


Modern data storage technologies may deliver high speed data access but not all make the cut for the exacting demands of high performance computing (HPC) applications.
Panasas is a niche supplier of high-end storage systems for HPC users. We asked Robert Murphy, director of product marketing, for the company’s views on quad-level cell (QLC) flash; storage-class memory; NVMe-over-Fabrics; multi-actuator disk drives; and shingled write tracks. What technologies get the seal of approval from his HPC customers?
Murphy has some distinctive views and ways of describing technology. For example:
- QLC is not a viable storage medium for HPC storage systems,
- NVMe-oF is too expensive to deploy at the multi-petabyte capacities HPC customers require
- Optane DIMMs do not seem to be good match for HPC use cases
- Optane DIMMs are way too small and too expensive for storing HPC user data
- Multi-actuator HDDs are equivalent to buying twice as many HDDs that are only half as large
- Computational storage is a very cool technology looking for a problem to solve.
Now for our interview, which we conducted by email.
Blocks & Files: How does Panasas view QLC (4bits/cell) flash? Why might this be a viable storage medium for its customers, or not?
Robert Murphy: Panasas does not believe QLC is a viable storage medium for HPC storage system customers. QLC’s biggest disadvantage is its very well-known exceedingly low write endurance that restricts it to heavy read-oriented workloads as found in the consumer device space. QLC is not suited for write-heavy workloads.
HPC storage requires both high performance and high capacity and customers demand an economical price too. HPC workloads are a mix of heavy reads and writes, big files and small files. It’s this demanding combination of performance, capacity and price that drives successful storage media choices for HPC storage. Panasas is agnostic when it comes to storage media selection, we pick the best media that meets the specific use case’s technical and economic requirements.
To accommodate this broad range of HPC workloads, PanFS and the ActiveStor Ultra hardware architecture is designed to have a very balanced read:write ratio as shown in the IOR performance diagram below;
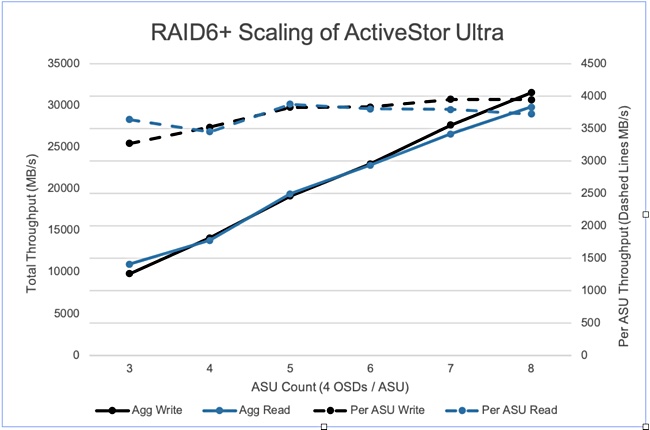
The Faustian bargain of low cost versus extreme sensitivity to writes requires very careful solution-level engineering for QLC to have any value in HPC storage where write performance is almost as prized as read performance.
To us, this uneven read:write performance ratio is a non-starter for HPC workloads and as such, Panasas would never use QLC in its HPC storage systems
In addition, there is also the very important question of storage medium economics. Using the QLC-based Vast Data system as an example, a quick survey of internet prices for the 15.36TB QLC SSD device it uses shows the device price hovers around $3,000 – a good deal for nearly 16TB of flash memory. But compare that with the $400 price for a 16TB HDD of the type used on the Panasas ActiveStor Ultra system.

Panasas can provide 7.5X the capacity of QLC with HDD technology for the same price – with virtually no endurance risk. And since PanFS is a parallel file system, Panasas ActiveStor Ultra can provide virtually unlimited performance by reading and writing to and from 100s to 1000s of drives in parallel – uniquely to both HDDs for big files, and flash SSDs for small files, with the Panasas Adaptive Small Component Acceleration (ASCA) architecture.
Blocks & Files: How does Panasas view NVMe-over Fabrics (NVMe-oF)? Why might this be a viable data access method for its customers, or not?
Murphy: Panasas is a fan of NVMe-oF. It meets all the requirements of our HPC storage customers, except one: it’s simply too expensive to deploy at the multi-petabyte capacities that HPC customers require.
For example, an 11TB NVMe SSD averages around $4,000 or 14.5X the price per TB compared to the HDDs used in the Panasas ActiveStor Ultra System. Hence, we are currently using NVMe sparingly and where it makes the most sense: to store the metadata in the PanFS database. We are also investigating adding an NVMe-oF tier (Ludicrous Mode) into future PanFS systems.
Blocks & Files: How does Panasas view storage-class memory (SCM – meaning Optane)? Why might this be a viable storage medium for its customers, or not? What role can SCM play in Panasas’ plans?
Murphy: If you’re asking about Optane DIMMs in particular, they do not seem to be good match for our HPC use case.
For transaction logs, we like the latency of the SCM being the same as DRAM, don’t want to worry (at all) about wear in the 100 per cent write workload of a transaction log, and don’t need the large capacities that Optane can offer. As far as using Optane DIMMs to store user data, they are way too small and expensive for that.

While it might make sense architecturally to use large quantities of them to store all the metadata for lower/slower layers in an all-flash storage hierarchy, you’d be pushing the overall solution toward another “DSSD” (Dell EMC’s withdrawn all-flash array of 2017), there simply isn’t a commercially viable market for something that fast and expensive.
PanFS has used NVDIMM Storage Class Memories in our systems for several years now; we use NVDIMM’s to hold our transient transaction logs in our Director Nodes and new ActiveStor Ultra Storage Nodes. The extreme bandwidth and low latency that result from SCM’s being on the CPU’s memory bus is tremendously valuable, but if the SCM is not used in the correct way in the solution’s architecture, the advantages can be hard to obtain.
Blocks & Files: How does Panasas view computational storage? Why might this be a viable technology for its customers, or not?
Murphy: The attraction of computational storage is based upon the idea that the underlying storage devices have more performance than that can be moved over the network, and that there is an advantage to moving the computation to the storage rather than moving the data from the storage across a network to the computation. We believe that the value of disaggregation should not be ignored, and that networking tech has improved to the point that there is no practical limitation on performance from networking, whether bandwidth or latency.
Disaggregation allows sharing of storage capacity and performance across multiple computations, allowing much more flexibility and therefore higher utilization of the available CPUs and GPUs compared to dedicating CPUs to just one storage device (the one they’re embedded within). In addition, the CPUs and GPUs can be chosen, maintained, and upgraded independently from the storage. Under the majority of circumstances, computational storage is a (very) cool technology looking for a problem.
Blocks & Files: How does Panasas view shingled media disk drives? Why might this be a viable storage medium for its customers, or not?
Murphy: In the performance-oriented world of HPC, shingled HDDs are best described as very, very small tape robots.They have a few hundred open ‘shingles’ which can only be appended to, and it takes significantly longer time than an “append” operation to close one shingle and open another one for writing. That sounds just like tapes in a tape robot with a few hundred tape drives.
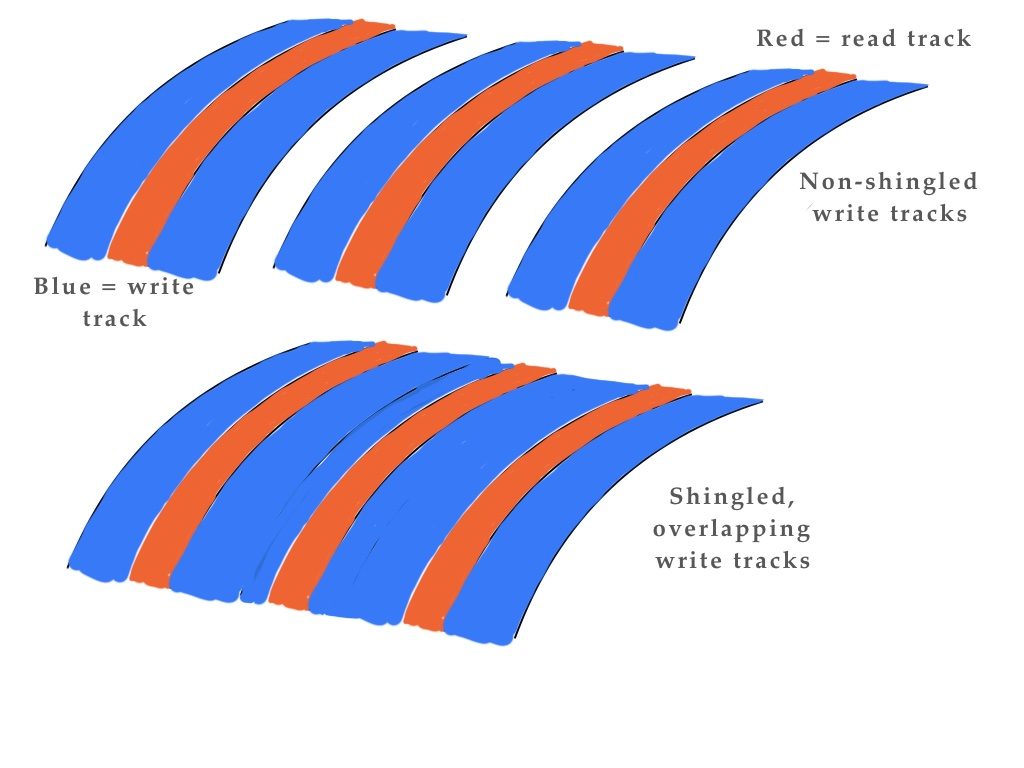
Each tape/shingle can only be appended to, and it takes significant time to eject a tape/shingle and load another one for access. And finally, the contents of a shingled drive needs to be ‘garbage collected’ – shingles that have had some of their content deleted must have their contents merged with other low-utilization shingles and copied into a new shingle before that shingle can be recycled.
Shingled drives are a response to the needs of cloud service providers for very dense, slow performance for cold archive content. In that role, they can be valuable for HPC customers, but it’s somewhat hard to imagine them being part of a performance tier of storage.
Blocks & Files: How does Panasas view multi-actuator disk drives? Why might this be a viable storage medium for its customers, or not?
Murphy: Today’s version of multi-actuator HDDs are actually a density play rather than a performance play – it’s just like buying twice as many HDDs that were only half as large.

Disk drive manufacturers take an HDD with N platters inside it that would have appeared to be a single drive to the host, and then add an additional actuator arm to the HDD, but that arm can only address N/2 platters, and that drive then appears to the host as two drives. The ‘I/O density’ goes up and the number of disk seeks per TB of capacity doubles, as does the number of disk seeks per data center rack.
But since any given piece of data only lives on one ‘drive’ or the other of the two in the multi-actuator HDD, the number of disk seeks or bandwidth per file does not go up. You can buy 6TB HDDs instead of 12TB HDDs right now and get the same effect, except that the 6TB HDDs are not half of the physical size of the 12TB HDDs; that’s why they are best described as a density play.
PanFS only puts large files onto HDDs, so the ability to double the seeks per HDD is not the significant advantage for us compared to a vendor that needs those extra seeks to access small files and metadata stored on HDDs. Again, PanFS always stores small files on SSDs to deliver the lowest latency access – an example of how we select the best media, both technically and economically, for each use case.





