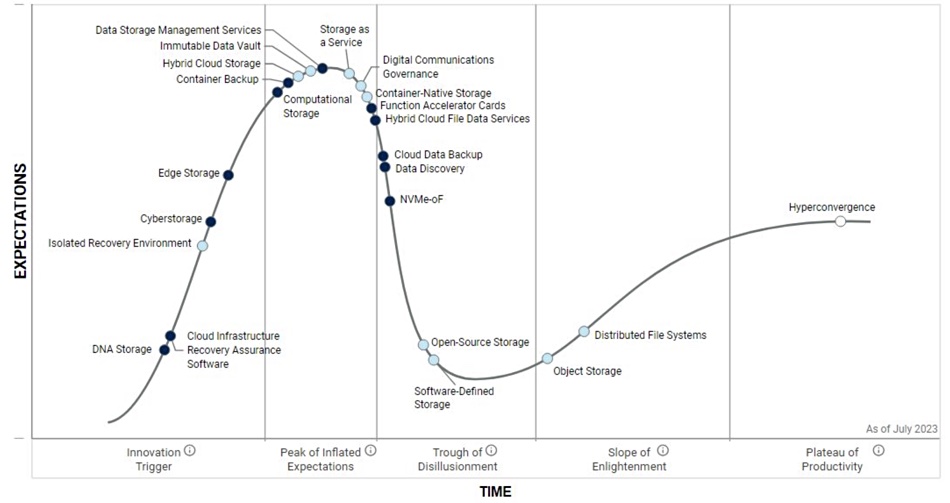
Comment: Research house Gartner has published its 2023 storage hype cycle, highlighting the evolving landscape of various technologies in the industry, and some have dropped completely out of sight.
The hype cycle serves as a five-stage technology progression chart, starting with an Innovation Trigger phase, followed by a Peak of Inflated Expectations, a Trough of Disillusionment, a Slope of Enlightenment, and finally reaching a Plateau of Productivity.
Gartner Research VP Julia Palmer, who shared the update on LinkedIn, said: “It’s like having a roadmap to navigate through the hype and identify the most promising innovations.” You need to log into a Gartner account to see it in detail. Here we present a screen grab of the highlights:
Technologies on the chart are represented by dot colors: dark blue indicates 5 to 10 years to reach the plateau, light blue represents two to five years, and a white dot indicates less than two years to plateau.
Upon initial analysis, some placements seem unusual. For instance, NVMe-oF should likely be positioned further to the right, and the positions of object storage and Distributed File Systems could potentially be exchanged.
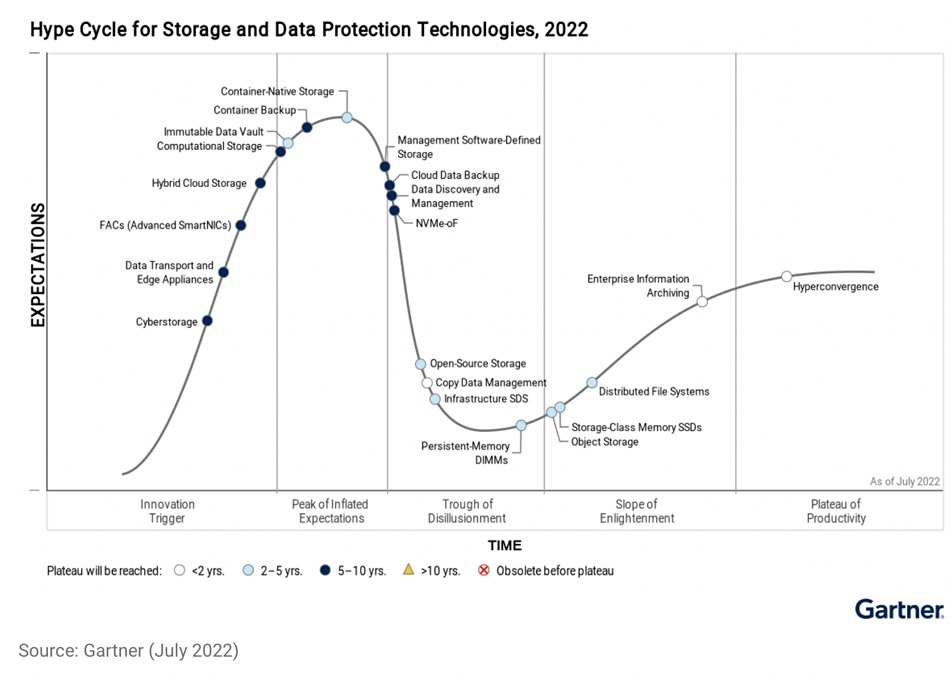
Flash Memory Summit organizer Jay Kramer pointed out some notable omissions from the chart, including Storage Class Memory, Multi-Cloud, and Converged Infrastructure. Here’s last year’s storage hype cycle chart:
Storage Class Memory was rising up the Slope of Enlightenment in 2022 but faced setbacks after Intel discontinued Optane. However, technologies like SCM-class SSDs, MRAM, and RERAM continue to be developed. Notable trends from last year’s storage hype cycle include the disappearance of Copy Data Management, Enterprise Information Archiving, Persistent Memory DIMMs, and Management Software-Defined Storage.
Hybrid Cloud File Data Services have come from nowhere and are now descending the Trough of Disillusionment. There is no entry for CXL, which is expected to play a significant role in storage products. Additionally, we believe that Data Orchestration and SaaS Application Backup deserve a place on the chart.
While the storage hype cycle can be an intriguing insight into the industry’s evolving landscape, it should perhaps be regarded as a fun and less formal representation of the market’s evolution.
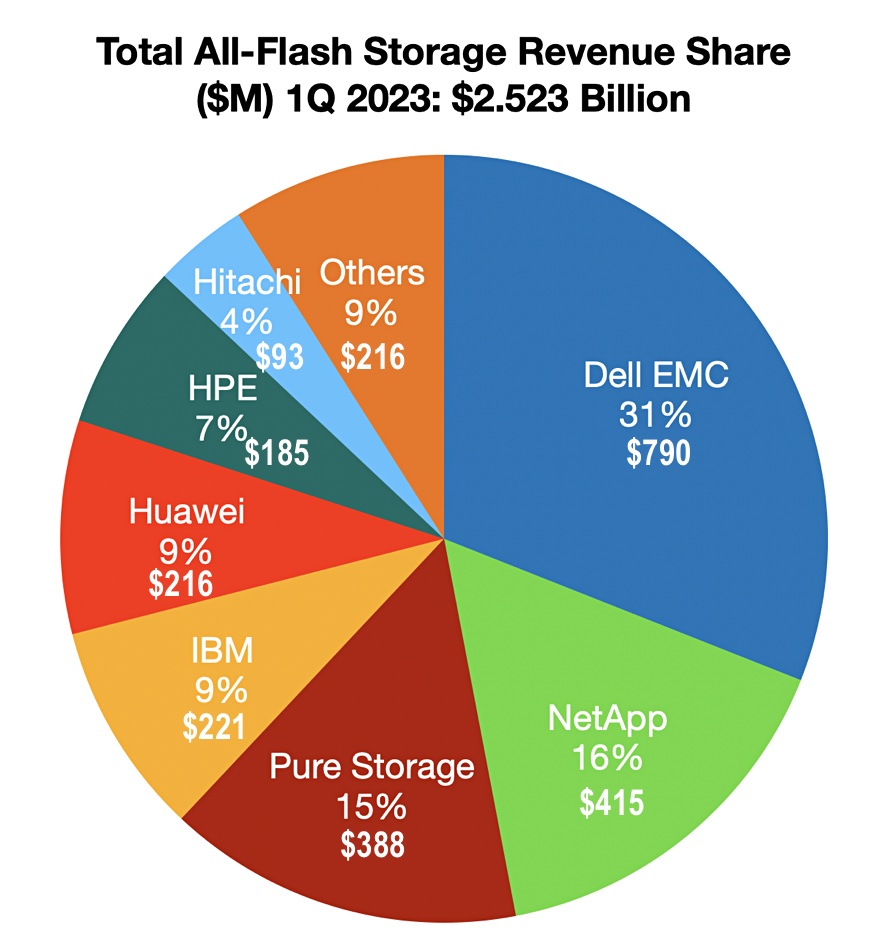
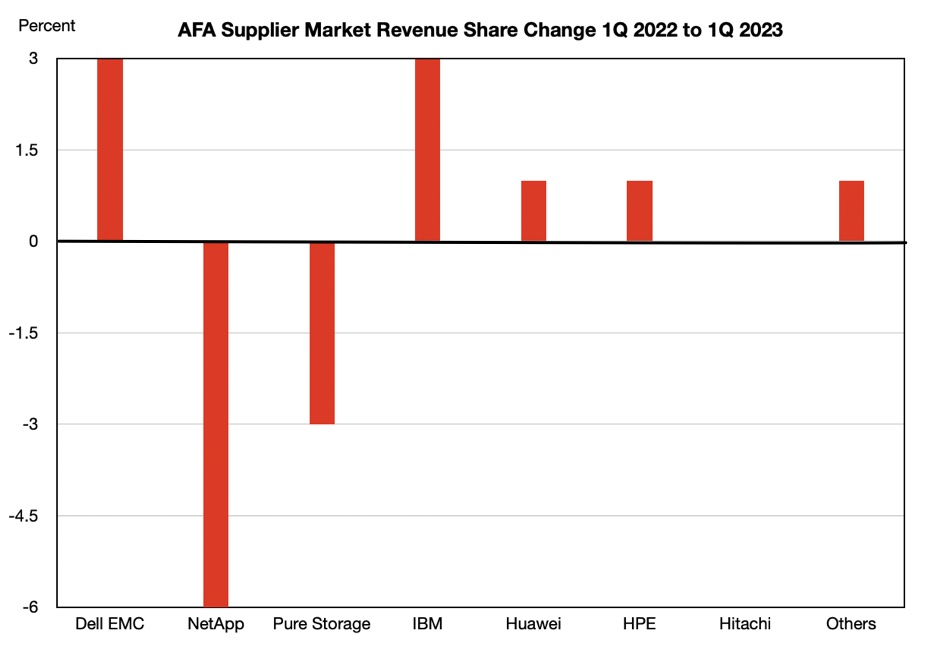
In its latest storage market review for the first quarter of 2023, Gartner reports that both NetApp and Pure Storage experienced a decline in market share.
The total all-flash market reached $2.523 billion, representing 50.4 percent of the overall storage market in monetary terms, with a year-on-year growth of 4 percent. However, it was down 22 percent compared to the previous quarter. Flash storage accounted for 31 percent of the total capacity shipped, marking a significant increase from the prior quarter’s 18.2 percent and a notable rise from the 16.8 percent recorded a year ago.
The supplier revenue shares are shown in a pie chart compiled by Gartner:
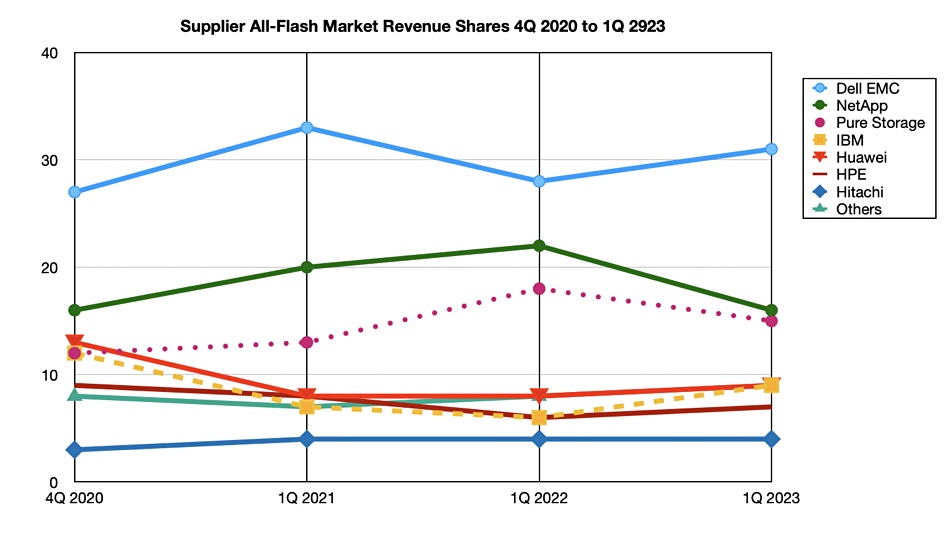
According to Wells Fargo analyst Aaron Rakers, Dell’s flash revenue rose by 17 percent year-on-year and 12 percent quarter-on-quarter, while HPE’s all-flash revenue also saw a 17 percent year-on-year bounce. However, Pure Storage’s revenue suffered a decline of 10 percent year-on-year and a substantial 24 percent plunge quarter-on-quarter, leading to a decrease in its market share from 17.7 percent a year ago to the current 15.4 percent in the all-flash array (AFA) market.
Rakers further mentioned that Pure Storage’s all-flash capacity share of 624EB increased by 5 percent year-on-year, but remained unchanged compared to the previous year at 4.7 percent.
While there is no detailed insight into the share changes of other suppliers, prior data from B&F articles indicates that NetApp’s market share dropped from 22 percent a year ago to 16 percent in Q1 2023. Pure Storage’s share also experienced a decline, although not as significant, meaning it narrowed the gap with NetApp. IBM, on the other hand, has been catching up with Huawei and is gradually distancing itself from HPE.
Among the Y/Y revenue share gainers were Dell EMC, IBM, Huawei, HPE, and the “Others” category. These changes in revenue share have been charted to illustrate their magnitude.
Overall, both NetApp and Pure Storage lost share to other players in the market.
The rest of the storage market
As for the total storage market, Gartner reports that it was worth a little more than $5.005 billion, showing a modest one percent year-on-year growth. Primary storage increased by one percent year-on-year, while secondary storage and backup and recovery rose by 4 percent and 9 percent, respectively.
Hybrid flash/disk and disk revenues declined 2 percent year-on-year. The total external storage capacity shipped experienced a 24 percent year-on-year growth, with secondary storage capacity witnessing a massive 70 percent increase, backup storage rising by 18 percent, and primary storage capacity seeing a modest 3 percent rise.
Managed infrastructure systems provider 11:11 Systems has joined the AWS Partner Network (APN) and will offer customers 11:11 Cloud Backup for Veeam Cloud Connect, 11:11 Cloud Backup for Microsoft 365, and 11:11 Cloud Object Storage.
Vitali Edrenkine.
…
Data protector Arcserve has appointed Vitali Edrenkine as its chief marketing officer (CMO). Edrenkine was most recently SVP Growth Marketing at Vendr, and prior to that, he worked as SVP of Demand Generation and Digital Platforms at DataRobot. Prior to that he was at Rackspace.
…
Catalogic’sCloudCasa for Velero is now available in the Microsoft Azure marketplace. CloudCasa is a cloud-native, data protection service that also fully supports Velero and detects and alerts on vulnerabilities in Kubernetes clusters.
…
Dell is recommending customers use Cirrus Data block migration with its Dell APEX-as-a-Service to move block data to the APEX block service, which is based on PowerFlex. Cirrus claims Dell APEX customers with Cirrus Data can perform block data migrations 4 to 6x faster than traditional approaches, meaning public cloud migration tools (see Azure and AWS) and specific vendor storage tools. The transfer uses thin reduction; data is compressed, and all zeros are eliminated. One Cirrus Data claimed a customer moving 9PB of data from AWS’ EBS to Dell PowerFlex realized savings of $3.2 million annually; 60% less than what they were paying for raw native storage.
…
DataCore’s Swarm object storage has been certified as a backup target for v12 Veeam Backup & Replication and v7 Veeam Backup for Microsoft 365.
…
Dell says it has enhanced PowerProtect Data Manager and PowerProtect Data Manager Appliance, PowerProtect Cyber Recovery and PowerProtect DD Operating System. The vendor lists the features below:
Customers can directly back up PowerStore data to PowerProtect DD. PowerProtect Data Manager provides volume and volume group snapshot backups directly to PowerProtect appliances from PowerStore arrays using the Data Manager UI.
PowerProtect Data Manager adds Recovery Orchestration for VMware VMs.
Customers can vault data from the Data Manager Appliance to a PowerProtect DD-based cyber vault on-premises or in cloud, facilitating orchestrated recovery checks and the restoration of backup and appliance configuration data.
Dell has added retention lock compliance on the Data Manager Appliance.
Customers can replicate data to/from the cloud using PowerProtect DD Virtual Edition on-premises or APEX Protection Storage for Public Cloud for AWS, Azure, Google Cloud and Alibaba Cloud.
PowerProtect DDOS includes Smart Scale workload management with automatic identification and inclusion of affinity groups when performing migrations between appliances.
PowerProtect DDOS updates have support for KVM VirtIO disks with PowerProtect DD Virtual Edition and enhanced cloud security of APEX Protection Storage for Public Cloud with support for retention lock compliance on AWS.
Storage Scale eBook.
…
IBM has claimed a performance breakthrough with up to 125GBps per node throughput (from 91GBps) via the Storage Scale System 3500 that scales to 1000s of parallel access nodes. It has improved caching performance and added automated page pools to enhance the system’s ability to provide more balanced and improved performance for AI applications. Read a Storage Scale eBook to find out more.
…
Marvell QLE2800 HBA.
Marvell says it’s the provider of the quad-port FC target host bus adapters (HBAs) in the HPE Alletra Storage MP hardware. The QLogic QLE2800 HBA has port isolated architecture and is capable of delivering up to 64GFC bandwidth and support concurrent FC-SCSI and FC-NVMe communications. It includes support for virtual machine identification (VM-ID), automatic congestion management using Fabric Performance Impact Notifications (FPIN) and enhanced security with encrypted data in flight (EDiF) that HPE can potentially use in the future.
…
Cloud file services supplier Nasuni is integrating Microsoft’s Sentinel security information and event management (SIEM) platform, with its offering. It allows customers to automatically spot threat activity and immediately initiate the appropriate responses. Microsoft Log Analytics Workspace gathers and shares Nasuni event and audit logs at any Nasuni distributed Edge device for constant monitoring with the Sentinel platform. Nasuni also has new targeted restore capabilities for its Ransomware Protection service.
…
HPC and AI storage supplier Panasas has listed some academic customers for its ActiveStor products: the Minnesota Supercomputing Institute (MSI), the UC San Diego Centre for Microbiome Innovation (CMI), LES MINES ParisTech, and TU Bergakademie Freiberg state technical university in Germany and Rutherford Appleton Laboratory in the UK. According to Hyperion Research, total HPC spending in 2022 reached $37 billion and is projected to exceed $52 billion in 2026.
…
SSD controller developer Phison says it has found a way of having its controlled SSDs hold AI application data that would otherwise be in DRAM, compensating for DRAM being expensive and consequently not fully specified for AI-processing servers. Based on the application timeline, Phison’s aiDAPTIV+ structurally divides large-scale AI models and collaboratively runs the model parameters with SSD offload support. This approach maximizes the executable AI models within the limited GPU and DRAM resources, which Phison claims reduces the hardware infrastructure cost required to provide AI services.
…
Swiss-based Proton has launched Proton Drive for Windows, a secure, end-to-end encrypted cloud storage app that offers users a way to sync and store their files to Proton Drive cloud storage right from their Windows device. Like Dropbox it ensures that files and folders are always up-to-date across all connected devices. Any changes made to files on a Windows PC will be automatically reflected on a user’s other devices that have Proton Drive installed.
…
Scale-out filer supplier Qumulo announced GA of Azure Native Qumulo Scalable File Service (ANQ) in 11 new regions: France Central, Germany West Central, North Europe, Norway East, Sweden Central, Switzerland North, UK South, UK West, West Europe, Canada Central, and Canada East.
…
RightData announced DataMarket, a user-friendly way to act on all data within an organization, including understanding definitions, viewing metadata, control access, and direct access to APIs, connectors, and natural language-based data analysis. Data consumers can use natural language search to find out about data products, see quality ratings and reviews. Users can then request access and use the data through its provided API, JDBC connectors, downloads, or the rendering of data visualizations directly within the DataMarket.
…
Serve The Home reportsSabrent has a Rocket X5 PCIe gen 5 M.2 2280 form factor SSD in development. It has 1TB and 2TB capacity points and is packaged with a fan-driven heatsink. The 2TB model so far delivers >14GBps sequential reads and 12GBps sequential writes. These numbers would put the X5 on a par with Kioxia’s read-intensive CM7-R.
…
Samsung has an automotive UFS 3.1 NAND with 128, 256 and 512-GB variants product for in-vehicle infotainment (IVI) systems and satisfying the negative 40°C to 105°C temperature requirements of AEC-Q100 Grade2 semiconductor quality standard for vehicles. The 256GB model provides a sequential write speed of 700MBps and a sequential read speed of 2,000MBps. Samsung claims the product offers the industry’s lowest energy consumption.
…
SMART Modular’s DC4800 data center SSD, in E1.S and U.2 formats, has been accepted as an OCP Inspired product and will be featured on the OCP Marketplace. It’s is a PCIe gen 4 connected drive available in capacities up to 7.68TB.
…
The SNIA’s Storage Management Initiative (SMI) announced that SNIA Swordfish has achieved a milestone with the publication of Swordfish v1.2.4a by ISO/IEC as ISO/IEC 5965:2023. The new ISO/IEC-published version replaces ISO/IEC 5695:2021, with the addition of functionality to manage NVMe and NVMe-oF.
…
SuperWomen in Flash today shared figures from a recent study by the National Center for Women & Information Technology (NCWIT), a non-profit community founded in 2004 which is funded by the National Science Foundation:
In the last five years, approximately 10% of U.S. IT patents included women as inventors.
In the US, IT patenting overall increased almost 17-fold between 1980-84 and 2016-2020.
Patents with woman inventors increased 56-fold from 1980-84 to 2017-2020, even as the percentage of women employed in IT either remained flat or decreased slightly.
In 2022, 27% of professional computing occupations in the U.S. workforce were held by women.
In 2022, 23% of total tech C-suite positions in Fortune 500 companies were held by women.
…
UC3400 (top) and SAA3400D (bottom). Looks pretty much like the same hardware with different labels.
Synology has launched two enterprise storage units, the UC3400 and SA3400D, both 12-bay dual-controller devices focused on business continuity. The SA3400D is focused on file and application hosting and provides minute-level failover in case of component failure. It provides more than 3,500/2,900 MBps seq. read/write throughput and 500 TB maximum storage capacity. The UC3400 is an active-active SAN, with in excess of 180,000 4K random write IOPS, and up to 576 TB of storage, for iSCSI & Fibre storage, such as VM storage.
…
Scale-out parallel filesystem vendor WekaIO announced what it terms as two guarantees: the WEKA Half Price Guarantee for cloud deployments; and the WEKA 2X Performance Guarantee for on-premises deployments. The Half Price Guarantee promises the WEKA Data Platform can help cloud customers achieve up to 50 percent cost savings over their current equivalent cloud storage solution with zero performance impact. Its 2x Performance Guarantee says on-prem customers will achieve a 2x performance increase over their all-flash arrays for the same cost. Eligible customers using a hybrid cloud deployment configuration can participate in both schemes. Learn more here.
…
Data protector Veeam has published an AWS Data Backup for Dummies eBook. Get it here.
…
Veritas and Kyndryl have partnered to launch two new services: Data Protection Risk Assessment with Veritas; and Incident Recovery with Veritas. These services will help enterprises protect and recover data across on-premises, hybrid and multi-cloud environments. Data Protection Risk Assessment with Veritas will rely on Kyndryl’s cyber resilience framework and Veritas’ data management solutions to offer unified insights across on-premises, hybrid and cloud environments. Incident Recovery with Veritas will use AI-based autonomous data management capabilities to give customers a fully managed service encompassing backup, disaster recovery and cyber recovery.
…
Phil Venables, CISO at Google Cloud has joined the Board of Directors at identity security company Veza.
…
Tom’s Hardware reports China’s YMTC is manufacturing 128-layer 3D NAND with Xtacking 3.0 technology, which is based on placing the 3D NAND flash wafer underneath a separately fabbed CMOS peripheral circuit logic chip, bonded to it with millions of small connectors. It has previously built its 128-layer NAND with Xtacking 2.0 tech. Xtacking 3.0 was developed for YMTC’s 232-layer chip but US tech export restrictions have halted that product’s development, so back to last generation tech rejuvenated with new peripheral logic. Research house Yole analysts have determined that YMTC’s 232L NAND has two separate components or decks; one with 128 layers and the other 125.
Case study. Oregon Health and Science University (OHSU) researchers in Portland are using cryogenically cooled electron microscopes to build 3D images of biological molecules as they investigate how proteins affect the brain, the COVID virus, serotonin neural processes, ageing and the myriad other aspects of human and other organisms’ biology.
Data from the instruments are stored in a Quobyte file system – chosen when OHSU decided it needed its own local storage rather than relying on an external system provided by the Pacific Northwest National Laboratory (PNNL). The storage system has to support high-performance computing applications used by researchers as well as being a vault for the instrument-generated data.
Craig Yoshioka and cryo-EM equipment.
The OHSU Cryo-EM center has four telephone kiosk-size Titan Krios 300-kiloelectron volt Transmission Electron Microscopes (TEM) to visualize proteins and other biological molecules in 3D and at near-atomic scale. They examine samples cooled down to liquid nitrogen temperature and use high-energy electrons to view their structures down to a resolution of 2.8 Å.
Each Krios has a direct-electron detection camera fitted, and is mounted on a vibration absorbing pad inside its booth to keep its detectors as still as possible. Without this, they would be affected by vibrations as small as that caused by a person’s voice, a breeze, or currents in the adjacent Willamette river.
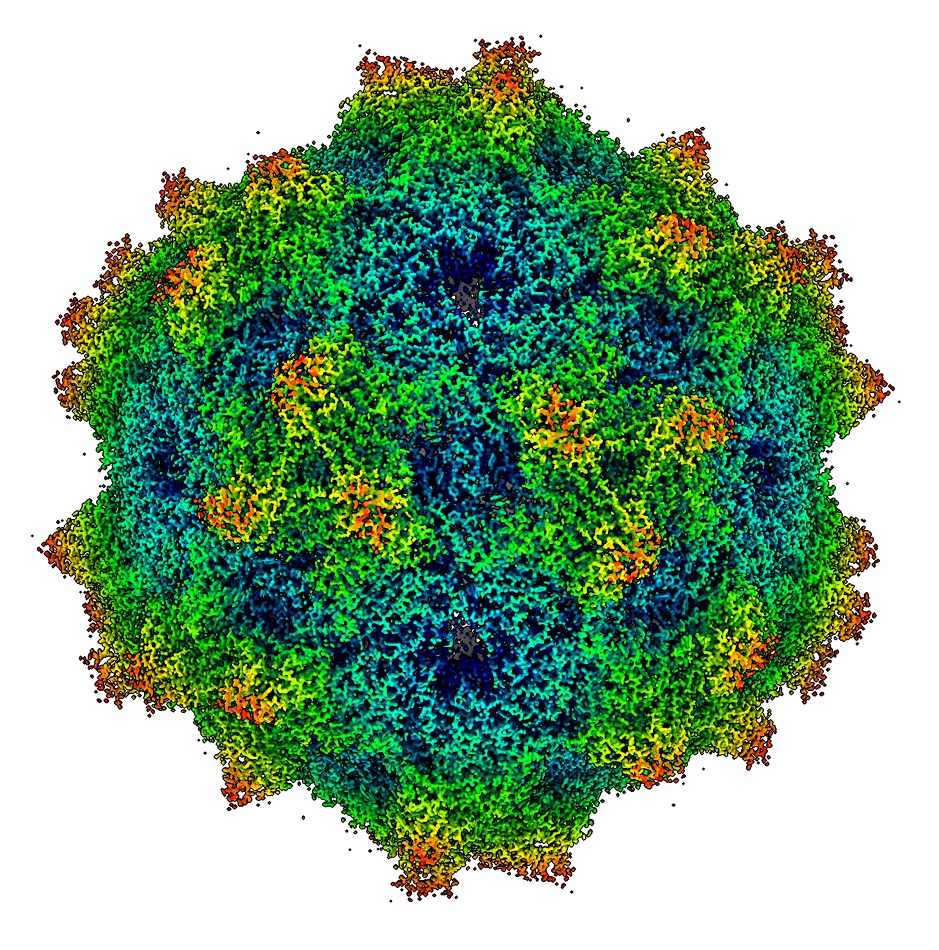
Cryo-EM image of a virus.
OHSU also has other microscopes, such as a Glacios Cryo-TEM, to pre-screen samples before using a Krios to get near-atomic resolution of selected images. Using a multi-million dollar Krios for pre-screening is overkill.
Each Krios generates an average 3TB of data a day, meaning 8 to 16TB/day for OHSU’s cryo-EM facility. We’re looking at around 120TB/week, up to 6.2PB/year, and that data has to be kept for use in the following 12 months or so. A proportion of it may be noise rather than signal, but the researchers may be able to pull out more signals from the noise with better algorithms in the future. So the data is kept.
There are 900 researchers using the cryo-EMs and accessing the data with up to 200 active projects at any given time.
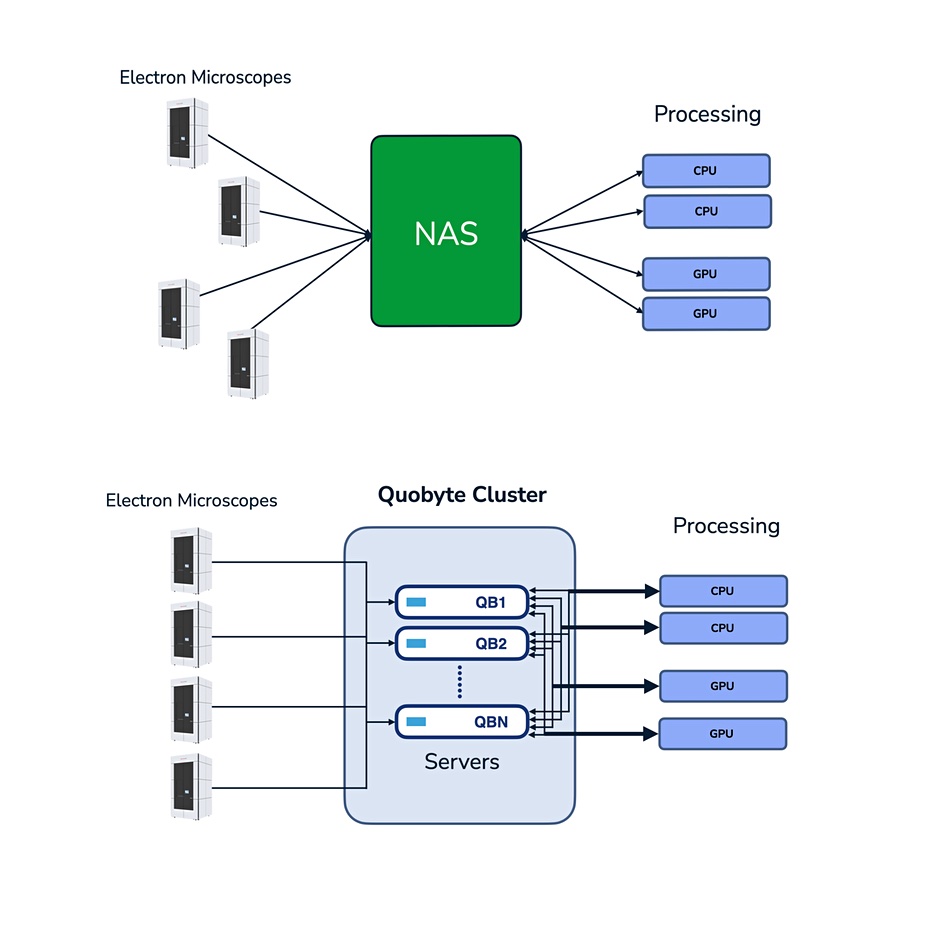
Craig Yoshioka, a PhD and Research Associate Professor at OHSU directs its cryo-EM center. He said the original storage system was based on ZFS running on Linux servers. This could accept the data from the instruments fine, but could be slow at delivering it to the HPC apps.
The possible options he considered for fixing the slowness included simply scaling it up, or moving to a BeeGFS alternative, a Panasas system, a Quobyte cluster setup, VAST Data array, or a WekaIO file system. He specifically wanted a distributed file system accessed via a centralized web interface with a single namespace and intuitive management utilities.
Orioginal NAS system (top) and new Quobyte cluster system (bottom) with Krios telephone-sized booths on the left of each image.
He inspected Quobyte in November last year, liked what he saw, and decided to use its software running on a mix of hard disk and solid state drives. His team had migrated and loaded 1.5PB of data onto the Quobyte system by January this year and the system is working just fine.
DataStax has tweaked its Astra DB Database-as-a-Service (DBaaS) by incorporating vector search capabilities in response to the increasing demand for generative AI-driven data storage solutions.
The foundation of vector search lies in vector embeddings, which are representations of aspects of various types of data, including text, images, audio, and video, presented as strings of floating-point numbers.
DataStax uses an API to feed text data to a neural network, which transforms the input into a fixed-length vector. This technology enables search input that closely matches existing database entries (vector embeddings) to produce output vectors in close geometric proximity, while inputs that are dissimilar are positioned further apart.
Ed Anuff, DataStax chief product officer, emphasized the significance of vector databases in enabling companies to transform the potential of generative AI into sustainable business initiatives. “Databases that support vectors – the ‘language’ of large learning models – are crucial to making this happen.”
He said massive-scale databases are needed because “an enterprise will need trillions of vectors for generative AI so vector databases must deliver limitless horizontal scale. Astra DB is the only vector database on the market today that can support massive-scale AI projects, with enterprise-grade security, and on any cloud platform. And, it’s built on the open source technology that’s already been proven by AI leaders like Netflix and Uber.”
Astra DB is available on major cloud platforms, including AWS, Azure, and GCP, and has been integrated into LangChain, an open source framework for developing large language models essential for generative AI.
Matt Aslett, VP and Research Director, Ventana Research, said in DataStax’s announcement: “The ability to trust the output of generative AI models will be critical to adoption by enterprises. The addition of vector embeddings and vector search to existing data platforms enables organizations to augment generic models with enterprise information and data, reducing concerns about accuracy and trust.”
Astra DB adheres to the PCI Security Council’s standards for payment protection and safeguards Protected Health Information (PHI) and Personally Identifiable Information (PII), we’re told.
Other database and lakehouse providers – such as SingleStore, Databricks, Dremio, Pinecone, Zilliz, and Snowflake – are also actively supporting vector embeddings, demonstrating the growing demand for these features in the generative AI data storage landscape.
Try DataStax’s vector search here (registration required) and download a white paper on Astra DB vector search here (more registration required).
Additionally, customers using DataStax Enterprise, the company’s on-premises, self-managed offering, will have access to vector search within the coming month.
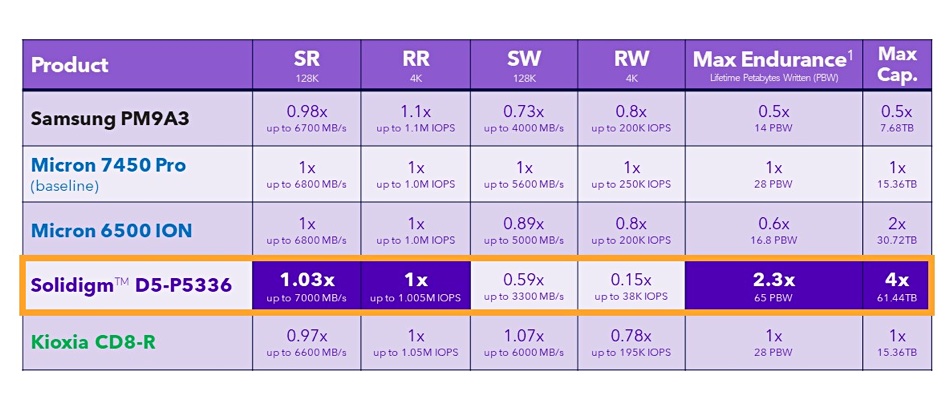
Solidigm has unveiled its latest product, the D5-P5336, featuring storage capacity of 61.44TB. This drive is currently the largest capacity PCIe drive available on the market and utilizes QLC (4bits/cell) flash technology while delivering performance comparable to TLC (3bits/cell) drives.
Building on its predecessor, the D5-P5430, the D5-P5336 is designed as a value endurance read-intensive product. The D5-P5430 remains a mainstream read-intensive drive, topping out at 30.72TB. Both drives are available in U.2, E1.L, and E3.S formats, built on 192-layer 3D NAND technology. The D5-P5336 incorporates a 16KB indirection unit, an upgrade from the previous 4KB unit, resulting in faster read operations through logical block address to physical block address mapping.
Greg Matson
Greg Matson, VP of Strategic Planning and Marketing at Solidigm said: “Businesses need storage in more places that is inexpensive, able to store massive data sets efficiently and access the data at speed. The D5-P5336 delivers on all three – value, density and performance. With QLC, the economics are compelling – imagine storing 6X more data than HDDs and 2X more data than TLC SSDs, all in the same space at TLC speed.”
The drive in U.2 format starts with a 7.68TB capacity, doubling its capacity in three steps to 61.44TB. The physically smaller E3.S format has a 7.68TB to 30.2TB range while the physically larger E1.L ruler format starts at 15.36TB, maxing out at 61.44TB like the U.2 product. This PCIe gen 4-connected drive boasts maximum speeds of 1,005,000/43,000 random read/write IOPS, 7GBps sequential read bandwidth, and 3.3GBps sequential write bandwidth, making it ideally suited for read-intensive workloads, particularly when contrasted with the D5-P5430, which delivers 971,000/120,000 random read/write IOPS, 7GBps sequential read and 3GBps sequential write bandwidth.
Exploded view of Solidigm D5-P5336 E1.S format drive
Compared to some datacenter TLC drives, the D5-P5336 excels in read-intensive performance, even though TLC flash is generally faster than QLC NAND. For example, the SK hynix PE811, a PCIe gen 4 drive utilizing 128-layer TLC NAND, outputs 700,000/100,000 random read/write IOPS and 3.4/3.0 GBps sequential read/write bandwidth.
Solidigm conducted a comparative analysis, normalizing to Micron’s 7450 Pro:
The five-year endurance is up to 0.58 drive writes per day (DWPD), varying with capacity: 7.68TB – 0.42; 15.36TB – 0.51; 30.72TB – 0.56; and 61.44TB – 0.58 DWPD.
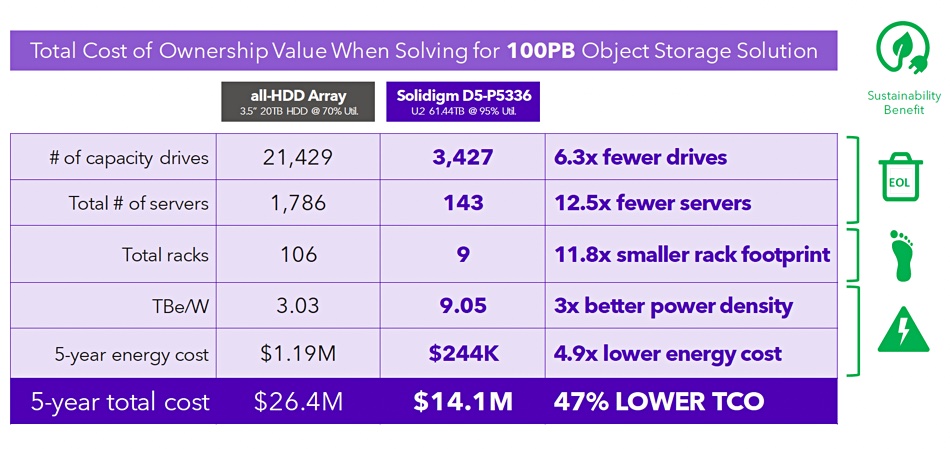
Given the speed, endurance, and pricing information, Solidigm created comparison grids for 100PB object storage disk and TLC flash arrays against its D5-P5336. The results indicated a significant cost advantage for the D5-P5336, offering a 47 percent lower 5-year total cost of ownership (TCO) when compared to an all-disk setup with 106 racks of 20TB HDDs. Moreover, compared to a 100PB Micron 6500 ION rack, the D5-P5336 showed a 17 percent lower cost.
The results are based on Solidigm’s own testing and we cannot independently verify the figures.
The D5-P5336 is shipping now in the E1.L form factor, supporting up to 30.72TB, with plans to extend the product line to U.2 and E1.L formats up to 61.44TB later this year. Furthermore, Solidigm intends to introduce E3.S form factor drives, featuring capacities of up to 30.72TB, in the first half of 2024.
Comment
Given the D5-P5336’s reported cost-effectiveness, high performance, and adoption by OEMs such as VAST Data, we suspect that other SSD manufacturers will likely follow suit and introduce their own 60TB-class drives in the next six months. This move will enable OEMs to compete at a drive capacity level and narrow the gap between current SSD offerings, which max out at 30TB, and Pure Storage’s 75TB Direct Flash Modules.
It will be interesting to see how costs compare between Solidigm’s D5-P5338 object storage array and equivalent HDD arrays at lower capacities, such as 75PB, 50PB, and 25PB. The potential shift to 30TB+ HAMR drives may also play a crucial role in influencing this landscape. The HDD suppliers are expected to closely scrutinize these factors and share relevant information in response.
Cisco and HPE, along with their channel partners, have entered into agreements to resell a suite of data protection managed services from Cohesity, using the AWS and Azure clouds.
Cohesity Cloud Services (CCS) comprises four fully managed, cloud-native as-a-service solutions: backup, cyber vaulting, threat defense, and disaster recovery. These are part of Cohesity’s Data Cloud software portfolio, which includes DataProtect backup, FortKnox cyber vaulting, DataHawk threat detection, SmartFiles, and SiteContinuity disaster recovery, all provided in a managed service format. It’s worth noting that SmartFiles is not a data protection product and isn’t included in the suite.
Chris Kent
Cohesity’s Vice President for Product and Solutions Marketing, Chris Kent, emphasized the company’s focus on partnerships, stating: “We are partner-focused, and these agreements add significant resources to our ability to reach even more customers worldwide.”
Both Cisco and HPE already have established agreements with Cohesity. The collaboration has resulted in over 460 joint customers for Cisco and Cohesity, and more than 600 joint customers for HPE and Cohesity. Cisco, HPE, and their respective resellers will now be able to offer Cohesity Cloud Services, which are hosted on the AWS and Azure platforms. The pair reckon that adopting CCS for data protection offers a simpler and more efficient alternative to on-premises solutions, reducing management requirements and freeing up valuable staff time.
Currently, one in five Cohesity customers utilize CCS, and approximately a quarter of all new business for Cohesity is attributed to CCS. Larger enterprises are showing significant interest, with nearly two-thirds of CCS’s annual recurring revenue over the past 12 months coming from companies with revenue exceeding $1 billion, we’re told.
Furthermore, the company has a sales partnership with OwnBackup, and there is potential for integrating OwnBackup’s SaaS application backup services for Microsoft Dynamics 365, Salesforce, and ServiceNow into the CCS backup-as-a-service product. However Cohesity is not a launch partner for the Microsoft 365 Backup service via API integration. Data protection competitors such as Commvault, Rubrik, Veeam and Veritas, are API integration-level partners for Microsoft 365 Backup.
CCS is available in America, Canada, Europe, Singapore and southeast Asia, Japan, and the Middle East. It is being sold today by Cohesity, HPE and HPE resellers, and will be available from Cisco and its channel crew later this year.
Commissioned: It’s not a revolutionary statement to say data has value – how many times have we heard it’s the new oil? But what might not be readily apparent is how much. Up until this point, the vastness of data – and lack of tools to efficiently parse it – has made it almost impossible to analyze at scale. But that’s all changing thanks to generative AI (GenAI), as well as broader AI breakthroughs on the horizon. The bigger question is, how do we measure it? How do we begin to understand it? What examples can we point to that show exactly how massive the value of data has become?
The good news is the internet, possibly the largest source of data value on earth, provides a great case study in data, its usage, and its exponentially growing value. Let’s take a look at why the internet might be the most visible and timely battleground to analyze and learn just how critical data will be in this new AI era.
The ebb and flow of the internet
We started with links and search engines. Early portals gave way to Google search dominance – a page with a single search bar that took you where you wanted to go. This soon gave way to social media platforms that brought your attention back to centralized hubs where you could scroll through curated lists of content that were brought to your feed. In an effort to create freedom from platforms and their algorithms and democratize access and ownership of digital content, we saw the rise of Web3 and the promise of the internet moving back towards decentralization. However, the Web3 movement relied on advanced technical skills and a trust in a broad community that had some high-profile challenges in recent years.
Could GenAI be the next iteration of the Web? A Web4?
GenAI has burst onto the scene and has become a sensation that every organization is now looking at. It’s changing how developers and ops folks are working. Every organization is rushing to explore how it can impact their business, touted in many areas. Let’s unpack how it changes the game for the internet.
GenAI offers ease of use. It’s why it’s captured the attention of users and organizations everywhere, and why it offers the potential to reshape the internet. Because GenAI suggests a return to a centralized web consumption experience, it’s not surprising that search engines are jumping in on this trend and trying to bolster their positions. Simply put, it’s doing something Web3 never did: making it much easier for users to get to what they want.
Here’s how it works: instead of going to a recommended destination where they must identify the answer themself, the user simply asks the GenAI application a question and the answers are brought to them in a conversational way. This is a potentially earth-shattering level of change to the internet – for the user to be able to interrogate the data and land on exactly what they were looking for is very elusive. This suggests the new Web4 era will be centered around personalization and the ability to interact with data similar to how we interact as humans. It is also creating the battle lines for what the future of the internet could look like, by bypassing the existing players and their platforms and surfacing up results in conversational responses.
GenAI training and internet scraping
When building and training a foundation model for GenAI, data quantity and quality is critical to achieving the best outcomes. As such, the internet was one of the earliest places that many of these AI models looked to. Where else could you get so much data from so many active participants? Plus, it was data that was freely available and, in many cases, the users of these platforms were actively giving their data away. But it gets murky because data ownership and whether there were intellectual property protections in play still is not readily understood nor legally tested.
Add to that many of the early players in this space were startups with a “move fast and break stuff” mentality, and AI and the internet very much is the wild west. We’ve seen early battlegrounds drawn by companies like Getty Images, who see GenAI images that pull from their archives as derivative works and are arguing these tools are more like Napster than something novel and new. But perhaps an area that is sparking the biggest seismic shifts is in social media, where typically, the platforms are granted some level of access and assigned rights via terms of service and offer a free platform as a result. The challenge here is that many had built extensions to their platforms using APIs or allowed unfettered access to users, and now they see GenAI as a massive threat to their efforts and valuation.
Social media strikes back
Recently, we’ve seen many social media companies go on the offensive, restricting access to GenAIs and leaving their users in the crossfire. It’s not hard to see why this is occurring; these AIs can collect and consume a sea of content and provide a contextual search of that content that is completely personalized.
What a value proposition for an audience. With things like GitHub Copilot, a simple GenAI prompt can surface documentation or code snippets in seconds. Stack Overflow, Reddit and Twitter have all moved to start charging for API access to their site’s content. It makes sense; if a perceived competitor is gathering and using all your data to gain a competitive advantage, why wouldn’t you seek compensation or limit access? Reddit has also recently moved to restrict third-party apps, and interestingly, that has sometimes put them at odds with their community moderators.
Then there’s Twitter. Over the 4th of July weekend, the social media platform began to temporarily limit user access to its content. We’re also beginning to see some of this battle spill over into other web properties, such as news outlets and GenAI powered search defeating paywalls. In a world where content and data become products themselves, we will continue to see this tug of war. Decisions are being made that are shaking the internet to its very foundation, and the sole reason for any of this is just how precious this data is.
What the internet can tell you about your own data
When thinking about your enterprise or business data versus what might commonly be found on the internet, consider this: your data’s probably way more valuable. We’re seeing tech behemoths fight tooth and nail to protect their data and IP, even when it’s user-generated and potentially available in many other platforms and forms, or full of low-quality data like spam and bot networks. With GenAI, the proportion of data that holds value has increased exponentially. This means that organizations may have to re-evaluate their existing notions on data because GenAI has changed the equation.
If social media companies work this hard to limit access and bolster their competitive position with data, leaders embracing AI must take similar steps. Lean into the world of ambiguity – the use cases may not yet be obvious – but the answer will lie in the data and retention policies must change as a result. Consider where your data sits and how best to get AI to it, because data gravity will still play a role. Understand how it’s used. Data and Intellectual Property leakage must be avoided; the data itself and the potential training it offers a foundation model could potentially reduce your differentiation.
Ultimately, what we are watching now in social media will play out repeatedly in other spaces; data will be the great differentiator. In this space, that means taking a hard look at your AI solutions and ensuring you are limiting areas of exposure. We’re rapidly approaching a world where every organization is data-driven and using AI. This means it will be more important than ever to protect your most valuable asset – your data – and never outsource your core competencies.
Microsoft’s Azure is using MANA smartNICs to accelerate network and storage speed, giving it AWS Nitro-like functions. Users will soon have access to MANA benefits through the upcoming Azure Boost service, currently available for preview.
Update: Fungible acquisition note added. 21 July 2023.
The Microsoft Azure Network Adapter (MANA) is purpose-built system-on-chip (SoC) hardware and software designed to expand network bandwidth, enabling faster and more efficient data transfers. It ensures superior network availability and stability, boasting ratings of up to 200Gbitps networking throughput, remote storage throughput of up to 10GBps, and 400,000 IOPS.
Max Uritsk
In a blog post by Max Uritsky, Partner Group Program Manager for Azure Host at Microsoft, he states: “Azure Boost is an innovative system that offloads virtualization processes, including networking, storage, and host management traditionally performed by the hypervisor and host OS, onto purpose-built hardware and software.”
By “separating hypervisor and host OS functions from the host infrastructure, Azure Boost enables greater network and storage performance at scale, improves security by adding another layer of logical isolation, and reduces the maintenance impact for future Azure software and hardware upgrades.”
MANA serves as a critical component already implemented within Azure, which Microsoft says provides exceptional remote storage performance for the Ebsv5 VM series as well as networking throughput and latency improvements for the entire Ev5 and Dv5 VM series instances. Specifically, customers can “achieve an industry-leading remote storage throughput and IOPS performance of 10 GBps and 400K IOPS with our memory optimized E112ibsv5 VM using NVMe-enabled Premium SSD v2 or Ultra Disk options.”
The smartNIC effectively offloads storage data plane operations from the host server onto dedicated hardware, resulting in accelerated storage performance and improved disk caching for Azure Premium SSDs. Additionally, it offers an SR-IOV NIC as a virtual function to a guest OS running on Hyper-V.
Uritsky says: “Experimental VMs provided as part of the preview will provide even faster remote storage throughput.”
MANA supports both Linux and Windows operating systems through a set of device drivers, expanding network bandwidth. It also enables network-focused Azure partners and customers to use Microsoft’s Data Plane Development Kit (DPDK) for enhanced hardware access.
With hardware-based secure boot and attestation, MANA ensures robust security, we’re told. Its operating system reduces the potential attack surface, incorporating multiple layers of defense-in-depth. This includes ubiquitous code integrity verification to prevent unexpected code execution and enforcement of mandatory access controls through Security Enhanced Linux (SELinux). The SoC features a FIPS 140 certified kernel for cryptography, providing security levels compliant with federal government standards.
Uritsky says: “Azure infrastructure updates can be deployed much faster by loading directly onto the Azure Boost hardware with minimal impact to customer running VMs on the host servers.“
This reminds us of Nebulon’s functionality delivered to on-premises server fleet users through its SPU (Services Processing Unit).
Azure now has similar hardware and functionality to that provided by AWS’s Nitro card. It invites partners and customers with high-performance network and storage needs, particularly those using the Data Plane Development Kit (DPDK), to take part in the preview. Make a request here.
To learn a little more about MANA, there’s an FAQ here.
Update
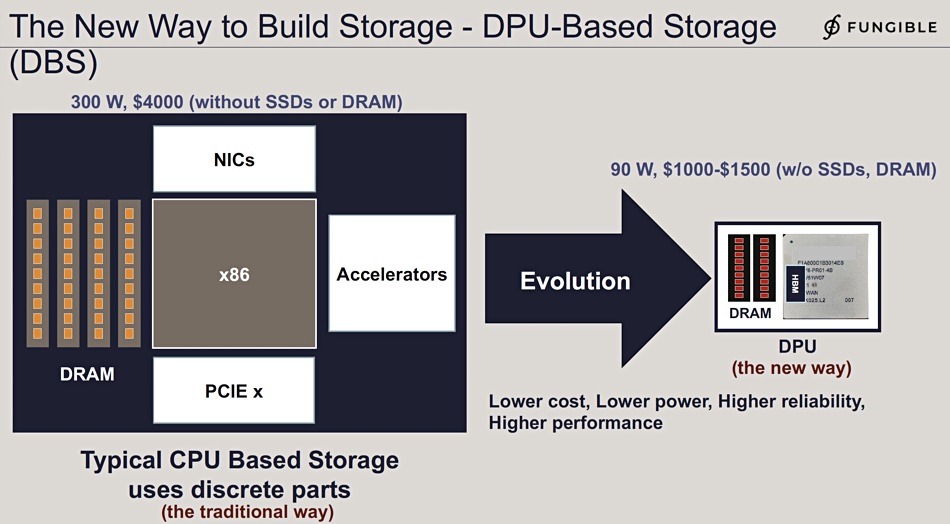
Microsoft acquired DPU startup Fungible in December last year for $190 million. Fungible had developed its own Data Processing Unit (DPU) silicon, the F1 chip. The company focussed on storage cluster technology using all-flash arrays controlled by its DPUs with no x86 involvement.
Fungible DPU slide.
Fungible also built an FS1600 NVMe array storage node product with its own DPU chips replacing standard X86 controllers.
Fungible FS1600 array.
We think MANA is based on Fiungible’s F1 chip and associated firmware and software.
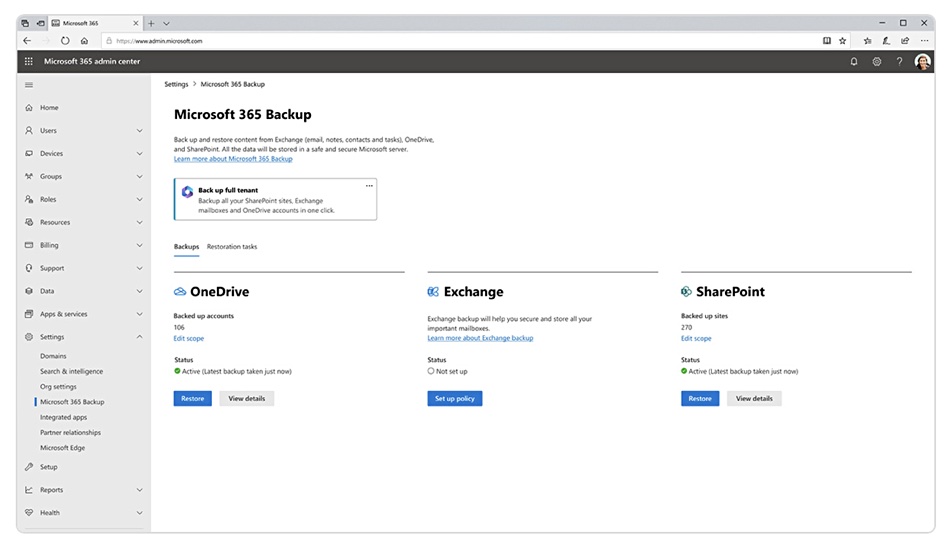
Microsoft is introducing user content backup for its M365 services, along with API integration for partners. Additionally, a SharePoint archive tier will be available later this year, also with API-based partner integration.
Numerous data protection suppliers offer user data protection services for SaaS apps like M365 and Salesforce because SaaS providers primarily protect their infrastructure rather than user content. Microsoft is enhancing its approach by providing user content protection for SharePoint, OneDrive for Business, and Exchange Online services. Furthermore, Microsoft will offer an archival storage tier for SharePoint at a lower cost than standard SharePoint storage to address rising storage costs.
Jeff Teper
According to Jeff Teper, President for Microsoft 365 Collaborative Apps and Platforms, Microsoft 365 Backup “provides recovery of your OneDrive, SharePoint, and Exchange data at unprecedented speeds for large volumes of data with a restore service level agreement (SLA) – while keeping it all within the Microsoft 365 security boundary.”
Key features of M365 Backup include:
Backup of all or selected SharePoint sites, OneDrive accounts, and Exchange mailboxes in your tenant.
Parallel restoration of files, sites, and mailbox items to a specific point-in-time, either granularly or at a larger scale.
Searching and filtering content within backups using metadata such as item or site names, owners, or event types within specific restore point date ranges.
Microsoft aims to carve out its share of the backup market while allowing partners to build applications on top of its Backup APIs. Teper mentions that users can benefit from this technology by adopting a partner’s application, especially if they have non-M365 data they want to back up.
Microsoft 365 Backup
Initial partners for Microsoft 365 Backup integration include AvePoint, Barracuda, Commvault, Rubrik, Veeam, and Veritas. Rubrik highlights the advantages of its integration, such as faster M365 restores, recovery of Azure Active Directory, and comprehensive centralized management of Microsoft 365 data and other SaaS and hybrid cloud workloads. Veeam, which already protects over 15 million M365 users, plans to use the Veeam Data Platform to deliver innovative features and capabilities, “taking advantage of the power and reliability of the Veeam Data Platform which keeps businesses running,” said CTO Danny Allan.
The public preview of Microsoft 365 Backup is set to launch in Q4 of this year, and you can sign up here. Rubrik integration will become generally available in the coming months, while Veeam’s updated offering is expected within 90 days of the availability of the Microsoft 365 Backup service.
Archive
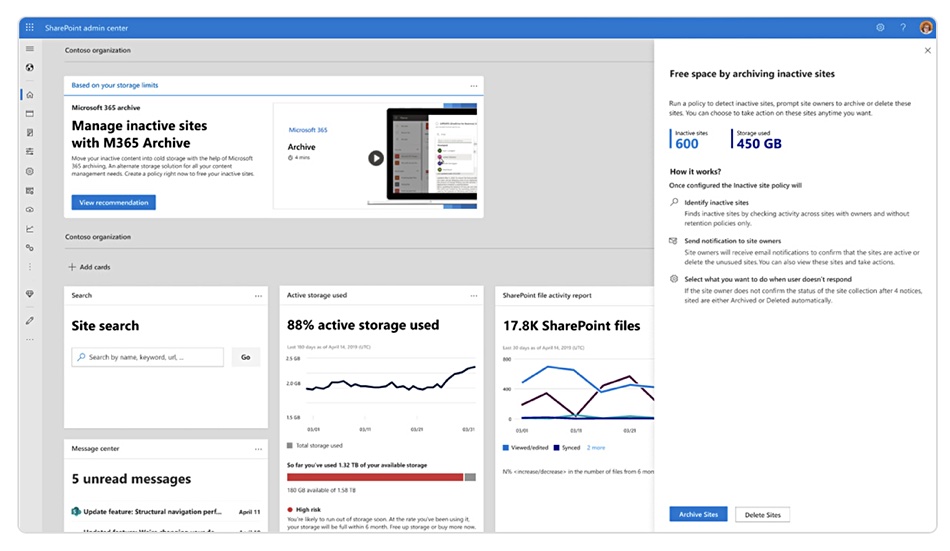
Teper’s blog post mentions the introduction of Microsoft 365 Archive, which he says will offer a cost-effective cold storage tier for aging, inactive, or deleted SharePoint sites. Although stored SharePoint content may become less useful for collaboration over time, it remains crucial for business records and compliance. Customers will retain full admin-level search, eDiscovery, access policy, sensitivity labels, DLP, retention policy, access control settings, and other security and compliance functionality. Content in the archive can be reactivated, and customers can automate mass archiving using PowerShell scripts or SharePoint Advanced Management’s site lifecycle management feature.
Microsoft 365 Archive
File-level archiving, along with retention policy workflow integrations, is planned for the second half of 2024. Microsoft 365 Archive APIs will enable partners like AvePoint and Veritas (Alta SaaS Protection) to integrate Microsoft SharePoint archiving into their existing offerings.
The public preview for Microsoft 365 Archive is expected to be available in Q4 of this year. Anyoen interested can sign up here.
Comment
It remains to be seen whether other SaaS application providers, such as Salesforce, will introduce their own user content data protection services to increase subscription revenues and outperform competitors.
Hammerspace, a company that specializes in data orchestration, has recently secured its first external funding round, aiming to boost sales and marketing efforts for its data orchestration product.
Founded in 2018 by CEO David Flynn, Hammerspace developed data orchestration software based on a parallel NFS global filesystem. This software manages and locates unstructured data elements across geographically dispersed data centers and users in a global namespace.
Previously, the company received funding from Flynn, various high net worth individuals, and long-term investing sources instead of venture capitalists.
However, with its latest funding round, Hammerspace raised $56.7 million, effectively being an A-round. Prosperity7 Ventures led this funding round, joined by other notable investors such as Pier 88 Ventures, Cathie Wood’s ARK Invest, and others.
Flynn explained the significance of unstructured data in the current data cycle: “The last data cycle focused on structured data rooted in business intelligence, but this data cycle, driven by compute, orchestration and applications, leverages unstructured data to drive product innovation and business opportunity with AI, machine learning and analytics. Hammerspace’s new funding will enable the company to help more customers unlock the value in unstructured data, create new revenue streams and drive operational efficiency.”
To utilize the new funds effectively, Hammerspace plans to expand its sales and marketing business infrastructure. As part of this initiative, they have recently hired a partner marketing executive, Betsy Doughty. The company points out the rapidly growing use of unstructured data for analytics, with data lakes and lakehouses complementing data warehouses. Additionally, AI data processing, especially with large language models for generative AI, further drives this trend, necessitating the breakdown of data silos.
Randy Kerns, a Senior Strategist at the Futurum Group, said: “With the technologies of today and requirements for data, the urgent need in the latest data cycle is the orchestration of a data pipeline of unstructured data to analytics for AI and machine learning applications, enabling speed and agility for enterprises.”
AI’s demand for high-performance file systems is also driving Hammerspace’s growth. The company already counts a major AI developer among its customers, and Flynn highlighted a system with 600 storage nodes boasting over 30 terabits per second bandwidth. With HPC-style computing becoming more prevalent in enterprises to run AI jobs, users no longer need to adopt HPC-style parallel file systems like Lustre or Storage Scale; standard NFS is now parallel and up to the task.
Contrary to common belief, object stores are not required to provide the scale that file systems lack. Hammerspace’s file-based software is being used by Jeff Bezos’ Blue Origin rocket company across multiple facilities in the US and the cloud, indicating its flexibility and efficiency in managing data.
Hammerspace believes that data should no longer be static or limited in visibility across an enterprise. Instead, it should be orchestrated to be fluid, easily accessible with proper controls, and visible throughout the organization. Like financial assets, data assets should be known, managed, activated, synchronized, and moved wherever needed to enhance business effectiveness. Hammerspace’s software effectively enables access and utilization of unstructured data for various applications, including generative AI models.
Hammerspace top-level architecture.
Jonathan Tower, managing director at Prosperity7 Ventures, praised Hammerspace’s breakthrough technology for providing efficient access to unstructured data, aligning with the original vision of the cloud to offer unified and seamless data access regardless of location, without silos or latency issues.
Notably, Hammerspace has not favored venture capital investment due to potential misalignments with the founding team’s interests in building a viable and profitable long-term business. Instead, the company has sought investors who share their long-term vision and do not intend to sell shares post-IPO. Both Cathie Wood’s ARK Invest and Prosperity7 Ventures are among such investors, and are planning to hold their Hammerspace shares for the long term without any plans to sell after a potential IPO, which may happen in a couple of years.
Lenovo has upgraded its storage array and Azure Stack lines with faster and higher-capacity products to support AI and hybrid cloud workloads – just a quarter after a previous refresh.
Kamran Amini, Vice President & General Manager for Lenovo’s Server, Storage & Software Defined Infrastructure unit, said: “The data management landscape is increasingly complex, and customers need solutions that offer the simplicity and flexibility of cloud with the performance and security of on-premises data management.”
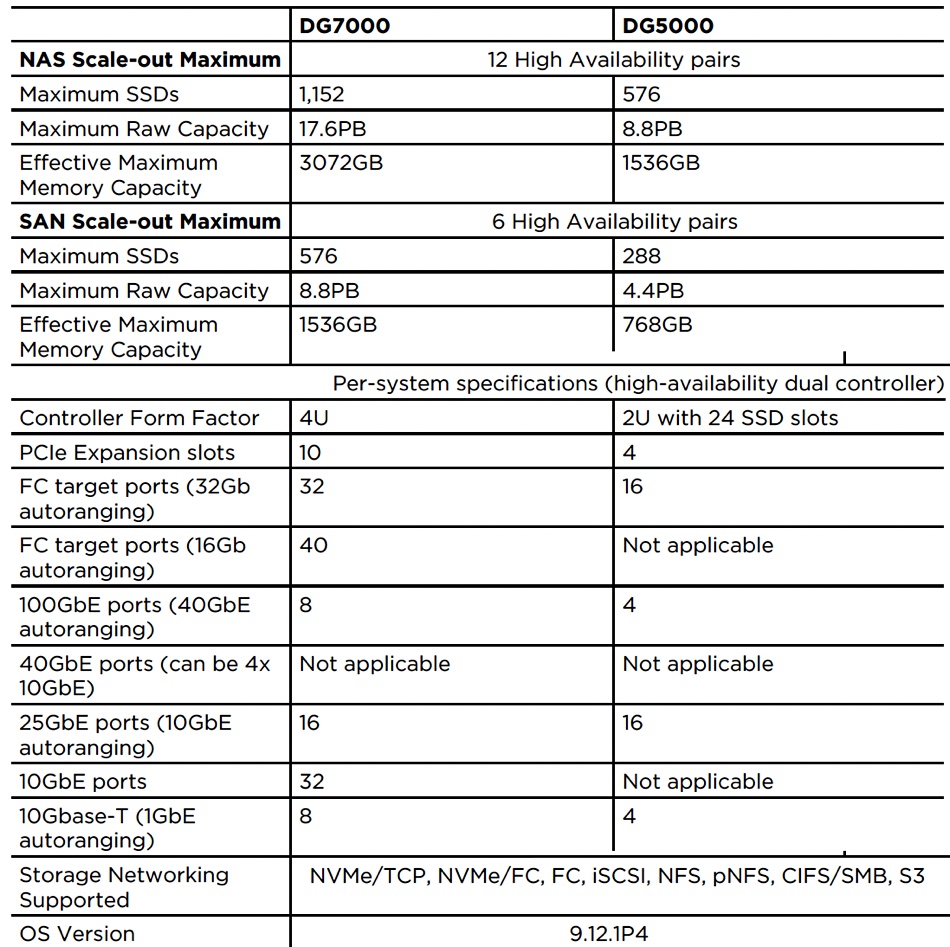
As such, Lenovo has announced the ThinkSystem DG and DM3010H Enterprise Storage Arrays, OEM’d from NetApp, and two new ThinkAgile SXM Microsoft Azure Stack systems. The DG products are all-flash arrays with QLC (4bits/cell or quad-level cell) NAND, targeted at read-intensive enterprise AI and other large dataset workloads, offering up to 6x faster data ingest than disk arrays at a claimed cost reductiuon of up to 50 percent. They are also lower cost, Lenovo says, than TLC (3bits/cell) flash arrays. We understand these are based on NetApp’s C-Series QLC AFF arrays.
Lenovo ThinkSystem DG5000 and DG7000 EnterpriseStorage Arrays
There is also the new DG5000 and larger DG7000 systems with the base controller enclosures being 2RU and 4RU in size respectively. They run NetApp’s ONTAP operating system to provide file, block and S3 access object storage.
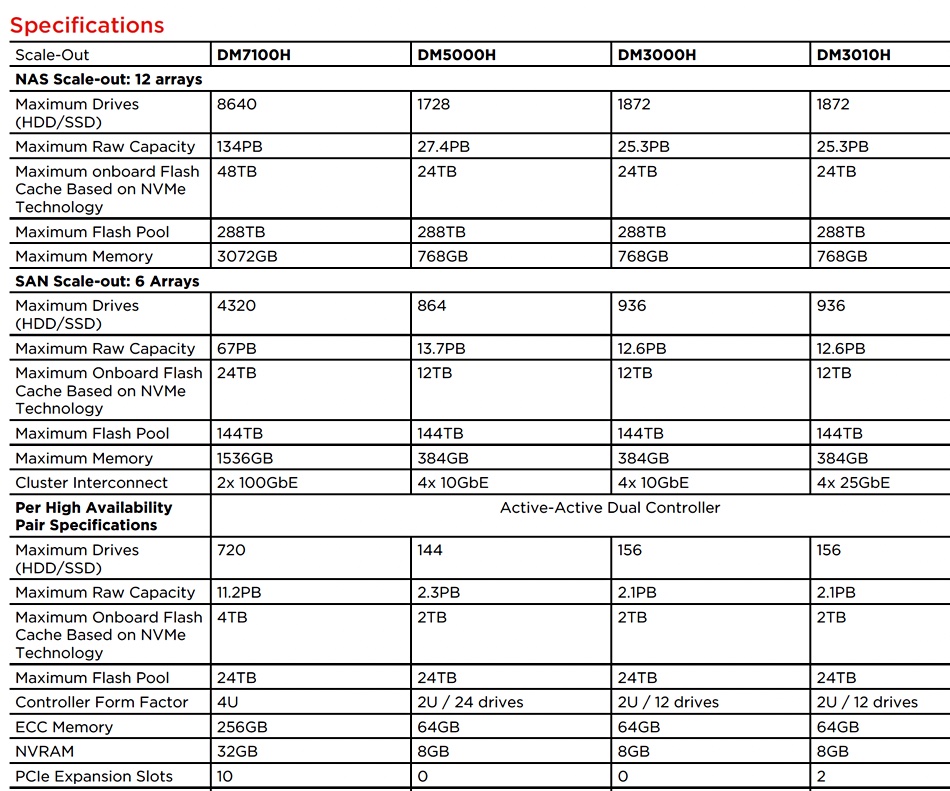
The DM products consist of five models: the new DM3010H, DM3000H, DM5000H and DM7100H, with combined disk and SSD storage.
The DM301H has a 2RU, 24-drive controller and differs from the DM3000, with its 4 x 10GbitE cluster interconnect by having faster 4 x 25 GbitE links.
Lenovo DM3010H
There are two new Azure Stack boxes – ThinkAgile SXM4600 and SXM6600 servers. These are 42RU rack hybrid flash+disk or all-flash models and augment the existing entry-level SXM4400 and full size SXM6400 products.
The SXM4600 has 4-16 SR650 V3 servers compared to the SXM440’s 4-8, while the SXM6600 has the same number of servers, 16, as the SXM6400, but has up to 60 cores versus the existing model’s maximum of 28 cores. Read a data sheet here.