After running its IPO, Astera Labs saw its shares, initially priced at $36/share, soar by 72 percent on March 20, closing at $62.03. This surge in share price valued the company at $10.4 billion, taking into account stock options and restricted share units. Astera will hire another 200 engineers and look at M&As as a way to grow its engineering team.
…
The Backblaze product portfolio has been added to Carahsoft’s National Association of State Procurement Officials (NASPO) ValuePoint contract. This enables Carahsoft and Backblaze to provide the company’s cloud storage to participating states, local governments, and educational institutions. This certification is augmented by the recent addition of Backblaze to Carahsoft’s NYOGS and OMNIA-approved vendor lists.
…
Data manager Datadobi launched StorageMAP 6.7. A blog says it has extended REST API extensions:
- Add or configure file or object servers, streamlining the setup process for large data management projects
- Dynamically adjust server throttling, allowing for precise control over performance and resource utilization
- Retrieve real-time status updates of ongoing data management jobs, including critical information such as status and error counts
v6.7 also integrates replication functionality into StorageMAP. It now encompasses both N2N (NAS-to-NAS) and O2O (object-to-object) replication capabilities, consolidating all replication functionalities in a single facility.
…
Data recovery services supplier Fields Data Recovery has launched a Partnership Program offering:
- Access to state-of-the-art data recovery technologies and tools
- Comprehensive training and support to enhance partners’ proficiency in data recovery processes
- Flexible partnership models tailored to meet the unique needs and objectives of each partner
- Marketing and sales assistance to help partners promote their data recovery services effectively
- Priority access to Fields Data Recovery’s expert team for technical assistance and consultation
More info here.
…
China-based SmartX has released its SMTX Kubernetes Service 1.2 (SKS), a production-ready container management and service product. Updates include enhanced support for high-performance computing scenarios such as AI, multiple CPU architectures, and optimized management and use of container images. With these updates, SKS 1.2 helps users apply AI scenarios in containers based on easily created Kubernetes clusters.
…
Swissbit says its new PS-66(u) DP SD and microSD cards have proven robustness and industrial suitability, and are certified CmReady by Wibu-Systems. This enables the integration of CodeMeter technology for software protection and license management. The use of the Swissbit cards as additional license containers within the CodeMeter ecosystem offers a way for developers of embedded and IoT devices to protect their software and monetize their licenses.
…
Taiwan-based TeamGroup has launched the MagSafe-compatible PD20M Mag Portable SSD, and the ULTRA CR-I MicroSD Memory Card Reader. The PD20M Mag External SSD is weighs 40g and measures 70 x 62 x 8.2 mm. It stores up to 2 TB, has a USB 3.2 Gen 2 x 2 Type-C interface, is compatible with the iPhone 15 Pro, and supports Thunderbolt interface ports with a maximum transfer speed of 20 Gbps. The ULTRA CR-I MicroSD Memory Card Reader supports UHS-I interface slots and USB Type C. The maximum data transfer speed is 180 MBps when used with TEAMGROUP MicroSD memory cards. It is meant for use with smartphones or other mobile devices.

…
Veritas announced enhancements to Backup Exec, which has more than 45,000 small and midsize business (SMBs) users worldwide. The updates include:
- Malware detection – powered by Microsoft Defender, can be used to scan both VMware and Hyper-V backup sets at any time or prior to recovery
- Role-based security – limits access to data based on a user’s specific role. In the event an account is compromised, hackers can only corrupt the small volume of data associated with that specific user’s account
- Faster backup and recovery – optimizes protection performance with forever incremental backup of VMware and Hyper-V. Protection of virtual machines is now faster with parallel backup of multiple virtual disks and the included ability to recover virtual machines instantly
Backup Exec is available as a subscription service and can be installed in ten minutes or less, we’re told. Once installed, completing the first backup takes only five minutes. Find a Veritas-certified partner or sign up for the Veritas Backup Exec free 60-day trial.
…
UK disaster recovery specialist virtualDCS has launched CloudCover Guardian for Azure, which protects more than 250 configurable items in an established Microsoft 365 estate. Configurations covered by CloudCover Guardian for Azure span user accounts, access privileges, and unique security groups across popular applications such as SharePoint, Teams, OneDrive, Exchange, and Entra ID (formerly Azure Active Directory). Microsoft does not currently offer a backup service for these configurations. The system captures every vital configuration, meaning a Microsoft 365 environment can be proactively managed from a single console for a complete, clean recovery after an incident.
The company has also launched a “Clean Room” service for customers that need to restore their systems in a sterile and isolated environment in the event of a ransomware attack.
…
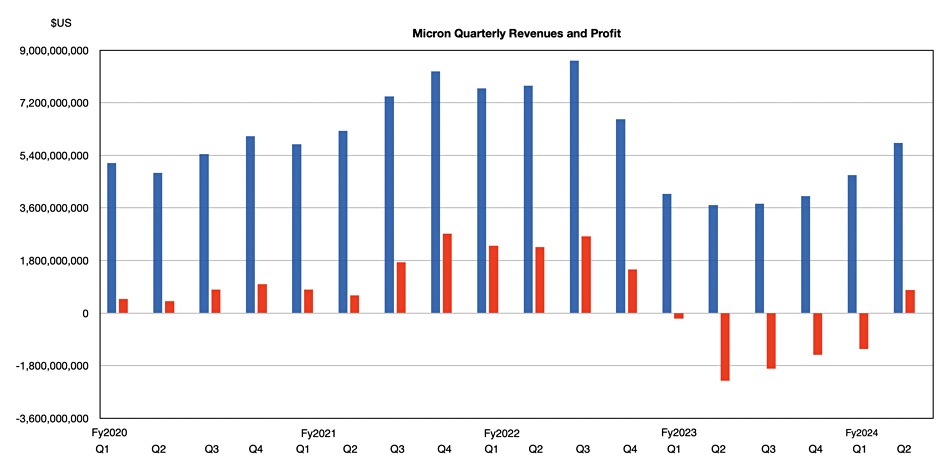
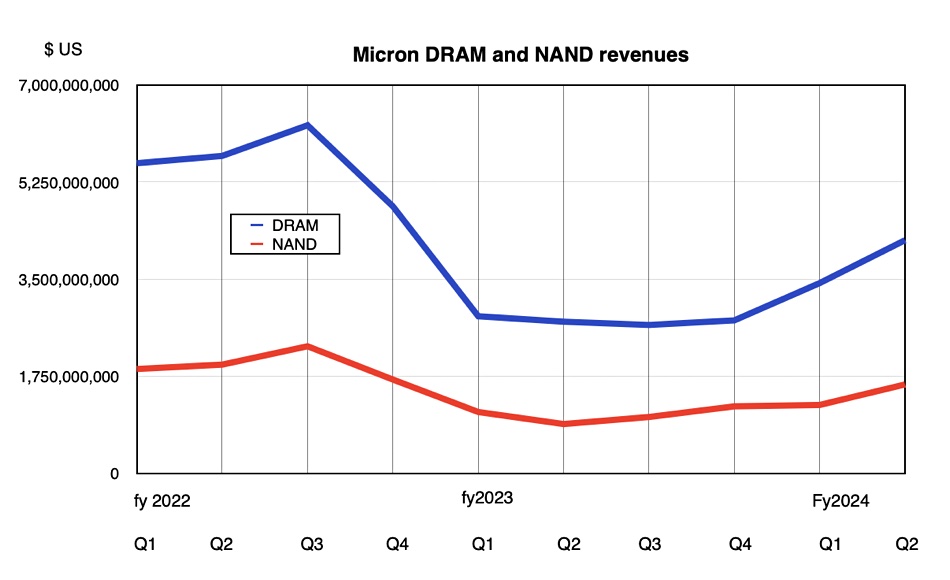
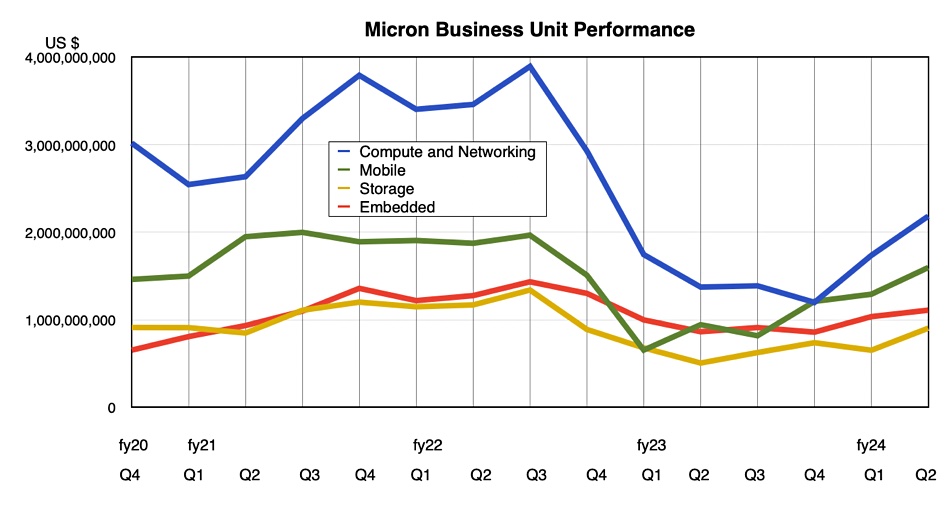
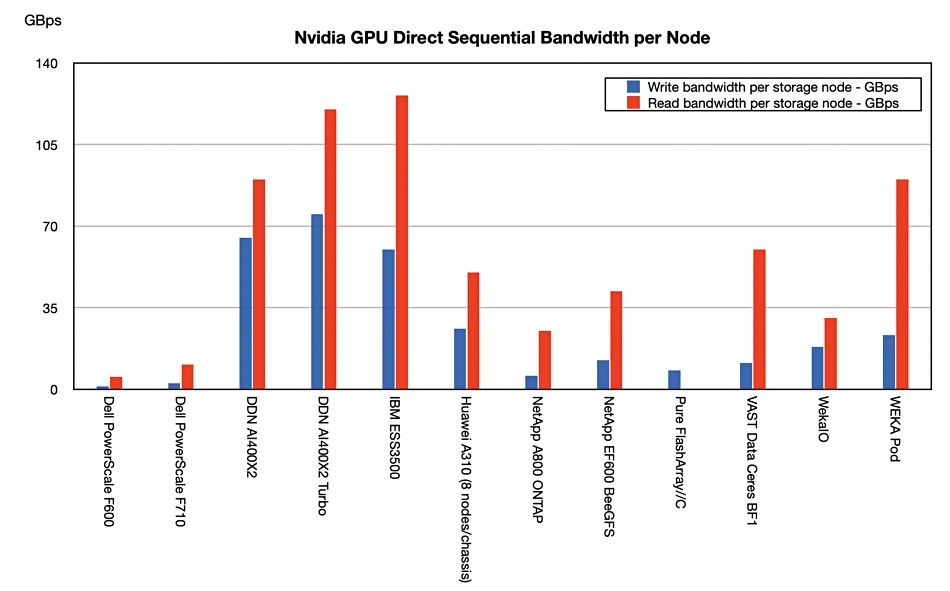
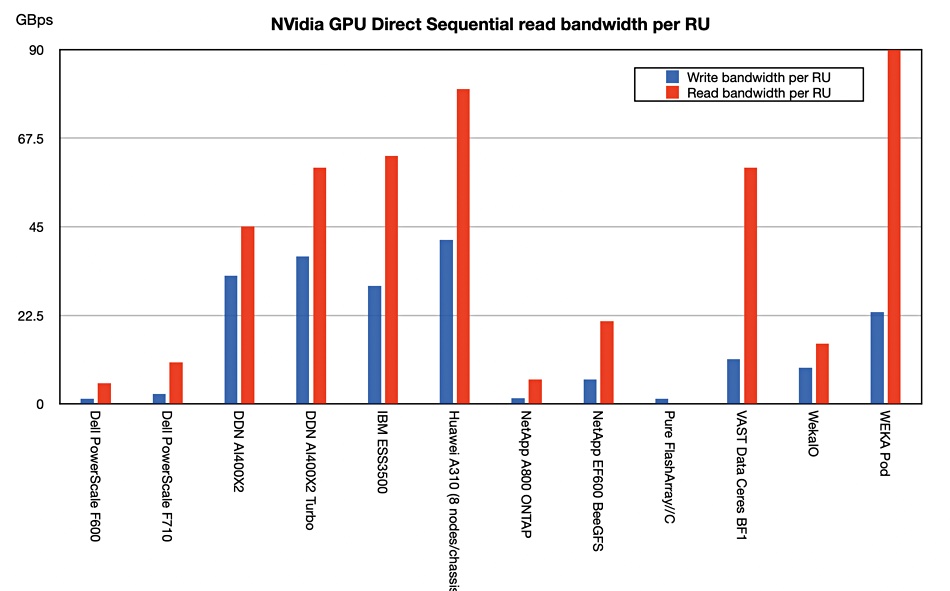
GenAI represents a Fourth Industrial Revolution, says Wedbush financial analyst Daniel Ives. He told subscribers: “With a March Madness-like atmosphere at the Nvidia GTC Conference with the Godfather of AI Jensen leading the way, its crystal clear to us and the Street that the use cases for enterprise generative AI are exploding across the landscape. The partnerships and spending wave around AI represents a generational tech spending wave with now Micron the latest example of beneficiaries from the 2nd/3rd/4th derivatives of AI just like we saw from Oracle a week ago. The ripple impact that starts with the golden Nvidia chips is now a tidal wave of spending hitting the rest of the tech world for the coming years. We estimate a $1 trillion-plus of AI spending will take place over the next decade as the enterprise and consumer use cases proliferate globally in this Fourth Industrial Revolution.”
The GenAI hype is getting relentless. Is it a dotcom-type boom and bust, though? Ives asserts this is “NOT a 1999 Bubble Moment.”