, including all software, and Tectonic is $10,000 per year.
Choosing the maximum capacity system of 768TB would cost $212,000.
TouchSupport customer view
Touch Support CTO Jason Hamilton was quoted in Nimbus’ announcement; “We chose ExaFlash One for our internal VMware environment and have been very pleased with its speed, availability, and ease of use. Given our experience, we recommend ExaFlash to our clients for their critical workloads.”
Touch Support is based in Chicago. We contacted Jason and asked him three questions about his decision to buy the ExaFlash One array.
Blocks & Files: Could you tell me what were the alternative arrays you considered for your workload and why you chose the ExaFlash ONE?
Jason Hamilton: When we started research for a new SAN I cast a wide net but ultimately narrowed our options down to three choices. HPE Nimble all-flash, Fujitsu (ETERNUS AF250 S2) and of course Nimbus ExaFlash.
There were a couple of reasons that we chose Nimbus. Firstly and probably most was price. Nimbus is priced very competitively even factoring in a 5-year support contract paid upfront.
Next, it’s important to know that I’ve been following Nimbus since mid-2012 where I learned of the company and their S-series arrays at a VMware conference. Even back then they were producing all-flash arrays touting 1 million IOPS. This impressed me greatly and I kept an eye on their progress over the years.
The Fujitsu option is very much a new player in the segment and didn’t give me as much confidence in their ability to maintain the product considering their diversified nature.
Lastly, going with ExaFlash seemed to make the most sense. This is their most recent flagship platform and would stand to have the longest support-life period available. We generally try to maximize our hardware lifecycle and it is critical to maintain an active support contract on critical systems such as a SAN.
Blocks & Files: How are you using the array? I mean for block, file or object work?
Jason Hamilton: We are an all VMware shop so the array is configured only for iSCSI block access to our ESXi hosts. We naturally do use the compression and deduplication features at the array level as well.
Blocks & Files: How does it compare to other arrays you have had experience with?
Jason Hamilton: Having either closely worked with or at the very least run proof-of-concept on a number of SAN and NAS solutions, the Nimbus ExaFlash is refreshingly simple. Coming from a Unix/Linux background the option to handle all configurations completely from an ssh shell is very pleasing. The web-based interface is likewise very simple to use and doesn’t have any irksome custom plugin requirements. Gone are the days of separate fat-client software or the hit-or-miss vSphere plugins for management and configuration.
Background
Nimbus has sold ExaFlash arrays since 2016 and claimed 200 customers in 2018. It now says it has 600 deployments. CEO and founder Thomas Isakovich says Nimbus was profitable in 2019 and expects to grow profits this year.
The privately-owned company appears to be very small. Six employees are listed for Nimbus Data on LinkedIn and the leadership page on its website lists one executive officer – Isakovich.