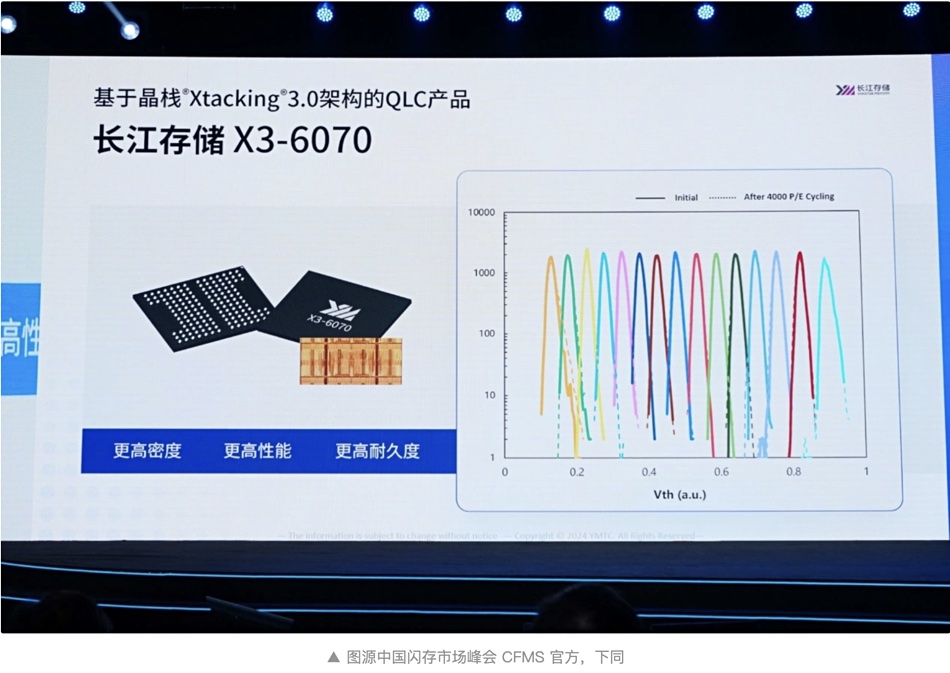
DataStax is buying Langflow, a large language model (LLM) development pipeline startup, to make building LLMs using proprietary data easier.
DataStax supplies its Astra DB database with vector embeddings support as a service. Vector embeddings are coded representations of aspects of text, images, videos, audio files, and other digital items that are used in the semantic searches by LLMs in AI inference tasks.
Langflow is an open source, no-code chatbot builder with chatbot executable node elements connected in a flow or stream pipeline structure through dynamic graphs. It can be used to fine-tune LLMs from spreadsheets. A partial or full pipeline can be saved as a composable building block entity for reuse with a drag-and-drop GUI. Langflow can be used to develop retrieval-augmented generation (RAG) apps that enable LLMs to use an organization’s proprietary data. This is a hot development focus for DataStax.
Chet Kapoor, DataStax CEO and chairman, said in a statement: “Langflow is focused on democratizing and accelerating generative AI development for any developer or company, and in joining DataStax, we’re working together to enable developers to put their wild new generative AI ideas on a fast path to production.”
Langflow CEO Rodrigo Nader, said that by joining the DataStax team he hopes to supercharge its ability to “grow the Langflow platform, bringing it to more researchers, developers, enterprises and entrepreneurs working on generative AI applications.”

“With DataStax, we will be fully focused on the execution of our product vision, roadmap, and community collaboration, and will continue to add to the greatest breadth of integrations across different AI ecosystem projects and products – including more data sources and databases, models, applications and APIs.”
Langflow was founded in 2020 by data scientist and CEO Rodrigo Nader and CTO Gabriel Luiz Freitas Almeida as a self-funded machine learning consultancy called Logspace. It launched Langflow in 2023.
LinkedIn lists seven Langflow employees in total. It is a remote working company with headquarters located in Uberlândia, Minas Gerais, Brazil.
DataStax says Langflow makes it simpler for developers to build RAG applications using partners such as LangChain and LlamaIndex. They can test, reuse, and share flows to iterate on RAG applications with fine-grained control, which – we’re told – can dramatically speed up deployment and drive better results.
There is already a large GenAI ecosystem of tools, components, chains, and integrations, and more than 10,000 Langflow developers. Langflow enables them to more rapidly determine if chatbot development issues are with data flows, models, or changing component integrations.
Langflow integrates with AI ecosystem frameworks supported by RAGStack, DataStax’s out-of-the-box RAG offering. This ensures developers can utilize the best generative AI technologies, streamlining the development of sophisticated applications, and providing enterprise support for companies to deploy RAG at scale.
DataStax now says it offers a complete one-stop shop for building GenAI RAG apps. Customers can build production-ready RAG applications using Python and a large ecosystem of custom components. The Langflow acquisition cost was not revealed.
Langflow will operate as a separate DataStax entity, focusing on product development and community collaboration. For more information, read the DataStax blog on this acquisition, also Langflow’s blog, in which the Langlow team assert: “Langflow will forever be open, free, and agnostic!”