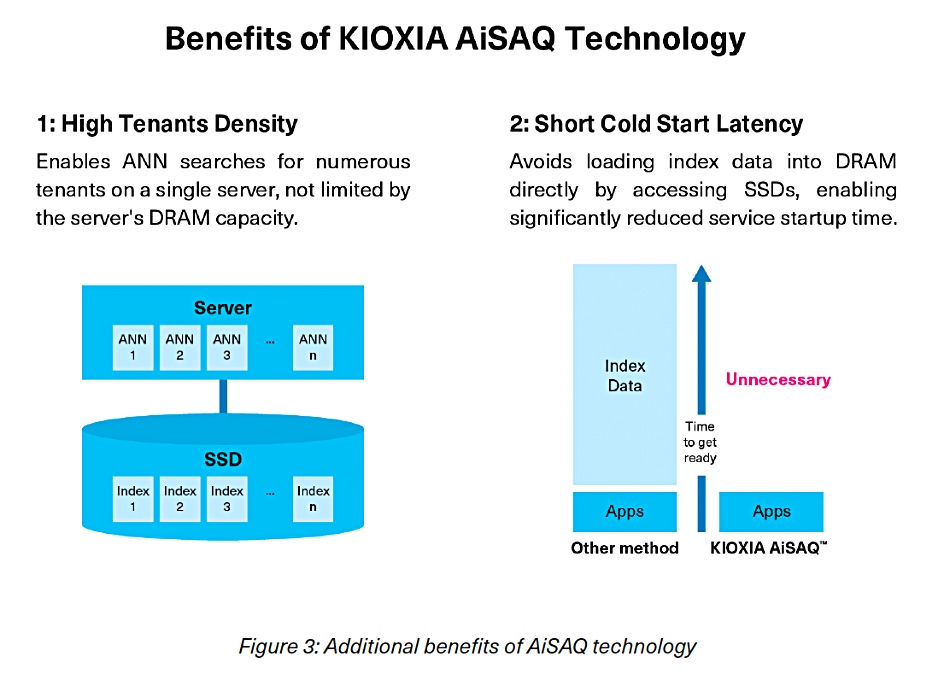
Graid occupies a technology niche with its Nvidia GPU-powered RAID cards and is powering ahead with a development roadmap featuring AI and high-performance computing (HPC) products.
The company, which says it now has thousands of customers worldwide, has three SupremeRAID products: The SR-1010 enterprise performance card, the SR-1000 enterprise mainstream card, and the SR-1010 workstation and edge card. Graid claims it doubled its revenue in 2024, when it shipped around 5,000 cards, compared to 2023, and it thinks it may grow 60 percent over 2024 this year, with expanded OEM and reseller engagements, possibly to a $15 million revenue total and 7,000 or so cards sold.
Graid says the SupremeRAID products protect data against drive loss and remove bottlenecks from the storage IO path. They don’t, in themselves, accelerate anything. Its SupremeRAID roadmap, as presented to an IT Press Tour in Silicon Valley, has five components:
- SE (Simple Edition) beta for desktops
- AE (AI Edition )for GPU servers and AI workloads
- SR-1000 AM (Ampere) with NVMe RAID on Nividia RTX A1000 GPU
- S1001 AM with NVMe RAID on Nividia RTX A1400 GPU
- HE (HPC Edition) and NVMe RAID with array migration for cross-node high availability (HA).

SupremeRAID SE is its first entry into the Bring-Your-Own-GPU market. It will provide enterprise-grade RAID protection and performance for PC/workstation users with a subscription scheme and be available this year. It will support up to 8 NVMe SSDs and use compatible GPUs in the PC. Suggested workloads include video editing, post-production, 3D rendering, animation, visual SFX for games, CAD, architecture, engineering and construction (AEC) apps.
The AE version for AI supports GPUDirect for direct NVMe-to-GPU memory transfers, and data offload to NVMe SSDs. It, Graid says, “integrates seamlessly with BeeGFS, Lustre, and Ceph, simplifying large-scale dataset management without data migration.” It achieves over 95 percent of raw NVMe drive performance with RAID protection.

Thomas Paquette, Graid’s SVP and GM Americas & EMEA, said: “We don’t have the failover built into this release. It will be built into the next release. So that’ll give you the opportunity to put two copies of the software, each one on a different GPU, and have one failover for your read.”
Graid says a fully enabled Nvidia H100 accelerator has 144 SMs (Streaming Microprocessors) or Multiprocessors), roughly equivalent to an x86 core, which manage multiple threads and cores for parallel processing. SupremeRAID-AE uses 6 x SMs on one GPU and doesn’t affect the others. It’s implemented with Time Division Multiplexing (TDM). Paquette said AE could use fewer SMs: “In low IO, we can go to sleep and give the GPU even more, and we implemented this with TDM.”
He added a comment: ”This was the best way for us to deploy and it’s it works quite well. It’s in the labs at Supermicro. They’re skewing it up right now. We’re testing it with Dell, and it’s going in the labs in Lenovo on a product project that Jason [Huang] is going to be working on.”
Paquette envisages Graid becoming a SW-only company, just selling licenses.

The Nvidia RTX A1000 and A400 single slot desktop GPUs were launched in April last year and feature an Ampere architecture. The The A400 introduced accelerated ray tracing, with 24 Tensor Cores for AI processing and four display outputs. The A1009 has 72 Tensor and 18 RT cores and is more powerful.
The SR-1000 AM combines SR-1000 and SR-1010 functionalities and performance.The SR-1001 AM follows on from the SR-1001 with equal performance and enhanced efficiency.
These AM products will have a new Graid software release, v1.7, which features a new GUI, Restful API, journalling for data integrity, bad block detection and improved error retry mechanism.
SupremeRAID HE is optimized for the BeeGFS, Ceph and Lustre environments found in the HPC world. it eliminates data replication across nodes and supports array migration. Graid and Supermicro have produced a Solution Brief document about a BeeGFS SupremeRAID HE system, which uses SupremeRAID HE with a SupremeRAID SR-1010 in each node.

The document says: “SupremeRAID HE, integrated with Supermicro’s SSG-221E-DN2R24R and BeeGFS, redefines NVMe storage standards. Leveraging array migration for cross-node high availability (HA), it delivers peak performance in a 2U system with two 24-core CPUs, saturating two 400Gb/s networks. By eliminating cross-node replication, it reduces NVMe costs and offers scalable adaptability. Achieving 132 GB/s read and 83 GB/s write locally – near theoretical limits post-RAID – and up to 93 GB/s read and 84 GB/s write from clients, this solution is excellent for your high performance storage needs, including HPC, analytics, and enterprise applications and is validated by rigorous benchmarks.”
Paquette said: “Supermicro calls this potentially a WEKA killer, and we’d have to scale pretty good to be a WEKA killer, but there’s nothing stopping us from doing that.”
Graid said the next software release will increase the number of supported drives beyond 32, potentially to 64, and there will be new Linux and Windows software releases later this year.
The company will also support new PCIe generations, with Paquette saying: “Each time PCIe changes three to four, four to five, … five to six, we automatically gain an exponential performance without doing anything to the product. Because the only bottleneck that we experience in a server today is the PCIe infrastructure. We can saturate it. So when six comes, we’ll saturate that as well.”
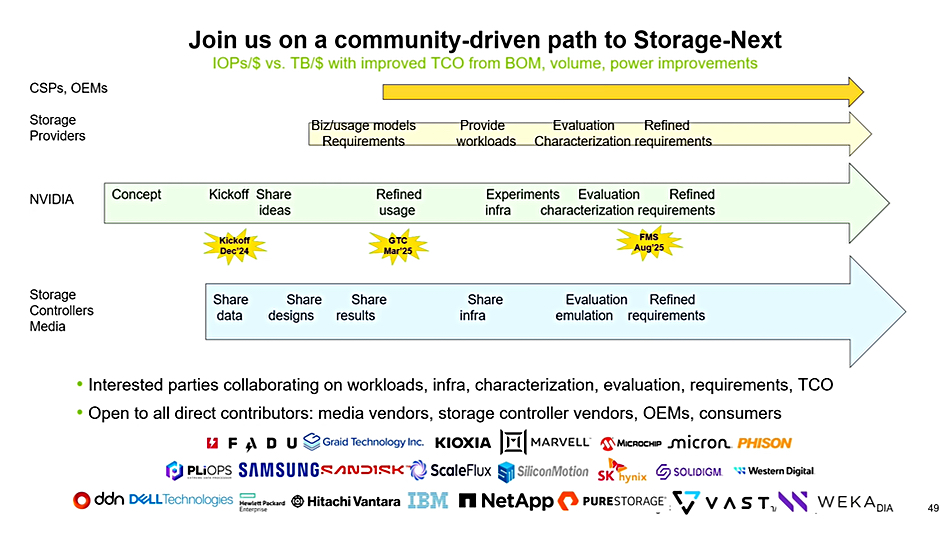
Erasure coding is on its roadmap but there is no committed date. We also understand the existing Dell and Graid partnership could be developing further. Graid is also a participant in an Nvidia Storage-Next initiative.
Could Graid support non-Nvidia GPUs? Paquette said: “We know that we could get it to work on an Intel GPU. We know that we can get it to work on an AMD GPU, but it’s a ground up rewrite, and we’ve got too much other stuff going on to play with.”
Find out more about SupremeRAID SE here and AE here.