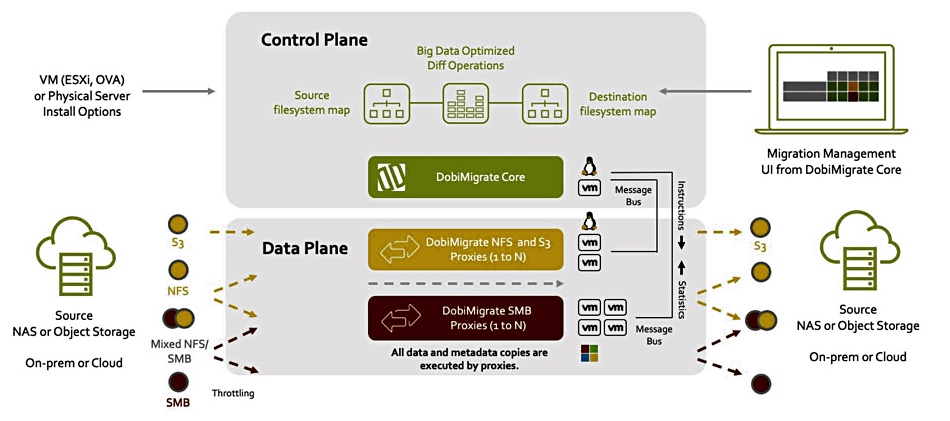
Datadobi, the file data migration specialist, has added S3 object transfer to its capabilities.
The company has supported S3 since 2017 via Dobisync, a product that copies files to an S3 target as a form of data protection. It has updated the technology to migrate from any S3 source to any S3 target and has included this tool in DobiMigrate 5.9, which hit the streets yesterday.
Carl D’Halluin, Datadobi CTO, said the new software release incorporates “everything we have learned about S3 object migrations into our DobiMigrate product, making it available to everyone. We have tested it with the major S3 platforms including AWS to enable our customers’ journey to and from the cloud.”
DataDobi migration diagram.
The S3 migration facility covers migration from any vendor or public cloud S3 store to any vendor or public cloud S3 store. It moves objects and object metadata, and verifies object transfer correctness by hashing each object as it is migrated. A fresh hash is calculated at the target site, and the source and target hashes are compared. If they match, the transfer has been successful.
DobiMigrate creates a report to show every single hash of every single object, which is kept for future auditing. This could be an extremely large report if millions of S3 objects are migrated.
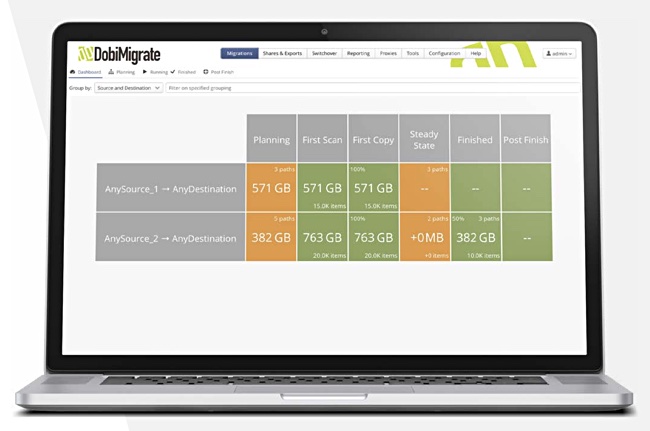
Migration progress is tracked on a dashboard. A formal switchover process can be run once all the objects have been moved.
DobiMigrate dashboard
DobiMigrate pricing is based on the number of terabytes to be migrated. Customers buy a fresh license if more data needs to be migrated subsequently.
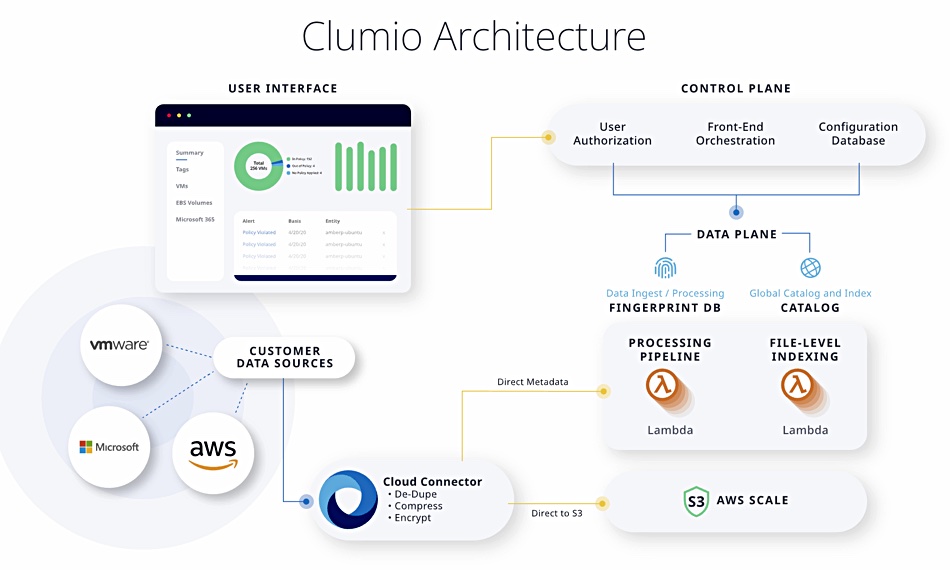
Clumio has expanded its AWS service coverage from EBS (Elastic Block Store) to RDS (Relational Database Service).
The SaaS backup startup, which came out of stealth last August, stores EBS and RDS snapshots in a separate AWS account from the customer’s own AWS account. This “air-gapping” separation adds security, particularly against ransomware, according to Clumio. (Note, the two AWS accounts are on the same AWS online system and so Clumio’s use of the term “air-gapping” is an analogy, not a description of a physical reality.)
Poojan Kumar, Clumio CEO said in a press statement yesterday: “Clumio delivers an authentic data protection service, that protects data outside of customer accounts for ransomware protection and lowers costs for long-term compliance. There is no other company, product, or service that can deliver these values in the public cloud today.”
Clumio RDS protection has three attributes:
Operational point-in-time recovery and free snapshot orchestration for EBS and RDS workloads
RDS data recovery with restores, granular record and column retrieval and the aforesaid air-gapped snapshots
Compliance with long-term retention, record-level retrieval and deletion, export for legal hold/eDiscovery and data store.
Poojan Kumar
Kumar told us the RDS record and column-level retrieval and EBS file retrieval “is huge and the beginning of more applications and use cases that can be run on top of the data we are protecting… There is much more to come.”
Clumio does not charge for the snapshots that Amazon RDS data protection creates, Kumar told us. “When it comes to the snapshot orchestration that everyone else charges for, that functionality is available in our free tier that is available for every customer.”
He said: “Enterprise customers tell us there isn’t much value in snapshot orchestration so we are instead focused on what is valuable to them – lower TCO for long-term retention and compliance for their data in the cloud.”
Kumar then took the gloves off: “No longer do customers need to pay for a product that just does snapshot orchestration. They can manage in-account snapshots with Clumio’s free tier. This throws out the window any product to protect cloud workloads by players like Rubrik, Cohesity, Druva, etc.”
Brian Cahill, technology director at FrogSlayer, a Texas software developer, provided a customer quote: “Clumio seamlessly handles operational recovery while significantly reducing our snapshot costs. Even better, I don’t have to worry about snapshot limitations, or develop scripts and retention algorithms because Clumio handles all of this. We now have line of sight to significantly reduce our TCO for long-term data retention since it is an integral part of the Clumio service.”
Clumio’s SaaS backup also protects VMware, VMware Cloud on AWS and Microsoft 365. Clumio for Amazon RDS goes live on June 11.
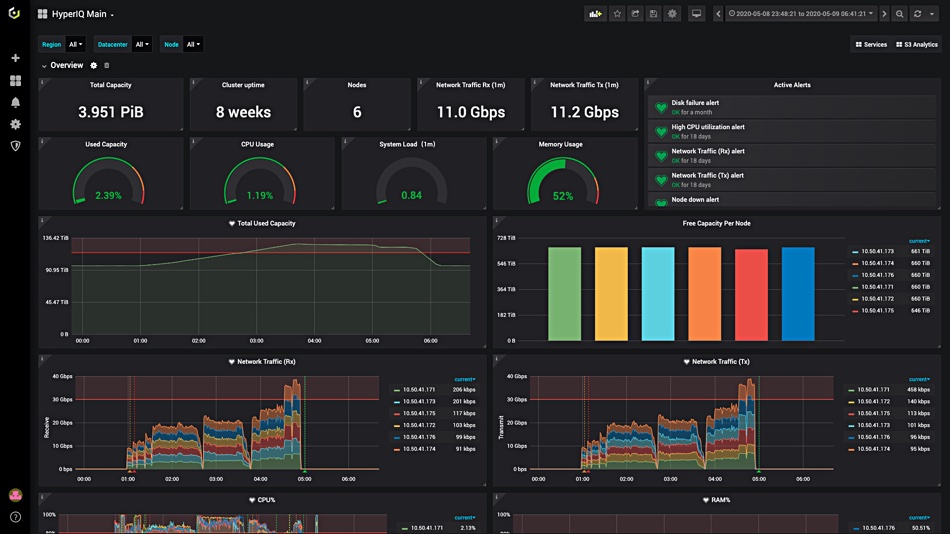
Cloudian has released HyperIQ, a monitoring and observability system for its HyperStore object storage platform. The analytics software gives a single view of the Cloudian object storage infrastructure across the estate and can reduce mean time to repair, increase system availability and save costs, the company said today.
Functionality includes monitoring with real-time interactive dashboards and historical data, Customers can analyse resource utilisation by data centre, node, and services with drill down, using customisable dashboards. There are more than 100 available data panels for the dashboard.
HyperIQ screen.
Customers can monitor user activities, provide insights into usage patterns such as uploads/downloads, API usage, S3 transactions, request sizes and HTTP response codes and enforce security and compliance policies.
HyperIQ identifies trends and faults and send alerts, causing the creation of support cases, repair activity or system tuning to optimise operations. The software issues alerts for predicted hardware failures, assessing maintenance needs, and avoiding performance impacts. These alerts can be sent through multiple notification channels such as Slack, OpsGenie, Kafka and PagerDuty. HyperIQ also has a ServiceNow plug-in.
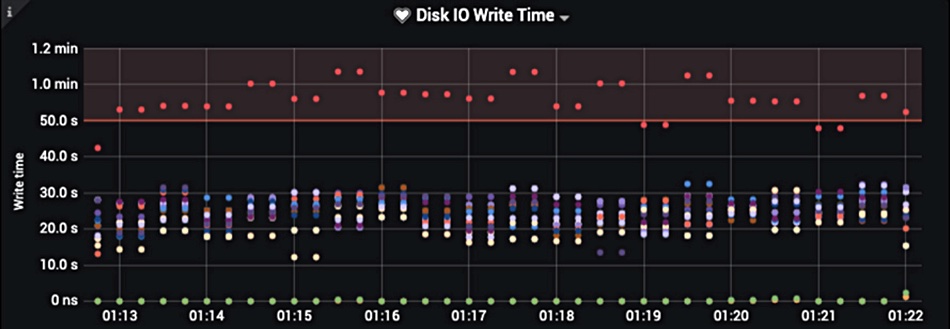
HyperIQ disk IO write time chart.
HyperIQ 1.0 supports HyperStore. The company will release an update later this year a version that supports HyperFile, Cloudian’s file gateway to to HyperStore. Cloudian’s ultimate goal is to make HyperIQ an AIOPs self-driving management tool.
Two versions of HyperIQ are available: HyperIQ Basic includes pre-configured dashboards and is offered to customers at no charge. HyperIQ Enterprise includes the analytics features, and is licensed by capacity at 0.025 cents per GB per month, including support. You can check out a HyperIQ datasheet for more information.
Cloudian said it has not yet looked at integrating HyperIQ with HPE InfoSight – HPE is a Cloudian reseller.
Rancher Labs, the Kubernetes management software developer, has moved up the stack with Longhorn, an open source storage solution for containers.
Sheng Liang, CEO of the California startup, said today: “Longhorn fills the need for 100 per cent open source and easy-to-deploy enterprise-grade Kubernetes storage solution.”
With this launch, Rancher Labs is directly competing with suppliers of storage for Kubernetes-orchestrated containers – which are also Rancher partners.
For cloud native development, enterprises need a container orchestration facility. Wrapping in storage provision with your Kubernetes distribution could save the bother of dealing with a third-party storage supplier such as Portworx and StorageOS. Also, Longhorn includes backup, which means that Rancher is competing with Kasten.
Grabbing K8s by the Longhorn
Longhorn is cloud-native and provides vendor-neutral distributed block storage. Features include thin-provisioning, non-disruptive volume enlargement, snapshots, backup and restore and cross-cluster disaster recovery. Users also get Kubernetes CLI integration and a standalone user interface.
Longhorn in Rancher Labs catalogue.
Storage volumes provisioned by Longhorn could live on the server’s local drives but Longhorn can also present existing NFS, iSCSI and Fibre Channel storage arrays. For instance, Dell EMC, NetApp and Pure Storage and Amazon’s Elastic Block Store could. be block storage sources. Longhorn will also work with Rancher Labs partners – and now competitors – Portworx, StorageOS and MayaData’s OpenEBS to provide their storage for apps orchestrated by Rancher software.
Longhorn’s backup is a multi-cluster facility and can send the backup data to external storage. Its disaster recovery has defined RTO and RPO numbers unnecessary. Longhorn can also be updated without affecting storage volumes.
Longhorn is free of charge. Rancher has an app catalogue and users can download Longhorn from its website and also purchase support. There there are no licensing fees and node-based subscription pricing keeps costs down.
Longhorn console
Rancher Labs reminds us it is the cloud native industry’s favourite Kubernetes distribution, with some 30,000 active users and more than 100 million downloads. The company cites an IDC forecast that 70 per cent of enterprises will have deployed unified VMs, Kubernetes, and multi-cloud management processes by 2022.
Bootnote: Maya’s OpenEBS technology is using a version, a fork, of Longhorn to manage replication among the storage pods in its Virtual Storage Machines. A blog explains the details.
AWS has improved Amazon FSx for Windows File Server with dynamic size and throughput growth scaling capabilities.
FSx for Windows File Server provides disk or SSD-based SMB-protocol file storage and is integrated with Active Directory for authentication purposes. The software runs in single or multiple availability zones, and shares can also be accessed from VMware Cloud on AWS and Amazon WorkSpaces. FSx supports data encryption in transit and at rest and includes backups.
Previously, users created a file system with a fixed capacity and set network throughput levels. They paid for defined storage and throughput capacity and for any backups they created.
As announced in an AWS blog yesterday, users can now scale up or down capacity and or network throughput with button clicks in the AWS Management Console or by using an API call. That means you can add capacity or throughput performance for one-off burst work sessions or regular, cyclical workloads.
FSx file system users can make the changes free of charge – once Amazon rolls out the update in a maintenance window. New users get them straight away.
Competitive heat
AWS added the disk drive storage option to FSx in March this year, pricing it below the standard SSD option. Now it has added dynamic capacity and throughput scaling. And last month it increased EFS read performance from 7,000 to 35,000 IOPS at no charge.
AWS’s FSx for Windows is an SMB file system, complementing its EFS (Elastic File System) service which is an NFS-based offering. NFS is largely used by Unix and Linux applications and is also available for Windows, whereas SMB is a Windows file access protocol. There is also a separate FSx for Lustre offering.
Microsoft is prepping a data lake migration service for Azure, with the help of WANdisco replication software.
Two WANdisco services are available as a limited customer preview. They are LiveData Migrator for Azure, which performs a single scan migration of data, and LiveData Plane for Azure, which captures any data changes and applies them at target sites to ensure data consistency. They work in conjunction to establish an active:active data plane between locations.
WANdisco’s LiveData Platform services and billing are integrated in the Azure customer portal and the company says more turnkey Azure services are planned.
Dave Richards
Dave Richards, CEO and chairman of WANdisco, said: “The LiveData Platform service [is] the culmination of joint engineering work between WANdisco and Microsoft, with the objective of creating a new native Azure service built around data movement and data consistency.”
Tad Brockway, Microsoft corporate VP for Azure Storage, Media and Edge, said: “Customers have a significant opportunity to optimise costs and expand analytics and insights capabilities by moving their on-premises data lakes to the cloud. WANdisco Live Data Migrator and LiveData Plane are the first offerings to provide a fully integrated and turnkey experience for customers migrating Hadoop data into Azure Data Lake Storage seamlessly and without business disruption.”
The two companies envisage the migration of petabyte-scale data lakes from on-premises data centres to Azure, using WANDisco’s LiveData Platform technology. Such migrations take time and the data lake are active during the process. If data is sent to Azure and then updated back at a source site then we have unreliable data – two versions of the truth. WANdisco’s Distributed Coordination Engine (DConE) uses consensus technology which resolves this data version disparity.
Microsoft and WANdisco are initially seeking 50-plus customers with 200-300 exabytes of data on-premises that could migrate to the Azure cloud. They have sized the market at more than $1bn.
UK-based WANdisco has OEM deals with IBM and Dell Technologies and reselling deals with Amazon Web Services, Cisco, Google Cloud, HPE, Microsoft Azure and Oracle for its LiveData Platform software.
Huawei is planning to use 20TB SMR drives in its OceanStor Pacific, a mass data storage “array for the 5G era”.
Launched last month, OceanStor Pacific is a unified silo for block, file, HDFS and object storage data, built from scale-out clustered nodes. It is intended to replace Huawei’s FusionStorage product line.
The array is designed to store massive amounts of data safely, using a clustered node design with from three to 4096 nodes. It uses erasure coding (EC) rather than RAID as EC is more space efficient than RAID, supporting up to 91 per cent disk space utilisation with Huawei’s 22 + 2 EC mode.
The array can withstand the failure of up to four nodes or four enclosures with no loss of data and no hiccup in service availability.
Robert Foley.
Robert Foley, the Principal Architect for Huawei’s Data Storage, described the Pacific series in an Huawei Data Storage online IT day presentation. He said the array has 2U performance nodes, 4U and 5U capacity nodes, and 2U flash-based high-performance nodes for high-performance computing. An ultra-high density flash node is coming soon.
The 5U storage enclosure holds 120 disk drives – that’s 24 drives per rack unit – and Huawei contrasts this with Dell Technologies’ Isilon 80-drive H5600 enclosure; with 4U and 20 drives/U.
Pacific’s capacity drive trays have a 2.4PB capacity, which means they use 20TB SMR (shingled magnetic recording) drives.
In his presentation, Foley played a video that explicitly shows 20TB disk drives in use.
Toshiba intends to deliver 20TB drives next year. Our conclusion is that Huawei’s Pacific uses Western Digital 20TB drives.
The drive drawers are controlled by Huawei Kunpeng 920 CPUs. These are 64-core, 64-bit ARM processors, designed by Huawei and built on a 7nm process. Huawei says they are 30 per cent more power-efficient than industry counterparts, which we understand is a reference to Intel Xeon X86 processors.
Pacific’s capacity enclosure is heavy – 8 x 5U enclosures in a 40U rack will total 960 drives – and Huawei has given it a butterfly wing design. The drive tray is divided into front and back halves, a 2-way drawer, with a tray capable of being half drawn out from the array’s front or rear aspects to give access to the drives. This helps rack cabinet stability.
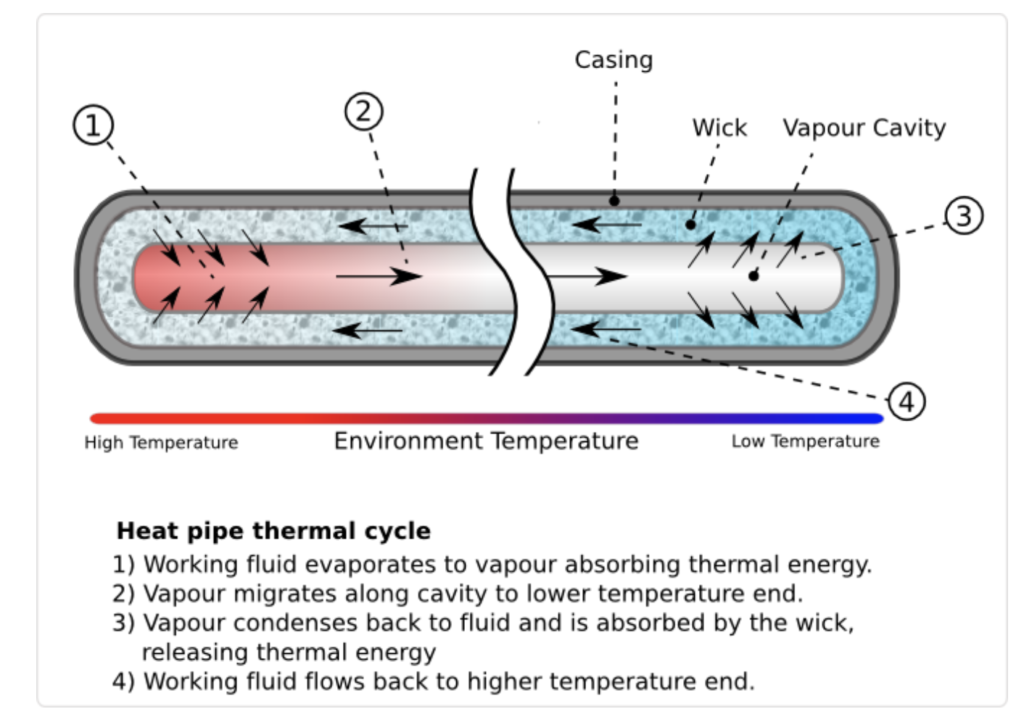
Drive tray cooling is another neat aspect of the array cooling. This uses phase-change, heat-pipe technology, a closed system in which heat is taken in at the hot end and converts a liquid to a gas. This flows to the cool end of the pipe, where it condenses, releasing heat, and the liquid returns to the hot end to pick up heat again in a continuous cycle.
Huawei heat pipe diagram.
The system balances temperatures in the front and rear of disk enclosures to keep disk operating temperature at the right level. Huawei says it uses this technology in some of its mobile phones.
The Pacific array has a 3-tier design. Hot, warm and cold data is automatically tiered onto SSDs, HDDs, and Blu-ray disks. Network connectivity includes 10 or 25GbitE, both TCP and RoCE, and 56 or 100Gbit/s InfiniBand. That means both low latency and high bandwidth needs can be met.
There is no datasheet available for the Pacific series of products yet.
Comment
OceanStor Pacific’s 5U high-capacity drawer design is an effective way to pack almost 1,000 disk drives into a 4U rack cabinet that doesn’t fall over when a drive tray is pulled out, and can cool the 120 drives inside each enclosure.
A 4U enclosure with 80 drives means a standard 40U rack would hold 800 drives. Huawei’s Pacific design can cram 960 drives into the same space – 20 per cent more.
As unified block, file, HDFS and object array, OceanStor Pacific can be sold as silo-reduction storage. For customers using HDFS in the classic way; with multiple server+storage nodes, the Pacific array decouples HDFS compute and storage, and saves more space by erasure coding instead of Hadoop’s traditional three copies of data.
Huawei claims a 22PB, 15-cabinet Hadoop system setup can be reduced to eight cabinets with Pacific’s decoupled compute and storage design, and reduced again to five cabinets with its high-density storage trays.
US regulators are putting the squeeze on Huawei, but elsewhere the Chinese company is a formidable contender for data storage budgets. OceanStor Pacific is potentially tough competition for other mainstream storage vendors.
This week’s storage digest features two funding rounds concluded in the pandemic, and data virtualizer Delphix declaring its original data source coverage mission is complete. We move on swiftly to an Excelero performance comparison with NetApp, and Pure Storage and Kioxia adding yet another data service to its Kumoscale all-flash array.
Couchbase funding
NoSQL database startup Couchbase has nabbed $105m in a G-series round led by new investor GPI Capital. It will spend the money on product development and global go-to-market capabilities. Total funding now stands at $260m.
Couchbase will complement feature development in its enterprise NoSQL server and mobile database platform with Couchbase Cloud, a fully managed Database-as-a-Service offering.
Couchbase says it has more than 500 enterprise customers, including 30 per cent of the Fortune 100, and receives nearly $100m in committed annual recurring revenue. It recorded over 70 per cent total contract value growth, 50+ per cent new business growth, and 35+ per cent growth in average subscription deal size in its latest fiscal year.
Delphix: Our (original) mission is completed
Delphix has declared the completion of its original mission to provide a comprehensive data platform that virtualizes data from all the main sources enabling its use for data operations (DataOps). This means supplying data swiftly and smoothly to DevOps teams and for use in analytics, AI, regulatory compliance, migration and other use cases.
In late 2019, Delphix made its data platform SDKs available to ISVs and they developed a host of new plugins this year covering;
Legacy platforms: mainframe, Informix, etc.
New data platforms: MongoDB, CouchDB, etc.
Cloud platforms: Aurora, RedShift, Azure SQL
Workflow, monitoring platforms: ServiceNow, Splunk, etc.
Automation platforms: Ansible, Terraform, Jenkins, Chef, etc.
That means data source coverage has expanded out from Oracle, Microsoft SQL Server, IBM DB2, SAP ASE, SAP HANA, and other major databases and apps. The SDK availability has enabled much fuller coverage.
Jedidiah Yueh
Delphix CEO Jedidiah Yueh said: “Customers need a comprehensive data platform to help drive transformations. Otherwise, it’s like trying to fly a plane without sufficient instrumentation. With our most recent platform release, we have completed everything on our initial roadmap.”
His pitch is that enterprises need fast access to both modern and legacy data sources fuel DevOps, analytics compliance and all the other workloads needing data; anything under a digital transformation heading. Delphix can provide data from more sources faster than any other product.
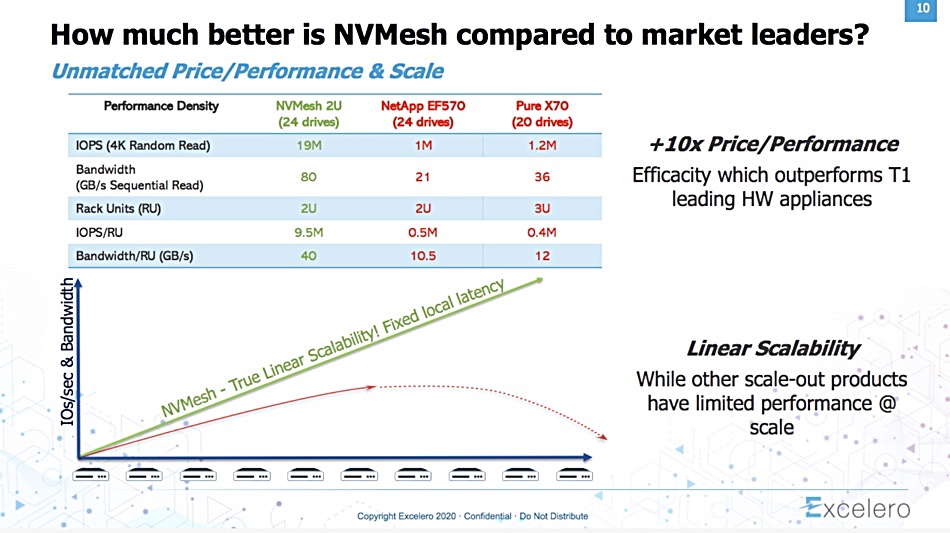
Excelero exceeds NetApp and Pure
Blocks & Files has seen a presentation slide from NVMe-oF storage supplier Excelero that compares its performance with NetApp’s E-Series and Pure’s FlashArray//X. Excelero claims it has 10x better price/performance and its product scales out linearly while the other two do not. Here’s the slide;
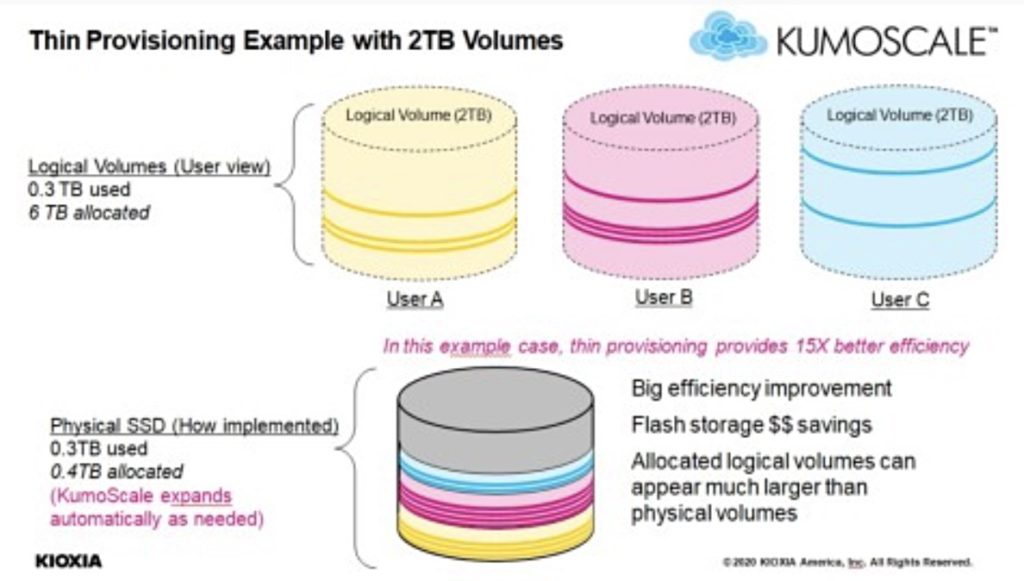
Kioxia thinly provisions KumoScale
Kioxia has added thin provisioning to its KumoScale storage software as it keeps on plugging away by adding features to the product.
KumoScale provides a scale-out aggregated multi-SSD block storage pool across an NVMe over Fabrics (NVMe-oF) connection to flash storage nodes. NVMe over RoCE and TCP are supported.
Host applications perform block IO to flash volumes and the Kumoscale software maps these volumes to individual flash drives and so enables the IOs to complete. The software’s Provisioner Service tracks the fleet of SSDs and storage nodes and manages the dynamic mapping of user volumes to nodes and physical drives. It processes provisioning requests, selecting the best KumoScale node, choosing the SSD and how to map it, and creates the volume via the REST API.
The software has REST API links to storage provisioning and orchestration frameworks such as Kubernetes, OpenStack, Intel RSD and Portworx.
In April Kioxia added Kubernetes CSI-compliant snapshots and clones to the KumoScale software. Joel Dedrick, GM for networked storage software at KIOXIA America, said: “We will continue to expand available options in order to help more users reap the benefits of a disaggregated architecture based on an NVMe-oF shared storage model.”
Wasabi funding
Cloud storage startup Wasabi has pulled in a $30m funding C-round, taking total investment to $110m.
The firm provides AWS-like storage at lower prices. It says it has a predictable pricing model that is one-fifth the cost of legacy cloud storage offerings with no fees for egress or API requests. Wasabi said it has tripled customer numbers, with more than 3,500 in EMEA, and claims 400 per cent revenue growthin the past year.
The funding will be used to expand Wasabi’s infrastructure and capacity to meet global demand and geographical expansion in Europe, APAC, Canada and Latin America. Wasabi plans to extend its hot cloud storage service to Canada and additional markets in Europe, APAC and Latin America through channel partners.
Shorts
Acronis has announced an artificial intelligence partnership with Roma, the Italian football club. Acronis will provide AI and machine learning technology to process football data to optimise game and business operations, and cyber protection for mission-critical workloads.
Igneous has completed a security assessment by the Trusted Partner Network (TPN) and so meets media and entertainment industry-specific requirements around content security, and general security standards focused on corporate governance, employee management, and operations.
Kingston is shipping 7.68TB capacity DC500R and DC450R SATA SSDs – The ‘R’ stands for read-intensive use. A DC1000M 7.68TB U.2 NVMe PCIe SSD is coming soon. All three have a 5-year warranty.
Dell will launch a unified unstructured storage array line next month, deputy chairman Jeff Clarke said yesterday.
In prepared remarks about the company’s Q1 earnings, Clarke revealed: “Next month, Unstructured.NEXT, the last of the powering up of the portfolio, will be delivered.”
‘Powering up’ is a nod to the Power brand prefix that Dell has adopted for its server, storage and networking portfolio. We think Unstructured.NEXT product will be called PowerScale. It will unify the Isilon scale-out file storage and ECS object storage lines with unified hardware and a single operating system.
Isilon was updated in January with support for containers, larger files, more capacity, faster Azure cloud compute access, and cloud-based management.
Blocks & Files suggests that the PowerScale OS will be a containerised operating system, in common with PowerStore OS, which runs the newly introduced PowerStore unified midrange array. Also we think Dell will offer automated migration to PowerScale from Isilon and ECS systems.
But will the new OS run as a virtual machine in a hypervisor-controlled PowerScale system? We have no insider information but this would enable applications to run on PowerScale as they do on PowerStore with its AppsOn feature.
We suggest that PowerScale will have an all-flash model, to compete head-to-head with Pure Storage’s FlashBlade.
PowerScale will ratchet up the competition with file and object storage vendors like Cloudian, Hitachi Vantara, IBM, Igneous, Minio, NetApp, Panasas, Pure Storage, Quantum, Qumulo, Scality and WekaIO.
Earnings
Onto Dell’s storage revenues, which took a five per cent hit to $3.8bn in its Q1 fy2021 ended April 30.
Our sister publication The Register has covered the overall Dell Technologies and VMware business unit results. Dell revenues were $21.9bn, about the same as a year ago, generating $182m net income, compared with last year’s $329m.
Dell storage revenues are included in the Infrastructure Solutions Group (ISG), which reported $7.6bn revenues, down eight per cent on the year. This was better than ISG’s server and networking sales, which declined 10 per cent to $3.8bn.
There were some bright storage spots and Dell vice chairman Jeff Clarke’s noted “double-digit demand growth in VxRail and in our high-end PowerMax solution and solid demand in unstructured storage, offset by softness in other areas of core storage.”
VxRail is Dell’s hyperconverged infrastructure appliance. Clarke’s comment implies other systems such as the SC, Unity, VNX and XtremIO arrays fared less well.
Dell will hope to rectify this with the unifying PowerStore midrange array, launched this month. Clarke was bullish about PowerStore in the earnings call: “The pipeline is growing rapidly. We have over 70 per cent of our storage specialists that already have had pipeline for PowerStore.”
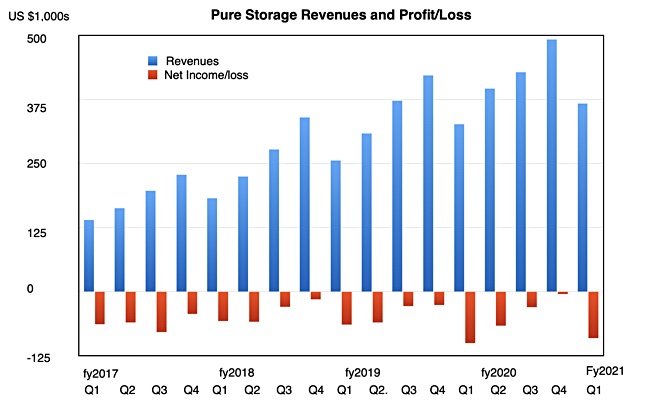
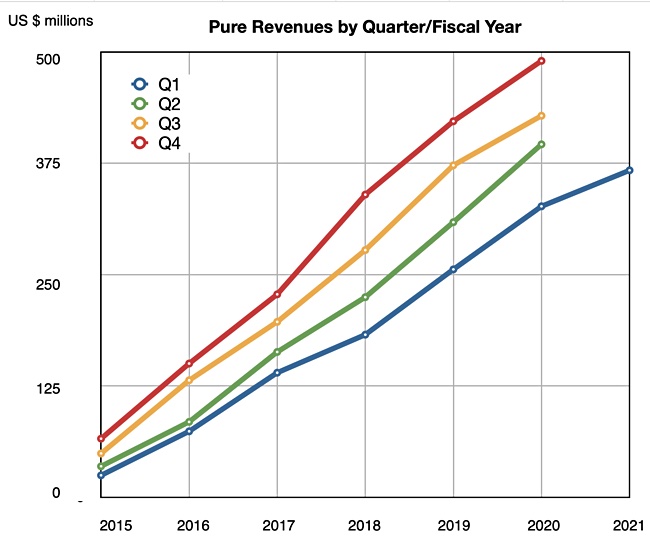
Pure Storage has reported growing quarterly earnings that shrugged off the initial impact of the COVID-19 pandemic, but it thinks next quarter will be flat.
Revenues in the all-flash array vendor’s first fiscal 2021 quarter ended March 31 were up 12 per cent at $367.1m, and the the company made a loss of -$90.6m, compared with -$100.3m last year. Pure said customers needed more mission-critical IT due to the pandemic and this had benefitted the business.
CEO and chairman Charlie Giancarlo provided a quote: “We are extremely proud of this quarter’s solid results and growth, especially during the current global crisis.”
He added: “I contracted covid-19 in March and that experience has provided me with a deep personal appreciation for this virus and its impact.”
Financial summary;
Subscription Services revenue $120.2 million, up 37% year-over-year
Operating cash flow was $35.1m, up $28.5myear-over-year
Free cash flow was $11.3m, up $29million year-over-year
Total cash and investments of $1.27bn
Total headcount c3,500 compared to 3,400 at the end of fy2020 and 3,150 at the end of Q1 a year ago.
Pure’s Q1 fy2021 is just another strong first quarter.
Where’s the revenue growth curve blip from the pandemic? It doesn’t exist yet
Product strength
Product revenues were $246.9m, up 3 per cent, and subscription revenues climbed 37 per cent to $120.2m. Pure said US enterprise and government business held up well but noted some weakness in its general commercial sector. Pure said it experienced zero impact on its supply chain from the pandemic and was able to work round issues that came up.
The company said the FlashArray//C array, launched in September last year with QLC (4bits/cell) NAND, is its fastest-growing product.
The FlashBlade line accounted for 15 per cent of total revenues ($55.1m), with nearly 10 customers spending more than a million bucks on the product since launch. Giancarlo said: “We’re very excited about the product going forward and expect continued growth.” This implies that all three main products are doing well.
Pure sees increasing demand for public cloud-based IT and claims its Pure-as-a-Service enables customers to move from an on-premises Pure environment to a public cloud with no difficulty. Giancarlo said: “It’s the same exact software and same interface to the application environment, in the cloud, as it is on-prem and that makes their ability to migrate their applications even easier.”
Pure announced that cloud-based workflow automation business ServiceNow has become a customer, using Pure for applications including Splunk, Elastic’s ELK stack, artificial intelligence (AI), and machine learning (ML). It is using Pure’s FlashArray//X and //C and FlashBlade arrays with Pure1 management.
Pandemic effects
The company said it had not laid off or furloughed any employees and did not intend to do so.
Charles Giancarlo
Pure added 300 customers in the quarter. Not that high a number – it was 500 the previous quarter – but not that low either. The company attributed this in part to the weakness in its commercial market and also to Pure’s push for more enterprise-class customers. In the earnings call, Giancarlo said: “The lower numbers are a mix of those two things.”
He said: “There is a general risk aversion out there in the market, whether it’s new products, new features, new vendors and that’s going to be with us for a quarter or two until I think the customers have started being able to feel comfortable in putting time into testing.“
On that account Pure is not issuing any formal earnings guidance for the next quarter but suggests that revenues may be flat.
Competition
Pure’s main competitor is Dell, which this month launched its PowerStore midrange array, unifying the prior SC, Unity, VNX and XtremIO product lines.
Giancarlo commented: “Our view very simply is it opens up opportunity to replace four products. Whenever there’s a disruptive upgrade and God loves them … it opens up the opportunity to all vendors, all new vendors, because the customer is going to go through that trouble. It’s basically a brand new product. And in this case, it’s a brand new 1.0 product.”
He thinks: “This is a terrible time to come out with a new 1.0 product. Customers are risk adverse. So we really see this as a great opportunity for us.”
NetApp, another competitor, this week reported its results for the first quarter of 2020. All-flash array revenues were $656m, so Pure has some way to go to reach that level with its equivalent $367m all-flash product, service and support sales.
Giancarlo’s view of Pure’s prospects? “We will continue to take market share.”
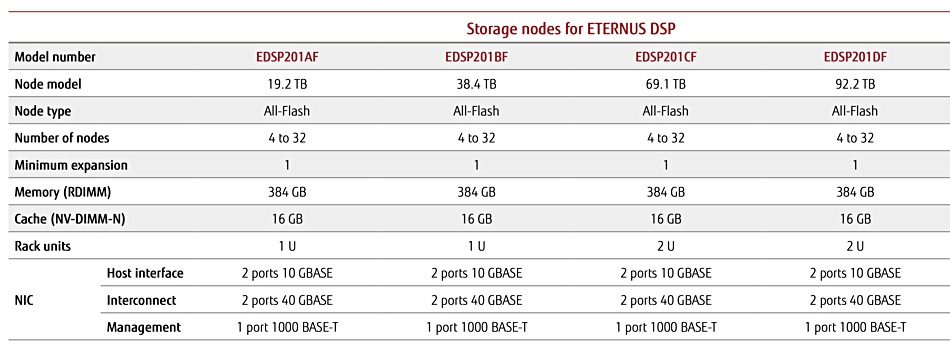
Fujitsu has announced a server-based, scale-out storage system, the first in a new line branded ETERNUS DSP.
ETERNUS is Fujitsu’s overall storage brand and DSP is short for Digital Services Platform. The new DSP200 M1 is a multi-node all-flash storage system that provides multiple petabytes of block and object storage for physical servers, VMs and containers.
The DSP200 M1 is designed for continuously available tier one performance and is a hyperscale system, according to Fujitsu. The system scales out to 2.9PB of capacity – which seems a bit on the small side of hyperscale.
The system is based on X86 server nodes – no CPU detail at time of writing – with an undisclosed number of storage drive bays. It comes in 1U and 2U enclosures.
There are four node capacity variants, all using SATA SSDs: 19TB or 38TB in a 1U enclosure, and 69TB and 92TB in a 2U enclosure. The minimum system has three nodes with 57TB capacity and it scales out to 32 nodes and 2.944PB.
Fujitsu documentation does not disclose the number of drive bays per node or the individual SSD capacities.
High capacity 2U node with 24 drive bays visible
The 2U node image above shows 24 drive bays. A 32-node maximum capacity of 2.944PB implies a per-node maximum of 92TB. Spreading that across 24 drives implies 3.83TB SSDs. This is low, considering that 15TB SSDs are readily available.
A 32-node system is claimed to provide up to 5.7 million IOPS, and latencies generally are at the 200us level. The cluster node interconnect uses 40GbitE.
The DSP software supports a maximum of 512 hosts and 4,069 LUNs. Fujitsu said there can be up to five replicas and 256 copy generations. The system provides system-wide, consistency group snapshots and features deduplication and compression.
Accessing servers use iSCSI across 10Gbit Ethernet, with two ports and NICs per node, to read and write data on the DSP system.
The self-tuning DSP software provides quality of service features. It monitors storage usage and load at each node, and can autonomously control data relocation and distribution to other nodes to balance the load. Management software is policy-driven and uses machine learning. It can be accessed by SNMP or REST APIs.
Fujitsu has not revealed any details of its object storage capabilities.
Management
There are multi-tenancy user access features, so that each user only sees and manages their own data.
New nodes can be added non-disruptively to a DSP system and have data automatically migrated to them. Existing nodes can be replaced in a sequential fashion.
Deployed systems send telemetry to a Fujitsu centre for use in system management. Blocks & Files expects this to develop into a classic predictive analytics management SaaS offering.
ETERNUS DSP is available to order in Japan and Europe starting May 28 from Fujitsu and its resellers. Pricing varies according to country and individual configuration; a typical Fujitsu pricing description, and there is a three-year warranty.
Brochureware
The ETERNUS DSP, as described in a Fujitsu brochure, is much higher spec than the DSP200 M1 and its 32 all-flash nodes.
For example the DSP “can run multiple service pools of 64 storage nodes each, and use any combination of storage device types including SATA HDD/Flash, NVMe Flash, NV-DIMM-N, rotating media, and persistent storage devices.” That’s doubled the maximum node count to 64.
Also, “the deployment of heterogeneous nodes with different hardware generations is possible.” Another DSP option is “flexible data tiering with the ability to run different price/ performance tiers in one cluster”.
So, we can anticipate more DSP announcements with support for nearline disk drives, NVMe SSDs, and Optane drives. Disk drive support will require a larger enclosure to hold the 3.5-inch drive bays needed.
Comment
Fujitsu says this is a software-defined storage system, but the software is available from Fujitsu only and it runs on Fujitsu hardware. Effectively, this is another proprietary scale-out storage system.
Today, Fujitsu announced an OEM deal with Datera, whereby Datera’s scale-out enterprise-class block and object storage runs on Fujitsu servers. Datera’s Data Services Platform is scale-out virtual SAN storage sotware that supporting bare metal servers, virtual machines and containers. It provides block and object access and is an alternative to both traditional SANs and hyperconverged infrastructure systems.
Ok – <Smacks head> – Fujitsu’s DSP is this system. Although unsaid, it is obviously based on Datera’s software. (We’re checking of course.) That means it is using Datera’s object storage with its S3 interface. And it is non-.proprietary software-defined storage.
Datera, the high-end software-defined storage vendor, has signed an OEM deal with Fujitsu, initially covering Europe and Japan.
Datera’s Data Services Platform is a scale-out virtual SAN storage software that supports bare metal servers, virtual machines and containers. It provides block and object access and is an alternative to traditional SANs and hyperconverged infrastructure systems.
Until now Fujitsu has been one of many sources of server hardware on which to run Datera’s software. It will now integrate the software into its own product set and bring it the global market. This makes Datera CEO Guy Churchward happy: “This agreement with Fujitsu… opens an additional pathway to take our leading platform to new markets.”
Datera also has an OEM relationship with HPE, which bundles its software with ProLiant DL360 servers.
Fujitsu motivation
What’s Fujitsu’s motivation here? It has Eternus storage arrays and server-based hyperconverged and converged infrastructure products in its portfolio. The reasoning is that many customers are moving away from complex SAN arrays and towards server-based storage.
Ashwin Shankar, a Fujitsu marketing manager for server products, wrote in March: “With the explosive growth in unstructured data, organisations are struggling to nail down a storage method that is easy to implement and upgrade, and that allows them to maximise capacity utilisation.[Traditional storage arrays] are often expensive, complex and lack openness…Server-based storage solutions reduce cost and complexity.”
Fujitsu server-based hyperconverged (HCI) and converged infrastructure products include:
Fujitsu Nutanix Enterprise Cloud on PRIMERGY x86 servers running Nutanix’s Acropolis OS and Prism management software
PRIMEFLEX for Storage Spaces Direct
PRIMEFLEX for VMware VSAN
Also, the company has a deal with NetApp concerning NFLEX, a converged infrastructure system with pre-integrated and tested Fujitsu PRIMERGY servers, NetApp storage and Extreme networking components. Fujitsu also has a data fabric partnership with NetApp to link Fujitsu edge servers to data centre and public cloud resources using ONTAP data management software.
Why does it need a server-based storage deal with Datera? Datera would say its software is an alternative to high-end SANs whereas mainstream HCI is for SMB and mid-range enterprise needs. We think Datera’s container support is a key point for Fujitsu.