Analysis: GenAI is washing through the IT world like water flooding across a landscape when a dam breaches. It is being viewed by many suppliers as an epoch-changing event, similar to the arrival of the internet, and feared by some as a potential dotcom bubble-like event.
Be that as it may, IT storage is being strongly altered by AI, from the memory-storage interface upward, as the rising tide of GenAI lifts all storage boats. A look at the storage world reveals six ways GenAI is transforming the world of block, file, and object storage.
At its lowest level, where storage systems talk to a server’s memory, the arrival of Nvidia GPUs with their high-bandwidth memory (HBM) has put a premium on file storage system and array controller processors and their DRAM just getting out of the way, and letting NVMe flash drives connect directly to a GPU’s memory to transfer data at high speed using remote direct memory access and the GPUDirect protocol.
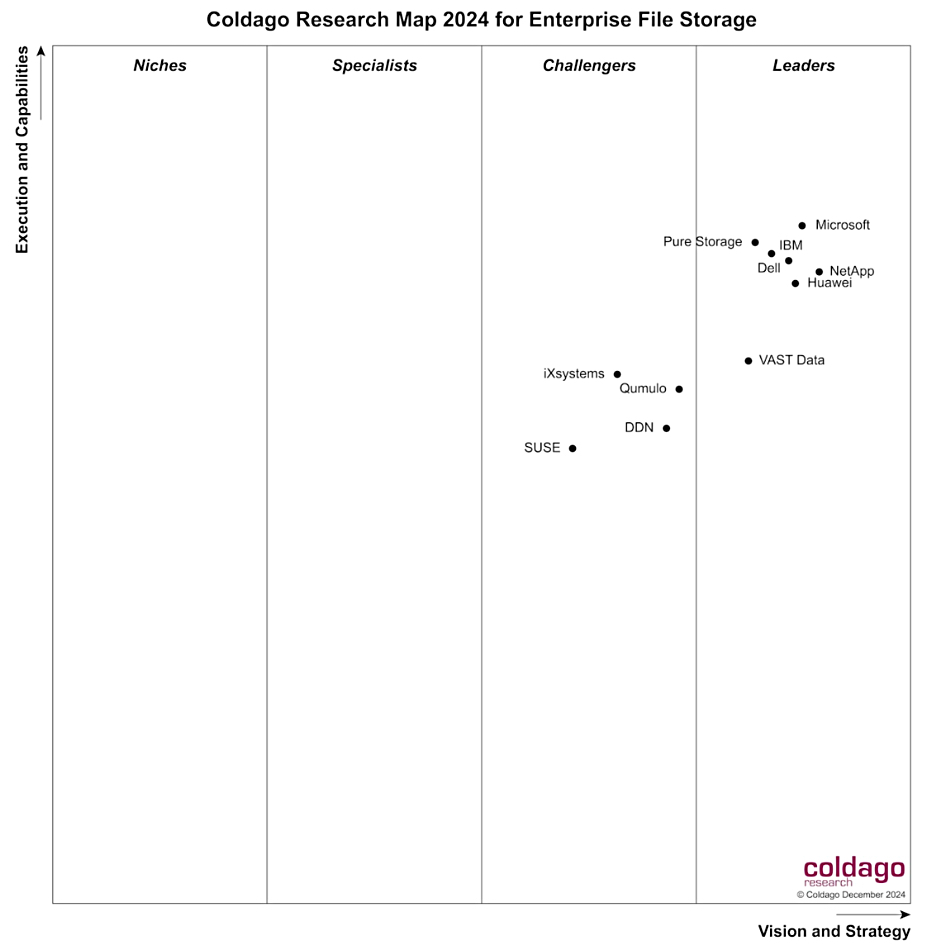
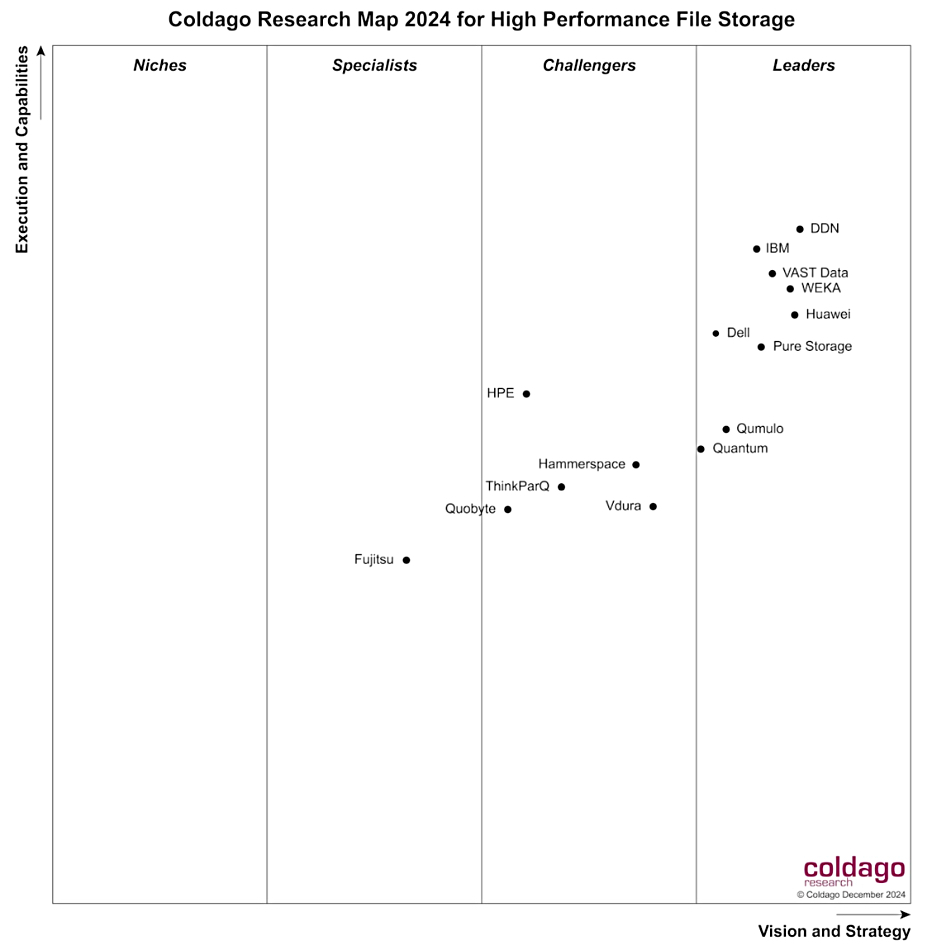
DapuStor, DDN, Dell, Huawei, IBM (Storage Scale), NetApp, Pure Storage, VAST Data, WEKA, YanRong, plus others such as PEAK:AIO and Western Digital (OpenFlex) are active here. Even Nutanix aims to add GPUDirect support.
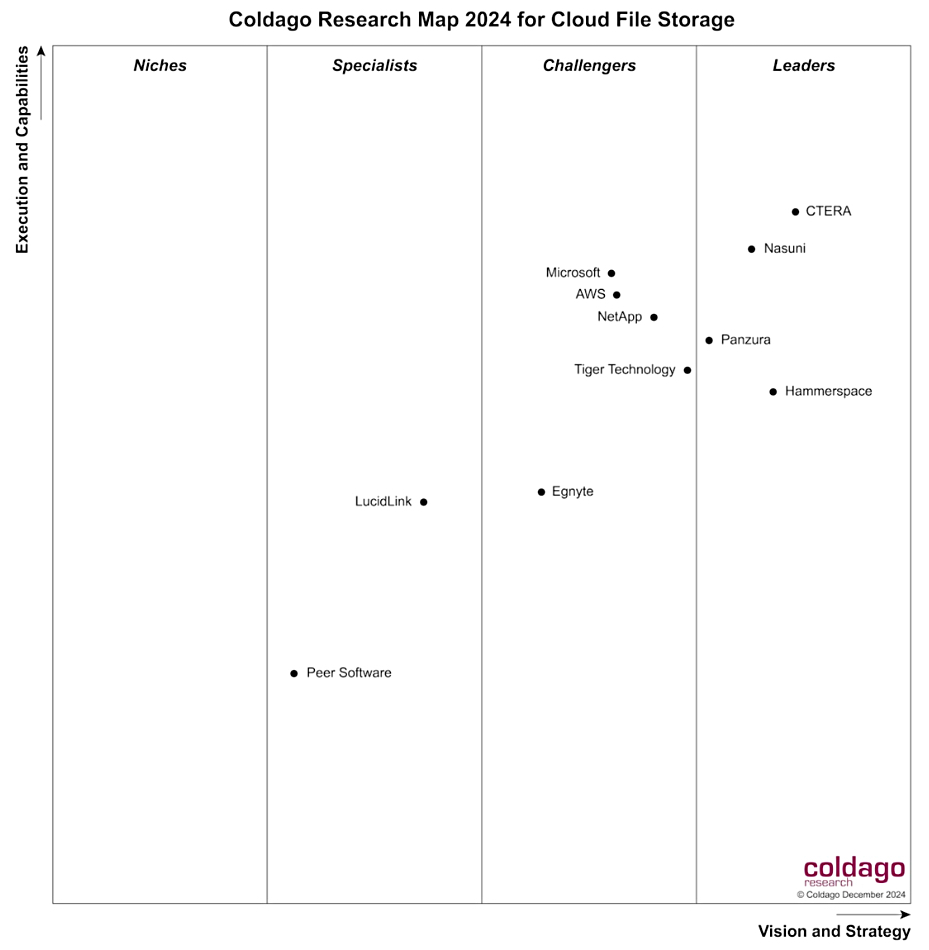
This style of unstructured data transfer is being extended to object storage so the petabytes of reserved data can be freed up for use in AI training and subsequently inferencing as well, when performed by GPUs. See the news from Cloudian, MinIO, and Scality in recent months.
Storage media manufacturers are reacting to GenAI too. The SSD manufacturers and NAND fabricators are recognizing that GenAI needs fast read access to lots of data, meaning they must produce high-capacity drives, 62 TB and, more recently, 123 TB SSDs, using affordable QLC (4bits/cell) 3D NAND. GenAI training also needs fast job checkpointing to enable quicker training job restarts.
Solidigm recognized this need early on with its 61.44 TB D5-P5336 drive in July 2023 and has been followed by Micron, parent SK hynix, and Samsung. Phison has also entered this market, matching Solidigm’s latest 122 TB drive with its own Pascari D205V 122.8 TB.
We will probably see news of double that capacity by late this year or early 2026. The use of hard disk drives (HDDs) for AI training is not happening. They are too slow and the drives too limited in capacity. Where GPUs are used for AI inferencing, SSDs will certainly be the storage choice as well, for the same speed and capacity reasons, and that will likely be true for x86 servers too. It’s likely that AI PCs, if they take off, will all be using SSDs and not HDDs for identical reasons.
What this means is that HDDs will only be used for GenAI secondary storage and, so far, that has not happened to any significant degree. Seagate, Western Digital, and no doubt Toshiba are pinning their hopes of HDD market expansion on GenAI data storage needs, and seem confident it will happen.
The tape market has not been directly affected by GenAI data storage needs at all, and likely will not be.
At levels above drive media in the storage stack, we have block array, filer, and object storage systems. The filer suppliers and, as we saw above, object storage suppliers have nearly all been affected by enabling GPUDirect access to their drives. Several have built AI-specific systems, such as Pure Storage’s Airi offering. Dell, VAST Data, DDN, WEKA, and others have shown sales increases by having Nvidia SuperPOD certification.
With GenAI chatbots being trained on unstructured data and transformed into vector embeddings, no GPUDirect-like access has been provided for block storage, which is critical for transactional databases and ERP systems.
There is activity in the Knowledge Graph area to enable such data to be made available for AI training, like in the cases of Graphwise and Illumex.
Storage array and data platform suppliers are all transforming their software to support the addition of proprietary and up-to-date unstructured data to augment AI inference by GenAI’s large language models (LLMs) trained on older and more general data. Such data has to be vectorized and the resulting vectors stored in a database for use by the LLM in retrieval-augmented generation (RAG).
Existing non-RDBMS database, data warehouse, and data lake suppliers are adding vector storage to their products, such as SingleStore. Database startups like Pinecone and Zilliz have developed specialized vector databases, promising better performance and enhanced support for LLMs.
The data warehouse and lakehouse vendors are in a frenzy of GenAI-focused development to be the data source for AI training and inference data. The high point of this was Databricks getting a $10 billion VC investment late last year to continue its GenAI business building evolution.
A fifth storage area affected greatly by GenAI is data protection, where vendors have realized that their backup stores hold great swathes of data usable by GenAI agents. Vendors like Cohesity, Commvault, and Rubrik are offering their own AI agents, like Cohesity’s Gaia, and also developing RAG support facilities.
In general, no data store vendor can afford to ignore RAG as it’s presumed all data stores will have to supply data for it. Supplying such data is not as simple as giving API access to an LLM and stepping aside, letting the model extract whatever data it needs. An organization will generally have many different data stores and enabling their contents to be appropriately filtered, excluding totally private information or data below an accessing LLM’s access privileges, will need the GenAI equivalent of an extract, transform (into vectors) and load (ETL) pipeline setup.
Data management and orchestration suppliers like Arcitecta, Datadobi, DataDynamics, Hammerspace, and Komprise are all playing their part in mapping data sources, providing a single virtual silo, and building data pipelines to feed the data they manage into LLMs.
Data storage suppliers are also starting to use GenAI agents inside their own offerings to help with support, for example, or to simplify and improve storage product administration and security. This will affect all suppliers of storage systems and AIOps will be transformed by the use of GenAI agents; think agentic AIOps. For example, Dell has its APEX AIOps software that is available in its PowerStore and other arrays.
The cyber-resilience area will need to withstand GenAI agent-assisted malware attacks and will certainly use GenAI agents in building responses to such attacks.
We are going to see the ongoing transformation of the storage world by GenAI throughout 2025. It seems unstoppable and should, aside from malware agents, be beneficial.