The latest version of the TrueNAS open source storage software from iXsystems will soon be available, according to the company’s latest update notes.
The release is called TrueNAS Fangtooth, and promises to improve performance, security, and scalability for both users and developers. Fangtooth is the successor to TrueNAS Electric Eel.
Fangtooth is based on TrueNAS SCALE, and marketed as the common TrueNAS Community Edition. TrueNAS Fangtooth will be an upgrade for both SCALE 24.10 and CORE 13.x users, and introduces new features for Community and Enterprise users.
The more mature CORE was seen as delivering better performance than SCALE, and it needs less CPU power and memory. TrueNAS CORE is the original successor of FreeNAS, based on the FreeBSD operating system. With the introduction of TrueNAS SCALE in 2022, more modern Linux capabilities were introduced to TrueNAS, enabling adoption by a much larger community.
SCALE was initially created as a fork of CORE, with each version continuing their development, bug fixes, and security updates independently.
But by the back end of last year, there were roughly equal numbers of SCALE and CORE users, with SCALE having doubled its system count over the year, and CORE “declining slowly” as users migrated to SCALE, said iXsystems.
“The benefits of unification will be enormous for the community, both users and developers. Before the end of 2025, we expect most TrueNAS users will be on Fangtooth,” the supplier said.
Fangtooth (aka TrueNAS 25.04) is already available for developers, and the BETA1 version is expected to be ready by February 11. Bug fixes, feature updates, and “ongoing polishing” will continue until the targeted release date for a “stable” community version on April 15.
Notable new capabilities in Fangtooth include TrueNAS Versioned API, which allows third parties to use APIs to control TrueNAS, knowing that future versions of TrueNAS will honor the same API schemas.
“TrueNAS can evolve and improve in a more organized manner,” said iXsystems, “allowing external tools to run with longer stability.” Future versions of TrueCommand are expected to enhance system longevity. User-Linked API Tokens are also included to provide secure and restricted management.
In addition, Fast Dedup promises a “significant reduction” in storage media costs, and iSCSI Block Cloning allows virtualization solutions to benefit from using iSCSI XCOPY commands for efficient and rapid data copying.
There is also upgraded containerization and virtualization, with TrueNAS integrating Incus support, and an upgraded WebUI with support for native LXC containers.
Also, by upgrading to Linux kernel 6.12 LTS, Fangtooth will support new hardware. This will be an advantage for both CORE and SCALE users upgrading their hardware.
Apps in Electric Eel use TrueNAS’s host IP address. Fangtooth enables IP alias addresses to be created and assigned to one or more apps. A number of other new features can be viewed here.
By July, it is expected that Fangtooth will be recommended to enterprise users.
Workload and data mobility player RiverMeadow has upgraded its platform to help extend Pure Storage’s on-premises Evergreen storage-as-a-service to the cloud.
RiverMeadow says it offers its Workload Mobility Platform and services to allow businesses to migrate and “optimize” workloads with “unprecedented scale, speed, and certainty.”
With the upgrade, customers will now be able to use RiverMeadow to access Pure Cloud Block Store on platforms like Azure, AVS (Azure VMware Solution), and AWS. “This advancement provides unprecedented flexibility and elasticity for cloud-based workloads and disaster recovery,” claimed RiverMeadow.
Jim Jordan
The two companies said the collaboration represents a “significant step forward” in reducing cloud storage costs through enhanced data optimization during workload migration. RiverMeadow says it is offering “fixed-price” migration capabilities to support Pure Storage’s enterprise-grade data platforms.
Jim Jordan, president and CEO of RiverMeadow, explained: “For customers moving storage-bound workloads to Azure, AVS, or AWS, Pure Storage now offers the ability to scale up their storage capacity without increasing the number of overall nodes. RiverMeadow’s integration with Pure Cloud Block Store means customers can move workloads faster, while simultaneously optimizing the target architecture.”
Cody Hosterman
“Pure Storage is committed to innovating to meet the evolving needs of our customers, and our work with RiverMeadow is an example of this commitment,” said Cody Hosterman, senior director of cloud product management at Pure Storage. “As businesses continue to migrate workloads due to shifts in strategy, cost management, or as part of their cloud efforts, our collaboration provides scalable and efficient solutions that enable customers to leverage Pure Storage capabilities to consume the cloud dynamically and cost-effectively.”
As part of a wide-ranging upgrade to its PowerMax high-end enterprise block storage arrays last October, Dell offered “simple options” to move live PowerMax workloads to and from its on-demand APEX Block Storage, which can be located on-premises and in the AWS and Azure public clouds. The company said the offer relied on RiverMeadow’s technology to do it.
Microsoft researchers have proposed Managed Retention Memory (MRM) – storage-class memory (SCM) with short-term persistence and IO optimized for AI foundation model workloads.
Sergey Legtchenko
MRM is described in an Arxiv paper written by Microsoft Principal Research Software Engineer Sergey Legtchenko and other researchers looking to sidestep high-bandwidth memory (HBM) limitations in AI clusters. They say it is “suboptimal for AI workloads for several reasons,” being “over-provisioned on write performance, but under-provisioned on density and read bandwidth, and also has significant energy per bit overheads. It is also expensive, with lower yield than DRAM due to manufacturing complexity.”
The researchers say SCM approaches – such as Intel’s discontinued Optane and potential alternatives using MRAM, ReRAM, or PCM (phase-change memory) – all assume that there is a sharp divide between memory, volatile DRAM, which needs constant power refreshes to retain data, and storage, which persists data for the long-term, meaning years.
They say: “These technologies traditionally offered long-term persistence (10+ years) but provided poor IO performance and/or endurance.” For example: “Flash cells have a retention time of 10+ years, but this comes at the cost of lower read and write throughput per memory cell than DRAM. These properties mean that DRAM is used as memory for processors, and Flash is used for secondary storage.”
But the divide need not actually be sharp in retention terms. There is a retention spectrum, from zero to decades and beyond. DRAM does persist data for a brief period before it has to be refreshed. The researchers write: “Non-volatility is a key storage device property, but at a memory cell level it is quite misleading. For all technologies, memory cells offer simply a retention time, which is a continuum from microseconds for DRAM to many years.”
By tacitly supporting the sharp memory-storage divide concept, “the technologies that underpin SCM have been forced to be non-volatile, requiring their retention time to be a decade or more. Unfortunately, achieving these high retention times requires trading off other metrics such as write and read latency, energy efficiency, and endurance.”
General-purpose SCM, with its non-volatility, is unnecessary for AI workloads like inference, which demand high-performance sequential reads of model weights and KV cache data but lower write performance. The tremendous scale of such workloads requires a new memory class as HBM’s energy per bit read is too high and HBM is “expensive and has significant yield challenges” anyway.
The Microsoft researchers say their theorized MRM “is different from volatile DRAM as it can retain data without power and does not waste energy in frequent cell refreshes, but unlike SCM, is not aimed at long term retention times. As most of the inference data does not need to be persisted, retention can be relaxed to days or hours. In return, MRM has better endurance and aims to outperform DRAM (and HBM) on the key metrics such as read throughput, energy efficiency, and capacity.”
They note: “Byte addressability is not required, because IO is large and sequential,” suggesting that a block-addressed structure would suffice.
The researchers are defining in theory a new class of memory, saying there is an AI foundation model-specific gap in the memory-storage hierarchy that could be filled with an appropriate semiconductor technology. This “opens a field of computer architecture research in better memory for this application.”
Endurance requirements for KV cache and model weights vs endurance of memory technologies
A chart (above) in the paper “shows a comparison between endurance of existing memory/storage technologies and the workload endurance requirements. When applicable, we differentiate endurance observed in existing devices from the potential demonstrated by the technology.” Endurance is the length of time over which write cycles can be continued. “HBM is vastly over-provisioned on endurance, and existing SCM devices do not meet the endurance requirements but the underlying technologies have the potential to do so.”
The Microsoft researchers say: “We are explicitly not settling on a specific technology, instead highlighting an opportunity space. This is a call for action for those working on low-level memory cell technologies, through those thinking of memory controllers, to those designing the software systems that access the memory. Hail to a cross-layer collaboration for better memory in the AI era.”
They conclude: ”We propose a new class of memory that can co-exist with HBM, Managed-Retention Memory (MRM), which enables the use of memory technologies originally proposed for SCM, but trades retention and other metrics like write throughput for improved performance metrics crucial for these AI workloads. By relaxing retention time requirements, MRM can potentially enable existing proposed SCM technologies to offer better read throughput, energy efficiency, and density. We hope this paper really opens new thinking about innovation in memory cell technologies and memory chip design, tailored specifically to the needs of AI inference clusters.”
Observability and data management supplier Apica announced a Freemium version of its Ascent offering, providing free access to an enterprise-grade telemetry pipeline and intelligent observability, processing up to 1 TB/month of logs, metrics, traces, events, and alerts. Ascent is designed to help organizations centrally manage and automate their telemetry data workflows and gain insights from their data. It supports OpenTelemetry. Ascent Freemium users can upgrade to paid tiers as their needs evolve.
CTO/CPO Ranjan Parthasarathy said: “With Ascent Freemium, we offer a comprehensive platform that consolidates telemetry data management and observability, while leveraging AI/ML workflows and built-in AI agents to significantly reduce troubleshooting time.” Sign up here.
…
Data orchestrator and manager Hammerspace is a finalist in three major categories at theCUBE Technology Innovation Awards: “Most Innovative Tech Startup Leaders” for CEO and co-founder David Flynn, the “HyperCUBEd Innovation Award – Private Company,” and “Top Data Storage Innovation.” Winners will be announced on February 18. The Most Innovative Tech Startup Leaders honors exceptional individuals from a B2B tech company who have significantly advanced the industry through groundbreaking ideas, leadership, and execution.
…
In-memory grid provider Hazelcast has joined the STAC Benchmark Council.
…
On-prem, hybrid, public cloud, and SaaS app data protector HYCU is now a Dell Technologies Extended Technologies Complete (ETC) program member, one of only two data protection providers to be a member. The other is Druva. There is more information in CEO Simon Taylor’s blog post.
…
HYCU R-Cloud was named a winner in the annual TechTarget Storage Products of the Year Awards. It won Bronze in the Backup and Disaster Recovery Hardware Software and Services Category in the 23rd Annual Awards edition of the TechTarget Storage Products of the Year.
…
The IBM Storage Ceph for Beginners document has been updated to v2.0 and includes NVMe-oF Gateway and native SMB protocol support. NVMe-oF Gateway is said to be ideal for VMware and other high-performance block workloads. Download the document here.
…
Tape backup hardware supplier and service provider MagStor has joined the Active Archive Alliance. Pete Paisley, MagStor’s VP of Business Development, said: “As MagStor has grown to offer increasingly capable tape storage hardware, media, and data services, we seek opportunities to add our voice to the storage archive ecosystem to help customers better solve problems related to AI and exponential data growth at the lowest possible cost.” Active Archive Alliance members and sponsors include Fujifilm, MediQuant, Spectra Logic, Arcitecta, Cerabyte, IBM, Iron Mountain, Overland Tandberg, PoINT Software & Systems, QStar Technologies, Savartus, S2|Data, Western Digital, and XenData.
…
Wedbush analysts told subscribers it believed nearline disk drive sales volumes came in the low to mid 16 million unit range. This result implies an incremental few hundred thousand units for both Seagate and Western Digital. It said: “Generally, we see favorable trends continuing through the next few quarters with industry units likely holding around current levels and ASPs appearing set to lift modestly.”
The flash market was different: “For NAND, we believe the quarter was defined by sharper than expected ASP declines as enterprise demand dipped sharply.” It was due to three factors: continued workdowns in client device OEM SSD and module inventories; a sharp drop in high capacity SSD demand tied to GPU server shipment delays; and a push by hyperscale customers to moderate pricing.
…
Solidigm announced a multi-year extension of its agreement with Broadcom on the use of high-capacity SSD controllers to support AI and data-intensive workloads. Broadcom’s custom controllers have served as a critical component of Solidigm SSDs for more than a decade, with more than 120 million units of Solidigm SSDs shipped featuring Broadcom controllers. The agreement also includes collaboration on Solidigm’s recently announced 122 TB D5-P5336 datacenter SSD, at the time of publication the world’s highest capacity PCIe SSD.
…
SMART Modular announced that its 4-DIMM and 8-DIMM CXL (Compute Express Link) memory Add-in Cards (AICs) have passed CXL 2.0 compliance testing and are now listed on the CXL Consortium’s Integrators’ List.
…
Multi-protocol storage array provider StorONE has added Kubernetes integration to its ONE Enterprise Storage Platform product. It allows all customers to benefit from Kubernetes functionality as part of their existing license, free of charge, after upgrading to the latest version. They gain access to StorONE’s data protection, security, and snapshots in Kubernetes environments. StorONE features like auto-tiering, snapshots, and replication work seamlessly alongside Kubernetes. More information here.
…
TrendForce said a magnitude 6.4 earthquake struck southern Taiwan, with its epicenter in Chiayi, at 12:17 AM local time on January 21. TSMC and UMC’s Tainan fabs, which experienced seismic intensity levels above 4, initiated immediate personnel evacuation and equipment shutdowns for inspections. While no critical equipment damage was reported, unavoidable debris was generated inside furnace equipment. Operations at these facilities began resuming on the morning of January 21, with TrendForce noting that the earthquake’s impact on production appears to be within controllable limits.
Dell is trying to beef up data protection services to customers via its security operations centers (SOCs) in a bid to stop cyber criminals that are targeting backup and restore systems in the datacenter.
It has expanded its managed detection and response (MDR) services through an agreement with CrowdStrike. Dell is now using CrowdStrike’s Falcon Next-Gen SIEM (security incident and event management) as part of its MDR, to “simplify” threat detection and response with a unified platform, “boosting visibility” and helping to prevent breaches.
The combo promises to give enterprises visibility into their infrastructure that’s “not possible with off-the-shelf tools”.
Dell says cyber baddies are increasingly targeting data protection environments first, because they are fundamental to recovering and restoring corrupted data. Currently, many IT security teams rely on the infrastructure to provide system log information to a SIEM tool. But this can create a flood of unprioritized alerts that security teams have to spend significant amounts of time manually reviewing and addressing, adding another layer of complexity to managing infrastructure security, according to Dell.
As an alternative, Dell and CrowdStrike have developed more than 60 unique indicators of compromise (IOCs) tailored specifically for Dell PowerProtect Data Domain and PowerProtect Data Manager. The IOCs are surfaced within Falcon Next-Gen SIEM’s AI-powered detections, ranked by severity, and provide forensics data to Dell security analysts to “accelerate” responses, we’re told.
Examples of the IOCs include disabled multi-factor authentication, login from a public IP address, mass data deletion, and multiple failed login attempts.
Mihir Maniar.
“Extending MDR to cover data protection infrastructure and software enhances visibility and proactive threat detection across the environment, providing exceptional protection from threats,” said Mihir Maniar, vice president, infrastructure, edge and security services portfolio, Dell Technologies. “Dell and CrowdStrike have developed advanced threat detection capabilities to provide actionable, high-quality data to our security experts. With this expansion, we’ve extended our MDR service to provide end-to-end coverage across IT environments.”
“Falcon Next-Gen SIEM provides Dell MDR with a powerful, foundational new platform to seamlessly ingest rich data backup and protection telemetry, and rapidly detect and respond to threats,” added Daniel Bernard, chief business officer, CrowdStrike. “Together, we look forward to delivering the technology and services that customers need to transform security operations, protect critical data, and stop breaches.”
This isn’t the first time that Dell has integrated its services with third party technologies to boost protection. Dell’s on-premises and in-cloud PowerProtect Cyber Recovery vault products use Index Engines’ CyberSense software to give full content indexing and searchability for ransomware activity. IBM’s Storage Defender product also uses CyberSense software, as does Infinidat’s InfiniSafe Cyber Detection.
Last year, both Rubrik and Cohesity announced service integration deals with CrowdStrike to improve their threat protection offer to customers.
Dell MDR services are currently available in 75 countries.
Edge hyperconverged infrastructure player Scale Computing is claiming strong annual growth for its solutions across the market.
The company, which is privately-owned so B&F has no way of verifying its financial results, said it saw a hike in software sales of over 45 percent year-on-year in 2024, and “more than doubled” its number of new customers. In the fourth quarter of the year, the business said software sales jumped 77 percent, and new logos were up 350 percent compared to the last quarter of 2023.
Scale Computing chose not to reveal its actual dollar sales, nor its profit figures.
Regarding overall growth, it claimed customers were increasingly seeing Scale as an alternative virtualization option to VMware, as businesses and the channel wrestle with licensing and support changes since Broadcom acquired VMware in 2023. It added that AI inference solutions were also driving sales.
Jeff Ready
“We currently see an unprecedented opportunity to enable the best outcomes for our customers and partners as they navigate the industry disruption caused by Broadcom and VMware,” Jeff Ready, CEO and co-founder of Scale Computing said in a statement. “Scale Computing Platform (SC//Platform) provides a major upgrade to VMware by providing a hypervisor alternative, while simultaneously enabling edge computing and AI inference at the edge. Our partners and customers get a two-for-one: a solution to today’s Broadcom problem, and a technology roadmap into the future of edge and AI.”
While not revealing the value, Ready claimed the firm was seeing “record profitability” on “record demand.”
The company claims that SC//Platform reduces downtime “by up to 90 percent” and “decreases total costs by up to 40 percent” compared to VMware, through “simpler” management, integrated backup and disaster recovery, built-in “high availability,” and “effortless scalability.”
In Q4, Scale Computing launched the SC//Fast Track Partner Promotion, offering new resellers a free hyperconverged edge computing system to experience the company’s technology. It also announced a new agreement with 10ZiG to provide “managed, secure, and flexible” virtual desktop infrastructure (VDI) by combining 10ZiG’s hardware and software tech with SC//Platform.
Open source vector database supplier Qdrant says it can use GPUs to calculate vector indices ten times faster than x86 CPUs.
A vector database holds vector embeddings, encoded tokens mathematically calculated from segments of text phrases, audio, image, and video streams, which large language models (LLMs) search when generating responses to users’ natural language requests. The search looks for items that are close to the search item in a vector space. There must be an index of vector embeddings for the search to take place. Building this index can become computationally intensive as the item count scales into the billions and beyond. Qdrant has enabled AMD, Intel, and Nvidia GPUs to be used to build such indices on its latest v1.13 software release.
Andrey Vasnetsov
Qdrant CTO and co-founder Andrey Vasnetsov stated: “Index building is often a bottleneck for scaling vector search applications. By introducing platform-independent GPU acceleration, we’ve made it faster and more cost-effective to build indices for billions of vectors while giving users the flexibility to choose the hardware that best suits their needs.”
The company bases its indexing technology on HNSW (Hierarchical Navigable Small World), an algorithm using a graph-based approximate nearest neighbor search technique used in many vector databases. A blog by David Myriel, Qdrant’s Director of Developer Relations, states that Qdrant developed this software in-house rather than using third-party code.
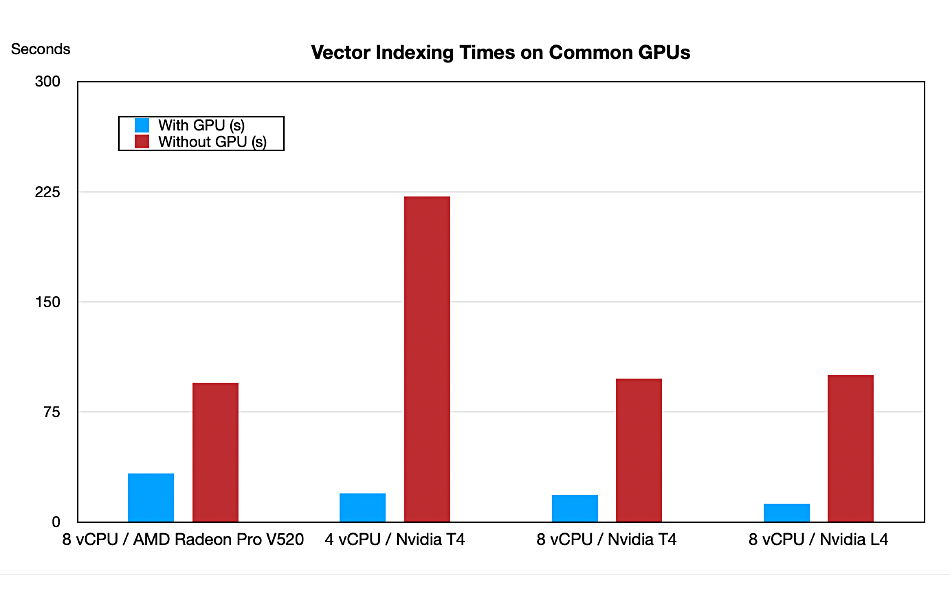
He says: “Qdrant doesn’t require high-end GPUs to achieve significant performance improvements,” and supplies a table showing indexing times and costs with and without using various common GPUs:
Quoted prices are from Google Cloud Platform. We don’t know the configuration of the without-GPU servers
Below is a chart visualizing the table’s two timing columns for clearer comparison:
The v1.13 release also includes:
Strict Mode to limit computationally intensive operations like unindexed filtering, batch sizes, and certain search parameters. It helps make multi-tenancy work better.
HNSW Graph Compression to reduce storage use via HNSW Delta Encoding by storing only the differences (or “deltas”) between values.
Named Vector Filtering for when you store multiple vectors of different sizes and types in a single data point. The blog says: “This makes it easy to search for points based on the presence of specific vectors. For example, if your collection includes image and text vectors, you can filter for points that only have the image vector defined.”
Custom Storage – using a custom storage backend instead of RocksDB to prevent random latency-increasing compaction spikes, ensuring consistent performance by requiring a constant number of disk operations for reads and writes, regardless of data size.
Qdrant says this release creates new possibilities for AI-powered applications – such as live search, personalized recommendations, and AI agents – that demand real-time responsiveness, frequent reindexing, and the ability to make immediate decisions on dynamic data streams.
There have been more than 10 million installs of its vector database.
Vector database startup Pinecone has launched Pinecone Assistant, an AI agent-building API service to speed RAG development.
Large and small generative AI language models (LLMs) generate their responses by looking for similarities to a request using mathematically encoded representations of an item’s many aspects or dimensions, known as vector embeddings. These are stored in a database with facilities for search. AI agents are used to provide automated intelligent responses to text input and can invoke LLMs to do their work. The LLM provides natural language processing capabilities to an agent, enabling it to interact with users in a human-like manner, understand complex queries, and generate detailed responses. Pinecone Assistant is designed to help build AI agents.
The company says: “Pinecone Assistant is an API service built to power grounded chat and agent-based applications with precision and ease.” The business claims it abstracts away the chunking, embedding, file storage, query planning, vector search, model orchestration, reranking, and more steps needed to build retrieval-augmented generation (RAG) applications.
Pinecone Assistant includes:
Optimized interfaces with new chat and context APIs for agent-based applications
Custom instructions to tailor your assistant’s behavior and responses to specific use cases or requirements
New input and output formats, now supporting JSON, .md, .docx, PDF, and .txt files
Region control with options to build in the EU or US
There is an Evaluation API and a Chat API that “delivers structured, grounded responses with citations in a few simple steps. It supports both streaming and batch modes, allowing citations to be presented in real time or added to the final output.”
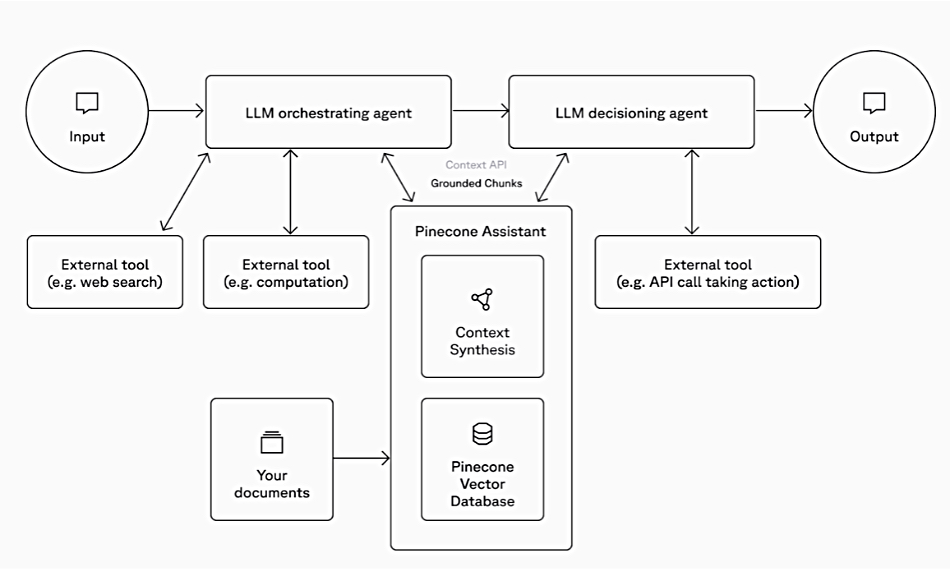
There is also a Context API that delivers structured context (i.e. a collection of the most relevant data for the input query) as a set of expanded chunks with relevancy scores and references. Pinecone says this makes it a powerful tool for agentic workflows, providing the necessary context to verify source data, prevent hallucinations, and identify the most relevant data for generating precise, reliable responses.
Pinecone Assistant Context API diagram
The Context API can be used with a customer’s preferred LLM, combined with other data sources, or integrated into agentic workflows as the core knowledge layer.
The Pinecone Assistant includes metadata filters to restrict vector search by user, group, or category, and also custom instructions so users can tailor responses by providing short descriptions or directives. For example, you can set your assistant to act as a legal expert for authoritative answers or as a customer support agent for troubleshooting and user assistance.
It has a serverless architecture, an intuitive interface, and a built-in evaluation and benchmarking framework. Pinecone says it’s easy to get started as you “just upload your raw files via a simple API,” and it’s quick to experiment and iterate.
Pinecone estimates in its own benchmark that Pinecone Assistant delivers results up to 12 percent more accurate than those of OpenAI assistants.
Pinecone Assistant is now generally available in US and EU for all users. with more info’ available here. It is powered by Pinecone’s fully managed vector database. The company says that customer data is encrypted at rest and in transit, never used for training, and can be permanently deleted at any time.
High-bandwidth memory demand, fueled by AI-focused GPU servers, has propelled SK hynix revenues and net income to record highs for the fourth 2024 quarter and full year.
The company reported ₩19.76 trillion ($13.76 billion) in preliminary revenues for the quarter, 74.7 percent higher year-on-year, with a net profit of ₩8 trillion ($5.56 billion), markedly contrasting with the year-ago ₩1.38 trillion ($960 million) loss. The full 2024 year numbers were remarkable too, with revenues of ₩66.19 trillion ($45.97 billion), up 49.5 percent, and a vast turnaround from the year-ago ₩9.14 trillion ($6.36 billion) loss to a ₩19.8 trillion ($13.8 billion) net profit. The company’s financial situation has been transformed.
VP and CFO Kim Woohyun stated: “With significantly increased portion of high value-added products, SK hynix has built fundamental to achieve sustainable revenues and profits even in times of market correction.”
The Korean company fabricates both DRAM and NAND chips and produces SSDs using its own NAND chips. The high-bandwidth memory (HBM) side of its DRAM operation exhibited “high growth,” the company said, and now accounts for more than 40 percent of its total DRAM revenue. It’s reported that SK hynix’s HBM 2024 revenue increased by more than 4.5 times over 2023. The company pointed out that “the memory sector is being transformed into a high-performance, high-quality market with [the] growth of AI memory demand.”
It also saw a 300 percent increase in eSSD sales in 2024 due to strong demand from datacenters.
A look at SK hynix’s successive quarterly revenues shows five quarters of solidly increasing revenues up to record levels:
Profits have also risen strongly from the late 2023-2024 slump and there have been seven successive quarters of revenue rises:
The annual revenue picture shows that SK hynix is now almost four times larger in terms of revenue than it was in 2016, and it has rebounded from the 2023 memory trough with much increased revenues and profit.
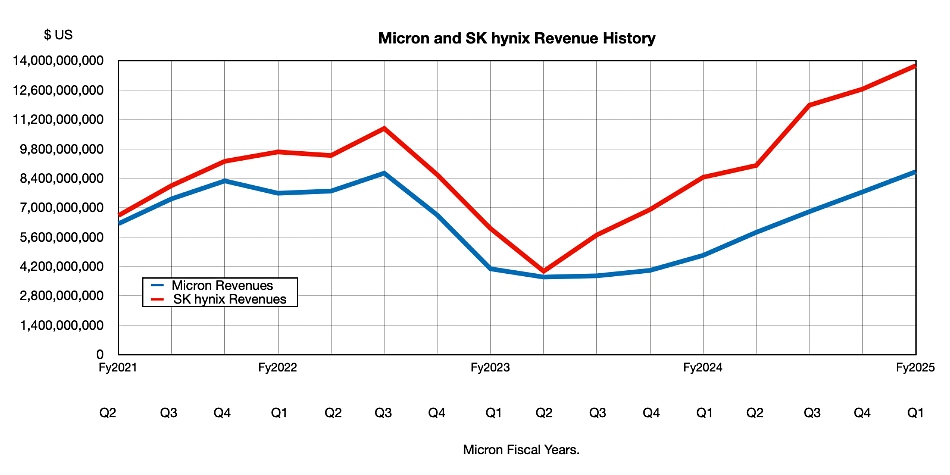
How does it compare to US competitor Micron, which also produces DRAM and NAND chips and SSDs?
The chart has been normalized to Micron fiscal years. It shows that SK hynix has grown faster than Micron after Q2 2023, most likely due to its dominance in the HBM market. Micron has revealed that it’s hoping to achieve an eventual 20 percent share of the HBM market, with CEO Sanjay Mehrotra saying: “Our HBM is sold out for calendar 2025, with pricing already determined for this time frame. In fiscal 2025, we expect to generate multiple billions of dollars of HBM revenue.”
We can conclude that Micron has a less than 20 percent share currently, meaning we might expect HBM revenues to be under half those of SK hynix, judging by publicly available information.
The Korean company “forecasts that the demand for HBM and high-density server DRAM, which is essential in high performance computing, will continue to increase as the global big tech companies’ investment in AI servers grows and AI inference technology gains importance.” The Korean Times reports that SK hynix expects its HBM sales to double in 2025.
It plans to expand current HBM3E production, with an earnings call comment saying: “Within the first half of this year, HBM3E will account for more than half of our HBM … And also, we believe 12-layer HBM4 will be our flagship product in 2026, and will finish developing and mass-producing 12-layer HBM4 this year, so that we can deliver it to customers on schedule … We aim to complete the development and preparation for mass production of HBM4 in the second half of this year and begin supplying them … The HBM4 supply will start with 12-layer chips and followed by 16-layer. The 16-layer chips are expected to be delivered in line with customer demands, likely in the second half of 2026.”
The company sees that sales of AI-equipped smartphones and PCs should expand, driving its sales into the consumer market higher in the second half of 2025.
SK hynix is so profitable that it has lowered its debt by ₩ 6.8 trillion ($4.73 billion) to ₩22.7 trillion ($15.8 billion) compared to the end of 2023, “leading to a significant improvement in the debt ratio and net debt ratio to 31 percent and 12 percent respectively.” The company has also raised the annual fixed dividend by 25 percent to ₩1,500 ($1.04) per share share and has decided to put aside 5 percent of its free cash flow, which was formerly included in the dividend payouts, to enhance its financial structure.
Unless the AI boom stops soon, SK hynix appears set for continued quarterly revenue rises throughout 2025.
Italian healthcare organization ASL CN1 Cuneo has begun using DS3 geo-distributed storage from Cubbit for its S3 backup, saying this has helped with compliance issues and cut costs.
DS3 Composer software enables the construction of sovereign networks of decentralized S3 object storage nodes by MSPs and other organizations. Cubbit is an Italian startup providing DS3 geo-distributed, partially decentralized storage (Web3) that takes advantage of idle storage capacity in existing datacenters. A centralized Coordinator component manages metadata, S3 gateways, and clusters or Swarms of storage nodes. Customers can use DS3 Composer software to build their own decentralized storage capability which satisfies local regulations.
In this instance ASL CN1 Cuneo – Cuneo for short – manages healthcare services across 173 municipalities in Northern Italy, employing over 3,500 staff. Some 80 percent of its data is health-related and classified as “critical” by the Italian National Cybersecurity Agency (ACN). That means Cuneo has to comply with GDPR and NIS2 data sovereignty requirements, security guidelines, and Italian public sector ACN certification. DS3 enables that by locating the storage nodes in Italy.
Andrea Saglietti
Andrea Saglietti, Head of Innovation and Information Security at ASL CN1 Cuneo, stated: “Finding a storage solution that met our strict compliance needs, elevated our security to NIS2 standards, and cut costs was no easy task. We’ve used US-based cloud storage providers for a long time, but they didn’t offer the sovereignty, resilience, or economic advantages that can be achieved with Cubbit.”
Cuneo protects its data using Veeam and has a 3-2-1-1-0 backup strategy requiring offsite and immutable copies of data, 110 TB of backup data in this case. It had been storing it in an AWS S3 object store, which came with egress costs and API call fees and thus increased expenses. It considered using its own data center instead, which offered control and compliance, but didn’t like the high upfront costs, additional IT resources, and ongoing maintenance.
DS3 offered better economics than S3, cloud flexibility, sovereign data control, and compliance.
Saglietti claims that using Cubbit “has enabled us to generate 50 percent savings on previous costs for the equivalent configuration. The speed of deployment and ease of use make Cubbit’s DS3 far more manageable than complex on-prem systems, while maintaining sovereignty and giving us full control over our data. Today, we have greater peace of mind knowing our data is stored securely, compliantly, and cost-effectively.”
Alessandro Cillario
Alessandro Cillario, co-CEO and co-founder of Cubbit said, “Healthcare organizations in Europe must navigate a dense framework of regulatory requirements while grappling with surging data volumes and sophisticated cyber-threats. With Cubbit, ASL CN1 Cuneo can ensure that its critical healthcare data is safeguarded, compliant, and cost-efficient – without the unpredictability of hidden fees or the burdens of on-prem infrastructure.”
Cubbit’s technology has been adopted by 400+ European companies and partners, including Leonardo, and supported by Exclusive Networks. Cubbit is also supported by international tech partners such as HPE and Equinix.
Interview. Blocks & Files sat down with Jason Hardy, Hitachi Vantara Vice President and CTO for AI, to discuss the company’s ongoing storage strategy refresh and how it’s unifying its high-end, mainframe-class enterprise block storage with a broadening VSP One mid-range line. The conversation also covered Hitachi Vantara’s embrace of all-flash alongside disk-focused storage, its hybrid on-premises/public cloud approach, evolving business models, and the rise of generative AI.
Blocks & Files: Hitachi Vantara is now back to its roots as a really solid enterprise storage array provider with a VSP One branding over everything. What’s the strategy going forward?
Jason Hardy: The strategy is simplifying our portfolio and modernizing it so that we can address software-defined and how all of our customers are demanding that we step into some modern approaches and that’s what we’re doing with the portfolio – while still not forgetting about our roots of being world-class, being stable as the most stable platform on the market. Having all the guarantees that we wrapped around it and evolving those and just not forgetting who we were. So going back to building, as you said, a damn fine product.
Jason Hardy
Blocks & Files: HPE just put out a release saying they’ve had an XP8 (OEM’d Hitachi Vantara VSP) array running for ten years without a stop.
Jason Hardy: Don’t doubt it. It just keeps going. It’s like the Energizer bunny.
Blocks & Files: Yet you look for the XP87 array on HP’s website and it’s hard to find.
Jason Hardy: It’s not just been forgetting who we are. Japan is closer in with us now. So we’ve incorporated the Japan product engineering group into this. We are operating as a more cohesive organization. There’s a single product engineering and management group. We always had a single product engineering group, but they were not directly tied in and now it’s all under Octavian Tanase’s umbrella. It’s going back to saying, listen, we can’t forget about what we’re trying to accomplish here.
Blocks & Files: How many customers does Hitachi Vantara have?
Jason Hardy: Last count on our Rolodex is still over 15,000 customers.
Blocks & Files: VAST Data has come along, file and not block, but still very enterprise. HPE has, I think, stumbled a little bit. It’s trying to simplify its product range, but at the moment Alletra is a simple brand of radically different products as far as I can see. HPE hasn’t unified the actual array hardware underneath at all. It’s possibly beginning to happen. NetApp pretty much stayed where it is. It’s got rid of SolidFire. StorageGRID is there, but basically it’s ONTAP forever. There’s Dell with PowerMax and IBM’s Flash System and DS8000. The DS8000 is basically a mainframe array and IBM doesn’t seem to want new customers.
Jason Hardy: One of the two out there.
Blocks & Files: And there seemed to be no moves to combine DS8000 and FlashSystem under one sort of branding or combine the hardware or anything like that. So in a way, you are like the old enterprise storage guard, restructuring yourself after VAST Data and Infinidat have come along, and so forth. Is that accurate?
Jason Hardy: I would say that’s accurate, yeah. I mean that these brands have created niches for themselves to operate inside of and created new ways of doing things that align with their product strategy. And we too are doing that. We are creating the VSP One portfolio, consolidating everything, bringing in a unified management and soon a unified data plane around it. We’re doing a lot to move into simplifying our portfolio while still being, again, those very robust features to provide block, file, and object, and how that all can cooperate and work together. And then being able to ultimately provide the outcomes that our customers need to support their traditional workloads from mainframe into OLTP and into that structured space. Now they’re evolving into the AI portfolio and we’re powering and supporting a lot of the AI work demand coming in.
Blocks & Files: There’s block and file and object in Hitachi Vantara’s product line. Are those three environments being brought more closely together? How is that going to happen?
Jason Hardy: Under VSP One, that’s what we’re doing now. So VSP One Block is where we started, which was the rebranding of the VSP portfolio. VSP One File is now bringing and unifying the file capabilities and management and, again, the data plane side of it to simplify and to bring them together, and then object. VSP One Object was announced [in November] to do the exact same thing.
Blocks & Files: I could think possibly of a single management plane above three silos: block, file, and object. Will you be able to move data between them?
Jason Hardy: Yes. And that’s what we’re doing a lot. Imagine file to object might be straightforward, block – still just let it operate. Now if we look at it from, and this goes to the rest of our portfolio, we have Pentaho* still. We have content intelligence. Some of these key products allow us to look inside the block ecosystem and say, “Hey, we can extract some of this data out and move it to something that’s more appropriate.”
And we’re doing that with some partner technologies as well. Suppose we have an Oracle environment. How can we do that? We can do that through Pentaho and our tooling and then bring that across and transform that into something that’s object-oriented. So that’s where, depending on what layer at the stack you look, we’ll have a lot of those capabilities to be able to address the evolving data demand from our customers.
Blocks & Files: Where does Hitachi IQ fit in with all this?
Jason Hardy: Hitachi IQ is us addressing the AI market and bringing in these technologies. Because it is compute, software, switching, and storage, it brings in VSP One object for density. It brings in our WEKA IO partnership, the content software for file to drive the demand for the GPU workload, and then to scale it to, again, whatever size required. But then it’s also tapping into VSP One File for source data.
It’s tapping into systems that are operating on the VSP One Block side like Oracle or SQL or whatever it is that’s operating from that more traditional workload, and pulling that data in to provide the point of view and relevance from an AI perspective. It’s a full engineered stack with also practices, frameworks, and blueprints of how to integrate in with the rest of the ecosystem. It has to support the holistic AI output that enterprises are looking at or thinking about.
Blocks & Files: Do you see a need for running any AI-type applications on the arrays themselves? VAST has started making noises about that.
Jason Hardy: Yes. They’ve started to look at how they can incorporate basically like a database on a file system. It’s an interesting idea, an interesting concept. There are some open source capabilities out there that can provide that, and it is something that we’re investigating.
Is there potential in this? We’re always investigating what’s next for us. Blending in that closeness of storage and compute, and confidential computing are all things that we look at, saying what is the potential for that?
But right now we’re focused on VSP One, getting that rock solid, getting that out to market, hitting on what our customers are asking for, getting SDS operational in the cloud, which it is. It’s like evolving that capability out and then driving in the AI space in a separate practice that we’ve created because it is a very specific conversation. But then pulling across all of those pieces that we have inside Vantara and then also pulling across what we have across the rest of the Hitachi ecosystem in the cloud.
Blocks & Files: Would you expect to see the block, file, and the object environments of Hitachi Vantara operating in the cloud so that your customers would have an absolutely seamless and hybrid experience?
Jason Hardy: Yes. I think ultimately we’ll evolve to that. Obviously if we look at VSP One File, it’s FPGA-driven, so it’s a little bit more complicated. However, looking at how we’re evolving file out, absolutely we can do that today, for example, with HCSF – content software for file. It’s very much cloud-aligned and it can utilize object storage and things like that in the cloud, whether it be VSP One object or S3 or something on-prem, or whatever combination thereof. And SDS (software-defined storage), the VSP One block SDS platform is very much capable of operating in the cloud.
Blocks & Files: How do you see Hitachi Vantara using generative AI in the future? For example, one of your customers may have four or five storage admins operating your kit, and I’m looking at them thinking they’re highly intelligent, well-trained people, but do I really want them moving volumes? Should I give them an AI tool so they can specify storage policies to the GenAI, which then initiates it, does its thing behind the scenes. Is that the sort of thing you might be thinking about doing?
Jason Hardy: Absolutely. We’re looking at a lot of options like that. We’re also looking at it from a supportability standpoint. These are things that we’re implementing now, such as how we can just improve on general customer service. We have a ton of information and telemetry. How can we use that to create a better customer service experience through a chat interface, through a localized capability?
Or through whatever that evolves into, but using that to improve on how our customers engage with us directly. And then also evolving that and looking at what the potential is to incorporate that into how it helps them drive from a manageability standpoint. What’s the automation that we can do? How can we bring in that more of a chat-style interface or whatever that evolves into, but having that level of sophistication attached to it.
Blocks & Files: So Hitachi Vantara customer support people could be getting a call saying, my VSP One array is doing something unexpected in the middle of night, whatever it happens to be. They might now use a generative AI interface to go search through Hitachi Vantara documentation to find out. Are you actually doing that now?
Jason Hardy: We’re in the middle of looking at implementing and piloting some of these functionalities, and this comes from a lot of what we’ve built outside of DORA and incorporating big Hitachi capabilities for support. We’ll even drink our own Champagne. These are the same things that we’re also working with our customers directly on to improve on their side of customer support or manufacturing or whatever it is. So it’s much the same as what we take out to the field is also what we’re focusing on internally.
Blocks & Files: Do you have conversations with Hitachi Vantara customers looking two years out, three years out, five years out, about what they would like the technology to do or where they see their needs going?
Jason Hardy: Yes, we have customer council, customer advocacy groups that say, “Hey, this is what we see today.” This is the trend that we’re seeing, whether it’s on the mainframe side or the open system side, or specific application or file or whatever. And we use that to help drive the decisions that we make and to the product as we go along. And, as well as what we observe from the market saying, “Hey, finger to the wind, it’s blowing this direction.” How can we help improve on that and innovate on top of it? Not just be a me-too, but how can we actually improve on what’s being offered to the market for theme A or theme B?
Blocks & Files:Do the customers say to you, we see a world where it’s going to be all flash in future with no disk drives at all, or do they say it’s going to be hybrid?
Jason Hardy: It’s about 50-50 on that, maybe 70-30, kind of in that range. But yes, we have some customers who are strictly flashing their datacenter and others are wanting that density/combination cost of disk drives. That’s why we haven’t given up spinning drives at all but why we are also releasing QLC (4bits/cell NAND). We see that the technology is there and we’ve improved, we’ve evolved our software to best utilize that as well.
So now we are meeting at that point where now we can take it to the market and still give our customers that reliability and everything that they come to expect from us with a technology like QLC.
Blocks & Files: From a technology perspective, do you see a need for really high-capacity QLC drives? Beyond 60 TB?
Jason Hardy: Absolutely. We’re already starting to see the trends that we’re going to be moving into 100-plus terabyte per drive. So I think we are still in the middle of a data explosion and AI, I think, is amplifying a lot of that. The density will still be there, but we also can’t trade density for low performance as well. So we need that fine balance. It’ll be the right thing in the right position. It won’t be one size fits all. We’ll still have our TLC (3 bits/cell) offering in some places. We’re still selling storage-class memory options for some of Optane, some other storage-class memory from Kioxia, their FL-class drive. We sell that with our parallel file system because we just need that high churn, high endurance drive.
VSP One object, a perfect example, needs to be super dense, but we want a flash capability now for it. Bringing in QLC to support that at that really high density, that’s a critical thing that we’re working towards. And that was announced with VSP One Object.
Blocks & Files: How about archiving data? What will you say to Hitachi Vantara customers who have a need to archive data. What should they do with it?
Jason Hardy: I think we’re finding that the archive is a more active part, or an active element, in the enterprises today than what it traditionally was. What was tape as an archive is no longer very viable from an active data perspective. In some cases, though, tape might be totally viable for cold, dark data.
I see archive playing more of an active role in the enterprise, but no longer the place where data goes to die. It’s just that next level of how data is interacted with. One can argue even an application that’s designed to use S3 directly is archiving in place because of the nature of how object storage provides that functionality.
It’s going to be the nature of the application and how it’s utilizing the underpinning storage that changes the definition almost of what is archive, and how am I treating this data? Am I archiving in place while still being active participant in how I’m using that data? Things like that. It’s a bit of an evolving theme.
Tape has been pushed down the storage hierarchy for data where we’ve got to keep it, but we’re not going to access it very much at all. But it’s got to be there. And we’ve got this new, more active archival layer of data which extends from object storage through to that, or even into the cloud and be a broker for that. And then it will use the cloud’s colder technologies. So there are a lot of options out there for archiving, and this is where having a proper data management strategy comes into play so that you’re using the right technology for the ultimate enterprise goal.
Blocks & Files: So, in a way, you can adopt particular archiving technologies as customers need them without pinning stacks and stacks of budget into developing a particular archive product that may not have a general need.
Jason Hardy: If you look at S3, it is a great example of how that enables some of these technologies. So if I have an S3 endpoint I can do tiering, I can do that integration.
Blocks & Files: It’s an abstraction layer of different hardware.
Jason Hardy: Exactly. And it’s much of what we’ve been doing already. So it’s not earth-shattering or anything like that. This has been a practice of ours since HCP (Hitachi Content Platform) adopted cloud as a tiering target.
Blocks & Files: Hitachi Vantara has erected its defenses against encroaching technologies from other people. You’re now on a par with NetApp with HPE. What’s the way forward? Would you be looking to sell to new customers or sell to new application areas within existing customers?
Jason Hardy: I think it’s both. We have a very loyal customer base. We love our customers. And they have an evolving enterprise need. Their enterprise ecosystem is not stagnant. So it’s having the right products. This is why Hitachi IQ is so relevant. It’s how to address that with our very loyal customer base.
But then also using that in combination of the VSP One simplification, our new mid-range block platforms and everything that we’re doing in there to address new markets as well. Being more partner-friendly now, having a complete reset of our partner engagement and really creating a product that helps them drive into that business from a channel and commercial business perspective, that kind of that area.
And then being able to still address the top end with the 5600 and our highest-end solutions and evolving that out. Being able to address, again, the unstructured side, and hybrid is big. So how are we supporting our customers hybrid ecosystems? Most of our customers operate in a hybrid ecosystem, and that’s why one of our main pillars is that hybrid solution being the number one hybrid solution provider out there.
We want to be supporting our customer’s data journey of what they’re deeming necessary to support their business.
Blocks & Files: Hitachi Vantara has no particular view about whether on-prem should basically be a ramp to the cloud or whether cloud applications should be repatriated on-prem. You are agnostic to this. You’ll support both.
Jason Hardy: We support both. And we support data movement in either direction, and we support even the retooling of applications into the cloud if necessary. Or taking our on-prem offer and wrapping it in an opex that allows for them to have that cloud-level consumption. With an on-prem technology, it’s up to our customers to make that decision. Now we will guide them, we will give them our best practices and our point of view on it, but ultimately that’s their decision. So we don’t want to alienate our customers if they make a decision one way or another.
It’s more about, all right, you’re stepping into this direction, great, how can we support you along the way? And then, hey, do you want to shift it over to the right a little bit or a left a little bit? It’s moving target; we will help you in that entire process.
Blocks & Files: All in all, you’re having a heck of a time?
Jason Hardy: I love my job. I love this company. I mean, I’ve been here long enough, but honestly, what (CEO Sheila Rohra) and Octavian and the whole new leadership regime have brought in has been this injection of energy and it’s like, all right, let’s innovate. Let’s go out and let’s do some amazing things together. So it’s been fantastic.
Bootnote
*Pentaho is Hitachi Vantara’s data integration, analytics, and business intelligence (BI) platform. It provides tools and capabilities to help organizations manage, process, analyze, and visualize data from diverse sources. Hitachi Vantara says Pentaho is particularly well-suited for building scalable data pipelines and supporting decision-making through data-driven insights.
Cloud providers purchased more high-capacity disk drives in Q4 2024, pushing Seagate revenues up nearly 50 percent.
Seagate revenues rose to $2.33 billion in its second fiscal 2025 quarter, which ended December 27, from $1.55 billion a year ago. The company reported a $336 million GAAP profit, marking a significant turnaround from a $19 million loss in the prior year. Investors were less than pleased with its forecasts for the upcoming third quarter, however. The drive maker says that it expects around $2.10 billion for Q3, compared with analysts’ average estimates of $2.19 billion, according to Reuters.
Dave Mosley
CEO Dave Mosley stated: “Seagate ended calendar 2024 on a strong note as we grew revenue, gross margin, and non-GAAP EPS successively in each quarter of the year. Our results demonstrate structural improvements in the business and our focus on value capture in an improving demand environment, highlighted by decade-high gross margin performance exiting the December quarter.”
“Our performance was supported by increased demand across nearly all markets we serve with the most significant growth in the cloud sector. This broad-based demand from global cloud customers led to an almost doubling of nearline product revenue in the December quarter on a year-on-year basis and close to 60 percent nearline revenue growth for the entire calendar year.”
“Overall, Seagate is in an outstanding competitive and technology position in a strengthening demand environment.”
Production of the company’s 24 TB CMR and 28 TB SMR drives is ramping quickly and the duo represent Seagate’s highest revenue and exabyte production platform.
Financial summary
Gross margin: 34.9 percent vs 23.3 percent last year
Operating cash flow: $221 million
Free cash flow: $150 million vs $27 million in previous quarter
Diluted EPS: $2.03 vs $0.12 a year ago
Dividend: $0.72/share
Cash & cash equivalents: $1.23 billion vs $787 million a year ago
However, it faced a production issue affecting non-HAMR drives, which has now been resolved. This led to supply constraints for the upcoming March quarter. CFO Gianluca Romano said in the earnings call: “We did not start enough material in a certain period of time because we didn’t put back the equipment that [was] necessary to produce that materials. So we don’t have that level of supply that could have been necessary to match demand in the March quarter (Q3 2025).”
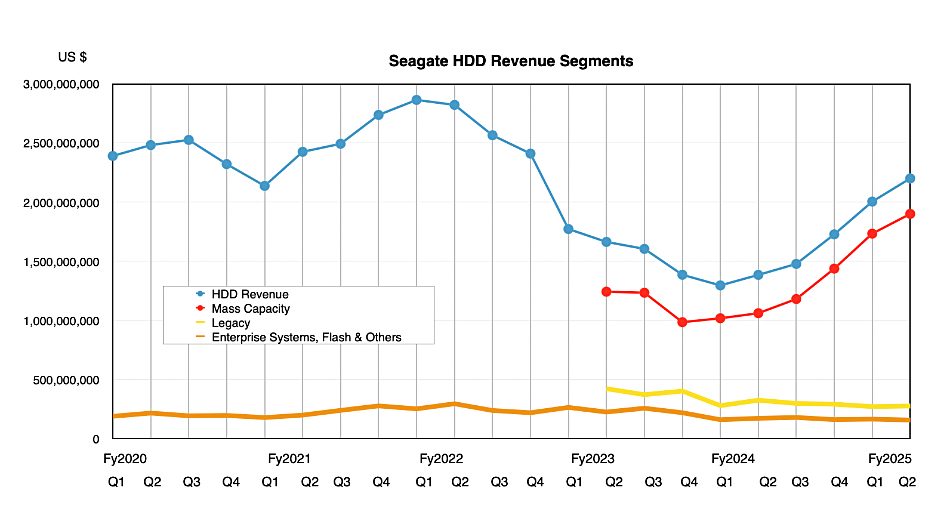
The final 2024 and 2025 figures reflect three quarters of accelerating growth, emerging from a revenue trough in 2023 and early 2024
The proportion of mass-capacity nearline drives continues to rise as other market segments languish:
Mosley highlighted an AI-led future, stating: “We expect GenAI to drive future mass capacity storage growth. This is particularly true of data-rich imagery and video content created by GenAI models, which is projected to expand nearly 170 times from 2024 through 2028.”
Disk drives will be needed because “HDDs play a crucial role in housing the massive data sets required for training AI models, serving as central repositories when these data sets are not actively being processed by GPUs. These mass storage data lakes form the backbone of trustworthy AI by storing checkpoints or snapshots of AI model data sets, ensuring that data is both retained and available in the future for continuous model refinement.”
“We expect enterprises to replicate and store more data locally at the edge as AI computing and inferencing moves closer to the source of data generation. VIA is another opportunity-rich market at the edge. For some time now, we’ve spoken about the increased adoption of AI analytics within the VIA markets, which help form actionable insights from data for applications such as smart cities and smart factories.”
HAMR technology drive qualifications are progressing, with Mosley saying: “There are now multiple customers qualified on this platform across each of the mass capacity end markets. Currently, we are ramping volume to our lead CSP customer while progressing on qualifications at additional cloud and hyperscale customers. These qualifications will set the foundation for the next phase of our Mosaic volume ramp starting in the second half of calendar 2025.”
Seagate plans to rely on HAMR technology’s areal density improvements to increase capacity, without needing to add an extra platter to its ten-platter products. Rival Western Digital now has 11-platter drives.
SSDs and HDDs will coexist. “Datacenter architects will continue to adopt both hard disk drive storage and compute-oriented memory technologies such as NAND flash to support the breadth of their workloads. NAND is best suited for high throughput, low latency tasks, while hard disk drives remain the preferred storage solution for the bulk of data storage needed in the cloud.”
Mosley asserted: “HDDs offer customers at least 6x lower cost per terabyte of storage capacity. They possess a significantly smaller embodied carbon footprint and provide manufacturing scale that is highly capital-efficient.”
The outlook for next quarter projects a sequential revenue decline to $2.1 billion +/- $150 million, representing a 26.9 percent increase compared to the year-ago Q3 at the midpoint.