


Uber is using Alluxio’s virtual distributed file system to speed its Hadoop-based analytics processing by caching hot read data.
Alluxio has developed open source data store virtualization software, a virtual distributed file system with multi-tier caching. Analytics apps can access data stores in a single way instead of using unique access routes to each storage silo. This speeds up data silo access and includes an HDFS driver and interface, which proved useful to Uber.
The ride-hailing company stores exabytes of data across Hadoop Distributed File System (HDFS) clusters based on 4TB disk drives. It’s moving to 16TB drives and has a disk IO problem – capacity per drive has gone up but bandwidth has not, causing slow reads from data nodes.
It analyzed traffic on the production cluster and found “that the majority of I/O operations usually came from the read traffic and targeted only a small portion of the data stored on each DataNode.” A table shows some of the statistics gathered from ~20 hours of read/write traces from DataNodes across multiple hot clusters.
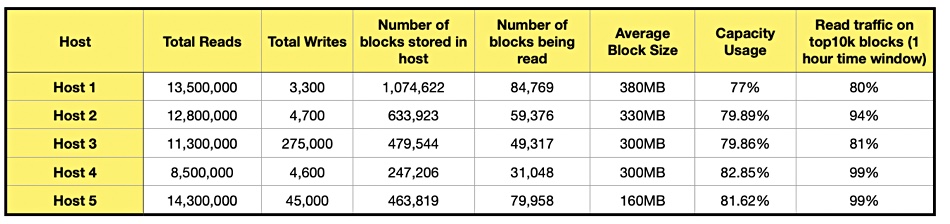
The table above shows the majority of the traffic is read IO and less than 20 percent of the data blocks were read in a 16 to 20-hour time window. In one hour, the top 10,000 blocks were responsible for 90 percent or more of the read traffic.
Based on this, the IT people at Uber reckoned that caching the hot read data would speed overall IO. They thought a 4TB SSD cache should be able to store 10,000 blocks based on the average block size in hot clusters.
They used Alluxio to have a read-only DataNode local cache for the hot data alongside the 525TB disk capacity using 16TB HDDs. The DataNode local SSD cache is situated within the DataNode process, and remains entirely transparent to HDFS NameNode and clients. It resulted in “nearly 2x faster read performance, as well as reducing the chance of process blocking on read by about one-third.”
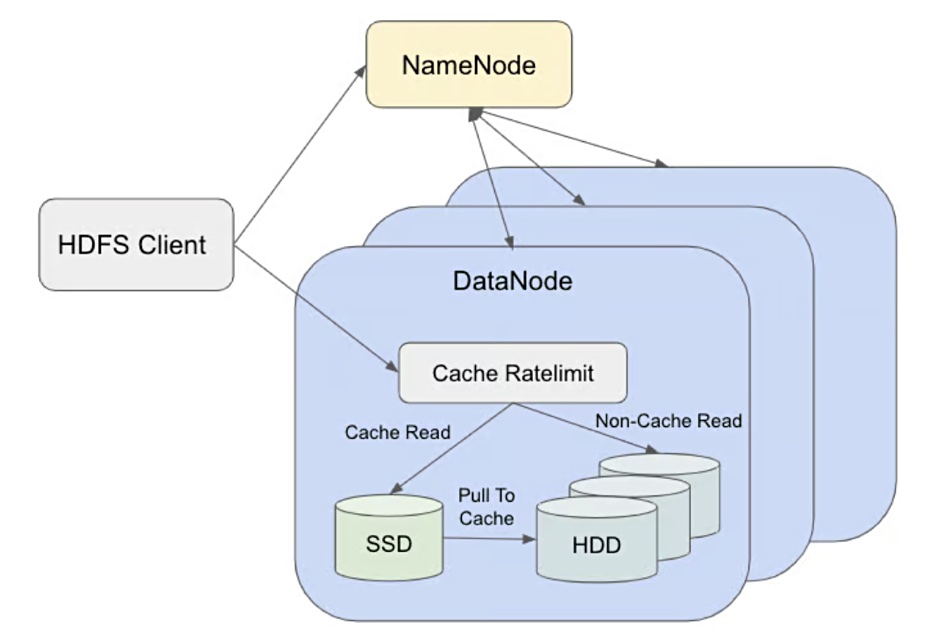
Uber experienced a 99.5 percent cache ratio, meaning there was a high chance that a data block in the cache would be accessed again. Cache DataNode read throughput was found to be significantly higher, nearly twice that of non-cache data node read throughput.
Uber concluded: “Overall, the local caching solution has proven to be effective in improving HDFS’s efficiency and enhancing the overall performance.”
An Uber blog contains much more information about the Alluxio caching arrangements.





