WekaIO, the very fast file access startup, this week released the Limitless Data Platform. As far as we can see this packages old news under a new label.
Weka claims Limitless Data Platform is storage without equal, helping accelerate outcomes and improving productivity in the hybrid cloud. So-called key enhancements include Snap2Object now supporting snapshots being stored on-premises or in the public cloud or both.
However this snapshot feature was previously announced in March 2020, when Weka stated: “Weka’s unique snap-to-object feature allows users to easily create a replica of the production data and instantly push it to any S3 object store — on-premises or in the cloud — enabling snapshot-based replication.”
Other new features mentioned in this announcement are also pre-existing. For example;
Enterprise-Grade Security using XTS-AES 512 bit keys. This was mentioned in a blog by then CTO Andy Watson in October 2019.
Any Hardware: Weka can be deployed on industry-standard AMD or Intel x86-based servers supporting PCIe v4. AMD and PCIe gen 4 support was mentioned in a Weka and Supermicro document in November 2020.
Your Cloud. Your Way. Weka’s Cloud-Native architecture enables customers to dynamically scale up or scale down resources in the Cloud-based on workload requirements. This was mentioned in a 2020 ESG review which said: “The storage capacity can scale by adding NVMe SSDs to a server, by adding more servers with NVMe devices, or by allocating additional S3 capacity, and the performance can scale by allocating additional CPU cores or adding server instances to the global namespace.”
Weka’s Limitless Data Platform announcement did not mention a new version of its software. We’ve asked the company what is actually new in this announcement. Ken Grohe, President and Chief Revenue Officer, told us: “No new software. We are taking this occasion to showcase the 16+ features that we have delivered to the market over the last 8 months that have been hidden until 2/2/21.”
He added: “The brutal truth is that people still find us from speed, and buy us the first time for speed reasons. But their next 3-8 purchase over the next 2 years post initial deployment now are a repeatable and measurable 7-9 times the initial $$ and PB size deployments across NVMe tier, Object store, and Cloud as validated by the leader in autonomous driving, Life Sciences, and the US Federal Government etc and are expanding their Weka footprint for Simplicity and Scale reasons.”
Disk drive IO limitations will cripple the use of larger disk drives in petabyte-scale data stores, according to VAST Data’s Howard Marks, who says Flash is the only way to go as it can keep up with IO demands.
Marks is a well-regarded data storage analyst who these days earns his crust as “Technologist Extraordinary and Plenipotentiary” at VAST Data, the all-flash storage array vendor. Happily for the industry at large, he continues to publish his insights via the VAST company blog.
Howard Marks
In his article The Diminishing Performance of Disk Based Storage, Marks notes that disk drives have a single IO channel which is fed by a read/write head skittering about on the disk drive platters’ surface. This takes destination track seek and disk rotation time, resulting in 5ms to 10ms latency.
This is “20-40 times the 500μs SSD read latency” and limits the number of IOs per second (IOPS) that a disk drive can sustain and also the bandwidth in MB/sec that it can deliver.
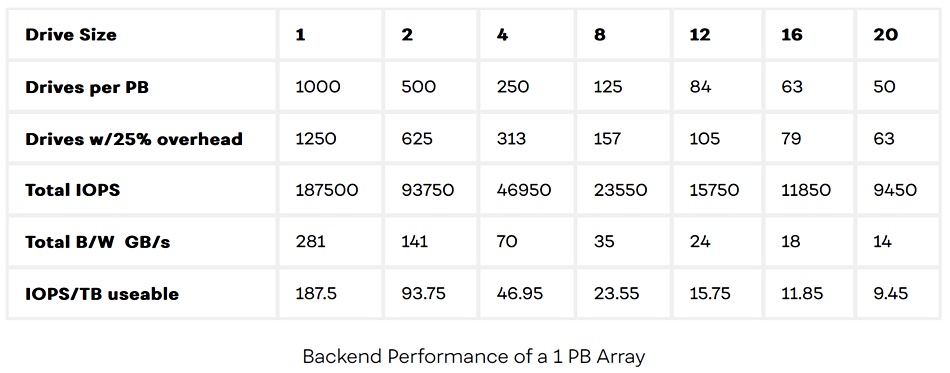
“As disk drives get bigger, the number of drives needed to build a storage system of any given size decreases and fewer drives simply deliver less performance,” Marks writes. He illustrates this point about overall IOPS and bandwidth with a table based on a 1PB array with 225MB/s of sustained bandwidth and 150 IOPS per drive:
Disk drive capacity numbers and performances in a 1PB array
This table shows 1,000 x 1TB drives are needed for a 1PB array, dropping to 50 x 20TB drives. He concludes: “As disk drives grow over 10 TB, the I/O density falls to just a handful of IOPS per TB. At that level, even applications we think of as sequential, like video servers, start to stress the hard drives.”
I-O. I-O. It’s off to work we go (slow)
He says disk drives cannot get faster by spinning faster because the power requirements shoot up. Using two actuators (read/write heads or positioners in his terms) per disk effectively splits a disk drive in half and so can theoretically double the IOPS and bandwidth. “But dual-positioners will add some cost, and only provide a one-time doubling in performance to 384 IOPS/drive; less than 1/1000th what an equal sized QLC SSD can deliver.”
Marks also points to the ancillary or slot costs of a disk drive array – the enclosure, its power and cooling, the software needed and the support.
He sums up: “As hard drives pass 20TB, the I/O density they deliver falls below 10 IOPS/TB which is too little for all but the coldest data.”
It’s no use constraining disk drive capacities either.
“When users are forced to use 4 TB hard drives to meet performance requirements, their costs skyrocket with systems, space and power costs that are several times what an all-flash system would need.”
“The hard drive era is coming to an end. A VAST System delivers much more performance, and doesn’t cost any more than the complex tiered solution you’d need to make big hard drives work.”
Comment
As we can see from the 1PB data store example that Marks provides, 50 x 20TB drives pumps out 14GB/sec total while 500 x 2TB drives pumps out 141GB/sec. Ergo using 50 x 20TB drives is madness.
But today 1PB data stores are becoming common. They will be tomorrow’s 10PB data store. Such large arrays will need more drives. Therefore, as night follows day, and using Marks’ own numbers, the overall IOPS and bandwidth will grow in proportion.
A 10PB store would need 500 x 20TB drives and its total IOPS and bandwidth can be read from the 2TB drive size column in Marks’ table above – i.e. 141GB/sec. Data could be striped across the drives in the arrays that form the data store and so increase bandwidth further.
Our caveats aside, Marks raises some interesting points about disk drive scalability for big data stores. Infinidat, which builds big, fast arrays incorporating high-capacity hard drives, is likely to have a very different take on the matter. We have asked the company for its thoughts and will follow up in a subsequent article.
Brett Shirk, Rubrik’s Chief Revenue Officer, resigned late last month, according to our sources. The data protection vendor has declined to answer our questions about this.
Rubrik’s front bench has seen multiple changes in recent months. What’s going on?
Executives who have left the company include:
Ann Boyd , VP Communications – Jan 2021 – joined in August 2020.
Murray Demo, CFO – resigned Sep 2020, left Jan 2021. Kiran Choudary promoted to take over.
Jeff Vijungco, Chief People Officer – left in January 2021, having joined in 2018.
Chris Wahl – Chief Technologist – Dec 2020.
Rinki Sethi – SVP and Chief information Security Officer – left in September 2020.
Shay Mowlem – SVP Product and Strategy – left in September, 2020. He joined in April 2018.
Avon Puri, CIO left in June 2020.
Brett Shirk
Prior to joining Rubrik in February 2019, Shirk was the GM of VMware’s America’s business. Before that he was the EVP for worldwide sales at Veritas. At Rubrik, he was responsible for driving Rubrik’s global go-to-market strategy and reported directly to Rubrik CEO Bipul Sinha.
At the time of his appointment, Sinha said Shirk’s “unparalleled expertise scaling world-class teams, ability to capitalise on changing market dynamics, dedication to partners, and customer-first mentality will be invaluable to Rubrik as we continue our global expansion.”
Rinki Sethi was hired as an SVP and Chief Information Security Officer in April 2019, coming from IBM, and she left in September 2020 to become a VP and CISO at Twitter.
When Shirk was hired Rubrik said it had expanded its executive team in 2018 with several high profile hires from leading technology companies, including: Chief Financial Officer Murray Demo (Atlassian), CIO Avon Puri (VMware), Chief Legal Officer Peter McGoff (Box), Chief People Officer Jeff Vijungco (Adobe), and SVP of Product & Strategy Shay Mowlem (Splunk).
Demo, Puri, Vijunco and Mowlem have all since left, as has Sethi, and it looks as if Shirk has followed them out of the door.
Veritas has extended NetBackup protection to OpenStack, courtesy of technology licensed from Trilio.
Veritas incorporated TrilioVault technology into the recently-announced NetBackup 9.0 Doug Mathews, Veritas VP of product management, said in prepared remarks: “Veritas NetBackup is a market leading enterprise backup and recovery solution that has been adopted by eighty-seven percent of the Fortune Global 500 companies. We maintain our leadership by continually seeking new ways to make our products better and working with innovators like Trilio is a great example.”
Trilio, a Kubernetes data protection startup which raised $15m in B-round funding in December, expressed its delight with the NetBackup deal. This is entirely understandable given the size of Veritas’s customer base
Trilio has three developed three flavours of TrilioVault software:
TrilioVault for Red Hat Virtualization to product apps and virtual machines (VMs)
TrilioVault for OpenStack is natively-integrated into OpenStack and looks after bare metal and VM environments
TrilioVault for Kubernetes protects Kubernetes-orchestrated containers.
The Veritas deal is for TrilioVault for OpenStack and not the other variants. A spokesperson confirmed that it does not cover containerised application protection.
Doug Matthews, Veritas’ VP of Enterprise Data Protection and Compliance, told us NetBackup already protects containers and does not need top use TrilioVault for this: “Veritas has supported Kubernetes in NetBackup since version 8.1 was released in 2017. Veritas offers a NetBackup client that can be deployed as a container, which can be used to protect application data stored either on persistent volumes or using a staging area.”
Four of the most important domesticated silk moths. Top to bottom: Bombyx mori, Hyalophora cecropia, Antheraea pernyi, Samia cynthia. From Meyers Konversations-Lexikon (1885–1892)
Interview: Chris Buckel is the VP for biz dev at Silk, a data storage startup based in Massachusetts that used to be called Kaminario. In a recent article, The Battle For Your Databases”, he wrote about the efforts of public cloud titans to win over relational databases, which are the last hold-out of mission-critical on-premises applications. We asked him to expand his thoughts via this email interview.
Blocks & Files: In your blog post you say, “Pretty much every company with an on-prem presence will have one or more relational databases underpinning their critical applications… These workloads are the last bastion of on-prem, the final stand of the privately-managed data centre. And just like mainframes, on-prem may never completely die, but we should expect to see it fade away this decade.” The reason is the hyperscalers (AWS, Azure and GCP) want them. Why?
Chris Buckel
Chris Buckel: For the public cloud vendors, this is the biggest game still left on the on-prem hunting ground. These business-critical databases are not only important workloads themselves – belonging to enterprise customers who are used to paying heavy costs to run them – but they also support a rich ecosystem of applications around which the hyperscalers can build their high-value offerings like AI and analytics. The phrase being used is “anchor workloads” because these are the anchors which hold back entire, revenue-rich environments from reaching the cloud, keeping them stuck in on-prem purgatory.
Blocks & Files: Aren’t these mission-critical RDMS apps and their data too big to move? Even for AWS Snowball? How will the hyperscalers try to persuade businesses to move their RDBMS app crown jewels to the public cloud?
Buckel: It feels like it, right? But then you have to ask yourself what you mean by “too big to move”. Big as in capacity? Many of the world’s most important transactional databases are less than a few terabytes in size – the rate of change is high, but the actual footprint is surprisingly small. Or maybe “too big” means too critical, too complex, too risky? Before the cloud, database upgrade or migration projects would take months or years.
But this is a different ball game: CIOs and executive boards are embracing the cloud for financial reasons, like exiting the boom and bust cycle of 5 year IT hardware refreshes; outsourcing operational IT to specialist, hyperscalers who can deliver economies of scale; moving to a flexible Opex-based cost model. Whether this dream is a reality or not is still to be decided, but very few companies want to own their own infrastructure anymore, so this journey really does feel inevitable.
Blocks & Files: Do you know of any public cloud efforts to attract mission-critical RDBMS-type applications?
Buckel:All of the major cloud vendors are fighting for these workloads right now. It’s no secret that AWS has been hiring enterprise salespeople for years, building its impressive range of RDS (managed) database services: Oracle, SQL Server, Postgres, MySQL etc. Microsoft – who arguably has the best enterprise credentials of the Big Three – is actively targeting its MS SQL customer base and searching out Oracle customers to bring into Azure.
Google, disadvantaged by Oracle’s refusal to support its eponymous database on GCP, is heavily pushing its Cloud SQL managed service for everyone. Finally, Oracle is obsessed with getting as many of its on-prem customers into the Oracle Cloud as possible, before time runs out. This includes some interesting policy decisions about which products are supported in which clouds, plus the commercial carrot and stick of licensing discounts and – allegedly – audits.
Buckel:It’s always possible – and some outliers will crop up to make headlines. But in most cases, moving these platforms to the cloud represents a wholesale shift in mindset, in company focus, in roles and responsibilities… If you want to go back, it means undoing a lot of work – you would have to really want it.
On the subject of egress charges, again most databases aren’t actually that big – especially if you can extract or export the raw data. Dropbox is an unusual example because they were a file storage company using AWS as the underlying storage. Given the relatively low margins in their business model, I suspect it was hard to maintain a solution where both Dropbox and AWS made a profit.
Blocks & Files: Do you think webscale companies will retain their data centres (and mission-critical applications) while sub-webscale data centres will move to the public cloud?
Buckel:I personally do not see on-prem dying out; I envisage a long fade away into obscurity in perhaps the same way as mainframes. But it does seem inevitable that workloads will continue to migrate to the hyperscalers over time, which will cause a slow but inexorable rise in the price of on-prem computing. On the other hand, the stellar growth experienced by the hyperscalers cannot continue forever – and what happens then? Could prices increase? If that happened, a lot of cloud customers could find their options very limited given the small number of serious public cloud players in the market.
Blocks & Files: How will non-cloud-native RDBMS app suites be migrated to the cloud? As virtual machines? Is it a massive migration exercise? Can consultancies help?
Buckel:This is a very interesting question. Oracle Database was first released in 1979, DB/2 in 1983, Microsoft SQL Server in 1989. These amazing database products, which still run so many businesses today, were not designed with highly distributed cloud-scale architectures in mind. And Oracle won’t even support the use of its scale-out clustering software outside of the Oracle Cloud.
But the real issue is the complexity of these environments; many will contain untold lines of business logic, written by long-since-departed developers. Moving this into a new database product like CloudSQL, or a managed DBaaS service like RDS, might be too difficult, so IaaS will be the compromise for many. Also, many business-critical databases require high levels of performance which either aren’t natively available in the cloud or are very expensive.
In fact, at Silk we are seeing that performance in the cloud is the single biggest blocker for RDBMS cloud migrations – it’s the number one reason customers engage with us. Consultancies will therefore be key here, as will in-house migration teams at the hyperscalers. Customers will want to be reassured by people who do this all day long.
Blocks & Files: With the rise of edge computing will it matter if the central data centre is hollowed out and its applications go to the public cloud?
Buckel:The nature of these classical RDBMS systems means they are centralised, so while edge computing might play a role at the application level, the database layer is destined to remain as the big, black hole of data around which everything else gravitates.
At least until these platforms are retired in favour of newly-designed, containerised cloud-native applications written by immaculately bearded, t-shirt wearing developers working in Shoreditch basement offices full of exposed brickwork and table-tennis tables. But hey, as a former Oracle guy I’m still a bit sore about finding my old technical skills on the wrong side of the word “legacy”.
Blocks & Files: Is some kind of hybrid model possible, with the on-prem RDBMS app bursting to the public cloud?
Buckel:Yes – it’s a choice which makes sense for many customers. But, architecturally, it’s challenging to take a classical RDBMS application – for example Electronic Patient Records in healthcare, or Warehouse Management in retail – and distribute it so that some users are accessing one location on-prem while others are accessing a public cloud location (a type of design known as “sharding”).
RDBMS is just a very centralised approach to data, so unless the application was already designed with sharding in mind, this may fall into the “too hard” bucket. A more common approach, which we see with Silk customers, is to move the DR site into the public cloud and keep production on-prem (for now). The benefit here is that the cloud DR site can be kept very small, to control cost, but in the event of a failover it can be scaled up (via APIs) to whatever size is appropriate for the necessary performance.
Blocks & Files: What would Silk advise customers to do?
Buckel:Firstly, we advise anybody who is about to renew on-prem database infrastructure to seriously evaluate the public cloud options. Five years is a long time to commit to another stack of on-prem big iron. No database is too big or too performance-hungry to run in the cloud – for example, we are currently helping a bunch of Oracle Exadata customers get the performance they need to move to one of the hyperscalers – so even if now isn’t the time, it makes sense to have a roadmap.
The other bit of advice I give customers is to take a hard look at the cloud roadmap of their on-prem infrastructure vendors. Every vendor has a “Cloud” page on their website, but scratch beneath the surface and many of them offer no value above what you can get direct from Amazon, Microsoft or Google – while some literally run a virtualised version of their product in a cloud VM and think that’s enough to underpin a hybrid cloud story. It’s never been easier to walk away from these guys, so if you are going to give them your money, make sure they are earning every penny.
Databricks has raised $1bn in a G-round that values the data lake analytics startup at a ginormous $28bn. The long list of investors includes AWS and Salesforce among a clutch of financial institutions.
Databricks enables fast SQL querying and analysis of data lakes without having to first extract, transform and load data into data warehouses. The company claims its “Data Lakehouse” technology delivers 9X better price performance than traditional data warehouses. Databricks supports AWS and Azure clouds and is typically seen as a competitor to Snowflake, which completed a huge IPO in September 2020.
Ali Ghodsi, CEO and co-founder of Databricks, said in the funding announcement: “We’ve worked with thousands of customers to understand where they want to take their data strategy, and the answer is overwhelmingly in favour of data lakes. The fact is that they have massive amounts of data in their data lakes and with SQL Analytics, they now can actually query that data by connecting directly to their BI tools like Tableau.”
The result is, the company says, data warehouse performance with data lake economics. “It is no longer a matter of if organisations will move their data to the cloud, but when, “Ghodsi said. “A Lakehouse architecture built on a data lake is the ideal data architecture for data-driven organisations and this launch gives our customers a far superior option when it comes to their data strategy.”
Prestissimo
Databrick’s open source Delta Lake software is built atop Apache Spark. The company’s SQL Analytics software queries data in Delta Lake, using two techniques to speed operations.
By auto-scaling endpoints for its query cluster nodes, query latency is consistently low under high user load. The software uses an improved query optimizer, and a caching layer that sits between the execution layer and the cloud object storage. It also has a ‘polymorphic vectorised query execution engine’, called Delta Engine, that executes queries quickly on large and small data sets. A Slideshare presentation deck with 88 slides delves deeper into the general technology while a video provides even more information about Delta Engine.
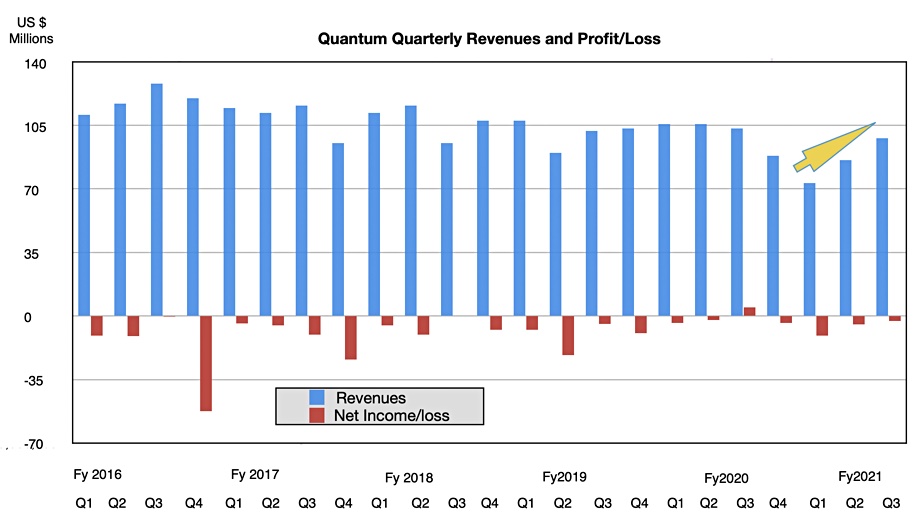
Quantum’s third fiscal 2021 quarter revenues ended December 31 were $98m, down 5.1 per cent and net income was -$2.7m, down from $4.7m. But Chairman and CEO Jamie Lerner was upbeat on the earnings call.
The veteran tape storage vendor said it became a self-sustaining business in the previous quarter and it has gone one better this time by achieving breakeven on an internal measure, according to Lerner.
“It was a great quarter… and we’ll keep everyone updated on our transformation as we move as quickly as we can to transform ourselves into a more profitable, more earnings rich company as we transition to software, services and subscriptions.”
Quantum’s revenues were “coming off the COVID related lows in the first fiscal quarter… Our average deal sizes have been increasing steadily over the past two years and increased 24 per cent year-over-year. … We closed a record number of six and seven figure deals in the quarter.“
CFO Mike Dodsonsaid: “We are… encouraged by the early signs of a recovery in our media and entertainment business. Keeping in mind, the year-to-date revenue is running just over half of last year’s level for the same period. This reflects the significant impact COVID has had on this end market segment.”
However, the pandemic also fuelled online sales and that has caused increased data storage requirements which benefits Quantum; eg, in the tape archival storage area for webscale and hyperscale customers.
Dodson said: “We really saw an increase across all the products, all the verticals, everything was up with the exception of service was plus or minus flat.”
Hyperscale, webscale and product breadth
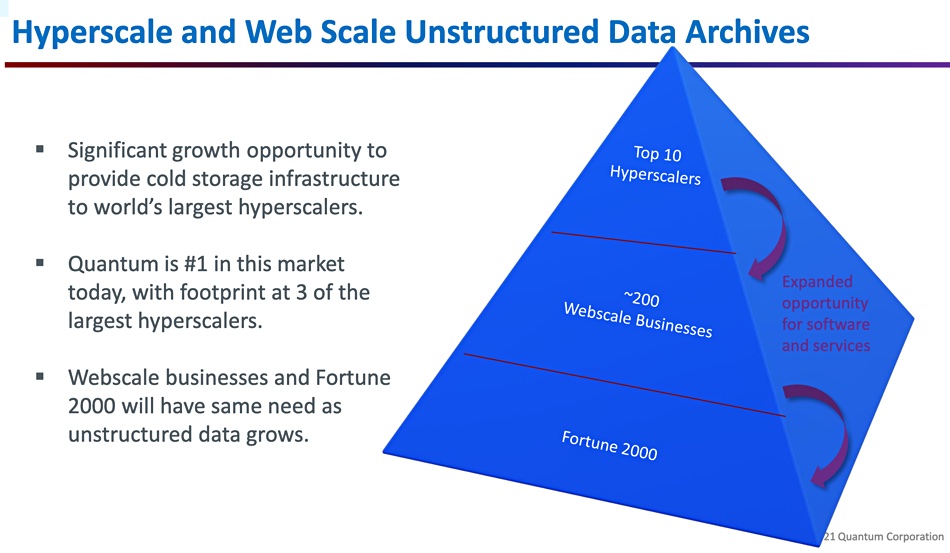
Lerner claimed Quantum is the biggest supplier of unstructured data archiving products to the hyperscale-webscale market.
“We put a lot of energy in our sales efforts with the top eight to 10 cloud and hyperscale customers just because of just how massive their buying power is. But we also put energy to the next 200 or so accounts beneath that in the web scale companies, maybe not at hyperscale, but they certainly are -certainly of scale and then the Global 2000, all of which have data they need to archive for decades, if not longer.”
“Obviously, we started at the top of the pyramid, but we’re pressing down. And the goal is, we need much more diversity in our install base. Having one or two very large customers is great. But that comes with all the issues of having just a handful of customers,” He pointed out.
He added: “We went from just selling tape hardware to now selling tape hardware, tape management software, storage software and now some of our primary software and hardware.”
The same is true for other customers: “So there were tiers of storage we didn’t use to have, right? We didn’t use to have flash storage. We gave up those sales to other people. Now we have that. We didn’t have mid-range storage. We would give that up to someone like Isilon at EMC. Now, we –with the ATFS, we actually have that midrange.”
“So the existing customers where we had gaps, we now can sell them the full range of storage they need instead of saying, you can buy some from Quantum, but you have to fill the gaps with other competitive vendors. We can now do end-to-end sales.”
What’s next
Quantum, once a $1bn/year tape-based data protection business, now sells three classes of product:
File Management – StorNext file system, ATFS NAS platform, and surveillance, IoT and Edge appliances – ATFS was added through acquisition
Analysis – CatDV asset management platform – added through acquisition
As well as broadening its product base Quantum is transitioning to adding a subscription business models.
Lerner mentioned “future product offerings, such as an all in one media appliance that will run StorNext and CatDV in a single H-Series hyper converged storage server.” This will be aimed at video production segments such as corporate video, sports, government and education markets. He said Quantum has the “potential to eventually expand the software to other markets such as genomic research, autonomous vehicle design, geospatial exploration and any use case dealing with large unstructured data.”
Financial summary
Financial summary
Gross margin – 43.1 per cent.
Cash and cash equivalents – $17.4m.
Product Sales – $63m compared to year-ago $66.4m.
Note the most recent two quarters exhibit strong revenue growth
This week, HPE announced it has sold a neat Qumulo system on its Apollo server for image processing, and Replix emerged from stealth as a containerised app data protector. We have also compiled the usual collection of news snippets from around the industry.
HPE and Qumulo store files for Rapid Image
Sweden-based Rapid Images replaces traditional 2D photo and film production with 3D-based technology. Its services are used by numerous industries to help companies market and sell their products and services online. It needs to look after a heap of unstructured data, a heap that has grown as the pandemic increased online shipping volumes – meaning more screen images.
Rapid Images graphic.
Rapid IMages bought an HPE Apollo 4210 Gen 10 server with Qumulo Core scale-out file storage software. Rapid Images has developed an in-house Image Rendering Platform (IRP) running on this which requires instantaneous access to millions of files. It uses complex algorithms to translate and process artist’s instructions, and so produce thousands of images using clustered rendering.
Rapid Images says it now has a highly available, cost-effective file storage system for IRP, with real-time visibility of usage and performance.
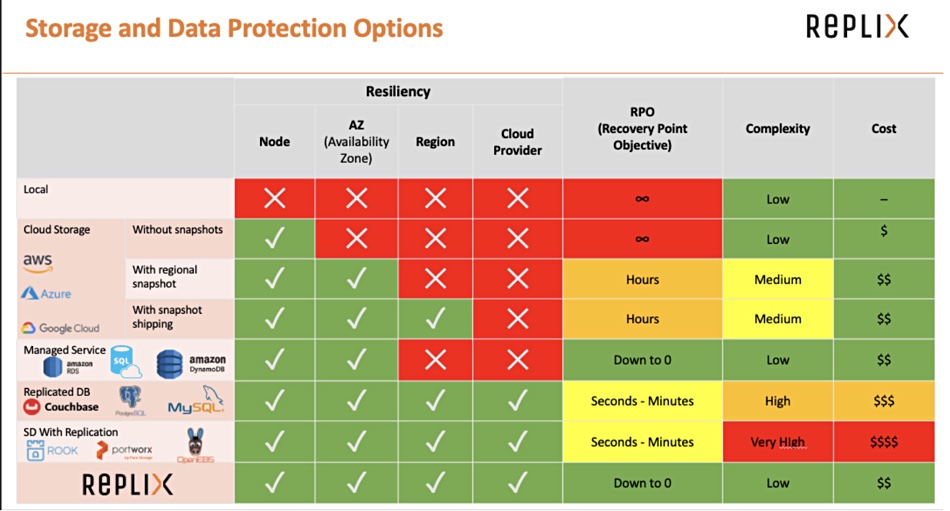
Replix protects Kubernetes containers data
Replix, another startup protecting Kubernetes-orchestrated containers has emerged from stealth. The Israel-based company said the Replix Global Data Fabric protects and moves stateful containers between multiple public clouds. Competitors already doing this include MayaData, Pure’s Portworx, Robin, Trilio and Veeam’s Kasten.
We asked Replix what it had that was so special. A spokesperson told us: “While they are many solutions that protect Kubernetes data, Replix enables synced replicated data across AZ, Region and cloud provider. With Replix, sStateful applications can resume operations with the same flexibility and self-healing capabilities as stateless applications.”
Replix competitive positioning
“Replix is a fully managed service that does not require any installation, networking configuration or maintenance and is consumed as a service, without any upkeep establishment cost.”
With Replix you’re able to move your workloads between multiple Kubernetes clusters in different regions or clouds in just a few seconds, with all your stateful application retaining their data up to the last transaction.
Short shorts
ChaosSearch said 2020 was a record-breaking year, with the customer count tripling and revenue growing almost 8X.
Clumio has released a Splunk app to supply insight and visibility into Clumio audit logs. The utility is generally available and live on Splunkbase.
GigaSpaces, the in-memory-computing startup, this week said it doubled annual recurring revenues in 2020 and doubled the number of subscription customers for the second year in a row.
Infinidat, the enterprise storage array maker, experienced “a surging uptick in growth of half an exabyte in the fourth quarter of 2020”. The company report 7EB of data is stored in its arrays. compared with 6EB recorded in February 2020. The company claims its total storage deployed is higher capacity than the top eight primary storage all-flash array (AFA) vendors shipped in 2020. Infinidat anticipates customer demand for petabyte-scale systems is expected to accelerate its growth in storage deployments.
Nvidia violates the Transaction Processing Performance Council’s Fair Use Policy. The council announced that, in the paper “State of RAPIDS: Bridging the GPU Data Science Ecosystem,” presented at Nvidia’s GPU Technology Conference (GTC) 2020, and in associated company blogs and marketing materials, Nvidia claims that it has “outperformed by nearly 20x the record for running the standard big data analytics benchmark, known as TPCx-BB.” Since Nvidia has not published official TPC results, and instead compared results from derived workloads to official TPC results, the comparisons are invalid. The council is working with NVIDIA to resolve the issue and make all relevant corrections.
Rubrik’s largest MSP customer, Assured Data Protection, has launched ProtectView, a centralised platform that enables businesses to run their entire Rubrik estate via a single management user interface.
Scale Computing said it hit record revenues in 2020 with revenues growing 45 per cent in 2020. HCI and edge systems startup said it is now profitable.
Digital business initiatives are fuelling an increased emphasis on creating, storing, and using data, leading to increased adoption of all-flash object storage. That’s the findings of market research conducted by ESG on behalf of Scality. According to the report, all-flash object storage is early in the adoption phase but will become pervasive. Although 95 per cent of respondents use flash in object environments, only 23 per cent use an all-flash storage system today. Eighty-seven per cent of respondents not currently using all-flash object storage expect they will evaluate the technology in the next 12 months.
StorONE claims its vRAID 2.0 rebuilds failed drives faster than anything else. A 1PB StorONE system using 14TB drives can complete rebuilds in less than two hours. Competing technology takes days to achieve a similar rebuild, StoreONE says. The company has verified its claims using Seagate’s Application Platform 5U84 server with 14 flash drives and 70 x 14TB hard disk drives. It rebuilt failed SSDs in under four minutes and says most vendors report eight-plus hours of rebuild times for flash volumes.
Western Digital’s Q2 revenues out-stripped expectations on the back of strong client-side and retail sales for disk drives and flash device. Yesterday’s earnings announcement saw the company’s stock jump 10 per cent in after hours trading. However, the strong financials also highlight WD’s continuing weakness in two key areas – nearline enterprise disk drives and enterprise SSDs, where it has fallen way behind the competition.
WD generated $3.93bn revenues for the quarter ended December 31, 2020. Net income was $62m – much better than the year-ago loss of $163m. Disk drive revenues totalled $1.9bn, down 20 per cent, and flash revenues climbed $2.03bn to 10.7 per cent. WD’s disk drive unit ship number was 25.7 million, down 22 per cent.
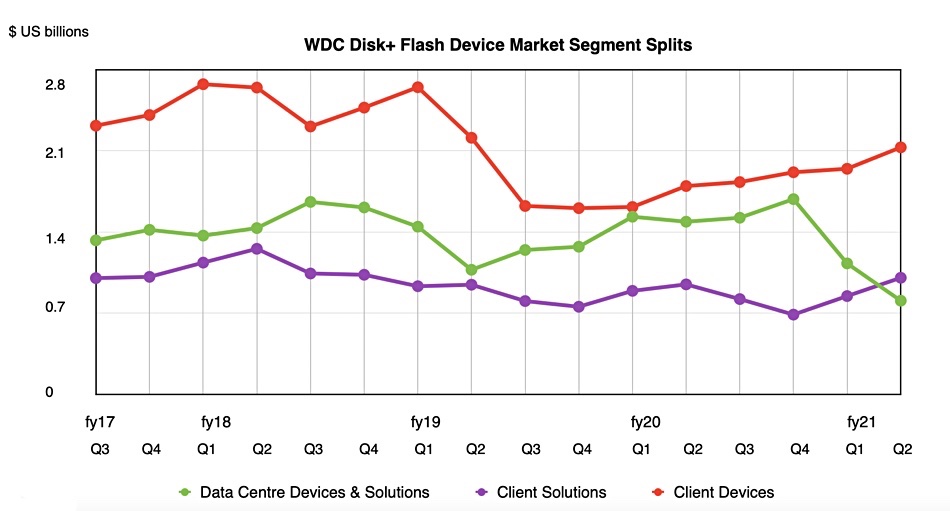
WD three business segments had contrasting fortunes in the quarter, as the revenue splits show.
Data Centre Devices and Solutions – $807m, down 46 per cent Y/Y,
Client Solutions (Retail) – $1.005bn, up 6 per cent
Client Devices (Notebook/PC) – $2.13bn, up 19 per cent.
Charting their revenues over the past few quarters show contrasting fortunes – and two quarters of steep decline in the data centre segment.
There are two reasons for the data centre poor performance. WD has ceded nearline disk drive market leadership to Seagate’s 16TB drive; and it has effectively no presence in the enterprise SSD market – just one per cent, according to TrendForce estimates.
“The positive side of WD’s eSSD results over the past few quarters, in our opinion, is that it is hard to see things get worse,” Wells Fargo analyst Aaron Rakers wrote in a note to subscribers.
The difference between Seagate and WD in enterprise disk capacity shipments is stark. Rakers estimates “WD’s nearline HDD capacity ship at ~56-57EBs, representing more than a 20 per cent y/y decline and declining double-digits q/q. This compares to Seagate reporting 71.2EBs, +45 per cent y/y; Toshiba’s nearline HDD capacity ship totalled ~17.4EBs, +19 per cent y/y in 4Q20.”
But there are reasons to be cheerful. WD has “completed 18TB [disk drive] qualifications at 3 out of 4 major cloud customers with a ramp expected to materialise through 2HF2021.”
In the enterprise SSD field the company has now completed “150 qualifications for its 2nd-gen NVMe eSSDs, including one cloud titan that is commencing ship in F3Q21,” Rakers said. This is up from the 100+ qualifications reported three months ago.
WD did much better in the client device market where its NVMe-based SSDs and major PC OEM relationships contributed to a record level of exabyte shipments.
Work in progress
David Goeckeler
David Goeckeler, WD CEO, had this to say in his prepared remarks: “During the quarter, we captured strength in the retail business and also delivered on our target outcome to complete qualification of our energy-assisted hard drives and second-generation enterprise SSD products with some of the world’s largest data centre operators.
“While there is still more work to be done, we remain extremely focused on meeting the needs of our customers and ramping our next-generation products throughout calendar 2021.”
WD expects next quarter’s revenues of $3.95bn at mid-point, down 5.5 per cent. Rakers anticipates an upturn in the following quarter.
Dell Technologies has spruced up the VxRail hyperconverged line-up with AMD EPYC processor options brought in to P Series performance-intensive configurations.
The new all-flash P675F and hybrid flash-disk P675N have a 2U chassis and support Nvidia Tesla T4 and V100S GPUs, which provide more power for intensive workloads such as AI, data analytics, deep learning, and high performance computing.
Nancy Hurley
Nancy Hurley, Dell’s senior manager CI/HCI product marketing, said in a blog post that the P Series chassis enables larger PSU options to allow a broader range of CPU offerings, larger memory configurations, and additional PCIe cards compared to the E Series EPYC systems. Dell introduced EPYC options for the E Series in June 2020.
There are six VxRail product families:
E Series – 1U/1Node with an all-NVMe option and T4 GPUs for use cases including artificial intelligence and machine learning. AMD EPYC processor and PCIe Gen 4 config available.
P Series – Performance-intensive 2U/1Node platform with an all NVMe option, configurable with 1, 2 or 4 sockets optimised for intensive workloads such as databases
V Series – VDI-optimised 2U/1Node platform with GPU hardware for graphics-intensive desktops and workloads
S Series – Storage dense 2U/1Node platform for applications such as virtualized SharePoint, Exchange, big data, analytics and video surveillance
G Series – Compute dense 2U/4Node platforms for general purpose workloads.
D Series – ruggedised 1U short depth – 20-inch – box in all-flash [SAS SSD] and hybrid SDD/disk versions.
VxRail systems support Optane Persistent Memory DIMMs, as well as Optane SSDs, also Nvidia Quadro RTX GPUs and vCPUs to accelerate rendering, AI, and graphics workloads. The new P-Series should go faster still with these workloads.
A VxRail 7.0.130 software update adds support for Intel’s x710 NIC Enhanced Network Stack (ENS) driver. This driver can dynamically prioritise network traffic to support particular workloads. A new feature enables system health runs to use the latest set of health checks whenever they are made available. There is also a support procedure to expand a 2-node ROBO VxRail configuration to a 3-or-more-node cluster
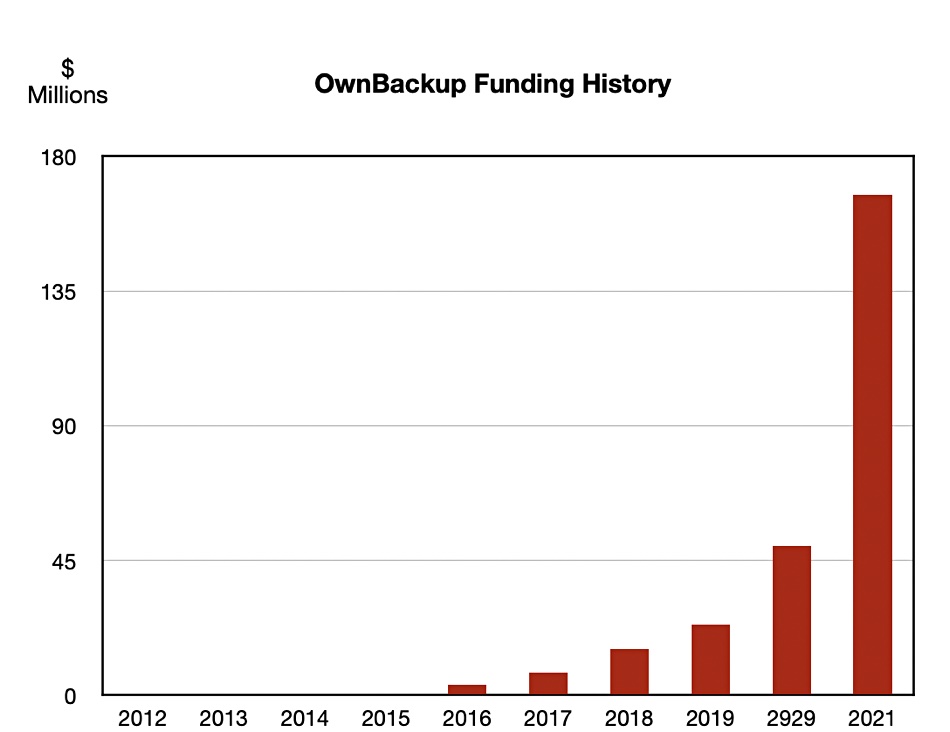
OwnBackup, the backup for Salesforce vendor, has bagged $167.5m at a $1.4bn valuation in a D-series round, taking total funding to $267.5m.
The startup, which was founded in 2012, will spend the cash on “ongoing investments in global expansion and extend OwnBackup’s platform to help companies big and small manage and secure their most mission-critical SaaS data.”
OwnBackup is present in the Salesforce AppExchange. It offers secure, automated daily backups of Salesforce SaaS and PaaS data, restoration, disaster recovery and management tools to pinpoint backup gaps.
The company said it has almost 3000 customers on its books, up from 2000 in July 2020, including 400 new customers gained in most recent quarter. “As cloud adoption and digital transformation accelerate, the data produced by and stored in SaaS applications is growing even faster,” Sam Gutmann, CEO said. “Our platform is purpose-built for cloud-to-cloud backup and protection and this latest round of funding is the next step in our mission to help our customers truly own their SaaS data.”
There is plenty of scope for expansion. OwnBackup’s customer count is a fraction of Salesforce, which has over 150,000 customers.
OwnBackups six consecutive years of increased funding rounds. Spot a hockey stick curve? The VCs are sure excited.
OwnBackup’s announcement says it is a cloud data protection platform company, with nothing about being specific to Salesforce. It currently supports four SaaS applications: Salesforce, Sage Business Cloud Financials, Veeva (life sciences) and nCino (financial data). It mentioned possible expansion to cover Workday in April last year.
Competitors in the Salesforce backup market include AvePoint, CloudAlly, Commvault (with Metallic), Druva, Odaseva, Kaseya’s Spanning and Skyvia. None of the other big backup suppliers, such as Acronis, Cohesity, Dell EMC, Rubrik, Veeam, and Veritas, appear to have Salesforce-specific capabilities yet.
The new funding was co-led by Insight Partners, Salesforce Ventures, and Sapphire Ventures, with participation from existing investors Innovation Endeavors, Vertex Ventures, and Oryzn Capital.
Note. Cohesity does provides backup for Salesforce, albeit not native (yet!). It’s enabled through an app in the Cohesity Marketplace.
Qumulo has increased the number of configurations for its scale-out File Data Platform on AWS Market place from seven to 27. The company says it has reduced prices by up to 70 per cent.
Barry Russell
Barry Russell, GM of cloud at Qumulo, said in a press statement: “Our new configurations in the AWS Marketplace enable customers to tackle the toughest, large-scale unstructured data challenges by creating high-performance file data lakes connected to workflows, while leveraging data intelligence services such as AI and ML from AWS.”
The AWS Marketplace lists Qumulo file storage cluster configurations in various capacity and media (HDD/SSD and SSD-only) combinations, as if they were HW/SW filers.
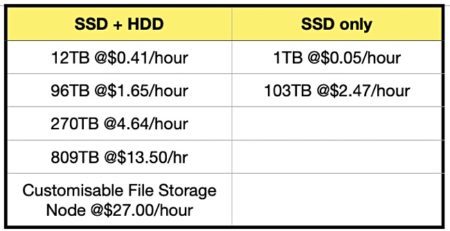
Seven pre-existing Qumulo configurations in the AWS Marketplace.
We checked the $/TB cost for Qumulo’s original seven AWS Marketplace configurations. Higher capacities get you lower cost/TB, but greater speed sends the cost/TB higher. Annual contracts will get you a 40 per cent or so discount.
The HDD+SSD cost per TB/hour for the 12TB config is $0.0341. The 96TB and 270TB configs work out at $0.01718/hour and there is a lower $0.01668/hour for 809TB. A 1TB SSD cost $0.05/hour but drops to $0.0239/hour for 103TB.
Each config comes with a CloudFormation template which specifies AWS instance types.