


Rubrik has announced its Annapurna offering, a single API service for customers building GenAI applications, which will integrate with Amazon Bedrock and give its large language models access to Rubrik-captured data with access controls.
Data protector and cyber resiliency supplier Rubrik captures and secures copies of customer data through its backup technology, working on-premises and in the public clouds to protect an enterprise’s application and SaaS data. It has access to huge amounts of its customers’ data stored in its RSC (Rubrik Security Cloud). This is a source for retrieval-augmented generation (RAG), the addition of private customer data to LLMs that have been trained on generic data. RAG augments the generic training data with proprietary information.

Bipul Sinha, Rubrik CEO, chairman, and co-founder, stated: “Organizations are faced with significant complexity when developing AI applications due to challenges around data access and sensitive data permissions. This could lead to applications that lack relevant knowledge or don’t adhere to access controls.”
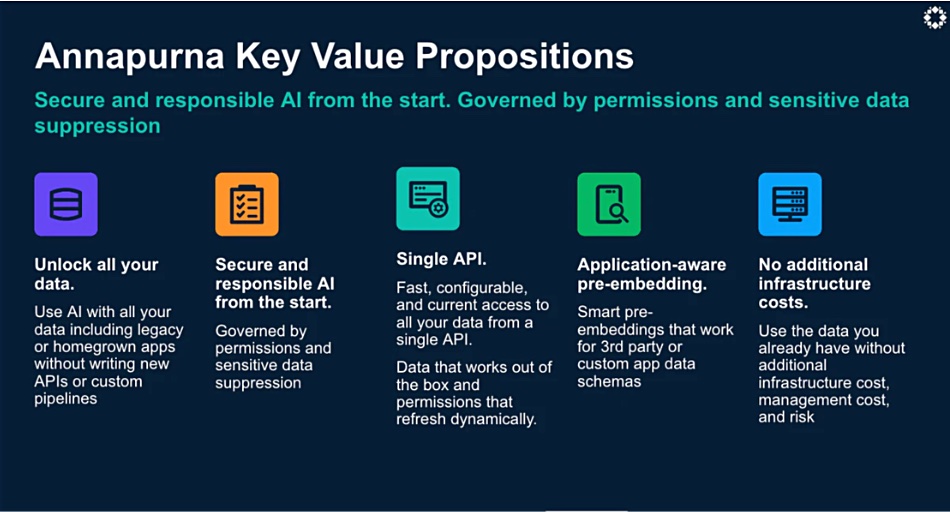
He asserts: “Rubrik Annapurna helps to unlock Rubrik Security Cloud’s enterprise data and metadata. Combined with Amazon Bedrock, which offers a vast collection of proven foundation models and enterprise-grade capabilities, we can deliver to customers powerful and secure pre-embeddings that turbocharge generative AI initiatives.”
Note the “pre-embeddings” item. This refers to the fact that LLMs use semantic search, which looks for similarities among stored vectors, in making their responses. Vectors are mathematical transformations of multiple aspects or dimensions of a search item. These are used to generate a user request response. The search items can be parts of a sentence, phrase or word, audio recording, image or video. Such data is stored in a raw format: document file, spreadsheet, mail, JPEG, MPEG, etc. and, in the case of Rubrik, a backup file with metadata.

Before this can be used by an LLM, it has to be extracted from its source store, transformed into vectors, and then loaded into a vector database; a classic ETL (Extract, Transform, and Load) procedure of the type used by data warehouses. Annapurna is Rubrik’s ETL for making its data available to LLMs for RAG and it embodies Rubrik’s security concerns to ensure the LLM, available in Amazon’s Bedrock in this case, only gets access to carefully curated data suitable to its status.
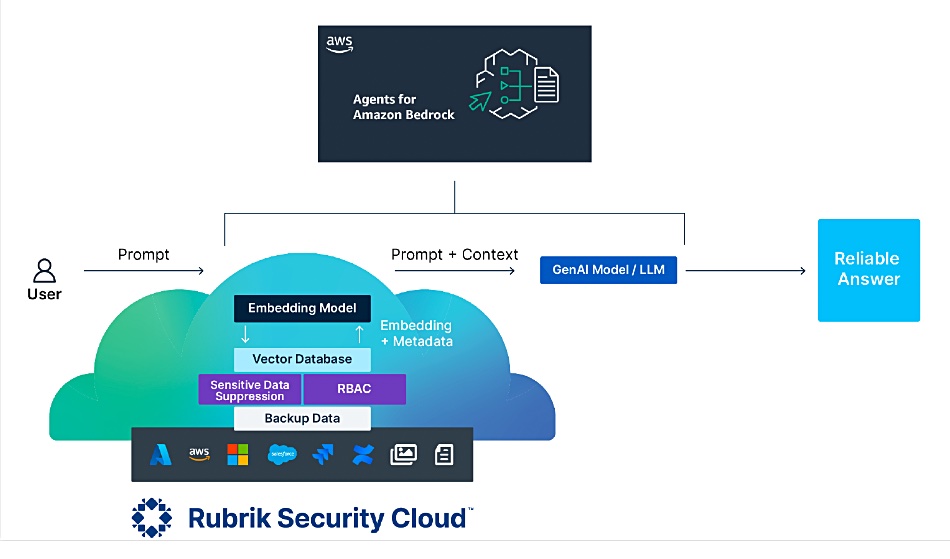
A customer’s GenAI application will make API calls to the Rubrik Security Cloud for data supply and separate API calls to Bedrock to activate an LLM there and can thus respond to user requests. Annapurna can dynamically update access as data refreshes, permissions change, and sensitive data is introduced. The safeguards include sensitive data suppression and filtering, Source Role-Based Access Control (SRBAC), and Amazon Bedrock’s guardrails.
Annapurna with Bedrock should enable customer GenAI apps to access and configure enterprise data and metadata across SaaS, legacy, and homegrown applications like CRMs, billing, and knowledge management systems. These can be connected “without custom APIs, cumbersome extract transfer load processes (ETLs), or custom data pipelines.” There is “one flexible and configurable datastore designed to be used across all of an organization’s AI applications.”
Chris Sullivan, VP Americas Channels & Alliances at AWS, said: “Rubrik’s integration of Amazon Bedrock with its Annapurna API service helps customers better leverage all their data – regardless of where it resides – to drive customized, secure generative AI applications.”
Rubrik-provided examples of such secure GenAI apps are a more intelligent customer support expert for every rep, a smarter sales assistant for every sales team, and a more creative marketing assistant. The sales assistant agent could connect “multiple disjointed applications such as Salesforce CRM, emails, Teams chat, and even Zoom recordings sitting in Amazon Simple Storage Service (Amazon S3) buckets. Sales teams can rapidly get a 360° summary and qualitative review of customer deals with organizational context from customer emails, phone conversations, and the relevant internal communications across the team.”
The principles are clear but it will take time to implement these capabilities. That is because the vector embedding of Rubrik-held data isn’t available yet.
The company says: “Annapurna is designed to provide secure embeddings of enterprise data and metadata via its single API. These embeddings recognize common application schemas and are customizable to help accelerate the development of data retrieval for retrieval-augmented generation (RAG).”
A December 3 Rubrik blog says: “Rubrik Annapurna for Amazon Bedrock will be designed to empower enterprises with a secure, scalable, and compliant foundation for generative AI.” Will be designed, meaning it’s not available yet. There is also a Rubrik Annapurna tech blog that points you to an Annapurna tech white paper.
This says Annapurna provides “pre-embeddings on data in RSC pre-trained by application type (e.g., CRM, Billing, etc.)” There are no details on what exactly is meant by a pre-embedding. The tech paper says Annapurna “will be designed to proactively secure the data pipeline for Amazon Bedrock by leveraging data already managed by Rubrik.” Annapurna will feature automated secure data retrievers which can be used by a Bedrock LLM. They utilize existing datasets in a Rubrik Secure Vault. Programmatic access is provided to Bedrock to integrate the Rubrik-stored enterprise data sources in the AI architecture, which can then be used for RAG.
Rubrik, the paper says, can use “backup data present in the Rubrik Security Cloud, embed this data in a vector database, and have it serve as the augmentation to the user prompt.”
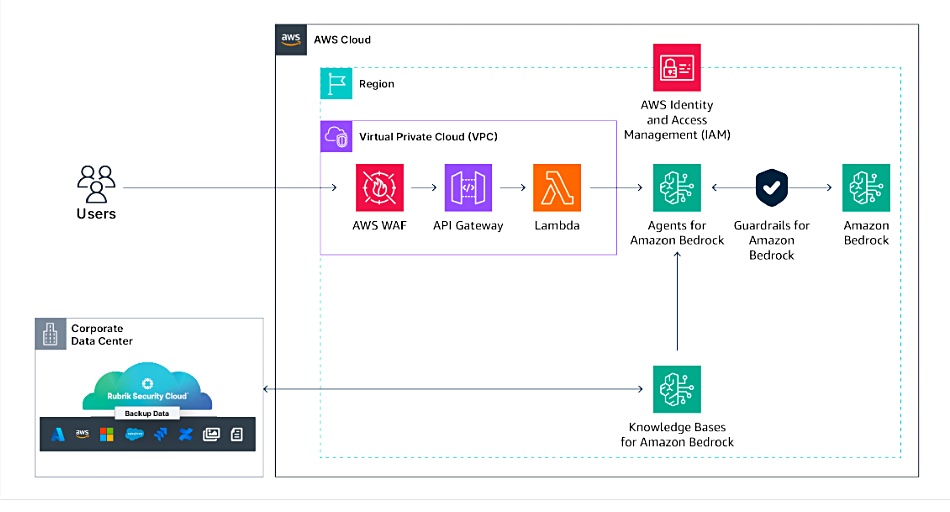
Rubrik has not yet explained how the vector embeddings of RSC-held data will be generated from its pre-embeddings nor where the vector database comes from. It might, for example, use Pinecone or Weaviate, which have vector embeddings services. These points will become clear as Annapurna capabilities are delivered next year. Annapurna will be extended to support Bedrock-equivalent functionality on Azure and Google Cloud.
Rubrik, like rival Cohesity with its Gaia, now has a solid GenAI concept and strategy for its customers. We would expect their main rivals, Veeam, Dell, and Commvault, to develop similar RAG data pipeline capabilities.





