


WekaIO’s file system has given HPE’s Apollo’s servers a boost for artificial intelligence workloads, giving them a leading Resnet-50 score.
Resnet-50 (Residual Neural Network- 50 layers) is an image recognition training workload for machine learning systems.
The Apollo server is an Apollo Gen 10 6500; a dual Xeon SP CPU server equipped with up to 8 Nvidia Tesla V100 GPUs (16GB versions) and the NVLink GPU-to-GPU interconnect. Mellanox EDR (100Gbit/s) InfiniBand was used to interconnect a cluster of eight ProLiant DL360 servers running the WekaIO Matrix filesystem with the Apollo 6500. Each DL360 contained four NVMe SSDs
HPE noted that “the WekaIO shared file system delivers comparable performance to a local NVMe drive and, in all but one test, WekaIO is faster than the local file system when scaled to four or eight GPUs.”
I have assembled and charted results for Dell EMC, DDN A3I, IBM Spectrum AI, NetApp A700 and A800 arrays, and Pure Storage AIRI systems, using servers equipped with varying numbers of Nvidia GPUs. Adding HPE Apollo 6500 servers fitted with GPUs and using WekaIO’s Matrix filesystem to these charts shows that HPE has the top results for the 2, 4 and 8 GPU levels with Resnet-50:
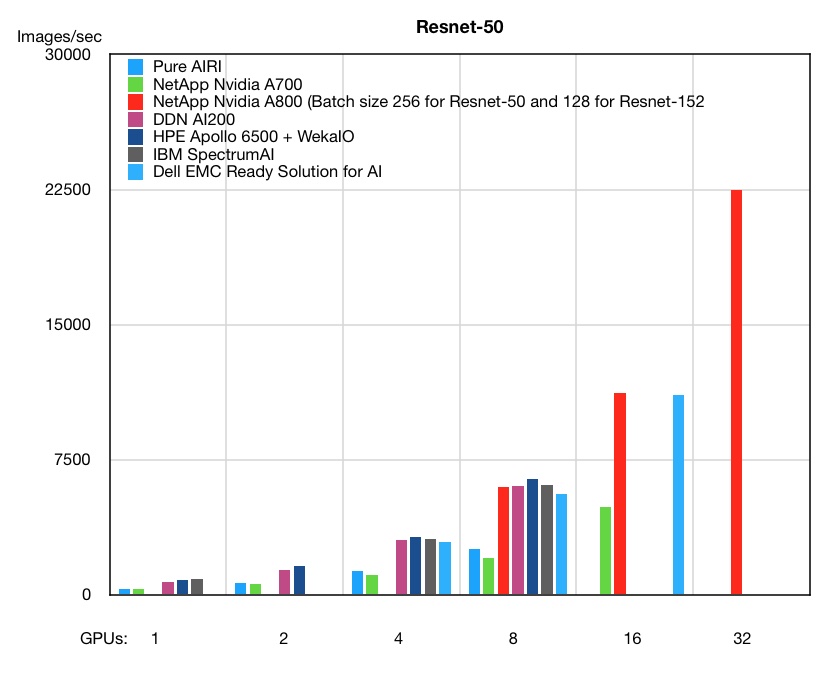
However, HPE came second to IBM Spectrum AI systems at the 4- and 8-GPU levels in the alternative Resnet-152 workload, but beat it at the 1-GPU level.
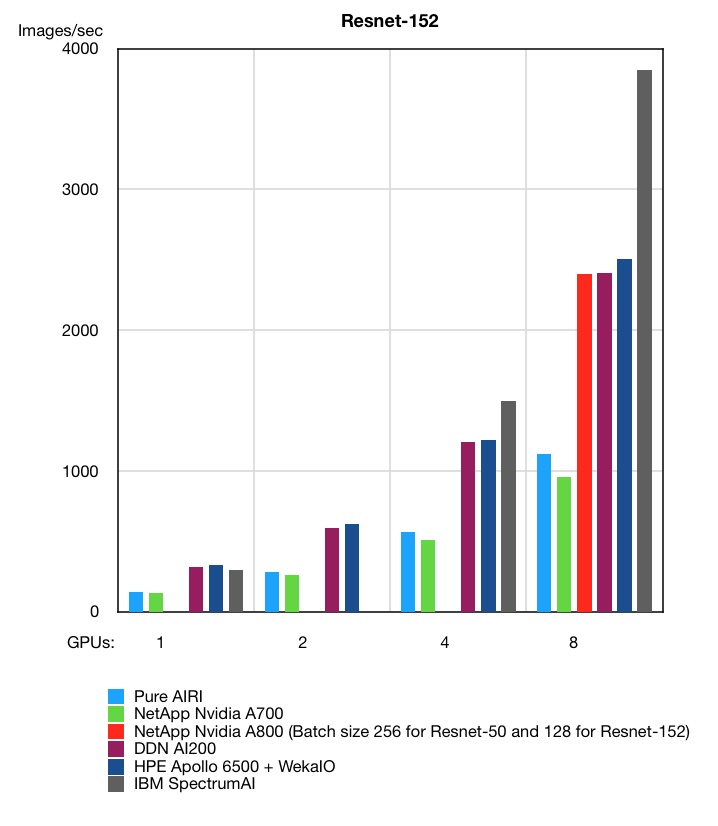
Why Spectrum AI is better than Apollo 6500/WekaIO at Resnet-152 but worse in Resnet-50 is something for machine learning experts to ponder. An HPE technical paper describes the hardware and software used in the tests above.
For reference, our recorded Resnet-50 and -152 supplier system results are below.
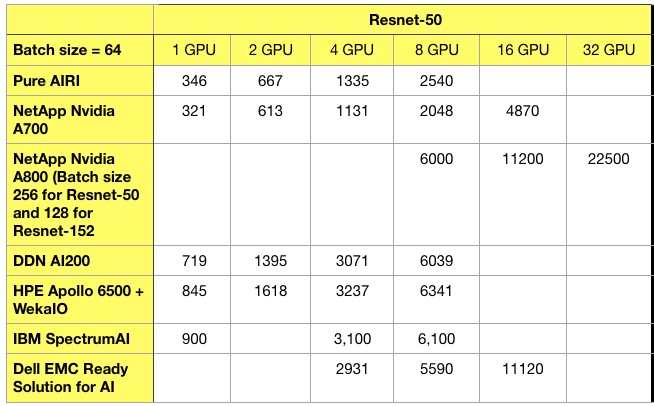
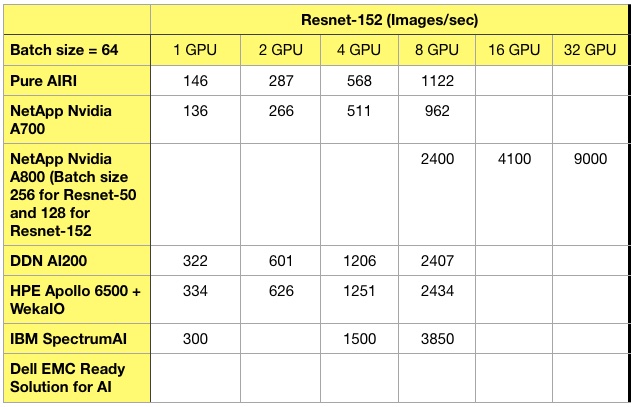
Not all suppliers provide values at each GPU count level, which explains the gaps in the tables.





