


MemVerge a stealth-mode startup, based in Silicon Valley, is developing shared pools of external Optane DIMM memory to make Spark and similar applications run faster than servers with local drives.
The company outlined the technology at the SNIA’s Persistent Memory Summit in January2019 and you can download the slides and watch the video.
The presentation shows how storage and memory can be converged using Optane DIMMs to reduce data-intensive application run times. Of course it is a sneak preview, and MemVerge gives no clue when it could become a shippable product.

The idea is to cluster Spark Accelerators – servers containing a CPU, some DRAM and Optane DIMMs – to form a single virtual pool of memory which is accessed by application compute nodes (servers) in a Spark Cluster using an Ethernet switch.
Data is analysed by the Apache Spark engine using MemVerge’s PMEM Centric Elastic Spark data storage system (PMEM is Optane persistent memory).
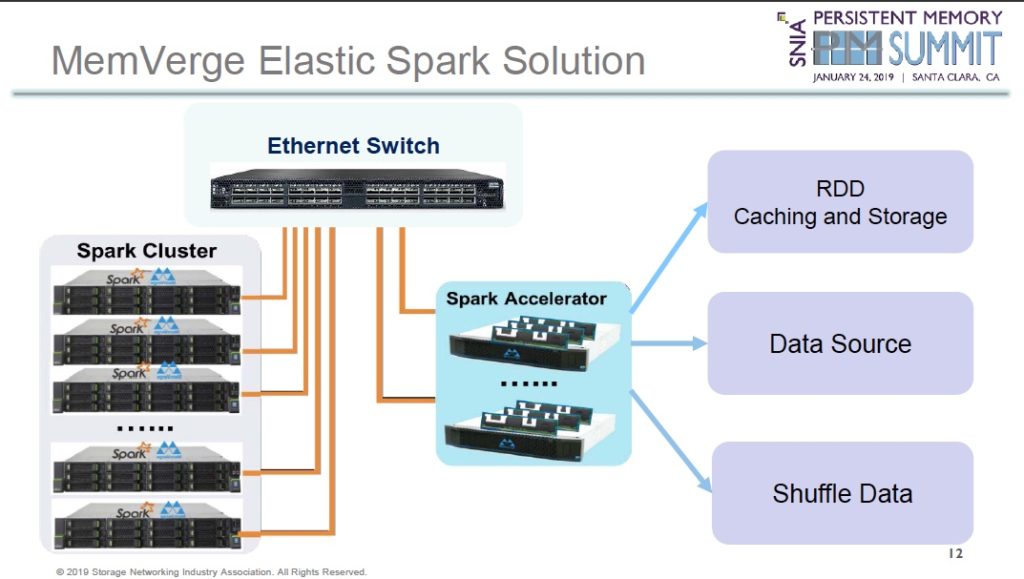
Spark cluster nodes run the Tencent Spark application and MemVerge software. Spark accelerators store source data for the Spark Cluster nodes and also intermediate calculation results called Resilient Distributed Dataset (RDD) and Shuffle data.
Shuffle dance
Shuffling is a process of redistributing data needed by the Spark application cluster nodes. It can mean data has to move between different Spark application servers.
If the shuffle data is held in a single and external virtual pool it doesn’t have to actually move. It just gets remapped to a different server, which is much quicker than a data movement.
A Spark Accelerator cluster looks like this architecturally:
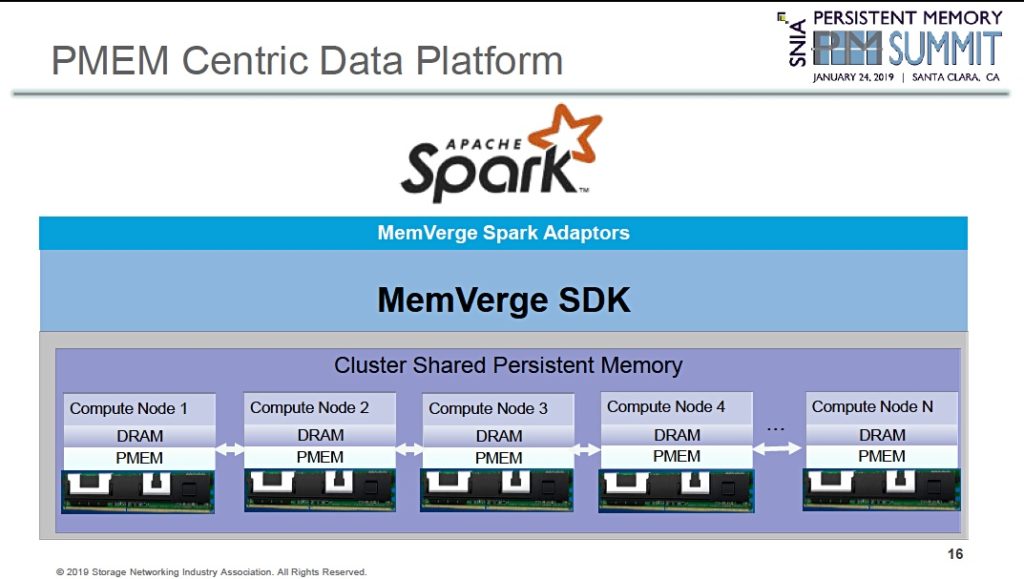
Individual accelerator nodes – called compute nodes in the diagram – use Optane DC Persistent Memory and standard DRAM. They present a pool of persistent memory through Spark adapters to the Spark accelerator nodes.
Each accelerator node has 12 x Optane DIMMs:

That number fits the 2-socket Cascade Lake AP Optane DIMM server configuration we are already familiar with.
Times table

In response to an audience question at the Summit, the MemVerge presenter, co-founder Yue Li, declined to say if the Spark cluster nodes accessed the accelerator nodes using RDMA. Blocks & Files thinks the company uses an RDMA-class access method to enable the accelerator to out-speed local drives in the cluster nodes.
Yue Li gave three performance examples in his presentation. First, a HiBench wordcount time run, with a 610GB data set, took 10 minutes using a 5-node Spark cluster with local SSDs while the PMEM-based Spark accelerator node took 2.2 minutes.
Second, persisting RDD data to a local hard drive took roughly a third longer than putting it in the remote PMEM pool formed by the Spark accelerators.
Third, shuffling data was also faster with the remote PMEM than local disk drives.
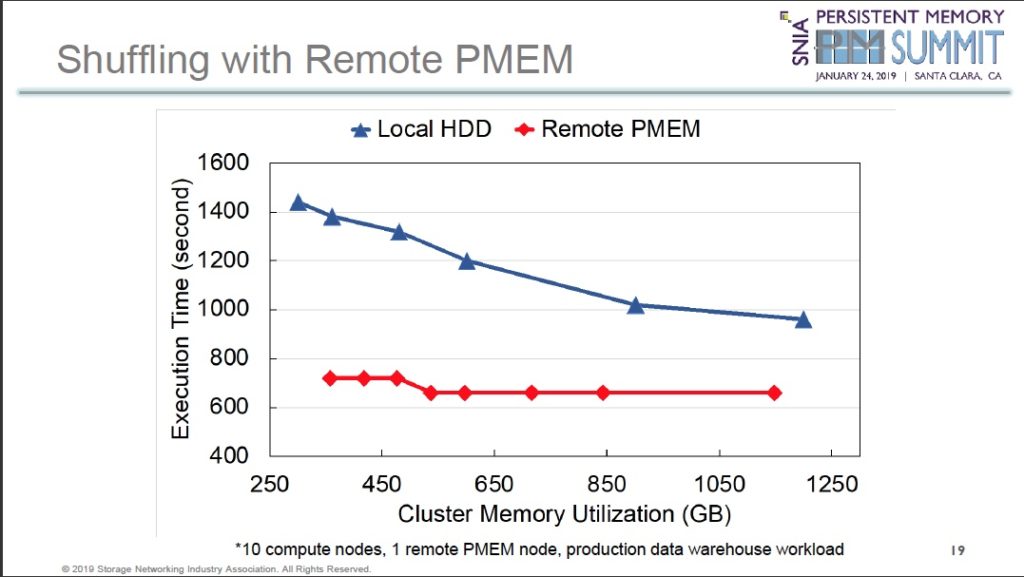
Asked why not simply put Optane drives in the Spark Cluster nodes, Yue Li said there could be a 1,000 or more such nodes, which makes it expensive and challenging. It is simpler and less expensive to build a single shared external PMEM resource, he said.
MemVerge is developing its technology with Intel’s help and in partnership with ecommerce powerhouse Tencent which has a Cloud Data Warehouse.





