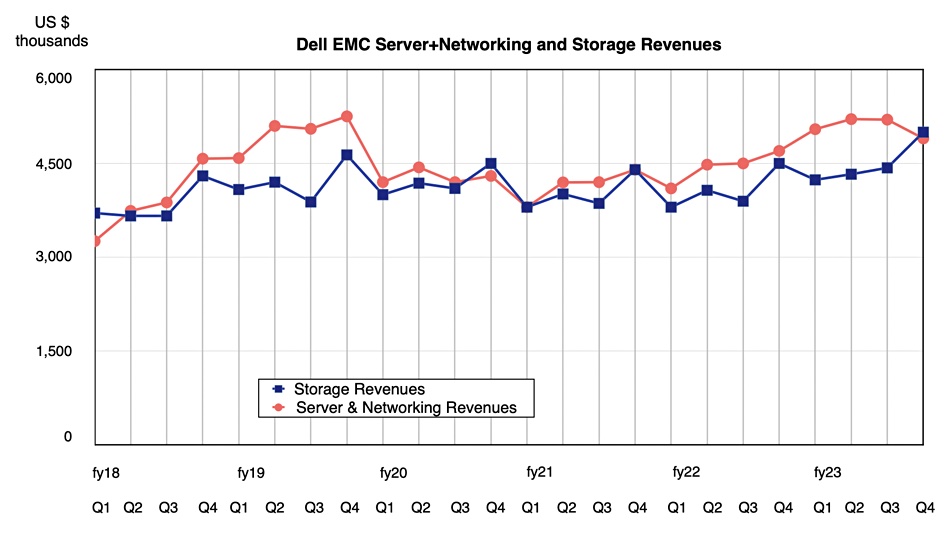
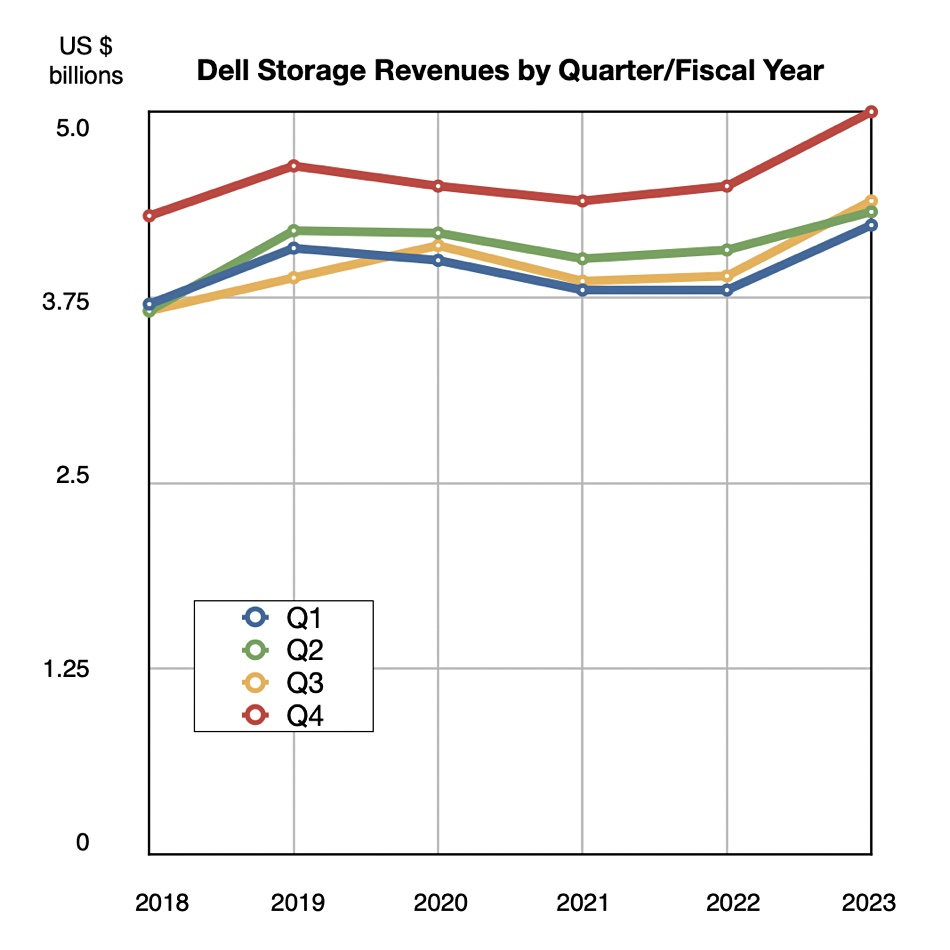
HPE storage contributed to strong first fiscal 2023 quarter results as all business units grew and collectively drove revenues, leading the company to raise its outlook.
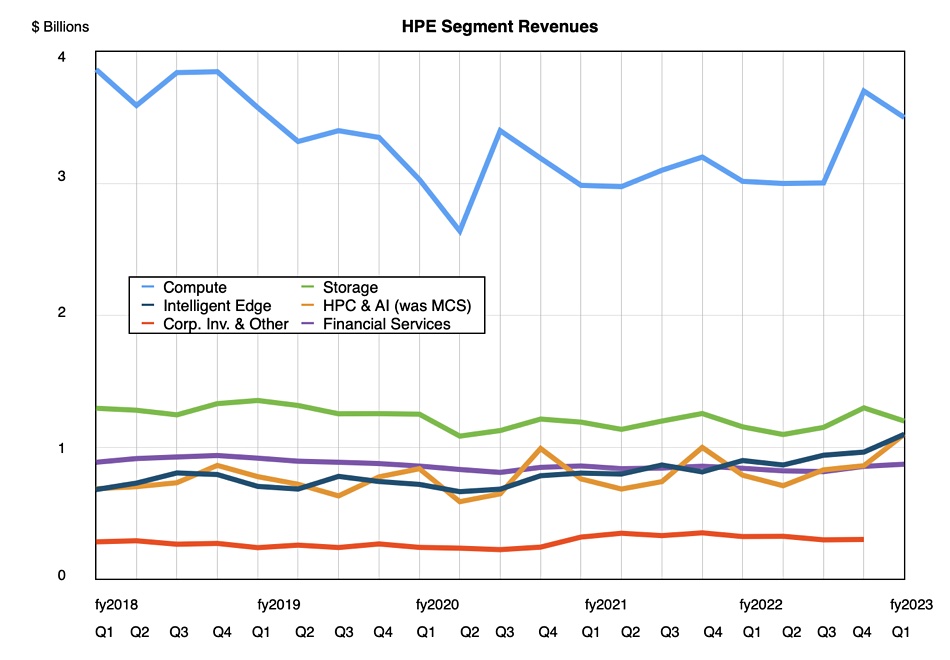
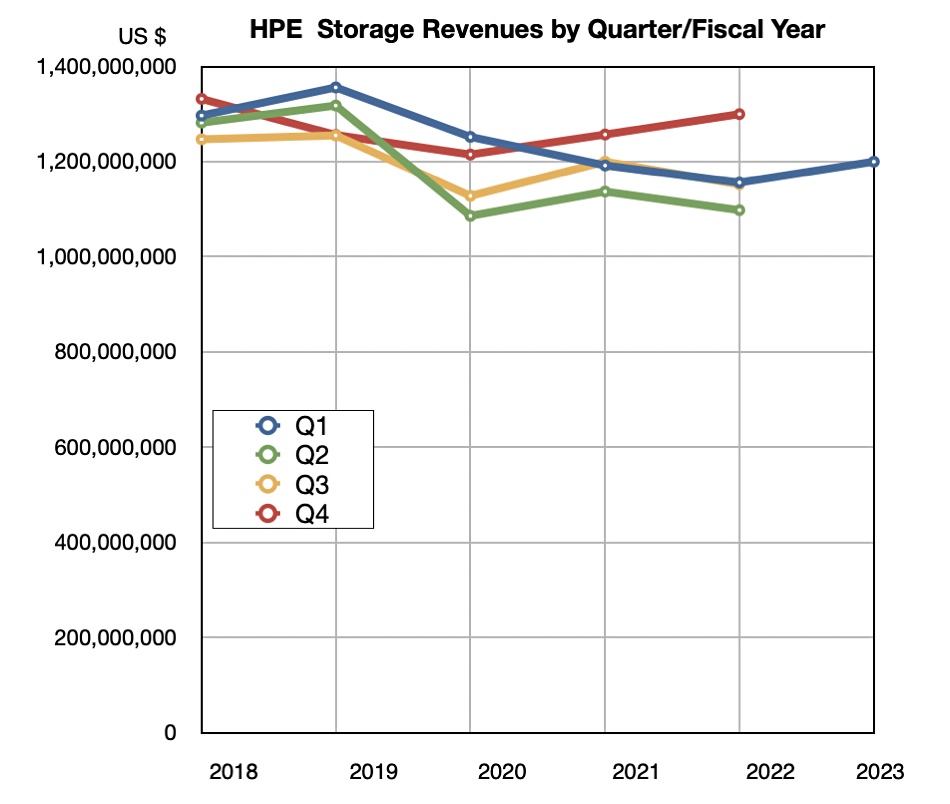
Revenues in the quarter ended January 31 were $7.8 billion, a 12 percent increase, beating guidance, with a $501 million profit, slightly less than last year’s $513 million. Compute revenues provided the bulk at $3.5 billion, up 14 percent, with storage bringing in $1.2 billion, 5 percent higher, and the Intelligent Edge (Aruba networking) contributing $1.13 billion, up 25 percent. HPC and AI provided $1.1 billion, a 34 percent rise, helped by a large contract associated with Frontier, the world’s first exascale system.

President and CEO Antonio Neri said: “HPE delivered exceptional results in Q1, posting our highest first quarter revenue since 2016 and best-ever non-GAAP operating profit margin. Powered by our market-leading hybrid cloud platform HPE GreenLake, we unlocked an impressive run rate of $1 billion in annualized revenue for the first time. These results, combined with a winning strategy and proven execution, position us well for FY23, and give us confidence to raise our financial outlook for the full year.”
EVP and CFO Tarek Robbiati said: “In Q1 we continued to out-execute our competition, despite uneven market demand, and produced more revenues in every one of our key segments, with our Edge business Aruba being a standout.”
Financial summary
- Annual Recurring Revenue: >$1 billion and up 31 percent year/year
- Diluted EPS: $0.38 down $0.01 from last year
- Operating cash flow: -$800 million
- Free cash flow: -$1.3 billion reflecting seasonal working capital needs
Robbiati said in the earnings call: “We expect to generate significant free cash flow in the remainder of fiscal year ’23 and reiterate our guidance of $1.9 billion to $2.1 billion in free cash flow for the full year.”
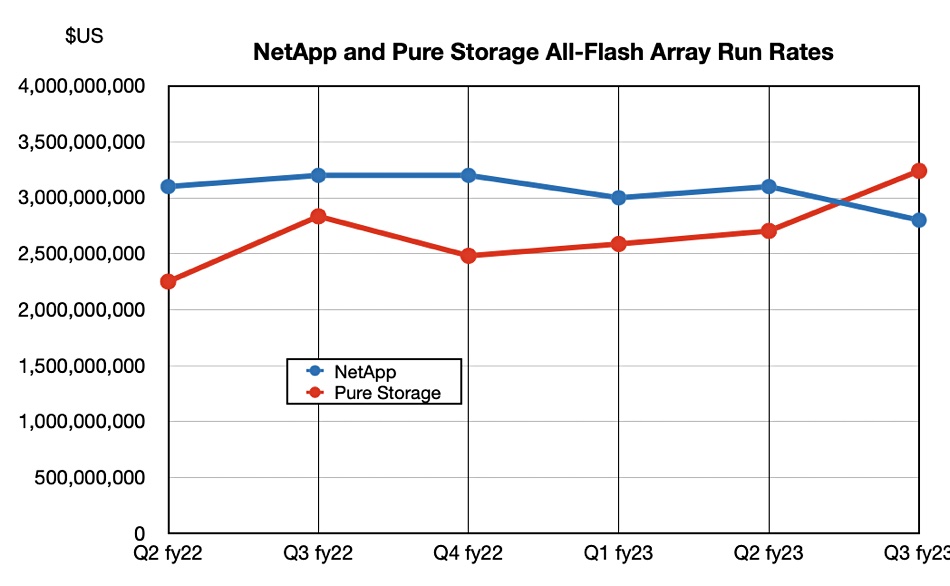
HPE’s Alletra storage array revenue growth increased well above triple digits from the prior-year, helped by stabilizing supply. That means at least 100 percent; doubled revenue at a minimum. HPE is altering its storage business to focus on higher margin, software-intensive as-a-service revenue. It is continuing to invest in R&D for its own IP.
Neri teased earnings call listeners by saying: “Alletra … is the fastest [growing] product in the history of the company. It has grown triple digits on a consistent basis and you will see more announcements about this platform going forward … It was conceived to be a SaaS-led offer. And that’s why it’s fueling also the recurring revenue as we go forward.
“Our order book at the start of Q1 was larger than it was a year ago. And as we exit that quarter, it is more than twice the size of normalized historical levels.”
The macroeconomic background is having an effect: “Demand for our solutions continue though it is uneven across our portfolio. We also see more elongated sales cycles, specifically in Compute that we have seen in recent quarters.”
Robbiati said: “Deal velocity for Compute has slowed as customers digest the investments of the past two years though demand for our Storage and HPC & AI solutions is holding and demand for our Edge solutions remains healthy.
AI and megatrends
The AI area with Large Language Model (LLM) technology is seen by HPE as an inflexion point it can use to its advantage. Neri said HPE is ”assessing what is the type of business model we can deploy as a part of our as-a-service model by offering what I call a cloud supercomputing IS layer with a platform as-a-service that ultimately developers can develop, train, and deploy these large models at scale.
“We will talk more about that in the subsequent quarters, but we are very well-positioned and we have a very large pipeline of customers.”
An analyst asked why HPE was doing well, mentioning “the contrast in your outlook on storage and compute versus some of your peers.”
Neri said this was due to HPE having a diversified portfolio unlike competitors who “don’t have the breadth and depth of our portfolio. Some of them are just playing compute and storage. Some of them play just in storage. Some of them only play in the networking … We have a unique portfolio, which is incredibly relevant in the megatrends we see in the market.”
The megatrends are around edge, cloud, and AI. They are reshaping the IT industry and HPE offers its portfolio through the GreenLake subscription business: “GreenLake is a winning strategy for us because it’s very hard to do.”
Also, unlike Dell, HPE now has no exposure to the downturned PC market.
The company’s director declared a regular cash dividend of $0.12 per share on the company’s common stock, payable on April 14.
The outlook for the next quarter is for revenue to be in the range of $7.1 billion to $7.5 billion. At the $7.3 billion midpoint that is an 8.7 percent increase on the year-ago Q2. Robbiati commented: “While many tech companies are playing defense with layoffs, we see fiscal year ’23 as an opportunity to accelerate the execution of our strategy.”