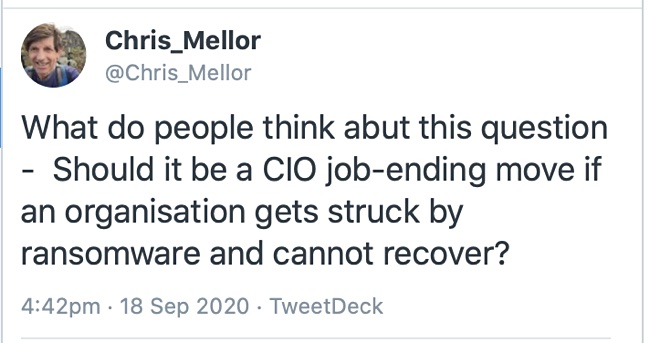
A ransomware attack happens. An organisation has to pay a ransom to get its encrypted files back. Why? Because there were no clean backup copies. At first sight, this appears negligent. So who’s to blame? Suppose the CEO said to the CIO: “Why should you keep your job?”
What reasonable response could the CIO make?
- It was a supplier’s fault; the ransomware protection technology failed.
- It was a staff member’s fault; they didn’t do what I directed.
- It was very clever ransomware; no-one could have predicted that type of attack.
- It was the business’ fault; it didn’t do what I recommended as I described in these mails and documents, which you saw.
Apart from number 4, the CEO might say: “But it happened on your watch and you are responsible.”
Heads should roll?
I asked my part of the Twittersphere what it thought. The answers are personal views.
Supercomputing engineer OxKruzr replied: “”Offline backup of critical data” is something that is just foundational to the [CIO] position.”
Andre Buss, a UK technology analyst, agreed that the CIO should go: “Absolutely – there are enough mitigations that any competent CIO should have in place to recover from this. If not, they are not on top of their brief.”
Yev Pusin, director of marketing at Backblaze, tweeted: “We think about ransomware a lot, and while I hate to put that much weight on it, if the company is unable to withstand the fallout, meaning if it is company ending, then I think so. It may even be career-ending.”
He added: “I always try to give the benefit of the doubt, so that’s why I’m thinking about it in terms of total exposure. If you lose some of your design assets, unless you’re a design firm it may not be company fatal but if you’re losing client data financial information, it’s bad.”
Flashdba, a staffer at an all-flash array software supplier, thought the affected organisation would “need to take into account tenure in the role. Some organisations take a long time for a new CIO to affect change, even for something so obviously critical as this.” That seems reasonable.
Andrew Dodd worldwide marcoms manager at HPE’s storage media devision, thought the CIO’s head should roll “only if there’s evidence of extreme negligence as to the risks. Otherwise, ransomware is just too prevalent and cybercriminals too well resourced and focused for businesses to be immune, however well prepared. Never say never – and always backup to an OFFLINE target.” This relates to the number 3 and 4 defences above.
‘Joshuad_’, a UK based techie, said: “I definitely think [the CIO should go], unless they’ve highlighted the risk before and been shot down.” That’s the number 4 defence in a nutshell.
Not just the CIO
Other respondents thought the responsibility was greater than that of CIO’s North Carolina-based Chad Richardson pointe to the Chief Technology Officer (CTO) as well: “I feel like that would fall more to the CTO. If it was negligence to prioritise spending for that scenario it would be the CIO.”
VMware marketeer John Nicholson looks higher up the business hierarchy for the responsibility, to the CFO’s office: “Allow shareholders to sue the external auditors who didn’t identify this as a business risk. If the CFO signed off on a quarterly filing that didn’t detail their risk exposure, he should be barred from being an officer of a public company for 5 years.”
He added: “Expecting a silo inside a company to police itself at scale is madness. We have an audit and reporting framework. They should be leveraged.”
If not now, when?
Ransomware is vast in its scale and impact but in essence it is just a new form of data loss.
The best defence is to to get prepared. Get yourself guaranteed clean copies of files (and objects and databases) that can be restored quickly – and document this.
Nearly all data protection suppliers now offer ransomware protection. For example; Acronis, ArcServe, Actifio, Asigra, Clumio, Cohesity, Commvault, Dell EMC, Druva, Exagrid, HPE, HYCU, Rubrik, StorageCraft, TMS, Veeam, Veritas and many more.
And let’s not forget that the IT department has used RAID, backup technology and DR for decades to guard against drive, system failures and user errors such as inadvertent deletion. In essence, these are ways to create data copies so that data on crashed drives can be recovered through a rebuild process.
Cohesity’s marketing VP Chris Wiborg said: “For most of our customers, this conversation has shifted from ‘if’ to ‘when’ they will be subject to such an attack.
“Our advice to CIOs would be to ensure their current backup and recovery provider provides at a minimum: immutability, anomaly detection, and the ability to instantly restore data and applications en masse so that recovery is ensured and this never becomes a question they have to face.”