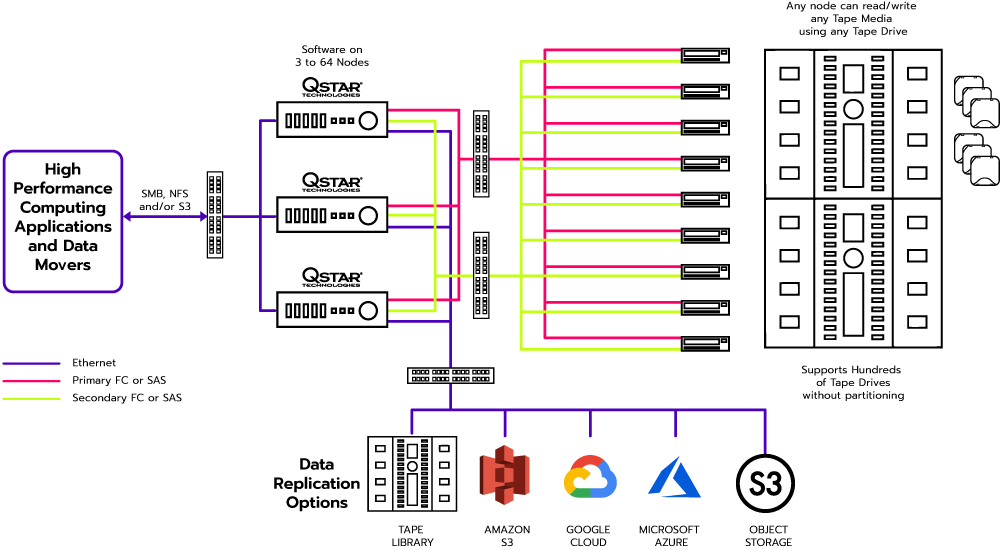
QStar Technologies, the provider of “active archive” software for tape libraries, is expanding the reach of stored data with the launch of its QStar Global ArchiveSpace offering.
The technology is a multi-node gateway solution that supports the massive archive needs of high performance computing (HPC), AI/ML, hyperscalers, media and entertainment, and video surveillance environments. It creates a multi-node Windows or Linux-based archive using Global Namespaces for SMB shares, NFS mounts or S3 buckets.
Installing on Windows or Linux allows users to take advantage of their preferred security model, using either Active Directory or LDAP. Users can run between three and 64 nodes.
Every node can access any tape media and use any tape drive to read or write data. Global ArchiveSpace can replicate content for data protection to same or different archive technologies, and present a unified view of the archived data through SMB or NFS file systems and/or S3 cloud interfaces.
At the IT Press Tour in Rome last week, Riccardo Finotti, CEO of QStar Technologies, said: “With this solution, you have availability across all locations, automated data orchestration, and a very high capacity archive with reduced running costs.”
ArchiveSpace is an extension of QStar Archive Manager, which is one solution already offered by the likes of Cohesity, Rubrik, HYCU and Hammerspace, to help serve the cloud data management needs of their end customers.
Qstar graphic.
Users can upgrade their existing QStar licenses to take advantage of the “improved resilience and performance” ArchiveSpace promises. It is designed to support all tape libraries from all vendors, but particularly the largest tape libraries available on the market today, using any version of LTO or proprietary tape drive technology.
It can be used with the IBM TS4500, Oracle SL8500, Quantum Scalar i6000 and Spectra Logic TFinity Exascale platforms, supporting hundreds of tape drives and an unlimited media count, allowing hundreds of Petabytes or Exabytes.
A multi-write option groups tape drives together for higher performance by allowing a single stream to be written to multiple tape drives based on policies. In addition, mirroring and replication options protect content by automatically creating copies of data within the library, to another tape library, or to private/public clouds. As tape libraries under management do not need to be partitioned, administration complexity is reduced.
Hammerspace added archival tape system support to its Global Data Environment (GDE) earlier this year []. Its parallel file system covers data in globally distributed and disparate sites, and enables it to be located, orchestrated, and accessed as if it were local.
Hammerspace is working with three active archive suppliers as part of its tape effort, including Grau Data, PoINT Software & Systems and QStar Technologies.
Dave Thomson, SVP of sales and marketing at QStar Technologies, said at the time: “QStar software makes archived data on tape quickly and easily accessible through an S3 interface/bucket. Together with Hammerspace, we can help our current and future customers manage their data across multiple storage platforms, including tape as an active archive.”
QStar Technologies was founded in 1987, and has main offices in Denver, Colorado and Milan, Italy. Its customers include the University of Cambridge, Raytheon, Walt Disney Animation Studios, Turner, Fox, Walmart, and Deutsche Bank.
Interview: With Cohesity acquiring much of the Veritas data protection business, the residual company will already be highly profitable, taking half a billion dollars a year, employing more than 1,500 people, and determined to grow.
Cohesity is buying Veritas’s NetBackup business but not its Backup Exec (BE), data compliance, and InfoScale storage management operations. These will be combined in a spun-off corporation, code named DataCo, to be led by Lawrence Wong, Veritas chief strategy officer and SVP for Products and Strategy.
B&F talked with CEO in waiting Lawrence Wong, and heard about DataCo’s organization and plans. The interview has been lightly edited for brevity.
Lawrence Wong
B&F: Give me the headline overview of DataCo.
Lawrence Wong: It’s a supercharged startup with around $500 million in revenues and 1,500 employees. It is certainly a good cohort to be in. There’s many, many, many companies of similar size and scope in the software industry. Certainly as we embark on our life as a standalone company, you would imagine that we would intend to pursue growth. And we will do that through continued investment. We believe that there’s a tremendous amount of potential for us to thrive as an independent company.
B&F: Are you profitable at the moment?
Lawrence Wong: Yes, we are actually very profitable. That is one of the advantages that we have that, let’s say, perhaps a traditional startup would not have.
We’re starting off essentially with three businesses with a significant set of blue chip customers. These are the Fortune 500, Fortune 100 customers. In fact, for both InfoScale, and for Data Compliance, we have over 21 percent of the Fortune 500 as customers. These are the largest of the largest banks, largest financial institutions; the most enviable and difficult and most demanding customers, as you would imagine. We’re very lucky and fortunate to have them as customers.
And similarly, with BE, we’ve got thousands of customers already established. So it’s not a issue of whether these products are relevant in the market, or whether there’s a product market fit that you would normally be going through as a traditional startup.
The analogy I actually use internally with our people is that we’re sort of adult children who have left the parents’ house, and now we’re going to stick out on our own. And while normally, you might have a little bit of trepidation doing that, going off to college or something like that, as a young adult, there’s nothing for us to worry about here.
Because we’re established adults with essentially solid credit profiles and solid financial profiles. And what we really have is an opportunity to build, rebuild the company, and do everything the way that we believe it should be done. With every company there’s opportunity to improve, right? So there’s an opportunity for us to use this as a catalyst to actually do that. And that’s exactly what we’re doing.
B&F: Take me through how you describe the three separate business units that you’re going to be setting up.
Lawrence Wong: First the businesses themselves will all have their own customer-facing teams, they will have their own product teams. And what they will share across all three is traditional head office functions. So they’ll share executive management, they’ll share finance; that gives them the ability to thrive, because they will be moving at their pace for their market. Each one of these businesses solve different problems for the enterprise customer; they have different buyers. And they also also have different stages of where they are in the industry. So I’ll go through each one of these.
With InfoScale, this has been a business that’s been part of Veritas from the beginning. It’s actually one of their core offerings. It continues to be very relevant, very sticky with our customers.
I was just on a call with one of the largest financial institutions in the world, inquiring about what we plan to do. I was unequivocal about sharing with him that we are going to be continuing to invest. We’re going to be continuing to maintain the relevancy of this product, we’re actually going to be investing and taking it to the future.
A product like InfoScale, allows them actually to very easily come into and out of the public clouds. So there’s a forward gear and a reverse gear, like I always like to describe it, and gives them a reverse gear. And they’re very pleased with that.
And of course, the next generation of architectures, when you talk about disaggregated architectures, as well as traditional architectures; that’s where InfoScale was. It’s evolving to being able to support that resiliency across both disaggregated architectures and traditional architecture. We’re working with our customers to think through what that intended future state looks like as they evolve. We will evolve with them. So we’re very relevant, and they’re very excited to hear that we’re going to continue to invest. So that’s the first product. It’s about $3 billion TAM (total addressable market) with very steady 5-6 percent growth.
B&F: And the second business unit?
Lawrence Wong: The second business is our Data Compliance business. That sits in a $10 billion TAM, which is actually growing quite significantly at over 11 percent.
Data compliance used to be about back room, regulatory things. Those guys over there in the closet who were risk managers have now moved to the forefront of board level conversations around data, provenance, regulatory compliance, and data privacy. And that has thrust this space now into our minds as the next big potential growth area for DataCo, principally because the environment around us, particularly with the rise of generative AI.
The hype cycle that we’re in with generative AI has really thrust all of these issues to the forefront.
The European Union and the United States are thinking about what sort of governmental regulations need to be there. How do we think about privacy? What sort of liability is there, particularly if you’ve got a machines making decisions? How do you test and ensure the provenance of the data that goes into that GenAI model.
That’s exactly what our software does. Our software allows you to track provenance, allows you to understand what sort of Personally Identifiable Information (PII) you have in your data, where that PII is located. It is all of a sudden, just like how cybersecurity has made backup software exciting and sexy.
I’m thrilled that the rise of AI has brought sexy back to data compliance. We intend that to be a growth vector for DataCo.
It is a highly profitable business today; roughly several $100 million ARR a year and we’ve got over 20 customers today that pay us over a million dollars in ARR. We’ve grown that, by the way, from a handful of customers, less than ten, to over 20 in the last 18 months. We see that potential, and we’re going to continue to invest here. We’re assured that this would be one of the areas in which we see tremendous progress.
B&F: And the third business unit?
Lawrence Wong: BE is one of the original data protection products that were out there for Veritas¹. And then Veritas acquired NetBackup, many, many years ago. BE continues to be a very relevant product for our SMB base now, where we see a huge opportunity today, going forward. It’s roughly a $50 million ARR year business. It is highly profitable. We’ve continued to invest in its roadmap and evolve it. We have a very loyal and enthusiastic customer base.
BE is focused on the SMB; it does not compete in the enterprise space. But we believe very strongly that the SMBs are the backbones of every major economy out there, right from the emerging market to the to the mature markets. They deserve phenomenal data resilience and backup capabilities the same way that a large enterprise would.
Large enterprises experience cyberattacks. They’ve got IT practitioners and CISOs and security experts to help mitigate all this. But I always go back to the SMB; what do they have? We have a mission to help them essentially get that same cyber-resilience that these large enterprise companies have, because they are also going to experience the same attacks.
I think there is a tremendous opportunity to provide something that’s easy, simple to use, and consume and purchase, and bring these folks the same degree, if not better, protection for their data and their systems that we historically provided … to the enterprise. Of course, there’s many folks in this space, but I think it’s a big ocean. And there’s lots of opportunity out there.
And I would say, message to Veeam, is that we are back. We know Veeam has grown off the back of BE. There’s no secret. The industry knows that Veeam had always attacked our base. We’re going to be fighting back now, we’re going to be attacking back.
B&F: You’re stable, you’re well funded, you have an existing experienced team, you have a loyal customer base. It’s not like you’re in trouble, far from it.
Lawrence Wong: In fact, I always say it’s our opportunity to really build on all of this firm, great foundation that we have to thrive as DataCo because all three of these businesses; they’re all data businesses in the sense that they all sit within the secular trends that will only continue to grow and become more important.
We all talk about data as the new oil. Well, all three of these businesses sit right in that secular tailwind. So I think having that wind in our back, having the established capabilities that we have, having the stability that we have, as an established player in the space, I think those are a lot of wonderful attributes to start off with, as this new-age startup. Because a traditional startup would never have that. We have that advantage. And we should be using that. And building off of that.
B&F: Do you have a date for when you achieve independence?
Lawrence Wong: Right now, we are in the throes of our separation activities. And as you would imagine, there are some other activities around getting our financing and regulatory pieces in order. Right now the thinking is the end of the year is when we would close the transaction.
Upon transaction closed, that’s when we would be independent as DataCo. We’re working on our name as well. We’ve engaged an agency to help us think of a new name.
Coming back to the transaction, as part of the transaction, the NetBackup data protection business, the appliances business, and everything associated with that, as well as the Veritas name goes to Cohesity. That’s why we lose our name.
It’s a bit disconcerting to lose your name, but I think we’ll deal with it. I also see it as an opportunity again. Since we are leaving our parents’ house, if you will, we have an opportunity to forge a new identity for ourselves.
And that’s exactly what we’re in right now; an opportunity to look at what a new name could be to help recognize all the goodness of our history, but also with a nod to the future of where we intend to go. And why we believe that we are going to thrive in the future. So those are all sort of the pieces that we’re trying to pull together right now.
Comment
DataCo, whatever its name will be by the end of the year, looks set to hit the ground running as an established business with three profitable operating units marketing their wares in markets with growth TAM characteristics. There is a high energy level in DataCo and a determination to claim what it sees as its rightful place in the world, out from under, if we could put it like this, Veritas and NetBackup’s shadow.
It’s not a left behind, unwanted remnant, but a thriving and profitable trio of businesses that are benefiting from a secular rise in the importance and safeguarding of data for businesses large and small.
Bootnote
¹Veritas acquired the small and medium business-focused Backup Exec, first developed by Maynard Electronics in 1982, when it bought Seagate’s Network and Storage Management Group in 1999. Veritas bought OpenVision Technologies in 1997 and so obtained the enterprise-focused NetBackup product.
Quantum is using SMB IP from Finnish outfit Tuxera to boost its StorNext file management and Myriad operating system software products.
Tuxera produces embedded file systems and data networking software. Its customers include Kioxia, Fujitsu, Lenovo, and now Quantum. It has an SMB partner agreement with Microsoft enabling it to provide SMB technology and an SMB patent license.
StorNext, a hierarchical file manager spanning flash, disk, and tape stores, is popular in the entertainment and media market. Myriad is a new all-flash file and object storage OS based on a core key/value store. Tuxera’s Fusion File Share SMB technology is being added to both StorNext and Myriad, which furthers Quantum’s vision of offering an end-to-end unstructured data and AI platform, available in both software-only and appliance options.
Nick Elvester, product operations VP at Quantum, said: “Our StorNext and Myriad customers are building ever larger teams of connected users, investing more in Ethernet infrastructure, and facing challenging requirements such as 8K, high frame rates, and HDR, which are pushing the limits of client connectivity. Adding Fusion File Share technology helps them effortlessly serve Windows, macOS, and Linux client systems with incredible performance and efficiency at scale.”
Tuxera says it’s the only company to offer fully licensed, high-availability, cloud-scale SMB software for enterprise storage requirements, as well as SMB for embedded devices.
According to Quantum, Tuxera’s patented Fusion File Share (FFS) software dramatically boosts file service performance and delivers enterprise-grade stability with features like SMB Direct RDMA, SMB scale-out, SMB Multichannel, SMB witness protocol, and persistent file handles.
It will offer FFS as an installation upgrade option for new and existing StorNext customers, boosting SMB file service performance to meet the demands of large teams of macOS, Windows, and Linux clients, serve larger files more efficiently, and deliver higher performance to their applications.
Customers deploying FFS on StorNext v7.2 volumes built with Quantum F-Series NVMe storage appliances will see the fastest SMB performance on StorNext. A single Windows client, using SMB Direct RDMA, can read SMB share data in excess of 10 GBps using 100 Gb Ethernet. Quantum claims this is extreme performance for ingest or streaming workflows, which is just not possible when using systems without SMB Direct.
Heather Goring, Tuxera director of sales for the Americas, said: “We’re especially excited to see Quantum integrate StorNext with NVMe-oF features to deliver extraordinary performance and make full use of our advanced features such as SMB Direct and SMB Multichannel, and as a core client service integration within Myriad.”
The SMB capabilities will be available for early access customers for both StorNext and Myriad in Q2. StorNext customers can then purchase the solution in Q3 as a turnkey Quantum Professional Services bundle that includes full-service installation, configuration, and management. The feature will be generally available for all Myriad customers in Q3.
Quantum will be demonstrating Fusion File Share on StorNext 7.2 and on Myriad at the NAB 2024 show April 13-17 in booth SL5083.
Cloud file storage vendor CTERA has made a number of enhancements to its offering as it reports consistent growth for the year.
At this week’s IT Press Tour in Rome, CEO Oded Nagel said CTERA “doubled” new business in 2023, and saw a 30 percent increase in its annual recurring revenue (ARR).
Oded Nagel
The firm also launched a new partner program last year to improve benefits for partners, and in June signed a go-to-market alliance with Hitachi Vantara for cloud file services.
Nagel said: “The biggest sales growth has been seen in North America, although with the help of the Hitachi Vantara alliance, we expect to see higher growth in Asia too.”
Product improvements also helped growth, not least the commercial introduction of the company’s integrated ransomware protection, and version 1 of its WORM Vault secured data technology.
CTERA execs at the presentation then outlined what else the company was rolling out and about to announce, as part of the effort to grow the company further, and win a larger share of the very crowded cloud data storage and management market.
The overarching theme was moving from “passive” protection of data to “active” protection of data, and “offense rather than defense.”
Saimon Michelson, VP of alliances, said: “If you have backup, that’s not the end of the story, although some organizations think that.
“If you have 1 billion files, it can take a lot of work to restore your systems after a ransomware attack, although it’s best not to be infected in the first place.”
To help prevent the infection or distortion of a company’s main business data, an updated version of WORM Vault is being introduced this second quarter to bring “immutability.”
New features include Legal Hold, Object Lock, and Chain of Custody. Legal Hold, for instance, means no one can change accounts according to policies, which can come in handy when considering legal/litigation files.
With Object Lock, there is immutability all the way to a data bucket end-to-end, and Chain of Custody retains all metadata end-to-end. All the new features were developed in partnership with Hitachi Vantara, said CTERA.
The firm’s ransomware protection is already being used by “top banks,” Fortune 500 companies, and health and federal bodies.
We were briefed on a major enhancement to this protection, which will be officially announced later this month, and it is focused on detecting attempted hacks on the network, and preventing exfiltration of data in the first place.
Tape storage media producer and evangelist Fujifilm recently launched its Kangaroo converged system for archive storage, and it is about to release a “Lite” version to target SMBs.
The original version contains 120 LTO tapes in a wheeled box configuration that comes with an integrated mouse and screen, UPS power, and the company’s object archiving software. The unit can store up to 1 PB of data and has a list price of up to €350,000 ($375,000).
The new Lite Kangaroo can provide SMBs with up to 100 TB of data, and comes in at under €100,000 ($107,000).
Speaking at this week’s IT Press Tour in Rome, Peter Struik, executive vice president at Fujifilm Europe, said the lightweight Kangaroo would be hopping around the market in “July or August” this year. He outlined how larger organizations in Europe had already put its original and heavier parent through their paces.
Peter Struik
The Bank of Luxembourg has already taken delivery of a unit, as has a health body, and a university in Holland. Struik added that two units were on their way to the UK to try to break the commercial market there through trials.
The Kangaroos are built using components from global markets and assembled in Germany. Struik said “the money for us is in the tapes and the software,” and that the hardware was sold “at cost” or with a “small administrative charge” on top.
Fujifilm Kangaroo
He added that the firm was currently searching for new technology and channel partners to help sell the Kangaroos.
“We just want to make it easier for companies to use tape, as well as making a contribution to help reduce global warming,” Struik said.
On that last point, Fujifilm maintains that storing data on tape reduces carbon emissions by 95 percent, when compared to other hard disk data storage options. The Kangaroo is primarily designed to be used offline, so that squares with the comparison, when considering that data stored on hard disks is usually primed with a constant power source to deliver instant access, whether it is immediately needed or not.
Indeed, Fujifilm says 70 percent of business data is “cold,” and therefore not immediately needed for business operations. However, only 5 percent of this cold data is stored on “appropriate” systems, like cheaper tape, says Fujifilm.
Reuters reports that AWS has lost an S3 and Dynamo DB patent infringement case brought by Kove IO. The jury awarded Kove $525 million. The case took place in an Illinois federal court and was initiated by Kove in 2018, alleging that AWS violated three of its patents for its in-house software inventions: US Patent No. 7,103,640, entitled “Network Distributed Tracking Wire Transfer Protocol”; US Patent No. 7,814,170, entitled “Network Distributed Tracking Wire Transfer Protocol”; and US Patent No. 7,233,978, entitled “Method and Apparatus for Managing Location Information in a Network Separate From the Data to Which the Location Information Pertains.” They relate to systems and methods for managing the storage, search, and retrieval of information across a computer network. AWS will appeal this jury decision. Kove has separately sued Google for infringing its patents.
…
Cloud storage provider Backblaze has joined the US Trusted Partner Network and achieved Blue Shield Status – a security initiative wholly owned by the Motion Picture Association. The Trusted Partner Network provides content creators and service provider partners with standardized methods to share critical security status specific to the industry. To achieve Blue Shield status, TPN members submit self assessments of their security posture which interested companies can then review when assessing their product or service.
…
BackupLABS, which offers protection for SaaS apps like including GitHub, GitLab, and Trello, has added coverage of Atlassian Jira and Notion backup. It will be adding more apps to protect over the next few months and is currently looking at Zendesk, Microsoft Entra, and Asana. It has also added additional features such as 2FA, audit trails, multiple backups, longer retention, and more.
…
Cohesity says IBM is joining Nvidia as a strategic Cohesity investor, completing a $150 million F-round of fundraising. This takes Cohesity’s total funding to $955 million, making it possibly the highest funded storage startup ever. It is notable that this funding was announced after news of Cohesity’s acquisition of the main Veritas data protection business. IBM also integrated Cohesity capabilities with its cyber resilience platform to strengthen joint customers’ ability to recover from data breaches and cyber attacks, bringing together Cohesity DataProtect with IBM’s Storage Defender offering to help joint customers protect, monitor, manage, and recover data.
…
Cohesity has partnered with Intel to bring its confidential computing capabilities to the Cohesity Data Cloud via the Fort Knox cyber vault service. Confidential computing enabled by Intel Software Guard Extensions (Intel SGX) will enable Cohesity customers to reduce the risk posed by potential bad actors accessing data while it is being processed in main memory. The Intel and Cohesity setup will protect encryption keys that secure customer data in a hardware-secured environment, leveraging Intel SGX for confidential computing in the cloud. The data is not viewable or downloadable by any privileged accounts when the data is being processed in memory as it is encrypted. Cohesity customers can verify that their Intel SGX is legitimate by using Intel Trust Authority, which has the latest patches and only runs the dedicated Cohesity application before extracting the data encryption key.
…
Ashley Baird
Commvault has appointed Ashley Baird as its VP and MD of Market Expansion into the hyperscaler area. Curiously, Baird will also serve as chief of staff to Commvault’s president and CEO, Sanjay Mirchandani. Baird issued a statement: “Commvault has helped thousands of companies accelerate their transition to the cloud, where data protection, security, and resilience are key. I look forward to working closely with cloud providers to extend our partnerships while helping customers advance their cyber resilience in the ransomware era.”
…
Lakehouse supplier Databricks announced its Data Intelligence Platform for Energy, a unified AI platform. It enables enterprises to harness vast streams of energy data and develop gen AI applications without sacrificing data privacy or their confidential IP. It offers offers packaged use case accelerators designed to jumpstart the analytics process and offer a blueprint to help organizations tackle industry challenges:
LLMs for Knowledge Base Q&A Agents – Easily build an LLM-powered chatbot with Databricks that is pretrained with industry context and a customer’s knowledge base to offer an elevated, personalized experience to end users;
IoT Predictive Maintenance – Ingest real-time Industrial Internet of Things (IIoT) data from field devices and perform complex time-series processing to maximize uptime and minimize maintenance costs;
Digital Twins – Process real-world data in real time, compute insights at scale and deliver to multiple downstream applications for data-driven decisions;
Wind Turbine Predictive Maintenance – Analyze wind farm productivity and predict faulty wind turbines through a mix of AI/ML and domain-specific models;
Grid-Edge Analytics – Optimize energy grid performance and prevent outages by unifying data from various IoT devices and training a fault detection model to easily spot and address anomalies;
Real-Time Data Ingestion Platform (RTDIP) – Enables optimization, surveillance, forecasting, predictive analytics, and digital twins with a cloud-native open source framework focused on data standardization and interoperability.
DataStax says it’s one of the first Google Cloud Platform partners to integrate with Vertex AI, with Astra DB API extensions to Google Cloud’s Vertex AI Extension and Vertex AI Search. This makes it easier for developers working in Python, JavaScript, and Java to build and scale up generative AI and RAG applications. Using these integrations, DataStax developed a generative AI application called Fashion Buddy – a fashion recommendation app that utilizes the Gemini Pro Vision foundation model in Vertex AI. It also spun up NoSQL Assistant – a customer support chatbot that harnesses Vertex AI’s text-embedding model and Astra DB’s vector search to deliver precise answers. Read a blog to find out more.
…
Dremio, the unified lakehouse for self-service analytics and AI supplier, has unveiled capabilities that include ingestion, processing, and migration. They simplify the process of building and managing an Apache Iceberg data lakehouse. By automating Iceberg management processes, Dremio reduces TCO, enhances data team productivity and improves overall time-to-insight. They are available immediately.
…
MRAM supplier EverSpin announced a new PERSYSTbrand name for its persistent memory product family. EverSpin’s legacy toggle MRAM parallel and serial products, 1Gb ST-DDR4 and new EMxxLX xSPI Industrial STT-MRAM will use the PERSYST brand.
…
Index Engines announced CyberSense v8.6, supporting smarter recovery from ransomware attacks, customizable threshold alerts to proactively detect unusual activity, and AI-powered detection of ransomware-based data corruption to accelerate recovery. It claims this update provides all the information needed to support a curated recovery of clean data quickly and efficiently to resume normal business operations. The threshold alerts are based on metadata and content changes to files and can be created based on the quantity or percentage changes of modified files, altered file type, added or deleted files, or entropy/encryption across any host. They allow for the generation of alerts when specific files exhibit unusual behavior.
CyberSense 8.6 has a CyberSensitivity Index (CSI), the AI-powered brain behind CyberSense, which measures normal activity vs probable data corruption from ransomware. The CSI has been trained on thousands of variants and hundreds of millions of datasets to detect signs of data corruption caused by ransomware with 99.5 percent accuracy. The CSI is now available for users to monitor and, optionally, adjust based on the needs of individual hosts.
CyberSense 8.6 also supports the RHEL 9.2 (LTS) operating system and VMFS file systems, and has a revamped user interface. CyberSense 8.6 is available now to Index Engines strategic partners. Their implementation and release schedules may vary.
…
High-end storage array supplier Infinidat announced a strategic partnership with global IT services, consulting and business solutions organization Tata Consultancy Services (TCS). It builds on an existing partnership and will focus on new services that TCS will provide to augment Infinidat’s InfiniBox and InfiniGuard systems. As they both sell to the Forbes Global 2000, TCS and Infinidat already share some of the same enterprise customers across industries –including financial services, insurance, retail, biomedical, and manufacturing. Erik Kaulberg, VP of Strategy and Alliances at Infinidat, declared: “We are excited to expand the strong business we have with TCS and our joint customers, opening the aperture more broadly for our step-change capabilities, including cyber resilience, AI-powered automation, ease of use, high availability, and storage consolidation. Customers can use the combination of TCS services and Infinidat storage to free up IT budget and resources, allowing them to focus on higher-level areas such as generative AI.”
…
SaaS data protector Keepit, which stores backup data in its own datacenters, is opening two bit barns in Switzerland, based in Equinix colos and its first ones there. They will enable Keepit to comply with Swiss laws and regulations for businesses inside and outside Switzerland. Keepit also has datacenters in Germany, Denmark, UK, US, Canada, and Australia. Keepit provides Backup-as-a-Service for SaaS platforms such as Microsoft 365, Entra ID, Azure DevOps, Power Platform, Dynamics 365, Google Workspace, Salesforce, and Zendesk.
…
Micron issued an SEC 8K form today with an update around the expected impact of the recent Taiwan earthquake on DRAM output. It currently estimates that the earthquake will result in an impact of up to a mid-single digit percentage of a calendar quarter’s company-level DRAM supply.
…
Micron low-power double data rate 5X (LPDDR5X) memory, Universal Flash Storage (UFS) 3.1, Xccela flash memory and quad serial peripheral interface NOR (SPI-NOR) flash have been pre-integrated for the latest generation of Qualcomm’s Snapdragon automotive solutions and modules – including the Snapdragon Cockpit Platform, Snapdragon Ride Platform and Snapdragon Ride Flex System-on-Chip (SoC), all of which are intended to handle the increasing requirements of modern and future workloads for artificial intelligence (AI) technologies.
…
Open source object storage software supplier MinIO has hired Mark Khavkin as its CFO. Current CFO and co-founder Garima Kapoor becomes the co-CEO with current CEO and co-founder Anad Babu Periasamy. Khavkin brings more than 15 years of experience, most recently serving as the CFO of Pantheon Systems, where he helped lead the company’s growth from $10 million to more than $100 million in ARR, with an associated increase in valuation to over $1 billion. A MinIO spokesperson explained that the AI ecosystem is exploding and MinIO is taking advantage of the market opportunities presented by the revolution in large scale AI data infrastructure. It’s adding Mark as CFO because he brings 15+ years of experience in enterprise tech, that will be invaluable in helping scale financially and operationally to meet the requirements of its growing enterprise customer base.
…
Startup PeerDB, which supplies a data movement platform for PostgreSQL, has received $3.6 million in seed round funding. Investors in the round include lead investor 8VC, Y Combinator, Wayfinder Ventures, Webb Investment Network, Flex Capital, Rogue Capital, Pioneer Fund, Orange Collective and several angel investors. PeerDB will use the funds to continue building its engineering team, propelling its go-to-market and client acquisition initiatives and supporting its growth. PeerDB revenue is doubling every two months.
…
Jason Feist
According to Jason Feist, SVP of Product and Marketing at Seagate since December 2023, while flash offers latency advantages and prices dropped temporarily, SSDs haven’t – and never will – replace HDDs. Datacenter operators will continue to need both. He says that those who argue flash will overtake and replace hard drives are ignoring some key facts:
Price: SSD and HDD pricing will not converge at any point in the next decade. According to IDC, the price-per-TB difference between enterprise SSDs and HDDs is projected to remain at or above a 6 to 1 premium through at least 2027. [B&F, which has no skin this game, thinks that leaves 2028–2034 in which prices could converge.]
Replacement: Swapping out HDDs for SSDs requires untenable capex investments. HDDs are far more cost efficient at delivering zettabytes to the datacenter, which is why they are still responsible for 90 percent of datacenter storage needs. [B&F: But if SSD cost premium is lowered and SSDs cost less to power and cool per TB than HDD then capex could be justified.]
Storage needs: Enterprise storage architecture calls for storage that optimizes cost, capacity, and performance for different workloads. HDDs and SSDs serve different needs and only a small percentage of workloads require the low latency advantages of flash. [B&F: But if SSD cost premium is lowered and SSDs cost less to power and cool per TB than HDD then the not-all-workloads-require-low-latency argument is moot.]
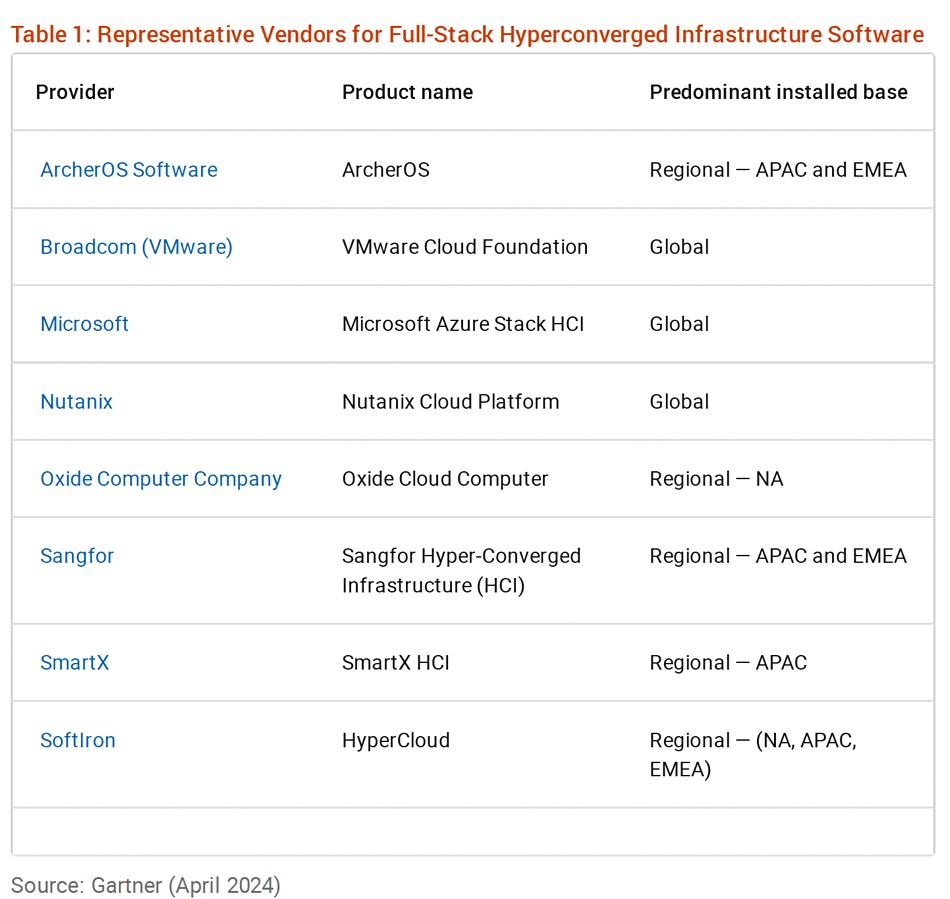
The Gartner analysts observe: “The SmartX HCI installed base exists primarily in APAC countries such as China and Korea. SmartX HCI is targeted as a means to optimize virtualization, disaster recovery, remote-office, branch-office, edge and virtual desktop infrastructure (VDI) implementations, as well as cloud-native and AI infrastructure.”
…
SQL-based GPU data analytics platform supplier SQream announced an “in-database model training” feature, to enable customers to use its product as both an integrated analytics platform as well as a machine learning model trainer. It says in-database model training benefits include minimized time to insight, faster ingestion, and preparation of large-scale datasets, enhanced model accuracy and precision – all meaning, it claims, more valuable insights. By using the power of SQL accelerated by GPUs to train models directly within the database, SQream says it maximizes efficiency in machine learning operations and frees up organizations’ valuable resources.
…
Open data lakehouse supplier Starburst has a fully managed Icehouse implementation on its multi-cloud Galaxy data lakehouse service. Starburst’s Icehouse builds on the Trino SQL analytics, governance, and auto-scaling capabilities in Starburst Galaxy, and adds new support for near-real-time data ingestion at petabyte-scale into managed Iceberg tables. The Icehouse architecture underpins some of the most sophisticated lakehouses on the planet – including those at Netflix, Apple, Shopify, and Stripe. With this, it claims, customers can benefit from the scalability, performance, and cost-effectiveness of a combined Trino and Iceberg architecture (Icehouse) without the burden and cost of building and maintaining a custom setup themselves. Additional information here.
…
Cloud object storage provider Wasabi has introduced Wasabi AiR – AI-enabled intelligent media storage with metadata auto-tagging and multilingual searchable speech-to-text transcription. Video files uploaded to Wasabi AiR are immediately analyzed and a second-by-second metadata index is created. This reduces the cost of metadata creation – customers pay only for the storage and there is no additional charge for use of the AI. The functionality is based on technology Wasabi obtained when it bought Curio AI.
…
Israeli software RAID supplier Xinnor is rebranding its kernel-space RAID implementation to xiRAID Classic, while introducing xiRAID Opus (Optimized Performance in User Space), based on the SPDK framework and operating in user space. In parallel with the launch of xiRAID Opus, xiRAID Classic has received a significant update to version 4.1. This release reaffirms xiRAID Classic’s position as the go-to solution for Linux kernel block devices. By operating in user space, Opus offers a streamlined and independent setup compared to Classic, which relies on kernel dependencies. This architectural variance enables Opus to adapt more readily to system updates and simplifies maintenance as it does not require compatibility adjustments with kernel updates.
Opus boasts a broader array of integrated functionalities, including built-in features such as NVMe initiator, NVMe over TCP/RDMA, iSCSI target, and Vhost controller. These features facilitate direct connectivity to modern storage technologies, without relying on external components, enhancing efficiency and flexibility in networking and virtualization scenarios. Additionally, Opus is compatible with Arm architectures, allowing its deployment on Arm-based DPUs like BlueField3 from Nvidia.
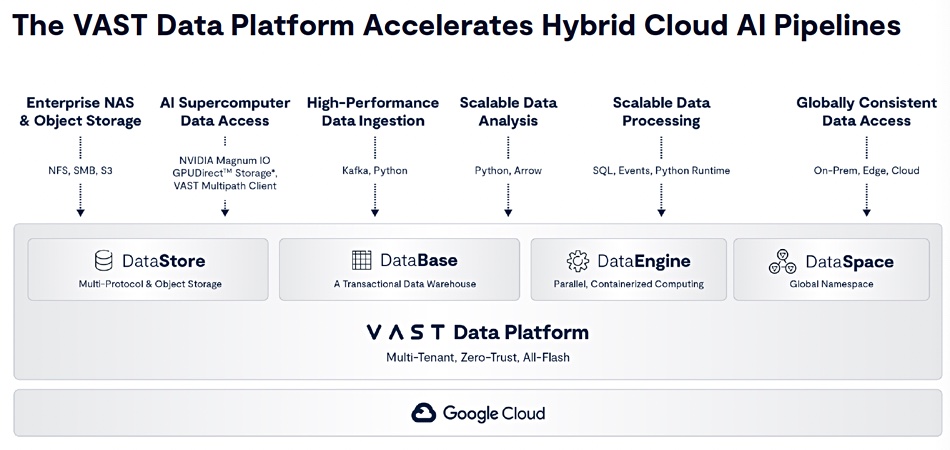
VAST Data has ported its Data Platform software to Google’s cloud enabling users to spin up VAST clusters there.
Update: VAST can work with Vertex AI. 12 April 2024.
VAST supplies all-flash storage with a software stack based on a data catalog, global namespace (DataSpace), database, and coming data engine. It began life as an on-premises offering and the software was ported to the AWS cloud in 2023. VAST has a strong focus on AI, forging deals with GPU farm providers such as CoreWeave, and having a Thinking Machines development ambition.
John Mao
John Mao, VP for Technology Alliances at VAST, said in a statement: “Now we’re enabling Google Cloud customers to take advantage of VAST natively on their preferred cloud platform, simplifying hybrid cloud data management, protection and access to accelerated computing cloud services no matter where their data resides, enabling faster time to value and accelerating innovation.”
VAST declares that its presence in Google Cloud paves the way for seamless hybrid and cloud-native experiences, centralizing data management through a global namespace for file, object, and structured data.
It makes much of this, saying the DataSpace and VAST’s DASE architecture “allows for efficient, limitless scale and collaboration between multiple applications or users across hybrid cloud/multi-location environments without having to manage multiple copies of their data.” VAST says: “Organizations can spin up Spark clusters with Google Cloud and gain radical compute efficiencies through integration with the VAST DataBase.”
The VAST software has a zero trust architecture, featuring granular access control, multi-tenancy with strict isolation, robust encryption, key management, and intelligent threat detection capabilities.
A Solution Brief talks about simplifying, accelerating, and securing hybrid cloud AI pipelines on Google Cloud. It says that VAST in Google Cloud lowers cloud expenses with global data reduction, minimizes data copies, and eliminates API charges. AI development and workloads are enhanced with the VAST Database and Apache Spark.
The brief says globally distributed organizations can collaborate in real time, with predictive prefetching ensuring fast, local access to files across datacenters and GCP regions. A global namespace ensures secure and transparent data access everywhere. There is a seamless, scalable data infrastructure and accelerated AI pipelines in the cloud with elastic compute resources in GCP.
But there is no mention of Google’s Vertex AI, a combination of Google’s cloud-based machine learning and AI services for developing, deploying, and managing machine learning (ML) models across the ML lifecycle. Vertex AI is integrated with Google’s Cloud Storage, BigQuery, and Dataflow for end-to-end data and AI integration.
VAST’s solution brief says the Google Cloud presence means using “on-premises data in GCP has never been easier with the platform’s global namespace, enhancing collaboration and innovation. It’s a game-changer for efficiently managing and leveraging data across hybrid environments, significantly improving performance and cost-efficiency in cloud-based AI and analytics projects.”
Vertex AI is Google’s offering for “cloud-based AI and analytics projects.” It is curious that VAST is not declaring any integration with Vertex AI and this is maybe because VAST and Vertex AI are competing. We have asked VAST why Vertex AI is not mentioned in its announcement and co-funder Jeff Denworth said: “Vertex is an MLOps that you can use to build foundation models and train them against your data for model fine tuning. It’s not specific to any one data source, so, yes, you can use VAST in conjunction with Vertex to train on VAST files, objects and tables.”
Bootnote
We think that VAST will port its data storage software and services to Microsoft Azure some time later this year, thus completing a major public cloud trifecta. It may also add some kind of support for Intel’s Gaudi3 GPU.
We quiz Pure’s VP for R&D Shawn Rosemarin on AI training, inference and Retrieval Augmented Generation. The first part of this interview is here.
B&F: Do storage considerations for running AI training in the public cloud differ from the on-premises ones?
Shawn Rosemarin: I think that they do, but the considerations themselves are nuanced. In the cloud and on-prem, we still have a choice of hard drives, spinning disk, SSDs, and persistent memory. We’re seeing roughly 60 to 80 percent of the current spinning disk is still sitting in the public clouds and hyperscalers. They are the last holdout in the move to flash-based storage.
This being said the price of SSDs continues to come down, and the requirement for more workloads to have access to energy efficient and high performant storage is increasing. Pure has a flash capacity advantage over SSDs with our Direct Flash Modules, which are at 75TB now and road-mapped out to 150TB and 300TB and beyond. We believe that, both in the cloud and on-prem, we’ll see this density advantage be a key pillar for Pure in terms of performance, density and efficiency.
Also, Pure’s Direct Flash Modules (DFM) lifespan of ten years, compared with our competitors’ SSD lifespan of five years, has a dramatic impact on long term total cost of ownership.
If you think about public clouds, and where their investments are going, they architect and invest in 5-, 7-, 10-year rack-scale designs. They’re very, very attracted by these DFMs because they’ll allow them to have a much lower operating cost over time.
Imagine if I’m a hyperscaler, and my current rack density only allows me to fill my rack at 50 percent using spinning disk or commodity SSDs. Pure’s Purity OS and DFMs allow me to scale that rack to 80 or 90 percent full. I essentially get a significant benefit – not just in density and power, but also because I can sell two or three times more capacity on the same energy footprint.
Also, in the cloud we have scale-up and scale-out for storage and we have to balance GPUs with switch fabric and storage. What’s the speed of the network that’s connecting between the two? Is the traffic going north-south or is it going east-west? Performance considerations for AI are complex and will challenge traditional network topologies.
The key point here is flexibility is essential. How easy is it going to be for me to add additional storage, add additional nodes, connect to additional facilities where there may be other datasets? And this is a real opportunity for Pure. We’ve taken non-disruptive upgrades to storage and, over the last 15 years, and well over 30,000 upgrades delivered, we have made it a core competency to make sure our customers can upgrade their environments without any disruption.
We see this as a major opportunity because of the newness of this market – how much change is likely to occur and our proven experience in non-disruptive upgrades and migrations.
B&F: Does RAG (Retrieval-Augmented Generation) affect the thinking here?
Shawn Rosemarin: As we look at RAG, I think this is huge, because I’m going to be able to take a proprietary data set, vectorize it, and enable it to enhance the LLM, which could be in the cloud. Having a consistent data plane between on-prem and the cloud will make this architecture much simpler.
If I’ve got particular edge sites where I want to keep data at the edge for a whole bunch of reasons – maybe physics, maybe cost, maybe compliance – I can do that. But if I want to move those datasets into the cloud, to increase performance, having a consistent data plane will make it simpler.
When you look at what we’re doing with Cloud Block Store, you look at what we’ve recently launched with Azure Cloud Block Store on cloud primitive infrastructure, we’re taking this simple, easy to operate data plane, Purity – that is at the heart of FlashArray and FlashBlade – and easily allowing customers to take those volumes and put them wherever they need to be, with an MSP in a cloud or on-prem.
B&F: What’s the difference between the processing and storage needs for AI inference compared to AI training?
Shawn Rosemarin: Oh, that’s huge. There’s training, there’s inference, and there’s archive. When you look at training, it’s computationally intensive. It’s what GPUs and TPUs were built for. It requires access to large volumes of data. This is the initial training of the models. You’re looking at high capacity, fast I/O, where data access speeds are critical.
When we look at inference, it’s taking a trained model, and seeing what kind of predictions and decisions it makes. Whether it’s an application that’s going to the model and asking questions, or whether it’s you and I going into ChatGPT and asking a question, we need a decent response time. It’s less about storage capacity and bandwidth compared to training – it’s more about latency and response times.
When you look at these two different models, the industry is very focused on training. At Pure, while we see a huge race to solve for training, we’re very bullish that, actually, in the long term, the majority of the market will be leveraging AI for inference.
The scale of that inference over time will be significantly larger than the scale of any training environment early on. We’re very focused on both the training and inference markets.
B&F: With AI training, the compute need is so great that the scalability of public cloud becomes attractive. But with inference, that relationship doesn’t apply. Should inferencing be carried out more on-premises than in the public cloud?
Shawn Rosemarin: I think inference will absolutely be carried out on-prem. I also think with inference, there’s also capturing the results of that inference. The enterprise wants to capture what questions were asked of my model, what responses were given, what did the customer do after they got that answer? Did they actually buy something? Did they abandon their cart?
I want to continue to refine my model to say that, even though it’s technically working the way it was designed, it’s not giving me the outcome I want – which is increased revenue, lower cost, lower risk. So I think that data organizations will be very, very interested in seeing what is the inference environment around what was asked, what came out? I’m going to take what I see happening in my on-prem inference model, and I’m going to use those findings to retrain it.
B&F: Do you think that where inferencing takes place in an enterprise will be partially dictated by the amount of storage and compute available? At edge locations outside the datacenter for example?
Shawn Rosemarin: I think we’ll actually see some training at the edge. I think we’ll actually see the development and the vectorization of datasets potentially start to happen at the edge.
If we think about where the compute is sitting idle, if we only have so much electricity, and we have much more training to do that we can accommodate by electricity, I have to look for idle sources of compute and processing power.
I think you’ll start to see some elements of the training process get broken out into a lifecycle where some of it will be done at the edge, because if I can train it, and I can shrink it, then I can actually save on the data ingress costs.
We really have to start thinking about what is the training process? How do we build it out? And how do we get each particular training element running on the most efficient platform.
Inference will not only be used by humans, inference will also be used by machines. Machines could query the inference model to get direction on what they should do next. Whether it be on a factory floor, whether it be on some remote location, et cetera.
When you think about an inference model, the key thing will be capturing the inputs and outputs of that model and being able to bring them back to a central repository where they can be connected with all the other inputs and outputs so that the next iteration of the training model can be determined.
B&F: Is GPUDirect support now table stakes for generative AI training workloads?
Shawn Rosemarin: Yes. There is absolutely no doubt about that. This is about enhancing the data transfer efficiency between GPUs and network interfaces and storage. I think that most vendors, including Pure, now have GPUDirect compatibility and certification. We’ve actually launched our BasePod and just recently, our OVS certified solution. So yes, getting the most efficient path between the GPUs and the storage is table stakes.
But that’s not necessarily where we’re going to be ten years from now. Today, CUDA – the compiler that allows the CPU to talk to the GPU – is only Nvidia. However, there have been whispers online of GitHub projects that allow CUDA instruction, CUDA compilers to be compatible with other processors. I’m not sure of the validity of those projects, but I do think it worth keeping an eye on.
I am interested to see if this becomes a universal standard – like Docker eventually became in the container world. Or does it stay Nvidia-only. Does CUDA become a more open model? Does the concept of an AI App Store extend across GPUs? Does performance become the vector? Or does the platform lock you in? I think these are all questions that need to be solved over the next three to five years.
Pure ultimately wants to make our storage operationally efficient and energy-efficient, to whatever GPU market our customers want access to. AMD and Intel have GPUs. Arm is a player, and AWS, Azure, and Google haven’t been keeping it a secret that they’re building their own GPU silicon as well.
We are very much proceeding down a path with Nvidia making sure that we’ve got OVX, BasePod and all the architectural certifications and reference architectures to satisfy our customers’ needs. Should our customers decide that there is a particular solution they want us to build into, then our job will be to make sure that we can be as performant, operationally efficient, and energy efficient as we are on any other platform.
B&F: What I’m picking up from this is that Pure wants to remain a data storage supplier. And it wants to deliver data storage services to wherever its customers want it delivered to. And for AI purposes that’s largely Nvidia today, but in two, three, four years’ time, it may include the public clouds with their own specific GPU processors. It could include AMD, or Intel or Arm. And whatever it takes, when there’s a substantial market need for Pure to support such a destination, then you’ll support it.
Shawn Rosemarin: I would agree with everything you said, but think a little bit larger about Pure. You’ll hear us talk a lot about data platform. And I know that everybody says platform these days. But I would think a little bit bigger.
So when you think about what’s happening with DFMs, remember the efficiency piece. Then think about a ten-year lifecycle of NAND flash, coupled with Purity operating system for flash that allows me to drive significantly better efficiency across how flash is managed. Then I have a portfolio that allows me to deploy with FlashArray and FlashBlade. Then I have Portworx that allows me to address and bring this efficiency to essentially any external storage capability for containers.
And now Pure is delivering Fusion to help customers automate orchestration and workload placement. The storage is a piece of it – but essentially, Pure is the data platform on which enterprises and hyperscalers deliver efficient access to flash, on-prem or the clouds. Enterprises also get flexible consumption with our Evergreen//One as-a-service consumption model governed by SLAs. So I’d encourage you to view Pure as a data platform message as opposed to just another storage appliance.
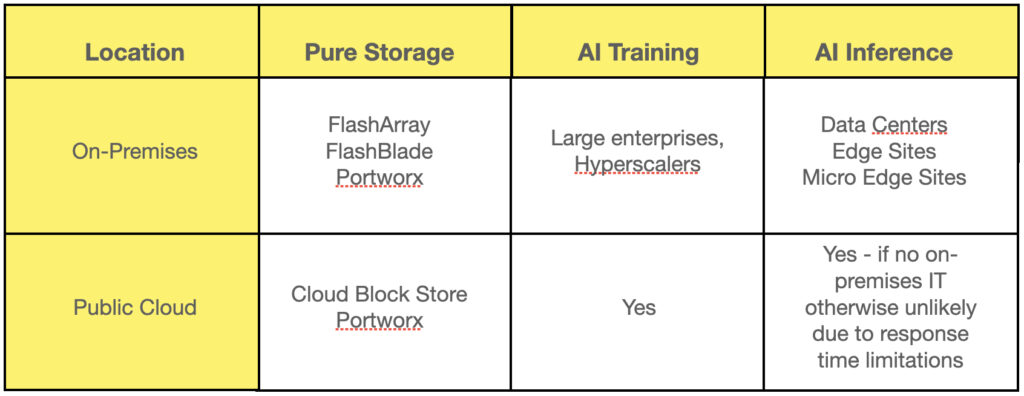
Pure Storage identifies itself as an AI data platform, storing and supplying data storage for AI training and inference workloads, whether they take place in the public cloud or on-premises, in datacenters, and large and small edge IT locations. It supplies this storage to bare-metal, virtual machines or containerized AI workloads, and does so as an integrated component of AI production work streams.
Generative AI – the application of machine learning Large language Models (LLMs) to provide knowledgeable responses to conversational-style text input – is revolutionizing the business intelligence world, with its ability to turn a speech-style request about a business issue – “Give me the top ten branch revenue locations for battery widgets over the Easter period” – into detailed SQL code, run the query and then provide an answer in text terms.
Such LLMs first need training, and this can require repeated runs against very large, indeed massive – exabyte-scale – data sets by GPU processing systems with hundreds if not thousands of GPUs involved. The expensive GPUs need a constant and high-speed supply of generalized data to complete training runs, which can take hours or even days – with interim checkpointed results written to storage to protect against failures causing whole job restarts.
When the trained LLMs are applied to user requests then they complete their responses much faster – in seconds or less. These responses can be augmented with a user’s own proprietary data sets in what is called Retrieval Augmented Generation (RAG) with the RAG data fed to the LLM from a storage system.
This is the basic Gen AI landscape, and the LLM processing can take place either in the public cloud or on-premises private cloud locations, or use both in a hybrid cloud arrangement. The public cloud provides immense and on-demand scalability, both for GPUs and for storage. The on-premises environment provides better location control for data and generally faster response for AI inference workloads at edge IT sites.
A diagram shows this fundamental AI environment and has Pure Storage’s main product offers included:
B&F talked with Shawn Rosemarin, Pure’s VP for R&D, about Pure Storage and data storage and supply for AI.
B&F: How should an enterprise approach generative AI training workloads? Run them on premises versus in the public cloud? What are the decision criteria for that?
Shawn Rosemarin.
Shawn Rosemarin: So, obviously, cost is a factor. If we think about cost on-prem, it clearly requires a significant investment if you’re going CAPEX, although there are as-a-service models such as Pure’s Evergreen//One, growing in popularity. But it’s not just the cost of the equipment. It’s also do you have the space, the power and the cooling to actually accommodate this AI infrastructure? I think that’s been largely ignored in the narrative to date.
Also, it’s not just do you have the absolute power? Do you have the density? If you think of a traditional datacenter being built for X megawatts, with a density element of 14 to 16 kilowatts per rack, this proposed AI infrastructure could easily consume the density of a rack within six or eight rack units, which is essentially 1/6 of the rack’s physical space.
Then you have to ask: do you have the budget to pay for that electricity on an ongoing basis? Do you have access to growth of the electricity supply over time? And more specifically, is this something that you can take on given the footprint of your existing application set?
All-in-all I think electricity is a kind of silent killer here that no one’s been thinking about.
Now, in the public cloud, it’s great because I don’t need to buy all that infrastructure up front. But, let’s assume I can get access to unlimited scale. If I don’t properly control my environment, I could end up with a bill similar to one that my friends used to get back in the early 1990s when they were streaming the World Cup over their cell phone. They didn’t realize that this would be one of the most expensive games ever observed. So I think cost controls are a big element of this as well.
B&F: Are there aspects of scalability which we need to understand?
Shawn Rosemarin: When we think about scale, it’s not just how big is it going to be. I may start on block, and then it may actually move to file or it might move to object. I may start on Nvidia GPUs, and then, years from now, there might be an alternative infrastructure for me to use. I think this is really important, because these applications will likely go through rescaling and re-platforming more than mature applications will.
When you look at Pure’s ability through the years to help customers to manage that aspect of scale and data migration, non-disruptively, whether capacity or performance, I think that’s a key consideration.
B&F: Is there a third factor to bear in mind?
Shawn Rosemarin: The third decision factor would be around security and compliance. I’m fascinated because as you look at RAG, this new concept of being able to take a traditional LLM, and have it learn my data – my proprietary data, my gold – I think that organizations will be very cautious about putting their proprietary datasets in the cloud.
They may very well run their LLMs in the cloud, but they will likely use “direct connect” capabilities to actually keep their data on-prem, and put their results on-prem, but leverage the bulk of the general purpose libraries in the cloud. Naturally, encryption at both a volume and array level will also be crucial here.
B&F: Are there things that Pure can do, either on premises or in the cloud. to help mitigate the money cost and the electricity supply and allied costs?
Shawn Rosemarin: A lot of these services that are being delivered are on siloed infrastructure. In many cases, if you want to use these datasets for AI, you have to migrate them so that you can get enough horsepower out of your storage in order to actually feed your GPUs.
When you look at Pure’s product and platform we eliminate these complex data migrations by allowing customers to run their AI workloads in tandem to their production workloads. There’s more than enough overhead, capacity and performance, so these migrations are not necessary.
We’re also very focused on energy and density at scale. In fact, our latest ESG report demonstrated that we’re 80 percent more efficient than traditional storage infrastructure. In some cases, even more than that.
What this does is free up the energy typically consumed by storage for customers so they afford to turn on the GPUs in their environment.
The other thing is that the majority of these environments, when running in containers, have a lot of inefficiency in the way in which containers interact with storage, through the container storage interface (CSI) drivers. You actually lose a lot of storage efficiency through this CSI transmission layer between Kubernetes and the storage itself.
At scale, we’re seeing our Portworx container storage technology as a better option to proprietary CSIs and, when combined our electricity and density savings, giving customers a more responsible and a more efficient way to scale for AI workloads.
B&F: Are you saying that, with Pure, storage efficiency gains are so large that you can transfer part of your anticipated storage cost and electricity budget to run GPU compute instead?
Shawn Rosemarin: That’s exactly it. The fact is, we’re on the cusp of an energy crisis. I truly believe the silent killer of AI is access to electricity. We’re seeing this problem emerge. We saw Microsoft’s Azure go and actually purchase a nuclear power plant a couple of weeks ago, so that they could power their own facility.
It’s going to take us time to develop alternative energy sources, but I’m confident that we will eventually innovate our way out of this problem. The challenge for an enterprise right now is “how long can I make that bridge?” So if I consume the way I’ve been consuming, I run out of power in, hypothetically, say eight months, right? That being said, as I stand up AI workloads and GPUs, I will have to decide which applications in my environment I’m willing to turn off and willing to actually take out of my datacenter to free up available power.
Alternatively, if I’m working with Pure, with our efficiency and density, I can take that 80 percent saving and extend that bridge from eight months to 24 or 36 months. I’ve now bought myself some time and can wait for key innovations in the world that will grant me easier and more affordable access to power.
The other alternative is: I go out and buy a bunch of datacenters that have grandfathered in power supplies, or I buy a nuclear power plant, or I find a way to open an office in an alternative country that is still offering available power to datacenters – but this opportunity is increasingly difficult.
Also, let’s be honest: we have a collective responsibility to make sure that we don’t allocate so much power to AI that we actually put the electricity grid for citizens at risk.
NetApp-hosted data can be used in RAG (retrieval-augmented generation) operations for Google’s Vertex AI platform in a previewed toolkit reference architecture.
NetApp’s ONTAP software is provided as a first-party service in Google’s public cloud, called Google Cloud NetApp Volumes (GCNV). A new Flex offering means users can now choose from four service levels with varying capacity and throughput performance. Vertex AI is Google’s combined data engineering, data science, and ML engineering workflow platform for training, deploying, and customizing large language models (LLMs) and developing AI applications. RAG (retrieval-augmented generation) adds proprietary data to an LLM trained on public data to fill in gaps in its trained answer set and help prevent inaccurate or hallucinatory responses to users’ conversational input.
Pravjit Tiwana
Pravjit Tiwana, Cloud Storage SVP and GM at NetApp, said: “By extending our collaboration with Google Cloud, we’re delivering a flexible form factor that can be run on existing infrastructure across Google Cloud system without any trade-offs to enterprise data management capabilities.”
The four GCNV service levels are:
Standard: highly available, general-purpose storage with data management capabilities and 16 MiBps per TiB of performance, for workloads such as file shares, virtual machines (VMs), and DevTest environments.
Premium: highly available, high-performance storage with data management capabilities and 64 MiBps per TiB of performance, again for file shares, VMs, and databases.
Extreme: highly available, low-latency, high-throughput storage with data management capabilities and 128 MiBps per TiB of performance, recommended for Online Transaction Processing (OLTP) high-performance databases and low-latency applications.
Flex: highly available storage volumes with scalability from 1 GiB to 100 TiB and up to 1 GiBps of performance depending on the size of the underlying storage pool. This can support a wide variety of use cases, including AI.
NetApp is also releasing a preview of its GenAI toolkit for Vertex AI with support for NetApp Volumes, saying it helps optimize RAG processes:
ONTAP allows customers to include data from any environment to power RAG ops with common operational processes.
NetApp’s BlueXP classification service automatically tags data to support streamlined data cleansing for both the ingest and inferencing phases of the data pipeline, helping ensure that the right data is used for queries and that sensitive data is not exposed to the model out of policy.
ONTAP Snapshot delivers near-instant creation of space-efficient, in-place copies of vector stores and databases, allowing immediate rollback to a previous version if data is corrupted or forward if point-in-time analysis is needed.
ONTAP FlexClone technology can create instant clones of vector index stores to make relevant data instantly available for different queries for different users, without impacting production data.
Tiwana said: “We have unmatched capabilities to support data classification, tagging, mobility, and cloning for data wherever it lives so our customers can run efficient and secure AI data pipelines. Building on our partnership with Google Cloud to streamline RAG enables customers to tap into market-leading AI services and models to generate a unique competitive advantage.”
There’s no new software functionality here. NetApp wants to ensure that its ONTAP data stores can be used in RAG workflows and is stressing that its data services, such as BlueXP classification, Snapshots, and FlexClones help the selection and presentation of such data to LLMs.
NetApp’s recognition that its customers embracing GenAI will want RAG-enhanced LLMs using their NetApp-stored data parallels that of Cohesity with its Gaia initiative. Dell’s AI Factory also has RAG elements to it. We can expect NetApp to expand its RAG support to Azure and AWS.
The Flex service level will be generally available by Q2 2024 across 15 Google Cloud regions, expanding to the other regions by the end of 2024. The GenAI toolkit will be available as a public preview within the second half of 2024.
Find out more about the Flex service level for NetApp Volumes or the GenAI toolkit reference architecture for Vertex AI by visiting the NetApp booth #1231 at the Google Cloud Next 2024 conference running April 9-11 at Mandalay Bay in Las Vegas.
Dell has added Intel Gaudi3 GPU support to its XE9680 server and ported APEX File Storage to Azure in support of AI workloads.
The XE9680 server was announced in January 2023 and has gen 4 Xeon processors (up to 56 cores), a PCIe 5.0 bus, and support for up to eight Nvidia GPUs. By October, it had become the fastest ramping server in Dell’s history. As of March this year, it supports Nvidia’s H200 GPU, plus the air-cooled B100 and the liquid-cooled HGX B200. Intel’s Gaudi3 accelerator (GPU) has two linked compute dies, each with eight matrix math engines, 64 tensor cores, 96 MB of SRAM cache, 16x lanes of PCIe 5.0, 24 200GbE links, 128 GB of HBM2e memory, and 3.7 TBps of bandwidth.
Now the XE9680 is adding Gaudi3 AI accelerator support. The Gaudi3 XE9680 version has up to 32 DDR5 memory DIMM slots, 16 EDSFF3 flash drives, eight PCIe 5.0 slots, and six OSFP 800GbE ports. It’s an on-premises AI processing beast.
Deania Davidson
A Dell blog written by Deania Davidson, Director AI Compute Product Planning & Management, says: “The Gaudi3’s open ecosystem is optimized through partnerships and supported by a robust framework of model libraries. Its development tools simplify the transition for existing codebases, reducing migration to a mere handful of code lines.”
The OSFP links allow for direct connections to an external accelerator fabric without the need for external NICs to be placed in system. Davidson says: “Dell has partnered with Intel to allow select customers to begin testing Intel’s accelerators via their Intel Developer Cloud solution.” Learn more about that here.
APEX File Storage for Azure
Dell launched its APEX File Storage for AWS, based on PowerScale scale-out OneFS software, in May last year. Now it has added APEX File Storage for Microsoft Azure, complementing its existing APEX Block Storage for Azure. It claims the APEX File Storage for Azure is “a game-changing innovation that bridges the gap between cloud storage and AI-driven insights” in a blog by Principal Product Manager Kshitij Tambe.
Kshitij Tambe
The Azure APEX File Storage provides high-performance and scalable multi-cloud file storage for AI use cases. Tambe says customers can “move data from on-premises to the cloud using advanced native replication without having to refactor your storage architecture. And once in the cloud, you can use all enterprise-grade PowerScale OneFS features. With scale-out architecture to support up to 18 nodes and 5.6 PiB in a single namespace, APEX File Storage for Azure offers scalability and flexibility without sacrificing ease of management.”
He says it has the highest performance at scale for AI, based on maximum throughput performance and namespace capacity. We’ve asked NetApp what it thinks about these claims and a spokesperson said: “Azure NetApp Files is a high-performance enterprise file storage service that is a managed native service from Microsoft. While it is based on NetApp’s leading storage OS, the team at Microsoft will be better able to answer your questions about the specifics of performance.”
COMMISSIONED: The decision by the three largest U.S. public cloud providers to waive data transfer fees is a predictable response to the European Data Act’s move to eradicate contractual terms that stifle competition.
A quick recap: Google made waves in January when it cut its data transfer fee, the money customers pay to move data from cloud platforms. Amazon Web Services and Microsoft followed suit in March. The particulars of each move vary, forcing customers to read the fine print closely.
Regardless, the moves offer customers another opportunity to rethink where they’re running application workloads. This phenomenon, which often involves repatriation to on-premises environments, has gained steam in recent years as IT has become more decentralized.
The roll-back may gain more momentum as organizations decide to create new AI workloads, such as generative AI chatbots and other applications, and run them in house or other locations that will enable them to retain control over their data.
To the cloud and back
Just a decade ago, the organizations pondered whether they should migrate workloads to the public cloud. Then the trend became cloud-first, and everywhere else second.
Computing trends have shifted again as organizations seek to optimize workloads.
Some organizations clawed back apps they’d lifted and shifted to the cloud after finding them difficult to run them there. Others found the operational costs too steep or failed to consider performance requirements. Still others stumbled upon security and governance issues that they either hadn’t accounted for or had to reconcile to meet local compliance laws.
“Ultimately, they didn’t consider everything that was included in the cost of maintaining these systems, moving these systems and modernizing these systems in the cloud environment and they balked and hit the reset button,” said David Linthicum, a cloud analyst at SiliconANGLE.
Much ado about egress fees
Adding to organizations’ frustration with cloud software are the vendors’ egress fees. Such fees can range from 5 cents to 9 cents per gigabyte, which can grow to tens of thousands of dollars for organizations working with petabytes. Generally, fees vary based on where data is being transferred to and from, as well as how it is moved.
Regulators dislike fear the switching costs will keep customers locked into the platform hosting their data, thus reducing choice and hindering innovation. Customers dislike these fees and other surcharges as part of a broader strategy to squeeze them for fatter margins.
This takes the form of technically cumbersome and siloed solutions (proprietary and costly to connect to rivals’ services), as well as steep financial discounts that result in the customer purchasing additional software they may or may not need. Never mind that consuming more services – and thus generating even more data – makes it more challenging and costly to move. Data gravity weighs on IT organizations’ decisions to move workloads.
In that vein, the hyperscalers’ preemptive play is designed to get ahead of Europe’s pending regulations, which commence in September 2025. Call it what you want – just don’t call it philanthropy.
The egress fee cancellation adds another consideration for IT leaders mulling a move to the cloud. Emerging technology trends, including a broadening of workload locations, are other factors.
AI and the expanding multicloud ecosystem
While public cloud software remains a $100 billion-plus market, the computing landscape has expanded, as noted earlier.
Evolving employee and customer requirements that accelerated during the pandemic have helped diversify workload allocation. Data requirements have also become more decentralized, as applications are increasingly served by on-premises systems, multiple public clouds, edge networks, colo facilities and other environments.
The proliferation of AI technologies is busting datacenter boundaries, as running data close to compute and storage capabilities often offers the best outcomes. No workload embodies this more than GenAI, whose large language models (LLMs) require large amounts of compute processing.
While it may make sense to run some GenAI workloads in public clouds – particularly for speedy proof-of – concepts, organizations also recognize that their corporate data is one of the key competitive differentiators. As such, organizations using their corporate IP to fuel and augment their models may opt to keep their data in house – or bring their AI to their data – to maintain control.
The on-premises approach may also offer a better hedge against the risks of shadow AI, in which employees’ unintentional gaffes may lead to data leakage that harms their brands’ reputation. Fifty-five percent of organizations feel preventing exposure of sensitive and critical data is a top concern, according to Technalysis Research.
With application workloads becoming more distributed to maximize performance it may make sense build, augment, or train models in house and run the resulting application in multiple locations. This is an acceptable option, assuming the corporate governance and guardrails are respected.
Ultimately, whether organizations choose to run their GenAI workloads on premises or in multiple other locations, they must weigh the options that will afford them the best performance and control.