Dell is launching an all-flash deduping PowerProtect backup target appliance, providing competition for all-flash systems from Pure Storage (FlashBlade), Quantum, and Infinidat.
The company is also announcing PowerStore enhancements at its Las Vegas-based Dell Technologies World event, plus Dell Private Cloud and NativEdge capabilities.
Arthur Lewis, Dell’s president, Infrastructure Solutions Group, stated: “Our disaggregated infrastructure approach helps customers build secure, efficient modern datacenters that turn data into intelligence and complexity into clarity.”
There are currently four PowerProtect systems plus a software-only virtual edition, offering a range of capacities and speeds.
The All-Flash Ready node is basically a Dell PowerEdge R760 server with 24 x 2.5-inch SAS-4 SSD drives and 8 TB HDDs for cache and metadata, a hybrid flash and disk server. The capacity is up to 220 TB/node and a node supports up to 8 x DS600 disk array enclosures, providing 480 TB raw each, for expanded storage.
The PowerProtect Data Domain All-Flash DD9910F appliance restores data up to four times faster than an equivalent capacity PowerProtect disk-based system, based on testing the DD9910F and an HDD-using DD9910. We don’t get given actual restore speed numbers for any PowerProtect appliance, and Dell isn’t providing the all-flash DD9910F ingest speed either.
All-flash PowerProtect systems have up to twice as fast replication performance and up to 2.8x faster analytics. This is based on internal testing of CyberSense analytics performance to validate data integrity in a PowerProtect Cyber Recovery vault comparing a disk-based DD9910 appliance to the all-flash DD9910F at similar capacity.
They occupy up to 40 percent less rack space and save up to 80 percent on power compared to disk drive-based systems. With Dell having more than 15,000 PowerProtect/Data Domain customers, it has a terrific upsell opportunity here.
PowerStore, the unified file and block storage array, is being given Advanced Ransomware Detection. This validates data integrity and minimizes downtime from ransomware attacks using Index Engines’ CyberSense AI analytics. This indexes data using more than 200 content-based analytic routines. The AI system used has been trained on over 7,000 variants of ransomware and their activity signals. According to Dell, it detects ransomware corruption with a 99.99 percent confidence level.
Dell says it’s PowerStore’s fifth anniversary and there are more than 17,000 PowerStore customers worldwide.
The company now has a Private Cloud to provide a cloud-like environment on premises, built using its disaggregated infrastructure – servers, storage, networking, and software. There is a catalog of validated blueprints. This gives Dell an answer to HPE’s Morpheus private cloud offering.
A Dell Automation Platform provides centralized management and zero-touch onboarding for this private cloud. By using it, customers can provision a private cloud stack cluster in 150 minutes, with up to 90 percent fewer steps than a manual process.
Dell has new NativeEdge products for virtualized workloads at the edge and in remote branch offices. These protect and secure data with policy-based load balancing, VM snapshots and backup and migration capabilities. Customers can manage diverse edge environments consistently with support for non-Dell and legacy infrastructure.
Comment
We expect that Dell announcing its first all-flash PowerProtect appliance will be the trigger ExaGrid needs to bring out its own all-flash product.
The Linus Tech Tips team has calculated Pi, the ratio of a circle’s circumference to its diameter, to a record 300 trillion decimal places with the help of AMD, Micron, Gigabyte, Kioxia, and WEKA.
Linus Sebastian and Jake Tivy of the Canadian YouTube channel produced a video about their Guinness Book of Records-qualified result.
From left, Linus Sebastian and Jake Tivy
The setup involved a cluster of nine Gigabyte storage servers and a single Gigabyte compute node, all running the Ubuntu 22.04.5 LTS operating system. This was because the memory-intensive calculation was done using the Y-cruncher application, which uses external storage as RAM swap space. Eight storage servers were needed to provide the storage capacity needed.
The storage servers were 1 RU Gigabyte R183-Z95-AAD1 systems with 2 x AMD EPYC 9374F CPUs and around 1 TB DDR5 ECC memory. They were fitted with dual ConnectX-6 200 GbE network cards, giving each one 400 GbE bandwidth. Kioxia NVMe CM6 and CD6 series SSDs were used for storage. Overall, there was a total of 2.2 PB of storage spread across 32 x 30.72 TB CM6 SSDs and 80 x 15.36 TB CD6 SSDs for 245 TB per server.
The compute node was a Gigabyte R283-Z96-AAE1 with dual 96-core EPYC 9684X 3D V-Cache CPUs and 196 threads/CPU. There was 3 TB of DRAM, made up from 24 x 128 GB sticks of Micron ECC DDR5 5600MT/s CL46 memory. It was equipped with 4 x Nvidia ConnectX-7 200 GbE network cards with 2 x 200 GbE ports/card and 16 x PCIe Gen 5 bandwidth per slot capable of approximately 64 GBps bidirectional throughput. There was a total of 1.6 Tbps of throughput, around 100 GBps to each 96-core CPU.
WEKA parallel access file system software was used, providing one file system for all nine servers to Y-cruncher. The WEKA software was tricked into thinking each server was two servers so that the most space-efficient data striping algorithm could be used. Each chunk of data was divided into 16 pieces, with two parity segments – 16+2 equaling 18 – matching the 18 virtual nodes achieved by running two WEKA instances per server.
They needed to limit the amount of data that flowed between the CPUs to avoid latency build-ups from one CPU sending data to the other CPU’s network cards and there was also a limited amount of memory bandwidth.
Avoiding cross CPU memory transfers
Tivy configured two 18 GB WEKA client containers – instances of the WEKA application running on the compute node – to access the storage cluster. Each container had 12 cores assigned to it to match the 3D V-Cache of the Zen 4 CPU die. This has 12 chiplets sharing 32 MB of L3 cache with 64 MB layered above for a 96 MB total. Tivy did not want Y-cruncher’s buffers to spill out of that cache because that would mean more memory copies and more memory bandwidth would be needed.
WEKA’s write throughput was around 70.14 GBps and this was over the network with a file system. Read testing showed up to 122.63 GBps with a 2 ms latency. The system was configured with 4 NUMA nodes per CPU, which Y-cruncher leveraged for better memory locality. When reconfigured to a single NUMA node per socket, bandwidth increased increased to 155.17 GBps.
The individual Kioxia CD6 drive read speeds were in excess of 5 GBps. Tivy set the record for the single fastest client usage, according to WEKA. Tivy said WEKA subsequently broke that record with GPUDirect storage and RDMA.
Tivy says Y-cruncher uses the storage like RAM, as RAM swap space. That’s why so much storage is needed. The actual Y-cruncher output of 300 trillion digits is only about 120 TB compressed. Their system used about 1.5 PB of capacity at peak. Y-cruncher is designed for direct-attached storage without hardware or software RAID, as it implements its own internal redundancy mechanisms.
The Linus Tech Tips Pi project started its run on August 1, 2024, and crashed 12 days later due to a multi-day power outage. The run was restarted and then executed past shorter-term power cuts and air-conditioning failures, meaning the calculation had to stop and restart, to complete 191 days later. At that time, they discovered that the 300 trillionth digit of Pi is 5.
Pi calculation history
Here is a brief history of Pi calculation records:
Around 250 BCE: Archimedes approximated π as approximately 22/7 (~3.142857).
5th century CE: Chinese mathematician Zu Chongzhi calculated π to 7 digits (3.1415926), a record that lasted almost 1,000 years.
1596: Ludolph van Ceulen calculated π to 20 digits using Archimedes’ method with polygons of up to 262 sides.
1706: John Machin developed a more efficient arctangent-based formula, calculating π to 100 digits.
1844: Zacharias Dase and Johann Martin Strassmann computed π to 200 digits.
By 1873: William Shanks calculated π to 707 digits. Only the first 527 digits were correct due to a computational error.
By 1949: The ENIAC computer calculated π to 2,037 digits, the beginning of computer-based π calculations.
By 1989: The Chudnovsky brothers calculated π to over 1 billion digits on a supercomputer.
1999: Yasumasa Kanada computed π to 206 billion digits, leveraging the Chudnovsky algorithm and advanced hardware.
2016: 22.4 trillion digits computed by Peter Trueb taking 105.524 days to compute,
2019: Emma Haruka Iwao used Google Cloud to compute π to 31.4 trillion digits (31,415,926,535,897 digits).
2021: Researchers at the University of Applied Sciences of the Grisons, Switzerland, calculated π to 62.8 trillion digits, using a supercomputer, taking 108 days and nine hours.
2022: Google Cloud, again with Iwao, pushed the record to 100 trillion digits, using optimized cloud computing.
This record could surely be exceeded by altering the Linus Tech Tips configuration to one using GPU servers, with an x86 CPU host, GPUs with HBM, and GPUDirect links to faster and direct-attached (Kioxia CM8 series) SSDs. Is a 1 quadrillion decimal place Pi calculation within reach? Could Dell, HPE, or Supermicro step up with a GPU server? Glory awaits.
Nvidia is turning itself into an AI datacenter infrastructure company and storage suppliers are queuing up to integrate their products into its AI software stack. DDN, HPE, and NetApp followed VAST Data in announcing their own integrations at Taiwan’s Computex 2025 conference.
DDN and Nvidia launched a reference design for Nvidia’s AI Data Platform to help businesses feed unstructured data like documents, videos, and chat logs to AI models. Santosh Erram, DDN’s global head of partnerships, declared: “If your data infrastructure isn’t purpose-built for AI, then your AI strategy is already at risk. DDN is where data meets intelligence, and where the future of enterprise AI is being built.”
The reference design combines DDN Infinia with Nvidia’s NIM and NeMo Retriever microservices, RTX PRO 6000 Blackwell Server Edition GPUs, and its networking. Nvidia’s Pat Lee, VP of Enterprise Strategic Partnerships, said: “Together, DDN and Nvidia are building storage systems with accelerated computing, networking, and software to drive AI applications that can automate operations and amplify people’s productivity.” Learn more here.
HPE
Jensen Huang
Nvidia founder and CEO Jensen Huang stated: “Enterprises can build the most advanced Nvidia AI factories with HPE systems to ready their IT infrastructure for the era of generative and agentic AI.”
HPE president and CEO Antonio Neri spoke of a “strong collaboration” with Nvidia as HPE announced server, storage, and cloud optimizations for Nvidia’s AI Enterprise cloud-native offering of NIM, NeMo, and cuOpt microservices, and Llama Nemotron models. The Alletra MP X10000 unstructured data storage array node product will introduce an SDK for Nvidia’s AI Data Platform reference design to offer customers accelerated performance and intelligent pipeline orchestration for agentic AI.
The SDK will support flexible inline data processing, vector indexing, metadata enrichment, and data management. It will also provide remote direct memory access (RDMA) transfers between GPU memory, system memory, and the X10000.
Antonio Neri
HPE ProLiant Compute DL380a Gen12 servers featuring RTX PRO 6000 Blackwell GPUs will be available to order on June 4. HPE OpsRamp cloud-based IT operations management (ITOM) software is expanding its AI infrastructure optimization features to support the upcoming RTX PRO 6000 Blackwell Server Edition GPUs for AI workloads. The OpsRamp integration with Nvidia’s infrastructure including its GPUs, BlueField DPUs, Spectrum-X Ethernet networking, and Base Command Manager will provide granular metrics to monitor the performance and resilience of the HPE-Nvidia AI infrastructure.
HPE’s Private Cloud AI will support the Nvidia Enterprise AI Factory validated design. HPE says it will also support feature branch model updates from Nvidia AI Enterprise, which include AI frameworks, Nvidia NIM microservices for pre-trained models, and SDKs. Support for feature branch models will allow developers to test and validate software features and optimizations for AI workloads.
NetApp
NetApp’s AIPod product – Nvidia GPUs twinned with NetApp ONTAP all-flash storage – now supports the Nvidia AI Data Platform reference design, enabling RAG and agentic AI workloads. The AIPod can run Nvidia NeMo microservices, connecting them to its storage. San Jose-based NetApp has been named as a key Nvidia-Certified Storage partner in the new Enterprise AI Factory validated design.
Nvidia’s Rob Davis, VP of Storage Technology, said: “Agentic AI enables businesses to solve complex problems with superhuman efficiency and accuracy, but only as long as agents and reasoning models have fast access to high-quality data. The Nvidia AI Data Platform reference design and NetApp’s high-powered storage and mature data management capabilities bring AI directly to business data and drive unprecedented productivity.”
NetApp told us “the AIPod Mini is a separate solution that doesn’t incorporate Nvidia technology.”
Availability
HPE Private Cloud AI will add feature branch support for Nvidia AI Enterprise by Summer.
HPE Alletra Storage MP X10000 SDK and direct memory access to Nvidia accelerated computing infrastructure will be available starting Summer 2025.
HPE ProLiant Compute DL380a Gen12 with RTX PRO 6000 Server Edition will be available to order starting June 4, 2025.
HPE OpsRamp Software will be available in time to support RTX PRO 6000 Server Edition.
Bootnote
Dell is making its own AI Factory and Nvidia-related announcements at its Las Vegas-based Dell Technologies World conference. AI agent builder DataRobot announced its inclusion in the Nvidia Enterprise AI Factory validated design for Blackwell infrastructure. DataRobot and Nvidia are collaborating on multiple agentic AI use cases that leverage this validated design. More information here.
HPE expands its storage guarantee program with new SLAs for cyber resilience, zero data loss, and energy efficiency
Today’s enterprise storage customers demand more than just technology; they seek assured IT outcomes. HPE Alletra Storage MP B10000 meets this requirement head-on with an AIOps-powered operational experience and disaggregated architecture that lowers TCO, improves ROI, mitigates risk, and boosts efficiency. We stand behind these promises with industry-leading SLAs and commitments that include free non-disruptive controller upgrades, 100 percent data availability, and 4:1 data reduction.
We’re taking our storage guarantee program to the next level with the introduction of three new B10000 guarantees for cyber resilience, energy efficiency, and zero data loss. These SLA-driven commitments give B10000 customers the confidence and peace of mind to recover quickly from ransomware attacks, lower energy costs with sustainable storage, and experience zero data loss or downtime.
Here’s a breakdown of the new guarantees.
Achieve ransomware peace of mind with cyber resilient storage—guaranteed
Ransomware remains a significant threat to organizations globally, affecting every industry. And attacks are becoming increasingly sophisticated and costly, evolving at an unprecedented pace.
The B10000 offers a comprehensive suite of storage-level ransomware resilience capabilities to help you protect, detect, and rapidly recover from cyberattacks. It features real-time ransomware detection using anomaly detection methodologies to identify malicious encryption indicative of ransomware attacks. In the event of a breach, the B10000 facilitates the restoration of uncorrupted data from tamper-proof immutable snapshots, significantly reducing recovery time, costs, and potential data loss. It also helps identify candidates for data recovery by pinpointing the last good snapshots taken before the onset of an anomaly.
We’re so confident in the built-in ransomware defense capabilities of the B10000 and our professional services expertise that we’re now offering a new cyber resilience guarantee1. This guarantees you access to an HPE services expert within 30 minutes of reporting an outage resulting from a ransomware incident, enabling you to rapidly address and mitigate the impact of a cyberattack. It also ensures that all immutable snapshots created on the B10000 remain accessible for the specified retention period.
HPE’s expert-led outage response services diagnose ransomware alerts and speed up locating and recovering snapshot data. In the unlikely event that we can’t meet the guarantee commitment, we offer you compensation.
Lower your energy costs with sustainable storage—guaranteed
Modern data centers are significant consumers of energy, contributing to 3.5 percent of global CO2 emissions2, with 11 percent of data center power used for storage3. As data grows exponentially, so does the environmental and cost impact. Transitioning from power-hungry, hardware-heavy legacy infrastructure to modern, sustainable storage is no longer optional; it’s now a fundamental business imperative.
The B10000 features a power-efficient architecture that enhances performance, reliability, and simplicity while helping reduce energy costs, carbon emissions, and e-waste compared to traditional storage. With the B10000, you can reduce your energy consumption by 45 percent4, decrease your storage footprint by 30 percent5, and lower your total cost of ownership by 40 percent6.
The B10000 achieves these impressive sustainability outcomes with energy-efficient all-flash components, disaggregated storage that extends product life cycles while reducing e-waste, advanced data reduction capabilities, and AI-powered management that optimizes resource usage. Better still, B10000 management tools on the HPE GreenLake cloud like the HPE Sustainability Insight Center and the Data Services Cloud Console provide visibility into energy consumption and emissions, enabling informed decision-making to meet sustainability goals.
Because the B10000 is designed for sustainability, performance, and efficiency, we can guarantee that it operates at optimized power levels while maintaining peak performance. Our new energy consumption guarantee7 promises that your B10000 power usage will not exceed an agreed maximum target each month. This helps ensure that you can plan for and count on a maximum power budget. If you exceed the energy usage limit, you will receive a credit voucher to offset your additional energy costs.
Sleep better at night with zero data loss or downtime—guaranteed
Application uptime is more important today than it’s ever been. Data loss and downtime mean lost time and money. You need highly available storage that will ensure multi-site business continuity and data availability for your mission-critical applications in the event of unexpected disruptions.
That’s why we are introducing a new HPE Zero RTO / RPO guarantee for the B100008. It’s a cost-nothing, do-nothing guarantee that is unmatched in the industry. The active peer persistence feature of the B10000 combines synchronous replication and transparent fail-over across active sites to maintain continuous data availability with no data loss or downtime—even in the event of site-wide or natural disasters. Because active peer persistence is built into the B10000, there are no additional appliances or integration required.
If your application loses access to data during a fail-over, we will proactively provide credit that can be redeemed upon making a future investment in the B10000.
Simplify and future-proof your storage ownership experience
In today’s fast-moving business world, your data infrastructure needs to keep up without surprises, disruptions, or unexpected costs. HPE Alletra Storage MP B10000 simplifies and future-proofs your experience, offering guaranteed outcomes, investment protection, and storage that gets better over time.
With the B10000, you get best-in-class ownership experience on the industry’s best storage array. And our outcome-focused SLAs provide peace of mind, so you can focus on business objectives rather than IT operations. Your storage stays modern, your costs stay predictable, and your business stays ahead.
The cyber resilience guarantee is available on any B10000 system running OS release 10.5. The guarantee is applicable whether you purchase your B10000 system through a traditional up-front payment or through the HPE GreenLake Flex pay-per-use consumption model. To be eligible for the guarantee, you will need to have an active support contract with a minimum three-year software and support software-as-a-service (SaaS) subscription.
“Top Recommendations for Sustainable Data Storage,” Gartner, November 2024.
“Top Recommendations for Sustainable Data Storage,” Gartner, November 2024.
Based on internal analysis comparing power consumption, cooling requirements, and energy efficiency when transitioning from spinning disk to HPE Alletra Storage MP all-flash architecture.
Based on internal use case analysis, HPE Alletra Storage MP B10000 reduces total cost of ownership (TCO) versus non-disaggregated architectures by allowing organizations to avoid overprovisioning.
Unlike competitive energy efficiency SLAs, the B10000 guarantee is applicable whether you purchase your B10000 system through a traditional up-front payment or the HPE GreenLake Flex pay-per-use consumption model. To qualify for this guarantee, an active HPE Tech Care Service or HPE Complete Care Service contract is required.
To qualify for the HPE Zero RTO/RPO guarantee, customers must have an active support contract, identical array configurations in the replication group, and a minimum three-year SaaS subscription.
VAST Data is integrating Nvidia’s AI-Q AI agent building and connecting blueprints into its storage to help its customers enter the AI agent-building rat race.
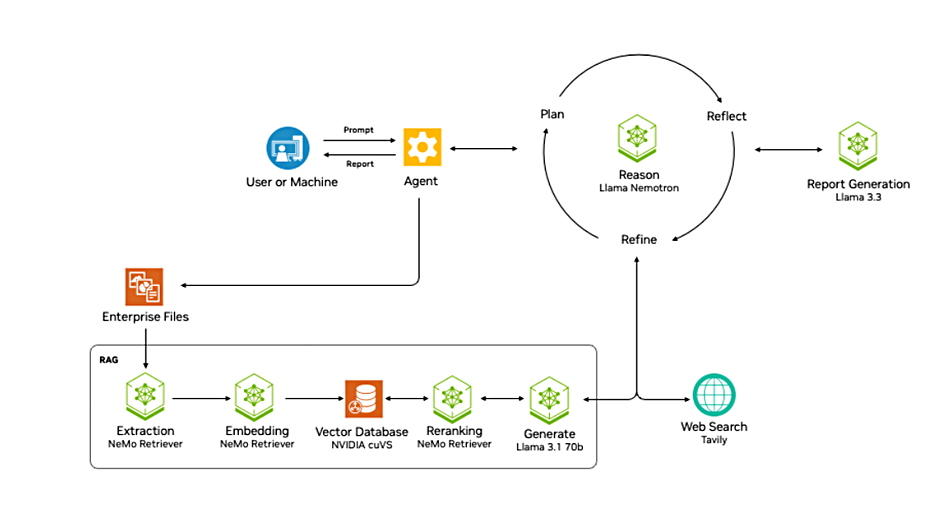
AI-Q is a blueprint or reference design plan for integrating Nvidia GPUs, partner storage platforms, and software and Agent Intelligence Toolkit when developing AI agents. It includes Nvidia’s Llama Nemotron reasoning models, NeMO retriever and NIM microservices. The Agent Intelligence Toolkit, available on GitHub, is an open-source software library for connecting, profiling and optimizing teams of AI agents. It integrates with frameworks and tools like CrewAI, LangGraph, Llama Stack, Microsoft Azure AI Agent Service and Letta. A storage partner, such as VAST, continually processes data so that connected agents can respond to data changes, reasoning and acting on them.
Jeff Denworth.
Jeff Denworth, Co-Founder at VAST Data, stated: “The agentic era is going to challenge every assumption about the scale, performance, and value of legacy infrastructure. As enterprises race to operationalize AI, it’s no longer enough to just build smarter models — those models need immediate, unrestricted access to the data that drives intelligent decision-making. By embedding NVIDIA AI-Q into a platform purpose-built for the AI era, we’re delivering the scalable, high-performance data platform required to power the next generation of enterprise AI; one driven by real-time, multimodal intelligence, continuous learning, and dynamic agentic pipelines.”
VAST Data says the AI-Q blueprint “povides an environment for rapid metadata extraction and establishes heterogeneous connectivity between agents, tools, and data, simplifying the creation and operationalization of agentic AI query engines that reason across structured and unstructured data with transparency and traceability.”
Within the AI-Q environment, the VAST Data storage and AI engine component data stack is a secure, AI-native pipeline that takes raw data and transforms and feeds it upstream to AI Agents. As part of that Nemo Retriever is used by VAST and AI-Q to extract, embed, and rerank relevant data before passing it to advanced language and reasoning models.
Nvidia AI-Q diagram.
VAST plus AI-Q will provide:
Multi-modal unstructured and semi-structured data RAG including enterprise documents, images, videos, chat logs, PDFs, and external sources like websites, blogs, and market data.
Structured data with VAST connecting AI agents directly to structured data sources such as ERP, CRM, and data warehouses for real-time access to operational records, business metrics, and transactional systems.
Fine-grained user and agent access control through policies and security features.
Real-time agent optimization via Nvidia’s Agent Intelligence Toolkit and VAST’s telemetry.
Justin Boitano.
VAST says it and Nvidia are enabling organizations to build real-time AI intelligence engines to enable teams of AI agents to deliver more accurate responses, automate multi-step tasks, and continuously improve via an AI data flywheel.
Justin Boitano, VP, Enterprise AI at Nvidia, said: “AI-driven data platforms are key to helping enterprises put their data to work to drive sophisticated agentic AI systems. Together, NVIDIA and VAST are creating the next generation of AI infrastructure with powerful AI systems that let enterprises quickly find insights and knowledge stored in their business data.”
VAST’s Jon Mao, VP of Business Development and Alliances, blogs “By leveraging the Nvidia AI-Q blueprint and a powerful suite of Nvidia software technologies — from Nvidia NeMo and Nvidia NIM microservices to Nvidia Dynamo, Nvidia Agent Intelligence toolkit, and more — alongside the VAST InsightEngine and our VUA acceleration layer, this platform empowers enterprises to deploy AI agent systems capable of reasoning over enterprise data, to deliver faster, smarter outcomes. It’s a new kind of enterprise AI stack, built for the era of AI agents — and VAST is proud to be leading the way.”
Read more in Mao’s blog.
Comment
Until recently a storage system only needed to support GPUDirect to deliver data fast to Nvidia’s GPUs. Now it needs to integrate with the Nvidia AI-Q blueprint and continually feed data to Nvidia agents and AI software stack components, which use the GPUs, so as to become an Nvidia AI data platform. We predict more storage suppliers will adopt AI-Q
Western Digital has extended its platform chassis business at Computex with a new disk drive box, NVMe SSD box, qualified partner SSDs, and an extended compatibility lab.
The company, before the SanDisk split, had a storage systems business, which included IntelliFlash arrays, ActiveScale object storage systems, the Kazan Networks PCIe-to-NVMe bridge business, and Ultrastar JBODS and OpenFlex JBOFs. This business was ultimately discontinued, with some components sold off – IntelliFlash to DDN in 2019 and ActiveScale to Quantum in 2020. That left it with the Ultrastar and OpenFlex chassis, and RapidFlex PCIe-NVMe bridge technologies grouped under a platforms banner. It spun off the Sandisk NAND fab and SSD business earlier this year, leaving its revenues overwhelmingly dominated by disk drive sales, yet it retained the SSD side of the platforms business and is now emphasizing its commitment with this set of releases.
Western Digital is announcing a new Ultrastar Data102 JBOD that is OCP ORv3 compliant, the OpenFlex Data24 4100 Ethernet-connected JBOF (EBOF) with single-port SSDs, which complements the existing 4200 with its dual-port SSD, new SSD qualifications for the OpenFlex chassis, and new capabilities in Western Digital’s Open Composable Compatibility Lab (OCCL).
Kurt Chan
Kurt Chan, VP and GM of Western Digital’s Platforms Business, stated: “With OCCL 2.0 and our latest Platform innovations, we’re not just keeping up – we’re setting the pace for what modern, disaggregated, and software-defined datacenters can achieve. We remain deeply committed to enabling open, flexible architectures that empower customers to build scalable infrastructure tailored to their evolving data needs.”
The Ultrastar Data102 3000 ORv3 JBODis designed to meet the Open Rack v3 (ORv3) specification, which focuses on rack design and power supply regulation. It complies with Rack Geometry Option 1, uses building blocks from the Data102 3000 series such as controllers, enclosures, and Customer Replaceable Units (CRUs), and is compliant with FIPS 140-3 Level 3 and TAA standards.
This chassis features up to 2.44 PB of raw capacity in a 4RU enclosure with 102 drive slots. There can be dual-port SAS for high availability or single-port SATA for cloud-like applications and economics, and up to 12 x 24 Gbps SAS-4 host connections.
Ultrastar Data102 3000
The OpenFlex Data24 4100 EBOF is designed for cloud-like environments where high availability is not a primary requirement. It uses single-port SSDs, up to 24 of them, where redundancy is provided by mirroring the storage system.
Western Digital says it has qualified SSDs from DapuStor, Kioxia, Phison, Sandisk and ScaleFlux with more vendors in the qualification process.
OpenFlex Data24 4100
The Western Digital Open Composable Compatibility Lab (OCCL) was set up in August 2019, Colorado Springs, to encourage support for open, composable, disaggregated infrastructure (CDI). It provided interoperability testing with partners like Broadcom and Mellanox for NVMe-over-Fabrics (NVMe-oF) systems, like its OpenFlex components, and therefore involved SSDs.
It is now launching OCCL v2.0, saying it will provide testing across disaggregated compute, storage and networking for NVMe-oF architecture systems – still having an SSD focus unless NVMe-accessible disk drives are in development – and components featuring:
Detailed solution architectures with guidance on deploying and managing composable disaggregated infrastructure effectively.
Disaggregated storage best practices.
Industry Expertise sharing strategic insights and innovations in the field of composable infrastructure.
SSD partner benchmarking with comprehensive results from benchmarking tools to evaluate the performance of SSD partners, ensuring optimal storage solutions.
The Data24 4100 is expected to be available in calendar Q3 2025 with the Data102 3000 expected in calendar Q4 2025.
Visit Western Digital at Computex in Taipei, at booth J1303a in Hall 1 Storage and Management Solutions at the Taipei Nangang Exhibition Center from May 20-23.
Analysis.Cohesity is moving beyond data protection and cyber-resilience by building a real-time data access and management facility alongside its existing data protection access pipelines so that it can bring information from both live and backed-up data to GenAI models.
Greg Statton
This recognition came from a discussion with Cohesity’s VP for AI Solutions, Greg Statton, that looked at metadata and its use in AI data pipelining.
An AI model needs access to an organization’s own data so that it can be used for retrieval-augmented generation, thereby producing responses pertinent to the organization’s staff and based on accurate and relevant data. Where does this data come from?
An enterprise or public sector organization will have a set of databases holding its structured and also some unstructured information, plus files and object data. All this data may be stored in on-premises systems – block, file, or object, unified or separate – and/or in various public cloud storage instances. AI pipelines will have to be built to look at these stores, filter and extract the right data, vectorize the unstructured stuff, and feed it all to the AI models.
This concept is now well understood and simple enough to diagram:
All diagrams are Blocks & Files creations
This diagram shows a single AI pipeline, but that is a simplification as there could be several being fed from different data resources, such as ERM applications, data warehouses, data lakes, Salesforce and its ilk, and so forth. But bear with us as we illustrate our thinking with a single pipeline.
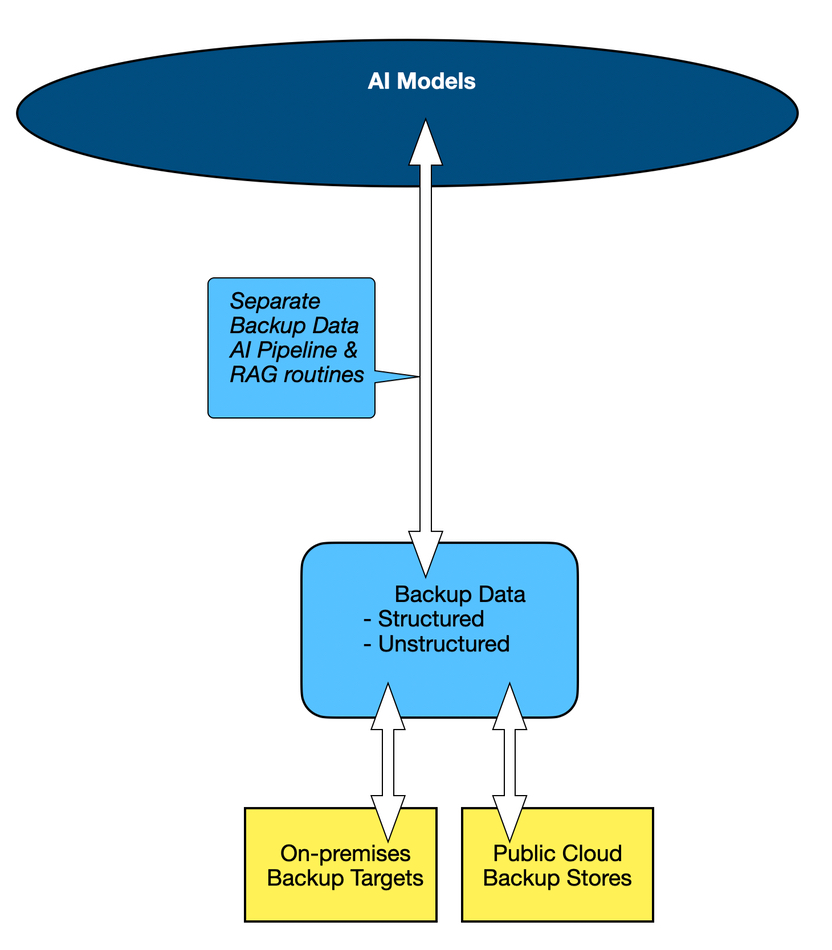
We’re calling this data live data, as it is real-time, and as a way of distinguishing it from backup data. But, of course, there are vast troves of data in backup stores and an organization’s AI Models get another view of its data estate which they can mine for user request responses. Data protection suppliers, such as Cohesity, Commvault, Rubrik, and Veeam. All four, and others, are building what we could call backup-based AI pipelines. Again, this can be easily diagrammed:
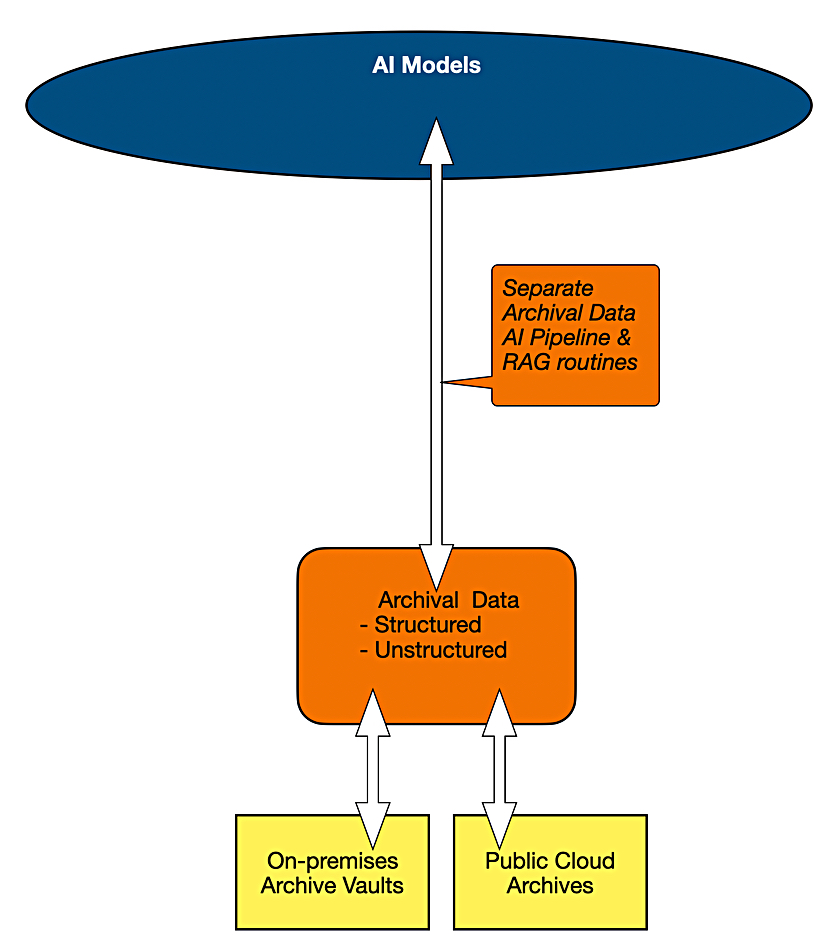
We now have two different AI data pipelines, one for live data and one for backup data. But that’s not all; there is also archival data, stored in separate repositories from the live and backup data. We can now envisage a third archival data AI pipeline is needed and, again, it is simple to diagram:
We are now at the point of having three separate AI model data pipelines – one each for live data, backup data, and archival data:
Ideally, we need all three, as together they provide access to the totality of an organization’s data.
This is wonderful but it comes with a considerable disadvantage. Although it gives the AI models access to all of an organization’s data, it is inefficient, will take some considerable time to build and also effort to maintain. As on-premises data is distributed between data centers and edge locations, and also the public cloud, and between structured and unstructured data stores, with the environment being dynamic and not static, ongoing maintenance and development will be extensive and necessary. This is going to be costly.
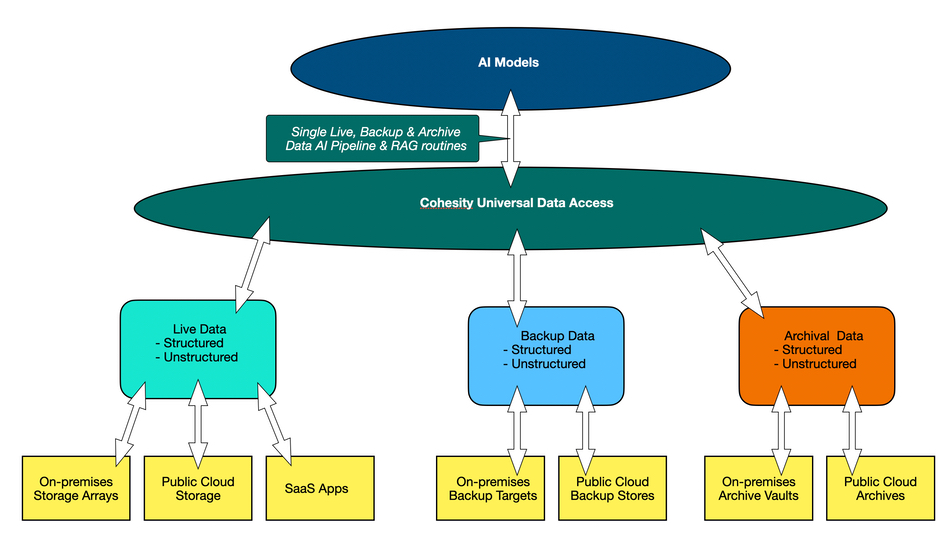
What we need is a universal data access layer, with touch points for live, backup and archive data, be it on-premises and distributed across sites and applications, in the public cloud as storage instances, or in SaaS applications, or a hybrid of these three.
Cohesity’s software already has touch points (connectors) for live data. It has to in order to back it up. It already stores metadata about its backups and archives. It already has its own AI capability, Gaia, to use this metadata, and also to generate more metadata about a backup item’s (database, records, files, objects, etc.) context and contents and usage. It can vectorize these items and locate them in vector spaces according to their presence or absence in projects for example.
Let’s now picture the situation as Cohesity sees it, in my understanding, with a single and universal access layer:
Cohesity can become the lens through which AI models look at the entirety of an organization’s data estate to generate responses to user questions and requests. This is an extraordinarily powerful yet simple idea. How can this not be a good thing? If an AI data pipeline function for an organization can not cover all three data types – live, backup, and archive – then it is inherently limited and less effective.
It seems to Blocks & Files that all the data protection vendors looking to make their backups data targets for AI models will recognize this, and want to extend their AI data pipeline functionality to cover live data and also archival stores. Cohesity has potentially had a head start here.
Another angle to consider – the live data-based AI pipeline providers will not be able to extend their pipelines to cover backup, also archive, data stores unless they have API access to those stores. Such APIs are proprietary and negotiated partnerships will be needed but may not be available. It’s going to be an interesting time as the various vendors with AI data pipelines wrestle with the concept of universal data access and what it means for their customers and the future of their own businesses.
An analyst report says disk drive capacity shipments are orojected to rise steeply bupwards between now and 2030.
Tom Coughlin
This data is included in Tom Coughlin’s latest 174-page Digital Storage Technology Newsletter which looks at how the three disk drive suppliers fared in the first 2025 quarter and forecasts disk drive units abd capacity shipped out to 2030.
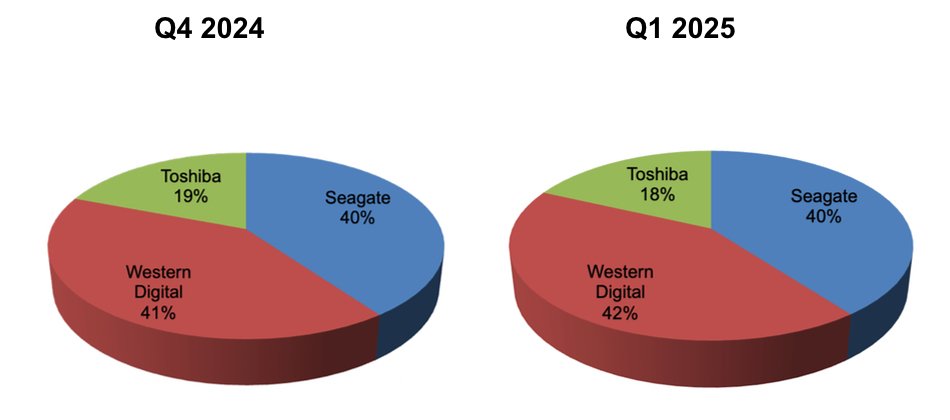
Leader Western Digital gained a point of market share from Toshiba in the first 2025 quarter as disk drive units and exabytes shipped both dipped relative to the final 2024 quarter.
There were 29.7 million drive shipped in the first 2025 quarter, about 9.5 percent down on the prior quarter’s 31.7 million, with mass-capacity nearline drive ships reducing 12 percent. The exabytes shipped total of 361.4 EB was down 4.4 percent over the same period. Total HDD supplier revenues were down around 8.4 percent quarter-on-quarter (Q/Q) to $5.242 billion.
Western Digital delivered 12.1 million drives and 179.8EB with $2.294 billion revenues and 42 percent market share by units.
Seagate shipped 11.4 million drives and 143.6 EB earning $2.003 billion with a 40 percent market share.
Toshiba shipped 5.2 million drives and 41 EB with an 18 percent market share and $945 million in revenues.
The drive format unit ship categories fared differently in a quarter-on-quarter (Q/Q) basis:
Notebook: up 1.4 percent
Desktop: up 1.4 percent
Consumer Electronics: down 10.4 percent
Branded: down 11.3 percent
High-performance enterprise: down 15.2 percent
Nearline enterprise: down 11.3 percent
Overall 3.5-inch drive unit shipped went down 8.7 percent to 22.7 million while 2.5-inch units dipped 12.9 percent to 6 million. This all reflects the increasing industry concentration on building 3.5-inch nearline drives.
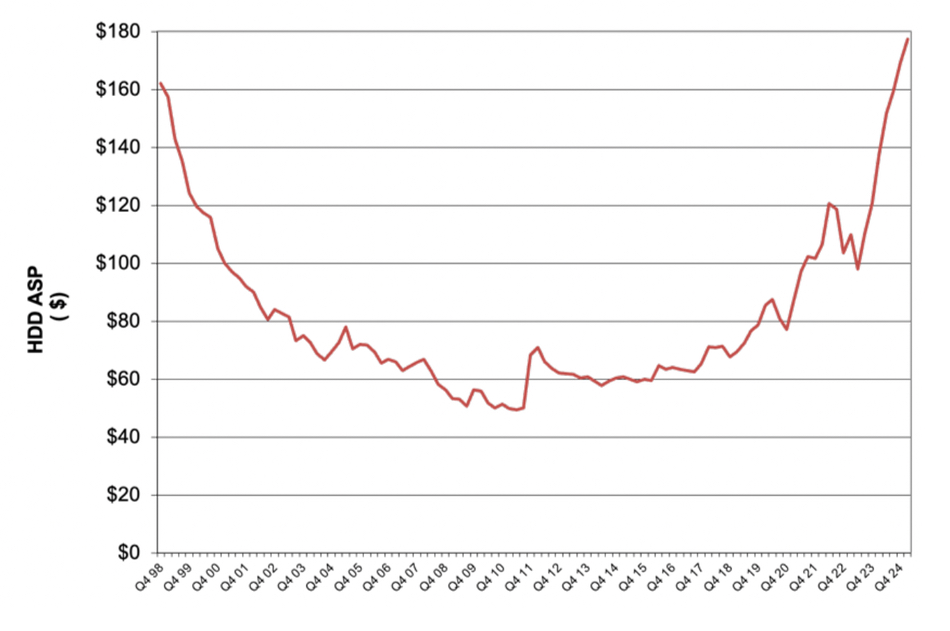
Coughlin says there was a a 4.9 percent average sales price (ASP) increase Q/Q in Q1 2025 and presented a ASP history chart, based on Seagate and WD ASPs, showing a near-symmetrical bathtub curve:
He notes: “HDD ASPs are now at levels higher than seen at the end of 1998 due to the increased demand for high capacity, high ASP, HDDs and the increase in the percentage of these drives shipped.”
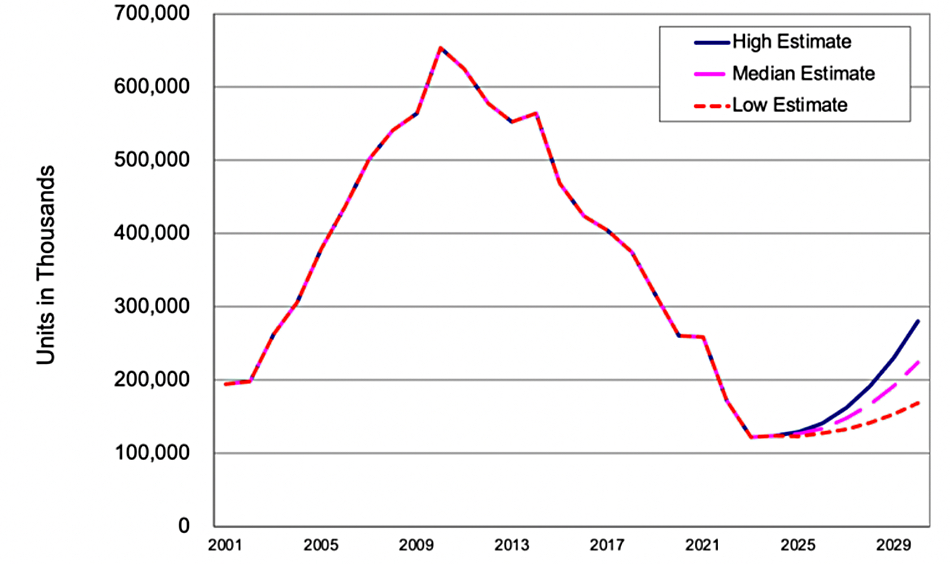
The report includes a chart showing high, media and low estimates for HDD unit ships out to 2030, with all three rising:
He reckons disk drive areal density has been increasing at 20 percent annually since the year 2000, with a 40-40 percent CAGR from 2000 to around 2010, and then a flattening off to something like 10 percent CAGR from then to 2024.
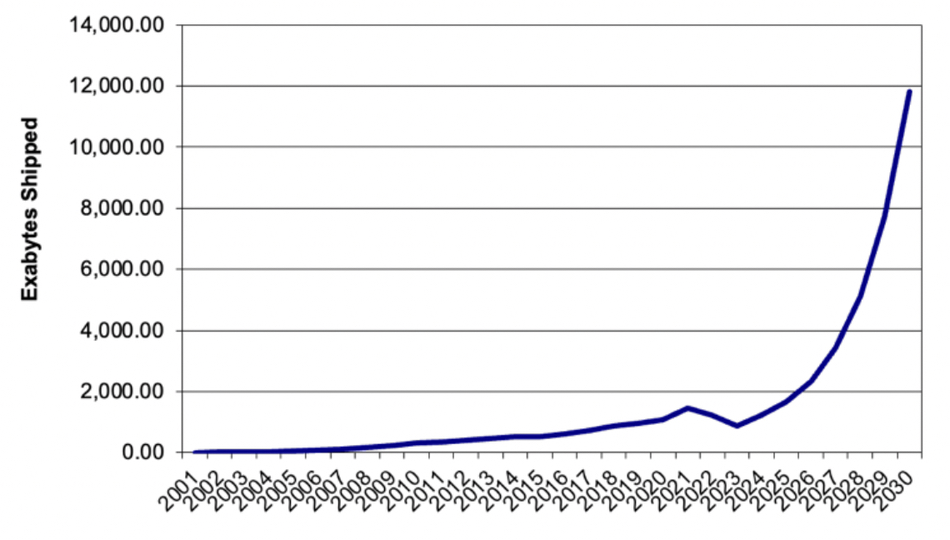
Coughlin’s report has a disk drive annual exabytes shipped projection chart showing a steep rise from 2024 to 2030:
We don’t know if this is based on the high, medium or low HDD unit ship projections and have asked. Tom Coughlin replied: “Yes, these two [charts] are tied together. The capacity shipment projection reflects my projections for average storage capacity of the HDDs and the median shipment projection.”
Altogether, beyond the ongoing steady attrition of notebook, PC and high-performance disk drives by SSDs, there is no sign of SSDs replacing nearline, mass-capacity HDDs in any significant way at all.
Open source ETL connector biz Airbyte announced progress in the first quarter with revenues up 25 percent, industry recognition, new product features, and Hackathon results. Michel Tricot, co-founder and CEO, Airbyte, said: “This year is off to a great start on every level – customer acceptance and revenue growth, industry recognition, and product development as we continue to evolve our platform to offer the very best technology to our users. There is much more to do and we’re working hard on the next wave of technology that includes the ability to move data across on-premises, cloud, and multiple regions which is all managed under one control plane.” With over 900 contributors and a community of more than 230,000 members, Airbyte supports the largest data engineering community and is the industry’s only open data movement platform.
…
The UK’s Archive360 says it has released the first modern archive platform that provides governed data for AI and analytics. It’s a secure, scalable data platform that ingests data from all enterprise applications, modern communications, and legacy ERP into a data-agnostic, compliant active archive that feeds AI and analytics. It is deployed as a cloud-native, class-based architecture. It provides each customer with a dedicated SaaS environment to enable them to completely segregate data and retain administrative access, entitlements, and the ability to integrate into their security protocols.
Support for enterprise databases including SAP, Oracle, and SQL Server enables streamlined ingestion and governance of structured data alongside unstructured content to provide a unified view across the organization’s data landscape. There are built-in connectors to leading analytics and AI platforms such as Snowflake, Power BI, and OpenAI. Find out more here.
…
Box CEO Aaron Levie posted an X tweet: “Box announced … new capabilities to support AI Agents that can do Deep Research, Search, and enhanced Data Extraction on your enterprise content, securely, in Box. And all with a focus on openness and interoperability. Imagine being able to have AI Agents that can comb through any amount of your unstructured data – contracts, research documents, marketing assets, film scripts, financial documents, invoices, and more – to produce insights or automate work. Box AI Agents will enable enterprises to automate a due diligence process on hundreds or thousands of documents in an M&A transaction, correlate customer trends amongst customer surveys and product research data, or analyze life sciences and medical research documents to generate reports on new drug discovery and development.”
“AI Agents from Box could work across an enterprise’s entire AI stack, like Salesforce Agentforce, Google Agentspace, ServiceNow AI Agent Fabric, IBM watsonx, Microsoft Copilot, or eventually ChatGPT, Grok, Perplexity, Claude, and any other product that leverages MCP or the A2A protocol. So instead of moving your data around between each platform, you can just work where you want and have the agents coordinate together in the background to get the data you need. This is the future of software in an era of AI. These new Box AI Agent capabilities will be rolling out in the coming weeks and months to select design partner customers, and then expand to be generally available from there.”
…
Datalaker Databricks intends to acquire serverless Postgres business Neon to strengthen Databricks’ ability to serve agentic and AI-native app developers. Recent internal telemetry showed that over 80 percent of the databases provisioned on Neon were created automatically by AI agents rather than by humans. Ali Ghodsi, Co-Founder and CEO at Databricks, said: “By bringing Neon into Databricks, we’re giving developers a serverless Postgres that can keep up with agentic speed, pay-as-you-go economics and the openness of the Postgres community.”
Databricks says the integration of Neon’s serverless Postgres architecture with its Data Intelligence Platform will help developers and enterprise teams build and deploy AI agent systems. This approach will prevent performance bottlenecks from thousands of concurrent agents and simplify infrastructure while reducing costs. Databricks will continue developing Neon’s database and developer experience. Neon’s team is expected to join Databricks after the transaction closes.
Neon was founded in 2021 and has raised $130 million in seed and VC funding with Databricks investing in its 2023 B-round. The purchase price is thought to be $1 billion. Databricks itself, which has now acquired 13 other businesses, has raised more than $19 billion; there was a $10 billion J-round last year and $5 billion debt financing earlier this year.
…
Databricks is launching Data Intelligence for Marketing, a unified data and AI foundation already used by global brands like PetSmart, HP, and Skechers to run hyper-personalized campaigns. The platform gives marketers self-serve access to real-time insights (no engineers required) and sits beneath the rest of the martech stack to unlock the value of tools like Adobe, Salesforce and Braze. Early results include a 324 percent jump in CTRs and 28 percent boost in return on ad spend at Skechers, and over four billion personalized emails powered annually for PetSmart. Databricks aims to become the underlying data layer for modern marketing and bring AI closer to the people who actually run campaigns.
…
Data integration supplier Fivetran released its 2025 AI & Data Readiness Research Report. It says AI plans look good on paper but fail in practice, AI delays are draining revenue, and centralization lays the foundation, but it can’t solve the pipeline problem on its own – data readiness is what unlocks AI’s full potential. Get the report here.
…
Monica Ohara
Fivetran announced Monica Ohara as its new Chief Marketing Officer. Ohara brings a wealth of expertise, having served as VP of Global Marketing at Shopify and led rider and driver hyper-growth through the Lyft IPO.
…
In-memory computing supplier GridGain released its GridGain Platform 9.1 software with enhanced support for real-time hybrid analytical and transactional processing. The software combines enhanced column-based processing (OLAP) and row-based processing (OLTP) in a unified architecture. It says v9.1 is able to execute analytical workloads simultaneously with ultra-low latency transactional processing, as well as feature extraction and the generation of vector embeddings from transactions, to optimize AI and retrieval-augmented generation (RAG) applications in real time. v9.1 has scalable full ACID compliance plus configurable strict consistency. The platform serves as a feature or vector store, enabling real-time feature extraction or vector embedding generation from streaming or transactional data. It can act as a predictions cache, serving pre-computed predictions or running predictive models on demand, and integrates with open source tools and libraries, such as LangChain and Langflow, as well as commonly used language models. Read more in a blog.
…
A company called iManage provides cloud-enabled document and email management for professionals in legal, accounting, and financial services. It has announced the early access availability of HYCU R-Cloud for iManage Cloud, an enterprise-grade backup and recovery solution purpose-built for iManage Cloud customers. It allows customers to maintain secure, off-site backups of their iManage Cloud data in customer-owned and managed storage, supporting internal policies and regional requirements for data handling and disaster recovery, and is available on the HYCU marketplace. Interested organizations should contact their iManage rep to learn more or apply for participation in the Early Access Program.
…
We have been alerted to a 39-slide IBM Storage Ceph Object presentation describing the software and discussing new features in v8. Download it here.
…
IBM Storage Scale now has a native REST API for its remote and secure admin. You can manage the Storage Scale cluster through a new daemon that runs on each node. This feature replaces the administrative operations that were previously done with mm-commands. It also eliminates several limitations of the mm-command design, including the dependency on SSH, the requirement for privileged users, and the need to issue commands locally on the node where IBM Storage Scale runs. The native REST API includes RBAC, allowing the security administrator to grant granular permissions for a user. Find out more here.
…
Data integration and management supplier Informatica announced expanded partnerships with Salesforce, Nvidia, Oracle, Microsoft, AWS, and Databricks at Informatica World:
Microsoft: New strategic agreement continuing innovation and customer adoption on the Microsoft Azure cloud platform, and deeper product integrations.
AWS:Informatica achieved AWS GenAI Competency, along with new product capabilities including AI agents with Amazon Bedrock, SQL ELT for Amazon Redshift and new connector for Amazon SageMaker Lakehouse.
Oracle: Informatica’s MDM SaaS solution will be available on OracleCloud Infrastructure, enabling customers to use Informatica MDM natively in the OCI environment.
Databricks:Expanded partnership to help customers migrate to its AI-powered cloud data management platform to provide a complete data foundation for future analytics and AI workloads.
Salesforce:Salesforce will integrate its Agentforce Platform with Informatica’s Intelligent Data Management Cloud, including its CLAIRE MDM agent.
Nvidia: Integration of Informatica’s Intelligent Data Management Cloud platform with Nvidia AI Enterprise. Nvidia AI Enterprise will deliver a seamless pathway for building production-grade AI agents leveraging Nvidia’s extensive optimized and industry-specific inferencing model.
Informatica is building on its AI capabilities (CLAIRE GPT, CLAIRE Copilot), with its latest agentic offerings, CLAIRE Agents and AI Agent Engineering.
…
Kingston has announced its FURY Renegade G5, PCIe Gen 5×4, NVMe, M.2 2280 SSD with speeds up to 14.8/14.0 GBps sequential read/write bandwidth and 2.2 million random read and write IOPS for gaming and users needing high performance. It uses TLC 3D NAND. It has a Silicon Motion SM2508 controller based on 6nm lithography and low-power DDR4 DRAM cache. The drive is available in 1,024 GB, 2,048 GB and 4,096 GB capacities, backed by a limited five-year warranty and free technical support. The endurance is 1PB per TB of capacity.
…
Micron announced that its LPDDR5X memory and UFS 4.0 storage are used in Motorola’s latest flip phone, the Razr 60 Ultra, which features Moto AI “delivering unparalleled performance and efficiency.” Micron’s LPDDR5X memory, based on its 1-beta process, delivers speeds up to 9.6 Gbps, 10 percent faster than the previous generation. LPDDR5X offers 25 percent greater power savings to fuel AI-intensive applications and extend battery life – a key feature for the Motorola Razr 60 Ultra with over 36 hours of power. Micron UFS 4.0 storage provides plenty of storage for flagship smartphones to store the large data sets for AI applications directly on the device, instead of the cloud, enhancing privacy and security.
…
Data protector NAKIVO achieved a 14 percent year-on-year increase in overall revenue, grew its Managed Service Provider (MSP) partner network by 31 percent, and expanded its global customer base by 10 percent in its Q1 2025 period. NAKIVO’s Managed Service Provider Programme empowers MSPs, cloud providers, and hosting companies to offer services such as Backup as a Service (BaaS), Replication as a Service (RaaS), and Disaster Recovery as a Service (DRaaS). NAKIVO now supports over 16,000 active customers in 185 countries. The customer base grew 13 percent in the Asia-Pacific region, 10 percent in EMEA, and 8 percent in the Americas. New NAKIVO Backup & Replication deployment grew by 8 percent in Q1 2025 vs Q1 2024.
…
Dedicated Ootbi Veeam backup target appliance builder Object First announced a 167 percent year-over-year increase in bookings for Q1 2025. Its frenetic growth is slowing as it registered 294 percent in Q4 2024, 347 percent in Q3 2024, 600 percent in Q2 2024 and 822 percent in Q1 2024. In 2025’s Q1 there was year-over-year bookings growth of 92 percent in the U.S. and Canada, and 835 percent in EMEA, plus growth of 67 percent in transacting partners and 185 percent in transacting customers.
…
Europe’s OVHcloud was named the 2025 Global Service Provider of the Year at Nutanix‘s annual .NEXT conference in Washington, D.C. It was recognized for its all-in-one and scalable Nutanix on OVHcloud hyper-converged infrastructure (HCI), which helps companies launch and scale Nutanix Cloud Platform (NCP) software licenses on dedicated, Nutanix-qualified OVHcloud Hosted Private Cloud infrastructure.
…
Objective Analysis consultant Jim Handy has written about Phison’s aiDAPTIV+SSD hardware and software. He says Phison’s design uses specialized SSDs to reduce the amount of HBM DRAM required in an LLM training system. If a GPU is limited by its memory size, it can provide greatly improved performance if data from a terabyte SSD is effectively used to swap data into and out of the GPU’s HBM. Handy notes: “This is the basic principle behind any conventional processor’s virtual memory system as well as all of its caches, whether the blazing fast SRAM caches in the processor chip itself, or much slower SSD caches in front of an HDD. In all of these implementations, a slower large memory or storage device holds a large quantity of data that is automatically swapped into and out of a smaller, faster memory or storage device to achieve nearly the same performance as the system would get if the faster device were as large as the slower device.” Read his article here.
…
Private cloud supplier Platform9 has written an open letter to VMware customers offering itself as a target for switchers. It includes this text: “Broadcom assured everyone that they could continue to rely on their existing perpetual licenses. Broadcom’s message a year ago assured us all that ‘nothing about the transition to subscription pricing affects our customers’ ability to use their existing perpetual licenses.’ This past week, that promise was broken. Many of you have reported receiving cease-and-desist orders from Broadcom regarding your use of perpetual VMware licenses.” Read the letter here.
…
Storage array supplier StorONE announced the successful deployment of its ONE Enterprise Storage Platform at NCS Credit, the leading provider of notice, mechanic’s lien, UCC filing, and secured collection services in the US and Canada. StorONE is delivering performance, cost efficiency, and scalability to NCS to help them in securing the company’s receivables and reducing its risk. Its technology allowed NCS to efficiently manage workloads across 100 VMs, databases, and additional applications, with precise workload segregation and performance control.
…
Western Digital’s board has authorized a new $2 billion share repurchase program effective immediately.
…
Western Digital has moved its 26 TB Ultrastar DC H590 11-platter, 7,200 rpm, ePMR HDD technology, announced in October last year, into its Red Pro NAS and Purple Pro surveillance disk product lines. The Red Pro disk is designed for 24/7 multi-user environments, has an up to 272 MBps transfer speed, rated for up to 550 TB/year workloads and has a 2.5 million hours MTBF. The Purple Pro 26 TB drive is for 24×7 video recording, the same workload rating, and has AllFrameAI technology that supports up to 64 single-stream HD cameras or 32 AI streams for deep learning analytics. The 26 TB Red Pro and Purple Pro drives cost $569.99 (MSRP).
Kioxia has announced a prototype CM9 SSD using its latest 3D NAND with 3.4 million random read IOPS through its PCIe Gen 5 interface, faster than equivalent drives from competitors.
The CM9 is a dual-port drive that will come in 1 drive write per day (DWPD) read-intensive and 3 DWPD mixed-use variants in U.2 (2.5-inch) and E3.S formats. The capacities will be up to 30.72 TB in the E3.S case and 61.44 TB in the U.2 format with Kioxia using its BiCS8 218-layer NAND in TLC (3 bits/cell) form. It should deliver 3.4 million/800,000 random read/write IOPS with sequential read and write bandwidths of 14.8 GBps and 11 GBps respectively.
Neville Ichhaporia
Kioxia America SSD business unit VP and GM Neville Ichhaporia stated: “As AI models grow in complexity and scale, the need for storage solutions that can sustain high throughput and low latency, and allow for better thermal efficiency, becomes critical. With the addition of the CM9 Series, KIOXIA is enabling more efficient scaling of AI operations while helping to reduce power consumption and total cost of ownership across data center environments.”
The drive is built with CBA (CMOS directly Bonded to Array) technology, where CMOS refers to the chip’s logic layer. The CMOS and NAND array wafer components are fabbed separately and subsequently bonded together using copper pads. Kioxia says this technology can reduce chip area and improve performance.
Kioxia says the CM9 will provide performance improvements of up to approximately 65 percent in random write, 55 percent in random read, and 95 percent in sequential write compared to the previous generation. We understand this means the CM7 products as there is no CM8 in the lineup; we’ve asked Kioxia to confirm and the company said: “There was a CM8 Series planned a long time ago, and the SSD model nomenclature is tied to a specific generation of BiCS FLASH 3D memory, which we skipped intentionally, resulting with the CM8 Series SSD getting skipped. We skipped a flash generation to catapult directly to a far superior BiCS FLASH generation 8 technology utilizing CBA architecture (CMOS directly Bonded to Array – enabling for better power, performance, cost, etc.), which is used in the CM9 Series.”
The company says the CM9 also has performance-per-watt gains of 55 percent better sequential read and 75 percent better sequential write efficiency than the CM7.
The dual-port CM7 used BiCS5 generation 112-layer NAND and a PCIe Gen 5 interface. It provided 2,700,000/310,000 random read/write IOPS with up to 14 GBps sequential read and 6.75 GBps sequential write bandwidth
Kioxia also has slower CD8 and CD8P single-port datacenter drives built with BiCS5 generation 112-layer flash.
Competing drives in the same U.2/E3.S format segment don’t match the CM9’s 3.4 million random read IOPS number. Micron’s 9550 Pro reaches 3.3 million. The FADU Echo achieves 3.2 million. The PS1010 from SK hynix has a 3.1 million number as does Solidigm’s D7-PS1010 and PS1030. Phison’s Pascari is rated at 3 million.
It’s possible that Kioxia could build a U.2 format SSD using a QLC (4 bits/cell) version of its BiCs8 NAND, and achieve a 124 TB capacity level. It’s built 2 Tbit chips this way and is shipping them to Pure Storage for use in its DirectFlash Modules.
Kioxia’s NAND fab joint venture partner Sandisk just announced its WD_BLACK SN8100 drive built with the same BiCS8 flash and also using the PCIe Gen 5 interface. It’s a slower drive, outputting 2.3 million random read IOPS, with much lower capacities of 2, 4, and 8 TB. The partners are aiming at different markets.
The CM9 Series SSDs are sampling to select customers and will be showcased at Dell Technologies World, May 19-22, in Las Vegas.
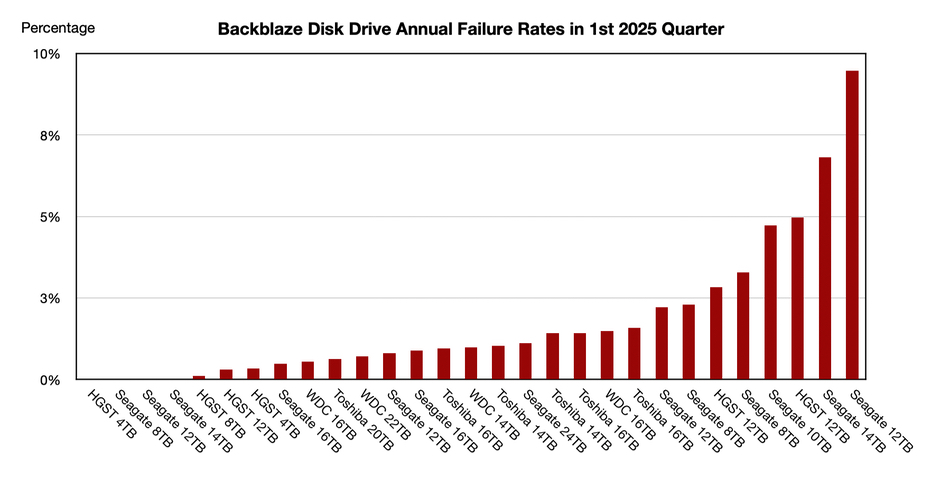
The cloud storage company was tracking 317,833 drives across models that had more than 100 drives in operation as of March 31, and that collectively logged over 10,000 drive-days during the quarter. The supplier/model AFRs were:
We sorted this table by ascending AFR and then graphed it on that basis:
Seagate has three of the top four AFR spots.
Backblaze noted that the four higher-end outlier AFRs, which contributed to the rise in overall AFR from the previous quarter, were:
Four drive models had zero failures in the quarter: the 4 TB HGST (model HMS5C4040ALE640), the Seagate 8 TB (model ST8000NM000A), the Seagate 12 TB (model ST12000NM000J), the and Seagate 14TB (model ST14000NM000J).
Overall, Backblaze’s “4 TB drives showed wonderfully low failure rates, with yet another quarter of zero failures from (HGST) model HMS5C4040ALE640 and 0.34 percent AFR from model (HGST) HMS5C4040BLE640.”
It also tracks lifetime AFRs and the only drive with a more than 2.85 percent AFR is Seagate’s 14 TB (ST14000NM0138) at 5.97 percent for 1,322 drives. But a second 14 TB Seagate drive model, the ST14000NM001G, with 33,817 drives in operation, has a much lower 1.42 percent AFR – problem sorted.
Backblaze has ported its drive AFR stats to Snowflake. Previously it was running SQL queries against CSV data imported into a MySQL instance running on a laptop. The team notes: “The migration to Snowflake saved us a ton of time and manual data cleanup … Gone are the days of us bugging folks for exports that take hours to process! We can run lightweight queries against a cached, structured table.”
The company says that “the complete dataset used to create the tables and charts in this report is available on our Hard Drive Test Data page. You can download and use this data for free for your own purpose,” with the following provisos: “1) cite Backblaze as the source if you use the data, 2) you accept that you are solely responsible for how you use the data, and 3) you do not sell this data itself to anyone; it is free.”
Western Digital is supplying NVMe PCIe-to-Ethernet RapidFlex bridge technology to Ingrasys, which will manufacture a fast, Ethernet-accessed box of SSDs for edge location use, cloud providers, and hyperscalers.
Taiwan-headquartered Ingrasys is a Foxconn subsidiary designing and manufacturing servers, storage systems, AI accelerators, and cooling systems for hyperscalers and datacenters. Western Digital is a disk-drive manufacturing business that has split off its NAND/SSD operation as Sandisk. The Ingrasys Top of Rack (TOR) Ethernet Bunch of Flash (EBOF) will, the two say, “provide distributed storage at the network edge for lower latency storage access, reducing the need for separate storage networks and avoiding trips to centralized storage arrays.”
Kurt Chan
Kurt Chan, VP and GM of Western Digital’s Platforms Business, stated: “Together with Ingrasys, we continue to accelerate the shift toward disaggregated infrastructure by co-developing cutting-edge, fabric-attached solutions designed for the data demands of AI and modern workloads. This collaboration brings together two leaders in storage infrastructure modernization to deliver flexible, scalable architectures that unlock new levels of efficiency and performance for our customers.”
Why is Western Digital involved with an SSD-filled storage chassis in the first place? This goes back to 2019, when Western Digital, then making both disks and SSDs, acquired Kazan Networks NVMe-oF Ethernet technology. It developed RDMA-enabled RapidFlex controller/network interface cards from this. A RapidFlex C2000 Fabric Bridge, with its A2000 ASIC, functioned as a PCIe adapter, exporting the PCIe bus over Ethernet, with 2 x 100 GbitE ports linked to 16 PCIe Gen 4 lanes. The C2000 could function in both initiator and target mode. The latest RapidFlex C2110 is a SFF-TA-1008 to SFF-8639 Interposer designed to fit the Ingrasys ES2000 and ES2100 EBOF chassis.
RapidFlex C2110
In 2023, Western Digital had an OpenFlex Ethernet NVMe-oF access Just a Bunch of Flash (JBOF), a 2RU x 24-bay disaggregated chassis, the Data24 3200 enclosure, integrating dual-port NVMe SSDs with its RapidFlex fabric bridge supporting both RoCE and NVMe/TCP. This Data24 3200 chassis could connect to up to six server hosts directly, eliminating the necessity for a switch device. A year later, Western Digital showed that it could deliver read and write I/O across an Nvidia GPUDirect link faster than NetApp’s ONTAP or BeeGFS arrays.
The OpenFlex system was envisaged as a way to sell Western Digital’s own SSDs packaged in the JBOF. Since then, the NAND+SSD operation has been split off, becoming Sandisk, and Western Digital is a disk drive-only manufacturing business, with disk drives providing some 95 percent of its latest quarterly revenues. By any measure, this RapidFlex/OpenFlex operation is now a peripheral business. It’s interesting that the Sandisk operation did not get the RapidFlex bridge technology, which is well suited for NVMe JBOF access. Perhaps Western Digital has NVMe-accessed disk drives in its future.
Western Digital claims that its RapidFlex device is the “only NVMe-oF bridge device that is based on extensive levels of hardware acceleration and removes firmware from the performance path. The I/O read and write payload flows through the adapter with minimal latency and direct Ethernet connectivity.” For Ingrasys, “this facilitates seamless, high-performance integration of NVMe SSDs into disaggregated architectures, allowing for efficient scaling of storage resources independently from compute.”
Data24 chassis
Ingrasys president Benjamin Ting said: “By combining our expertise in scalable system integration with Western Digital’s leadership in storage technologies, we’re building a foundation for future-ready, fabric-attached solutions that will meet the evolving demands of AI and disaggregated infrastructure. This partnership is just the beginning of what we believe will be a lasting journey of co-innovation.”
The Ingrasys TOR EBOF is targeted for 2027 availability. That’s quite a time to wait for revenue to come in.