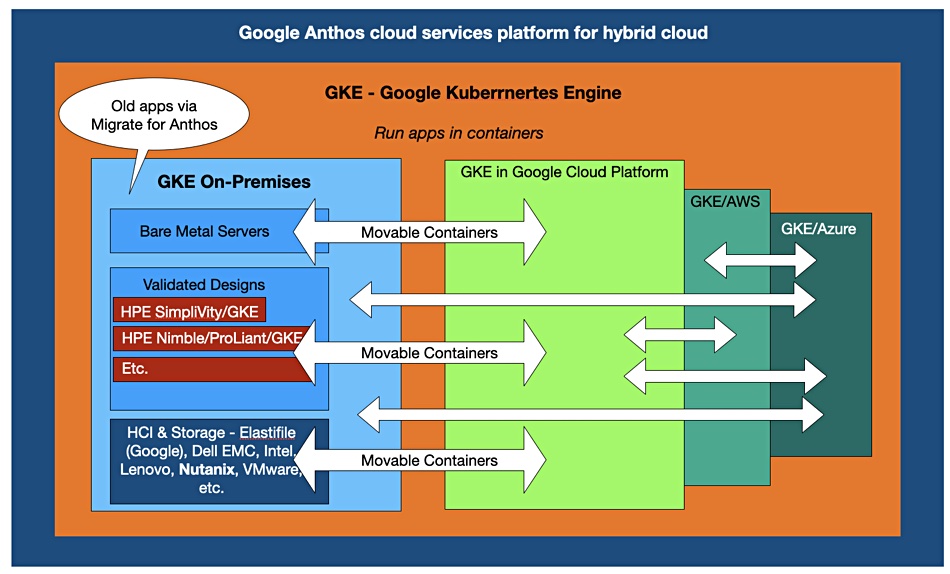
Nutanix HCI now supports Anthos, the Google application management platform for customers who run Google Kubernetes Engine (GKE) on their own servers.
Anthos also runs on the big three public clouds, which means that containerised applications can be moved between these environments using a single management tool.
Nutanix bloggers Sean Roth and Luke Congdonwrite: “Enterprise IT teams often run into major issues when trying to build on-prem Kubernetes environments using their existing legacy infrastructure. This is because traditional servers, storage, and networking solutions aren’t architected for the way that Kubernetes and containers use IT resources.”
They say running Anthos on Nutanix gives customers a multi-cloud infrastructure capability that delivers limitless ability to run web-scale containerised applications. It also enables users to choose their preferred hardware and integrates comprehensive virtualization, storage, and management features.
B&F Anthos diagram
Bare metal
Google in November 30 added bare metal server support to Anthos for customers who do not need an intervening hypervisor layer such as Nutanix AHV, or want to use their own OS.
Anthos on bare metal includes overlay networking and L4/L7 load balancing out of the box. Customers can also use F5 and Citrix load balancers.
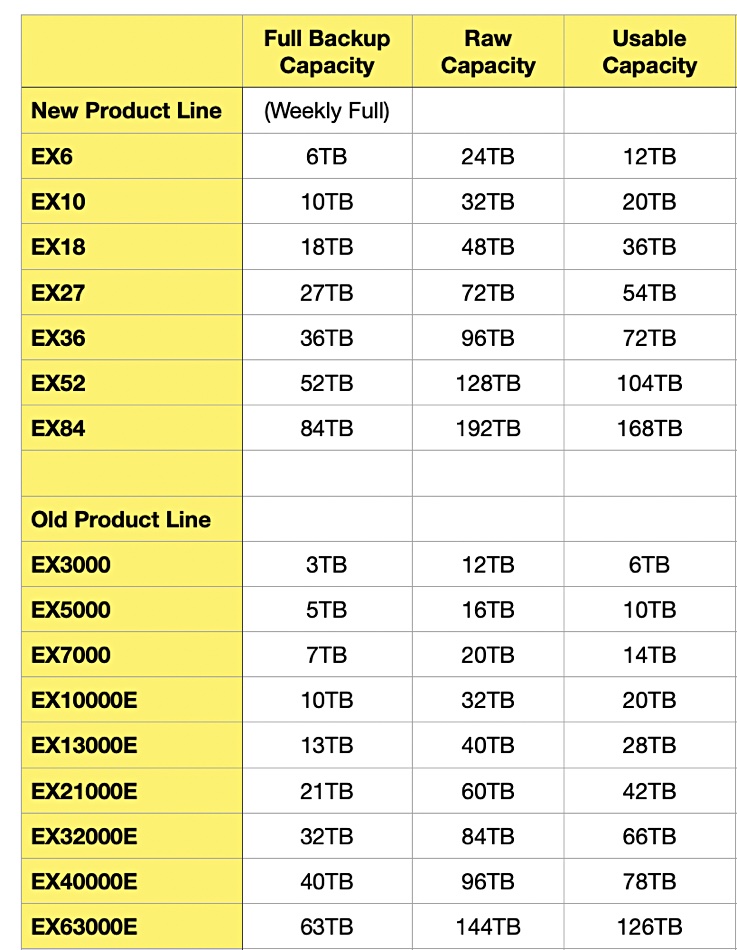
ExaGrid has increased capacity in its deduplicating backup appliances and at the same time, cut the product portfolio from nine systems to seven. Appliances of any size can be mixed and matched in a 32-appliance cluster.
Old and new Exagrid appliance product lines.
Bill Andrews, President and CEO of ExaGrid, said in a statement: “ExaGrid continues to build on its scale-out architecture and we are excited to announce our largest system to date.
“In addition to offering the largest backup system in the industry, we also offer the only system with a disk-cache Landing Zone that is tiered to a long-term retention repository and the only approach to deduplication that doesn’t negatively impact backup and restore performance, which differentiates us from first-generation storage products – inline scale-up deduplication appliances such as Dell EMC Data Domain and HPE StoreOnce.”
ExaGrid doesn’t discuss hardware speeds and feeds but we guess that the new appliance models have newer and more powerful processors and larger capacity disks than the superseded line. The old EX3000 to EX63000E product line used 2TB, 4 and 6TB drives. The disk makers are now supplying drives at 20TB capacities, and the market sweet spot is currently 14TB -16TB.
A single scaled-out clustered system of 32 EX84 appliances can take in up to 2.69PB full backup with 43PB of logical data, making it the largest backup storage system in the industry. This new EX84 occupies 33 per cent less rack space than the previous top end EX63000E model.
Dell EMC Data Domain is ExaGrid’s biggest competitor. The largest Data Domain system is the DD9800 with 1PB of usable capacity. This is larger than Exagrid’s high-end EX84 and its 168TB usable capacity. But stick 32 EX84s together in a cluster and the usable capacity is 5.37PB, which is roughly five times more than Data Domain.
ExaGrid’s new appliances can be installed in existing clusters and are available immediately. No pricing information was revealed.
In this week’s storage news roundup, Cohesity and Cisco say users can save bundles of cash compared to using other servers and unstructured data management software. We’ve also got a couple of flash products, a DNA storage snippet, a NAS earthquake tremor and a clutch of suppliers making good coin.
Cisco and Cohesity benefits studied
Cisco and Cohesity commissioned Forrester Consulting to conduct an independent Total Economic Impact study that evaluates the tangible value of Cohesity software on Cisco Unified Computing System (UCS).
The study found a Cisco UCS/Cohesity software system delivered an overall return on investment (ROI) of 150 per cent in three years for a modeled composite organisation. The payback period was a year, and the total benefits present value realised, when compared to the total costs of $1.05m, was $2.63m.
Other findings:
83 per cent to 99 per cent reduction in recovery time
25 per cent of the workday returned to data administrators and application developers by boosting efficiency in sharing backup data
70 per cent reduction in annual storage infrastructure expenditures
80 per cent + less time to install servers with Cisco Validated Design
Microchip’s tri-mode storage controller
Microchip has announced the production release of the first products to deliver 24Gbit/s SAS, SATA, PCIe Gen 4 and NVMe; the Smart Storage PCIe Gen 4 Tri-Mode SmartROC (RAID-on-Chip) 3200 and SmartIOC (I/O Controller) 2200 storage controllers.
Pete Hazen, VP for Microchip’s data centre solutions business unit, said: “Our industry firsts include support for a PCIe Gen 4 interface with DirectPath technology for low-latency NVMe transactions, and 24G SAS with Dynamic Channel Multiplexing (DCM) for more efficient aggregation of lower-speed SAS or SATA hard drives onto 24G SAS infrastructure.”
SmartROC 3200 and SmartIOC 2200 products support both x8 and x16 PCIe Gen 4 host interfaces and up to 32 lanes of SAS/SATA/NVMe connectivity. Support for up to 8 GB of on-board cache triples the RAID performance compared to competitive alternatives, while DCM delivers link efficiency of greater than 99% while ensuring full interoperability with existing legacy SAS/SATA infrastructure.
The products are available in volume production quantities.
OWC’s 4-stack M.2 carrier
OWC’s U2 Shuttle contains four M.2 (gumstick) NVMe SSDs and fits in 3.5-inch drive bays. It can be used with U.2 port-equipped PCs and servers, as well as OWC storage and PCIe expansion systems. The M.2 SSDs can be OWC’s own Aura brand drives.
OWC U2 carrier shuttle
Aura P12 Pro preconfigured U2 Shuttles have NVMe drives using Triple-Level Cell (TLC) 3D NAND with SLC caching and a Phison E12 controller. By utilising a U.2 port equipped OWC system or a PC with an available 3.5-inch drive bay on both ends, you can ship the shuttle to the post-processing lab where it swaps in to a host system.
This carrier Shuttle can be used by video editors, audio producers, photographers, and graphic designers who want a multi-blade SSD providing, OWC says, blistering speed, massive capacity, RAID-ready flexibility, and swappable convenience. The product lowers production-to-lab shipping costs versus shipping larger, disk-based, heavier drives.
A RAID 0, 1, 4, 5, or 10 scheme can be set up across the 4 SSDs using RAID hardware cards hardware cards or RAID utilities including SoftRAID. RAID will provide extra performance and/or protection.
The OWC U2 Shuttle will be available in January 2021 for $149.99 at MacSales.com. It has a 1 Year OWC limited warranty and lifetime support
Show me the money
Hornetsecurity has bought backup supplier Altaro. The buyer is a cloud security specialist headquartered in Germany that operates in more than 30 countries and has arounds 40,000 customers. Altaro has backup offerings for Hyper-V, VMware, physical servers, network endpoints and Microsoft Office 365. It says it has 50,000+ customers in 121+ countries, 10,000 partners and 2,000+ MSPs.
Deduplicating backup target supplier Exagrid reported it had a record bookings quarter ending December 31, 2020, adding over 130 new customers, including a record 41 new customers with initial purchases over six figures. Bill Andrews, Exagrid CEO and President, said: “We are replacing low-cost primary storage disk from Dell, HPE, and NTAP behind Commvault and Veeam, as ExaGrid is far less expensive for longer-term retention. We are also consistently replacing Dell EMC Data Domain, HPE StoreOnce and Veritas inline scale-up deduplication appliances.”
Kasten by Veeam has announced 500 per cent growth Y/Y in both revenue and customers for its Kubernetes data management platform. This was helped in part of its acquisition by Veeam in October, along with the explosion of global Kubernetes and container adoption.
Data management startup Komprise announced record growth in 2020, despite the challenges of the pandemic. Key growth drivers included: unstructured data under management grew by over 300 per cent, a record number of major enterprises signed up as new customers, and the company expanded key strategic partnerships. Over 50 new channel partners were on-boarded.
File system platform supplier WekaIO recorded a 350 per cent Y/Y increase in its cloud business, while on-premises revenues more than doubled Y/Yin 2020. Additionally, customer confidence was strong with a 95 per cent re-purchase rate, with re-purchases generally 500 per cent higher than the original purchase. Today, 8 of the Fortune 50 are WekaIO customers.
VAST Data has announced a major U.S. Federal Agency has committed over $10m on VAST Data’s Universal Storage to consolidate their data analytics infrastructure into a single, flash-based storage system to support the needs of so-called grand-challenge data science. The agency will utilise VAST’s technology to unlock the secrets hidden within vast reserves of biological, population and health data. We understand the RFP was written for “Netapp, Netapp equivalent or better.”
Databricks has added two new board members. Elena Donio is on Twilio’s board and was on PayScale’s Board before the company was sold in 2019. She is the former president at Concur and most recently served as CEO at Axiom. Jonathan Chadwick is a board member and advisor to Zoom, Stripe, Elastic, and ServiceNow. He is the former EVP, COO and CFO of VMware and CFO at Skype. Databricks achieved a $350m+ revenue run rate as of Q3 2020, up from $200m in Q3 2019, and is now among the fastest-growing enterprise software cloud companies on record.
Starburst announced an undisclosed additional investment from David Schneider who will bring his expertise from leadership positions at ServiceNow, EMC, and Data Domain to help build and scale Starburst’s growth strategy. This follows the company’s recent $100m funding round.
Eat my shorts
Cloud data warehouser Snowflake announced an over 300 per cent increase in the total number of data providers on its Data Marketplace since April 2020. The marketplace has more than 350 datasets from over 120 data providers like Heap Analytics, Knoema, FactSet, Safegraph, WeatherSource and more, across 16 key categories – 26 per cent of which are open datasets available for all Snowflake customers to access.
Couchbase’s Database-as-a-Service offering, Couchbase Cloud, is now available on Microsoft Azure.
In-memory computing supplier GridGain has announced GridGain v8.8 with enhanced support for GridGain’s multi-tier database engine. It now scales up and out across memory and disk. This changes enable customers to leverage the disk tier of the database to query much larger datasets, reduce total cost of ownership, and secure sensitive or personal data at rest.
The California Institute of Technology is using iXsystems open source TrueNAS to support its fibre optic seismic research. This involves measuring seismic activity using dark fibre optic cables. As tremors occur, the fibre optic lines identify the earth’s movement at thousands of locations and relay that data back to Caltech for fast analysis.
Quantum has joined the DNA Data Storage Alliance to support the ongoing growth and development of the future DNA data storage market. It says Quantum’s digital archive experience and expertise will help the Alliance advance the use of DNA data storage to solve the challenges of preserving valuable digital data for centuries.
Showa Denko K.K. (SDK) will increase its aluminium substrate manufacturing for disk drive media, raising the group’s production capacity by 30 per cent. SDK’s Japan-based subsidiary Showa Denko HD Yamagata will build a new facility, beginning in February 2021, with mass production scheduled to commence in early 2022. Toshiba uses SDK aluminium platters in its MG-series and other disk drives and will use them in its coming MAMR disk drives.
Recently, I spoke to Cloudian CEO Michael Tso about the awesome scale and data storage management challenges of exabyte-levels of storage. This prompted me to wonder what an exabyte vault should look like – and who would build them.
For starters, an exabyte vault will be based on disk drives as no other affordable media performs at an acceptable level. The vault will contain many hundreds of thousands of drives.
For example, as we wrote in our earlier article, an exabyte of capacity entails buying, deploying and managing one million 10TB disk drives (HDDs), 500,000 x 20TB HDDs or 750,000 14TB drives. There will be a continuous need to add new capacity, physically deliver, rack-up, cable, power and cool, and bring on-line disk chassis.
So, the sheer scale of exabyte-level storage vaults will necessarily entail hard drive management at the intelligent enclosure level – and not, as in most cases today, at the drive level. Quite simply, there are far too many drives to manage individually.
As far as we are aware, this multi-layered management does not exist yet in the public domain. But the customised software stacks built by Backblaze, a cloud service provider, illustrates how this could work in enterprise data centres.
Scale horizontally
Backblaze CEO Gleb Budman said in an email interview that the company no longer manages just at the drive level; it’s multi-level: “Our entire Backblaze Storage Cloud is designed to scale horizontally: drives to Storage Pods to Vaults to Clusters to Regions. We’re confident in continuing to be able to scale past exabytes and to zettabytes with this approach.”
Backblaze Storage Pods
Backblaze’s experience gives us a glimpse in a future in which an exabyte vault has multi-layered management; drives in enclosures, enclosures in racks or vaults, and vaults in clusters, and then clusters in some larger entity.
That prompted us to ask Seagate about the need for drive enclosure-level management as data centre disk stores head towards the exabyte level. According to Seagate, the exabyte storage vault will likely be a distributed system via a collection of data centres.
Ken Claffey, SVP, enterprise data solutions, at Seagate, told us: “We agree with your line of thinking that managing large numbers of drives in a distributed system requires a new approach, as enterprise customers move to 100PBs and even exabyte scale.”
Ken Claffey
“This approach needs more intelligence at the ‘enclosure’ level that can reduce the burden on the higher level SDS (Software-Defined Storage) stacks to effectively manage 1000s or 10,000s of individual drives/storage devices.
“The move to ever greater drive capacity (for example, as enabled through HAMR technology), will further stress the current approach (think about having to rebuild 30, 40, or 50TB drives across the network).
“Therefore, the industry is looking at new multi-level erasure coding approaches and other such innovations to address this challenge. Seagate is at the forefront of this innovation.”
So what is Seagate doing on this front? We recently heard that Seagate is developing a 107-drive Pod –a building-block for massive storage deployments.
BackBlaze’s Budman confirmed what our sources were saying: “We had a Seagate 107-drive chassis to use as a batch processor for a data migration project recently. It’s a JBOD setup though, so not the same as our systems which have onboard compute. It’s an impressive amount of storage in one box, but not quite right for our architecture.”
He added: “We also have a Seagate AP 5U 84-drive chassis in-house. This system does include compute, so it’s a little more interesting for us. We’re regularly testing new systems to see how they’d work in our environment.”
Builders
So who would build the exabyte storage vault management software? I think that two HDD suppliers – Seagate and Western Digital – are key to making it work, as they have control at the base drive-level access layer.
They are also building their own intelligent enclosures – see Seagate above, and Western Digital, with OpenFlex.
Possibly CSPs like Backblaze could also do this. Backblaze is already building and deploying its own exabyte-scale vault and manages this using its own software. Now uppose Backblaze, or another bulk cloud storage CSP, such as Datto or Wasabi, productised their exabyte-capable disk vault management software. That could appeal to on-premises exabyte vault builders?
That said, the software stacks would have to manage commercially-available HDD enclosures – and not just their own proprietary Pods.
Lastly, it is remotely conceivable that the big three CSPs, AWS, Azure and Google could do the same. I think this is unlikely because they all appear hell bent on getting bulk on-premises storage data moved to their clouds rather than helping large-scale on-premises storage survive.
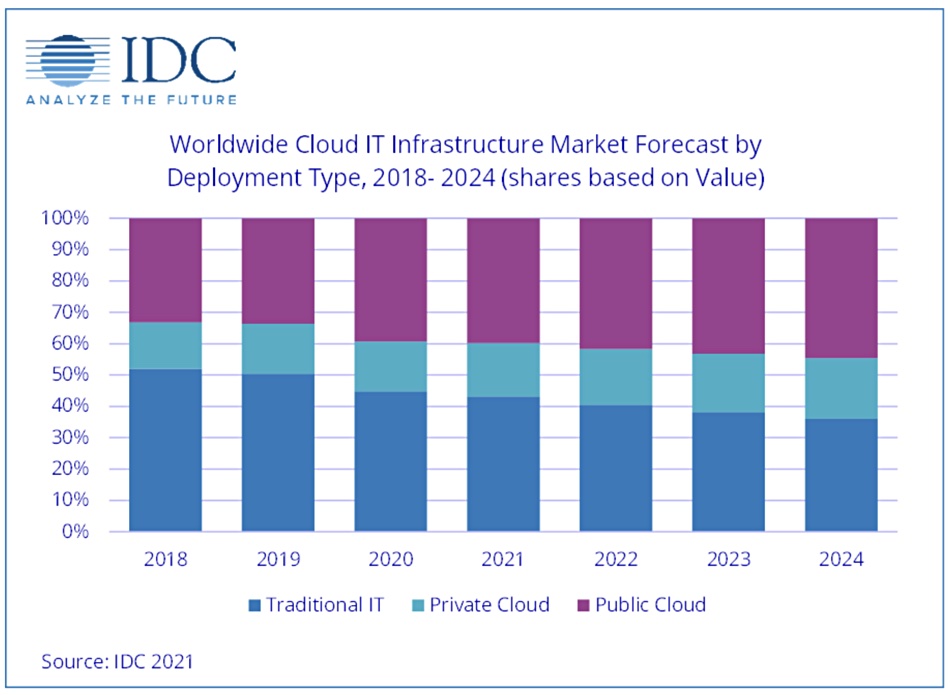
Revenues derived from sales IT infrastructure products to public and private cloud environments grew 9.4 per cent Y/Y in the third quarter of 2020, according to IDC number-crunchers. At the same time vendor revenues from in traditional, non-cloud, IT infrastructure fell 8.3 per cent over the period.
IDC tots ups vendor revenues for servers, enterprise storage, and Ethernet switches for this quarterly report. The tech analyst firm said the pandemic has caused a massive global IT adjustment and it has detected massive shifts to online tools. Fast growing use cases include collaboration, virtual business events, entertainment, shopping, telemedicine, and education. Cloud environments, and particularly the public cloud, are a key enabler of this shift, IDC said.
Spending on public cloud IT infrastructure increased 13.1 per cent year over year in 3Q20, reaching $13.3bn. Spending on private cloud infrastructure increased 0.6 per cent Y/Y to $5.0bn with on-premises private clouds accounting for 63.2 per cent of this amount. IDC expects public cloud IT infrastructure spending to expand its lead going forward.
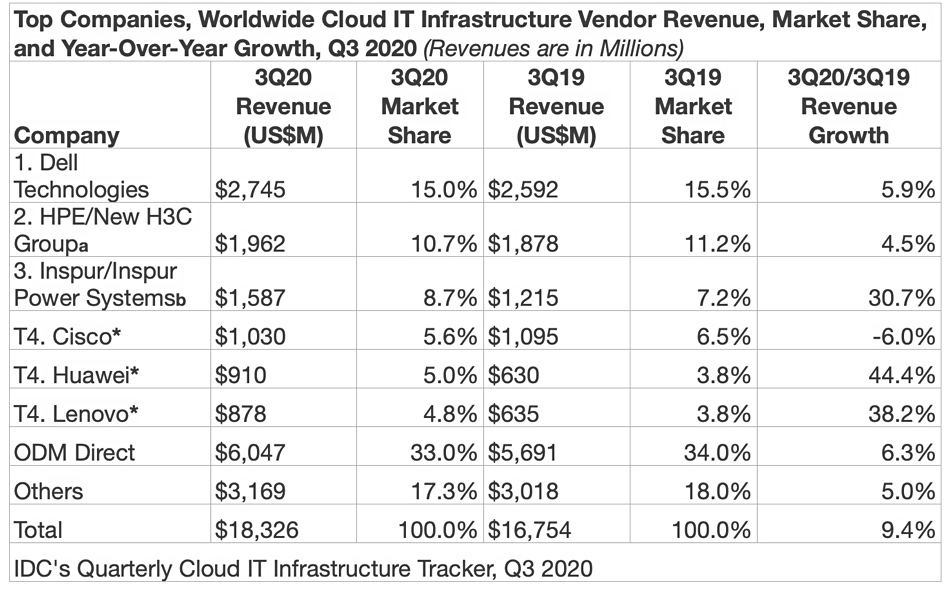
IDC has also provided a table that showsgsupplier revenues and market shares in the quarter. The results were mixed. Inspur, Huawei, and Lenovo had double-digit year-over-year growth while most other major vendors, including the ODM Direct group of vendors, had single-digit growth. Cisco was the only major vendor with a year-over-year decline.
The USA’s National Highway Traffic Safety Administration (NHTSA) wants Tesla to recall 158,000 Tesla Model S and X vehicles, in order to replace a flash storage unit that wears out too quickly and blanks the rear-view camera on the video screen dashboard.
Some screen management functions are handled by the car’s media control unit (MCU) which includes a Nvidia Tegra 3 processor and integrated 8GB eMMC flash memory drive with a 3,000 Program-Erase endurance rating.
The MCU displays the rear-view camera image on the car’s dashboard screen and is fitted to Model S vehicles manufactured in 2012 – 2018 and Model Xs I built in 2016 – 2018. This screen area is also active in windscreen defogging and defrosting control, the autopilot system and various driver signals and alerts.
All these functions fail when the MCU NAND wears out, the NHTSA wrote in a letter to Tesla, dated 13 January. “During our review of the data, Tesla provided confirmation that all units will inevitably fail given the memory device’s finite storage capacity.”
“At a daily cycle usage rate of 1.4 per block, accumulation of 3,000 P/E cycles would take only 5-6 years. Historically, the expected life of a vehicle generally far exceeds 5-6 years of service.”
Tesla predicted the “replacement rates for MCU failures will peak in early 2022 and gradually decline until (near) full part turnover has been accomplished in 2028.”
The company has not yet commented on the NHTSA recall letter. However, it issued a UK warranty update notice in November 2020: “For customer peace of mind, we are providing additional coverage on some Model S and Model X vehicles built before March 2018 that are equipped with an 8GB embedded MultiMediaCard (“8GB eMMC”) in the media control unit.”
Tesla said it would “repair or replace the 8GB eMMC free of charge at any Tesla Service Centre” if the affected vehicle was less than eight years old or had accumulated less than 100,000 driven miles. The repair includes fitting the vehicle “with an enhanced, 64GB eMMC to restore original functionality of the touchscreen.”
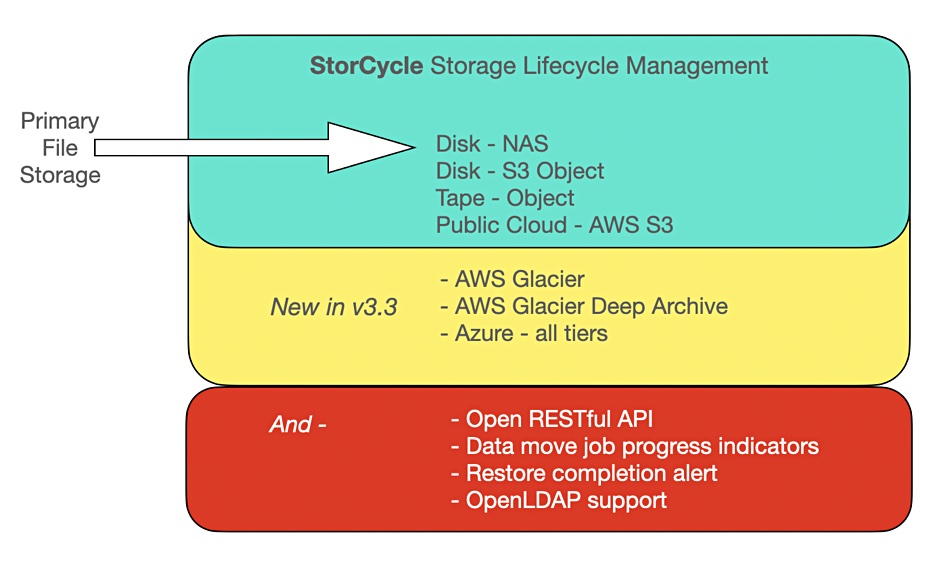
Spectra Logic has upgraded its StorCycle file lifecycle management software, with V3.3 adding support for Azure, more AWS S3 tiers, and improved workflows.
StorCycle takes ageing files from expensive primary storage and moves them to cheaper bulk storage. These could span on-premises NAS format disk filers and S3 format object stores. SpectraLogic object format tape vaults and Amazon’s public cloud S3 store. The software also restores archived data.
Jeff Braunstein, a Spectra Logic product manager, wrote in a blog post: “The new functionality makes it easier than ever for customers to migrate their data off of expensive primary storage and manage it effortlessly throughout its lifecycle so that it remains available and protected to provide long-term value to organisations.”
Moved file data retains its original format. This means applications can continue to access the data even though it resides in slower access repositories.
StorCycle v3.3 additions.
StorCycle 3.3 supports standard hot, cold and archive tiers in Azure. Files migrated to AWS’s S3 tier can now be tiered off to S3 Glacier and/or Glacier Deep Archive for lower-cost retention.
Users can get real time migration and data move progress indicators – this is useful as large data movements can take many minutes. They can also receive an alert when a data restoration job completes.
Data movements and the tiering work are programmable through an open RESTful API interface. Users can code custom workflow commands and integrations with StorCycle. Braunstein suggests these “commands might be used for actions such as bulk creation of storage locations, scripting of migrations that first require actions of other systems, and allowing user restores through a separate web portal.”
StorCycle 3.3 is available now to supported users. New users can buy StorCycle as stand-alone software or paired with Spectra hardware.
From time to time, vendors publish their Net Promotor Score (NPS) as a way to trumpet how great they are – and by extension how much better they are than their competitors.
For example, Nutanix, in an undated but presumably old blog post titled ‘Nutanix Blows Away Industry Net Promoter Scores‘, proclaimed that “Omega Management Group recognized 35 companies for “Delivering World-Class Customer Service” in 2013. Nutanix was honored to be included in this elite group of companies.”
To drive home the point, author Steve Kaplan wrote: “A high Net Promoter Score is notoriously difficult to obtain. Apple, for example, despite their reputation for sterling customer service received a +42 last year. The dominant virtualization player, VMware, received a +48. Dell achieved a very respectable +37. EMC garnered a +28 and NetApp a +25. And Nutanix? A whopping +73 (and it’s now over 80). The next highest on this list of 60 tech vendors was Intel with 53.”
Since then Nutanix’ score has risen to 90 and a spokesperson said it: “has been 90 for several years.”
So how well does NPS capture a snapshot of a company’s reputation with customers? And what do those numbers mean? Let’s take a look.
NPS mechanics
The Net Promoter Score is a number from -100 from 100. The idea was developed by a Fred Reichheld, presented in a Harvard Business Review article in 1993, and subsequently adopted by Bain & Company and Satmetrix.
Scores above 0 are generally thought good and ones above 50 excellent. An organisation runs a survey of a supplier’s customers and asks one question: how likely on a scale of 0 (not at all) to 10 (extremely likely) to recommend the supplier to their peers.
NPS Scoring scheme.
A score between 0 and 6 is classed as a detractor. A 7-8 score represents a passive customer while a 9 – 10 score signals a customer who will promote the supplier to their peers.
The actual NPS score value is obtained by subtracting the percentage of 0 to 6 responses (detractors) from the percentage of 7 – 10 responses (promotors) and presenting this as a number between -100 and +100.
Here is a small sample of recent NPS’s in the data storage industry.
Cohesity attained a +100 NPS score in January 2020. A company spokesperson said its NPS rating is: “currently in the low 90s, but I don’t think it’s dropped below 90 in two years.”
Pure Storage said that, for the sixth year in a row, it scored an NPS in the top 1 per cent of Medallia benchmarked B2B scores. A spokesperson told us it uses NPS data to actively improve customer experience through direct feedback and address specific customer pain points.
Actionable insights
In 2018 HPE interviewed its own customers. Dr. James Borderick, who led the Net Promoter Competitive Loyalty program at HPE Software at the time, said: “The numerical NPS value does not really matter. What matters is the actionable insight that you have learned, and where you stand relative to your competitors.” The company did not reveal its own NPS score.
According to Pure, an independent third party should validate or certify the supplier’s NPS That way a spread of customers can be surveyed and not just a supplier’s own subset.
“Pure’s audited score, based on the Medallia platform, was more than twice the B2B average of 40,” it says, “and the highest among Medallia B2B scores in 2019. Specifically, we’re pleased to announce an Owen CX certified score of 82, as Pure has scaled to receiving nearly 1,000 surveys in the last year. “
NPS issues
An obvious problem for a supplier publishing NPS scores is what to do if the score goes down. Another is that the customers providing promoter ratings for a supplier may not actually promote the supplier to their peers at all.
This was discussed in a 2019 Harvard Business Review article, “Where Net Promoter Score Goes Wrong.” Christina Stahlkopf, a research analyst at C Space, an agency looking at suppliers’ customers, wrote: “We’ve come to believe that NPS offers mostly broad strokes, akin to a compass pointing companies in the right direction. This is not to say we think it’s irrelevant. A compass is still a helpful tool… Sometimes, what the compass indicates is the best direction to follow actually isn’t once you take into account the on-the-ground terrain.”
The “promise of NPS was elusive” for many companies, according to Stahlkopf. C Space’s study of 2000 consumers in the USA and UK found “52 per cent of all people who actively discouraged others from using a brand had also actively recommended it… Consumers who had both actively promoted and actively criticised the same brand.”
“While enthusiasts are happy to extol the virtues of a brand they love, that doesn’t mean they like every product in the lineup.”
Another finding: “50 per cent of customers in our … survey were promoters, but 69 per cent of customers had actually recommended a brand. So the NPS categorisation missed a big chunk of the actual promoters.”
Stahlkopf concludes:“We think that companies would do better with a framework that focuses on customers’ actual behaviour.”
SK hynix, the Korean memory chip maker, has issued a $1bn green bond to help clean up its manufacturing act.
Water management is extremely critical in the semiconductor industry, according to the company, which intends build a state-of-the-art wastewater disposal plant and a water recycling system. The bond cash will also help pay for energy efficiency improvements, pollution prevention, and ecological environment restoration. (The Register has more to say about the water treatment in semicon manufacturing here.)
SK Hynix is a member of RE100, an industry initiative that commits participants – they include Chanel, Apple, Starbucks and TSMC – to move to 100 per cent renewable electricity. This is a tough ask for the Korean vendor.
The SK group of companies, which includes SK Telecom, collectively consumes 31 terawatts of electricity a year, amounting to five per cent of South Korea’s entire electricity energy use. One group company, SK Holdings, is aiming for 100 per cent renewable energy use by 2030 while the other group companies are giving themselves 20 years more, and looking at 2050. They say that it is currently impossible to make the switch to renewable electricity, without a renewable power supply certificates system in place in the market.
The Korean government is launching Korea Renewable Energy Guarantees of Origin this month. It has pledged that the country, the world’s seventh largest CO2 emitter, will achieve net zero emissions by 2050. and says disk replacement by SSDs could cut disk-based carbon emissions by 93 per cent.
SK hynix said in November, it wants to replace disk drives with SSDs which emit up to 93 per cent less carbon through electricity use, according to the company. This is basically telling customers not to buy Seagate, Toshiba and Western Digital disk drives because they harm the environment much more than SSDs. Also, while you’re at it, buy SSDs from SK hynix, a company with has great green credentials.
A green bond is used to fund projects that have positive environmental and/or climate benefits. Issuers must track, monitor and report on use of proceeds. The benefits include a positive marketing story with a supplier’s so-called green assets and green business activities being highlighted. A green bond supplier can also widen their investor base to include specialist ESG (Environmental, Social, Governance) and Responsible Investors.
Scality today announced it has bagged $20m in new financing – and said this is enough to fund it to profitability.
The object and file storage startup’s CEO, Jerome Lecat told us: ‘It is a mix of capital and debt, with a mix of existing and new investors. We are not sharing the detail because this is not what matters. What matters is that it makes the company independent from external forces on the financial markets, and that we are really proud of our business results during a really complicated year: more new customers than last year, revenue growth, significant geographic expansion, and lots of product development.”
“We feel really good about our 2020 results, and excited at the prospect of 2021.”
Scality will spend the money on R&D, customer support and sales. Prior to today, the company has raised $152m in equity finance, including $60m in a E-series round in 2018.
“With Scality now funded to profitability, this new financing gives the company the push it needs to continue on its long-term, rapid growth curve. Along with its impressive growth last year, Scality came much closer to profitability in 2020 and, with this new investment, we anticipate the company will reach profitability in 2021,” Jason Donahue, board chairman of Scality, said.
Scality revenues grew 30 per cent in 2020, according to the company which said it experienced the biggest fourth quarter revenue results in its 10-year history. Customer spend grew the most in 2020 in all-flash file and object storage systems, as well as S3 hybrid deployments across the big three public clouds.
The company also proclaimed continuing strength in its HPE alliance and highlighted reseller agreements signed in 2020 with Supermicro and Western Digital.
GigaIO announced yesterday it is using silicon from Microchip in its FabreX PCIe 4.0 network fabric to dynamically compose server systems and share memory, including Optane, between servers.
FabreX is a unified fabric, intended to replace previously separate Ethernet, InfiniBand and PCIe networks. It’s all PCIe, and this lowers overall network latency as there is no need to hop between networks.
Alan Benjamin
GigaIO CEO Alan Benjamin said in a statement: “The implication for HPC and AI workloads, which consume large amounts of accelerators and high-speed storage like Intel Optane SSDs to minimise time to results, is much faster computation, and the ability to run workloads which simply would not have been possible in the past.”
The main rationale of composability is that server-attached resources such as GPUs, FPGAs or Optane Persistent Memory, are stranded on their host server and may not be in use much of the time. By making them shared resources, other servers can use them as needed, and so improve their utilisation. GigaIO is small California startup that competes with composability system suppliers such as DriveScale, Fungible and Liqid.
FabreX
FabreX dynamically reconfigure systems and enables server-attached GPUs, FPGAs ASICs, SoCs, networking, storage and memory (3D XPoint) to be shared as pooled resources between servers in a set of racks. The fabric supports GDR (GPU Direct RDMA), MPI (Message Passing Interface), TCP/IP and NVMe-oF protocols.
GigaIO composability scheme
GigaIO supports several composability software options to avoid software lock-in. These include open source Slurm (Simple Linux Utility for Resource Management) integration; automated resource scheduling features with Quali CloudShell; and running containers and VMs in an OpenStack-based Cloud with vScaler. The management architecture is based on open standard Redfish APIs.
Microchip
Microchip provides Switchtec silicon for GigaIO’s PCIe Gen 4 top-of-rack switch appliance. This has 24 non-blocking ports with less than 110ns latency – claimed to be the lowest in the industry. Every port has a DMA (Direct Memory Access) engine. The appliance delivers up to 512Gbits/sec transmission rates per port at full duplex, and will soon scale up to 1,024Gbits/sec with PCIe Gen 5.0.
The switch provides direct memory access by an individual server to system memories of all other servers in the cluster fabric, for the industry’s first in-memory network. This enables load and store memory semantics across the interconnect.
Scoop!Veritas has bought HubStor, a Canadian backup and archive vendor, gaining itself a SaaS-based data protection development team. Terms are undisclosed.
Ontario-based HubStor was founded in 2015 by CEO Geoff Bourgeois and CTO Gregg Campbell, and its 21 employees have developed a unified backup and archive to the cloud as-a-service. The service supports Azure file and Blob storage, Box, Google Drive and VMware vSphere.
The entirely bootstrapped company is customer-funded through recurring – and growing – subscription revenues. Bourgeois told us: “HubStor proved it could build a SaaS product. Veritas will take it to the next level.”
Simon Jelley, general manager for Veritas Backup Exec, EndPoint Protection and SaaS Protection, told us: “It’s a great union and it’s about how we bring our enterprise-data services to the cloud.”
Geoff Bourgeois (left) and Gregg Campbell
Hubstor’s team will work in Jelley’s organisation inside Veritas. Bourgeois said: “HubStor was a highly profitable business with a substantial software platform and very strong customer adoption. We did not need to sell. Veritas made it compelling and we felt it was a strong win for our customers, and that Veritas would do an amazing job realizing the full potential of what we built in the years ahead.” We can expect integration efforts between Veritas software and Hubstor’s technology.
Was this an acqui-hire? Bourgeois says not. Yes, Veritas is acquiring the team but the acqui-hire term is generally used to refer to buying a a technology company primarily for its people and not its technology or products; not the case here.
Veritas is a veteran data protection business that faces the prospect of customers migrating to cloud-based rivals such as Clumio, Commvault Metallic, Druva, Cohesity and Rubrik.
A Druva executive who declined to be named because he was not authorised to speak to the press said Veritas’s purchase of Hubstor “is yet another validation of the popularity of the DPaaS (data protection-as-a-service) market, as well as how hard it is to get started in it.”
Bourgeois has stints at Iron Mountain, Mimosa and Autonomy on his CV, after which he joined startups ExchangeSavvy and Acaveo as a board member and CTO respectively. Campbell was also a board member at ExchangeSavvy and Chief Architect at Acaveo. He also spent time at Mimosa, Iron Mountain and Autonomy.