


In-memory data supplier Hazelcast is adding storage drive persistence and better SQL support in a v5.0 release, so it can be used to unify processing of real-time streaming data, transactional, operational and analytic workloads.
Hazelcast’s software, clustered across server nodes, is not a database, data warehouse or datalake. It is not a SingleStore equivalent. Instead, it has connectors to products such as MongoDB, Redis Labs and Snowflake, so they can execute against in-memory datasets. Think of it as a MemVerge-type offering.
John DesJardins, CTO of Hazelcast, said in a canned statement: “The addition of persistence and production-ready unified SQL support directly correlates to the desire of our customers to merge multiple workloads, while gaining the performance and reliability of in-memory technologies.”
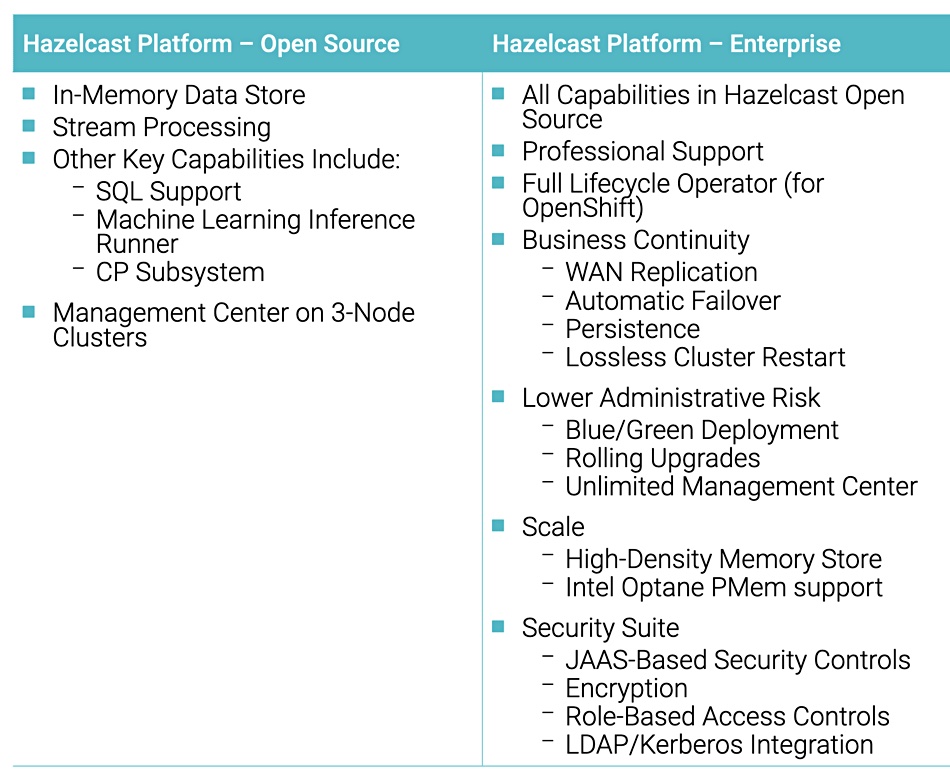
The basic Hazelcast offering is open-source software (limited to three nodes), but it is also available in an “Enterprise” edition with bells and whistles. This v5.0 upgrade has had a branding change and is now called the Hazelcast Platform.
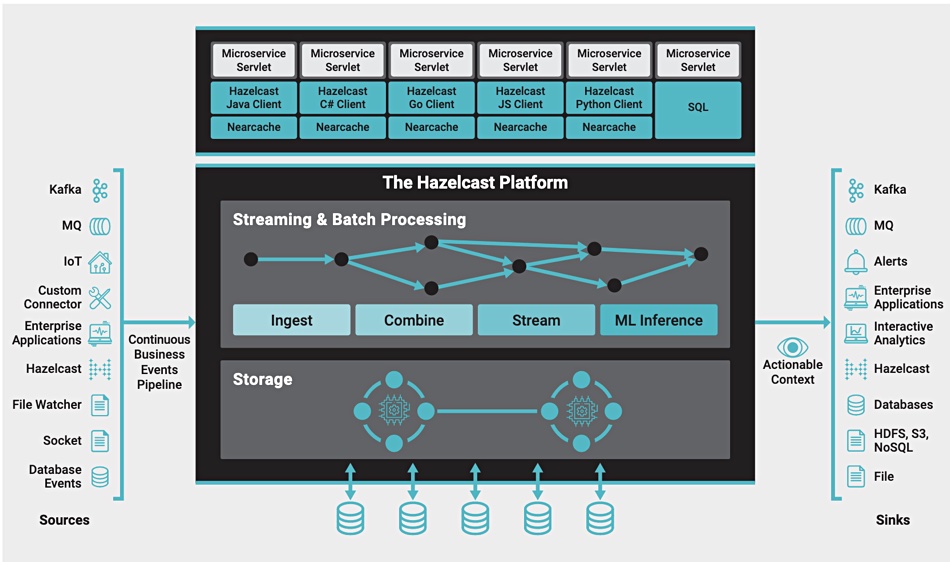
Hazelcast says its v5.0 Platform software combines the capabilities of a real-time stream processing engine with in-memory computing, and enterprises can unify event streams with the context of traditional data sources such as databases and data lakes. The streaming engine is able to pre-process data as it is ingested, while the in-memory compute can analyse and act upon the insights in real-time. Customers can combine historical data, event data and file-based data with a single query, with microsecond latency.
SQL improvements and persistence
The Hazelcast Platform’s SQL engine now supports basic data manipulation language (DML) functionality to enable INSERT, UPDATE and DELETE on data in Hazelcast. It adds sorting, aggregations and new SQL expressions. Users can use SQL to declaratively ingest data from messaging systems like Kafka or files and object storage such as S3, insert it into an IMap, and execute streaming queries and computations also via SQL.
By adding disk and SSD support, Hazelcast provides greater uptime for any individual cluster member. Customers can use it to restore data after an unexpected crash, as well as reduce maintenance and migration windows to improve availability. The customer can control the recovery time window as needed — holding off the cluster rebalancing process, for example, if a short-term maintenance window is needed.
If a Hazelcast server cluster member is being transferred to another server, the persistence files let customers restart the member at the new location using the existing data without the need for full data shuffling.
Other v5.0 additions include fine-grained security controls for the stream processing engine. The Management Center has been unified to manage and monitor streaming and data store jobs, and gets an upgraded user interface for simplified management of Hazelcast clusters.
The Hazelcast Platform is available today in beta, with the expectation that it will be generally available in August 2021. The same features will also be available through Hazelcast Platform for IBM Cloud Paks as part of the Hazelcast and IBM OEM partnership announced last year.
Users will be able to upgrade seamlessly from 3.x and 4.x versions of Hazelcast. Check out a datasheet here.





