

SPONSORED: In August 2023, Danish hosting subsidiaries CloudNordic and AzeroCloud were on the receiving end of one of the most serious ransomware attacks ever made public by a cloud services company. During the incident, CloudNordic suffered a complete encryption wipe-out that took with it applications, email services, websites, and databases, and even backup and replication servers. In a memorably frank admission, the company said that all customer data had been lost and would not be recoverable.
To the hundreds of companies Danish media reported as having lost data in the incident, this must have sounded incredible. Surely service providers are supposed to offer protection, not even greater vulnerability? Things were so bad, CloudNordic even offered customers last resort instructions on recovering lost website content through the Wayback Machine digital archive. The company reportedly refused to pay a ransom demanded by the attackers but even if it had paid there is no guarantee it would have made any difference.
Ransomware attacks are a dime a dozen these days and the root causes are various. But the assumption every customer makes is that behind a service provider’s virtual machine (VM) infrastructure is a comprehensive data protection and disaster recovery (DR) plan. Despite the common knowledge that ransomware targets backup and recovery systems, there is still a widespread belief that the same protections will always ride to the rescue and avoid catastrophic data loss. The CloudNordic attack is a warning that this isn’t always the case. Doubtless both companies had backup and data protection in place, but it hadn’t been enough.
“The attack and its outcome is not that extraordinary,” argues Kevin Cole, global director for technical product marketing at Zerto, a Hewlett Packard Enterprise company. “This probably happens more than we know. What’s unusual about this incident is simply that the service provider was open about the fact their backups had been attacked and deleted.”
This is what ransomware has done to organizations across the land. Events once seen as extreme and unusual have become commonplace. Nothing feels safe. Traditional assumptions about backup and data resilience are taking a battering. The answer should be more rapid detection and response, but what does this mean in practice?
The backup illusion
When responding to a ransomware attack, time is of the essence. First, the scale and nature of the incursion must be assessed as rapidly as possible while locating its source to avoid reinfection. Once this is within reach, the priority in time-sensitive industries is to bring multiple VM systems back online as soon as possible. Too often, organizations lack the tools to manage these processes at scale or are using tools that were never designed to cope with such an extreme scenario.
What they then fall back on is a mishmash of technologies, the most important of which is backup. The holes in this approach are well documented. Relying on backup assumes attackers haven’t deactivated backup routines, which in many real-world incidents they manage to do quite easily. That leaves offline and immutable backup, but these files are often old, which means that more recent data is lost. Even getting that far takes possibly days or weeks of time and effort.
Unable to contemplate a long delay, some businesses feel they have no option but to risk paying the ransom in the hope of rescuing their systems and data within a reasonable timescale. Cole draws a distinction between organizations that pay ransoms for strategic or life and death reasons – for example healthcare – and those who pay because they lack a well-defined strategy for what happens in the aftermath of a serious attack.
“Organizations thought they could recover quickly only to discover that they are not able to recover within the expected time window,” he explains. “They pay because they think it’s going to ease the pain of a longer shutdown.”
But even this approach is still a gamble that the attackers will hand back more data than will be recovered using in-house backup and recovery systems, Cole points out. In many cases, backup routines were set up but not properly stress tested. Under real-world conditions, poorly designed backup will usually fall short as evidenced by the number of victims that end up paying.
“Backup was designed for a different use case and it’s not really ideal for protecting against ransomware,” he says. “What organizations should invest in is proper cyber recovery and disaster recovery.”
In the end, backup falls short because even when it works as advertised the timescale can be hugely disruptive.
Achieving ransomware resilience
It was feedback from customers using the Zerto solution to recover from ransomware that encouraged the company to add new features tailored to this use case. The foundation for the Zerto solution is its continuous data protection (CDP) technology, with its replication and unique journaling technology, which reached version 10 earlier this year. Ransomware resilience is an increasingly important part of this suite, as evidenced by version 10’s addition of a real-time anomaly system that can detect that data is being maliciously encrypted.
Intercepting ransomware encryption early not only limits its spread but makes it possible to work out which volumes or VMs are bad and when they were infected, so that they can be quickly rolled back to any one of thousands of clean restore points.
“It’s anomaly and pattern analysis. We analyze server I/O on a per-volume basis to get an idea of what the baseline is at the level of virtual machines, applications and data,” explains Cole. “Two algorithms are used to assess whether something unusual is going on that deviates from this normal state.”
An important element of this is that Zerto is agentless which means there is no software process for attackers to disable in order to stop backup and replication from happening behind the victim’s back.
“It sounds small but it’s a really big advantage,” says Cole. “Many ransomware variants scan for a list of backup and security agents, disabling any they find protecting a VM. That’s why relying on a backup agent represents a potential weakness.”
A second advanced feature is the Zerto Cyber Resilience Vault, a fully isolated and air-gapped solution designed to cope with the most serious attacks where ransomware has infected the main production and backup infrastructure. Zerto stresses that this offers no point of compromise to attackers – replication from production via a ‘landing zone’ CDP mirror happens periodically via an FIPS-validated encrypted replication port rather than a management interface which might expose the Vault to compromise.
The possibility of a total compromise sounds extreme, but Cole points out that the use of this architecture is being mandated for financial services by the SEC in the U.S., and elsewhere by a growing number of cyber-insurance policies. The idea informing regulators is that organizations should avoid the possibility of a single point of failure.
“If everything blows up, do you have copies that are untouchable by threat actors and which they don’t even know exist?,” posits Cole. “In the case of the Cyber Resilience Vault, it’s not even part of the network. In addition, the Vault also keeps the Zerto solution itself protected – data protection for the data protection system.”
Ransomware rewind
The perils of using backup as a shield against ransomware disruption are underscored by the experience of TenCate Protective Fabrics. In 2013 this specialist manufacturer of textiles had multiple servers at one of its manufacturing plants encrypted by the infamous CryptoLocker ransomware. This being the early days of industrial ransomware, the crippling power of mass encryption would have been a shock. Tencate had backups in place but lost 12 hours of data and was forced to ship much of its salvageable data to a third party for slow reconstruction. In the end, it took a fortnight to get back up and running.
In 2020, a different version of CryptoLocker returned for a second bite at the company, this time with very different results. By now, Tencate was using Zerto. After realizing that one of its VMs had been infected, the security team simply reverted this to a restore checkpoint prior to the infection. Thanks to Zerto’s CDP, the total data loss was a mere ten seconds and the VM was brought back up within minutes.
According to Cole, TenCate’s experience shows how important it is to invest in a CDP that can offer a large number of recovery points across thousands of VMs with support for multi-cloud.
“Combined with encryption detection, this means you can quickly roll back, iterating through recovery points that might be only seconds apart until you find one that’s not compromised.”
While loss of service is not the only woe ransomware causes its victims, the inability to run applications and process data is where the immediate economic damage always begins. For the longest time, the only remedy was to keep the attackers out. But when those defenses fail as they surely will one day, it is better to fail in style, says Cole.
“The choice is not just backup as people have come to know it,” he advises. “Continuous data protection and isolated cyber recovery vaults are the future anyone can have now.”
Sponsored by Zerto.
Building cyber resilience with data vaults

Western Digital boss most disliked tech CEO in survey

David Goeckeler, CEO of Western Digital, has the highest disapproval ratings in a survey of tech bossess by social network company TeamBlind.
The Blind social network is formed of business professionals who register through their work email to comment anonymously on their work experience, without the threat of reprisals.
Blind asked 13,171 members of its network about 103 CEOs in August: “Do you approve or disapprove of the way your CEO is handling their job?” The CEOs were then ranked in terms of their approval and disapproval ratings. There were many storage and storage-related companies in the ratings list and we have picked them out below. Overall Jensen Huang of Nvidia was the most approved CEO while Western Digital’s David Goeckeler had the strongest disapproval rating. The average CEO approval rating was 32 percent.
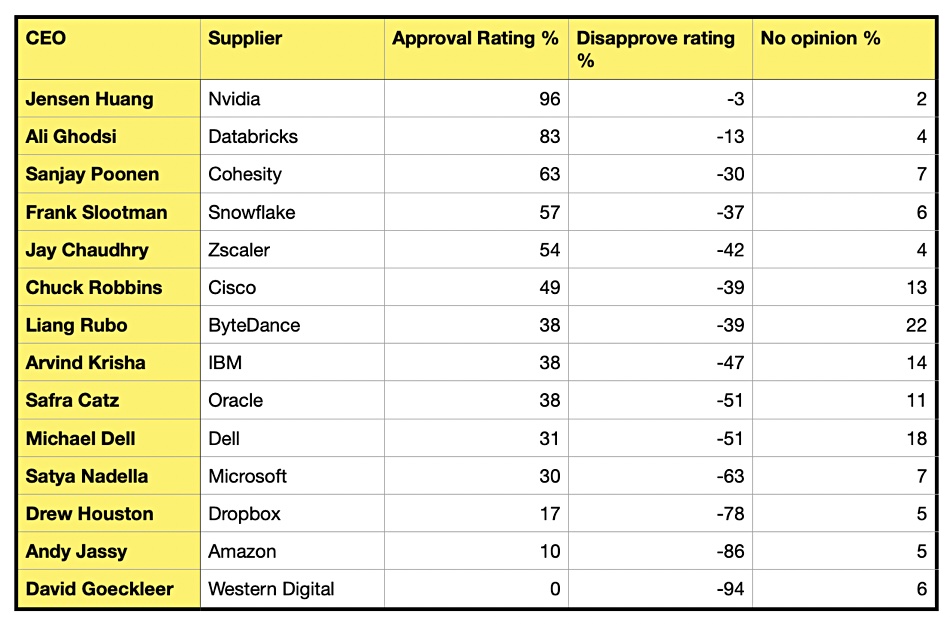
Huang had a 96 percent approval, 3 percent disapproval and 2 percent no opinion rating amongst survey respondents. Databricks’ Ali Ghodsi had an 83 percent approval rating, 13 percent disapproval, and 4 percent no opinion. Other highly ranked CEOs included Apple’s Tim Cook; 83 percent approve, 13 percent disapprove, while 4 percent had no opinion.
Goeckeler had a zero approval rating, 94 percent disapproval rating, and 6 percent had no opinion. Amazon’s Andy Jassy was also unpopular; 10 percent approval, 86 percent disapproval, and 5 percent no opinion. Dropbox CEO Drew Houston was lowly rated too, with only 17 percent approving, 78 percent disapproving, and 5 percent having no opinion.
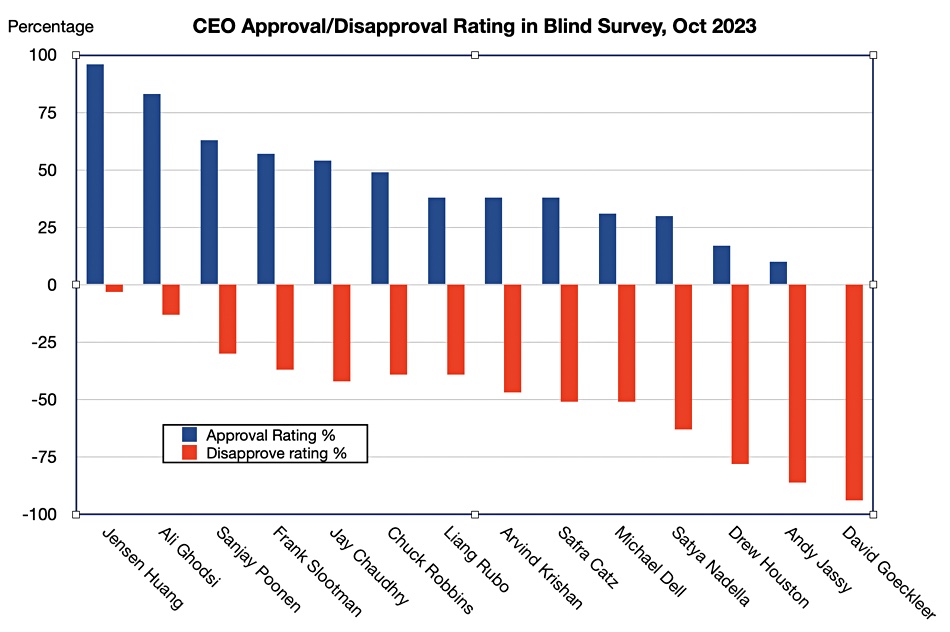
Blind noted: “Top bosses with the highest CEO approval ratings have generally led their companies to higher valuations in 2023… Nvidia shares now trade more than three times higher (+208 percent year-to-date) than they did at the beginning of the year under Huang’s leadership.
“Perceived job security may be one of the most significant factors in determining a chief executive’s approval among employees… some chief executives with the worst CEO approval ratings had cut jobs in 2023, including some of this year’s highest-profile workforce reductions.”

Western Digital laid off 211 staff in the Bay Area in June this year and cut 60 jobs in Israel in May. Goeckeler’s compensation was $32 million in 2022 while the average Western Digital employee earned $108,524. He became CEO in May 2020. We have asked Western Digital if it has any comment about this survey.
Bootnote
Blind survey respondents could answer “strongly approve,” “somewhat approve,” “somewhat disapprove,” “strongly disapprove” or “no opinion.” The approval rating is the sum of “strongly approve” and “somewhat approve” responses. In other words, a CEO with a 0 percent approval rating indicates no employee answered “strongly approve” or “somewhat approve” in the survey.
Interpreting the MLPerf storage benchmark

Silverton Consulting’s president, Ray Lucchesi, has looked at the MLPerf storage benchmark’s initial results and suggested that simulated accelerators per compute node is a useful way to compare suppliers.
Last month we looked at this first MLPerf storage benchmark, which examines how well storage systems serve data to simulated Nvidia V100 GPUs. We focused on the MBps values per supplier system and found not that much difference between suppliers. DDN suggested we should focus on how many GPUs (accelerators in MLPerf terminology) are driven at a specified performance level from a given number of controllers, number of SSDs, and how much power is needed. DDN drives 40 GPUs from a single AI400X2 (2 controllers) and Weka drove 20 GPUs from 8 nodes. Nutanix agreed with this accelerator number per system metric, and it could drive 65 accelerators with a 5-node Nutanix cluster, 15 accelerators per node.
Lucchesi observed: “What they are showing with their benchmark is a compute system (with GPUs) reading data directly from a storage system.” We should use the number of simulated accelerators as a relative number to compare suppliers’ system and not an absolute number of V100 GPUs supported as it’s a simulated and not physical accelerator. A constraint of the benchmark is that storage systems should keep the simulated V100 90 percent busy.
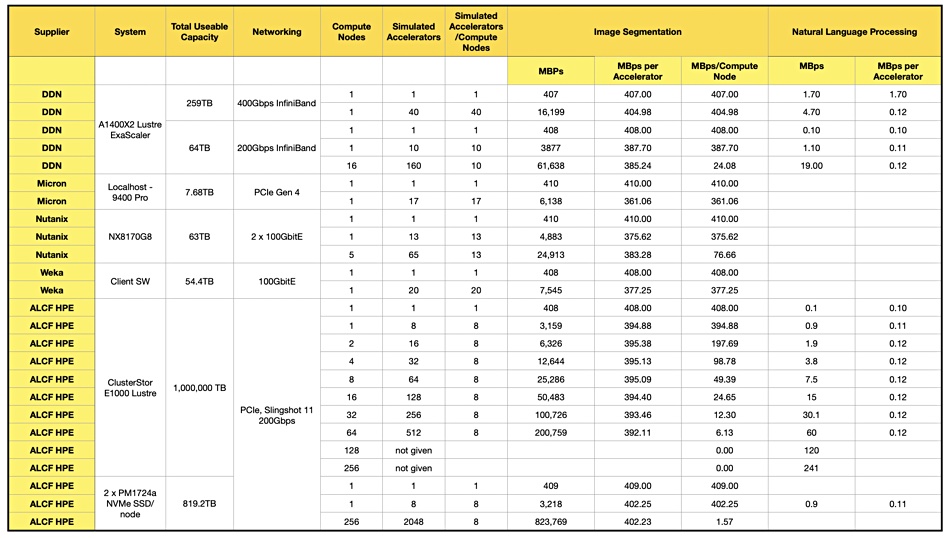
Lucchesi inspected the results and noted a disparity with, for example, DDN. One of its results, 160 accelerators with 64TB of flash storage, listed 16 compute nodes, while another for 40 accelerators listed just one compute node but had 259 TB of flash – more capacity but a lower result. This is counter-intuitive. Lucchesi suggests “the number of compute nodes makes a significant difference in simulated GPUs supported.”
We added a simulated accelerators over compute node column for image segmentation to our table of MLPerf supplier data, as above, and then charted the result:
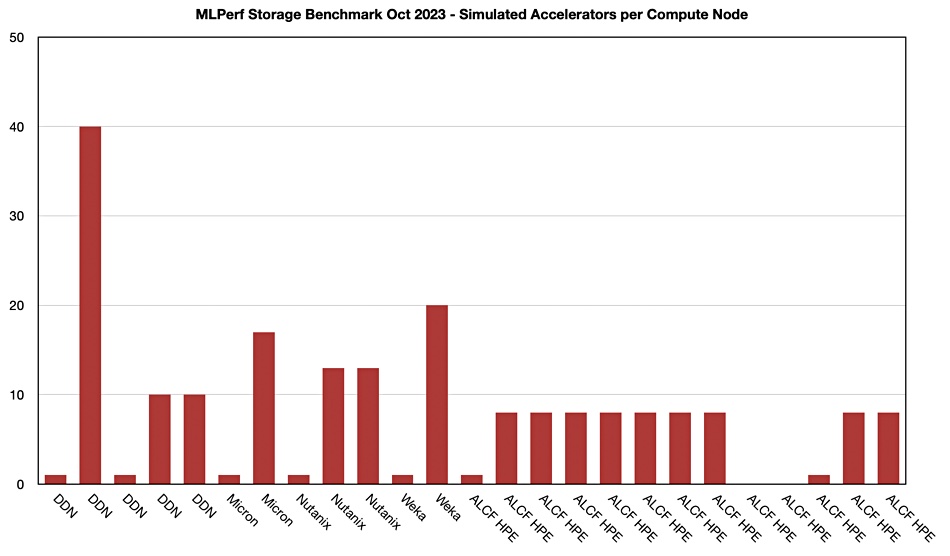
The highest result per supplier – meaning DDN, Weka, Micron, Nutanix, and HPE – are nicely differentiated from each other.
Lucchesi writes: “The Micron SSD used an NVMe (PCIe Gen4) interface while the other two storage systems used 400 Gbps InfiniBand and 100 Gbps Ethernet, respectively. This tells us that interface speed, while it may matter at some point, doesn’t play a significant role in determining the # simulated V100s.”
He suggests ways in which the benchmark could be improved to facilitate better comparisons between suppliers:
- There should be different classes of submissions, with one class for only 1 compute node and another for any number of compute nodes.
- He would uprate the simulated GPU configurations to A100 rather than V100s, one generation behind best-in-class GPUs.
- Have a standard definition for a compute node – the compute node hardware/software should be locked down across submissions.
- Clearly specify the protocol used to access the storage.
- Describe the storage configurations with more detail, especially for software-defined storage systems.
Storage news ticker – October 9

Data protector Arcserve has hooked up with Wasabi Technologies to introduce an integrated total unified data solution package. Exclusively available through Climb Distribution, it combines Arcserve’s Unified Data Protection (UDP) 9.0 and above with Wasabi’s immutable cloud storage, and is a bid to fortify defenses against data loss and ransomware threats.
…
Cisco’s Compute Hyperconverged with Nutanix, which replaces Cisco’s HyperFlex hyperconverged product, has moved to general availability.
…
Data protector Cobalt Iron announced Isolated Vault Services, an enhancement available in the Cobalt Iron Compass enterprise SaaS backup platform. Isolated Vault Services makes it possible to transition normal backup operations into isolated vault recovery services. It is intended for companies needing to recover data in an isolated vault or clean-room environment, typically as part of a declared disaster or cyber recovery operation.

…
Data protector Commvault has appointed Richard Gadd as SVP of EMEA and India. Previously, he was VP and GM for EMEA at Cohesity, and before that he held senior roles at Hitachi Vantara, EMC, and Computacenter. He is credited with growing Hitachi Vantara’s EMEA business to become the company’s largest sales region worldwide, and made Cohesity’s EMEA operation the fastest growing in the organization.
…
Startup and SMB cloud supplier DigitalOcean has launched Scalable Storage for DigitalOcean PostgreSQL and MySQL Managed Databases, which – the company said – enables small and medium-sized businesses to only pay for the data resources they need, preventing cloud underutilization and optimizing customer spend. With this new offering, DigitalOcean customers can increase the disk storage of their Managed Databases without needing to change compute and memory to meet higher data utilization demands.
…
Backup system supplier ExaGrid can now deduplicate compressed Commvault backups. CEO Bill Andrews told us: “Up until now, we had to ask the customer to disable compression in Commvault. Now, they can leave compression enabled.” He explained: ”The Commvault data is written to our Landing Zone, when we go to deduplicate it to our repository tier if the data is compressed. First we uncompress it and then either deduplicate into our repository or further deduplicate it into our repository depending if the data inside is already deduplicated or not.”
…
HPE is creating a new Global Center of Excellence for the HPE GreenLake edge-to-cloud platform in Galway, Ireland, with more than 150 new technical roles. The team of software R&D professionals will support customers and partners with one integrated platform, one customer experience, and a portfolio of solutions under one brand. These new roles are in addition to 150 jobs announced in 2021. Ireland serves as the EMEA hub for Digital Services R&D, HPE GreenLake Cloud Services & Solutions R&D, and Cyber Security, as well as HPE Financial Services (HPEFS), and HPE Aruba Networking operations.
…
The InfiniBand Trade Association (IBTA) announced the immediate availability of the IBTA Specification Volume 1 Release 1.7 and Volume 2 release 1.5. The Volume 1 Release 1.7 includes initial specifications for XDR and lays the foundation for the next speed generation in the IBTA roadmap, providing 2x increased bandwidth over the previous generation to meet the rapid performance and scalability demands of AI and HPC datacenters.

…
MongoDB has appointed 17-year AWS veteran Jim Scharf as its new CTO. He was most recently VP of AWS Identity. Scharf was one of Amazon’s first employees, a founding owner of six services, GM for Amazon DynamoDB, and is the author of 20 US patents in the area of cloud computing. He replaces Mark Porter who spent three years at MongoDB before leaving this summer. Porter now sits on the board of GitLab.
…
Storage array supplier Nexsan has a customer base trade-up deal. It has announced a limited-time Storage Refresh Rebate program with a rebate of $50 per terabyte on Blade, ATABoy, SATABoy, ATABeast, SATABeast, BEAST or E-Series systems returned to Nexsan with the purchase of a new BEAST or E-Series. The company has more than 2,600 systems deployed and more than 600PB of storage under active maintenance today. This refresh, coupled with Nexsan’s pledge to recycle rather than dispose of materials, is expected to reduce the environmental impact.
…
Sony Interactive Entertainment has fallen victim to a cybersecurity breach in Progress Software’s MOVEit file transfer service. Some 6,800 current and former employees have been told that their personal information was exposed after the Clop ransomware group used a zero day vulnerability in MOVEit – CVE-2023-34362 – a critical-severity SQL injection flaw. The attack took place in June. See Sony’s employee letter here.
…

Transcend has an MTE245S NVMe PCIe gen 4×4 SSD in an M.2 form 2280 factor using 3D NAND and delivering up to 5.3GBPs sequential read and 4.6GBps sequential write bandwidth. The IOPS are up to 630,000 for random writes and 500,000 for random reads. The drive has a graphene heat sink. Capacities range from 500 GB, 1 TB, and 2 TB to 4 TB, with total TB written ranging from 300 TB to 2,400 TB over the five-year warranty. The MTBF is 2 million hours and the drive uses the LDPC (Low-Density Parity Check) ECC coding algorithm for data security.
…
Data replication supplier WANdisco has become Cirata as it tries to distance itself from the false accounting fiasco earlier this year.
Databricks report asks GenAI hungry biz to look at its lakehouse

A Databricks-sponsored MIT Tech Review reports says businesses adopting generative AI will become 25 percent more efficient.
Databricks pushes the idea that AI processing needs access to a single, all-encompassing data repository; its lakehouse combining data warehouse and data lake attributes, and with support for streaming data needed for real-time analytics. The MIT Technology Review Insights “Laying the foundation for data-and AI-led growth” report surveyed 600 CIOs, CTOs, CDOs and tech leaders for large public and private sector organizations.
It declares: “Enterprise adoption of AI is ready to shift into higher gear. The capabilities of generative AI have captured management attention across the organization, and technology executives are moving quickly to deploy or experiment with it.”
The report’s exec summary says organizations are sharply focused on retooling for a data and AI-driven future. Everything from data architecture to AI-enabled automation is on the table, as technology executives strive to find new efficiencies and new sources of growth. At the same time, the pressure to democratize the power of data and AI creates renewed urgency to bolster data governance and security.
It found that 88 percent of surveyed organizations are using generative AI, with 26 percent investing in and adopting it, and another 62 percent experimenting with it. The majority (58 percent) are taking a hybrid approach, using vendors’ large language models (LLMs) for some use cases and building their own models for others when IP ownership, privacy, security, and accuracy requirements are tighter.
Some 81 percent of survey respondents expect AI to boost efficiency in their industry by at least 25 percent in the next two years. A third say the gain will be double that. Every organisation surveyed will boost spending on modernising data infrastructure and adopting AI during the next year, and for nearly half (46 percent), the budget increase will exceed 25 percent.
Reassuringly for Databricks, nearly three quarters of surveyed organizations have adopted a lakehouse architecture, and almost all of the rest expect to do so in the next three years. Survey respondents say they need their data architecture to support streaming data workloads for real-time analytics (a capability deemed “very important” by 72 percent), easy integration of emerging technologies (66 percent), and sharing of live data across platforms (64 percent). Ninety-nine percent of lakehouse adopters say the architecture is helping them achieve their data and AI goals, and 74 percent say the benefits are “significant.”
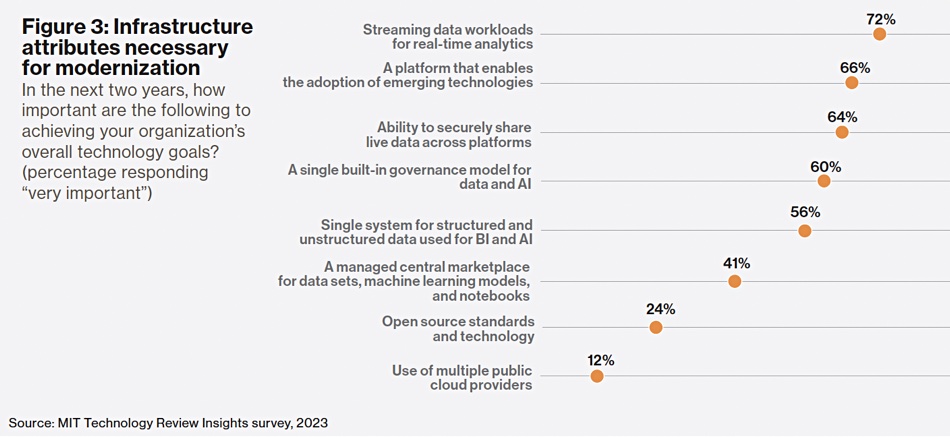
As for data governance, 60 percent of respondents say a single governance model for data and AI is “very important.”
Samuel Bonamigo, SVP and GM EMEA at Databricks put out a statempt: ’”These findings indicate that investments in generative AI are no longer optional for business success – and leaders across the globe have firmly taken notice.”
He said: ‘‘Particularly in EMEA, we are not only seeing increased lakehouse adoption across the board, but also a high degree of AI optimism from executives – for instance, 63 percent of EMEA CIOs were “very optimistic” about the business value that AI could bring to their organisations within two years. 88 percent of organisations are already investing and adopting generative AI. It’s clear that this momentum is showing no signs of slowing.’’
Comment
This Databricks MIT Tech Review report basically tells undecided businesses to get on board the gen AI train or be left behind by those already aboard. This is a good thing for Databricks whose own momentum needs to continue; it’s hoping punters will get a Databricks lakehouse before they start using their data to train gen AI models.
It’s not alone in its lakehouse pitch. Dell’s multi-faceted gen AI activities include supplying a lakehouse as well and that strengthens the idea that lakehouse tech is the best way of storing, managing and arranging data access for AI model training.
How to stop ransomware thieves WORMing their way into your data

SPONSORED FEATURE: Most of us dislike cyber criminals, but not many of us dislike them quite as much as Anthony Cusimano. The director of technical marketing at storage company Object First was on the sharp end of an identity theft attack after his details were leaked in the massive 2017 Equifax breach. Thieves armed with these details SIM-jacked his phone, used it to authenticate into his PayPal account, then stole money from Cusimano and his family.
“I became passionate about security for both individuals and businesses,” he says.
The attack inspired Cusimano to join the battle against cyber crime and move increasingly into more cybersecurity-focused roles. Today, he spends his working day at Object First helping customers understand the importance of protecting their data from a range of attacks.
Object First specialises in protecting data from encryption by ransomware crooks. Its solution, Ootbi, is designed specifically to work with Veeam backup solutions, providing extra protection in the form of data immutability.
The company was founded by Ratmir Timashev and Andrei Baronov, who started Veeam as a backup company for VMware virtual machines in 2006 and then expanded quickly, building it first into a multi-faced backup solution and then into a data management empire.
However, one thing that the two didn’t have was a purpose-built object storage system for Veeam. They wanted a hardware appliance that would work seamlessly with their backup software, providing customers with a way to easily store backup data on their own premises, fed directly from Veeam’s system. They had specific requirements in mind, the most important of which was to make that backup data tamper-proof.
Timashev and Baronov understood the security risks facing stored data and backups. They had made great progress getting companies to back up their data properly in the first place by creating automated solutions that made it more convenient.
Nice bit of backup data you have there
Then, along came the spectre of ransomware. Beginning as badly-coded malware released ad hoc by individuals or small groups, it exploded into a sophisticated business model with professionally written code.
As more victims hit the headlines, the spread of ransomware hammered home the need to back up your data.
Then, the crooks started coming for the backups.
Data backups were a form of business risk to these new, grown-up ransomware gangs. Like any business, they sought to eliminate the risk. They did it by seeking out backup servers and encrypting or deleting those, too, leaving victims more inclined to pay them.
One answer to this is write once read many (WORM) disks, or storage taken offline. WORM disks can’t be overwritten, but they are expensive and difficult to manage. Offline hard drives or tape must be connected to the system and then disconnected when the backups are complete, all in the hope that ransomware doesn’t target them while they’re online.
In search of indelible data
Instead, Object First wanted a system that combined the advantages of both; the immutability of a WORM disk with the convenience of online backup storage that could stay permanently connected to the network. And, naturally, they wanted a solution built specifically for Veeam.
This is what prompted them to begin creating Ootbi (it stands for ‘out of the box immutability’) three years ago, which eventually led to Object First.
“Ootbi is based on the idea of resiliency domains”, explains Cusimano. “You treat every single software stack you have as an individual resiliency domain. If one gets compromised, you still have the others to lean on and recover from.”
One component of this is the 3-2-1-1-0 rule: this means, storing three copies of your data, in addition to the original, across two media types, one of which must be off-site. Ootbi satisfies both of these by storing one in the cloud and the other on the customer’s premises on its own appliance’s NVME flash storage.
That leaves another one and a zero. The zero refers to zero errors, meaning that the storage solution must check that the data is clean going in so that you’re not restoring garbage later. The one means that one of the copies must be kept offline, or air-gapped, so that no one can tamper with it.
Ootbi didn’t air-gap this data by taking it physically offline. It wanted to handle the offline storage within its own network-connected appliance for maximum efficiency and user convenience.
“How do we make something where the backup lands on a box and there is no digital way that data can be removed from the box once it gets there?” says Cusimano. “That’s what we built.”
The inner workings of immutability
To build an immutable but connected backup appliance, Object First began by locking down the box as much as possible. Any attacker hoping for privilege escalation on the Linux-based product has a surprise in store: there’s no basic or root account that is accessible to users on its hardened version of their customized Linux OS.
Unsurprisingly given its name, Object First also opted for native object storage out of the box with its appliance. Whereas file and block-based storage models tend to store data in hierarchical structures, object storage stores data as uniquely-identifiable units with their own metadata in a single bucket.
Object storage has its historical drawbacks, the main one being its slower speed relative to file and block approaches. However, this is a backup appliance rather than a transactional one, and in any case it uses extremely fast NVME flash for write caching.
Because it’s built exclusively for Veeam, the technology also takes advantage of some proprietary work that Veeam did in building its data communications on the Amazon S3 API andVeeam’s SOS (Smart Object Storage) API. That enables the backup appliance to eke more performance out of Amazon’s cloud-hosted Simple Storage Service than other solutions can, Cusimano says. Ootbi also avoids any compression or de-duplication overhead because Veeam already takes care of those tasks.
Tight integration gives Ootbi support for all Veeam functionality, including simple backup, restore, disaster recovery, Instant Recovery, SureBackup, and hybrid scenarios. The appliance can run failed Instant Recovery workloads directly from backup within minutes, according to Object First.
Object storage also scales quickly and simply thanks to the GUID object labelling. This makes it good at scaling to handle large amounts of static, unstructured data.
“Because the concept was created in the last 20 years, it doesn’t have the kind of baggage that that file or block carries,” he adds.
The company not only configured its own hardened Linux distribution but also its own customized file system that communicates using the S3 API, which while developed by Amazon is now available as an open protocol.
“We’ve modified our own file system and we’ve created our own object storage code base,” Cusimano says. “That’s proprietary, so we’re running our own special sauce on this very normal box.”
The S3 API enabled Object First to take advantage of object lock. This introduces write-once-ready-many (WORM) immutability to stop an attacker doing anything even if they did somehow compromise the box. Explicitly built for object storage, it has two modes: governance, and compliance.
Governance mode prevents people overwriting, deleting, or altering the lock settings of a stored object unless they have special permissions. Compliance mode, which is the only mode used in Ootbi’s immutable storage, prevents any protected object from being altered or deleted by anyone for the designated retention period (set by the user in Veeam Backup and Recovery).
Software is key
The hardware is effectively a JBOD appliance, with up to ten 16Tb hard drives, another hot spare drive, and a 1.6Tb NVME that acts as a data cache. The hard drives form a RAID 6 array, storing data parity information twice, so that data is recoverable even if two disks fail. This gives customers up to 128Tb of available backup capacity, along with fast data reading thanks to multi-disk striping.
Data arrives from Veeam through two 10Gbit/sec NICs and lands on the NVME cache, which provides a 1Gb per second write speed per node.
The system is designed with expandability in mind. Customers can build a cluster of up to four Ootbi appliances, adding nodes when necessary. This not only increases capacity, but also speed, as each appliance’s built-in NIC provides another 1Gb/sec of write speed. It only supports a maximum four-node implementation today, but that’s because the company is a small startup focusing on its first sales. The design of its software architecture will allow it to increase that threshold as demand comes in from customers, Cusimano says.
Object First also tailored the system for usability, with an interface that relatively non-technical people can use.
“There’s no operating system updates. There’s nothing they have to do to make this thing work. You plug it in, you rack and stack the box, you hook it up to your network. You go through two different NIC configurations inside of a text user interface, give it a username and password, and you’re configured,” Cusimano says. The system automatically optimises its storage, minimising the amount of on-site storage expertise that customers need.
Data backups alone aren’t a gold-plated protection against more modern ransomware business models. Double-extortion ransomware gangs will steal your data even if they can’t encrypt it, meaning that restoring scrambled files will only solve half of your problems.
With that said, backup protection forms a critical part of a multi-layered defence-in-depth solution that should include employee awareness, anti-phishing scans and malware protection. It will enable you to continue operating after a ransomware attack, making that data immutability worth every penny of your investment.
Sponsored by Object First.
Dell goes all-out on GenAI

Dell is hoping a splash of generative AI can loosen wallets and shift more of its software, server, storage and ultimately PC sales.
It’s made three moves in the space in recent days, appointing ISG head Jeff Boudreau as CAIO – Chief AI Officer; bringing out customizable validated gen AI systems and services; and yesterday pushing the narrative as hard as it can with securities analysts.

At the securities analysts meeting Michael Dell claimed: “We are incredibly well-positioned for the next wave of expansion, growth and progress. … AI, and now generative AI, is the latest wave of innovation and fundamental to AI are enormous amounts of data and computing power.”
This is set to increase Dell’s server and storage revenues such that its forecast CAGR for ISG, its servers and storage division, is increasing from the 3 to 5 percent range declared at its September 2021 analyst day to a higher 6 to 8 percent range. The PC division, CSG, CAGR stays the same as it was back in 2021 – 2 to 3 percent.

Wells Fargo analyst Aaron Rakers tells subscribers that the ISG CAGR uplift has been driven by factors such as a ~$2 billion order backlog (significantly higher pipeline) for its AI-optimized XE9680 servers exiting the second fiscal 2024 quarter. This is the fastest ramping server in Dell’s history.

AI servers, which have a 3 – 20 x higher $/unit value than traditional PowerEdge servers, should account for ~20 percent of the next quarter’s server demand. CFO Yvonne McGill said the XE9860 has a <$200k ASP, about 20 times more than the ordinary PowerEdge server.
Vice chairman and COO Jeff Clarke claimed Dell’s AI will enable its total addressable market (TAM) to grow by an incremental $900 million from 2019 to 2027, growing from $1.2 trillion to $2.1 trillion.
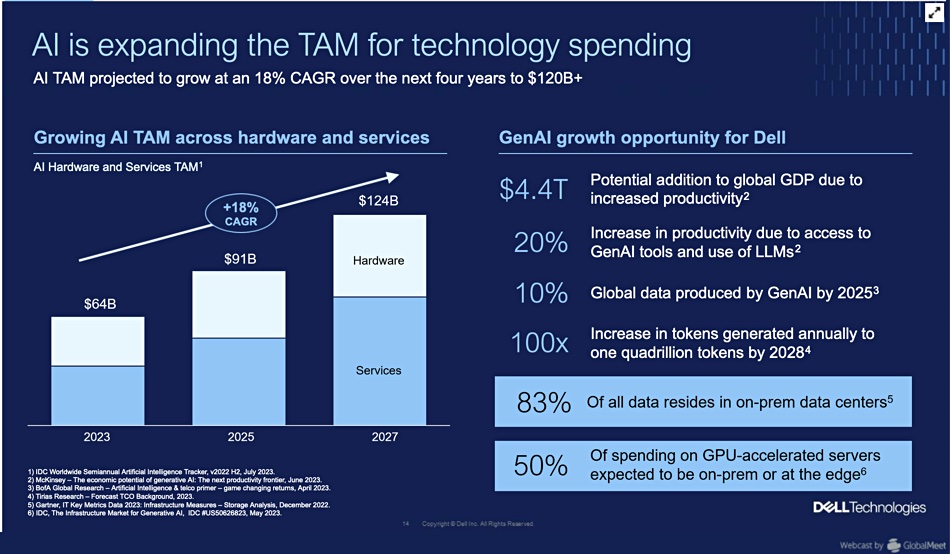
Data is growing at a +25 percent CAGR. Most companies’ data, 83 percent of it, is stored on premises, not in the public cloud, and represents a tremendous asset for AI processing. Dell thinks it could mean a 20 – 30 percent productivity and efficiency improvement for industries and economies. Some 10 percent of data could be produced by AI by 2025.
As data has gravity it expects AI processing will move to the data location point, ie, on-premises in data centers and edge sites. He thinks 50 percent of the spending on GPU-accelerated servers will be for data center or edge site location.
We are, Dell believes, in the starting phase of a significant AI demand surge. Clarke said gen AI is set to be the fastest-ever adopted technology, with 70 percent of enterprises believing AI will change the rules of the game, and 60 percent thinking AI will change the core fundamental cost structure of their organizations and change their product delivery innovation.
There are four emerging use cases: customer experience, software development, the role of sales. and content creation and management.
ISG president Arthur Lewis said leverage its market share lead in servers, with Dell capturing 43 percent of the growth in servers over the past 10 years, plus 38 percent of new industry storage revenue over the past 5 years. Dell, he said, has seen eight consecutive quarters of growth in midrange PowerFlex and 12 consecutive quarters of growth in PowerStore. ISG is focusing on higher margin IP software assets and next-generation storage architectures, such as PowerFlex (APEX Block Storage).
CSG President Sam Burd said AI will also be a positive PC demand driver. It AI promises immense productivity benefits for PC users and could be as revolutionary as the early PC days. In 2024 Dell will have PC architectures that will effortlessly handle more complex AI workloads, with on-board AI processing becoming the norm in the future.
Dell validated AI solutions
This AI-infused thinking presented to the analysts is what lies behind yesterday’s validated AI solutions announcement. Carol Wilder, Dell ISG VP for cross-portfolio SW, tells us Dell realizes AI has to be fueled with data. That means there has to be a unified data stack using an open scale-out architecture with decoupled compute and storage and featuring reduced data movement; data has gravity. Data needs discovering, querying and processing in-place. Customers will be multi-cloud users and will want to store, process, manage, and secure data across the on-premises data center and edge and also public cloud environments.
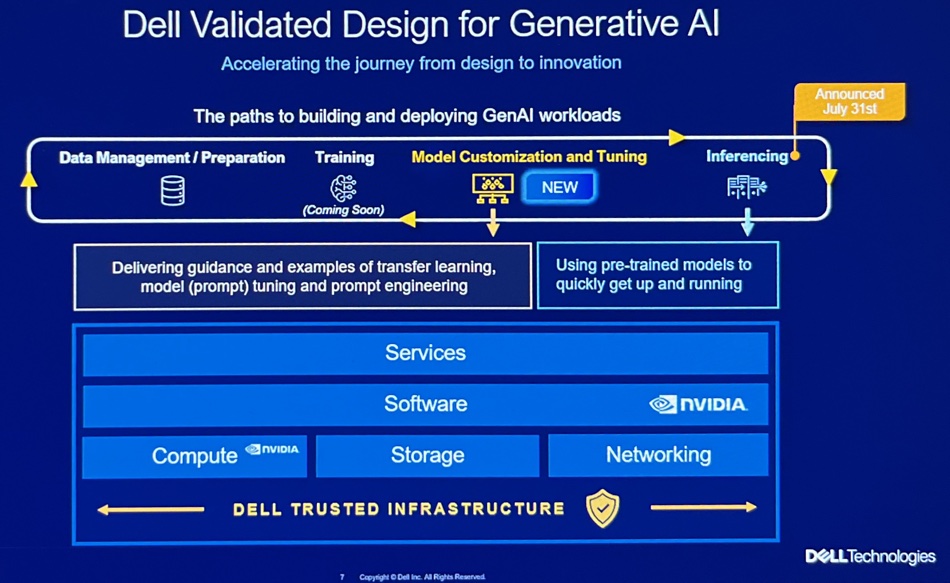
Customers are beginning gen AI adoption and the HW/SW stack is complex, hence Dell’s announcement of validated AI systems along with professional services services to help ease and simplify customers’ AI system adoption.
Looking ahead Wilder told us customers’ AI activities will be helped by giving the AI processing systems the widest possible access to data, and that means a data lakehouse architecture, with data integrated across the enterprise, and Dell will provide one. A slide shows its attributes and says it uses the Starburst Presto-based distributed query engine, and supports Iceberg and Delta lake formats.
Naturally it uses decoupled Dell PowerEdge compute and storage; its file (PowerScale) and object (ECS) storage.
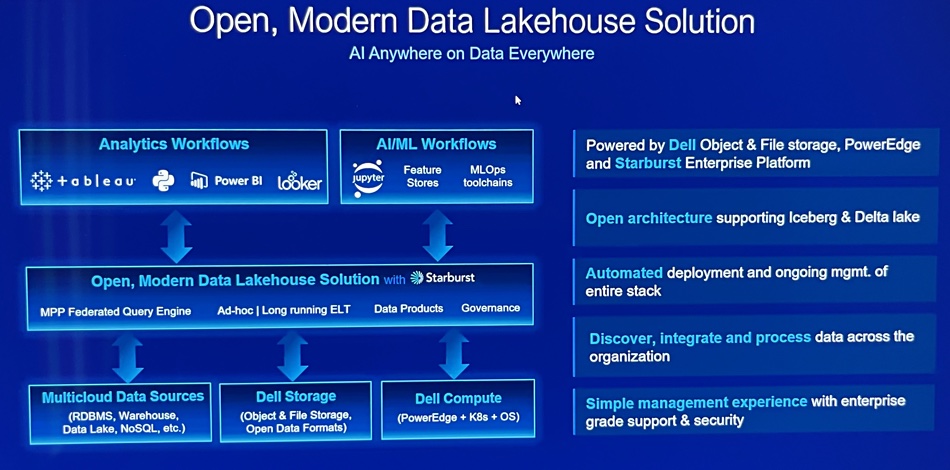
It will make data available first, to high-performance engines, and consolidate it later. We think there could be an APEX lakehouse service coming in the future.
Comment
Dell will be providing a lakehouse datastore to its customers. So far, in our storage HW/SW systems supplier world, only VAST Data has announced an in-house database it’s built for AI use. Now here is Dell entering the same area but with a co-ordinated set of server, storage, lakehouse and professional services activities for its thousands of partners and its own customer account-facing people to pour into the ears of its tens of thousands of customers. That’s strong competition.
No doubt Gen AI will enter Gartner’s Trough of Disillusionment, but Dell Technologies is proceeding on the basis that it will be a temporary shallow trough, transited quickly to the Slope of Enlightenment, with Dell’s AI evangelizing army pushing customers up it as fast as possible.
CoreWeave lists Backblaze as customer data store

CoreWeave, the mammoth GPU-as-a-Service supplier, has listed Backblaze as a store for its customers’ data.
Cloud storage supplier Backblaze has a strategic partnership with CoreWeave and can deliver a cost saving over Amazon S3, which is used as a store for CoreWeave customers’ data. Backblaze, with $24.6 million in revenues last quarter, is a financial sprat in comparison to CoreWeave, which raised $421 million in a B-round last April, another $200 million in May, plus $2.3 billion debt financing in August.
Our thinking is that AI is expensive. This partnership enables AI developers to save cash by not buying on-premises equipment and not using big 3 public cloud object storage resources.
CoreWeave states that automatic volume backups are supported using Backblaze via CoreWeave’s application catalog.
It suggests customers should use Backblaze to store the data needed to fuel AI models running on CoreWeave GPUs and can put the money saved towards their overall AI costs.
Backblaze bases its storage facilities on pods of disk drives, its own design of storage enclosures, with closely watched drive failure rates and high reliability software schemes to keep data safe. It used more than 241,000 disk drives as of August 2023 and stores many petabytes of customer data.
CoreWeave announced a deal with VAST Data to use its all-flash storage for customers’ real-time and nearline storage needs in its datacenters last month. Backblaze now has a new marketing/selling angle – providing long-term cloud storage for VAST customers.
Comment
This is a terrific boost for Backblaze, which is now swimming alongside cloud storage whales and has received a leg-up. We can expect the amount of data stored by CoreWeave customers to rise substantially over the next few quarters with Backblaze capacity used rising in lockstep.
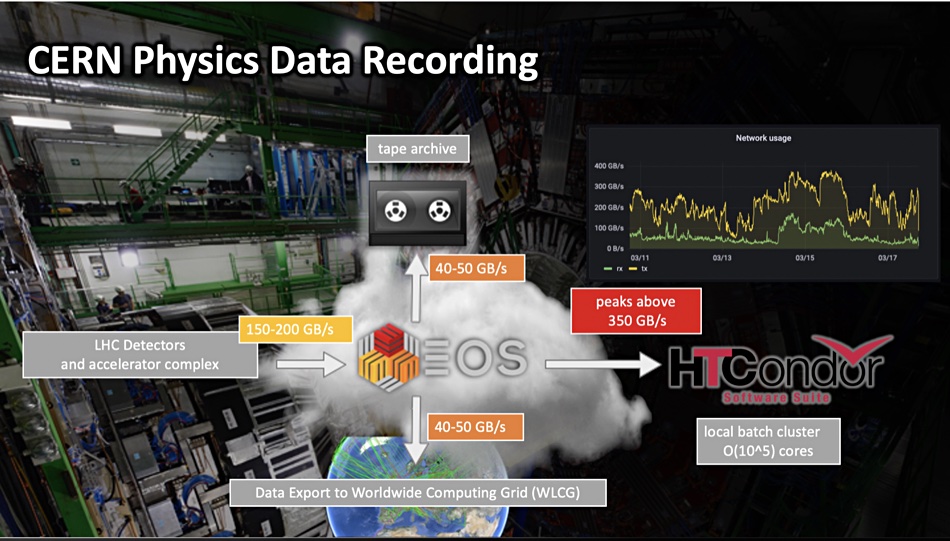
CERN’s exabyte-plus of data needs exabyte-class EOS filesystem

The reason that CERN, Europe’s atom-smashing institution, can store more than an exabyte of online data comes down to its in-house EOS filesystem.
EOS was created by CERN staff in 2010 as an open source, disk-only, Large Hadron Collider data storage system. Its capacity was 18PB in its first iteration – a lot at the time. When atoms are smashed into one another they generate lots of sub-atomic particles and the experiment recording instruments generate lots of data for subsequent analysis of particles and their tracks.
The meaning of the EOS acronym has been lost in time; one CERN definition is that it stands for EOS Open Storage, which is a tad recursive. EOS is a multi-protocol system based on JBODs and not storage arrays, with separate metadata storage to help with scaling. CERN used to have a hierarchical storage management (HSM) system, but that was replaced by EOS – which is complemented with a separate tape-based cold data storage system.
There were two originial EOS data centers: one at CERN in Meyrin, Switzerland, and the other in the WIGNER center in Budapest, Hungary. They were separated by 22ms network latency in 2015. CERN explains that EOS is now deployed “in dozens of other installations in the Worldwide LHC Computing GRID community (WLCG), at the Joint Research Centre of the European Commission and the Australian Academic and Research Network.”
EOS places a replica of each file in each datacenter. CERN users (clients) can be located anywhere, and when they access a file the datacenter closest to them serves the data.
EOS is split into independent failure domains for groups of LHC experiments, such as the four largest particle detectors: LHCb, CMS, ATLAS, and ALICE.
As shown in the diagram below, the EOS access path has one route for metadata using an MGM (metadata generation mechanism) service and another route for data using FST. The metadata is held in memory on metadata service nodes to help lower file access latency. These server nodes are active-passive pairs with real-time failover capability. The metadata is persisted to QuarkDB – a high-availability key:value store using write-ahead logs.
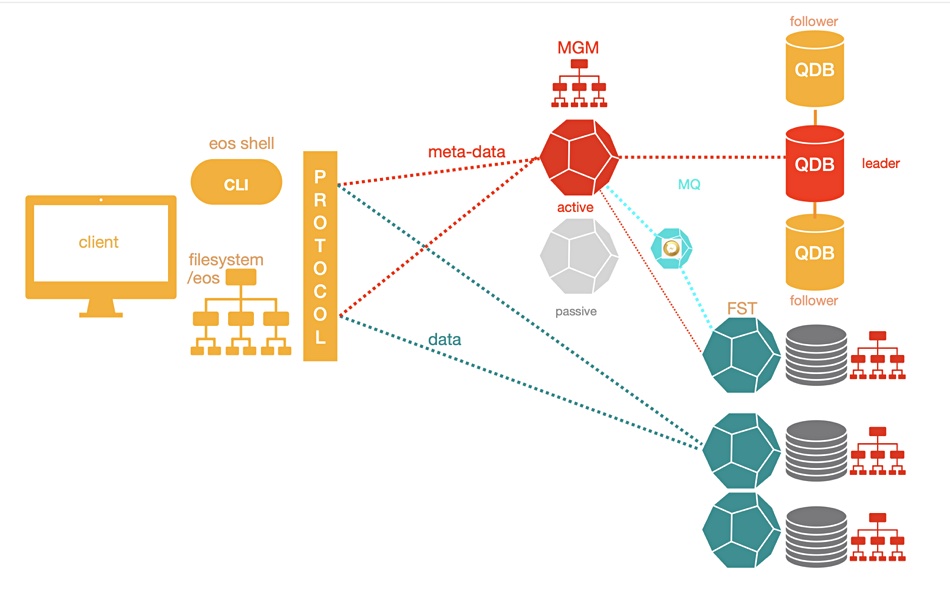
Files are stored on servers with locally-attached drives, the JBODs, distributed in the EOS datacenters.
Each of the several hundred data-holding server nodes has between 24 and 72 disks, as of 2020. Files are replicated across JBOD disks, and EOS supports erasure coding. Cluster state and configuration changes are exchanged between metadata servers and storage with an MQ message queue service.
The MGM, FST and MQ services were built using an XRootD client-server setup, which provides a remote access protocol. EOS code is predominantly written in C and C++ with a few Python modules. Files can be accessed with a Posix-like FUSE (Filesystem in Userspace) SFTP client, HTTPS/WebDav or the Xroot protocol – also CIFS (Samba), S3 (MinIO), and GRPC.
The namespace (metadata service) of EOS5 (v5.x) runs on a single MGM node, as above, and is not horizontally scalable. There could be standby nodes to take over the MGM service if the active node becomes unavailable. A CERN EOS architecture document notes: “The namespace is implemented as an LRU driven in-memory cache with a write-back queue and QuarkDB as external KV store for persistency. QuarkDB is a high-available transactional KV store using the RAFT consensus algorithm implementing a subset of the REDIS protocol. A default QuarkDB setup consists of three nodes, which elect a leader to serve/store data. KV data is stored in RocksDB databases on each node.”
Client users are authenticated, with a virtual ID concept, by KRB5 r X509, OIDC, shared secret, JWT and proprietary token authorization.
EOS provides sync and share capability through a CERNbox front-end service with each user having a terabyte or more of disk space. There are sync clients for most common systems.
The tape archive is handled by CERN Tape Archive (CA) software, and it uses EOS as the user-facing, disk-based front end. Its capacity was set to exceed 1EB this year as well.
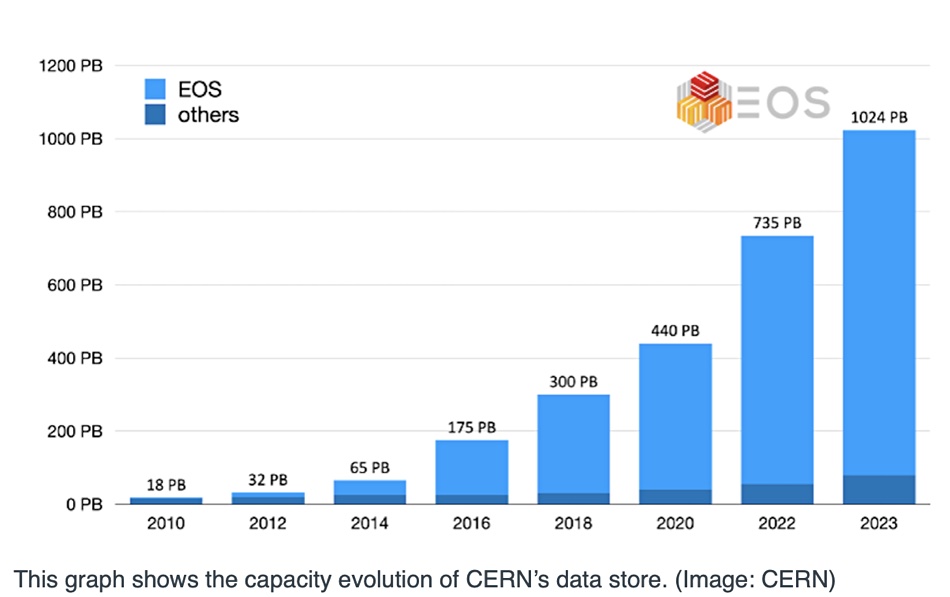
Exabyte-level EOS can now store a million terabytes of data on its 111,000 drives – mostly disks with a few SSDs – and an overall 1TB/sec read bandwidth. Back in June last year it stored more than 7 billion files in 780PB of disk capacity using more than 60,000 disk drives. The user base then totalled 12,000-plus scientists from institutes in 70-plus countries. Fifteen months later the numbers are even larger, and set to go higher. The EOS acronym could reasonably stand for Exabyte Open Storage.
Storj is Adobe’s Premiere Pro storage cloud

Decentralized storage provider Storj has announced a new integration with Adobe Premiere Pro, and says its revenues are growing 226 percent year on year.
Premiere Pro is professional video editing software used by artists and editors worldwide. They need to collectively work on media projects, such as special effects and video sequencing, and share project work with other team members. In other words, media files need storing and moving between the teams. Storj supplies a worldwide cloud storage facility based on spare datacenter capacity organized into a single virtual data store with massive file and object sharding across multiple datacenters, providing error-coded protection and parallel access for file and object read requests. Adobe has selected Storj as its globally distributed cloud storage for Premiere Pro.
Storj’s 226 percent growth has brought it customers and partners such as Toysmith, Acronis, Ad Signal, Valdi, Cribl, Livepeer, Bytenite, Cloudvice, Amove, and Kubecost. The growth has been helped by a University of Edinburgh report showing a a 2-4x factor improvement in Storj’s transfer performance over the prior year. It found speeds of up to 800 Mbps when retrieving large quantum physics data sets from Storj’s network.
The university’s Professor Antonin Portelli stated: “You can really reach very fast transfer rates thanks to parallelism. And this is something which is built-in natively in the Storj network, which is really nice because the data from many nodes are scattered all over the world. So you can really expect a good buildup of performances.”
Storj says it reduces cloud costs by up to 90 percent compared to traditional cloud providers, and also cuts carbon emissions by using existing, unused hard drive capacity. However, these hard drives have embodied carbon costs, so-called Scope 3 emissions accumulated during their manufacture, which will be shared between the drive owner and the drive renter (Storj).
It also cites a Forrester Object Storage Landscape report which suggests “decentralization of data storage will disrupt centralized object storage providers as computing shifts to the edge.” Storj is listed as one of 26 object storage vendors covered by the report, which costs $3,000 to access.
Bootnote
Scope 1, 2, and 3 emissions were first defined in the Green House Gas Protocol of 2001.
- Scope 1 emissions come directly from an organization’s own operations – burning fuel in generators or vehicles.
- Scope 2 emissions come indirectly from the energy that an organization buys, such as electricity, the generation of which causes greenhouse gas emissions.
- Scope 3 emissions are those an organization is indirectly responsible for when it buys, uses, and disposes of products from suppliers. These include all sources not within the Scope 1 and 2 boundaries.
The generative AI easy button: How to run a POC in your datacenter

Commissioned: Generative AI runs on data, and many organizations have found GenAI is most valuable when they combine it with their unique and proprietary data. But therein lies a conundrum. How can an organization tap into their data treasure trove without putting their business at undue risk? Many organizations have addressed these concerns with specific guidance on when and how to use generative AI with their own proprietary data. Other organizations have outright banned its use over concerns of IP leakage or exposing sensitive data.
But what if I told you there was an easy way forward already sitting behind your firewall either in your datacenter or on a workstation? And the great news is it doesn’t require months-long procurement cycles or a substantial deployment for a minimum viable product. Not convinced? Let me show you how.
Step 1: Repurpose existing hardware for trial
Depending on what you’re doing with generative AI, workloads can be run on all manner of hardware in a pilot phase. How? There are effectively four stages of data science with these models. The first and second, inferencing and Retrieval-Augmented-Generation (RAG), can be done on relatively modest hardware configurations, while the last two, fine-tuning/retraining and new model creation, require extensive infrastructure to see results. Furthermore, models can be of various sizes and not everything has to be a “large language model”. Consequently, we’re seeing a lot of organizations finding success with domain-specific and enterprise-specific “small language models” that are targeted at very narrow use cases. This means you can go repurpose a server, find a workstation a model can be deployed on, or if you’re very adventurous, you could even download LLaMA 2 onto your laptop and play around with it. It’s really not that difficult to support this level of experimentation.
Step 2: Hit open source
Perhaps nowhere is the open-source community more at the bleeding edge of what is possible than in GenAI. We’re seeing relatively small models rivaling some of the biggest commercial deployments on earth in their aptitude and applicability. The only thing stopping you from getting started is the download speed. There are a whole host of open-source projects at your disposal, so pick a distro and get going. Once downloaded and installed, you’ve effectively activated the first phase of GenAI: inferencing. Theoretically your experimentation could stop here, but what if with just a little more work you could unlock some real magic?
Step 3: Identify your use cases
You might be tempted to skip this step, but I don’t recommend it. Identify a pocket of use cases you want to solve for. The next step is data collection and you need to ensure you’re grabbing the right data to deliver the right results via the open source pre-trained LLM you’re augmenting with your data. Figure out who your pilot users will be and ask them what’s important to them – for example, a current project they would like assistance with and what existing data they have that would be helpful to pilot with.
Step 4: Activate Retrieval-Augmented-Generation (RAG)
You might think adding data to a model sounds extremely hard – it’s the sort of thing we usually think requires data scientists. But guess what: any organization with a developer can activate retrieval-augmented generation (RAG). In fact, for many use cases this may be all you will ever need to do to add data to a generative AI model. How does it work? Effectively RAG takes unstructured data like your documents, images, and videos and helps encode them and index them for use. We piloted this ourselves using open-source technologies like LangChain to create vector databases which enable the GenAI model to analyze data in less than an hour. The result was a fully functioning chatbot, which proved out this concept in record time.
Source: Dell Technologies
In Closing
The unique needs and capabilities of GenAI make for a unique PoC experience, and one that can be rapidly piloted to deliver immediate value and prove its worth to the organization. Piloting this in your own environment offers many advantages in terms of security and cost efficiencies you cannot replicate in the public cloud.
Public cloud is great for many things, but you’re going to pay by the drip for a PoC, it’s very easy to burn through a budget with users who are inexperienced at prompt engineering. Public cloud also doesn’t offer the same safeguards for sensitive and proprietary data. This can actually result in internal users moving slower as they think through every time they use a generative AI tool whether the data they’re inputting is “safe” data that can be used with that particular system.
Counterintuitively, this is one of the few times the datacenter offers unusually high agility and a lower up front cost than its public cloud counterpart.
So go forth, take an afternoon and get your own PoC under way, and once you’re ready for the next phase we’re more than happy to help.
Here’s where you can learn more about Dell Generative AI Solutions.
Brought to you by Dell Technologies.
Veeam moves into backup-as-a-service for Microsoft fans with Cirrus grab

Veeam can now back up Microsoft 365 and Azure with its Cirrus by Veeam service.
Backup delivered as a Software-as-a-service (SaaS) has been the focus of suppliers such as Asigra, Clumio, Cohesity, Commvault with its Metallic offering, Druva, HYCU, and OwnBackup, which believe SaaS is the new backup frontier. Up until now, Veeam has been largely absent from this market, apart from a February 2023 partnership deal with Australian business CT4. This has now blossomed into buying CT4’s Cirrus cloud-native software, which provides the BaaS layer on top of Veeam’s backup and restore software.
CTO Danny Allan said the company is “the #1 global provider of data protection and ransomware recovery. We’re now giving customers those trusted capabilities – for Microsoft 365 and for Microsoft Azure – delivered as a service.”
Cirrus for Microsoft 365 builds on Veeam Backup for Microsoft 365 and delivers it as a service. Cirrus Cloud Protect for Microsoft Azure is a fully hosted and pre-configured backup and recovery offering.
Veeam says its customers now have three options for protecting Microsoft 365 and Azure data:
- Cirrus by Veeam: a SaaS experience, without having to manage the infrastructure or storage.
- Veeam Backup for Microsoft 365 and Veeam Backup for Microsoft Azure: Deploy Veeam’s existing software solutions for Microsoft 365 and Azure data protection and manage the infrastructure.
- A backup service from a Veeam service provider partner: Built on top of the Veeam platform, with value-added services unique to the provider’s area of expertise.
Veeam has invested in Alcion, a SaaS backup startup founded by Niraj Tolia and Vaibhav Kamra. The two founded container app backup outfit Kasten, which was bought by Veeam for $150 million in 2020. The company now has two BaaS bets, with Cirrus looking much stronger than Alcion. The company and its partners can now sell the Cirrus Microsoft 365 and Azure BaaS offerings into Veeam’s 450,000 customer base and hint at roadmap items extending coverage to other major SaaS app players.
It has to extend its BaaS coverage to other major SaaS apps such as Salesforce and ServiceNow, and on to second tier SaaS apps as well, if it is going to catch up with the existing SaaS backup suppliers. That means it has to decide how to solve the connector-build problem to extend its coverage to the tens of thousands of SaaS apps in existence. Our thinking is that it will rely on its existing market dominance and attractiveness as a backup supplier, and provide an SDK for SaaS app developers to use.

When the BaaS partnership was announced, Dan Pearson, CT4’s founder, CEO and CTO, said: “We recognize that technologies are continually evolving, along with the ever-changing needs of our clients, so we’re developing new Veeam-powered offerings like Cirrus for Cloud Protect Azure, Cirrus for Cloud Protect AWS, and Cirrus for Salesforce. Our vision is for Cirrus to be considered the only data protection solution for SaaS products globally. This is the cornerstone of our business and go-to market strategy, and Veeam is supporting us every step of the way.”
Not so much now. CT4 is still a partner, but Cirrus development is in Veeam’s hands alone. We think it will throw development resources at it to become a major force in the market with common management and security across its on-premises VM, container, and SaaS backup offerings.
Cirrus by Veeam is available now via here, on the Azure Marketplace, and all existing Cirrus channels, and will soon be expanded to Veeam’s additional routes to market. Veeam will launch a new, enhanced, and fully integrated version of the BaaS offering in Q1 2024, available through Veeam service providers, the Microsoft Azure marketplace, and Veeam’s online store.