


Pure Storage identifies itself as an AI data platform, storing and supplying data storage for AI training and inference workloads, whether they take place in the public cloud or on-premises, in datacenters, and large and small edge IT locations. It supplies this storage to bare-metal, virtual machines or containerized AI workloads, and does so as an integrated component of AI production work streams.
Generative AI – the application of machine learning Large language Models (LLMs) to provide knowledgeable responses to conversational-style text input – is revolutionizing the business intelligence world, with its ability to turn a speech-style request about a business issue – “Give me the top ten branch revenue locations for battery widgets over the Easter period” – into detailed SQL code, run the query and then provide an answer in text terms.
Such LLMs first need training, and this can require repeated runs against very large, indeed massive – exabyte-scale – data sets by GPU processing systems with hundreds if not thousands of GPUs involved. The expensive GPUs need a constant and high-speed supply of generalized data to complete training runs, which can take hours or even days – with interim checkpointed results written to storage to protect against failures causing whole job restarts.
When the trained LLMs are applied to user requests then they complete their responses much faster – in seconds or less. These responses can be augmented with a user’s own proprietary data sets in what is called Retrieval Augmented Generation (RAG) with the RAG data fed to the LLM from a storage system.
This is the basic Gen AI landscape, and the LLM processing can take place either in the public cloud or on-premises private cloud locations, or use both in a hybrid cloud arrangement. The public cloud provides immense and on-demand scalability, both for GPUs and for storage. The on-premises environment provides better location control for data and generally faster response for AI inference workloads at edge IT sites.
A diagram shows this fundamental AI environment and has Pure Storage’s main product offers included:
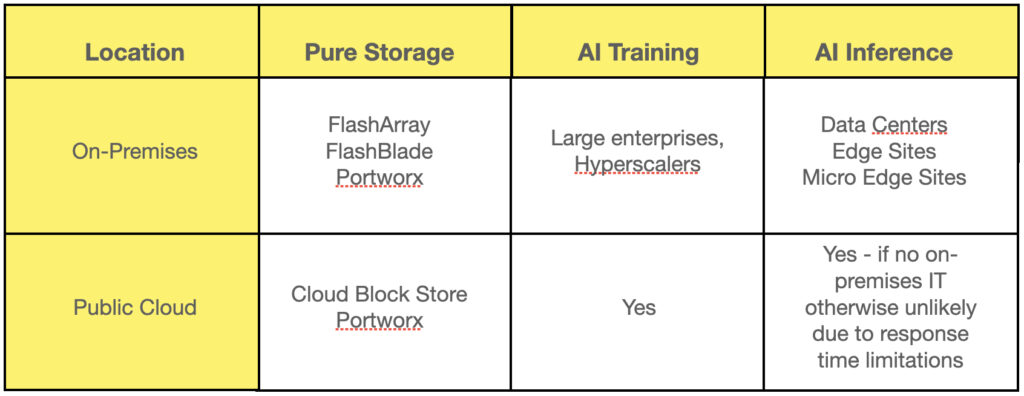
B&F talked with Shawn Rosemarin, Pure’s VP for R&D, about Pure Storage and data storage and supply for AI.
B&F: How should an enterprise approach generative AI training workloads? Run them on premises versus in the public cloud? What are the decision criteria for that?
Shawn Rosemarin: So, obviously, cost is a factor. If we think about cost on-prem, it clearly requires a significant investment if you’re going CAPEX, although there are as-a-service models such as Pure’s Evergreen//One, growing in popularity. But it’s not just the cost of the equipment. It’s also do you have the space, the power and the cooling to actually accommodate this AI infrastructure? I think that’s been largely ignored in the narrative to date.
Also, it’s not just do you have the absolute power? Do you have the density? If you think of a traditional datacenter being built for X megawatts, with a density element of 14 to 16 kilowatts per rack, this proposed AI infrastructure could easily consume the density of a rack within six or eight rack units, which is essentially 1/6 of the rack’s physical space.
Then you have to ask: do you have the budget to pay for that electricity on an ongoing basis? Do you have access to growth of the electricity supply over time? And more specifically, is this something that you can take on given the footprint of your existing application set?
All-in-all I think electricity is a kind of silent killer here that no one’s been thinking about.
Now, in the public cloud, it’s great because I don’t need to buy all that infrastructure up front. But, let’s assume I can get access to unlimited scale. If I don’t properly control my environment, I could end up with a bill similar to one that my friends used to get back in the early 1990s when they were streaming the World Cup over their cell phone. They didn’t realize that this would be one of the most expensive games ever observed. So I think cost controls are a big element of this as well.
B&F: Are there aspects of scalability which we need to understand?
Shawn Rosemarin: When we think about scale, it’s not just how big is it going to be. I may start on block, and then it may actually move to file or it might move to object. I may start on Nvidia GPUs, and then, years from now, there might be an alternative infrastructure for me to use. I think this is really important, because these applications will likely go through rescaling and re-platforming more than mature applications will.
When you look at Pure’s ability through the years to help customers to manage that aspect of scale and data migration, non-disruptively, whether capacity or performance, I think that’s a key consideration.
B&F: Is there a third factor to bear in mind?
Shawn Rosemarin: The third decision factor would be around security and compliance. I’m fascinated because as you look at RAG, this new concept of being able to take a traditional LLM, and have it learn my data – my proprietary data, my gold – I think that organizations will be very cautious about putting their proprietary datasets in the cloud.
They may very well run their LLMs in the cloud, but they will likely use “direct connect” capabilities to actually keep their data on-prem, and put their results on-prem, but leverage the bulk of the general purpose libraries in the cloud. Naturally, encryption at both a volume and array level will also be crucial here.
B&F: Are there things that Pure can do, either on premises or in the cloud. to help mitigate the money cost and the electricity supply and allied costs?
Shawn Rosemarin: A lot of these services that are being delivered are on siloed infrastructure. In many cases, if you want to use these datasets for AI, you have to migrate them so that you can get enough horsepower out of your storage in order to actually feed your GPUs.
When you look at Pure’s product and platform we eliminate these complex data migrations by allowing customers to run their AI workloads in tandem to their production workloads. There’s more than enough overhead, capacity and performance, so these migrations are not necessary.
We’re also very focused on energy and density at scale. In fact, our latest ESG report demonstrated that we’re 80 percent more efficient than traditional storage infrastructure. In some cases, even more than that.
What this does is free up the energy typically consumed by storage for customers so they afford to turn on the GPUs in their environment.
The other thing is that the majority of these environments, when running in containers, have a lot of inefficiency in the way in which containers interact with storage, through the container storage interface (CSI) drivers. You actually lose a lot of storage efficiency through this CSI transmission layer between Kubernetes and the storage itself.
At scale, we’re seeing our Portworx container storage technology as a better option to proprietary CSIs and, when combined our electricity and density savings, giving customers a more responsible and a more efficient way to scale for AI workloads.
B&F: Are you saying that, with Pure, storage efficiency gains are so large that you can transfer part of your anticipated storage cost and electricity budget to run GPU compute instead?
Shawn Rosemarin: That’s exactly it. The fact is, we’re on the cusp of an energy crisis. I truly believe the silent killer of AI is access to electricity. We’re seeing this problem emerge. We saw Microsoft’s Azure go and actually purchase a nuclear power plant a couple of weeks ago, so that they could power their own facility.
It’s going to take us time to develop alternative energy sources, but I’m confident that we will eventually innovate our way out of this problem. The challenge for an enterprise right now is “how long can I make that bridge?” So if I consume the way I’ve been consuming, I run out of power in, hypothetically, say eight months, right? That being said, as I stand up AI workloads and GPUs, I will have to decide which applications in my environment I’m willing to turn off and willing to actually take out of my datacenter to free up available power.
Alternatively, if I’m working with Pure, with our efficiency and density, I can take that 80 percent saving and extend that bridge from eight months to 24 or 36 months. I’ve now bought myself some time and can wait for key innovations in the world that will grant me easier and more affordable access to power.
The other alternative is: I go out and buy a bunch of datacenters that have grandfathered in power supplies, or I buy a nuclear power plant, or I find a way to open an office in an alternative country that is still offering available power to datacenters – but this opportunity is increasingly difficult.
Also, let’s be honest: we have a collective responsibility to make sure that we don’t allocate so much power to AI that we actually put the electricity grid for citizens at risk.
****
The second part of this interview is here.





