In what appears to be a tangible sign of its commitment to its acquired Veritas data protection product portfolio, Cohesity has issued a v11.0 major release of NetBackup.
It features extended encryption to defend against quantum attacks, more user behavior monitoring, and an extended range of cloud services protection.
Vasu Murthy
Cohesity SVP and chief product officer Vasu Murthy stated: “This represents the most powerful NetBackup software release to date for defending against today’s sophisticated threats and preparing for those to come …The latest NetBackup features give customers smarter ways to minimize the impact of attacks now and post-quantum.”
NetBackup v11.0 adds quantum-proof encryption, claiming to guard against “harvest now, decrypt later” quantum computing attacks. Quantum-proof encryption is designed to resist attacks from quantum computers, which could potentially break current encryption methods. Encrypted data could, it is theorized, be copied now and stored for later decryption using a yet-to-be-developed quantum computer. Post-quantum cryptography uses, for example, symmetric cryptographic algorithms and hash functions that are thought to be resistant to such attacks. The US NIST agency is involved in these quantum-proof encryption efforts.
Cohesity claims that NetBackup v11.0 “protects long-term confidentiality across all major communication paths within NetBackup, from encrypted data in transit and server-side dedupe, to client-side dedupe, and more.”
v11.0 also includes a wider range of checks looking for unusual user actions, saying it’s a “unique capability” and “can stop or slow down an attack, even when threat actors compromise administrative credentials.”
It automatically provides recommended security setting values. An included Adaptive Risk Engine v2.0 monitors user activity, looking for oddities such as unusual policy updates and user sign-in patterns. Alerts and actions can then be triggered, with Cohesity saying “malicious configuration changes can be stopped by dynamically intercepting suspicious changes with multi-factor authentication.”
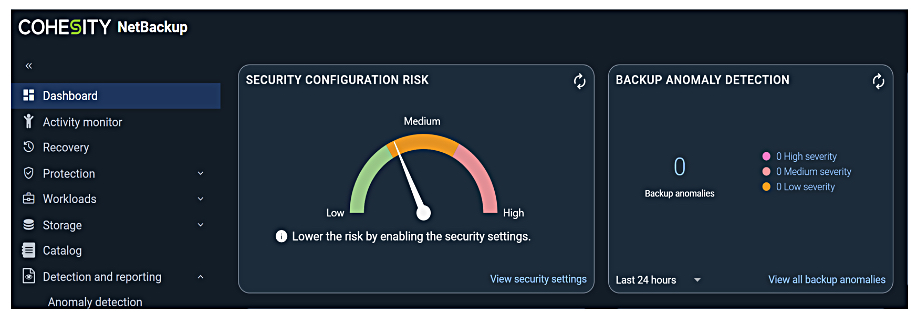
A Security Risk Meter provides a graphic representation of various risks across security settings, data protection, and host communication.
Security Risk Meter screenshot
NetBackup 11.0 has broadened Platform-as-a-Service (PaaS) protection to include Yugabyte, Amazon DocumentDB, Amazon Neptune, Amazon RDS Custom for SQL Server and Oracle Snapshots, Azure Cosmos DB (Cassandra and Table API), and Azure DevOps/GitHub/GitLab.
It also enables image replication and disaster recovery from cloud archive tiers like Amazon S3 Glacier and Azure Archive.
The nonprofit Sheltered Harbor subsidiary of the US FS-ISAC (Financial Services Information Sharing and Analysis Center) has endorsed NetBackup for meeting the most stringent cybersecurity requirements of US financial institutions and other organizations worldwide.
A Cohesity blog by VP of Product Management Tim Burowski provides more information. NetBackup v11.0 is now available globally.
Fresh from allying with Big Four accounting firm Deloitte, Rubrik has signed an agreement with Japanese IT services giant NTT DATA to push its cyber-resilience services.
NTT revenues for fiscal 2024 were $30 billion, with $18 billion of that generated outside Japan. Rubrik is much smaller with revenue of $886.5 million in its latest financial year, and its focus on enterprise data protection and cyber-resilience led to a 2024 IPO, and product deals with suppliers including Cisco, Mandiant, and Pure Storage. Rubrik and NTT DATA have been working together for some time and have now signed an alliance pertaining to security services.
Hidehiko Tanaka, Head of Technology and Innovation at NTT DATA, said: “We recognize the critical importance of cyber resiliency in today’s digital landscape. Our expanded partnership with Rubrik will significantly enhance our ability to provide robust security solutions to our clients worldwide.”
NTT will offer its customers Rubrik-influenced and powered advisory and consulting services, implementation and integration support, and managed services. Its customers will be able to prepare cybersecurity responses before, during, and after a cyber incident or ransomware attack affecting their on-premises, SaaS, and public cloud IT services. The NTT DATA partnership includes Rubrik’s ransomware protection services.
In effect, Rubrik is adding global IT services and accounting firms to its sales channel through these partnerships, giving it access to Fortune 2000 businesses and public sector organizations, potentially offering an advantage over competitors such as Commvault, Veeam, and Cohesity. Once it has won a new customer this way, Rubrik will no doubt put in its salesteam to work on cross-sell and upsell opportunities.
Ghazal Asif, VP, Global Channel and Alliances at Rubrik, said: “As a trusted and longstanding strategic partner, Rubrik is proud to expand our collaboration with NTT DATA for cyber resilience. Together, we will empower hundreds of organizations with differentiated offerings that ensure rapid recovery from ransomware attacks and other cyber threats, no matter where their data lives.”
NTT DATA has used Commvault internally in the past, as a 2018 case study illustrates, and NTT UK is a Veeam partner.
N2WS says its latest backup software provides cross-cloud backup across AWS, Azure, and Wasabi, which it claims lowers costs and enables direct backup cold tier storage for Azure Blob and Wasabi S3.
N2WS (Not 2 Worry Software) backup uses cloud-native, platform-independent, block-level snapshot technology with an aim to deliver high-speed read and write access across Azure, AWS, and third-party repositories like Wasabi S3. It charges on a per-VM basis and not on a VM’s size. N2WS says it provides vendor-neutral storage and, with its cloud-native snapshot technology, delivers control over cloud backups, designed to unlock “massive cost savings.” N2WS is a backup and recovery supplier that has not broadened into cyber-resilience.
Ohad Kritz
Ohad Kritz, CEO at N2WS, claimed in a statement: “We excel in protecting data – that’s our specialty and our core strength. While others may branch into endpoint security or threat intelligence, losing focus, we remain dedicated to ensuring our customers are shielded from the evolving IT threat landscape.”
N2WS claims Backup & Recovery v4.4 offers:
Lower long-term Azure storage costs with up to 80 percent savings through Azure Blob usage, and more predictable costs compared to Azure Backup, with new per-VM pricing ($5) and optimized tiering
Seamless cross-cloud automated archiving with low-cost S3-compatible Wasabi storage
Faster, more cost-effective disaster recovery via Direct API integrations with AWS and Azure with greater immutability
New custom tags improve disaster recovery efficiency, with better failover and failback
Targeted backup retries, which retry only failed resources to cut backup time and costs
The tiered Azure backup is similar to N2WS’s existing and API-linked AWS tiering. Azure VM backup pricing is based on VM and volume size. An N2WS example says that if you have 1.2 TB of data in one VM, the cost of using Azure Backup would be $30 plus storage consumed versus $5 plus storage consumed for the same VM using N2WS.
N2WS Azure customers can also select both cross-subscription and cross-region disaster recovery for better protection with offsite data storage, we’re told.
The cross-cloud backup and automated recovery provides isolated backup storage in a different cloud and sidesteps any vendor lock-in risks associated with, for example, Azure Backup.
N2WS uses backup tags to identify data sources and apply backup policies. For example, AWS EC2 instances, EBS volumes, and RedShift databases are identified with key-value pairs. N2WS scans the tags and applies the right backup policy to each tagged data source. If a tag changes, a different backup policy can be applied automatically.
It says its Enhanced Recovery Scenarios introduce custom tags, enabling the retention of backup tags and the addition of fixed tags, such as marking disaster recovery targets. This improvement enhances the differentiation between original and DR targets during failover. v4.4 has a Partial Retry function for policy execution failures, which retries backing up only the failed sources and not the successful ones.
N2WS Backup & Recovery v4.4 is now generally available. Check out N2WS’s cost-savings calculator here.
An EMEA-based GPU server cloud provider is using PEAK:AIO storage to hold customer data for its Blackwell GPU cluster.
Blackwell DGX B200
Startup PEAK:AIO is building scale-out AI Data Server storage based on highly efficient single-node building blocks, maximizing density, power efficiency, and performance. This delivers 120 GBps throughput from a 2RU, 1.5 PB Dell R765 server chassis filled with Solidigm 61.44 TB SSDs, using a PCIe Gen 5 bus.
Existing PEAK:AIO customer and Nvidia Elite Partner Scan Computers is using it to store data for its GPU-as-a-Service (GPUaaS) offering built on its DGX Blackwell B200 cluster – one of the first in EMEA – and representing a multimillion-pound investment in AI infrastructure.
PEAK:AIO founder and Chief Strategy Officer Mark Klarzynski tells us: “PEAK:AIO has been quietly perfecting ultra-efficient single-node AI storage … a concept that often flies under the radar because ‘single node’ doesn’t sound groundbreaking at first. But if you stop viewing it as just storage and start seeing it as a building block, the potential starts to become more visible.”
Mark Klarzynski
“Take that building block … so that when scaled, it forms the most efficient, scalable AI infrastructure possible.”
PEAK:AIO’s AI Data Servers feature:
GPUDirect NVMe-oF – Optimized for ultra-fast, I/O-intensive workloads, with interruption-free data movement directly between storage and GPU memory.
GPUDirect RDMA NFS – Providing scalable, file-based data movement suited for larger AI clusters.
Next-Gen S3 Storage – Delivering significantly more powerful S3-compatible object storage, pushing object storage to new levels of efficiency and accessibility.
Elan Raja
Elan Raja, Scan Computers CEO, said: “It takes real expertise to craft a system where every element works in harmony to deliver the results customers expect.”
Klarzynski tells us PEAK:AIO has “had a two-year roadmap on features and extensions, and we will soon see a steady stream of new features, solutions, and collaborations set to roll out soon. And not just new tech, but solutions that will surprise even those who think they know where AI storage is headed.”
“It is not an easy decision to forgo the potential business benefits of mainstream enterprise storage. But GPUs represent such a fundamental shift in computing that we believe it is essential to fully commit to this evolved AI market rather than rebranding legacy storage. AI is a new frontier; it demands new storage and new thinking, not just new marketing.”
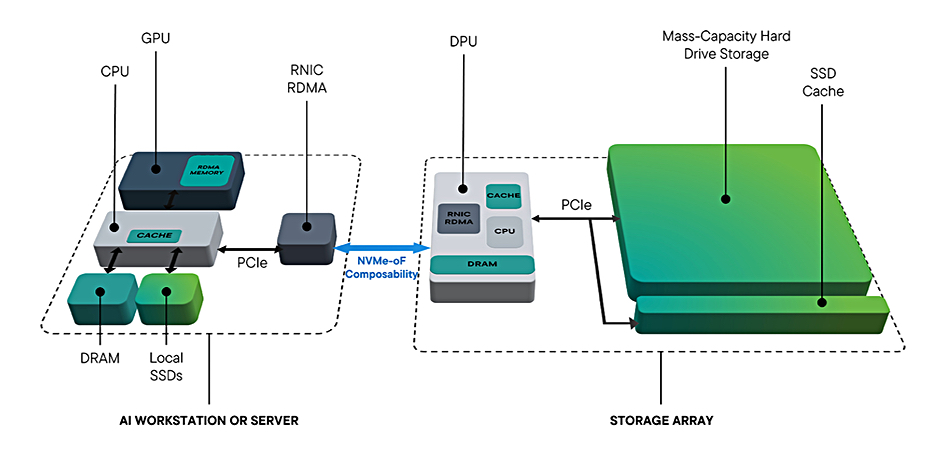
A Seagate blog says that fast-access hybrid flash+disk drive arrays are a good fit to AI workload needs because retaining large datasets solely on SSDs is financially unsustainable for most enterprises.
It goes on to say that, by adopting a parallel NVMe interface instead of the existing serial SAS/SATA hard disk drive (HDD) interface, we can “remove the need for HBAs, protocol bridges, and additional SAS infrastructure, making AI storage more streamlined.” By using “a single NVMe driver and OS stack, these drives ensure that hard drives and SSDs work together efficiently, removing the need for separate software layers.”
Access to data stored on NVMe SSDs benefits from GPUDirect protocols with direct GPU memory-to-drive access and no intervening storage array controller CPU involvement with memory buffering of the data to be transferred. Also existing NVMe-over-Fabrics infrastructure can be used “to integrate into distributed AI storage architectures, ensuring seamless scaling within high-performance data center networks.”
This is of no benefit at the individual HDD level where access latency is far more dependent on HDD seek time, with the head moving to the right track and then waiting for the appropriate blocks in the track to spin around underneath the head, than drive controller response time. An SSD has far lower access latency than a disk drive because the controller has fast electrical connections to the data storing cells and is not subject to seek time waits.
Seagate is suggesting that an entire drive array, a hybrid one with both SSDs and HDDS, gets NVMe connectivity to a GPU server. Then the speed of the link, compared to a SATA/SAS 12Gbits connection would enable far higher aggregate connectivity, even taking seek time into account. The HDDs and SSDs would share the NVMe connection to the GPU server, simplifying that side of things.
An RNIC, a BlueField-3 smartNIC/DPU for example, in the array would send data, using RDMA, to its twin in the GPU server, which would be linked to that server’s memory. Seagate built a demo system for Nvidia’s GTC 2025 conference with NVMe HDDs and SSDs in a hybrid array with a BlueField-3 front-end and Nvidia’s AIStore software, which supports Nvidia’s GPUDirect for object data protocol.
It says this was a proof-of-concept idea showing that:
Direct GPU-to-storage communication via NVMe hard drives and DPUs helped reduce [overall] storage-related latency in AI data workflows,
Legacy SAS/SATA overhead was eliminated, simplifying system architecture and improving storage efficiency,
NVMe-oF integration enabled seamless scaling, proving the composability of multi-rack AI storage clusters,
Model training performance was improved by AIStore’s dynamic caching and tiering.
Seagate says the POC demonstrated the composability of multi-rack storage clusters.
If we agree that “retaining large datasets solely on SSDs is financially unsustainable for most enterprises” then this demo of an NVME-connected hybrid flash+disk array could illustrate that AI workloads don’t need all-flash array architectures.
Seagate says that NVMe-connected HDDs will have applicability in manufacturing, autonomous vehicles, healthcare imaging, financial analytics and hyperscale cloud AI workloads. Compared to SSDs, NVMe hard drives would offer, it says:
10× more efficient embodied carbon per terabyte, reducing environmental impact.
4× more efficient operating power consumption per terabyte, lowering AI datacenter energy costs.
Significantly lower cost per terabyte, reducing AI storage TCO at scale.
Seagate has an NVMe HDD roadmap which includes using its 36TB and above HAMR drives, and creating reference architectures.
The company has history here. Back in 2021, it produced a 2 RU JBOD (Just a Bunch of Disks) enclosure housing 12 x 3.5-inch disk drives and accessed through an onboard PCIe 3 switch and NVMe at an Open Compute Summit. That initiative did not spur either Toshiba or Western Digital into doing the same.
Four years later, neither Toshiba nor Western Digital still have any public involvement in adding NVMe interfaces to their disk drives. It’s probable that customers for NVMe-connected hybrid arrays would appreciate freedom from HDD lock-in and single vendor pricing by having NVMe HDD support available from them as well as Seagate.
Komprise has updated its Elastic Data Migration (EDM) tech with automated destination share and user/permission mapping.
EDM ships unstructured data from a source to a target system. EDM v1.0 in 2020 took file data from an NFS or SMB/CIFS source and transferred it across a LAN or WAN to a target NAS system or, via S3 or NFS/SMB, to object storage systems or the public cloud. It used parallel transfers and was claimed to be up to 27 times faster than Linux rsync.
In 2022, EDM v4.0 provided up to 25x faster small file uploads to the public cloud with a so-called Hypertransfer feature, matching NFS transfer speed, according to Komprise. EDM v5.0 in 2023 enabled users and applications to add, modify, and delete data on the destination shares during the warm cutover period, when the last changes made on the source are copied to the destination. This, we’re told, eliminated downtime while the migration process was completed and the source data access switched off. Now we have a spring 2025 release.
Krishna Subramanian.
Krishna Subramanian, COO and co-founder of Komprise, said: “IT leaders are looking for efficiencies across the board and data migrations can incur unnecessary extra costs and risks. Komprise has features that help stakeholders align on which unstructured data to move, automation to set up migrations and detailed reporting for ongoing data governance.”
According to Komprise, this latest EDM release provides:
Automatic creation and mapping of destination shares which directly map source hierarchies to the destination to increase transparency and minimize compliance risks, eliminating manual mapping from source to target shares with its high error risk when thousands of shares are involved.
Automated user/permission mapping with a security identifier (SID) mapping, automating the process of changing owner and group permissions when migrating files based on customer-defined mapping policies. SID mapping saves time and lowers the risk of manual user/permission mapping errors.
Automatic generation of consolidated chain-of-custody reports listing each file’s source and destination checksums and timestamps for the migration. Chain of custody is often required in regulated industries to serve as evidence of successful transfers.
Transparent Share Mapping for Tiering: A migration is an opportunity to put old data in cheaper storage. Komprise says it can reveal cold data and have EDM tier it to object storage, reducing the need for new storage capacity. It allows transparent 1-1 mapping from file shares to object buckets so data owners can see the original file data hierarchy represented in a similar structure in the destination object buckets.
Transparent share mapping provides transparent visibility into data lineage for AI data governance.
Komprise EDM chain-of-custody screenshot
Komprise suggests that when organizations have centralized storage teams supporting multiple departments, each with their own share hierarchies, EDM’s automatic creation of destination shares from source hierarchies minimizes compliance risks. It also says that users can pick any source – NFS, SMB, Dual, Object – and choose a destination. Komprise EDM then does the rest.
EDM, available both for Azure and AWS, can be obtained as a separate service or as part of Komprise’s Intelligent Data Management offering. Learn more here.
Bootnote
Datadobi’s DobiMigrate also automates the replication of data hierarchies, within a single migration NFS, SMB or S3 environment, by scanning the source environment and replicating the directory structures, file paths, and associated metadata (e.g. permissions, timestamps) to the target. Multi-protocol migrations may require separate runs. Chain-of-custody technology with hash validation is used to ensure data integrity during the process.
Ceramic nano-dot archiving startup Cerabyte has received an investment from In-Q-Tel as part of a strategic initiative to speed up its product development.
Cerabyte’s technology uses femto-second laser-created nano dots in a ceramic-coated glass storage tablet that is stored in a robotic library. The medium is immutable, can endure for 1,000 years or more and promises to be more performant and cost-effective than tape. It is based in Germany and has opened offices in Silicon Valley and Boulder, Colorado. In-Q-Tel (IQT) is effectively a VC for the US CIA and other intelligence agencies and was set up to bring new commercial information technology to these agencies.
IQT Munich managing director Greg Shipley stated: “Cerabyte’s innovative technology can significantly enhance storage longevity and reliability while also reducing long-term costs and complexity. This strategic partnership aligns with our mission to deliver advanced technologies that meet the needs of the national security community.”
Christian Pflaum, co-founder and CEO of Cerabyte, matched this with his statement: “The strategic partnership with IQT validates our mission and fuels our ability to deliver accessible permanent data storage solutions.”
Cerabyte says that Commercial and government organizations anticipate managing data volumes comparable to those of major corporations such as Meta or Amazon. Most of this data will remain in cold storage for extended periods, aligning with typical declassification timelines of 25 to 50 years. The US National Academies of Sciences, Engineering, and Medicine (NASEM), conducted a Rapid Expert Consultation (REC) on technologies for archival data storage upon request of the Office of the Director of National Intelligence (ODNI); ODNI is the head of the US intelligence community.
We understand a a US National Academies REC is a report by subject matter experts looking at urgent issues where decision makers need expert guidance quickly.
Other recent In-Q-Tel investments include:
Participating in $12 million A-round for VulnCheck, a CVE vulnerability and exploit intelligence monitoring startup.
Participating in Israeli defense tech startup Kela’a $11 million seed round.
Contributing to US Kubernetes and AI workload security startup Edera’s $15 million A-round.
Participating in cloud GPU server farm business Lambda’s $480 million D-round.
It has famously invested in big data analytics supplier Palantir and also in Databricks.
Cerabyte has previously received an investment from Pure Storage and been awarded a portion of a €411 million ($426 million) European Innovation Council (EIC) Accelerator grant.
It’s possible we may have Cerabyte product development news coming later this year.
Interview: B&F caught up Rohit de Souza, CEO of MariaDB, following his visit to Finland where he met founder Michael “Monty” Widenius.
MariaDB was founded in 2009 by some of the original MySQL developers, spurred into action by Oracle buying MySQL owner Sun Microsystems. They developed their SkySQL open source databases as a MySQL fork. It was an alternative to proprietary RDBMSes and became one of the most popular database servers in the world. It went through some ten funding events, amassing around $230 million before going public through a SPAC transaction in 2023. In February 2022, it was valued at $672 million but started trading at the much lower $368 million. Michael Howard was CEO at the time, but Paul O’Brien took the post in March 2023. Tom Siegel was appointed CRO and Jonah Harris CTO.
Things did not go well. MariaDB posted poor quarterly results, received NYSE warnings about its low market capitalization, laid off 28 percent of its staff, closed down its Xpand and SkySQL offerings, and announced Azure Database for MariaDB would shut down in September 2025. A lender threatened to claw back cash from its bank account. Harris left in April 2024. O’Brien left in May that year.
MariaDB was acquired by private equity house K1 Investment Management in September 2024, at a suggested $37 million price, about a tenth of its initial public trading capitalization.
Rohit de Souza
At that time, MariaDB had 700 customers, including major clients such as Deutsche Bank, Nokia, RedHat, Samsung, ServiceNow, the US Department of Defense, and multiple US intelligence and federal civilian agencies. This gave K1 something to build on. It appointed Rohit de Souza as CEO, with previous executive experience from his roles at Actian and MicroFocus. O’Brien was transitioned out to advisor status.
De Souza’s job is to pick up the pieces and rebuild the company after its near-disastrous public ownership experience. How has he set about doing that?
He claimed MariaDB had been “completely mismanaged,” but there is a strong community and it’s “still the number three open source database in the world.” It has had a billion downloads of its open source software and it’s used by up to 1.3 million enterprises. “And if that’s not a customer base who wants to continue using its product, and see it develop further,” then he doesn’t know what is, De Souza said.
Some executive musical chairs took place. Siegel left the CRO job in January this year, Widenius was rehired as the CTO, and Mike Mooney became MariaDB’s CRO.
There is a free community edition of MariaDB and a paid-for Enterprise edition that has support. De Souza said there is “a very small sliver of those who are paying for it, but that’s because we’ve not managed that whole process right.” MariaDB has been leaving money on the table.
He said: “For instance, take a big bank, a prominent bank in the UK, they’re using both the community version and the enterprise one. They’re paying us support on the enterprise piece, but there’s been no diligence with them around saying, ‘Hey, if you’re going to get support from us, you need to get support on the entire estate.'”
“People can pay for the support on the enterprise and then use the skills they’ve got to fix the community edition. They use the support on the community stuff.”
This will be one strategy De Souza will use to increase revenue from the customer base. He said “there’s scope for the smooth scheme increase in the discussions” with customers.
How have customers responded to that idea? “So far I’ve touched a lot of customers as we’ve gone forward. The reception has been fabulous. The reception has been, ‘Oh really? We didn’t know you were going down that path. We thought MariaDB was sort of on its way out’.”
He is also updating the product. “We talked to them about what we’re doing around vector, how it’s an obvious development. It’s out with the community edition already and the GA piece for the enterprise edition will be in there soon.”
MariaDB added vector support alongside its existing transactional, analytical, and semi-structured data support in January.
De Souza has been giving MariaDB employees and partners “the message that there’s more value we can provide to our customer base. There’s more revenue that we can get from our customer base for this.”
He told us he had visited Widenius in Finland, and met his daughter Maria, after whom MariaDB is named, and other family members.
He said of Monty: “This guy, this is his life’s work. This is part of why I joined, because I see so much value in this and I see so much innate capability. Until this point engineering at MariaDB was every engineer did what he thought was right. There was no hope. Monty is a fabulous technologist, but you can’t ask him to drive the roadmap. He doesn’t want to do that.”
So, De Souza said: “You need a chief product officer. I’ve got a good chief product officer. I’ve got a good chief technology officer. I brought in a top-notch engineering leader to make sure that the trains run on time, and make sure our releases are right, make sure our roadmaps are correct. I brought in the right AI talent to make sure that we’re working on AI to put next to SQL in the database to do checkpointing.”
“I want to make it really, really simple to use for all of the fellas trying to mine the gold out of the AI system.”
The situation is that a MariaDB customer is looking to use AI agents and have them access structured and unstructured information in the database. That information will need vectorizing and the vectors stored in the database. Is MariaDB developing its own AI agents?
“We’re using traditional LLMs, Langchain or whatever. Whatever you want to use. We’d like to be able to use the typical externally available agents.”
Think of the LLM as an arrow and MariaDB as a data target.”“Use whatever arrows you want and we’ll make our target big and bold for those arrows and we’ll make it usable. We’ll make whatever information you’ve got stored in MariaDB accessible to all your AI, to the rest of your AI estate.”
MariaDB may well add an AI pipeline capability, including data masking to screen out sensitive data, “filtered to remove sensitive information. Then maybe transformed a little and then fed upstream and add to that on the front end the right security models. This is thanks to K1 and their relationships in the security area.”
De Souza is also concerned that his customers don’t get information leakage through AI agent use. “So for example, if you did a query through your large language model of your financial database to, say, give me what’s the revenue of the company, and think, ‘Hey, I’ll email this to my friend downstairs.’ You won’t be able to. You won’t have access to that on the front end.”
He sees AI agents as “extraordinarily powerful microscopes,” and will be looking at partnerships and/or acquisitions to gain technology access.
He said the company is getting enthused and growing. “I’m adding 20 percent to the staff in the company and I’m having no trouble finding the right talent. Because you say to prospective talent, check out MariaDB’s customer base and exposure and heritage. Check out what we can do with it. Do you want to be part of this or would you prefer to go risk yourself elsewhere?”
De Souza is adding senior advisors to MariaDB, such as Linux Foundation exec director Jim Zemlin and ServiceNow president Amit Zavery. He said ServiceNow has been trying to develop its own database. “We’ve just renewed a relationship with them and I’m convinced that at some point [CEO Jim] McDermott is going to see the light” – and use MariaDB.
He said there is a substantial large enterprise appeal in moving off Oracle and saving lots of cash. “We now have lots of interest. We’re in the process of migrating a large Middle Eastern airline off Oracle. They’ve said, ‘Show me that you can move a critical system,’ which is a little unnerving for us, and I’ve had to have all hands on that. But if that’s successful, we’ll have proved – we’ve already proved it in financial services, in retail – we’ll be able to prove it in the airlines and the transportation business.”
Another direction for development is automating the migration off Oracle. De Souza said: “The Oracle mode will only be available for the enterprise, of course, because these are going to be customers who are already paying millions of dollars.”
Airbyte announced new capabilities for moving data at scale for AI and analytics workloads:
Support for the Iceberg open standard for moving data into lakehouses
Enterprise Connector Bundle that includes connectors for NetSuite, Oracle Database with Change Data Capture (CDC), SAP HANA, ServiceNow, and Workday
Support for AWS PrivateLink with secure, private cloud-to-cloud data transfers to ensure sensitive information is controlled
…
Lenovo announced new full-stack systems using Nvidia components at GTC 2025. The Lenovo Hybrid AI Advantage with Nvidia framework includes the Lenovo AI Library. A new AI Knowledge Assistant is a “digital human assistant” that engages in real-time conversation with attendees to transform their event experiences and navigation. It enables users to customize Lenovo AI Library use cases and operationalize new AI agents and assistants within weeks. Lenovo is helping businesses build, scale, and operate their own AI factories. Lenovo’s agentic AI and hybrid AI factory platforms include Nvidia Blackwell Ultra support.
…
Phison has updated its aiDAPTIV+ “affordable AI training and inferencing solution for on-premises environments.” Customers will be able to fine-tune large language models (LLMs) up to 8 billion parameters using their own data. The new aiDAPTIVLink 3.0 middleware provides faster time to first token (TTFT) recall and extends the token length for greater context, improving inference performance and accuracy. A Maingear AI laptop PC concept was demonstrated at GTC 2025 using aiDAPTIVCache SSDs, aiDAPTIVLink middleware, and a Pro Suite GUI-based all-in-one feature set for LLMOps, including ingest, fine-tuning, RAG, monitoring, validation, and inference.
It says aiDAPTIV+ is a budget-friendly, GPU memory extension capability allowing users to train an LLM with their data within an on-premises “closed-loop” secure network, while providing a simple user interface to interact with and ask questions about the data. AI Inference for IoT with aiDAPTIV+ now supports edge computing and robotics use cases with Phison’s validation of Nvidia Jetson-based devices.
…
Predatar, which scans backups for malware, is releasing third-gen CleanRoom tech that supports more storage environments than the previous version, is more cost effective, and significantly quicker and easier to deploy. It has removed the need for customers to purchase hypervisor licences and third-party EDR software to reduce cost and streamline procurement, and can run on commodity hardware. There is a new ISO-based deployment method that enables a CleanRoom to be created as a Virtual Machine, or on bare metal. CleanRoom 3 can be built in just a few hours without the need for highly specialized skills or extensive training.
CleanRoom 3 will be available from March 31 directly from Predatar, Predatar’s Apex Partners, or from any IBM Storage Reseller.
…
Cyber-resilience and data protector Rubrik announced a strategic alliance with Big Four accounting firm Deloitte to deliver advanced data security and management to help organizations safeguard their data assets, business continuity, and cyber resilience. The two will:
Combine Rubrik’s Zero Trust Data Security software with Deloitte’s technical knowledge in cybersecurity, risk management, and digital transformation
Deliver integrated offerings that help clients streamline data management processes, providing efficient data backup and recovery
Use cloud technologies and analytics to assist organizations in improving their IT systems
Deloitte employs over 460,000 professionals worldwide and reported revenues of $67 billion in its fiscal year 2024. It will also serve as a sales and integration channel for Rubrik’s offerings.
…
SK hynix is speeding up high bandwidth memory (HBM) manufacturing following a customer order surge, including from Broadcom, says Korean media outlet TheElec, planning to bring in equipment into its new M15X fab two months earlier than originally planned. Wafer capacity at M15X is planned to increase from 32,000 wafers/month. Broadcom is expected to account for 30 percent of SK hynix’s total HBM capacity by the end of the year.
We understand Broadcom’s Strata DNX Jericho2 (BCM88690) Ethernet switch-router, launched in 2018, delivers 10 Tbps of bandwidth and integrates HBM for large-scale packet buffering. Jericho2c+ announced in 2020, offers 14.4 Tbps and uses HBM for enhanced buffering and power efficiency. The StrataDNX Qumran3D single-chip router provides 25.6 Tbps of routing capacity and uses HBM to support high-bandwidth, low-power, and secure networking for carrier and cloud operators.
In December 2024, Broadcom announced availability of its 3.5D eXtreme Dimension System in Package (XDSiP) platform technology, enabling consumer AI customers to develop next-generation custom accelerators (XPUs). The 3.5D XDSiP integrates more than 6,000 mm2 of silicon and up to 12 HBM stacks in one packaged device to enable high-efficiency, low-power computing for AI at scale.
TechRadar reported in January that Broadcom CEO Hock Tan told investors the company has three hyperscale customers who are each planning to deploy one million XPU clusters by 2027, and that it has been approached by two additional hyperscalers who are also in advanced development for their own AI XPUs.
…
Synology is thought to be launching DS925+, DS425+, DS225+, DS1525+, DS1825+, DS725+, DS625slim, DS1825xs+ and RS2825RP+ NAS storage systems between now and summer 2025, according to the NAScompares website, citing a ChipHell source. The new systems have 2.5 Gbps Ethernet ports.
…
Content Distribution Network supplier Akamai and VAST Data are partnering to profit from edge AI inference by enabling distributed customers to have better local response time and localization for distributed inference, compared to the centralized inference processing offered by hyperscalers. Akamai has a large Edge presence, with 4,300 points of presence and servers in more than 700 cities; effectively a distributed cloud. The partnership suggests that VAST Data storage and its AI software stack will be deployed in Akamai’s server locations.
Akamai says latency, cost, and scalability are hurdles to deploying AI-powered applications at scale. Unlike training, which is resource-intensive but happens in controlled environments, inference must operate continuously, on-demand, and often with ultra-low latency. Adding VAST Data to the Akamai Cloud aims to lower costs and improve customer experience to help democratize edge AI computing.
…
Agentic AI developer H2O.ai is partnering with VAST Data to bring agentic GenAI and predictive AI to enterprises’ exabyte-scale datasets. The two will combine “VAST Data’s modern infrastructure for storing and managing all data types (video, audio, documents, sensor data) with H2O.ai’s enterprise h2oGPTe platform to deliver retrieval-augmented answers, powerful model fine-tuning options, and grounded insights for enterprise users across on-premise, airgapped, and private cloud deployments.”
Enterprises can build agentic AI applications on top of the VAST Data Platform. Sri Ambati, Founder and CEO of H2O.ai, said: “h2oGPTe, the world’s #1 Agent AI, with VAST data platform makes the perfect platform for sovereign AI. Agentic AI is bringing incredible agility to businesses and modern automated workflows are transforming SaaS. With the accuracy of H2O.ai and instant access to any volume and variety of data from VAST, enterprises can deliver real-time decisions and become AI superpowers.”
H2O.ai partners include Dell, Deloitte, Ernst & Young (EY), PricewaterhouseCoopers (PwC), Nvidia, Snowflake, AWS, Google Cloud Platform (GCP), and Microsoft Azure. Founded in 2012, H2O.ai has raised $256 million from investors, including Commonwealth Bank, Nvidia, Goldman Sachs, Wells Fargo, Capital One, Nexus Ventures, and New York Life.
…
Datacenter virtualizer VergeIO, claiming it’s the leading alternative to VMware, has a strategic partnership with app virtualization and VDI supplier Inuvika to deliver a more cost-effective, high-performance virtual desktop and application delivery offering. The two aim to provide customers with “a seamless, scalable alternative to VMware Horizon and Citrix, addressing the increasing cost and complexity of legacy VDI solutions.”
…
A 2025 Emissions Blindspots Report commissioned by S3 cloud storage supplier Wasabi says “almost half of Europe’s business leaders (47 percent) are afraid to learn the full extent of their emissions data, even though 61 percent fear public backlash if their emissions are too high.” Wasabi surveyed 1,200 business decision makers across the UK, France and Germany and 51 percent are concerned they are going to lose customers if they fully disclose their emissions data. Only 66 percent of European businesses think that they can paint an accurate picture of their tech stack emissions, which includes Scope 3 emissions. You can read the 2025 Wasabi Emissions Blindspots Report in its entirety here.
In July last year, Wasabi and Zero Circle, a sustainable finance marketplace, teamed up to give businesses the data they need to “reduce their environmental impact.” Wasabi uses Zero Circle’s invoice-based carbon footprint calculator to provide customers with “transparency” and a real-time assessment of their emissions.
Data integration supplier Adeptia announced double-digit annual growth since 2021 by enabling enterprises to manage and optimize their first-mile (raw data created outside of an organization’s internal data operations) unstructured and third-party data with its AI-powered Adeptia Connect software. In the past year, it has hired Charles Nardi as CEO, Geoff Mueller as COO, and Ross Trampler as VP Sales. Deepak Singh, Adeptia founder and CTO, has moved into the new role of Chief Innovation Officer. Adeptia received a $65 million strategic growth investment round led by PSG in March 2023.
…
Alluxio, supplier of open source data store virtualization software using a virtual distributed file system with multi-tier caching, announced a strategic collaboration with the vLLM Production Stack, an open source implementation of a cluster-wide full-stack vLLM serving system developed by LMCache Lab at the University of Chicago.
AI inference requires low-latency, high-throughput, and random access to handle large scale read and write workloads. This partnership aims to help large language model (LLM) inference by providing an integrated solution for KV Cache management, utilizing both DRAM and NVMe, enabling efficient KV Cache sharing across GPU, CPU, and a distributed storage layer. By optimizing data placement and access across different storage tiers, the solution delivers low-latency, greater scalability, and improved efficiency for large-scale AI inference workloads.
…
Italy-based Avaneidi launched “CyberStorage by Avaneidi, a scalable and reliable storage infrastructure that seamlessly combines tailored Secure Hardware Storage, proprietary Data Governance and advanced CyberShield into one unified platform.” Avaneidi has introduced a new proprietary SSD, fully designed and manufactured in Europe, which it claims sets new standards for performance, durability, and reliability. Avaneidi says its “Enterprise Solid State Drives (ESSDs) utilize tailor-made chips and advanced algorithms, providing a bespoke solution optimized for performance and cyber security applications” with “extended drive lifetime, improved security, and significant energy savings.”
Avaneidi Goldrake ESSD.
The ESSD, codenamed Goldrake, comes in an AIC HHHL format with an NVMe PCIe gen 3 x4 interface. Capacities are 2TB, 3.84TB and on up to 16TB. It delivers 550,000/310,000 random read/write IOPS and has 2.5GBps/1.5GBps sequential read/write bandwidth. The endurance is 2 DWPD read-intensive and 5 DWPD write-intensive with a 5-year warranty.
…
Cloud backup and storage supplier Backblaze is partnering with media workflow designer CHESA to help M&E professionals collaborate anywhere by breaking down geographical barriers and connecting creative teams worldwide, leveraging Backblaze’s cloud infrastructure and CHESA’s workflow design. The two say they are “partnering with leaders in the M&E space, like LucidLink, iconik, and many others to offer a unified ecosystem that caters to every stage of the creative process.” CHESA delivers design and implementation expertise, while Backblaze provides scalable, cost-effective cloud storage for media workflows.
…
Data protection and management provider Cohesity announced an expanded collaboration with Red Hat to provide enhanced support for Red Hat OpenShift Virtualization, now available on the Cohesity Data Cloud. Customers can secure and protect data from virtual machines and containers in their Red Hat OpenShift Virtualization environments with Cohesity DataProtect and NetBackup. Backup and recovery operations for Red Hat OpenShift Virtualization-based virtual machines, along with containers, can be managed using the same workflows as existing data sources on the Cohesity Data Cloud. Watch a video with Cohesity CEO and president Sanjay Poonen with Red Hat CEO Matt Hicks, discussing the news.
…
Cohesity announced a partnership with AI supplier Glean to become a fully integrated data source for the Glean platform. It involves extending Glean’s connector capabilities to cover data sources protected by Cohesity, such as files stored on virtual machines, physical hosts, and NAS devices. This will “enable mutual customers to leverage high-quality backup data from Cohesity-protected workloads within Glean’s platform, further expanding enterprise knowledge and AI-driven insights.”
Users can search across historical data, going beyond the current state of data to access past versions of documents, including deleted files and other previously inaccessible data. Historical snapshots will offer a unique advantage, particularly in compliance, forensic investigations, and data recovery efforts. The integration is expected to be available for customers later this year.
…
Data streamer Confluent announced new capabilities in Confluent Cloud for Apache Flink to streamline and simplify development of real-time AI applications, including Flink Native Inference, running open source AI models in Confluent Cloud without added infrastructure management, Flink Search using just one interface to access data from multiple vector databases, and built-in ML functions to make data science skills accessible to more teams.
Confluent also announced further advancements in Confluent Cloud, making it easier for teams to connect and access their real-time data, including Tableflow, Freight Clusters, Confluent for Visual Studio (VS) Code, and the Oracle XStream CDC Source Connector. Learn more about these new features here.
…
Cloud file services vendor CTERA announced the availability of CTERA Edge-to-Cloud File Services in the Microsoft Azure Marketplace. Powered by Azure, CTERA gives “organizations cloud-native file services that extend from edge to cloud, offering enhanced availability, cyber resiliency, and scalability, while significantly reducing costs” with continuous data protection to Azure Blob Storage and global file access. Learn more about CTERA Edge-to-Cloud File Services at its page on the Azure Marketplace.
…
Vector databases supplier DataStax announced Astra DB Hybrid Search, a product that will improve AI search relevance by 45 percent. Using Nvidia NeMo Text Retriever reranking microservices, part of Nvidia AI Enterprise, Astra DB Hybrid Search, hosted on Astra DB with GPUs, integrates vector search and lexical search to deliver highly accurate, AI-driven search and recommendation experiences. Hybrid search combines two retrieval methods – vector search (for semantic understanding and contextual relevance) and lexical search (for exact keyword matching) – to help ensure both contextual relevance and precise keyword matching.
Astra DB automatically and intelligently reorders search results using fine-tuned LLMs, providing state-of-the-art ranking for more relevant and meaningful responses. Developers can integrate this functionality using the Astra DB Python client and schemaless Data API. The new capability will be available in Langflow, the open source tool and community for low-code AI application development.
…
DDN, French AI Model developer Mistral AI, and AI Cloud platform supplier Fluidstack announced a strategic alliance designed to make AI investments more successful, more flexible, easier to deploy, and significantly more cost-effective. The three say they deliver the most powerful AI infrastructure for training and deploying massive LLMs for enterprises, governments, and cloud providers. Timothée Lacroix, co-founder and CTO at Mistral AI, said: “DDN’s AI-optimized platform gives us the power to scale massive AI models with superior efficiency, reliability, and speed. Combined with Fluidstack’s cloud flexibility, this partnership ensures that our AI innovations deliver real-world impact – faster and at scale.”
…
Global engineering consultant Worley is using the Dell AI Factory with Nvidia to develop secure AI systems for employees and customers. One of their first products will be a GenAI app to assist Worley customer procurement teams in technical evaluations of vendor bid documents, reducing the time spent on data extraction and analysis from weeks to hours. Another will help Worley engineers accelerate design time by using GenAI to leverage insights from past projects for faster and more productive project delivery.
Kit being used includes PowerEdge XE9680 servers with Nvidia H100 GPUs, PowerScale F710 storage, AI Optimized Networking, and Nvidia AI enterprise software.
…
According to a Dell’Oro Group report, Server and Storage Component revenues grew to a record $244 billion in 2024, fueled by strong AI demand, primarily from GPUs, custom accelerators, HBM, and storage systems. Additionally, memory and storage demand for the general-purpose server market saw a strong rebound, accompanied by improved pricing throughout the year. Additional highlights from the Q4 2024 Data Center IT Semiconductors and Components Quarterly Report:
The Server and Storage Systems Component market is forecast to moderate to a healthy growth of over 40 percent in 2025.
Nvidia dominated Data Center Component market revenues, leading all vendors, with Samsung and SK Hynix trailing behind in 2024. Nvidia captured nearly half of the total reported revenues, while hyperscalers deploying custom solutions are rapidly gaining ground.
Smart NIC and DPU revenues increased by 77 percent, driven by strong deployment of Ethernet adapters in AI clusters.
The recovery in the CPU market is overdue, with revenues projected to increase by 45 percent in 2025.
Backup supplier Druva announced a new integration with Microsoft Sentinel for SecOps teams with a unified view of data insights across their company’s security and backup environments. This integration, “a key component of Druva’s ongoing collaboration with Microsoft,” combines backup telemetry, system behaviors, data anomalies, and threat detections into security operations, enabling centralized monitoring and real-time threat detection. SecOps teams get:
Bi-Directional Integration: seamless and real-time connection between the Druva Data Security Cloud and Microsoft Sentinel – SecOps teams can quarantine compromised snapshots directly within their Microsoft Sentinel console.
Faster Threat Detection & Recovery: With insight into backup telemetry, SecOps teams can detect cyber threats like ransomware or data corruption in real-time, significantly reducing recovery time.
Improved Productivity: Respond to incidents faster and more efficiently.
Enhanced Security Visibility & Compliance: Centralized management in Sentinel, now augmented by Druva’s data protection insights, providing deep visibility for threat hunting, compliance audits, and proactive threat mitigation.
Cloud backup supplier Eon “launched the first cloud-native package to provide protection and recovery from ransomware attacks.” Engineered for immediate recovery, it restores clean data in minutes, as opposed to hours or even days. Eon’s ransomware package aligns with the NIST Framework. It “delivers industry-first ransomware detection across cloud resources, including managed databases and data warehouses, and offers logically air-gapped backup vaults with immutable snapshots.”
Eon was founded in 2024 by Ofir Ehrlich and Gonen Stein of the CloudEndure founding team (acquired by Amazon), along with Ron Kimchi, former GM of AWS Migration and Disaster Recovery Services. Eon is backed by VCs including Sequoia, Lightspeed, Greenoaks, and BOND, as well as various industry execs. Find out more here.
…
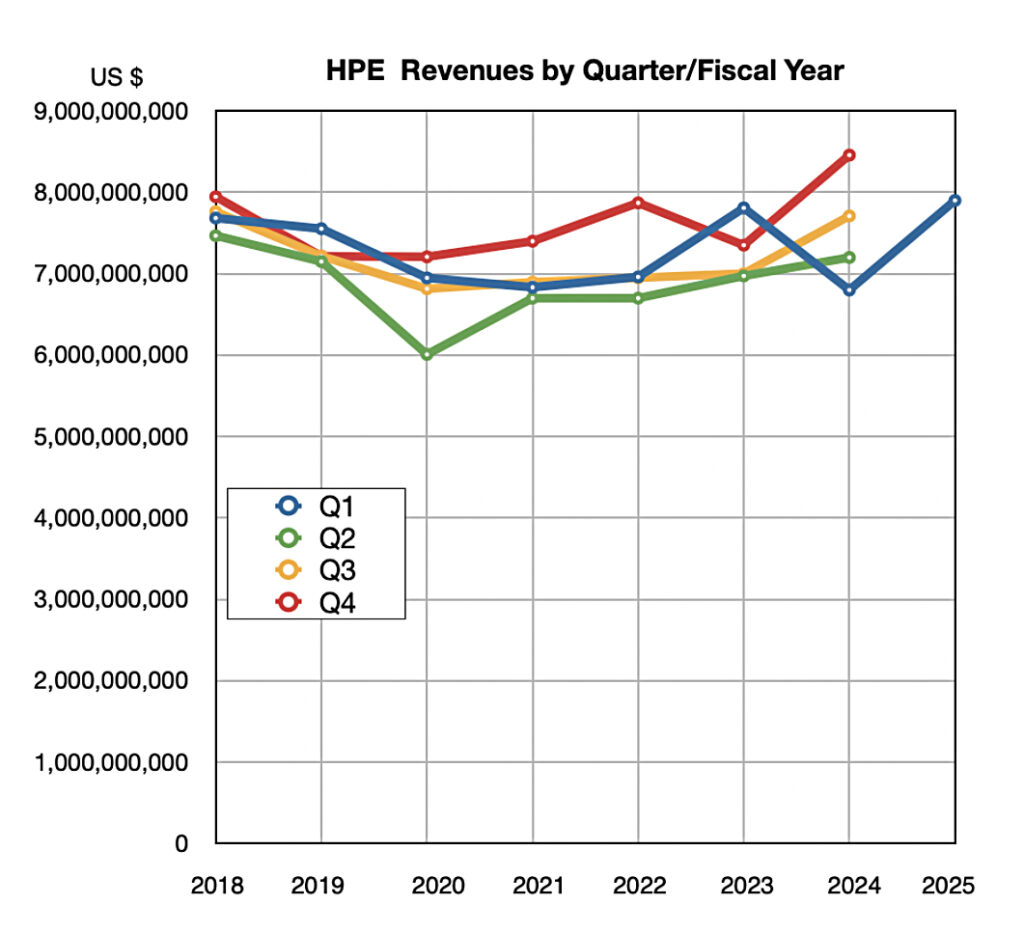
HPE reported $7.9 billion revenues for its Q1, up 16 percent year-over-year, with a $627 million GAAP profit, compared to the year-ago $387 million. CEO Antonio Neri said: “HPE achieved our fourth consecutive quarter of year-over-year revenue growth, increasing revenue by double digits in Q1.” Server segment revenues were $4.3 billion, up 29 percent. Intelligent Edge earned $1.1 billion, down 5 percent. Hybrid Cloud reported $1.4 billion, up 10 percent driven by Alletra Storage MP and GreenLake Cloud. Financial Services were flat at $873 million. AI systems orders doubled quarter-over-quarter with backlog increasing 29 percent. Its outlook for Q2 is $7.4 billion ± $2 million, just 2.7 percent up at the midpoint. It is cutting costs, with 2,500 jobs going, as the results were not as good as HPE had hoped and the outlook weak.
…
MagStor announced “the world’s first Thunderbolt 5 LTO drive, marking a monumental step forward in data storage technology.” It “offers unprecedented speed, reliability, and compatibility for professional data backup and archival needs” and is expected to be available by the end of 2025. The product has pending Intel and Apple Thunderbolt 5 certification and is also patent-pending.
VP Product Tim Gerhard tells us: “Thunderbolt 5 series will be available in LTO-7 thru LTO-10 single or dual configurations. Read/Write speeds will be up to 400 MBps on full height drives. In all honesty, there are no performance gains on the LTO drive itself, but you’re getting the latest controller chipsets and the ability to daisy chain TB5/USB4 v2 devices up to 80 GBps bandwidth. Most Thunderbolt 3 chipsets are going end of life and aren’t being produced anymore.”
…
Micron says it’s the world’s first and only memory company shipping both HBM3E and SOCAMM (small outline compression attached memory module) products for AI servers in the datacenter. The SOCAMM, a modular LPDDR5X memory, was developed in collaboration with Nvidia to support the GB300 Grace Blackwell Ultra Superchip. It is “the world’s fastest, smallest, lowest-power, and highest capacity modular memory.” Micron HBM3E (High Bandwidth Memory) 12H 36 GB is designed into the Nvidia HGX B300 NVL16 and GB300 NVL72 GPUs while the HBM3E 8H 24 GB is available for the HGX B200 and GB200 NVL72 GPUs.
…
MSP backup service and cybersecurity supplier N-able announced disappointing Q4 FY 2025 revenue growth up only 0.1 percent sequentially and 7.5 percent year-over-year to $116.4 million with a $3.3 million GAAP profit. It was accustomed to 10 to 12 percent year-over-year revenue growth. Full-year revenues were $466.1 million, up 10.5 percent year-over-year. CFO Tim O’Brien said: “Our product and go-to-market teams executed critical initiatives, the strategic acquisition of Adlumin expanded the aperture of our business, and we once again operated above the Rule of 40. We firmly believe we have the right pieces in place to win in our markets, and are investing to seize an expanding market opportunity and scale N-able to new heights.”
William Blair analyst Jason Ader commented: “At its 2025 investor day, N-able laid out its plan to reaccelerate growth and margins through sales of its Adlumin XDR/MDR solution (new business and cross-sell), upmarket expansion to new channel partners (VARs and distributors), and new pricing and packaging initiatives (to drive bundles and cross-sell).”
….
Nutanix says its Cloud Platform with Nutanix Unified Storage will integrate with the Nvidia AI Data Platform and enable inferencing and agentic workflows deployed across edge, datacenter, and public cloud. As the only HCI supplier openly supporting AI workflows, we wonder if Nutanix will support GPU servers and external parallel access file and object storage. We’re asking Nutanix about this.
…
PCI-SIG has announced that the PCI Express 7.0 specification, v0.9, the final draft, is now available for member review. The raw bit data rate doubles from PCIe 6’s 64 GT/s to 128 GT/s, and up to 512 GBps bi-directionally via x16 configuration. The PCIe 7.0 spec is designed to support data-intensive market segments such as hyperscale datacenters, high-performance computing, and military/aerospace, as well as emerging applications like AI/ML, 800G Ethernet, and cloud computing. PCI-SIG says it’s on track to publish the full specification later this year. PCI-SIG members can access the PCIe 7.0 specification in the Review Zone on its website.
…
Quantum announced Quantum GO Refresh for the DXi T-Series deduping appliances to provide flexible payment options and hardware refreshes. Quantum GO Refresh is a new offering within the Quantum GO portfolio offering a turnkey subscription model paid quarterly or annually. It includes the typical hardware, software, and support and a new dimension of ongoing hardware refreshes as the system ages. For more information, click here.
…
Quantum celebrated its channel partners’ achievements at the 2025 Quantum EMEA Elevate Partner Summit in Kraków, Poland, recognizing six companies for outstanding performance in 2024: ADT Group (Poland), Errevi System Srl (Italy), Fujitsu (Germany), Econocom (UK), SVA System Vertrieb Alexander GmbH (Germany), and Sithabile Technology Services (South Africa).
…
Parallel file system supplier Quobyte has announced support for Arm-based servers with Arm support from Rocky Linux 9 and Ubuntu 24.04. It will deliver the same high performance as Quobyte’s x86 offering as well as a complete set of features including RDMA support. The new Arm platforms can be used as they are or added to existing Quobyte x86-based clusters in a mixed environment. Supported processors include Nvidia Grace, Ampere CPUs, and the AWS Graviton.
…
Scale-out file system supplier Qumulo announced back-to-back quarters of record bookings and growth with profitable net operating income in the most recent quarter. President and CEO Douglas Gourlay said: “In our last two quarters Qumulo delivered record-breaking results measured by bookings, ACV, and gross margin generating over seven percent net operating income.” It has seen new product adoption and significant expansion of its cloud product portfolio and client base. Qumulo has more than 1,100 customers. Cloud Native Qumulo, launched in October 2024 on both AWS and Azure, with 165 customers, has experienced “remarkable customer adoption, delivering 485 percent year-over-year increase in cloud storage consumption.” EVP and COO Michelle Palleschi said: “Achieving both GAAP and non-GAAP net operating income [is] a rare feat for a growth-stage business.”
…
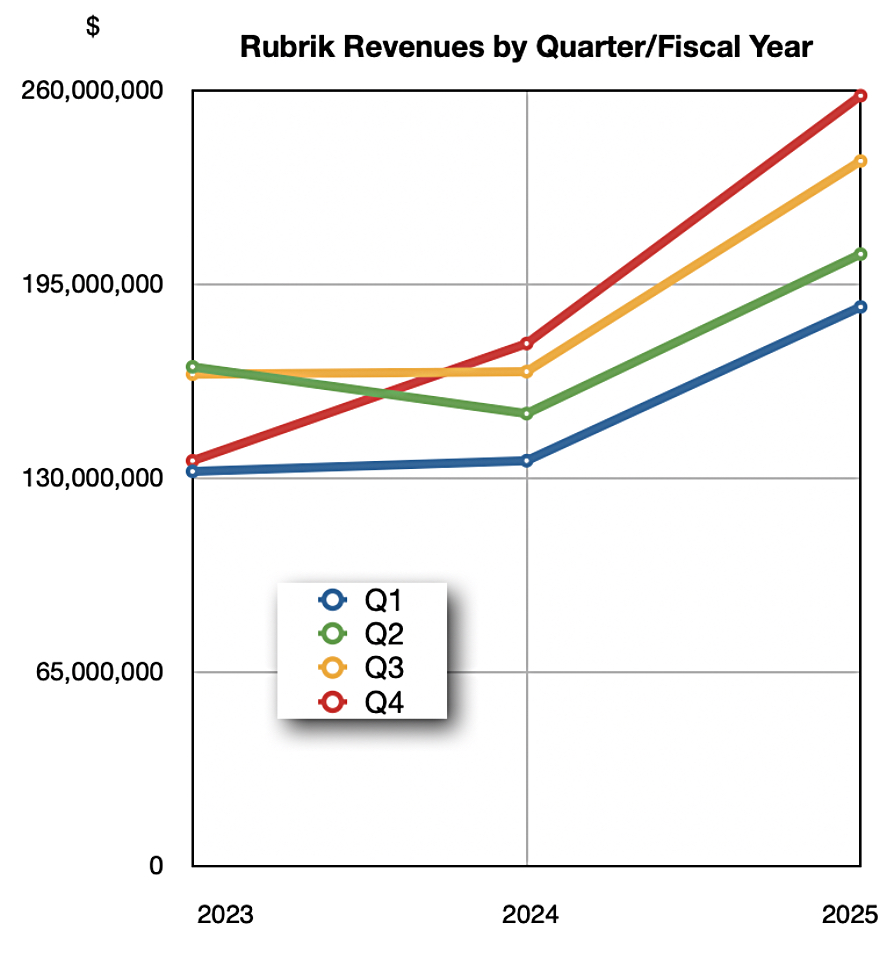
Cyber-resilience data protector Rubrik announced Q4 FY 2025 revenues of $258.1 million, up 47 percent year-over-year, with a GAAP loss of $114.9 million. Full-year revenues were $886.5 million, up 41 percent, with a loss of $1.15 billion.
CEO and co-founder Bipul Sinha said: “Fiscal 2025 was a milestone year for Rubrik. Our strong growth at scale demonstrates that we’re winning the cyber resilience market. However, we are still very early in Rubrik’s journey to achieve the company’s full potential and I’m confident that what’s ahead of us is even more important and exciting.” Rubrik and Commvault are reporting similar revenue figures:
…
Silicon Motion announced sampling of its MonTitan SSD Reference Design Kit (RDK) that supports up to 128 TB with QLC NAND, incorporating Silicon Motion’s PCIe Dual Ported enterprise-grade SM8366 controller, which supports PCIe Gen 5 x4 NVMe 2.0 and OCP 2.5. The 128 TB SSD has QLC NAND built with the latest 2 Tb die and sequential read speeds of over 14 GBps and random read performance exceeding 3.3 million IOPS, “providing over 25 percent random read performance improvement to other Gen 5 high-capacity solutions.” It supports NVMe 2.0 FDP (Flexible Data Placement) that improves SSD write efficiency and endurance. The software also uses Silicon Motion’s proprietary PerformaShape technology, utilizing a multi-stage shaping algorithm to optimize SSD performance based on user-defined QoS sets. The new 128 TB SSD RDK is now available for sampling to select partners and customers. Click here for more info.
Silicon Motion MonTitan graphic
…
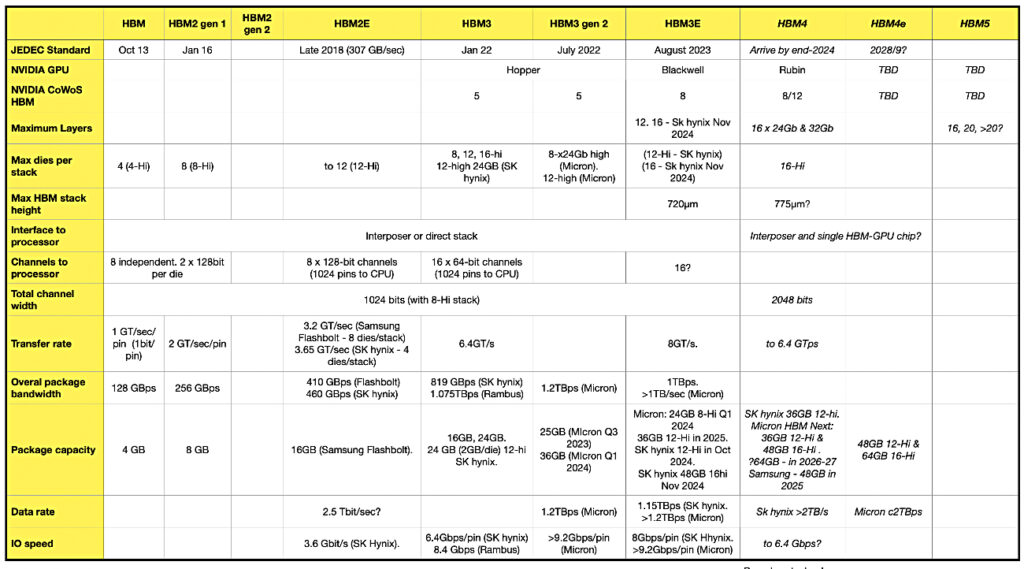
SK hynix is sampling 12-hi 36 GB HBM4 DRAM with mass-production slated for the second half of this year. It says the product “has implemented bandwidth capable of processing more than 2 TB of data per second for the first time” and more than 60 percent faster than HBM3E. Bandwidth is the total data capacity that one HBM package can process per second.
Partially filled table of HBM generations and characteristics
Wedbush analyst Matt Bryson says the production schedule “would seemingly put SK hynix in a position to comfortably support Nvidia’s shift to HBM4 with Rubin (expected to ship 2H 2026) and support SK hynix’s continued leadership in this market.”
…
StorPool Storage says it’s among the first block storage software platforms to support the Arm-based Ampere Altra processors available in HPE ProLiant RL300 servers, providing fast and reliable cloud solutions at a significant cost savings. This “brings predictable high performance, linear scaling, and extreme energy efficiency for cloud and AI workloads.” Cloud services provider CloudSigma will deliver the first commercial application of this technology – an IaaS offering leveraging StorPool software running on Arm-based HPE ProLiant servers.
Demos of this joint StorPool, Ampere, and CloudSigma system are taking place now through March 20 in the KVM Compute Zone at CloudFest 2025 at the Europa-Park resort in Rust, Germany.
…
DDN’s Tintri subsidiary with its workload-aware, AI-powered data management offering announced its latest Geek Out! Technology Demo Session “Container Boys: Hello Tintri” taking place on Wednesday, March 26 at 10am PT / 1pm ET. Hosted by Tintri CTO Brock Mowry, the session will explore how containerized workloads can streamline workflows and accelerate time-to-market. Register here.
…
Ahmed Shihab
Western Digital has hired Ahmed Shihab as chief product officer. He most recently served as Corporate VP of Azure Storage at Microsoft, leading the engineering and operations teams for object and block storage, driving the design and development of Microsoft’s cloud storage offerings. Before that he worked as VP Infrastructure Hardware at AWS and VP and Chief Architect (FSG) at NetApp, with an 8.5-year stint at disk storage supplier Xyratex before that. Irving Tan, CEO of Western Digital, said: “Given his tenure with storage and infrastructure design and development, Ahmed is the right leader to move Western Digital forward as we help our customers unleash the power and value of data. Hyperscalers, cloud service providers, and OEMs are looking to Western Digital to provide them with the most cutting-edge HDD technology to grow their businesses.”
…
Open source backup supplier Zmanda has introduced its Ask Zmanda AI support assistant, pre-loaded with enterprise backup expertise to help users get immediate answers when troubleshooting a backup issue or exploring advanced configurations. It has product-specific guidance for all Zmanda offerings, including Zmanda Pro-Instant answers to detailed technical questions. Try it out here.
…
Veeam Backup & Replication software has a security flaw that could lead to remote code execution, tracked as CVE-2025-23120, and carring a CVSS score of 9.9 out of 10.0. It affects 12.3.0.310 and all earlier version 12 builds and was reported by Piotr Bazydlo of watchTowr. It is fixed starting in the following build: Veeam Backup & Replication 12.3.1 (build 12.3.1.1139).
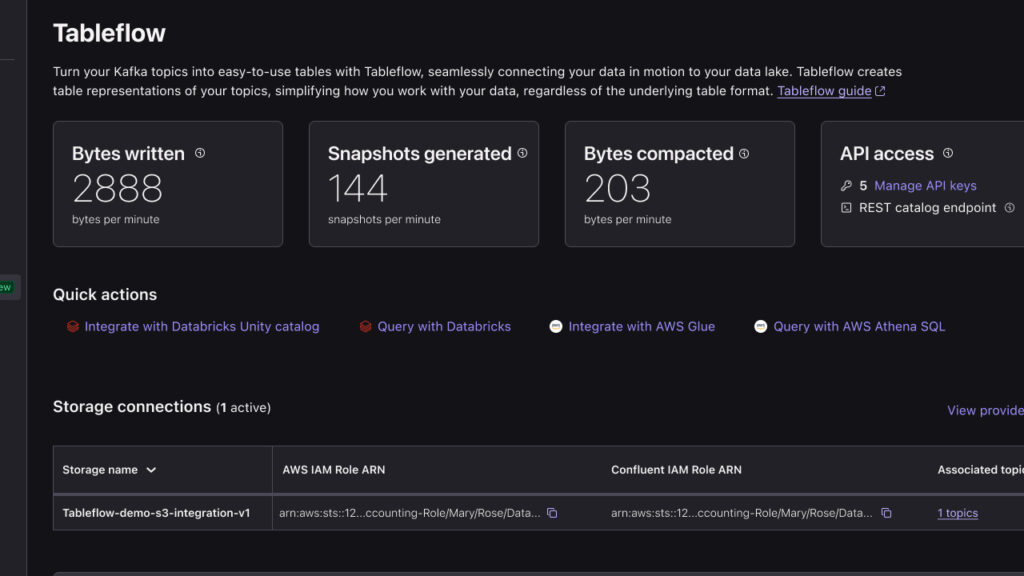
Data streamer Confluent has updated its Tableflow software to give AI and analytics software access to real-time operational data in data warehouses and lakes.
The Tableflow updates build on the Confluent-Databricks partnership announced in February to add bi-directional integration between Tableflow, Delta Lake, and the Databricks Unity Catalog.
Specifically, support for Apache Iceberg is now generally available and an Early Access Program for Delta Lake support is open. Production workload teams “can now instantly represent Apache Kafka topics as Iceberg tables to feed any data warehouse, data lake, or analytics engine for real-time or batch processing use cases.”
Tableflow also offers enhanced data storage flexibility and integrations with catalog providers, such as the AWS Glue Data Catalog and the Snowflake Open Catalog (a managed service for Apache Polaris). The Apache Iceberg and Delta Lake support enable real-time and batch processing and help ensure real-time data consistency across applications.
Confluent’s Chief Product Officer, Shaun Clowes, stated: “With Tableflow, we’re bringing our expertise of connecting operational data to the analytical world. Now, data scientists and data engineers have access to a single, real-time source of truth across the enterprise, making it possible to build and scale the next generation of AI-driven applications.”
Confluent Tableflow screenshot graphic
Citing the IDC FutureScape: Worldwide Digital Infrastructure 2025 Predictions report, which states: “By 2027, after suffering multiple AI project failures, 70 percent of IT teams will return to basics and focus on AI-ready data infrastructure platforms,” Confluent claims AI projects are failing because old development methods cannot keep pace with new consumer expectations.
The old development methods, or so says Confluent, are related to an IDC finding: “Many IT organizations rely on scores of data silos and a dozen or more different copies of data. These silos and redundant data stores can be a major impediment to effective AI model development.”
The lesson Confluent draws is that instead of many silos, you need a unified system that knows “the current status of a business and its customers and take action automatically.” Business operational data needs to get to the analytics and AI systems in real-time. It says: “For example, an AI agent for inventory management should be able to identify if a particular item is trending, immediately notify manufacturers of the increased demand, and provide an accurate delivery estimate for customers.”
Tableflow, it declares, simplifies the integration between operational data and analytical systems, because it continuously updates tables used for analytics and AI with the exact same data from business applications connected to the Confluent Cloud. Confluent says this is important as AI’s power depends on the quality of the data feeding it.
The Delta Lake support is AI-relevant as well as it’s “used alongside many popular AI engines and tools.”
Of course, having both real-time and batch data available though Iceberg and Delta Lake tables in Databricks and other data warehouses and lakes is not enough for AI large language model processing; the data needs to be tokenized and vectorized first.
Confluent is potentially ready for this, with its Create Embeddings action, a no-code feature “to generate vector embeddings in real time, from any model, to any vector database, across any cloud platform.”
Users can bring their own storage to Tableflow, using any storage bucket. Tableflow’s Iceberg tables support access for analytical engines such as Amazon Athena, EMR, and RedShift, and other data lakes and warehouses, including Snowflake, Dremio, Imply, Onehouse, and Starburst.
Apply for the Tableflow Early Access Program here. Read a Tableflow GA product blog to find out more.
Bootnotes
The Confluent Cloud is a fully managed, cloud-native data streaming platform built around Apache Kafka. Confluent was founded by Kafka’s original creators, Jay Kreps, Jun Rao, and Neha Narkhede. They devised Kafka when working at LinkedIn in 2008.
Delta Lake is open source software built by Databricks that is layered above a data lake and enables batch and real-time streaming data processing. It adds a transaction log, enabling ACID (Atomicity, Consistency, Isolation, Durability) transaction support. Users can ingest real-time data, from Apache Kafka, for example, into a dataset, and run batch jobs on the same dataset without needing separate tools. Databricks coded Delta Lake on top of Apache Spark.
Apache Kafka is open source distributed event streaming software built for large-scale, real-time data feeds used in processing, messaging, and analytics. Data in Kafka is organized into topics. These are categories or channels, such as website clicks or sales orders. A source “producer” writes events to topics, and target “consumers” read from them.
Apache Iceberg is an open source table format for large-scale datasets in data lakes, sitting above storage systems like Parquet, ORC, and Avro, and cloud object stores such as AWS S3, Azure Blob, and the Google Cloud Store. It brings database-like features to data lakes, such as ACID support, partitioning, time travel, and schema evolution. Iceberg organizes data into three layers:
Data Files: The actual data, stored in formats like Parquet or ORC
Metadata Files: Track which data files belong to a table, their schema, and partition info
Snapshot Metadata: Logs every change (commit) as a snapshot, enabling time travel and rollbacks
Apache Spark is an open source, distributed computing framework intended for fast, large-scale data processing and analytics. It’s used for big data workloads involving batch processing, real-time streaming, machine learning, and SQL queries.
The Databricks Unity Catalog provides a centralized location to catalog, secure, and govern data assets like tables, files, machine learning models, and dashboards, across multiple workspaces, clouds, and regions in the Databricks Lakehouse environment. It acts as a single source of truth for metadata and permissions.
Micron saw revenues for its DRAM and NAND grow year-over-year as datacenter servers used more high-bandwidth memory but sales outside the datacenter market turned down with buyers using up inventories.
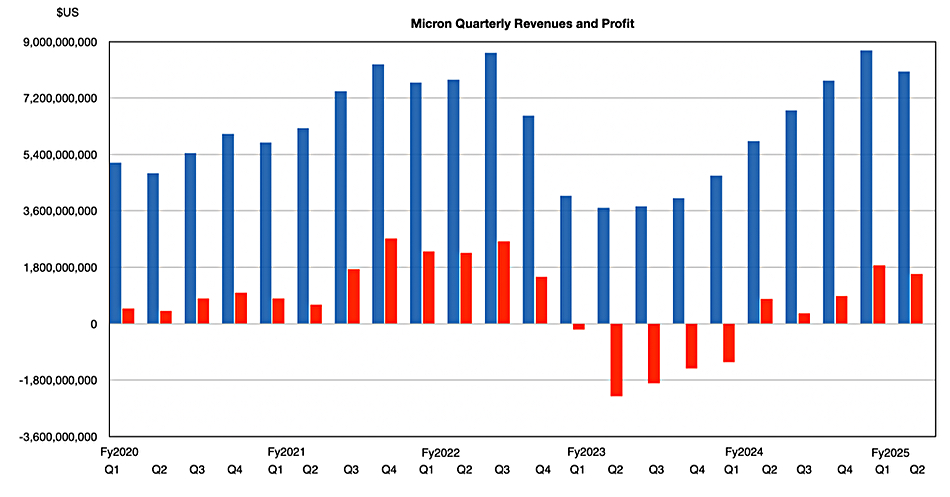
Revenues in the quarter ended December 31, 2024, were $8.05 billion, up 38 percent year-on-year but down 8 percent quarter-on-quarter after seven consecutive growth quarters. There was a $1.58 billion GAAP profit, virtually doubling the year-ago $793 million profit.
CEO Sanjay Mehrotra stated: “Micron delivered fiscal Q2 EPS above guidance and datacenter revenue tripled from a year ago” with record DRAM sales. He added in the earnings call: “Micron is in the best competitive position in our history, and we are achieving share gains across high-margin product categories in our industry.”
Note the quarter-on-quarter downturn in Q2 FY 2025 – but Micron expects a rebound next quarter
Financial summary
Gross margin: 36.8 vs 18.5 percent a year ago
Operating cash flow: $3.94 billion vs $1.2 billion a year ago
Free cash flow: $857 million vs -$29 million last year
Cash, marketable investments, and restricted cash: $9.6 billion vs $9.7 billion a year ago
Diluted EPS: $1.41 vs 0.71 a year ago
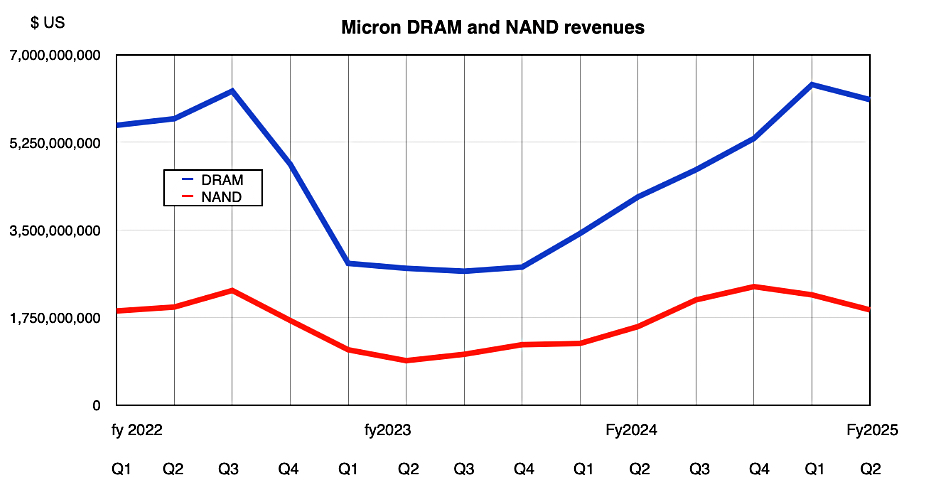
Micron has two main tech segments, DRAM and NAND. DRAM revenues of $6.1 billion were up 47 percent year-on-year but down 4 percent quarter-on-quarter, with high-bandwidth memory (HBM) driving the growth.
Mehrotra said: “We expect a strong ramp of HBM throughout calendar 2025. As noted before, HBM3E consumes three times the amount of silicon compared to D5 to produce the same number of bits. Looking ahead, we expect the trade ratio to increase with HBM4 and then again with HBM4E when we expect it to exceed 4-to-1.” HBM DRAM commands a premium over conventional DRAM.
NAND revenues were $1.9 billion, up 18 percent year-on-year and down 17 percent quarter-on-quarter. Mehrotra said: “In calendar Q4 2024, based on industry analyst reports, Micron achieved yet another record high market share in datacenter SSDs with revenue growth in each category, including performance, mainstream, and capacity SSDs.”
“In NAND, we continue to underutilize our fabs, and our wafer output is down mid-teens percentage from prior levels,” he said. However, a rebound is coming with Micron saying that demand moderated in fiscal Q2 due to short-term customer inventory-driven impacts. It sees a return to bit shipment growth in the months ahead and expects to generate multiple billions of dollars in datacenter NAND revenue and grow its datacenter NAND market share in calendar 2025.
It looks like a cyclical revenue trough might be coming – but Micron disagrees with that perception
There are four business segments:
Compute & Networking revenues were $4.6 billion, up 47 percent year-on-year and down 4 percent quarter-on-quarter
Storage revenues were $1.4 billion, up 54.7 percent year-on-year and down 20 percent quarter-on-quarter with low datacenter sales
Mobile revenues dropped 32 percent year-on-year and 30 percent quarter-on-quarter to $1.1 billion as customers used up inventories
Embedded market revenues went down 10 percent year-on-year and 3 percent quarter-on-quarter as automakers used up inventory
Sequentially, only the compute and networking segment revenues grew; the HBM effect in action. AI training needs GPU servers, which require HBM and SSD storage but the AI Inferencing market is still nascent. That is affecting NAND growth in datacenters and workstations, much of Micron’s storage market. The mobile and embedded markets seem to be stalled.
HBM is increasingly important to Micron, with HBM DRAM representing a significant growth opportunity for market leader SK hynix and Samsung. Mehrotra said: “We expect multibillion dollars in HBM revenue in fiscal 2025 … As noted before, HBM3E consumes three times the amount of silicon compared to D5 to produce the same number of bits. Looking ahead, we expect the trade ratio to increase with HBM4 and then again with HBM4E when we expect it to exceed 4-to-1.”
Micron is enthusiastic about its coming HBM4, which will ramp in volume in calendar 2026. It aims to deliver “the best HBM4 products to the market across power efficiency, quality, and performance.” And it expects to gain HBM market share compared to SK hynix and Samsung.
PC demand for DRAM will be driven by PC refreshes for AI-capable systems and the Windows 10 end-of-life in October this year. AI PCs require a minimum of 16 GB of DRAM versus the average 12 GB PC content last year.
Smartphone unit volume growth looks to be in the low single-digit percentage area, and, with inventories emptying, Micron expects mobile DRAM and NAND bit shipment growth in the current quarter. AI-capable phones will need more DRAM and NAND but demand for such devices is low presently. The embedded market is still affected by automotive OEMs, industrial, and consumer-embedded customers adjusting their inventory levels.
On tariffs, Micron says it “serves as the US importer of record (IOR) for a very limited volume of products that would be subject to newly announced tariffs on Canada, Mexico, and China … Where tariffs do have an impact, we intend to pass those costs along to our customers.”
Concerning next quarter’s outlook, Mehrotra said: “We expect fiscal Q3 revenue to be another record for Micron, driven by shipment growth across both DRAM and NAND.” The actual revenue outlook is a record $8.9 billion ± $100 million, a 30.7 percent year-on-year increase at the mid-point. That’s a rebound from the current quarter’s sequential decline.