


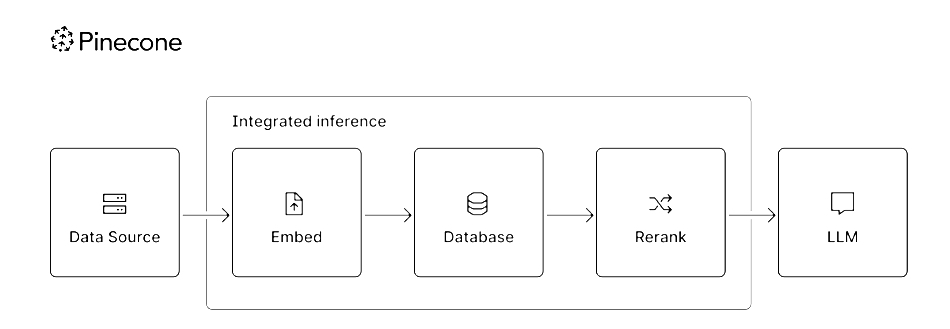
GenAI inferencing can now be run directly from the Pinecone vector database to improve retrieval-augmented generation (RAG).
Pinecone supplies a vector embedding database to be used by AI language models when building responses to chatbot user requests. Vector embeddings are symbolic representations of multiple dimensions of text, image, audio, and video objects used in semantic search by large language models (LLMs) and small language models (SMLs). It says the database now includes fully managed embedding and reranking models, plus a “novel approach” to sparse embedding retrieval alongside its existing dense retrieval features.

Pinecone CEO Edo Liberty, a former research director at AWS and Yahoo, stated: “By adding built-in and fully managed inference capabilities directly into our vector database, as well as new retrieval functionality, we’re not only simplifying the development process but also dramatically improving the performance and accuracy of AI-powered solutions.”
The database, now called a platform, has had these features added:
- pinecone-rerank-v0 proprietary reranking model
- pinecone-sparse-english-v0 proprietary sparse embedding model
- New sparse vector index type
- Integration of Cohere’s Rerank 3.5 model
- New security features, including role-based access controls (RBAC), audit logs, customer-managed encryption keys (CMEK), and general availability of Private Endpoints for AWS PrivateLink
Dense retrieval, employed by GenAI’s language models during semantic searches against vector databases, utilizes all relevant vectors. Sparse retrieval is a keyword search method where only specific words and terms are vectorized, while all other dimensions in the vector embeddings are assigned a zero value. The keywords can be represented as sparse vectors, with each keyword corresponding to a dimension in the vector space.
The company said it has collaborated with Cohere to host Cohere Rerank 3.5 natively within the Pinecone platform, and it can be selected through the Pinecone API. It says Rerank 3.5 excels at understanding complex business information across languages making it optimal for global organizations in sectors like finance, healthcare, the public sector, and more.
Pinecone says its new proprietary reranking and embedding models, along with third-party models like Cohere’s Rerank 3.5, provide customers with “quick, easy access to high-quality retrieval.” These enhancements significantly streamline the development of grounded AI applications.
“Grounded” means less likely to hallucinate or generate imaginary responses.
The company says its research shows that the best performance from GenAI models requires combining three key components:
- Dense vector retrieval to capture deep semantic similarities
- Fast and precise sparse retrieval for keyword and entity search using a proprietary sparse indexing algorithm
- Best-in-class reranking models to combine dense and sparse results and maximize relevance
A reranking model takes a first response from an information retrieval pipeline and reorders (re-ranks) the listed entries to help ensure the more relevant ones are ranked higher to improve retrieval effectiveness.
Pinecone claims that, by combining the sparse retrieval, dense retrieval, and reranking capabilities within its database, “developers will be able to create end-to-end retrieval systems that deliver up to 48 percent and on average 24 percent better performance than dense or sparse retrieval alone.” It says:
- pinecone-rerank-v0 improves search accuracy by up to 60 percent and on average 9 percent over industry-leading models on the Benchmarking-IR (BEIR) benchmark
- pinecone-sparse-english-v0 boosts performance for keyword-based queries, delivering up to 44 percent and an average of 23 percent better normalized discounted cumulative gain (NDCG@10) than BM25 on Text Retrieval Conference (TREC) Deep Learning Tracks.
Pinecone provides these capabilities, hosted on its infrastructure, via a single API. It says that developers can now develop GenAI retrieval applications “without the burden of managing model hosting, integration, or infrastructure” and “eliminating the need to worry about vectors or data being routed through multiple providers.”
Customers can access Pinecone through the AWS Marketplace.





