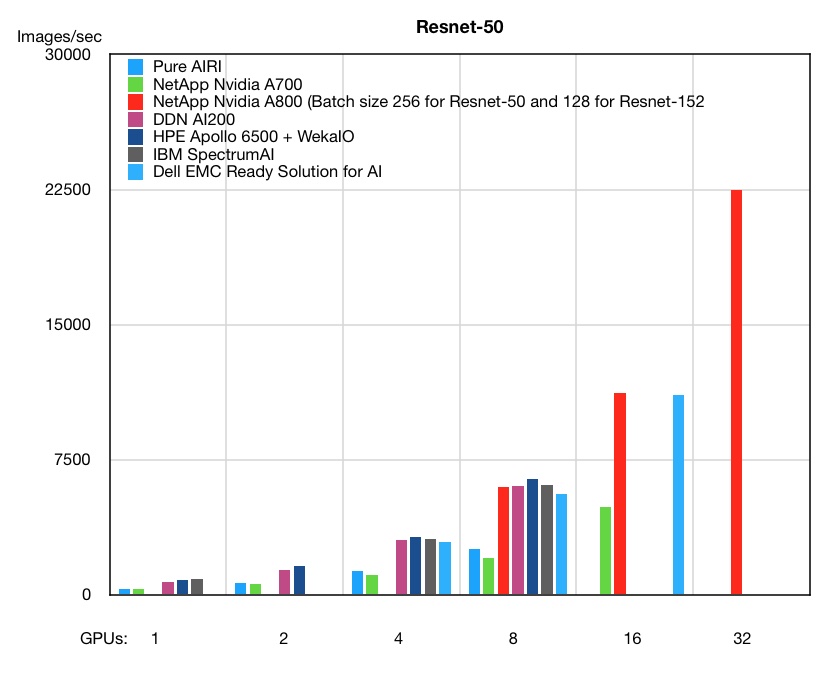
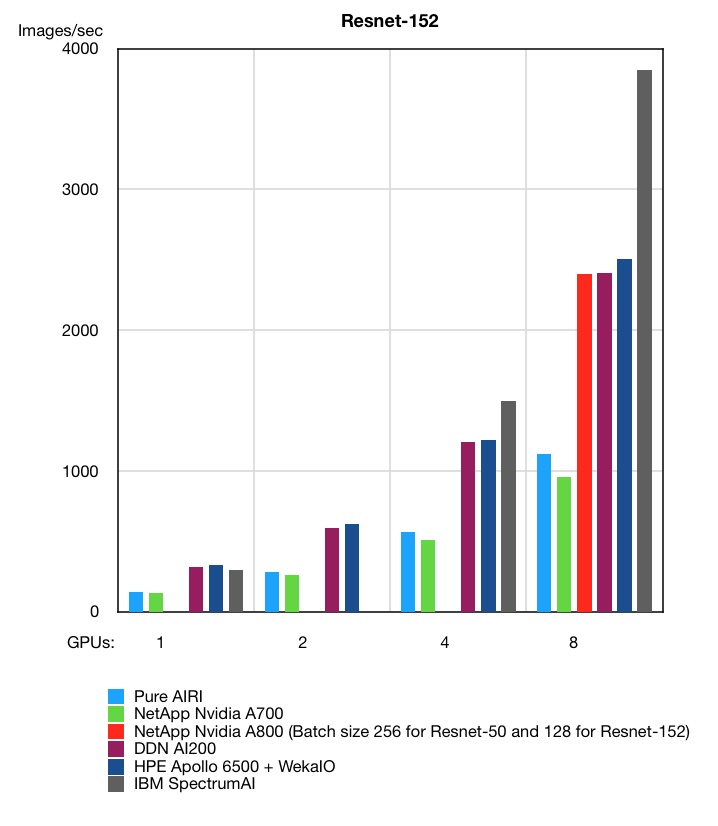
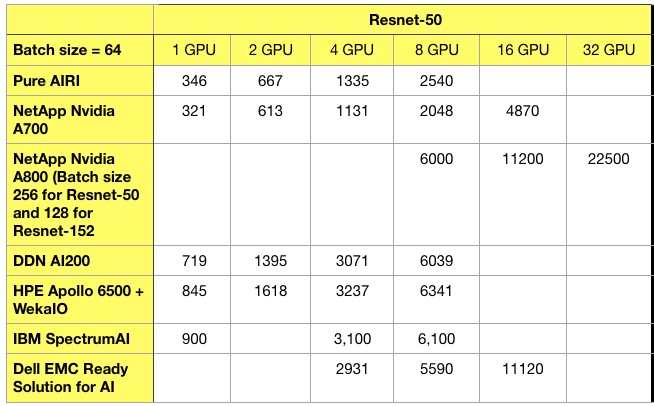
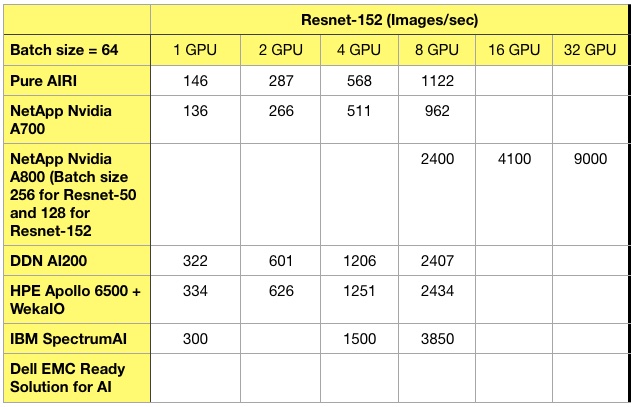
We have four sets of predictions for 2019, followed by 11 brief news items, two customer notes and a CEO promotion at Datto.
Three Archive360 predictions
Archive360 archives data up to the Azure cloud. It reckons these things will happen in 2019:
1. To achieve defensible disposition of live data and ongoing auto-categorization, more companies will turn to a self-learning or “unsupervised” machine learning model, in which the program literally trains itself based on the data set provided. This means there will be no need for a training data set or training cycles. Microsoft Azure offers machine-learning technology as an included service.
2. Public cloud Isolated Recovery will help defeat ransomware. It refers to the recovery of known good/clean data and involves generating a “gold copy” pre-infection backup. This backup is completely isolated and air-gapped to keep the data pristine and available for use. All users are restricted except those with proper clearance. WORM drives will play a part in this.
3. Enterprises will turn to cloud-based data archiving in 2019 to respond to eDiscovery requests in a legally defensible manner, with demonstrable chain of custody and data fidelity when migrating data.
Three Arcserve predictions for 2019
1. Public cloud adoption gets scaled back because of users facing unexpected and significant fees associated with the movement and recovery of data in public clouds. Users will reduce public cloud use for disaster recovery (DR) and instead, use hybrid cloud strategies and cloud service providers (CSPs) who can offer private cloud solutions with predictable cost models.
2. Data protection offerings will incorporate artificial intelligence (AI) to predict and avert unplanned downtime from physical disasters before they happen. DR processes will get automated, intelligently restoring the most frequently accessed, cross-functional or critical data first and proactively replicate it to the cloud before a downtime event occurs.
3. Self-managed disaster recovery as a service (DRaaS) will increase in prominence as it costs less than managed DRaaS. Channel partners will add more self-service options to support growing customer demand for contractually guaranteed recovery time and point objectives (RTOs/RPOs) and expanding their addressable market free of the responsibility of managing customer environments.
NetApp’s five predictions for 2019
These predictions are in a blog which we have somewhat savagely summarised
1. Most new AI development will use the cloud as a proving ground as there is a rapidly growing body of AI software and service tools there.
2. Internet of Things (IoT) edge processing must be local for real-time decision-making. IoT devices and applications – with built-in services such as data analysis and data reduction – will get better, faster and smarter about deciding what data requires immediate action, what data gets sent home to the core or to the cloud, and what data can be discarded.
3. With containerisation and “server-less” technologies, the trend toward abstraction of individual systems and services will drive IT architects to design for data and data processing and to build hybrid, multi-cloud data fabrics rather than just data centres. Decision makers will rely more and more on robust yet “invisible” data services that deliver data when and where it’s needed, wherever it lives, using predictive technologies and diagnostics. These services will look after the shuttling of containers and workloads to and from the most efficient service provider solutions for the job.
4. Hybrid, multi-cloud will be the default IT architecture for most larger organisations while others will choose the simplicity and consistency of a single cloud provider. Larger organisations will demand the flexibility, neutrality and cost-effectiveness of being able to move applications between clouds. They’ll leverage containers and data fabrics to break lock-in.
5. New container-based cloud orchestration technologies will enable better hybrid cloud application development. It means development will produce applications for both public and on-premises use cases: no more porting applications back and forth. This will make it easier and easier to move workloads to where data is being generated rather than what has traditionally been the other way around.
StorPool predicts six things
1. Hybrid cloud architectures will pick up the pace in 2019. But, for more demanding workloads and sensitive data, on-premise is still king. I.e. the future is hybrid: on-premise takes the lead in traditional workloads and cloud storage is the backup option; for new-age workloads, cloud is the natural first choice and on-prem is added when performance, scale or regulation demands kick-in.
2. Software-defined storage (SDS) will gain majority market share over the next 3 to 5 years, leaving SAN arrays with a minority share. SDS buyers want to reduce vendor lock-in, make significant cost optimisations and accelerate application performance.
3. Fibre Channel (FC) is becoming an obsolete technology and adds complexity in an already complex environment, being a separate storage-only component. In 2019, it makes sense to deploy a parallel 25G standard Ethernet network, instead of upgrading an existing Fibre Channel network. At scale, the cost of the Ethernet network is 3-5 per cent of the whole project and a fraction of cost of a Fibre Channel alternative.
4. We expect next-gen storage media to gain wider adoption in 2019. Its primary use-case will still be as cache in software-defined storage systems and database servers.
On a parallel track, Intel will release large capacity Optane-based NVDIMM devices, which they are promoting as a way to extend RAM to huge capacities, at low cost, through a process similar to swapping. The software stack to take full advantage of this new hardware capability will slowly come together in 2019.
There will be a tiny amount of proper niche usage of Persistent memory, where it is used for more than a very fast SSD.
5. ARM servers enter the data centre. However this will still be a slow pickup, as wider adoption requires the proliferation of a wider ecosystem. The two prime use-cases for ARM-based servers this year are throughput-driven, batch processing workloads in the datacenter and small compute clusters on “the edge.”
6. High core-count CPUs appear. Intel and AMD are on a race to provide high core-count CPUs for servers in the datacenter and in HPC. AMD announced its 64-cores EPYC 2 CPU with overhauled architecture (9 dies per socket vs EPYC’s 4 dies per socket). At the same time, Intel announced its Cascade Lake AP CPUs, which are essentially two Xeon Scalable dies on a single (rather large) chip, scaling up to 48 cores per socket. Both products represent a new level of per-socket compute density. Products will hit the market in 2019.
While good for the user, this is “business as usual” and not that exciting.
Shorts
Data sprawl controller and data-as-a-service provider Actifio said it had a very good 2018 year, surpassing the 3,500 mark in global customers across 38 countries. It recently won an OEM deal with IBM.
Commvault issued results from a conducted at Data Protection World Forum 2018 in London. While four in five data experts and IT professionals believe that the requirement to comply with stronger, more stringent data management regulations (like GDPR), will be a long-term benefit to their organisations, only one in five were fully confident in their business’ level of compliance with current data protection legislation.
Research house DRAMeXchange says NAND flash manufacturers are cutting CAPEX in 2019, aiming to moderate oversupply in the industry by limiting bit output growth. The total 2019 CAPEX in the global NAND flash industry is expected to be $22 billion, about 2 per cent YoY lower than in 2018.
GIGABYTE’s decentralised storage cluster, VirtualStor Extreme, invented with software-defined storage vendor Bigtera, is claimed to simplify storage management with its virtualised system architecture. It can integrate and manage existing storage systems (including the vast majority of storage types on the market such as SAN, NAS, Object, File) to provide flexibility in allocating and using existing storage resources.
GridGain Systems, which provides enterprise-grade in-memory computing based on Apache Ignite, has improved GridGain Cloud, its in-memory-computing-platform-as-a-service (imcPaaS), to include automatic disk-based backup persistence of the in-memory operational dataset. This ensures immediate data access if a cluster restart is ever required.
Quad-level cell (QLC or 4bits/cell) flash is the latest development in 3D NAND with Micron, Toshiba, Western Digital and others producing QLC SSDs. Taiwan-based LITE-ON is joining them with its own line of QLC SSDs coming in the second half of 2019. It thinks it can capture sales with these SSDs that would otherwise have gone to disk drives.
Micron, with its automotive-grade LPDDR4X memory devices, is working with Qualcomm Technologies and its Snapdragon Automotive Cockpit Platforms to develop products for next-generation in-vehicle cockpit compute systems for things like infotainment.
QNAP has four AMD-powered NAS systems;
- The TS-1677X is a Ryzen NAS with graphics processing to facilitate AI-oriented tasks.
- The TS-2477XU-RP is a Ryzen-based rackmount NAS with up to 8 cores/16 threads and integrated dual 10GbitE SFP+ ports,
- The TS-977XU is a HDD + SSD hybrid-structure AMD Ryzen 1U rackmount NAS with up to 4 cores/4 threads,
- The low-end TS-963X is a quad-core AMD NAS with 10GBASE-T port and dedicated SSD slots for caching and tiering.
Starwind says its NVMe-oF Target is a protocol tailored to squeeze maximum performance out of NVMe devices and deliver close-to-zero latency for IOPS-hungry applications. By mapping each disk to the particular CPU core and expanding the command queue, you get microsecond-scale latency without overwhelming CPUs and build, probably, the fastest storage ever. Grab a white paper here.
IT infrastructure performance monitor, tester and simulator Virtual Instruments recorded its best year to date in 2018, with record bookings, nearly a 100 per cent growth rate in new customers, over 200 per cent growth in EMEA sales, and 125 per cent growth in channel-initiated business
Replicator WANdisco and IBM have jointly engineered an offering providing replication of IBM Db2 Big SQL data. Db2 Big SQL is a SQL engine for Hadoop with support for HDFS, RDBMS, NoSQL databases, object stores and WebHDFS data sources. It’s the first time WANdisco technology has been applied to SQL data.
Customers
Strava, the GPS tracking app and social network for athletes, is now using Snowflake Computing’s data warehouse in the cloud to find out which features customers use and how they want to use them. It has a 120 TB data warehouse, 13 trillion GPS data points, 15 million uploads/week and 1.5 billion analytics points ingested daily.
Mobileye will use Micron DRAM and NOR flash products in its fifth-generation EyeQ5 system-on-chip (SoC)-based EPM5 platform for fully autonomous driving (up to level 5; full autonomy.) Mobileye is developing its EyeQ5 SoC-based platform to serve as the central computer, performing vision and sensor fusion, as part of its effort to have fully autonomous driving vehicles on the road in 2020.
People
On-line backup outfit Datto appointed a new CEO following on from founder Austin McChord who quit the CEO role after Vista Equity Partners bought Datto last year.
McChord stays on the board while interim CEO, Tim Weller, pictured left, who was the CFO, now gets confirmed as the CEO. He joined Datta in June 2017 and apparently played a big part in the merger of Datto and Autotask by Vista.
Nick Dyer has been appointed as a Worldwide Field CTO & Evangelist for HPE Nimble Storage. The role is is part Engineering, part Sales Engineer, part Technical Marketing and part Product Management. He’s part of a team which he says HPE decided to invest in in order to kickstart further growth of Nimble storage. HPE and Dyer reckon new coming technology will boost this growth; Synchronous Replication availability, Cloud Volumes going international (UK in April/May!), Intel Optane “Memory Driven Flash”, StoreOnce integration and “a slew of cool stuff due in the coming months on the Nimble platform.”