Samsung has begun making NAND wafers at its new flash foundry in X’ian, China – on schedule despite the Covid-19 pandemic.
The new plant will manufacture fifth generation Samsung 3D V-NAND, with 90+ layers and a 256Gb die capacity. Samsung is targeting 20,000 wafers per month initially and will increase output to 65,000 wafers.
Samsung’s Xi’an fab
So how many flash memory chips does that equate to? Samsung and other NAND producers typically do not reveal die dimensions as competitors can use this figure to work out their cost. But to give you a very rough idea, 65,000 wafers with about 700 dies per wafer equals 45,500,000 chips per month.
(Samsung’s 48-layer V-NAND has a die size of 99.84mm squared, equivalent to a maximum of 708 dies on a wafer. As 3D NAND layers extend upwards the die count on a wafer should remain fairly consistent around the 700, other things being equal. Also, note that some dies fail testing – so yield per wafer is lower than the theoretical maximum.)
Samsung plans to introduce gen 6 V-NAND in June, still using the 256Gb die and with 100+ layers. A seventh generation will follow, with a 512Gb die utilising 200+ layers.
Samsung makes V-NAND at its Pyeongtaek and Hwaseong foundries in South Korea. Pyeongtaek will “soon” move to gen 6 V-NAND, the company says.
The new Xi’an fab marks the completion of a $7bn investment announced in August 2017. Samsung operates another fab in Xi’an, employing 3,300, which produced its first wafers in 2014. The company plans another investment of $8bn to double output to 130,000 wafers per month. We don’t have timing details.
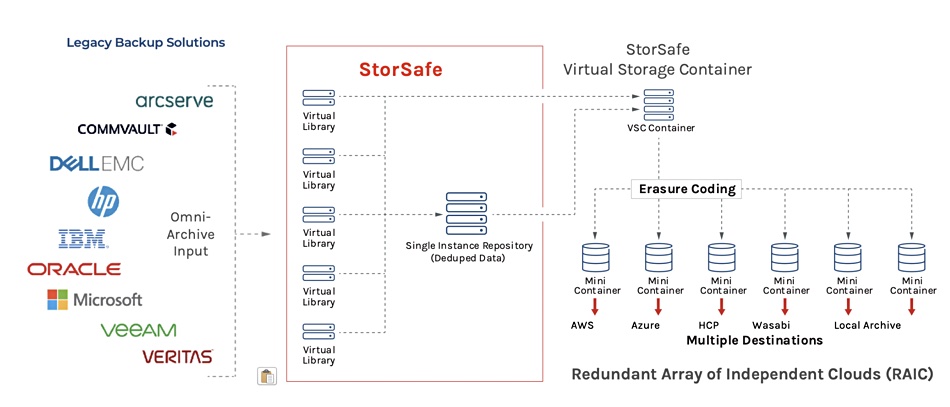
FalconStor has announced StorSafe, a persistent data storage container for enterprises. The software integrates with legacy backup and archive software and processes, and is compatible with cloud- and S3 object-based storage architectures.
In effect this is a virtual container-based archive abstraction layer across the AWS, Azure, and Wasabi clouds, and also the Hitachi Content Platform and other on-premises (S3-compliant) archive stores.
StorSafe diagram
StorSafe uses persistent virtual storage container (VSC) technology which enables disaggregation of the data from the system-level storage component. It features variable payload container storage – deduplication over large storage containers reduces cost and storage capacity consumption, and accelerates data reinstatement from smaller storage containers.
StorSafe archives are portable between public clouds and on-premises systems. The software uses redundant array of independent clouds (RAIC) container distribution via multi-cloud erasure coding. This is claimed to deliver more than 7 nines (99.99999 + per cent) availability, even if a cloud provider goes dark.
Falconstor’s virtual container archive idea is novel. It will be interesting to see how this small enterprise storage supplier develops the technology.
Road to recovery?
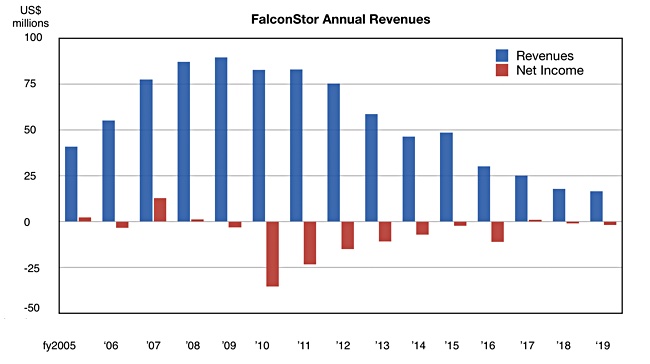
FalconStor revenues peaked in 2009. The company has travelled a rocky road since the founding CEO’s suicide in September 2011.
But last quarter there were encouraging signs and CEO Todd Brooks has more progress to report for 2019’s fourth quarter.
His release quote said: “The strategic decisions we made throughout 2019 to place additional commercial focus on our long-term archive retention and reinstatement product, within our core regions, delivered encouraging growth in those areas throughout 2019, and has created a focused and healthy foundation for continued growth in 2020.”
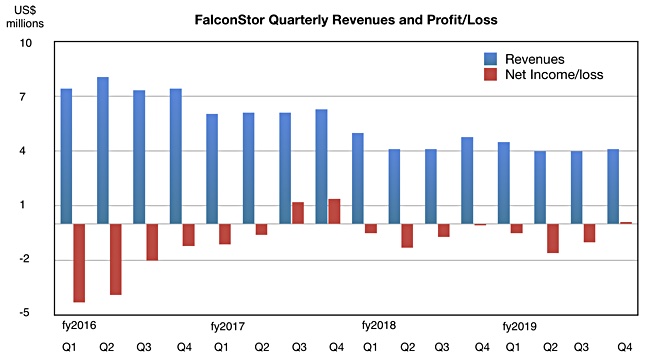
Revenues of $4.1m were down 14.1 per cent on last year’s $4.8m but Falconstor made a profit of $101,590 – its first profit after seven quarters of losses. The turnaround is slight – the year-ago loss was $77,058 – but it is a profit, achieved despite lower revenues.
Full year revenues were $16.5m compared to $17.8 million in 2018, and net loss was $1.75m (2018 – $906,714).
FalconStor’s said the revenue fall in Q4 2019 was due mostly to an intentional decreased commercial focus in China. Operating expenses of $3.3m were 7.1 per cent down on the $3.6m in the year-ago quarter. Cash and cash equivalents of $1.5m were lower than the $3.3m reported a year ago. And Falconstor has executed a 10:1 reverse stock split of its common stock.
On the bright side it reported total year-over-year sales growth of more than six per cent in its core regions, meaning outside China. Sales of its long-term archive retention and reinstatement product grew 38 per cent year on year.
Modern data storage technologies may deliver high speed data access but not all make the cut for the exacting demands of high performance computing (HPC) applications.
Panasas is a niche supplier of high-end storage systems for HPC users. We asked Robert Murphy, director of product marketing, for the company’s views on quad-level cell (QLC) flash; storage-class memory; NVMe-over-Fabrics; multi-actuator disk drives; and shingled write tracks. What technologies get the seal of approval from his HPC customers?
Murphy has some distinctive views and ways of describing technology. For example:
QLC is not a viable storage medium for HPC storage systems,
NVMe-oF is too expensive to deploy at the multi-petabyte capacities HPC customers require
Optane DIMMs do not seem to be good match for HPC use cases
Optane DIMMs are way too small and too expensive for storing HPC user data
Multi-actuator HDDs are equivalent to buying twice as many HDDs that are only half as large
Computational storage is a very cool technology looking for a problem to solve.
Now for our interview, which we conducted by email.
Blocks & Files: How does Panasas view QLC (4bits/cell) flash? Why might this be a viable storage medium for its customers, or not?
Robert Murphy: Panasas does not believe QLC is a viable storage medium for HPC storage system customers. QLC’s biggest disadvantage is its very well-known exceedingly low write endurance that restricts it to heavy read-oriented workloads as found in the consumer device space. QLC is not suited for write-heavy workloads.
HPC storage requires both high performance and high capacity and customers demand an economical price too. HPC workloads are a mix of heavy reads and writes, big files and small files. It’s this demanding combination of performance, capacity and price that drives successful storage media choices for HPC storage. Panasas is agnostic when it comes to storage media selection, we pick the best media that meets the specific use case’s technical and economic requirements.
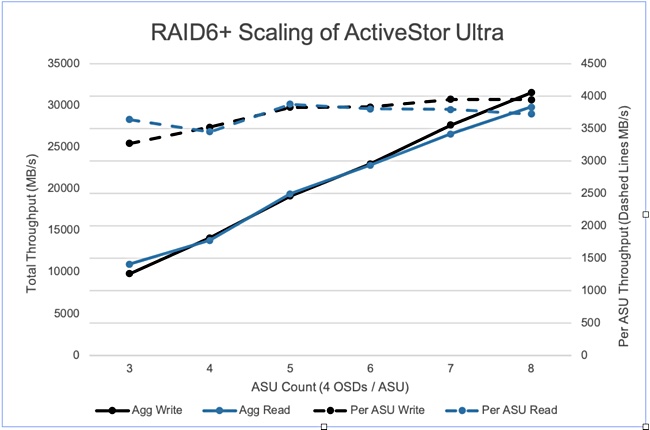
To accommodate this broad range of HPC workloads, PanFS and the ActiveStor Ultra hardware architecture is designed to have a very balanced read:write ratio as shown in the IOR performance diagram below;
The Faustian bargain of low cost versus extreme sensitivity to writes requires very careful solution-level engineering for QLC to have any value in HPC storage where write performance is almost as prized as read performance.
To us, this uneven read:write performance ratio is a non-starter for HPC workloads and as such, Panasas would never use QLC in its HPC storage systems
In addition, there is also the very important question of storage medium economics. Using the QLC-based Vast Data system as an example, a quick survey of internet prices for the 15.36TB QLC SSD device it uses shows the device price hovers around $3,000 – a good deal for nearly 16TB of flash memory. But compare that with the $400 price for a 16TB HDD of the type used on the Panasas ActiveStor Ultra system.
Panasas ActiveStor Ultra system.
Panasas can provide 7.5X the capacity of QLC with HDD technology for the same price – with virtually no endurance risk. And since PanFS is a parallel file system, Panasas ActiveStor Ultra can provide virtually unlimited performance by reading and writing to and from 100s to 1000s of drives in parallel – uniquely to both HDDs for big files, and flash SSDs for small files, with the Panasas Adaptive Small Component Acceleration (ASCA) architecture.
Blocks & Files: How does Panasas view NVMe-over Fabrics (NVMe-oF)? Why might this be a viable data access method for its customers, or not?
Murphy: Panasas is a fan of NVMe-oF. It meets all the requirements of our HPC storage customers, except one: it’s simply too expensive to deploy at the multi-petabyte capacities that HPC customers require.
For example, an 11TB NVMe SSD averages around $4,000 or 14.5X the price per TB compared to the HDDs used in the Panasas ActiveStor Ultra System. Hence, we are currently using NVMe sparingly and where it makes the most sense: to store the metadata in the PanFS database. We are also investigating adding an NVMe-oF tier (Ludicrous Mode) into future PanFS systems.
Blocks & Files: How does Panasas view storage-class memory (SCM – meaning Optane)? Why might this be a viable storage medium for its customers, or not? What role can SCM play in Panasas’ plans?
Murphy: If you’re asking about Optane DIMMs in particular, they do not seem to be good match for our HPC use case.
For transaction logs, we like the latency of the SCM being the same as DRAM, don’t want to worry (at all) about wear in the 100 per cent write workload of a transaction log, and don’t need the large capacities that Optane can offer. As far as using Optane DIMMs to store user data, they are way too small and expensive for that.
Optane DIMM.
While it might make sense architecturally to use large quantities of them to store all the metadata for lower/slower layers in an all-flash storage hierarchy, you’d be pushing the overall solution toward another “DSSD” (Dell EMC’s withdrawn all-flash array of 2017), there simply isn’t a commercially viable market for something that fast and expensive.
PanFS has used NVDIMM Storage Class Memories in our systems for several years now; we use NVDIMM’s to hold our transient transaction logs in our Director Nodes and new ActiveStor Ultra Storage Nodes. The extreme bandwidth and low latency that result from SCM’s being on the CPU’s memory bus is tremendously valuable, but if the SCM is not used in the correct way in the solution’s architecture, the advantages can be hard to obtain.
Blocks & Files: How does Panasas view computational storage? Why might this be a viable technology for its customers, or not?
Murphy: The attraction of computational storage is based upon the idea that the underlying storage devices have more performance than that can be moved over the network, and that there is an advantage to moving the computation to the storage rather than moving the data from the storage across a network to the computation. We believe that the value of disaggregation should not be ignored, and that networking tech has improved to the point that there is no practical limitation on performance from networking, whether bandwidth or latency.
Disaggregation allows sharing of storage capacity and performance across multiple computations, allowing much more flexibility and therefore higher utilization of the available CPUs and GPUs compared to dedicating CPUs to just one storage device (the one they’re embedded within). In addition, the CPUs and GPUs can be chosen, maintained, and upgraded independently from the storage. Under the majority of circumstances, computational storage is a (very) cool technology looking for a problem.
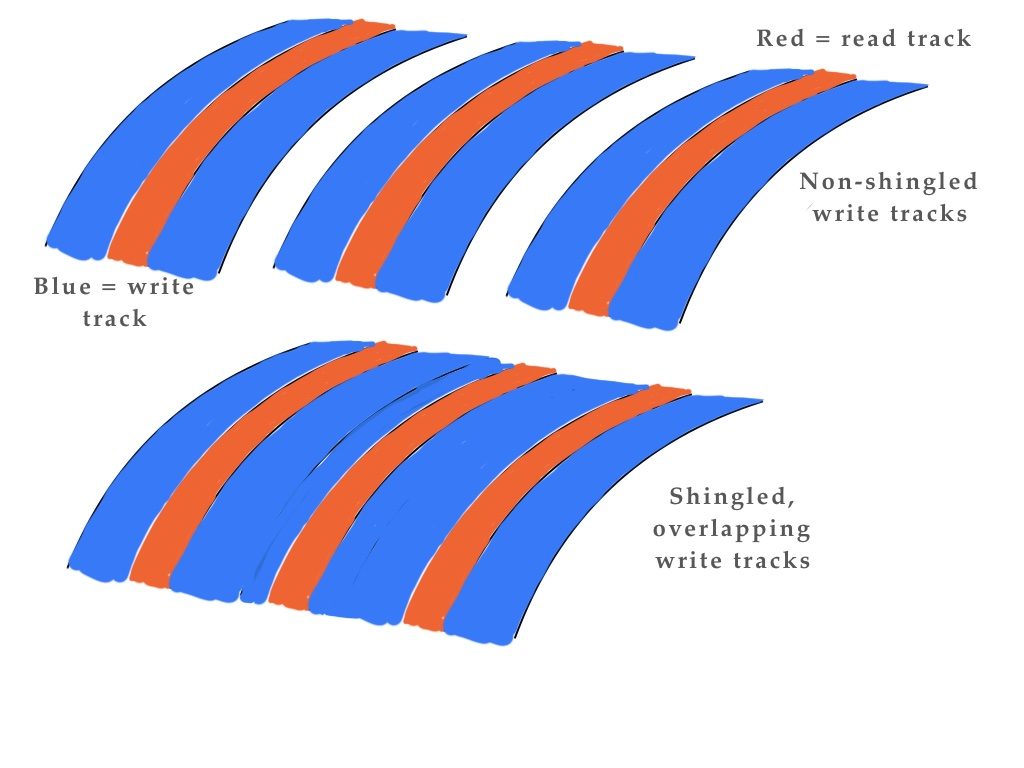
Blocks & Files: How does Panasas view shingled media disk drives? Why might this be a viable storage medium for its customers, or not?
Murphy: In the performance-oriented world of HPC, shingled HDDs are best described as very, very small tape robots.They have a few hundred open ‘shingles’ which can only be appended to, and it takes significantly longer time than an “append” operation to close one shingle and open another one for writing. That sounds just like tapes in a tape robot with a few hundred tape drives.
Shingled disk drive write track diagram.
Each tape/shingle can only be appended to, and it takes significant time to eject a tape/shingle and load another one for access. And finally, the contents of a shingled drive needs to be ‘garbage collected’ – shingles that have had some of their content deleted must have their contents merged with other low-utilization shingles and copied into a new shingle before that shingle can be recycled.
Shingled drives are a response to the needs of cloud service providers for very dense, slow performance for cold archive content. In that role, they can be valuable for HPC customers, but it’s somewhat hard to imagine them being part of a performance tier of storage.
Blocks & Files: How does Panasas view multi-actuator disk drives? Why might this be a viable storage medium for its customers, or not?
Murphy: Today’s version of multi-actuator HDDs are actually a density play rather than a performance play – it’s just like buying twice as many HDDs that were only half as large.
WD dual-actuator disk drive
Disk drive manufacturers take an HDD with N platters inside it that would have appeared to be a single drive to the host, and then add an additional actuator arm to the HDD, but that arm can only address N/2 platters, and that drive then appears to the host as two drives. The ‘I/O density’ goes up and the number of disk seeks per TB of capacity doubles, as does the number of disk seeks per data center rack.
But since any given piece of data only lives on one ‘drive’ or the other of the two in the multi-actuator HDD, the number of disk seeks or bandwidth per file does not go up. You can buy 6TB HDDs instead of 12TB HDDs right now and get the same effect, except that the 6TB HDDs are not half of the physical size of the 12TB HDDs; that’s why they are best described as a density play.
PanFS only puts large files onto HDDs, so the ability to double the seeks per HDD is not the significant advantage for us compared to a vendor that needs those extra seeks to access small files and metadata stored on HDDs. Again, PanFS always stores small files on SSDs to deliver the lowest latency access – an example of how we select the best media, both technically and economically, for each use case.
A DNA-based data storage system can store millions of times more data in the same volume as a conventional system, lasts for thousands of years at room temperatures, and gives you the ability to physically own and easily transport your data.
Current DNA storage technologies are costly and slow. For example, University of Washington and Microsoft researchers described an automated DNA storage proof of concept in a March 2019 Nature Scientific Reports paper. They encoded data, the word “hello” in DNA, stored it and then read it back. Their paper says the “system’s write-to-read latency is approximately 21 hours.
University of Washington and Microsoft automated DNA storage proof of concept.
The race is now on to build a commercially viable DNA data storage technology, with Microsoft, Georgia Tech and several startups including Catalog Technologies, Iridia, and Helixworks Technologies throwing their hats into the ring.
In this article we take a closer look at Catalog Technologies, an MIT spinoff, which declares DNA storage has been prohibitively slow and expensive, until now. It claims it is making DNA data storage economically feasible for the first time. Catalog is tiny but thinks it has stolen a march on its competitors. “We’re positioned to make this a reality within the next year or two, rather than in five or six years,” CEO Hyunjun Park told MIT in 2019.
The Boston-based startup was founded in 2016 by Park, a microbiologist, and Nathaniel Roquet, chief technology and innovation officer, who is a biophysicist. The company emerged from stealth in June 2018 and has received $10.5m in funding, according to the 2019 MIT article.
The ABC of DNA
Catalog’s ultimate goal is to offer DNA data storage-as-a-service to customers that need to store petabytes of data in archives.
It is still early days but the company thinks DNA storage will be less expensive than on-premises tape libraries and cloud storage services. It thinks it can get DNA storage costs down to under a three thousandth of a cent per MB.
Catalog is developing a DNA-based data storage system to hold and process massive amounts of data. As a demo of DNA as a medium for ultra-long term archival of data, Catalog has encoded the entire contents of Wikipedia – about 16GB of compressed data – into DNA.
In June 2019 Park told his alma mater MIT that Catalog was readying a demonstration system.
Catalogic CEO Hyunjun Park in video.
In a 2019 video Park explains that Catalog treats DNA as an alphabet.
“Catalog’s method is to synthesize batches of a bunch of different kinds of short DNA sequences, which can be thought of as analogous to letters. The original binary data is encoded by stitching together these DNA letters into billions of possible words.”
The short sequences are about 30 to 40 base pairs long; combinations of the As, Gs, Cs, and Ts of the genetic code, and there are around 200 of them.
The resulting less than a millilitre of fluid, or dry powder pellets, containing the DNA molecules, can remain stable for thousands of years, according to Park. It can be sequenced back [read] whenever information retrieval is needed.
Writing speed
Working with UK-based Cambridge Consultants, Catalog proved the feasibility of using its proprietary DNA data encoding method in a test machine or instrument. This recorded 1Mbit of data per 24-hour day into DNA.
Catalog compares its machine to a printing press with movable typefaces. These typefaces are pre-built DNA molecules in different combinations, and this obviates the need to synthesize billions of different molecules.
A Mbit/day rate is better than the 5bytes in 21 hours demonstrated by the University of Washington and Microsoft researchers, but Catalog reckoned it needed to be a million times faster than that;1Tbit per day instead of 1Mbit per day.
In October 2018 it announced it was working again with Cambridge Consultants on building a terabit writing instrument that would encode DNA “for about 1/1,000,000 the cost of what’s been possible before.”
Park said at the time: “The machine we are developing with Cambridge Consultants will bring DNA data storage out of the research lab and into the real world, for the first time in history.”
He thinks this leap in speed will help make it economically attractive to use DNA as the medium for long-term archival of data.
That is a great advance in DNA storage writing. But it is slow in data storage write bandwidth terms. For instance, a 14TB WD Purple disk drive spinning at 7,200rpm reads and writes data at up to 255MB/sec.This is 176 times faster than Catalog’s prototype.
The upfront trade-off is that you write data 176 times slower than a disk drive to store it thousands of times longer in an offline way. This is analogous to a magnetic tape cartridge but in a much smaller space.
Catalog terabit writing machine
DNA dot printer
The terabit writer prints – quasi-inkjet style – DNA ‘letters’ into dots on a sheet of plastic film. A dot corresponds to a block of binary data and contains multiple DNA letters. These are fixed through drying and then washed off the film into a fluid which is turned into pellets for storing.
The pellets are rehydrated and fed through a genome sequencer when the information they hold has to be retrieved.
A Catalog image envisaging a DNA storage facility
Reading DNA storage
Writing data into DNA storage is one thing. Reading it is another. Assume you have some store of pellets holding DNA molecules representing encoded digital information. How do you read them?
We have asked Park directly about the reading process but he has not replied. Cambridge Consultants declined to comment.
In the absence of definitive information Blocks & Files speculates this will involve a robotic library with automated movement of desired pellets to a ‘drive’, which rehydrates them and feeds them into a DNA sequencer. It then reads a pellet’s contents and outputs a file of digital data. A tape library is the analogy we have in mind.
We are interested in finding out if this is, as it seems, a destructive read, or if the pellet can be recreated and moved back to its location in the library.
DNA computing’s far out future
According to Catalog, DNA storage is nothing new … we humans have been using it for millions of years.
But in common with the University of Washington and Microsoft researchers, Catalog conceives a future for DNA computing. This is the notion of using data stored in DNA molecules and manipulating it directly, using enzymes for example. This would be performed in a highly parallel way, with potentially millions of simultaneous operations.
It all seems very far away at this stage. Watch the video above for more information on this notion of a way to bring computation to storage.
We will explore Iridia, Helixworks and Microsoft’s efforts with DNA data storage in subsequent articles.
Slow SATA no longer cuts it for SSDs in Seagate’s IronWolf NAS systems, with the company announcing the much faster NVMe IronWolf 510 SSD.
Seagate launched the SATA IronWolf 110 SSD in January last year. This uses a 2.5-inch form factor to provide a capacity range of 240GB to 3.84TB. The Ironwolf 510 is a reduced capacity range in the smaller and faster M.2 2280 gumstick format. When single-sided, it has 240GB and 480GB capacities, rising to 960GB and 1.92TB in a double-sided product.
Seagate’s Matt Rutledge, SVP, devices, issued a quote: “We are the first to provide a purpose-built M.2 NVMe for NAS that not only goes beyond SATA performance metrics but also provides 3x the endurance when compared to the competition.”
He could be thinking of drives such as Samsung’s M.2 format 970 EVO which has up to 1.2TB written rating at a 2TB capacity – about three times less than the IronWolf 510.
Seagate rates the IronWolf 510 at one drive write per day for its five-year warranty period. This is equivalent to 3.15PB for the 1.92TB model – which is lower than the IronWolf’s 110’s 3.5PB for the same capacity.
The need for speed
The 510’s read performance is on another planet compared with the SATA IronWolf 110, and sequential write numbers are also elevated.
The IronWolf 110 performs up to to 90,000/20,000 random read/write IOPS. The 510 is more than four times faster at reading, delivering up to 380,000/28,000 random read/write IOPS.
Sequentially, the 110 provides up to 560/535MB/sec bandwidth, which the 510 blows away with its 3,150/1,000 MGB/sec. This delivers a 5.6x read speed increase and a 1.4x write speed boost.
Seagate positions the 510 as best suited for use as a cache tier in front of IronWolf disk drives in a NAS system.
The IronWolf 510 has 1.8 million hours between failure rating and comes with two years of Rescue Data Services to restore data from a failed drive.
It’s available now and retails at $119.99 for the 240GB, $169.99 for 480GB, $319.99 for 960GB; and $539.99 for 1.92TB.
LAM Research, a Bay area-based semiconductor tooling maker, has called a temporary halt to California operations, in compliance with ‘shelter-in-place’ orders that came into effect at midnight Monday night.
As a result the company said it is unlikely to meet guided revenue amount for the March 2020 quarter. Also, upstream semiconductor plants will not receive ordered LAM Research product when expected. Customers include Intel, Micron, Samsung, SK hynix. Taiwan Semiconductor Manufacturing Company, and Kioxia.
LAM Research operates plants in Fremont and Livermore to build equipment that chip fabs use to make NAND, processors and DRAM. The company’s woes are compounded by a Malaysian government order to close certain business activities from March 18 through March 31, 2020. The company has supply chain activities in Malaysia, which are currently unable to ship components to LAM’s U.S. plants.
Some seven million residents in seven Bay Area counties are expected to stay at home under shelter in place, which is intended to slow the spread of coronavirus in the region.
The order states: “All businesses with a facility in the County, except Essential Businesses as defined below in Section 10, are required to cease all activities at facilities located within the County except Minimum Basic Operations.” Semiconductor firms are not defined as an ‘essential business’.
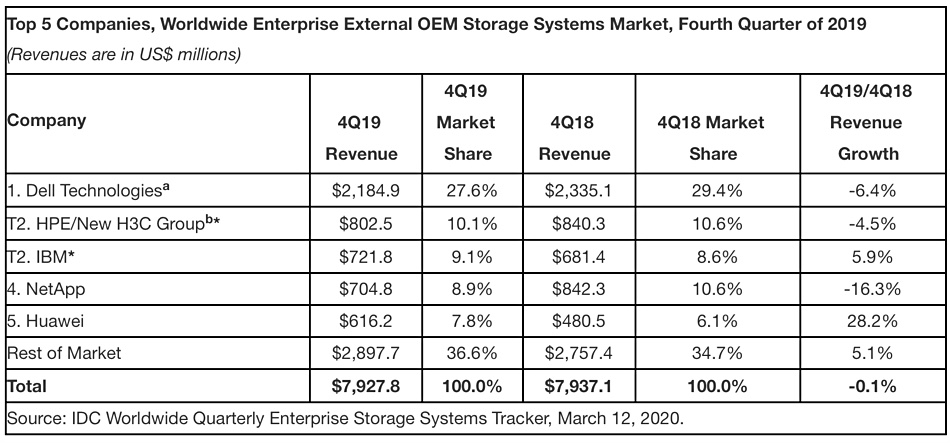
Dell continues to dominate IDC’s external OEM storage market numbers for 2019’s fourth quarter. But the company experienced a 6.4 per cent fall in revenue in a flat market in which hyperscale buyers gave Original Design Manufacturers (ODMs) their strongest growth in five quarters.
Paul Maguranis, senior research analyst at IDC, provided the announcement quote: “ODMs witnessed double-digit year-over-year growth this quarter for revenue, units, and capacity shipped and accounted for 58.9 per cent of capacity shipped for the entire storage market, up from 46.8 per cent this time last year.”
IDC notes the all-flash array market grew 13.1 per cent to $3.23bn in revenues. It didn’t provide numbers for disk drive storage, but noted that hybrid (flash + disk) arrays took in $3.04bn, declining 2.8 per cent annually.
IDC’s number crunchers reckon the overall external storage market was flat at $7.927.8bn in Q4. Huawei, in fifth place, was the main gainer, recording a 28.2 per cent rise in revenues to $616.2m. IBM also did well, tying with HPE for second place, while NetApp fell to fourth.
Hitachi was in IDC’s external storage table last quarter, but has dropped the latest top five supplier rankings. Pure Storage failed to make top five for the second consecutive quarter.
Pure told us that, looking at the 5 year (2014 – 2019) compound annual growth rate of Pure versus its major competitors, Pure grew 55.7 per cent, and HPE grew less than 2 per cent. Dell EMC, IBM and NetApp are all negative.
In the WW external storage market, Pure grew 18.8 per cent YoY from CY2019 to CY2020. HPE and Hitachi also grew, but Dell, IBM and NetApp all shrank, with NetApp dropping 13 per cent. Pure did not provide growth numbers for Q4 2019 so we can’t make a comparison between it and the suppliers which IDC lists.
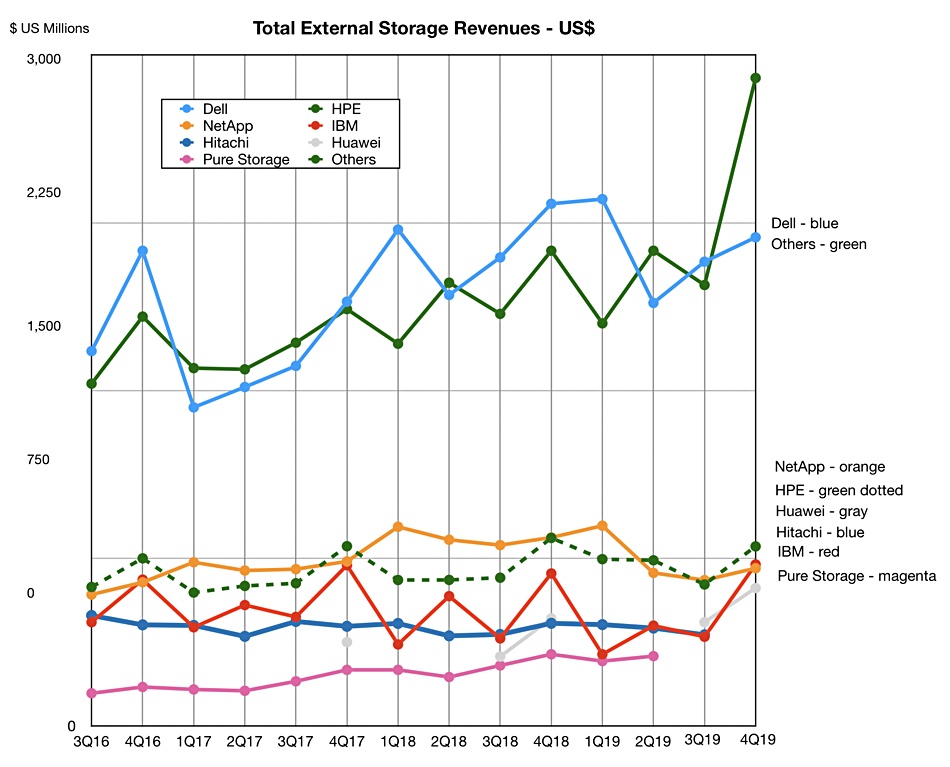
Here is a chart showing the trends since Q3 2016;
Revenues of ODMs, Pure and Hitachi are in the Others Category in Q4 2019, which accounts for the sharp rise in Others revenues for this quarter.
We can see that Huawei and IBM have both overtaken Hitachi recently and Pure is growing steadily closer to Hitachi.
Nutanix has enlarged the capacity of its object store, deepened Splunk integration and improved inviolable archiving to give users more control of the unstructured data fire hose.
The company’s aims for Nutanix Objects 2, launched today, is to make Nutanix systems more attractive for big data analytics by storing, managing and using more unstructured data at lower cost.
Nutanix has corralled a quote from Amita Potnis, research director in IDC’s Storage team: “Object storage is rapidly becoming the storage of choice for next gen and big data applications. As object storage makes the leap from the cloud to the datacenter and mission critical workloads, economics must be balanced with performance.”
Scale up and out
Nutanix Objects 2.0 supports 240TB capacity nodes, which is 1.8 times more than the existing NX-8155-G7’s 135.36TB capacity. Put five of these 240TB nodes in a cluster and you scale up to 1.2PB of raw object capacity.
The upgrade adds a single object namespace across clusters to enlarge an object store to massive scale, according to Nutanix. IT admins manage the namespace from a single console and they can add unused – ‘stranded’ -storage capacity in a set of clusters to an object store. improving effective costs. The degree of improvement that can be achieved is dependent on available stranded capacity.
WORMs and Splunk
Nutanix Objects already supports write-once-read-many (WORM) storage to prevent written objects being changed. A WORM object is stored as a specific numbered version, and any update attempt creates a newer version. Nutanix Objects 2.0 makes this easier with users able to to lock content without enabling versioning.
Splunk software is used to ingest machine-generated data, index it, search for patterns and analyse the data. A SmartStore function acts as an indexer that uses locally-cached data or remote object stores, either on-premises or in an S3-compliant cloud. Nutanix Objects 2.0 is integrated with SmartStore so joint customers can run Splunk workloads on Nutanix software, and use Nutanix Objects for the object store.
Intel will likely have to pay more to Micron for Optane memory chips, under a new supply deal that kicked in on March 7.
Terms of the agreement are confidential but as Wells Fargo analyst Aaron Rakers notes: “Given Micron’s entire ownership of the 3D Xpoint [another name for Optane], we would assume that the new wafer supply agreement reflects net-positive pricing and forecast terms for Micron.” Micron supplies Intel with 3D XPoint wafers made at its Lehi, UT fab.
JimHandy, a senior analyst at Objective Analysis, told Blocks & Files: “Intel is losing money in its NVM Solutions Group (NSG) because 3D XPoint is proving very unprofitable to produce. By my estimate Intel lost about $2 billion on 3D XPoint in each of 2017 and 2018, and $1.5 billion in 2019.”
According to Rakers, Micron had $158m in Lehi-based XPoint and NAND sales to Intel in its first fiscal 2020 quarter. The new agreement will not be hugely material to Micron revenues. The company records an under-utilisation charge averaging $150m per quarter for the Lehi XPoint fab.
Micron maxes credit line in COVID-19 precaution
Micron said in a SEC 8K filing dated March 12 it had increased borrowings by $2.5bn “as a precautionary measure in order to increase its cash position and preserve financial flexibility in light of current uncertainty in the global markets resulting from the COVID-19 outbreak”.
COV-19 virus. CDC/ Alissa Eckert, MS; Dan Higgins, MAM - This media comes from the Centers for Disease Control and Prevention's Public Health Image Library (PHIL), with identification number #23312.
Qumulo is making its cloud filesystem software available at no charge to researchers that are working to minimise the spread and impact of the COVID-19 virus.
The scale-out filesystem supplier has made the offer to public and private sector medical and healthcare research organisations, effective immediately until the end of June.
Bill Richter, president and CEO of Qumulo, provided a quote: “This virus requires every organisation that can make a difference to do so right now, and band together to solve this problem with all available technology resources and the smartest minds on the planet collaborating seamlessly.”
COVID-19 virus. CDC/ Alissa Eckert, MS; Dan Higgins, MAM – This media comes from the Centers for Disease Control and Prevention’s Public Health Image Library (PHIL), with identification number #23312.
Matt McIlwain, chairman of the board of trustees of the Fred Hutchinson Cancer Research Center and managing partner at Madrona Venture Group, a Qumulo investor, also provided a quote: “Research and healthcare organisations across the world are working tirelessly to find answers and collaborate faster in their COVID-19 vaccine mission. It will be through the work of these professionals globally, sharing and analysing all available data in the cloud, that a cure for COVID-19 will be discovered.”
Visit qumulo.com/cloudfileforcovid to register your organisation for the use of Qumulo’s file software in the cloud, running on AWS and GCP platforms.
Earlier this week we covered the main details of VMware’s blockbuster vSphere 7 launch. In this article we zoom in on VMware’s vSphere 7 support for NVMe over Fabrics for faster data access to external block storage arrays.
This support gives virtual machines faster read and write access to external stored data, thus increasing performance.
NVMe-oF is the NVMe drive protocol carried over Ethernet or another network fabric. It enables access to a network-linked storage drive as if it were local to the accessing server – in other words, like a direct-accessed NVMe drive IO but cheaper and faster. Latency for the pooled storage is about 100μs instead of the 500μs or more of an all-flash storage array accessed across a File Channel or iSCSI network.
NVMe-oF also increases IO access speed using multiple IO queues and by enabling parallel access to more of an SSD’s flash.
Network fabrics
vSphere 7 supports Fibre Channel and RoCE v2 (RDMA over Converged Ethernet) network fabrics, Jason Massae, technical marketing architect at VMware, writes in a company blog. This enables faster access to any NVMe-oF array, such as those from HPE, NetApp, Pure Storage and, of course, VMware’s parent company, Dell.
vSphere 7 also supports shared VMDKs for Microsoft WSFC, and, in VMFS, optimised first writes for thin-provisioned disks, Massae writes. And there is extended VVOL support.
Jacob Hopkinson, VMware solutions architect at Pure Storage, explains in this article, “vSphere 7.0: Configuring NVMe-RoCE with Pure Storage”, how to configure vSphere’s ESXi hypervisor for NVMe-oF RoCE. He covers Mellanox and Broadcom network adapters and the setting up of vSwitches, port groups and the vmkernel.
I can store five terabytes in my shirt pocket with Western Digital’s My Passport portable drive.
The latest iteration of My Passport as released in September last year, and its recent launch in India prompted us to take a fresh look.
My Passport is a certainly capacity whopper, and is available in 2TB and 5TB base formats, with two or four platters. The 5TB drive can use 4 x 1TB base platters because deploys shingling – using overlapping write tracks to cram more read tracks in the drive.
My Passport drive Windows colours
Power comes through a USB port: USB-C for Macs, and USB 3.2 Gen 1 for Windows. There is 256-bit AES encryption and built-in password protection.
The device has a SATA interface, spins at 5,400rpm, and the actual capacities available are 1TB, 2 TB, 4TB and 5TB, using 1TB platters.
The 4TB and 5TB drive’s extra thickness and near doubled weight reflects the two extra platters inside. The case is part-diagonally ribbed and available in blue for Mac and black, red and a different blue for Windows.
Shingling
The 5TB drive, claimed to be the thinnest such drive available, uses drive-managed shingling. This slows the data rewrite process as blocks of tracks have to be read, the data altered, and then the block re-written to the drive. Fresh data writes to empty tracks proceed as normal.
Large sequential files are accepted by the drive and written with no interruption. Smaller randomly-addressed files are stored temporarily in a cache and then, when the drive is idle, written out in a sequential manner, with address translation to speed the writing process.
WD’s Discovery software provides management functions, and enables the drive, with included Backup utility, to backup host system files on a settable schedule. It can also backup Facebook, Dropbox and Google Drive (cloud) account data, such as photos, videos, music and documents. Data is transferred to and from the drive at up to 5Gbit/s. In practice that means, , 100 to 115MB/sec when reading large sequential files.
Writing such files over deleted files will be slower because of the shingled media effect. In other words, the 5TB drive will seem slower as it fills up and files get deleted to make space for newer ones. The 4TB drive should not suffer from this effect.
Pricing
My Passport is warranted for three years. A 5TB model costs $125.99 on Amazon; £112.99 in the UK from Scan. The 1TB model is $47.00 (£46.05.)
This pricing makes them affordable for desktop, notebook and low-intensity gaming systems. High-intensity gamers will do better with external SSD storage. The rest of us can enjoy 5TB capacity for $0.026/GB. Cheap as chips.
However, 5TB of slightly faster (5,526rpm) spinning Seagate Backup Plus Portable external storage, which is shingled as well, costs $109.99 (£98.66) on Amazon; cheaper still.
My Passport vs. My Passport Ultra
WD also sells the My Passport Ultra drive. What’s the difference? A WD spokesperson said: “The My Passport drives are the best choice for most everyday consumers. The 5TB My Passport drive is actually the slimmest of its capacity in the WD lineup. For those looking for a more premium portable hard drive, the My Passport Ultra features a modern metal design and USB-C technology out of the box. Both drives offer a three-year limited warranty and WD Discovery software (including social media and cloud importing, WD Backup and 256-bit AES hardware encryption).”