Micron told the Sanford C. Bernstein Operational Decisions Conference last week that it has 3D XPoint SSD and memory DIMM roadmaps. This will take the company into direct competition on all fronts with the Intel Optane portfolio – in a couple of years or so.
In a wide-ranging interview, CFO Dave Zinsner said (transcript): “We want to continue to build out a portfolio for 3D XPoint.” He noted the technology “has some pretty interesting use cases particularly in the AI space.”
Zinsner’s remarks will resolve any ambiguity concerning Micron’s resolve to build and market 3D XPoint product on its own account. Many industry observers have questioned its commitment on this score. For instance, the technology analyst Jim Handy wrote last year that Micron might “desire to extricate itself from the 3D XPoint business while still satisfying alternate-sourcing agreements made by the company prior to XPoint’s 2015 introduction”.
Zinsner said the company is working with some of the “really big players in the space with this technology. The early read has been very positive, quite honestly, about it. But like all emerging technologies, adoption takes some time to get the use cases to the right place and get the cost and the performance at the right place… but we’re optimistic we’ll get there.”
Dave Zinsner
Micron currently builds 3D XPoint dies for Intel’s Optane 200 series products and Micron’s own X100 SSDs, which launched in October 2019.
This “was just kind of a teaser product to get it out there, “Zinsner said, “and there’s certainly a road map of products, both continued road map on SSDs, but also a road map on the memory front. And I think we should look for those products coming over the next couple of years.” At that point Micron will have second generation XPoint SSDs and also XPoint DIMMs.
Intel Optane 200 series products use generation 2 (4-deck) XPoint, launched in June, but it is unclear if Micron’s X100 SSDs have moved yet from gen 1 to gen 2 XPoint.
In reply to question about their status, Zinsner said: “We’re in really early stages… then we got to continually move to better generations that have better cost structure and also hopefully increase the performance.”
This implies the addition of more layers so that the cost per XPoint bit goes down. Zinsner declined to discuss layer counts on the call.
Zinsner said Micron still have not had any meaningful revenue outside of wafers that we’re selling to our prior partner in 3D XPoint, Intel… I think for the next couple of years, it’s probably not going to be a meaningful portion of our revenue as we kind of build out the portfolio and work on the cost side of things. But eventually, we’re fairly optimistic about this business.”
Micron’s XPoint fab is currently under-utilised, which affects costs: “We peaked out at around $155m or so in the third quarter [to end August] of underload charges associated with that fab. They were down in the fourth quarter to more like $135m. They’ll probably be down again in the first quarter [which finishes at the end of February 2021].”
Intel’s Ice Lake servers will unblock storage performance by reading data faster and loading it into a larger memory space. Storage writes are quicker too – that’s because Ice Lake supports PCIe 4.0, more memory channels and Optane 200 series persistent memory.
Ice Lake is Intel’s code name for the 10th generation Xeon processors which were introduced for laptops in August 2019. The server version, Ice Lake SP, is due in early 2021.
The company teased out some performance details last week to coincide with SC20. In her presentation for the supercomputing event, Trish Damkroger, GM of Intel’s High Performance Computing Group, proclaimed: “The convergence of HPC and AI is a critical inflection point. The Xeon SP is optimised for this convergence.”
We’ll discuss that another time. Let’s dive into the numbers.
In general, Ice Lake should provide up to 38 per cent faster SPEC floating point rate benchmark performance, at identical core count and frequency as a Cascade Lake Xeon. The greater memory capacity of Xeon SP Ice Lake servers translates into fewer IOs slowing down the processor, hence significantly faster app processing speed and storage IO overall.
PCIe Gen 4 is twice as fast as the current PCIe Gen 3’s 32GB/sec maximum. The standard supports up to 16 lanes and 16Gbit/s data link speed to deliver 64GB/sec. This means stored data can be loaded into memory faster – and that memory can be larger with Ice Lake.
Ice Lake SP increases memory capacity with two more memory channels per socket, with eight x DDR4 channels. Xeon Scalable Performance (Skylake) series processors have two built-in memory controllers that each control up to three channels. That equals six memory channels per CPU [socket]. Up to two DIMMs are possible per channel, totting up at 12 DIMMs per CPU. So, a Xeon SP M-class CPU has a maximum of 1.5TB of memory, or 0.25TB per channel. Ice Lake increases the memory channel count to eight, handling 2TB of DRAM.
Trish Damkroger slide from her SC20 presentation.
Memory performance is faster at 3,200 MT/s, up from 2,933 MT/s. And bandwidth is increased to 190.7 GiB/s, up from 143.1 GiB/s.
In conjunction with Optane persistent memory, Xeon Cascade Lake has 4.5TB overall memory capacity. Ice Lake increases this to 6TB, using gen 2 Optane with sequential read bandwidth of 8.10GB/sec and 3.15GB/sec for write bandwidth. The first generation Optane PMem series runs up to 6.8GB/sec read and c2.3GB/sec writes.
Ice Lake and Sunny Cove
Intel is to introduce Sunny Cove, a new core microarchitecture, for Ice Lake. This is designed for Intel’s 10nm+ technology and provides about 18 per cent more instructions per clock (IPC) than its predecessor in the Xeon Skylake chips. Things that make Sunny Cove chips faster include a 1.5x large level 1 cache, 2x larger Level 2 cache and elements such as higher load-store bandwidth and lower effective access latencies.
Multiple data storage vendors surfed on this week’s Kubecon conference to push out Kubernetes announcements. But first, let’s kick off with a little acquisition.
P.S. Check out my stories on The Register this week.
Data protector Acronis has bought CyberLynx, a small Israeli IT security consultancy. This will increase training and solutions options for Acronis Security Services, in particular for serving managed service providers;(MSPs) and managed security service providers (MSSPs).
Five mainstream storage suppliers have announced containerised app news to coincide with this week’s KubeCon.
Commvault’s Metallic VM & Kubernetes Backup is available and provides SaaS data protection for containers. Protected workloads include any CNCF-Certified Kubernetes distribution with validated support for Red Hat OpenShift Kubernetes, Azure Red Hat OpenShift, Azure Kubernetes Service (AKS), Amazon Elastic Kubernetes Service (EKS), and VMware Tanzu. The Hedvig Distributed Storage Platform has been enhanced to store, protect, and migrate containers across hybrid multi-cloud environments.
NetApp is the starting member of a Rancher Labs OEM and Embedded Alliances Program, and is working to pioneer the next evolution of hyperconverged infrastructure (HCI) services. NetApp HCI will be the first to embed Rancher’s enterprise Kubernetes management platform.
Pure Storage-owned Portworx has updated PX-Backup to v1.2 which works with any Kubernetes CSI-supporting backend. It works with Portworx’s own PX-Store, Amazon EBS, Google Persistent Disk, Azure Managed Disks, VMWare Storage, Pure FlashArray, and any other CSI-compatible storage system. PX-Backup v1.2 has a usage-based billing model priced at 20 cents/node/hour.
Veritas has added Kubernetes support to InfoScale automated high-availability software, which will support multi-vendor cloud and on-premises environments. It adds high availability for containerised applications with non-disruptive scaling of persistent volumes; three storageclasses of persistent volumes (performance, resiliency and secure; and. quality of service features to provide predictable performance.
Disaster Recovery supplier Zerto is adding data protection and disaster recovery for containerised apps with the beta program of Zerto for Kubernetes (Z4K), an extension of its core Zerto Platform. The Z4K beta program includes access to a remote access hands-on lab running the Z4K beta code. The lab has no-charge, on-demand training on how to set up, configure, and manage a Z4K environment.
A Zerto-sponsored ESG survey of North American enterprises revealed that containers adoption is in full acceleration and in position to become the preferred for production deployment in 24 months. 71 per cent of survey respondents have deployed or plan to deploy container-based applications in a hybrid-cloud strategy.
Shorts
Cloud providers in the VMware Partner Connect program can protect healthcare data from ransomware with free Cloudian software. For every healthcare organisation enrolled, VMware cloud service providers serving this industry receive a free 50 TB, year-long license for Cloudian object storage, including Cloudian’s government-certified Object Lock technology.
Datadobi has announced support for NAS file data migration to and protection on Microsoft Azure. Data integrity is fully preserved between the two locations.
DDN‘s SFA18K’s storage platform has been selected for tier 2 storage for the Fugaku supercomputer. Five SFA18KE and 25 SFA18KXE devices will provide a total effective capacity of at least 150 PB, with a minimum effective throughput of 1.5 TB/sec. They will be compute nodes for OSS (object storage servers), which serve as a gateway to other data storage units. Fugaku is a joint development with RIKEN and Fujitsu, and ranks first in the Top500 list. It goes into operation 2021.
DDN’s A³I A1400X all-NVMe flash storage system will be used by the University of Florida’s HiPerGator supercomputer to help make it the world’s fastest AI supercomputer in academia. HiPerGator will use 4PB of storage to feed 140 NVIDIA DGX A100 systems, which contain 1,120 NVIDIA A100 Tensor Core GPUs, with data flowing through an Nvidia Mellanox HDR 200Gbit/s InfiniBand network.
DDN A³I
Druva has added detection of unauthorised or non-compliant admin access into the backup environment and unusual data activity alerts. Users can search for and delete malicious files across endpoint backups to prevent re-infection. The software automatically creates a recovery snapshot from the last known good snapshots at the backup and file level, and scans for malware during recovery to prevent re-infection.
Druva acquired sfApex, a Salesforce developer tools and data migration service provider. Druva says its SaaS offering, combined with sfApex, delivers comprehensive SaaS data protection and management for Salesforce with granular backup and data recovery, streamlined and automated migrations, and improved tools for developers
Central Pacific Bank, a commercial bank in Hawaii, has implemented HPE Nimble Storage dHCI to support 1,000 virtual desktops, allowing expanded remote working for employees, continuity of regulatory compliance and improved performance, efficiency and cost savings overall.
HPE and StorMagic have announced a joint hyperconverged edge system, with StorMagic SvSAN validated with HPE Edgeline Converged Edge Systems. SvSAN runs on any hypervisor as a guest virtual machine to enable highly-available shared storage and virtualisation with two Edgeline servers per site. Active-active synchronous mirroring creates a copy of data on both servers, eliminating downtime.
Microsoft’sAzure HPC team has used the BeeOND (“BeeGFS On Demand”) filesystem, 300 HBv2 virtual machines and 250TB of NVMe SSD capacity to reach 1.46 TB/sec of read throughput and 456GB/sec of write bandwidth. They claim this is at least 3.6 higher read performance than that demonstrated or claimed elsewhere on the public cloud.
Pure Storage has had an episode of minor lay-offitis with people leaving, we heard, in New Zealand and elsewhere. A Pure spokesperson said: “We undertook a minor workforce rebalancing initiative in one function to align our employees with company priorities and areas that are strategic to the business. The employees affected by this initiative were encouraged to seek other open positions within the company and we also put support in place to aid them through the workforce transition if seeking a new role outside of Pure.”
Pure Storage has announced the Pure Validated Design (PVD) program to help partners deliver simplified deployments. PVDs are available, for Commvault data protection and Vertica for analytics. More PVDs will arrive in the coming months.
Storj Labs has announced Velero (data recovery and migration in K8s environments) and Docker Registry integrations with its Tardigrade Decentralised Cloud Storage Service, launched earlier this year. Tardigrade’s network capacity has grown from 22PB to 78PB and the user count from 3,600 to 11,200. Carnegie Mellon University and the University of Maryland are new Tardigrade storage partners.
WekaIO has set up a validation and certification program to help server partners certify their hardware running the Weka File System (WekaFS) with Nvidia DGX A100. It has also published a reference architecture for using Weka with the DGX A100.
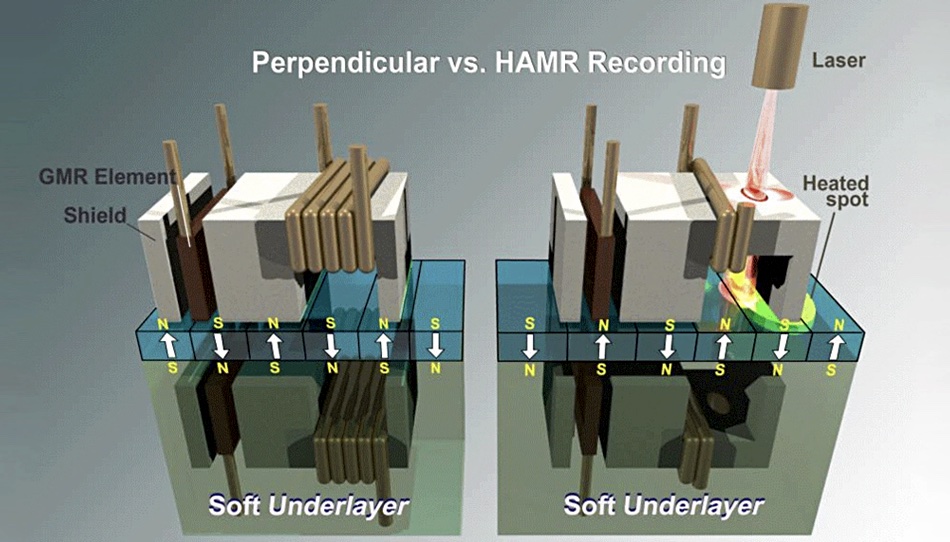
Seagate CEO Dave Mosley told an investment conference this week that he wants to make bigger capacity jumps on hard disk drive developments – and HAMR technology will help the company achieve this. Seagate will move from its first 20TB HAMR technology to a 24TB HDD, missing out a 2TB intermediate step, he said.
Heat-assisted magnetic recording (HAMR) pushes disk drive areal density beyond the limits of current perpendicular magnetic recording (PMR) technology. It uses a more stable, harder-to-change recording medium than PMR, making it possible to write data by heating the bit areas using a laser.
HAMR vs PMR.
The 20TB drive may cost more to make than non-HAMR 20TB drives because each head must have a laser heating diode.
Dave Mosley.
Seagate aims to spread HAMR technology widely across its disk drive range to amortise expense across a greater number of drives and so lower the per-drive cost, Mosley told the conference.
He said HAMR technology, with its higher density platters, could be used for lower capacity 12TB and 16TB drives, as a way of taking out platters and heads, while offering the same capacity, to cut costs. Mosley said: “If we can save a disk and two heads in a 16, we will look at doing that.”
Western Digital, Seagate’s arch-rival, thinks microwave assisted magnetic recording (MAMR) is a better way to push disk drive capacity levels into 20TB and beyond, partly because drive read/write heads do not require the addition of a laser heating element. However, WD acknowledges it may have to move to HAMR eventually, because the technology increases areal density more than MAMR.
Mosley said: “We know MAMR really well. It’s a viable technology, but it’s, again, a small turn of the crank. What we believe is that HAMR, largely because of the media technology, the ability to store in much, much smaller grain sizes with better signal noise, with much more permanence, we believe that HAMR is the right path.”
And it’s the way to be able to make bigger jumps in capacity than the smaller increments achievable with MAMR. Think about it this way; WD says MAMR knows best while Seagate says HAMR blows are what we need.
Amazon has made it easier for customers to figure out how to reduce their S3 cloud object storage costs, with a new analytics dashboard.
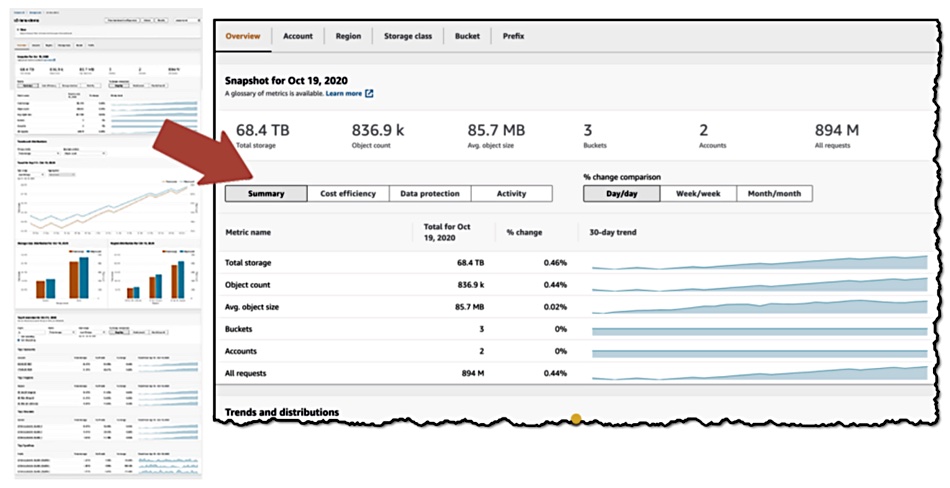
AWS’s S3 Storage Lens enables users to get a customer-wide handle on multiple S3 buckets in multiple AWS regions. Prior to the launch of the service, users had to manage S3 buckets individually – a tall order for heavy users.
The interactive dashboard is located in the S3 console and enables admins to perform filtering and drill-down into metrics to show how and where S3 storage is used. Metrics are organised into categories like data protection and cost efficiency.
The utility includes point-in-time and rolled-up metrics, trend lines and recommendations. There are 29 usage and activity metrics and the dashboard aggregates data for an entire organisation, specific accounts, regions, buckets, or prefixes. All the Storage Lens data is accessible in the S3 Management Console or as raw data in an S3 bucket.
AWS Storage Lens
You can configure this dashboard or use AWS tools to create your own from scratch.
S3 Storage Lens has two tiers. Free Metrics, contains 15 usage related metrics, is free of charge and automatically available for all S3 customers. The paid-for Advanced Metric plan includes all 29 usage and activity metrics with 15-month data retention, and contextual recommendations.
A Storage Lens video describes Storage Lens and how it works and a blog by AWS Principal Advocate Martin Beeby provides more detailed information. A product details webpage goes into greater depth.
S3 Storage Lens is available in all commercial AWS Regions. You can use it with the Amazon S3 API, CLI, or in the S3 Console.
Rubrik has announced a major software release thats speeds backup and restore and extends public cloud coverage.
The data protection vendor’s Cloud Data Management (CDM) Andes 5.3 release also adds faster file scans and validates Oracle database restores.
Rubrik president Dan Rogers provided a statement: “With Andes 5.3 … companies can add automation to their data operations, protection across hybrid environments including all three major public cloud providers, and mitigate increasing data risks.”
That sounds bland but let’s consider the problem area for a moment. Rubrik has to provide enterprise backup and restore facilities, enable adherence to compliance regulations, and protect on-premises and three major public cloud environments from malware.
The number of things to be backed and restored – databases, applications and files – gets larger month by month and their size can grow too. A Rubrik customer could have 100 databases, 1,000 databases, 5,000 databases, even 10,000 or more, according to CEO Bipul Sinha. That means Rubrik’s system has to scale to cope, and run faster to keep pace with the growth.
Bipul Sinha
Sinha said: “Every aspect of Rubrik recovery has to be superfast.”
Andes 5.3’s multiple speed improvements include:
10x faster backups of SQL Server environments with hundreds of databases per host–supporting up to 10,000 SQL databases on a single Rubrik 4-node cluster
Oracle backup speed doubled to nearly one gigabyte per second
‘Recovery Validation’ feature for Oracle will enable validation and recovery tests that ensure an Oracle database is recoverable to a valid state
NAS restore performance has improved 3x and NetApp scanning performance has doubled, allowing for 35 million files to be scanned in less than 15 minutes.
Sinha told us in a briefing that Covid-19 has accelerated enterprise’s movement to hybrid clouds and remote working. This hybrid cloud movement is the context for the second group of new features.
CDM supports Google Cloud to include VMs and file sets, and automated discovery and backup of SAP HANA using SLA-based policies
Protection of VMware Cloud on AWS adding to VMware protection across on-premises, AWS, Azure and Google
Cloud-native Polaris management for Amazon RDS, enabling unified protection of RDS across multiple AWS accounts and regions, and recovery to different AWS regions
New protection of Oracle databases on AWS and Azure
Improved Smart Tiering to archive data to cool storage when storage savings are greater than the compute costs of having to reconstruct the data for recovery.
Rubrik told us Smart Tiering “works in Azure and we are working on a similar capability for AWS. For AWS, we offer instant tiering which allows customers to move data directly to Glacier or Deep Glacier storage at a fraction of the cost of S3.” The company will roll outSmart Tiering to AWS and GCP in the near future.
Rubrik’s next release of the Polaris Sonar compliance product will offer visibility into high risk locations, including sensitive files open to everyone and those that contain data that has not been accessed for some time.
Customer count
In our briefing, Sinha disclosed that Rubrik has passed the 2,700 customer count and is adding new enterprise customers at a rate of 200-300 per quarter.
He said Rubrik has a unified backup and storage offering that provides for immutable backups and protection against ransomware and contrasted this with Cohesity, Commvault, Veeam and others. He characterised these competitors as providing separate backup and storage products, with the storage product acting as a second attack surface for malware.
We noted the recent Veeam-Kasten and Pure-Portworx acquisitions and asked Sinha if Rubrik had considered buying or developing cloud-native backup of containerised apps. Rubrik wants to enter this space, he replied, and reminded us that the company had bought Datos IO for distributed database backup.
Remember GDPR? Of course you do. The GDPR directive gives individuals the right to be forgotten and requires EU and UK companies in certain instances to erase all personal data per a customer’s request.
But this is problematic when details are contained inside a non-searchable database backup file. At first sight the individual has been forgotten, but if a backup file is restored the business again has that person’s details in plain view, and so breaks the GDPR rules.
OCL Technologies, a California startup, has devised a continuous data privacy SaaS-based tool, Forget Me Yes (FMY), which it claims ensures the right to forget really does mean “forget me”.
CEO and president Michael Johnson said: “FMY’s Zero Knowledge Proof (ZKP) platform technology ensures auditable privacy and security throughout the entire compliance process”.
OCL gave us an advanced briefing on the ‘ForgetMeYes’ utility, which is soon to launch formally. The technology assures businesses that they are compliant with GDPR right-to-be-forgotten requests, the company says. Initially it is being tested against Salesforce and should be extended to other data sources.
ForgetMeYes verifies the right to be forgotten and right of erase data subject compliance requirements of the CCPA, LGPD, SB220 and GDPR regulations.
For example, individuals have the right to have search results removed from Google results if they are inaccurate, irrelevant or “considered superfluous”.
When a business, like Google, expunges records of a person exercising a right-to-be-forgotten ruling, that business removes all mentions of the person from databases, emails, etc. To verify this is that you have to run a query against the databases, email records, etc. And that query has to contain the name and other details of the person that’s been forgotten. i.e. the business has to remember it, which it cannot do.
OCL Technologies addresses this with an indirect, coded representation of the ‘forgotten’ people that does not directly identify them. The software runs this as a query against the various source databases and files looking for that target term. If it is found – maybe a backup has inadvertently restored the forgotten person’s records, then the person’s details are deleted afresh.
The infrared image from NASA's Spitzer Space Telescope shows hundreds of thousands of stars in the Milky Way galaxy
Pavilion Data, the high-end array vendor, has released a speedy parallel file system that brings it into direct competition with major HPC storage players for the first time.
The new capability, modestly called HyperParallel File System, means that Pavilion now provides probably the fastest unified file, block and object storage array in the industry. In fact, the startup claims this system is the most performant, dense, scalable, and flexible storage platform in the universe.
Gurpreet Singh.
Customers can accelerate all workloads, such as AI/ML, Analytics, HPC, and at the Edge, according Gurpreet Singh, Pavilion Data CEO. “With our announcement today,” he said, “customers are able to … process massive amounts of unstructured file and object data, without limits and at unprecedented speeds to extract the most value out of their critical assets.”
The superlatives keep coming. Marc Staimer, President of Dragon Slayer Consulting, said in a statement, “Pavilion has been able to achieve industry leading performance for simultaneous block, file, and object workloads, at scale, while using standards based hardware in an incredibly compact form factor. This is truly impressive. What’s even more amazing, it is the first in the industry.”
Just one more, from Eric Burgener, research VP for the Infrastructure Systems, Platforms and Technologies Group at IDC. “The system efficiently delivers extremely high performance and low latency, predictably at scale, providing a highly efficient end-to-end NVMe-based platform suitable for high performance cloud native as well as traditional workloads that significantly outperforms the competition, with in many cases a 50 per cent to 75 per cent smaller footprint.”
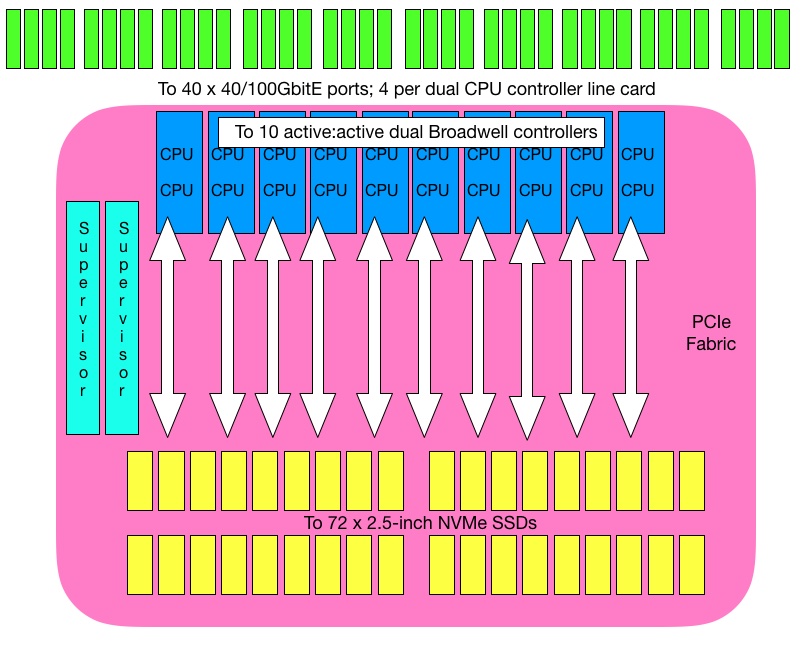
The set-up
Pavilion Data’s 4RU HyperParallel Flash Array (HFA) has up to 20 controllers linked across NVMe to up to 72 SSDs, with NVMe-oF external access. The company’s HyperOS 3.0, released today, has added the HyperParallel File System with multi-chassis, global namespace support for NFS and S3, enabling linear scaling across an unlimited number of clustered HyperParallel Flash Array systems.
Pavilion Data HFA scheme
A single HFA delivers 120 GB/sec throughput, 25µs of latency, and 2.2 PB of storage in its 4R form factor. At rack level It can provide 20.2PB of capacity, 1.2 TB/sec read, 900 GB/sec write bandwidth, and 200 million IOPS at the same 25µs latency.
Pavilion says this is up to 4x the read performance and up to 8x the write performance for NFS and S3 data versus the incumbent and new players in this space. We take incumbents to mean Dell, HPE, NetApp and Pure, and new players to include Qumulo, StorOne, WekaIO and VAST Data
Pavilion arrays support iSCSI, NVMe-oF/TCP, NVMe-oF/RoCE, NFS, and S3. They can also link to an external file system such as IBM Spectrum Scale, Lustre, or BeeGFS. A single HFA supports up to 20 controllers and 40 100Gbit/s Ethernet or InfiniBand ports.
NFS data services include tiering, replication, security, snapshots, clones, encryption, and compression. S3 data services include compression, replication, file access controls, identity management, multi-cloud tiering, and multi-ecosystem integration.
Money talk
Singh said in a video press briefing that Pavilion’s Q3 was a blockbuster quarter, with nearly 10x revenue growth y/y, and equivalent to Pavilion’s entire 2019 revenues. Recent wins include PayPal and Cisco.
DDN this week spruced up its enterprise portfolio with EXAScaler and DataFlow upgrades, and a new midrange storage array line-up. The enhancements are intended to establish the HPC storage vendor as a good fit for mainstream enterprise AI/ML and analytics workloads.
Update; Infiniband link speeds added to DDN, WekaIO and VAST Data GPU data delivery speed comparisons. Nov 19, 2020.WekaIO provides 173.9GB/sec (162 GiB/sec) to a DGX A100. Nov 20, 2020.
Philippe Nicolas, lead analyst, Coldago Research, said in a statement: “Broadening [DDN’s] portfolio to address the growing AI and performance needs of Enterprise environments is a prudent decision that will improve operational efficiencies for countless organisations.”
Let’s start with EXAScaler 5.2, the new version of DDN’s Lustre parallel file system storage array. EXA v5 was announced in June 2019 and used Lustre v2.12. EXAScaler 5.2 adds snapshots and synchronised data movement between EXAScaler and other file systems, including public clouds. A search facility offers fast metadata scans and file searches at any scale. Admin staff can create new statistics and visualisations to hep improve efficiency and trend analyses.
EXAScaler array models
DDN’s DataFlow management software gets deeper hooks into EXAScaler and can identify file changes and move incremental data to a customer’s designated location. Users can set up DataFlow to customers to migrate data to the cloud, enabling cloud synchronised file systems and snapshot capabilities.
DDN has also rebranded the mid-range Tintri IntelliFlash H-Series to sell as the DDN IntelliFlash H-Series, emphasising the hardware commonality across the DDN and Tintri ranges.
Pumping high speed data to GPUs
Separately, DDN has demonstrated data delivered at 173.9GB/sec (162 GiB/sec) from its A3I storage to Nvidia’s DGX A100 GPU server with its eight A100 GPUs.
This uses Nvidia’s GPUDirect technology and is claimed to be 60x faster than NFS. There is a Reference Architecture with Nvidia for DGX SuperPOD customers. A3I storage uses EXAScaler arrays.
DDN A3I system.
The A100 has a huge data intake capacity with eight x single ported Mellanox ConnectX6 Network Interfaces using HDR200 (200Gbit/s InfiniBand). They link to four PCI switches, each with two GPUs and two NICs. The four PCI switches are interconnected through two AMD CPUs. DDN claims to be pumping data at almost the full line rate capability of the eight HDR200 NICs.
We don’t have direct comparisons with other storage suppliers’ ability to deliver data to the DGX A100.
VAST Data has achieved 92.6GB/sec to the 16 Nvidia A100 GPUs inside a DGX-2 using 100Gbit/s InfiniBand.
On a per-A100 GPU basis DDN delivers 21.7GB/sec across 200Gbit/s IB with Weka pumping out 20.25GB/sec. VAST provides 5.8GB/sec across 100Gbit/s IB, if our back-of-the envelope calculations are accurate.
EXAScaler 5.2, the new DataFlow features and the DDN IntelliFlash H-Series are available now directly from DDN and through certified partners.
The University of Cambridge has plumped for NetApp HCI in an IT infrastructure overhaul that underpins online teaching and learning.
The Covid-19 ready solution sees Citrix Workspace desktop software, running on NetApp hardware. Citrix Consulting helped to install the NetApp HCI hardware and Citrix Workspace is now available to thousands of users.
NetApp HCI enables Cambridge University Information Services (UIS) to take advantage of cloud and scale storage and compute and reduce software licensing costs.
NetApp will help UIS to centralise, consolidate, and migrate the IT portfolio to a private cloud environment. The company says it will help develop an IT billing system for use across the university.
UIS said it “consolidated multiple storage systems and services offered by the university. We then searched for efficiencies through automating processes, improving scalability and eventually move some of our larger workloads to the cloud. Our partnership with NetApp allows us to consolidate many of our services, and saving much needed resources while delivering to staff and students’ needs in the ‘New Normal’.”
UIS has selected NetApp HCI, previously known as the Solidfire all-flash arrays with the Elements OS. NetApp HCI comprises software running on H series hardware nodes, as this datasheet illustration depicts:
NetApp HCI nodes
NetApp says that the UIS move to the cloud has enabled students and staff to work and lecture remotely, and also meet high performance and reliability SLAs and service-level objectives for nuclear physics simulations and big data analysis involved in the university’s research programmes.
Cambridge University’s Department of Computer Science and Technology has run NetApp file servers in a system called Elmer since 2002.
Interview; Storage IO slows down applications and there is nothing you can do about it, except by not doing it. In-memory computing accelerates applications to sprint speed by having them run entirely in memory. This eliminates storage IO, except when the application is first loaded into memory.
However, memory is expensive and capacity per server is limited by the number of sockets and channels up to 1.5TB. If an application’s code and data is larger than 1.5TB it can’t all run in memory. Some storage IO Is necessary.
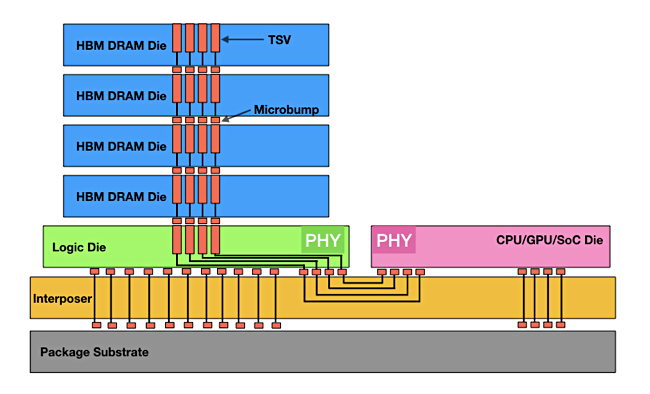
The use of Optane persistent memory increases server memory capacity to a maximum of 4.5TB per server, greatly increasing the space available for in-memory applications. Newer memory technologies such as DDR5 and HBM should enable in-memory applications to run even faster. But how much faster?
John DesJardins, CTO of Hazelcast, the developer of an in-memory computing platform, has shared his thoughts with us about Intel Optane PMem, HBM and DDR5 DRAM. Check out our interview below.
Blocks & Files: DRAM is expensive so an in-memory app needs costly memory. Is storage-class memory, like Optane, worth the money?
John DesJardins: Hazelcast has benchmarked with Intel Optane and found it performs well, offering an attractive, lower cost alternative to DRAM.
John DesJardins
Blocks & Files: How does Hazelcast extend memory by using persistent memory like Optane or Samsung’s Z-SSD or Kioxia’s X SSD?
DesJardins: Hazelcast is optimised as a pure in-memory platform, meaning that our data, indexes and metadata all are retained in-memory for ultra-low-latency performance. So, we don’t use SSDs or other storage to extend memory. We do offer persistence features for ultra-fast restarts or optionally for data structures such as within our CP Subsystem. These persistence features can leverage either Optane PMem or SSDs including Intel Optane SSD, OCZ Octane SSD, Samsung Z-SSD, etc.
Blocks & Files: How does it compare and contrast these different storage-class memory devices?
DesJardins: Intel Optane PMem dramatically outperforms other storage class memory in our benchmarks. We see nearly 3X faster restart times with Optane PMem, for example.
Optane Persistent Memory.
Blocks & Files: How does it use Optane PMem such that no app code changes are needed?
DesJardins: Hazelcast provides advanced Native Memory features that extend beyond Java to fully leverage memory and storage interactions available from the Operating System level, and this has been extended to leverage Intel libraries for Optane PMem. These capabilities are all abstracted and managed via simple configurations within our platform, eliminating any need for application code changes to leverage Optane PMem.
Blocks & Files: Can Hazelcast show price performance data to justify PMem use?
DesJardins: We are working with Intel on a paper that will include the price/performance TCO figures to justify Optane PMem. We expect to release this paper within the next few weeks and are happy to share it.
Blocks & Files: What does Hazelcast think of DDR5?
DesJardins: Hazelcast tracks and evaluates all advances in hardware technology to assess their impact and the benefits to our customers. As they become available on the market, we will do more detailed benchmarks. We see good potential in DDR5 to improve performance.
However, as the standard for DDR5 DIMMs was only released on July 14, 2020, we have not yet done benchmarks to know what that level of impact will be. Until now, DDR5 was only available integrated into GPUs and other specialised processors.
DesJardins: We are tracking High Bandwidth Memory technology but have not yet seen it mad available in server class hardware or from Cloud Service Providers outside of being integrated with GPUs or other specialised processors. The first availability of HBM in general purpose DIMMs seems to be with DDR5. We will continue to track demand and availability, as well as assess how these technologies apply to our customers’ use-cases. As technology is available, we will benchmark with it, and where it makes sense, optimise our platform to leverage it.
Blocks & Files: Does in-memory processing benefit containerised apps? Can Hazelcast work with Kubernetes?
DesJardins: Yes, in-memory platforms work very well within containerised applications. Hazelcast is Cloud-Native and supports Kubernetes, as well as Red Hat OpenShift, VMWare Tanzu and Kubernetes on major Cloud Service Providers.
Comment
The net:net here is that in-memory applications will get larger and execute in less time. They have an inherent advantage over traditional applications that can’t fit into memory and have to use storage IO.
But in-memory compute will still only be available to a minority of applications overall, until memory capacity limits such as CPU sockets and memory channels are swept away, and until DRAM becomes more affordable.
Igneous, the Seattle-based data management startup, has laid off an unspecified number of staff, citing a “difficult economic environment”.
A company spokesperson confirmed the layoffs, adding: “We continue to serve our customers and work with our partners to deliver value.”
According to LinkedIn, Igneous employs 51-200 people. Pitchbook estimates 75 staff are on the books.
Igneous has developed a UDMaaS (Unstructured Data Management-as-a-Service) that provides a petabyte-scale unstructured data backup, archive and storage system with a public cloud backend. At the end of 2019, the company said it had 40-60 customers.
The company was founded in 2013 to develop software to manage massive file populations (read our profile). It has raised $66.7m in venture funding, including $25m in the most recent round in March 2019.
Founding CEO Kiran Bhageshpur resigned in December last year, while retaining a seat on the board. Dean Darwin, the incoming CEO and President, joined the Igneous board in June 2019. His career includes senior roles at Palo Alto Networks and F5 Networks.