


Storage supplier VAST Data is building a Thinking Machines-class system with its own queryable AI-capable database for asking and answering analytical questions, processed on Nvidia GPU servers like SuperPOD.
We came away from a VAST briefing thinking in terms of a vertically integrated AI supercomputing environment – running from VAST Data’s storage nodes at the bottom for storage capacity and I/O, control logic encapsulated as containers running in x86 CPUs, or BlueField-3 data processing units (DPUs) attached to Nvidia GPUs or GPU+CPU systems, and a data infrastructure software stack. This would provide the capability to receive and understand deep learning-type requests about data – including text, video, images, genomics and other types.
Generative AI, such as ChatGPT, has rocketed Nvidia’s market importance sky high. Renen Hallak, VAST Data’s co-founder and CEO, told us: “It’s the future. Now everybody knows about it. A year ago, two years ago, three years ago, we were talking about AI. Most people didn’t understand what we were saying. But now ChatGPT has made it popular.”
Looking back: “I knew it [AI] was coming. I did not expect it to come this fast. I thought we had a little bit more time.” Generative AI is fully aligned with VAST’s engineering development direction.
He said that AI needs “to run on infrastructure. That infrastructure needs to run on hardware.” And the processing part of the hardware needs data – “So the first thing we built was the unstructured data store.” This is VAST Data’s Universal Storage with its disaggregated shared everything (DASE), scale-out, single-tier, all-flash architecture and use of storage-class memory for metadata. This system stores unstructured (file and object) data and has control nodes (dedicated x86 systems) talking across an NVMe Ethernet fabric to NVMe SSDs.
The control nodes run VAST’s control logic, which is containerized.
To this has been added a Data Catalog software layer which generates metadata about every file and object in the system. This is stored in a SQL-queryable tabular format – meaning it’s a database, and it adds a layer of structure to the data. But it is not a transaction-type database, such as a relational Oracle or SAP system. The system is basically an AI-enabled NAS, not an HPC parallel file system, which means that existing file-based enterprises can adopt it with no need to learn about HPC and parallel file systems.
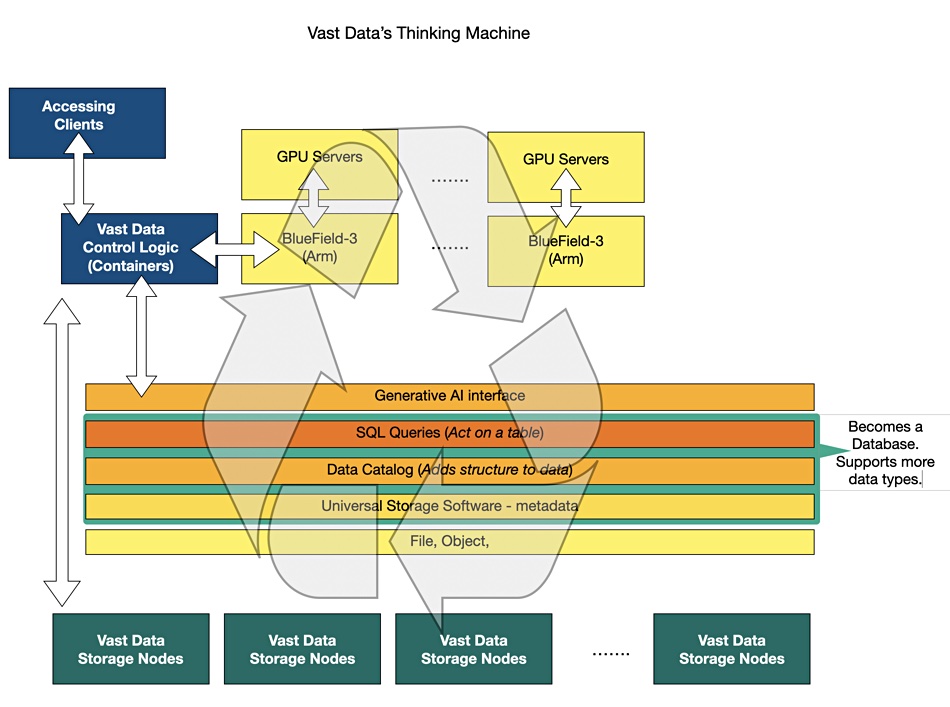
VAST’s control logic could run in the Arm processors found on Nvidia’s BlueField DPUs, or even in the CPUs of Nvidia’s coming Grace Hopper superchips. Hallak is keen on a vertical integration concept embedding VAST software, Nvidia compute, and storage hardware in a single system. We have seen, we think, the first starting iteration of this with VAST being certified for use with Nvidia’s SuperPOD.
He said: “Vertical integration gives you power. If we know where the data is and how it’s stored, that allows us to access it and to generate insight from it in a much more efficient manner.”
VAST vs parallel file systems and dual-controller arrays
In Hallak’s view, Nvidia had to go with shared-nothing parallel file system suppliers and clustered dual-controller all-flash systems, because they were the only suppliers offering the data I/O rates needed for its GPUs running AI applications. Now, he says, VAST enables the use of standard interface NAS to feed data at similar or better rates to Nvidia’s GPUs. This is because of its DASE, scale-out, all-flash architecture and use of storage-class memory for metadata.
He says enterprises will find it easier to adopt Nvidia SuperPOD AI with a NAS-type storage facility than with parallel file systems, which are a complex and downtime-prone HPC niche. In Hallak’s view: “Parallel file systems are not easy enough to use and resilient enough to go into the enterprise. … Enterprises cannot deal with parallel file systems.”
Up until now, “enterprise grade file systems were not fast enough to feed the GPUs.” He reckons VAST’s technology, confirmed by its SuperPOD certification, means that it is the first enterprise-grade file system to bridge parallel file system I/O speed and scalability to enterprise NAS reliability and acceptability.
“I can tell you that we’ve already sold several SuperPOD deals – SuperPODs, with VASTs connected to them. And that we have many, many, many more in the pipeline. We’re seeing basically anyone who is trying to build a large AI cluster call us, now that this announcement has been made, and ask: ‘Is it really true that I don’t need a parallel file system anymore?’ And this is driving a bigger piece of our business.”
As for alternative enterprise NAS systems, Hallak says: “You can’t scale those architectures to the level that these new workloads require. … We have clusters today that are half an exabyte in size.”
It’s both a capacity and an I/O problem at scale – not just one or the other. He pointed out: “You can do a lot of access to a little bit of capacity. [Or] you can do a lot of capacity with a little bit of access.” VAST’s technology, he says, enables both high capacity and high I/O rates.
Data catalog and database
The data catalog is going to be developed. Hallak said: “Right now it’s built in tabular form. So it’s very similar to what you would find in a data warehouse. But over time, we’re going to add more abilities into this database.” We suggested vector embedding data types – necessary for AI work – but Hallak wouldn’t be drawn. Our impression was that vector database facilities will be supported.
He said the VAST system “is a data analysis software data platform.” It’s different from data warehouse and data lakehouse companies because “These companies were built for machine learning for numbers – for rows and columns of a database. We are building this not for numbers and rows and columns of a database, but for deep learning for pictures and genomes and videos.”
Traditionally, storage companies don’t build system-level infrastructure software. Yet this is what VAST is doing.
Hallak said: “I like to look at what is the biggest problem that needs solving. What is the optimal solution for that problem? How close can we get to that optimal solution? And that way, I find that we build something that is completely different than what everybody else has built.
“You don’t find storage companies building out database functionality. And that’s because they look at each other, and they say ‘nobody else has done it, we’re not going to do it.’ We ask the customer, ‘what would you like to see?’ And then we accommodate for that. And we leverage our architecture to do it in a much better way than it was done before.”
The focus of his storage attention is moving up the stack. Hallak again: “Everything is data-centric. … You still need a hardware piece and SSD to store the information. You still need a CPU to run logic. You still need a network to connect those two. … We are that data, the middle of the sandwich data infrastructure stack.”
“Wherever our customers take us, we will expand to. We started with storage, because it was the anchor of the datacenter. And it needed fixing, such that you have fast access to a lot of information. Now that we’ve solved that, there are a lot of other pieces to this puzzle that we’re working on building.”
His ambition here, his view of AI’s potential, is immense. Extraordinary. “I will say that whoever builds true artificial intelligence first – when I say true artificial intelligence, I’m talking about a machine that can generate ideas that can solve and understand energy better than we do, understand disease better than we do, those types of things – will be the wealthiest men on the planet. Because that’s game over. Once we reach that level, then you can take over everything else.”
Comment
Hallak is driving VAST to build a software integration layer that will be an AI-capable front-end and database. It will be a vertically integrated storage to CPU+GPU to data infrastructure software system. In our view, he wants this to be the enterprise generative AI workhorse through which VAST’s revenues will climb to billions of dollars a year.
HPE, with its GreenLake adoption of VAST, will funnel VAST systems to mid-range enterprises – so far ignored by VAST. VAST’s own salesforce will concentrate on the larger enterprises and ride the Nvidia generative AI wave to leapfrog every other storage supplier in the AI market. Startup founders have to have confidence in their own judgements, luck in timing, and a market needing their product. Hallak is convinced VAST is in the right place at the right time with the right – the only – product that meets the need.
The big three public clouds are also in the generative AI game. So too is Dell with Project Helix, Pure Storage, along with DDN, IBM, NetApp, and WEKA. They are all hungry for generative AI glory and won’t want to concede a market millimeter to VAST Data. This is going to be an almighty clash.




