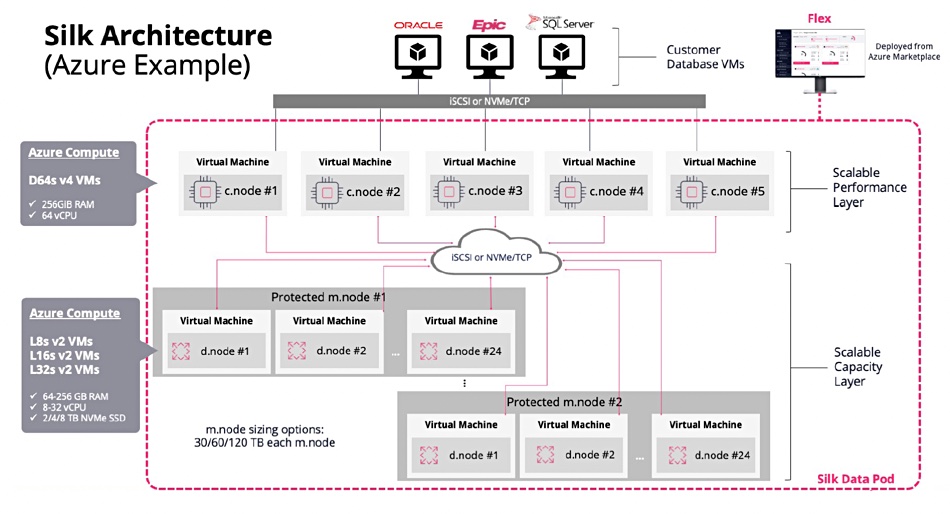
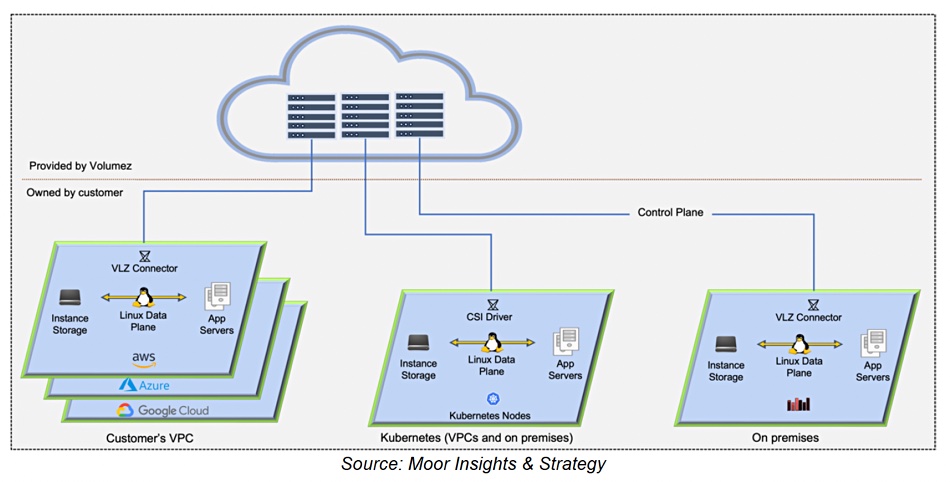
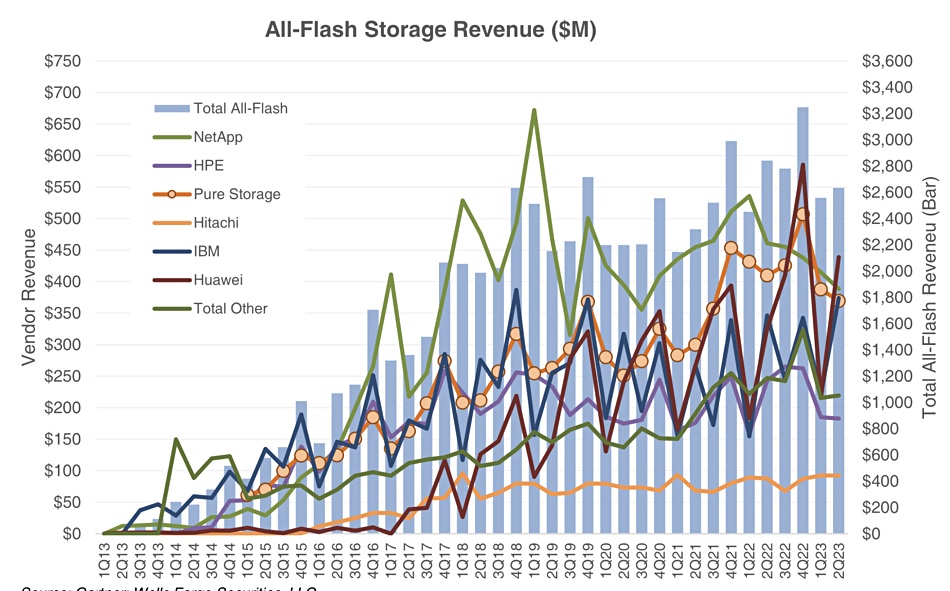
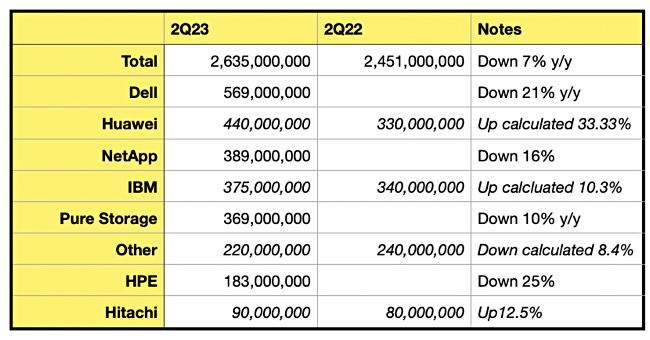
Dell is hoping a splash of generative AI can loosen wallets and shift more of its software, server, storage and ultimately PC sales.
It’s made three moves in the space in recent days, appointing ISG head Jeff Boudreau as CAIO – Chief AI Officer; bringing out customizable validated gen AI systems and services; and yesterday pushing the narrative as hard as it can with securities analysts.

At the securities analysts meeting Michael Dell claimed: “We are incredibly well-positioned for the next wave of expansion, growth and progress. … AI, and now generative AI, is the latest wave of innovation and fundamental to AI are enormous amounts of data and computing power.”
This is set to increase Dell’s server and storage revenues such that its forecast CAGR for ISG, its servers and storage division, is increasing from the 3 to 5 percent range declared at its September 2021 analyst day to a higher 6 to 8 percent range. The PC division, CSG, CAGR stays the same as it was back in 2021 – 2 to 3 percent.

Wells Fargo analyst Aaron Rakers tells subscribers that the ISG CAGR uplift has been driven by factors such as a ~$2 billion order backlog (significantly higher pipeline) for its AI-optimized XE9680 servers exiting the second fiscal 2024 quarter. This is the fastest ramping server in Dell’s history.

AI servers, which have a 3 – 20 x higher $/unit value than traditional PowerEdge servers, should account for ~20 percent of the next quarter’s server demand. CFO Yvonne McGill said the XE9860 has a <$200k ASP, about 20 times more than the ordinary PowerEdge server.
Vice chairman and COO Jeff Clarke claimed Dell’s AI will enable its total addressable market (TAM) to grow by an incremental $900 million from 2019 to 2027, growing from $1.2 trillion to $2.1 trillion.
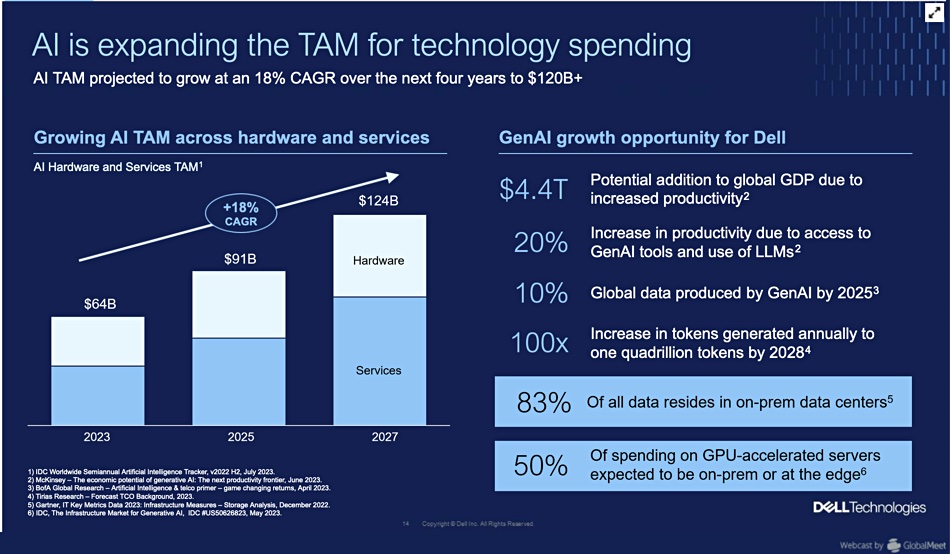
Data is growing at a +25 percent CAGR. Most companies’ data, 83 percent of it, is stored on premises, not in the public cloud, and represents a tremendous asset for AI processing. Dell thinks it could mean a 20 – 30 percent productivity and efficiency improvement for industries and economies. Some 10 percent of data could be produced by AI by 2025.
As data has gravity it expects AI processing will move to the data location point, ie, on-premises in data centers and edge sites. He thinks 50 percent of the spending on GPU-accelerated servers will be for data center or edge site location.
We are, Dell believes, in the starting phase of a significant AI demand surge. Clarke said gen AI is set to be the fastest-ever adopted technology, with 70 percent of enterprises believing AI will change the rules of the game, and 60 percent thinking AI will change the core fundamental cost structure of their organizations and change their product delivery innovation.
There are four emerging use cases: customer experience, software development, the role of sales. and content creation and management.
ISG president Arthur Lewis said leverage its market share lead in servers, with Dell capturing 43 percent of the growth in servers over the past 10 years, plus 38 percent of new industry storage revenue over the past 5 years. Dell, he said, has seen eight consecutive quarters of growth in midrange PowerFlex and 12 consecutive quarters of growth in PowerStore. ISG is focusing on higher margin IP software assets and next-generation storage architectures, such as PowerFlex (APEX Block Storage).
CSG President Sam Burd said AI will also be a positive PC demand driver. It AI promises immense productivity benefits for PC users and could be as revolutionary as the early PC days. In 2024 Dell will have PC architectures that will effortlessly handle more complex AI workloads, with on-board AI processing becoming the norm in the future.
Dell validated AI solutions
This AI-infused thinking presented to the analysts is what lies behind yesterday’s validated AI solutions announcement. Carol Wilder, Dell ISG VP for cross-portfolio SW, tells us Dell realizes AI has to be fueled with data. That means there has to be a unified data stack using an open scale-out architecture with decoupled compute and storage and featuring reduced data movement; data has gravity. Data needs discovering, querying and processing in-place. Customers will be multi-cloud users and will want to store, process, manage, and secure data across the on-premises data center and edge and also public cloud environments.
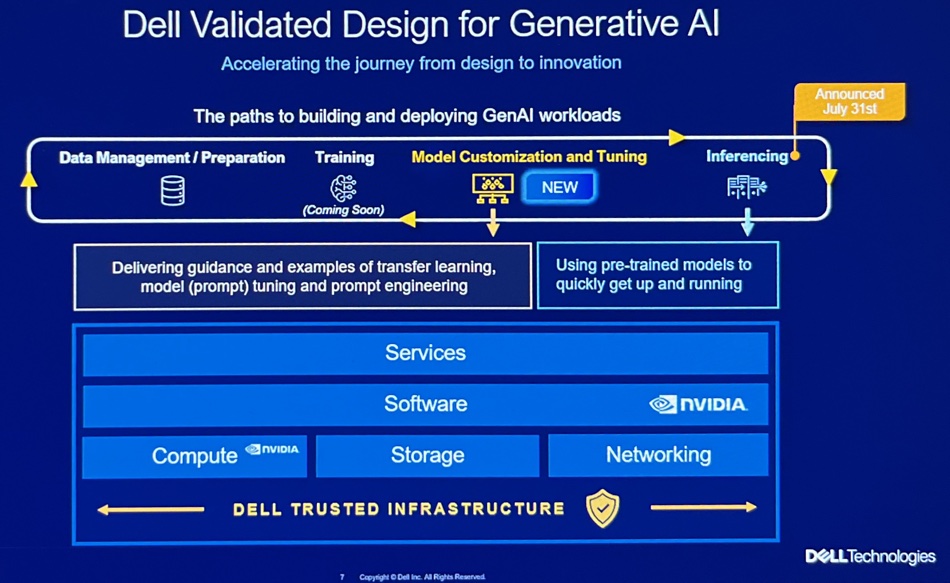
Customers are beginning gen AI adoption and the HW/SW stack is complex, hence Dell’s announcement of validated AI systems along with professional services services to help ease and simplify customers’ AI system adoption.
Looking ahead Wilder told us customers’ AI activities will be helped by giving the AI processing systems the widest possible access to data, and that means a data lakehouse architecture, with data integrated across the enterprise, and Dell will provide one. A slide shows its attributes and says it uses the Starburst Presto-based distributed query engine, and supports Iceberg and Delta lake formats.
Naturally it uses decoupled Dell PowerEdge compute and storage; its file (PowerScale) and object (ECS) storage.
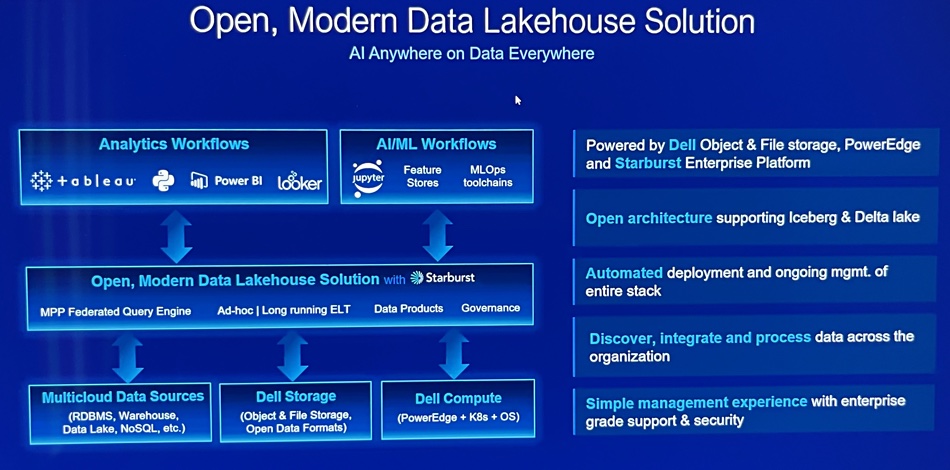
It will make data available first, to high-performance engines, and consolidate it later. We think there could be an APEX lakehouse service coming in the future.
Comment
Dell will be providing a lakehouse datastore to its customers. So far, in our storage HW/SW systems supplier world, only VAST Data has announced an in-house database it’s built for AI use. Now here is Dell entering the same area but with a co-ordinated set of server, storage, lakehouse and professional services activities for its thousands of partners and its own customer account-facing people to pour into the ears of its tens of thousands of customers. That’s strong competition.
No doubt Gen AI will enter Gartner’s Trough of Disillusionment, but Dell Technologies is proceeding on the basis that it will be a temporary shallow trough, transited quickly to the Slope of Enlightenment, with Dell’s AI evangelizing army pushing customers up it as fast as possible.









")