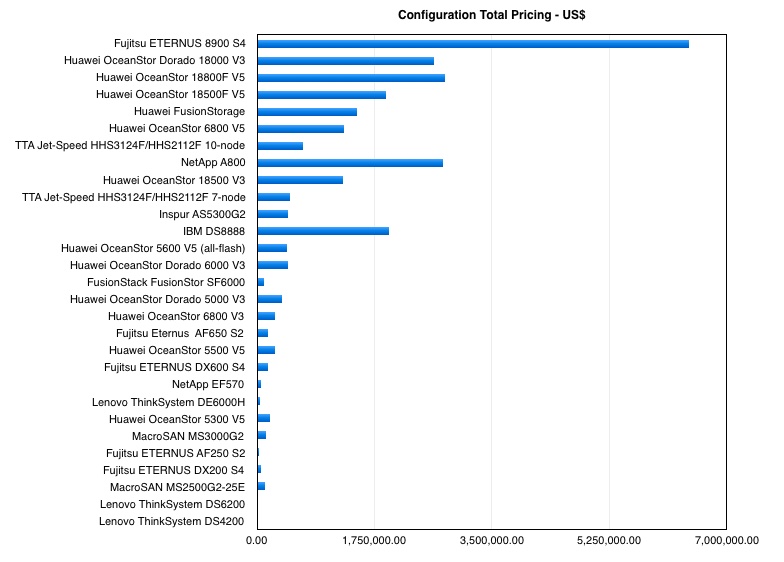
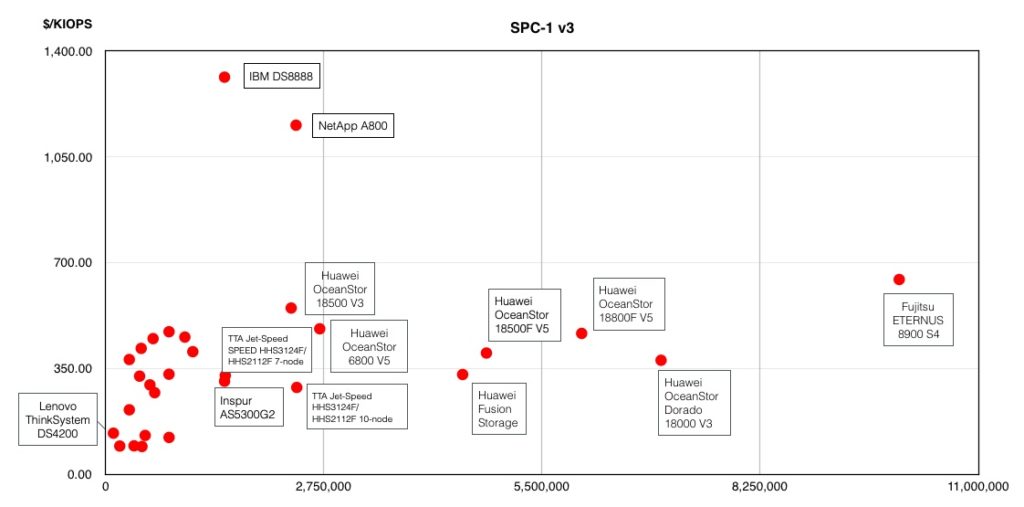
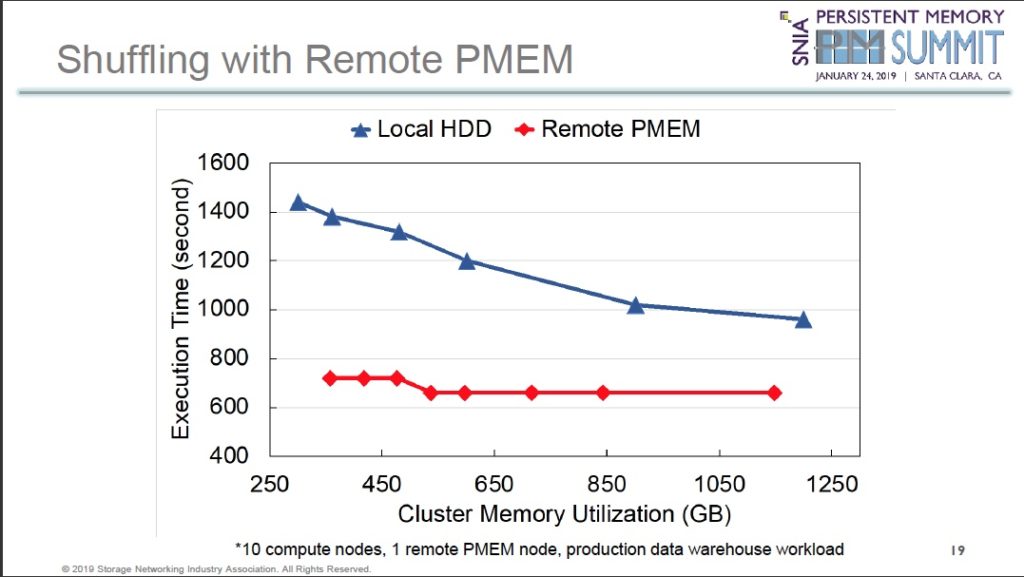
Fourteen years ago Violin Memory began life as an all-flash array vendor, aiming to kick slower-performing disk drive arrays up their laggardly disk latency butt. Since then 18 startups have come, been acquired, survived or gone in a Game of Flash Thrones saga.
Only one startup – Pure Storage – has achieved IPO take-off speed and it is still in a debt-fuelled and loss-making growth phase. Two other original pioneers have survived but the rest are all history. A terrific blog by Flashdba suggested it was time to tell this story.
Blocks & Files has looked at this turbulent near decade and a half and sees five waves of all-flash array (AFA) innovation.
We’re looking strictly at SSD arrays, not SSDs or add-in cards, and that excludes Fusion IO, STEC, SanDisk – mostly – and all its acquisitions, and others like Virident.
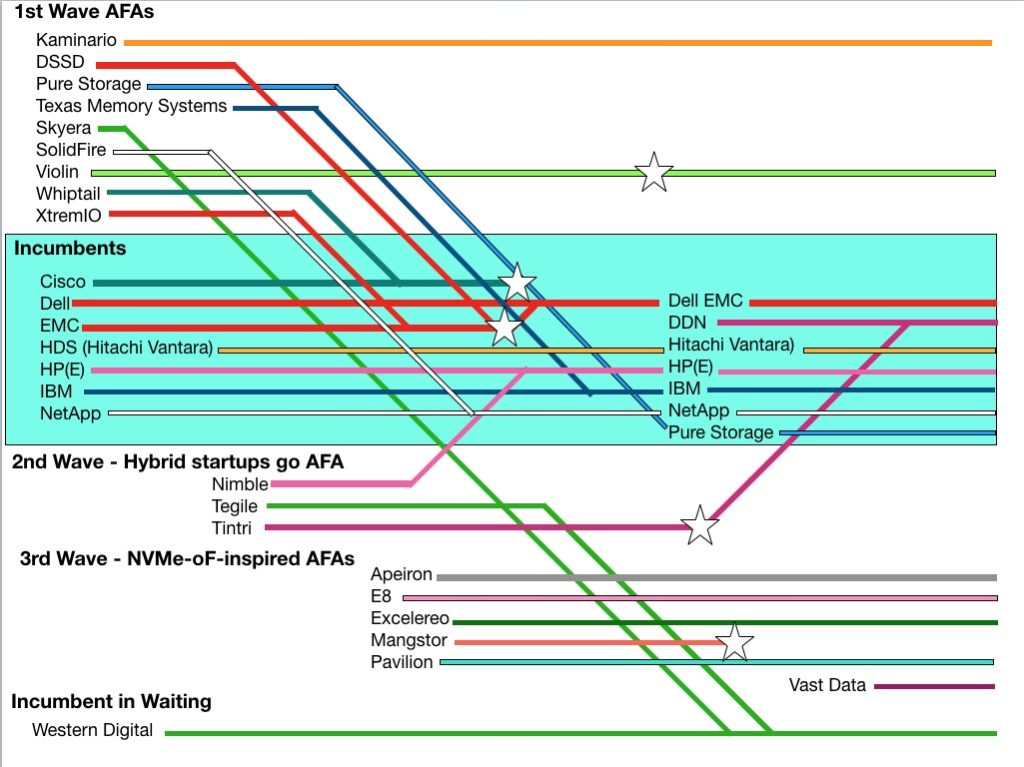
A schematic chart sets the scene. It is generally time-based, with the past on the left and present time on the right hand side. Coloured lines show what’s happened to the suppliers, with joins representing acquisitions. Stars show firms crashing or product lines being cancelled. Study it for a moment and then we’ll dive into the first wave of AFA happenings.
First Wave
The first group of AFA startups comprised DSSD, Kaminario, Pure Storage, Skyera, SolidFire, Violin Memory, Whiptail, X-IO and XtremIO. Pure and XtremIO achieved major success and XtremIO post-acquisition by EMC, became the biggest-selling AFA of its era, achieving $3bn in revenues after three years availability.

EMC was convinced of AFA goodness and spent $1bn buying DSSD, an early NVMe-oF array tech – but it bought a dud. After Dell bought EMC it canned the product in March 2017. This was possibly the biggest write-off in AFA history.

Pure Storage grew strongly, IPOed and has now joined the incumbents, boasting a $1.6bn annual revenue run rate.
Kaminario survives and is growing. Violin has survived a Chapter 11 bankruptcy and is recovering from walking wounded status.

Texas Memory Systems was bought by IBM and its tech survives as IBM’s FlashSystem arrays. Skyera stumbled and was scooped up by Western Digital in 2014.
SanDisk had a short life as an AFA vendor with its 2014-era IntelliFlash big data array, before it was bought by Western Digital in 2015 for an eye-watering $19bn. That was the price WD was willing to pay to get into the enterprise and consumer flash drive business.
SolidFire was bought by NetApp for $870m in December 2015.

Whiptail was bought by Cisco in September 2013 for $415m. It found it had bought an array tech that needed lots of development work. In the end itcanned the Invicta product in June 2015.
Second wave – hybrid starts go all-flash
The next round of AFA development came from Nimble, Tegile and VM-focused Tintri. These three prominent hybrid array startups quickly went all-flash and formed a second AFA wave;.
All have been acquired. HPE bought Nimble with its pioneering InfoSight cloud management facility for its customers arrays. Nearly every other array supplier has followed Nimble’s lead and HPE is extending the tech to 3PAR arrays and into the data centre generally.

Poor Tintri crashed, entered Chapter 11 and its assets were bought for $60m by HPC storage supplier DDN in September last year. Tintri gives it a route into the mainstream enterprise array business.

X-IO was another hybrid startup that went all-flash. It stumbled, went through multiple CEOs and then, under Bill Miller, sold off its ISE line to Violin. It continues as Axellio, a maker of all-flash IOT edge boxes.
Incumbents retrofit and acquire
The seven mainstream incumbent suppliers all bought startups or /and retrofitted their own arrays with AFA tech and in two cases tried to develop their own AFA technology. One, NetApp’s FlashRay, was killed off on the verge of launch in favour of AFA retrofitted ONTAP.
The other, HDS’s in-house tech, survives but is not a significant player. In other words, no incumbent developed an AFA tech from the start that became a great product.
Dell EMC retrofitted flash to VMAX and VNX arrays on the EMC side of the house, and SC arrays on the Dell side. IBM flashified its DS8000 and Storwize arrays. HPE put a flash transplant into its 3PAR product line.
And Cisco? Cisco gave up after killing Invicta.

Interfaces
Initially, SSDs were given SATA and SAS interfaces. Then much faster multi-queue NVMe interfaces were used with direct access to a server or drive array controller’s PCIe bus, instead of indirect access through a SATA or SAS adapter.
This process is ongoing and SATA is on the way out as an SSD interface. NAND tech avoided the planar (single layer) development trap looming from every smaller cells becoming unstable, by reverting to large process sizes and layering decks of flash one above the other in 3D NAND.
It started with 16, then 32, 48, 64, and is now moving to 96-layers with 128 coming. At roughly the same planar-to-3D NAND transition time, single-bit cells gave way to double capacity MLC (2bits/cell) flash, then TLC (3bits/cell) and now we are seeing QLC (4 bits/cell) coming.
The net:net is that SSD capacities rose and rose to equal disk drive capacities – 10 and 12 and 14TB – and then surpass them with 16TB drives.
This process accelerated the cannibalisation of disk drive arrays by flash arrays. All the incumbents are busy helping their customers replace old disk drive arrays with newer AFA products. It’s a gold mine for them.
Third wave of NVME-oF inspired startups
We have also seen the rise of remote NVMe access, extending the NVMe protocol across networking links such as Ethernet and InfiniBand initially and lCP/IP and Fibre Channel latterly, to speed up array data access.
This technology prompted a third wave of AFA startups: Apeiron, E8, Excelero, Mangstor and Pavilion Data. Interestingly, DSSD was a pioneer of NVMeoF access but, among other things, was too early with its technology.
Late arrival Vast Data has seasoned its NVMe-oF tech with QLC flash and Optane storage-class memory, giving it a one array-fits-most-use-cases- product to sell.
Mangstor crashed and fizzled out, becoming EXTEN Technologies, but the others are pushing ahead, trying to grow their businesses before the incumbents adopt the same technology and crowd them out.
However, the incumbents, having learnt the expensive lesson of buying in AFA tech, are adopting NVME-oF en masse.
The upshot is that 15 companies are pushing NVME-oF arrays at the market.
The storage-class memory era arrives
Storage-class memory (SCM), also called persistent memory, as exemplified by Intel’s Optane memory products using 3D XPoint non-volatile media, promises to greatly increase data access speed. Nearly all the vendors have adoption programs. For instance:
- HPE has added Optane to 3PAR array controllers.
- Dell EMC is adding Optane to its VMAX and mid-range array line.
- NetApp is feeding Optane caches in servers from its arrays.

The third wave of startups need to adopt SCM fast or face the prospect of getting frozen out of the NVMe-oF array market they were specifically set up to develop.
Fast-reacting incumbents are moving so quickly that large sections of the SCM-influenced array market, the incumbent customer bases, will be closed off to the third wave startups and that will result in supplier consolidation.
It has always been that way with tech innovation and business. Succeed and you win big. Fail and your fall can be long and miserable. But we salute the pioneers- the healthy like Pure and Kaminario, and the ones with arrows in their back – DSSD, Mangstor, Tintri, Violin, Whiptail, X-IO.
You folks helped blaze a trail that revolutionised storage arrays for the better. and there is still a ways to go. How great is that.