


I spoke recently to Michael Tso, Cloudian CEO, about the consequences of exabyte-level object stores. Exabyte-level data egress from the public cloud could take years, he told me, and cost a million dollars-plus in egress fees. There’s lock-in and then there’s throwaway the key lock-in.
Supercomputers are already approaching exascale, meaning compute exaflops and also, quite likely, storage at the exabyte level. How far behind are enterprise installations?

Cloudian has “multiple customer sites designed for Exabyte scale,” Tso said. “Not all are at the exabyte level yet but we have one knocking at the door.”
Customers will not arrive at the exabyte level in one go, according to Tso. Consider this: an exabyte of capacity entails buying, deploying and managing one million 10TB disk drives (HDDs), 500,000 x 20TB HDDs or 750,000 14TB drives. There will be a continuous need to add new capacity, physically deliver, rack-up, cable, power and cool, and bring on-line disk chassis.
There will be drives of different capacities in the population, because drive capacities rise over time, and different drive types, with SSDs, also in different capacities, added to disk drives as fast object stores become needed. The system will be multi-tiered.
It will therefore be crucial to ensure that the management of disk drive populations of 500,000 drives and up is practicable – no-one wants to spend their days removing failed drives and adding new ones. On-premises management difficulties will scale up enormously unless drive-level management approaches are superseded.
Disk failures and upgrades
In a population of 500,000, some drives will inevitably fail. For example cloud backup storage provider Backblaze in 2019 reported a 1.89 per cent annualised HDD failure rate with a population of 122,507 drives. That translates into 2,316 drives failing over the course of the year, about six or seven each day. Scale this example to 750,000 drives and 14,175 drives will fail in a year, about 39 per day.
It gets worse. You will need to add new drives as well as replace failed ones. Tso said: “The data will outlive the hardware. The system will be continuously renewing. You will be continuously adding new hardware.“
Storage at that scale is constantly upgrading. If your exabyte data store is growing at 1PB per week, you will be adding 50 drives a week. If it grows at 1PB a day then you will add 50 HDDs and replace 39 failed drives every day.
These illustrations show that it is not possible to manage exabyte data stores at the individual drive level. They store must managed at multiple-drive, chassis levels. Hold that thought while we look at data gravity.
Public cloud data gravity
Suppose you have an exabyte of S3 object storage in Amazon, or as blobs in Azure. You decide the cost is too great and you want to repatriate it. How long will it take and how much will it cost in egress fees?
Tso provided a data migration time taken vs network speed table.
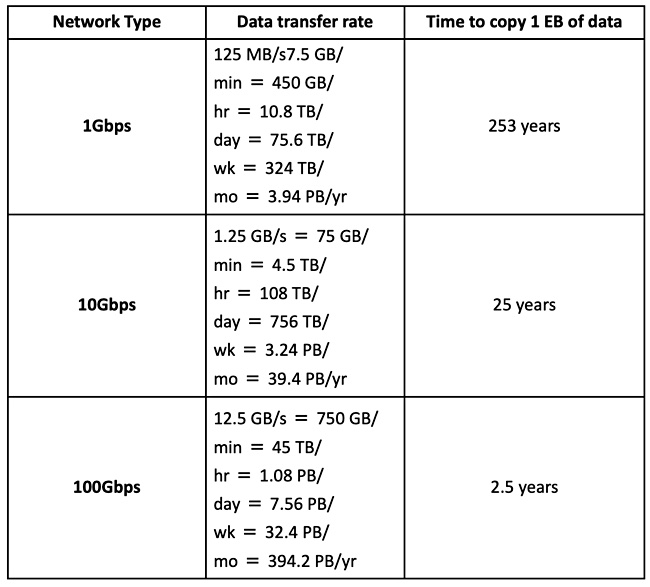
It will take two-and-a-half years using a 100Gbit/s link, and an astonishing 25 years with a 10Gbit/s link. And the egress fees will be astronomical.
With Azure, outbound (egress) charges can be reduced by using Azure’s Content Delivery Network (CDN), with an example cost of $0.075/GB in a rate band of 10 – 50TB/month. Let’s apply that price to moving 1EB – one million GB – out of Azure. It will cost $1.5 million, a ransom on its own.
“At that [exabyte] scale a customer’s data is not that portable,” says Tso. “When people have more than 10PB of data, data migration is not a topic; it’s not possible…. It’s data gravity…[after a certain size] gravity dictates everything.”
Customers looking to move data out of the cloud may well find it impossible, due to the time and cost reasons above. They may cap their cloud data level and start storing data on-premises instead. One extra reason for doing this could involve keeping data private to prevent potential cloud service provider competition.
Whatever the reasoning, it means they have two classes of stores to manage and software to do it.
Management
Tso argues that managing exabyte-scale object stores will require AI and machine learning technologies. Here’s why.
At the exabyte level, the storage software and management facility has to handle continuous upgrading and multi-tier storage. The software must cope with drive failures, without internal infrastructure rebuild and error-correction events taking up increasing resources. It has to manage multiple tiers such as flash, disk tape; multiple locations on-premises and in the public cloud; and protection schemes,such as replications and erasure coding. And do this all automatically.
Tso offers this thought: “For EB scale, how cluster expansions are managed is critical. Nobody starts off with an EB of data but rather grows into it, so starting smaller and scaling up is a key challenge that needs to be addressed.
He says there are two approaches; either a single physical pool of nodes\disks, which he and Cloudian support, or having islands of object storage.
The islands approach means “storage HW resources are deployed in domains determined by the erasure coding stripe size (e.g., EC 4+2 would need 6 nodes).
“At expansion time, you would need to add a new domain of nodes (6 nodes in this example)… Data written to a storage domain stays on those disks forever (until deleted of course). Write IOPs are limited to the amount of free HW resources which is probably the new nodes that have just been added (again, 6 nodes in this example). In short, write performance will never scale beyond the amount of nodes in a single domain.”
The single pool approach means: “All storage HW resources are grouped in a single logical cluster, and data requests are load balanced across all nodes\disks in the cluster. The object storage platform uses algorithms to balance data evenly across all nodes in the cluster to deliver resilience, scalability and performance.”
From drives to chassis
Blocks & Files thinks that the management software will need to work at the drive chassis level and not at the drive level. Managing 750,000-plus drives individually will become impossible. This means that the single pool approach that Tso supports would need to be modified to embrace islands.
It would be simpler for the management software to look after 75,000 chassis, each containing 100 drives, than 750,000 drives. Each chassis would have a controller and software looking after the drives in its box. But even that may be too much. We could end up with groups of chassis being managed as a unit – say 10 at a time – which would mean the management software now looks after 7,500 clusters of drive chassis.
Toshiba (KumoScale), Seagate (AP 5U84), and Western Digital (OpenFlex) are each building chassis with multiple drives, and it would be unsurprising if they are also developing in-chassis management systems.
A final thought. this article looks at 1EB object storage, but exabyte-level file storage is coming too, and possibly exabyte block storage also. Data storage will soon move up to a whole new level of scale and complexity.
N.B. X-IO tried to develop sealed chassis of disk drives, ISE canisters, between 2010 and 2014 but the technology foundered. Perhaps it was a few years ahead of its time.





