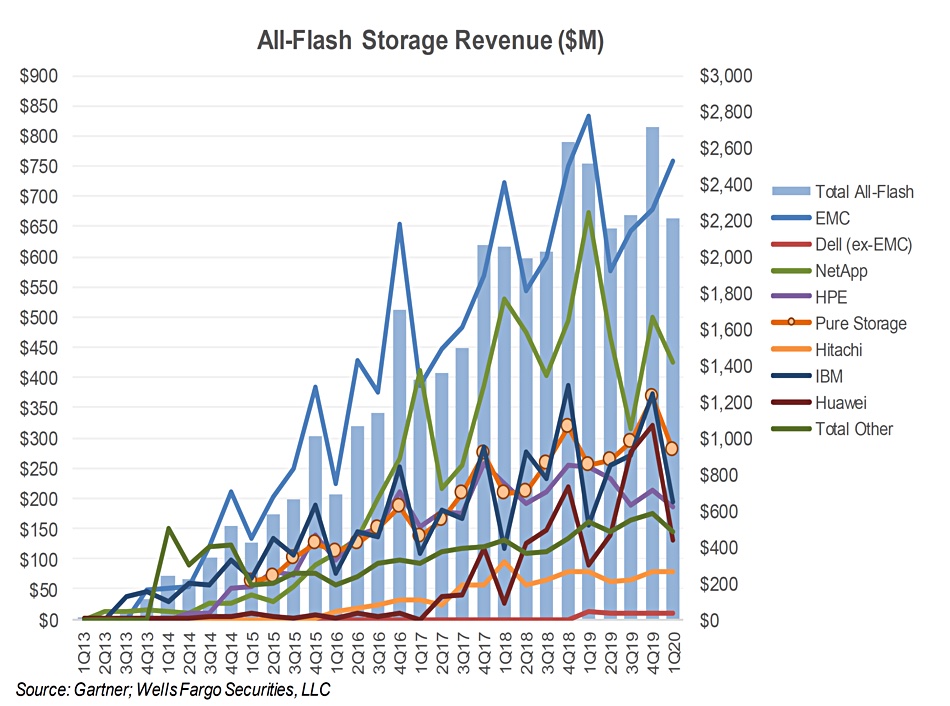
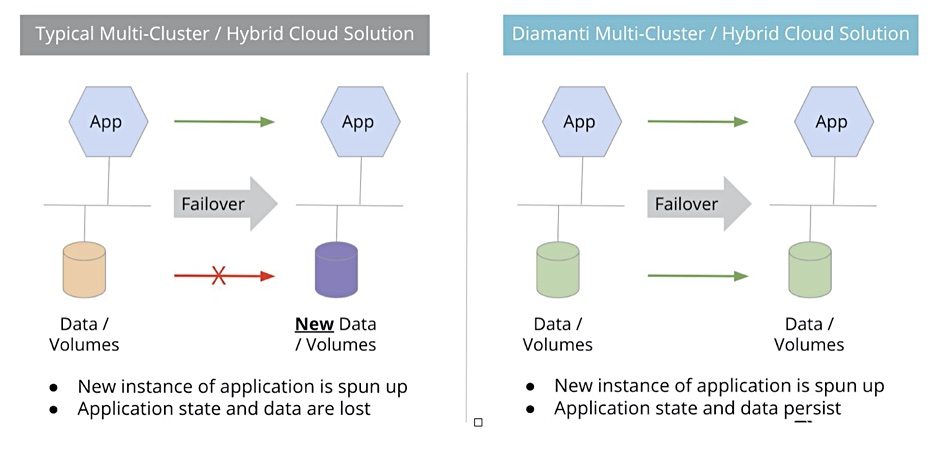
So, Rubrik is getting sued again – this time by Actifio. Druva is on a roll as business booms, and we have lots of data storage titbits for your delectation in this week’s digest.
Actifio sues Rubrik
Copy data manager Actifio is suing Rubrik for patent infringement, alleging the competitor has infringed and continues to infringe at least one claim of each of U.S. Patents 6,732,244; 6,959,369; 9,495,435; and 10,013,313. These relate to relating to copy data management technologies and it wants injunctive relief and monetary damages.
The patent subjects are:
- 6,732,244 – Instant Visual Copy Technique with Expedited Creation of Backup Dataset Inventory from Source Dataset Inventory
- 6,959,369 – Method, system, and program for data backup
- 9,495,435 – System and method for intelligent database backup
- 10,013,313 – Integrated database and log backup
This will give Rubrik’s legal department another potentially long-running case to defend. Commvault filed a patent infringement suit agains Rubrik and Cohesity in April.
Druva drums up lots of business
Druva, the endpoint, data centre and SaaS backup startup, has boasted of its most successful year to date, with a 70 per cent recurring revenue increase for data centre protection software, and 50 per cent growth in overall data under management.
Druva claims it is the largest and most trusted company delivering SaaS-based data protection.
CEO and founder Jaspreet Singh issued a quote: “The spring of 2020 will be forever remembered as the inflection point of the cloud era, when years of planning and discussion transformed into action and massive migration efforts nearly overnight.”
The company claims more than 4,000 customers and reckons they have performed over 1.5 billion backups in the last 12 months. Druva aims to grow faster still this year and is prepping various product enhancements.
Shorts
Actifio has launched backup and disaster recovery services for Google Cloud’s Bare Metal Solution (BMS). It supports on-premises Oracle workloads, migration from on-premises and-or other clouds to Google Cloud, and rapid database cloning in BMS to accelerate testing.
SaaS backup provider Cobalt Iron has introduced multi-tenancy capabilities for the virtual tape library (VTL) ingest feature of Compass, its enterprise SaaS backup system. These make Compass the first enterprise SaaS backup solution to provide multi-tenancy at tape ingest, according to the company.
Couchbase has announced the general availability of Couchbase Cloud, its database-as-a-service. This is available initially on AWS, and support is slated for Azure and Google Cloud by year-end.
DDN Tintri has formed a partnership with DP Facilities, a data centre firm, to deliver integrated VDI systems. This combines VDI-optimised storage with colocation services within DP Facilities’ secure Wise, VA, data centre.
Nasuni‘s cloud file services platform is now available for purchase in the Microsoft Azure Marketplace.
UC San Diego Center for Microbiome Innovation (CMI) has bought an additional 2PB of ActiveStor capacity to add to its Panasas installation. This will help support the organisation’s Covid-19 research studies. A case study document provides more information.
Cinesite Studios, a global producer of special effects and feature animation, has chosen Qumulo’s file software to support its rendering workloads. Cinesite uses Qumulo across multiple AWS Availability Zones, supporting artists and staff dispersed geographically. Qumulo replicates data between on-premises and AWS.
Object storage supplier Scality has announced its founder status and membership of SODA Foundation, an open source community under the Linux Foundation umbrella. Scality joins Fujitsu, IBM, Sony and others to figure out data management across multiple clouds, edge and core environments for end users.
SK hynix has started mass-production of high-speed DRAM, HBM2E, which supports over 460GB/s with 1,024 I/Os based on 3.6Gbit/s performance per pin. It is the fastest DRAM in the industry, SK hynix, able to transmit 124 full-HD movies (3.7GB each) per second. The density is 16GB by vertically stacking eight 16Gb chips through TSV (Through Silicon Via) technology, and it is more than doubled from the previous generation HBM2.
WANdisco has signed a deal worth up to $1m initially with a major British supermarket for its replication software. In addition, it reports strong uptake for the Group’s Azure Cloud product, with 11 companies registered in the first month of public preview.
Yellowbrick Data has announced the general availability of the Cloud Disaster Recovery service, and new database replication and enhanced backup and restore features. These support backups at near-line speed, allow for incremental backups, and provide transactional consistency (ACID) of restored data. They also enable the automation of backup and restore operations without intermediate storage.
Zadara Storage, which supplies on-premises SAN arrays as a service, is claiming record growth. No hard numbers, as is the way with privately-held US startups, but the company said gross profits increased 93 per cent y/y and that it has delivered 17 consecutive quarters of recurring revenue growth. New customer accounts grew over 100 per cent y/y – as did its global partner network.
People
Hitachi Vantara announced a new CEO, Gajen Kandiah, who replacies current CEO, Toshiaki Tokunaga, effective July 13, 2020. Tokunaga will transition responsibilities to Kandiah through Oct. 1, 2020, after which he’ll remain as chairman of the Board for Hitachi Vantara, and also take an expanded role for Hitachi Ltd’s Services and Platform Business Unit in Japan. Kandiah recently spent 15 years with Cognizant, where he helped grow the company from $368m in annual revenues to more than $16bn.
Kaminario CTO Eyal David is now ex-Kaminario as he has resigned and is joining Model9, a startup replacing mainframe tape and VTL systems with object storage in the cloud.
Qumulo has appointed Adriana Gil Miner as its CMO. She joins from Tableau where she was SVP of Brand, Communications and Events. It’s a year since the previous Qumulo CMO, Peter Zaballos, left.
Zadara has appointed Tim DaRosa as Chief Marketing Officer. He comes from being SVP of global marketing for HackerOne, where helped build brand awareness and go-to-market strategies that propelled the Silicon Valley-based cybersecurity business to record growth over the past four years.