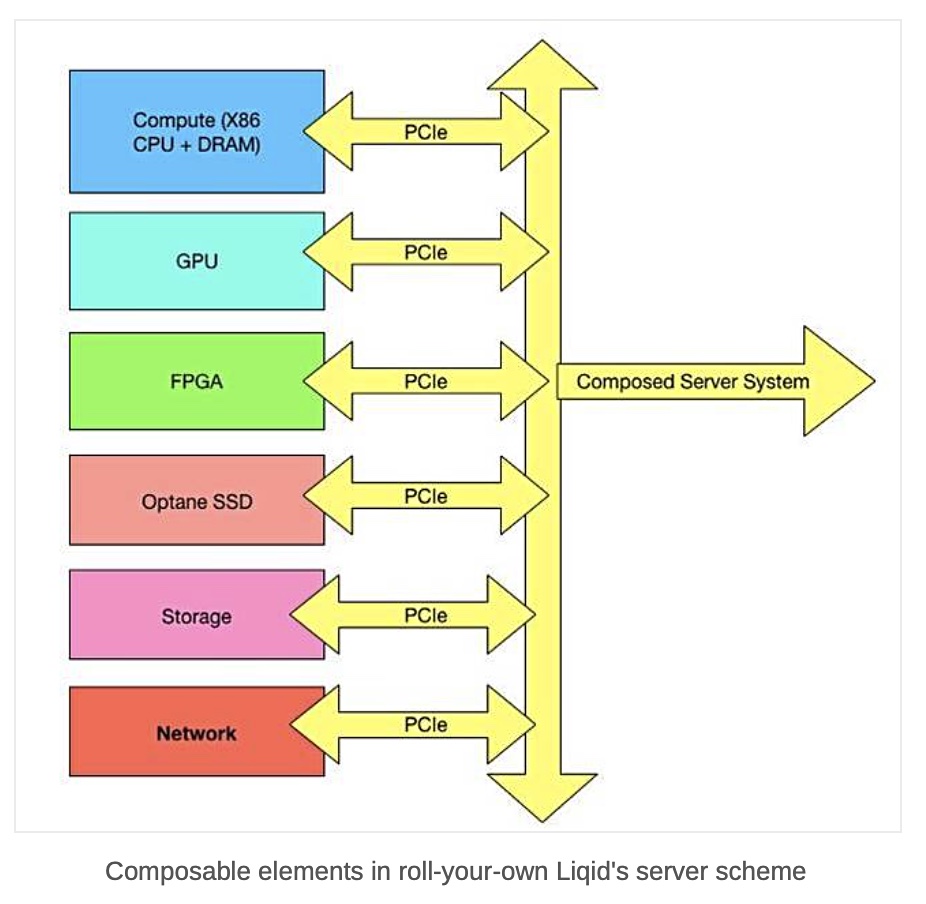
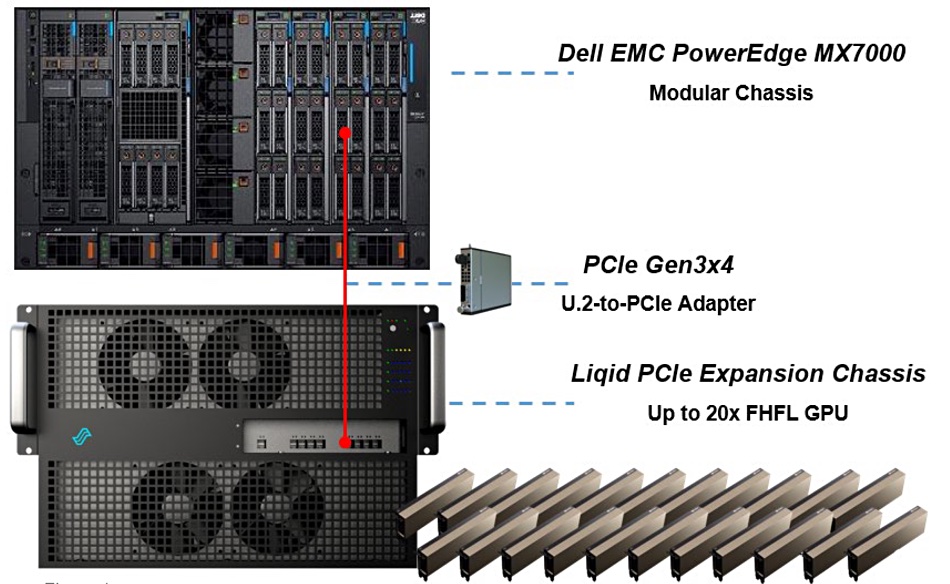
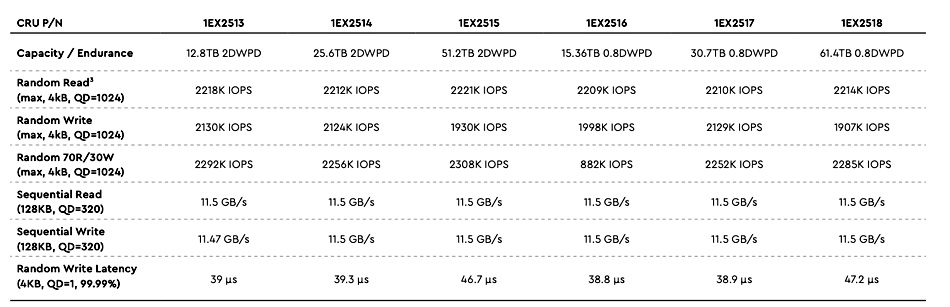
An internal effort to containerise NetApp’s ONTAP is leading to a cloud-native version of the operating system.
NetApp’s Project Astra is focused on developing application data lifecycle management for Kubernetes-orchestrated containerised applications that run on-premises and in the public clouds.

NetApp’s Project Astra lead Eric Han this week outlined progress to date via a blog post.
He said Astra’s early-access users had a common interest in wanting to run a full set of workloads in Kubernetes where the right storage is always selected, the performance is managed, application data is protected, and where the Kubernetes environment spanned on-premises and the public clouds.
The first stage of the early-access program involved Project Astra managing data for Google Kubernetes Engine (GKE) clusters with storage from the Google Cloud Volumes Service. Astra looked at unified app-data management with backup and portability, and then added logging of storage and other events, with an intent to look at persistent workloads.
NetApp is now extending Astra to handle Kubernetes Custom Resources and Operators (operators are the interface code that automate Kubernetes operations). Custom Resources are extensions of Kubernetes’ API. Han said a firm lesson is that Astra needs to work with application ISVs who are writing extensions in the form of Operators.
He also writes: “We are working to accelerate our next release into Azure to support AKS and Kubernetes in AWS with EKS.”
Then he drops a quiet bombshell: “In AWS, Google Cloud, and Azure, the Cloud Volume Service (CVS) provides storage to virtual machines. So, as part of that evolution, the Project Astra team has been redesigning the NetApp storage operating system, ONTAP, to be Kubernetes-native.”
Cloud (Kubernetes)-native ONTAP
A Kubernetes-native ONTAP is intended specifically to run in a Kubernetes-orchestrated environment – a strict subset of the cloud-native environment – and so is able to use all of Kubernetes’ features.
We note that Kubernetes-native ONTAP could in theory run on any Kubernetes cluster, whether on-premises or in the public clouds.
Han blogs: “This containerised ONTAP now powers some of the key regions in the public cloud, where customers see a VM volume that happens to be backed by a microservice architecture.”
He asserts: “Users really want a common set of tools that work for stateless and stateful applications, for built-in Kubernetes objects and extensions, and that run seamlessly in clouds and on-premises.”
We can expect a public preview of Project Astra in the next few weeks or months.
Comment
Much, maybe most, of NetApp’s business comes from selling its own hardware, running ONTAP software, being deployed on premises and paid for with perpetual licenses and support contracts. But by making ONTAP Kubernetes-native the lock-in to NetApp hardware is removed.
If the various ONTAP data services were also turned into Kubernetes-native software NetApp’s customers could in theory run their complete NetApp environments on commodity hardware and in the public clouds, presumably on a subscription basis. It’s the cloud way.